
使用MQL5和Python构建自优化的EA(第四部分):模型堆叠

在本系列文章中,我们将讨论构建能够动态适应不断变化的市场条件的交易应用程序的不同方法。我们可能有无限多种方法来解决这个问题,但并非所有可能的解决方案都有效。因此,我们今天的目标是展示和实证分析不同可能解决方案的优点和缺点,以帮助您改进交易策略。
交易策略概述
我们将关注新西兰元兑日元(NZDJPY)货币对的预测。我们希望从MetaTrader 5终端收集的该货币对数据中,算法化地学习一种交易策略。作为人类,我们可能天生倾向于与自己的信念和利益一致的交易策略。机器学习模型也有偏差。机器学习模型的偏差是模型所做的假设被违反的程度。我们的交易策略将依赖于2个AI模型的集成。第一个模型将被训练以预测新西兰元兑日元货币对未来20分钟的收盘价。通过训练第二个模型,以便预测第一个模型所给出的预测误差量。这种技术被称为堆叠(stacking)。我们希望通过堆叠2个模型,能够克服人类自身的偏差,并且希望这足以引领我们达到更高的性能水平。
方法论概述
我们使用定制的MQL5脚本从MetaTrader 5终端获取了大约9000行新西兰元兑日元(NZDJPY)货币对的M1市场数据。我们创建了市场数据的二维和三维散点图。然而,我们未能在数据中识别出任何明显的关系。我们还对数据集进行了时间序列分解,并能够识别出数据中明显的下降趋势和强烈的季节性效应。
我们的数据随后被划分为训练集和测试集。一组15种不同的模型在训练集上进行了拟合和评估。随机梯度下降(SGD)回归器是该组中表现最优的模型。
随后,当我们分析特征重要性指标时,我们发现最高价似乎是预测新西兰元兑日元货币对未来收盘价所拥有的最具信息量的预测因子。最高价获得了最优的互信息(MI)分数。此外,我们还采用了 scikit-learn 库中实现的递归特征消除(RFE)算法。RFE算法认为我们所有的预测因子都很重要。然而,正如我们将在探讨中所看到的,仅仅因为存在关系,但并不能保证能够成功地捕捉并建模。
在确定了表现最优的模型之后,我们接着对模型参数进行调整。在参数调整之后的探讨中,我们通常会通过比较定制的模型与默认模型的性能来测试过拟合。然而,测试过拟合的方法有很多种。今天,我们选择通过分析模型的残差来测试过拟合。我们观察到模型的残差与其滞后项之间存在高度相关性。通常,一个已经充分学习的模型的残差应该没有相关性。因此,这表明我们的最优表现模型可能没有有效地学习,或者存在其他数据可以帮助解释目标,而我们未能包括这些数据。
之后,我们在训练集和测试集上记录了模型的残差。此时我们没有在测试集上拟合模型。然后我们在SGD回归器的训练残差上对15种模型进行了交叉验证。表现最优的模型是Lasso回归,然而我们选择了排名第三的模型,一个深度神经网络(DNN),作为我们的候选解决方案。我们这样做的理由是深度神经网络提供的灵活性使我们有机会更好地将其调整到数据上,而我们无法像这样对Lasso进行调整,因为Lasso的可调整参数数量有限。
我们通过一个两步过程调整了我们的DNN回归器,以预测SGD回归器的残差,从而得到了两个独特的模型。我们首先对DNN回归器的参数进行了100次随机搜索迭代,从而创建了第一个模型。我们识别出的最优连续参数,被用于有限内存L-BFGS-B算法进行无约束全局优化尝试的起点,这也是我们如何获得第二个模型。两个模型在未见的验证数据上都优于默认的DNN回归器。此外,我们的最后一个模型是表现最优的模型,这意味着我们经过了额外的两步过程并没有浪费时间。
最后,我们将两个模型导出为ONNX格式,并继续构建一个能够自我纠正错误的AI驱动的EA。
获取我们需要的数据
我们将从MetaTrader 5终端获取我们需要的数据。以下附加的脚本将从我们的终端获取指定数量的历史价格数据,然后以CSV格式写入数据,并将其存储在我们的“Files”文件夹中。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
清理数据
我们将首先对数据进行格式化。第一步,加载我们需要的库。
#Import the libraries we need import pandas as pd import numpy as np
现在读取市场数据。
#Read in the market data
nzd_jpy = pd.read_csv('Market Data NZDJPY.csv') 数据的顺序是错误的,让我们将其重置,以便从最早的日期开始,最接近当前时刻的日期应该排在最后。
#Format the data nzd_jpy = nzd_jpy[::-1] nzd_jpy.reset_index(inplace=True, drop=True)
定义目标。
#Labelling the data nzd_jpy['Target'] = nzd_jpy['Close'].shift(-20) nzd_jpy.dropna(inplace=True)
我们还将添加二进制目标,用于绘图目的。
#Add binary target for plotting nzd_jpy['Binary Target'] = np.nan nzd_jpy.loc[nzd_jpy['Close'] > nzd_jpy['Target'],'Binary Target'] = 1 nzd_jpy.loc[nzd_jpy['Close'] <= nzd_jpy['Target'],'Binary Target'] = 0
让我们检查一下数据。
#Current state of our dataframe
nzd_jpy 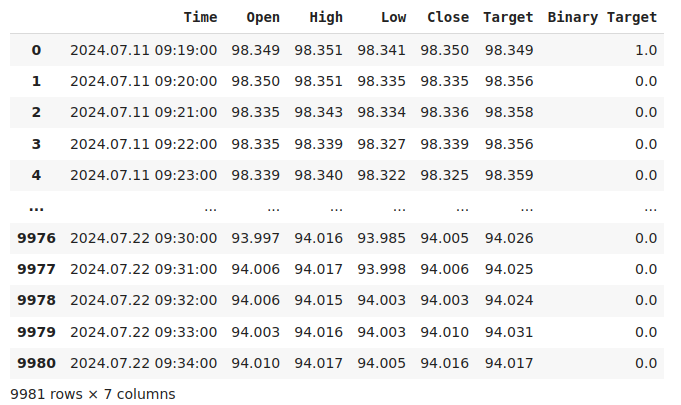
图1:我们当前的数据框架
探索性数据分析
让我们创建散点图,以确定是否可以观察到任何关系。遗憾的是,我们的数据似乎随机分布,市场上涨和下跌之间没有明显的分离。
#Lets perform scatter plots sns.scatterplot(data=nzd_jpy,x=nzd_jpy['Open'], y=nzd_jpy['Close'],hue='Binary Target')
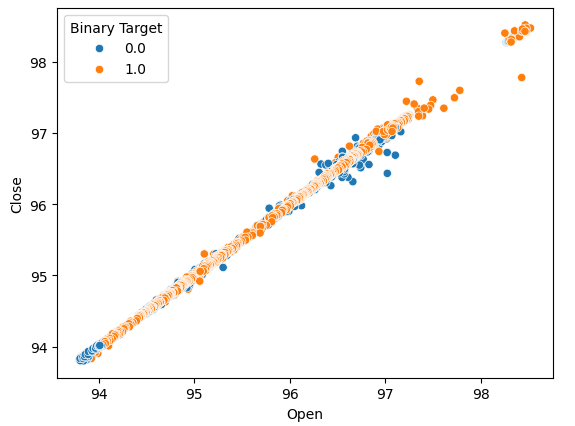
图2:开盘价和收盘价的散点图
我们曾考虑创建箱线图,以总结所有价格要么上涨要么下跌的情况。我们曾认为,对于这两种有可能的目标,在数据分布方面可能存在差异。遗憾的是,我们的箱线图显示,这两种可能的结果中数据分布几乎没有差异。
#Let's create categorical box plots sns.catplot(data=nzd_jpy,x='Binary Target',y='Close',kind='box')
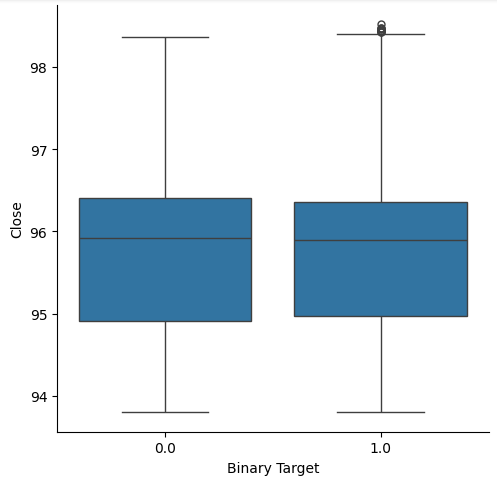
图3:总结所有价格水平下跌(0)或上涨(1)情况的箱线图
我们还可以将时间序列数据分解为3个组成部分:
- 趋势
- 季节性
- 残差
趋势部分代表价格水平的长期平均变动。季节性部分解释了在数据中反复观察到的周期性模式,而残差部分则是前两个组成部分无法解释的剩余部分。由于我们使用的是新西兰元兑日元(NZDJPY)货币对的M1数据,我们将周期设置为1440,换句话说,即一天内价格表现的平均情况。即使在进行分解之前,我们也可以观察到数据中非常清晰且强烈的下降趋势。然而,通过从原始数据中减去趋势,我们现在可以清晰地观察到数据中的季节性效应。
#Time series decomposition import statsmodels.api as sm nzd_jpy_decomposition = sm.tsa.seasonal_decompose(nzd_jpy['Close'],period=1440,model='additive') fig = nzd_jpy_decomposition.plot()
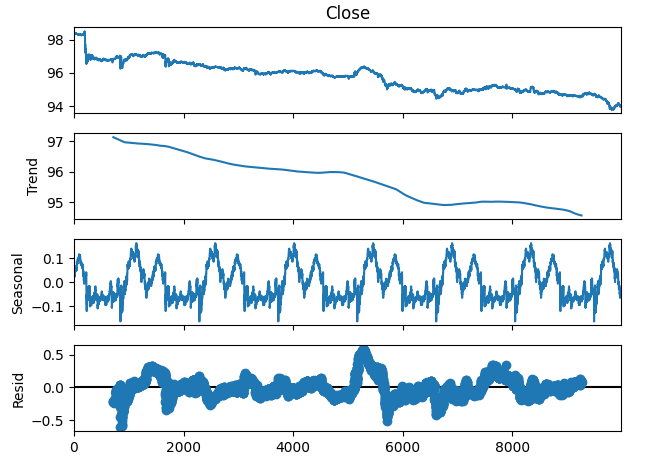
图4:数据的时间序列分解
一些效应可能隐藏在更高的维度中。创建数据的三维散点图,使我们有可能揭示二维散点图范围之外隐藏的效应。遗憾的是,这个数据集并不属于这种情况。我们的数据仍然很难分离,并且没有显示出任何可辨别的关系。
#Let's also perform 3D plots #Visualizing our data in 3D import matplotlib.pyplot as plt fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'red' for movement in nzd_jpy.loc[:,"Binary Target"]] ax.scatter(nzd_jpy.loc[:,"Low"],nzd_jpy.loc[:,"High"],nzd_jpy.loc[:,"Close"],c=colors) ax.set_xlabel('NZDJPY Low') ax.set_ylabel('NZDJPY High') ax.set_zlabel('NZDJPY Close')
图5:可视化我们的三维散点图
准备建模数据
在我们开始建模数据之前,我们首先需要对数据进行标准化和缩放。加载我们需要的库。
#Let's prepare the data for modelling from sklearn.preprocessing import RobustScaler
缩放数据。
#Scale the data X = pd.DataFrame(RobustScaler().fit_transform(nzd_jpy.loc[:,['Close']]),columns=['Close']) residuals_X = pd.DataFrame(RobustScaler().fit_transform(nzd_jpy.loc[:,['Open','High','Low']]),columns=['Open','High','Low']) y = nzd_jpy.loc[:,'Target']
模型选择
让我们加载建模数据所需的库。
#Cross validating the models from sklearn.model_selection import cross_val_score,train_test_split from sklearn.linear_model import Lasso,LinearRegression,Ridge,ElasticNet,SGDRegressor,HuberRegressor from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor,AdaBoostRegressor,ExtraTreesRegressor,BaggingRegressor from sklearn.svm import LinearSVR from sklearn.neighbors import KNeighborsRegressor from sklearn.tree import DecisionTreeRegressor from sklearn.neural_network import MLPRegressor
现在将数据分成两部分。
#Create train-test splits train_X,test_X,train_y,test_y = train_test_split(nzd_jpy.loc[:,['Close']],y,test_size=0.5,shuffle=False) residuals_train_X,residuals_test_X,residuals_train_y,residuals_test_y = train_test_split(nzd_jpy.loc[:,['Open','High','Low']],y,test_size=0.5,shuffle=False)
将模型存储于列表中,并创建一个数据帧来存储我们的验证误差水平。
#Store the models models = [ Lasso(), LinearRegression(), Ridge(), ElasticNet(), SGDRegressor(), HuberRegressor(), RandomForestRegressor(), GradientBoostingRegressor(), AdaBoostRegressor(), ExtraTreesRegressor(), BaggingRegressor(), LinearSVR(), KNeighborsRegressor(), DecisionTreeRegressor(), MLPRegressor(), ] #Store the names of the models model_names = [ 'Lasso', 'Linear Regression', 'Ridge', 'Elastic Net', 'SGD Regressor', 'Huber Regressor', 'Random Forest Regressor', 'Gradient Boosting Regressor', 'Ada Boost Regressor', 'Extra Trees Regressor', 'Bagging Regressor', 'Linear SVR', 'K Neighbors Regressor', 'Decision Tree Regressor', 'MLP Regressor', ] #Create a dataframe to store our cv error cv_error = pd.DataFrame(columns=model_names,index=np.arange(0,5))
交叉验证每个模型。
#Cross validate each model for model in models: cv_score = cross_val_score(model,X,y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): index = models.index(model) cv_error.iloc[i,index] = cv_score[i]
可视化结果。
cv_error
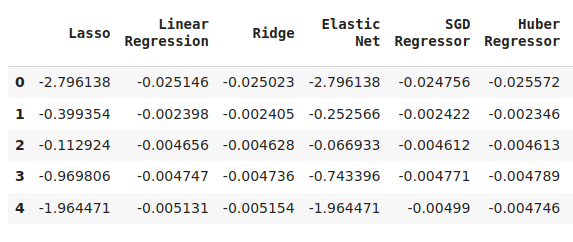
图6:预测新西兰元兑日元未来收盘价的一些误差水平
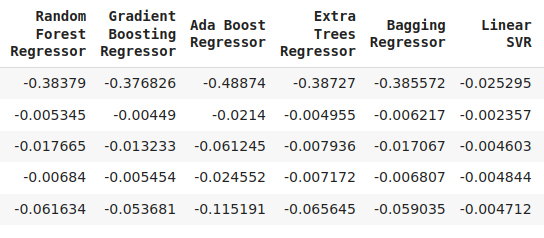
图7:我们误差水平的延续
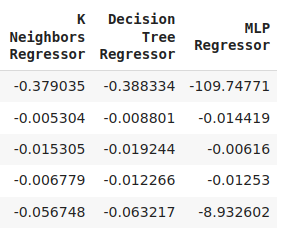
图8:我们最终模型的误差水平
我们可以绘制在所有5折的性能水平。当我们以这种格式可视化数据时,神经网络因表现不佳令人担忧。但它却有可能从参数调整中受益匪浅。
cv_error.plot()
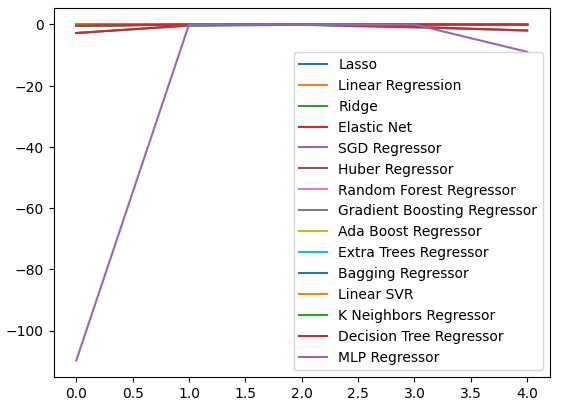
图9:可视化我们的误差水平
箱线图有助于我们在单个图表中总结大量信息。例如,在下面的图表中,我们可以清楚地看到DNN在这个任务上的表现有多差。它是右边的最后一个模型,其性能表现(波动/差异程度)相较于其他模型要大得多。
sns.boxplot(cv_error)

图10:以箱线图形式展示我们的误差
我们可以将误差均值水平最低的模型识别为性能最优的模型。
#Our mean validation error
cv_error.mean() 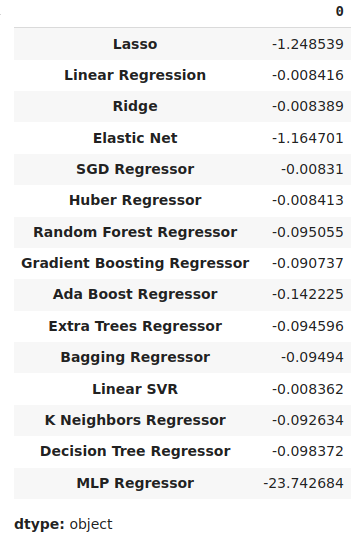
图 11:可视化我们的误差均值水平
特征的重要性
特征重要性算法有助于我们理解模型是否学习到了有意义的关联关系,或者模型是否学习到了我们之前可能并不知晓的关系。让我们开始导入需要的库。
#Feature importance
from sklearn.feature_selection import mutual_info_regression,RFE 我们将首先计算互信息(MI)得分。互信息能够告诉我们每个预测变量所具备的潜在能力,以帮助我们预测目标变量。最后,互信息是以对数尺度来衡量的。因此,在实际应用中,互信息得分高于3的情况非常罕见。
mi_score = pd.DataFrame(mutual_info_regression(X,y),columns=['MI Score'],index=X.columns)
绘制的互信息(MI)得分图能够清晰地表明,最高价似乎在预测新西兰元兑日元货币对未来收盘价方面具有最大的潜力。
mi_score.plot()
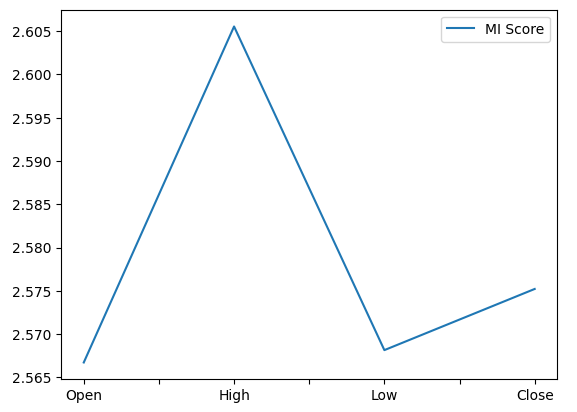
图12:绘制我们的互信息(MI)分数
递归特征消除(RFE)算法的使用几乎和scikit-learn库中的任何对象一样简单。我们只需创建该类的一个实例,并将其拟合到数据上,然后就可以评估它为每个预测变量所分配的特征重要性水平。我们的RFE算法认为所有预测变量对于预测新西兰元兑日元的收盘价同等重要。
#Select the best features rfe = RFE(model, n_features_to_select=5, step=1) rfe = rfe.fit(X, y) rfe.ranking_
参数调整
让我们现在尽可能多地从我们的SGD回归器模型中提取性能。我们将对模型参数空间内的一个样本执行随机搜索。让我们首先导入我们需要的库。
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV 创建默认模型的一个实例。
#Initialize the model
model = SGDRegressor() 创建一个调优器对象,并指定我们想要采样的可能参数值。
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"loss" : ['squared_error', 'huber', 'epsilon_insensitive','squared_epsilon_insensitive'],
"penalty":['l2','l1', 'elasticnet', None],
"alpha":[0.1,0.01,0.001,0.0001,0.00001,0.00001,0.0000001,10,100,1000,10000,100000],
"tol":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"fit_intercept": [True,False],
"early_stopping": [True,False],
"learning_rate":['constant','optimal','adaptive','invscaling'],
"shuffle": [True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) 拟合调优器对象。
#Fit the tuner
tuner.fit(train_X,train_y) 我们找到的最优参数。
#Our best parameters
tuner.best_params_ 'shuffle': False,
'penalty': 'elasticnet',
'loss': 'huber',
'learning_rate': 'adaptive',
'fit_intercept': True,
'early_stopping': True,
'alpha': 1e-05}
检测过拟合
如果我们在模型的残差中观察到相关性,就可以检测到过拟合。如果一个模型已经有效地完成学习,其残差应该是随机的白噪声,这表明我们的模型所犯的错误中没有可预测的模式。然而,如果一个模型的残差表现出自相关性,这可能是一个令人担忧的信号。它可能表明我们进行的回归是虚假的,或者我们为我们的任务选择了一个不合适的模型。要正常开启,我们需要捕获我们定制模型的残差。
#Model validation model = SGDRegressor( tol = tuner.best_params_['tol'], shuffle = tuner.best_params_['shuffle'], penalty = tuner.best_params_['penalty'], loss = tuner.best_params_['loss'], learning_rate = tuner.best_params_['learning_rate'], alpha = tuner.best_params_['alpha'], fit_intercept = tuner.best_params_['fit_intercept'], early_stopping = tuner.best_params_['early_stopping'] ) model.fit(train_X,train_y) residuals = test_y - model.predict(test_X)
我们可以在图表中可视化模型的残差。遗憾的是,我们可以清楚地看到模型的残差中存在自相关性。换句话说,每当残差下降时,它们倾向于继续下降,当残差上升时,它们倾向于继续上升。这意味着残差的未来值可能与其先前的值有关,这是一个明显的迹象,表明即使在执行参数调整之后,我们的模型可能也没有有效地学习!
#Plot the residuals
residuals.plot() 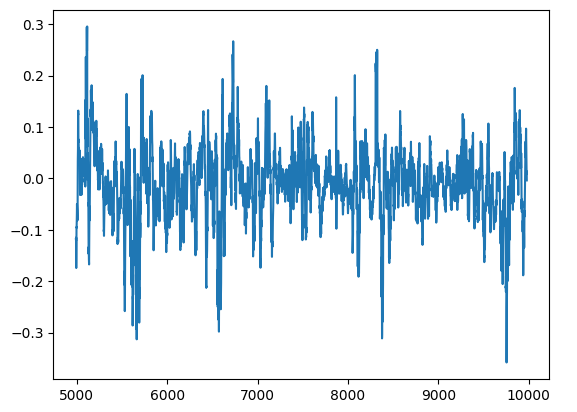
图13:我们模型的残差
还有更稳健的自相关性检验方法,例如我们可以创建一个自相关(ACF)图。ACF图将在每个可能的滞后值处有尖峰。每个尖峰的高度表示时间序列数据与其滞后值之间的相关性水平。我们的图表背景中还有一个类似蓝色锥体的结构,蓝色锥体代表我们的置信区间。任何超出置信区间的相关性水平都被认为是统计上显著的。
#The residuals appear to have autocorrelation
from statsmodels.graphics.tsaplots import plot_acf
fig = plot_acf(residuals) 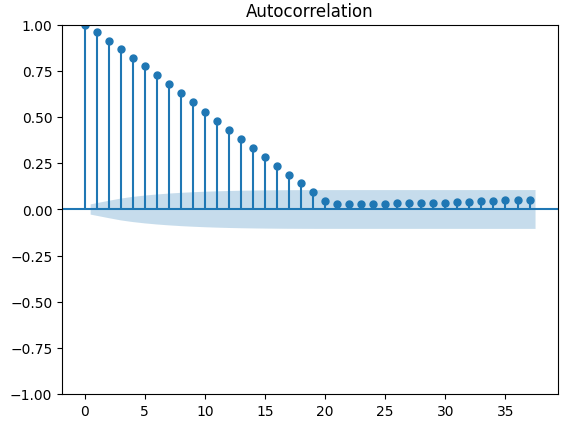
图14:我们模型残差的自相关性
这不是一个好兆头,希望我们可以通过训练DNN来纠正第一个模型,从而缓解这个问题。让我们记录在训练数据上的SGD回归器的误差,然后在测试数据上记录。请注意,我们此时不会在测试数据上拟合模型,而只会测量其误差水平。
#Prepare the residuals for our second model model = SGDRegressor(tol= 0.001, shuffle=False, penalty= 'elasticnet', loss= 'huber', learning_rate='adaptive', fit_intercept= True, early_stopping= True, alpha= 1e-05) #Store the model residuals model.fit(train_X,train_y) residuals_train_y = train_y - model.predict(train_X) residuals_test_y = test_y - model.predict(test_X)
我们现在将在预测SGD回归器的误差水平时对模型进行交叉验证。
#Cross validate each model for model in models: cv_score = cross_val_score(model,residuals_train_X,residuals_train_y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): index = models.index(model) cv_error.iloc[i,index] = cv_score[i]
让我们可视化验证误差。
#Cross validaton error levels
cv_error 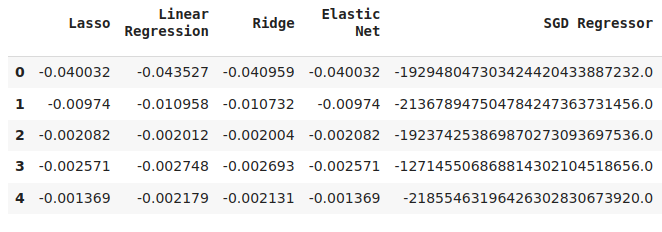
图15:预测我们第一个模型时的一些模型验证误差水平
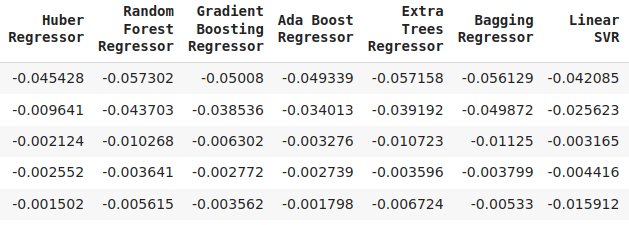
图16:我们验证误差水平的延续
我们可以按降序查看平均误差水平,以快速识别表现最优的模型。
#Store the model's performance cv_error.mean().sort_values(ascending=False)
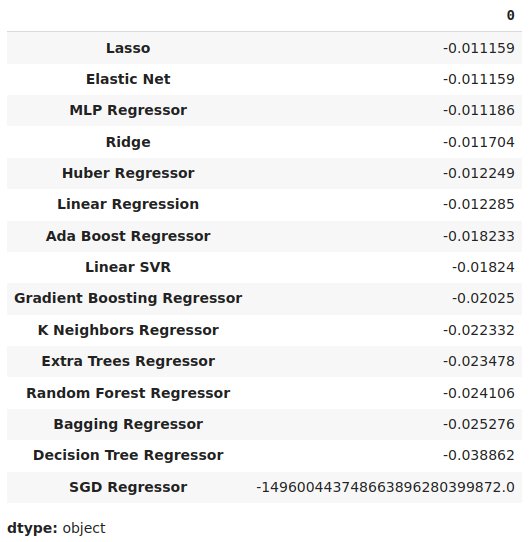
图17:我们的平均验证误差水平清楚地显示Lasso是我们表现最优的模型
我们的箱线图显示了SGD回归器在尝试预测其自身误差水平时表现有多差。
sns.boxplot(cv_error)
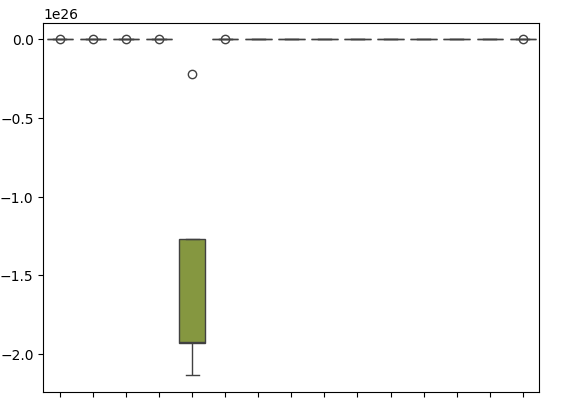
图18:预测我们模型残差时的验证误差箱线图
我们还可以通过创建折线图来可视化数据。
cv_error.plot()
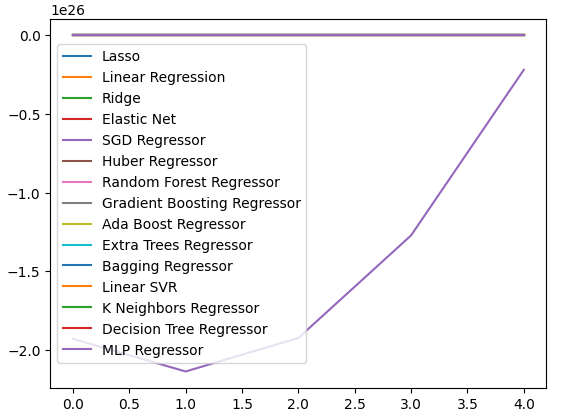
图19:使用折线图可视化我们的误差水平
调整深度神经网络(DNN)的参数
让我们现在准备调整DNN回归器的参数,首先我们将定义调优器对象和想要搜索的参数空间的样本。
#Let's tune the model
#Reinitialize the model
model = MLPRegressor()
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"activation":["relu","tanh","logistic","identity"],
"solver":["adam","sgd","lbfgs"],
"alpha":[0.1,0.01,0.001,0.00001,0.000001],
"learning_rate": ["constant","invscaling","adaptive"],
"learning_rate_init":[0.1,0.01,0.001,0.0001,0.000001,0.0000001],
"power_t":[0.1,0.5,0.9,0.01,0.001,0.0001],
"shuffle":[True,False],
"tol":[0.1,0.01,0.001,0.0001,0.00001],
"hidden_layer_sizes":[(10,20),(100,200),(30,200,40),(5,20,6)],
"max_iter":[10,50,100,200,300],
"early_stopping":[True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) 现在我们将拟合调优器对象。
#Fit the tuner
tuner.fit(residuals_train_X,residuals_train_y) 最后我们可以看到已获得的最优参数。
#The best parameters we found
tuner.best_params_ 'solver': 'lbfgs',
'shuffle': False,
'power_t': 0.5,
'max_iter': 300,
'learning_rate_init': 0.01,
'learning_rate': 'constant',
'hidden_layer_sizes': (30, 200, 40),
'early_stopping': False,
'alpha': 1e-05,
'activation': 'identity'}
更深入的参数调整
让我们现在测试看看是否还能找到更好的参数。由于未必知道最优输入值可能在哪里,我们将尝试使用SciPy库中的有限内存L-BFGS-B算法进行无约束全局优化。L-BFGS-B算法可以有效地用于全局优化问题。数值求解器本身是用Fortran代码实现的,而SciPy库提供了一个薄包装,以便轻松与该例程接口。我们将从导入所需的库开始。

图20:原始BFGS算法的开发者,从左到右分别是:Broyden、Fletcher、Goldfarb和Shanno
#Deeper optimization
from scipy.optimize import minimize 现在我们将定义要最小化的目标函数,希望最小化我们DNN回归器的训练误差。我们将固定模型的所有其他输入参数,因为我们的SciPy最小化器只能处理连续优化问题。
#Define the objective function def objective(x): #Create a dataframe to store our accuracy cv_error = pd.DataFrame(index = np.arange(0,5),columns=["Current Error"]) #The parameter x represents a new value for our neural network's settings #In order to find optimal settings, we will perform 10 fold cross validation using the new setting #And return the average RMSE from all 10 tests #We will first turn the model's Alpha parameter, which controls the amount of L2 regularization MLPRegressor(hidden_layer_sizes=(20,5),activation='identity',learning_rate='adaptive',solver='lbfgs',shuffle=True,alpha=x[0],tol=x[1]) model = MLPRegressor( tol = x[0], solver = tuner.best_params_['solver'], power_t = x[1], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = x[2], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = x[3], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], ) #Cross validate the model cv_score = cross_val_score(model,residuals_train_X,residuals_train_y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): cv_error.iloc[i,0] = cv_score[i] #Return the Mean CV RMSE return(cv_error.iloc[:,0].mean())
我们将通过随机搜索找到的最优参数来定义优化过程的起始点。我们还将为优化过程传递约束条件,我们将强制所有值为正,并且允许所有值在10的-100次方到10的100次方的范围内。这是一个非常大的范围,希望它能包含我们正在寻找的最优参数。
#Define the starting point pt = [tuner.best_params_['tol'],tuner.best_params_['power_t'],tuner.best_params_['learning_rate_init'],tuner.best_params_['alpha']] bnds = ((10.0 ** -100,10.0 ** 100), (10.0 ** -100,10.0 ** 100), (10.0 ** -100,10.0 ** 100), (10.0 ** -100,10.0 ** 100))
寻找最优参数。
#Searching deeper for better parameters result = minimize(objective,pt,method="L-BFGS-B",bounds=bnds)
我们的优化结果。
结果
success: True
status: 0
fun: -0.01143352283130129
x: [ 1.000e-04 5.000e-01 1.000e-02 1.000e-05]
nit: 2
jac: [-1.388e+04 -4.657e+04 5.625e+04 -1.033e+04]
nfev: 120
njev: 24
hess_inv: <4x4 LbfgsInvHessProduct with dtype=float64>
检测过拟合
现在让我们测试是否存在过拟合。这一次,我们将比较我们的两个模型与默认DNN回归器的性能。让我们为每个我们想要测试的DNN回归器创建实例。
#Model validation default_model = MLPRegressor() customized_model = MLPRegressor( tol = tuner.best_params_['tol'], solver = tuner.best_params_['solver'], power_t = tuner.best_params_['power_t'], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = tuner.best_params_['learning_rate_init'], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = tuner.best_params_['alpha'], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], ) lbfgs_customized_model = MLPRegressor( tol = result.x[0], solver = tuner.best_params_['solver'], power_t = result.x[1], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = result.x[2], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = result.x[3], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], )
现在我们将创建一个模型列表,并创建一个数据帧来存储验证误差水平。
models = [default_model,customized_model,lbfgs_customized_model] cv_error = pd.DataFrame(index=np.arange(0,5),columns=['Default NN','Random Search NN','L-BFGS-B NN'])
交叉验证每个模型。
#Cross validate the model for model in models: model.fit(residuals_train_X,residuals_train_y) cv_score = cross_val_score(model,residuals_test_X,residuals_test_y,cv=5,n_jobs=-1,scoring='neg_mean_squared_error') for i in np.arange(0,5): index = models.index(model) cv_error.iloc[i,index] = cv_score[i]
我们的交叉验证误差。
cv_error
| 默认NN | 随机搜索NN | L-BFGS-B NN |
|---|---|---|
| -0.007735 | -0.007708 | -0.007692 |
| -0.00635 | -0.006344 | -0.006329 |
| -0.003307 | -0.003265 | -0.00328 |
| 0.005225 | -0.004803 | -0.004761 |
| -0.004469 | -0.004447 | -0.004492 |
现在让我们分析一下平均误差水平。
cv_error.mean().sort_values(ascending=False)
| 模型 | 验证误差 |
|---|---|
| L-BFGS-B NN | -0.005311 |
| 随机搜索NN | -0.005313 |
| 默认NN | -0.005417 |
正如我们所见,我们所有模型的性能都在同一范围内。然而,我们定制的模型平均误差水平明显更低。遗憾的是,我们模型所展示的方差几乎在所有情况下都相同,这一点可以从箱线图中看出。方差水平有助于我们确定模型的技能水平。
sns.boxplot(cv_error)
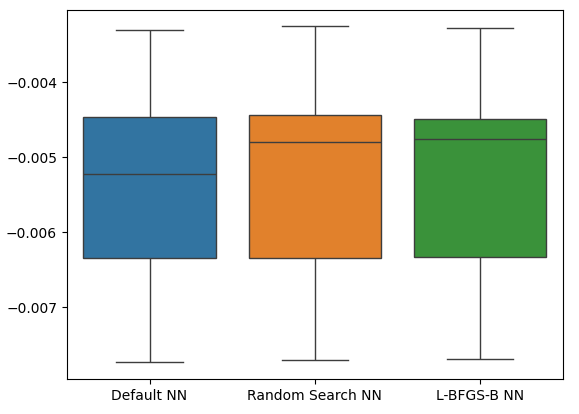
图21:我们基于保留数据的验证误差水平
让我们现在看一下集成方法是否比仅使用单个模型来预测价格水平更好。我们将首先准备所需的模型。
#Now that we have come this far, let's see if our ensemble approach is worth the trouble baseline = LinearRegression() default_nn = MLPRegressor() #The SGD Regressor will predict the future price sgd_regressor = SGDRegressor(tol= 0.001, shuffle=False, penalty= 'elasticnet', loss= 'huber', learning_rate='adaptive', fit_intercept= True, early_stopping= True, alpha= 1e-05) #The deep neural network will predict the error in the SGDRegressor's prediction lbfgs_customized_model = MLPRegressor( tol = result.x[0], solver = tuner.best_params_['solver'], power_t = result.x[1], max_iter = tuner.best_params_['max_iter'], learning_rate = tuner.best_params_['learning_rate'], learning_rate_init = result.x[2], hidden_layer_sizes = tuner.best_params_['hidden_layer_sizes'], alpha = result.x[3], early_stopping = tuner.best_params_['early_stopping'], activation = tuner.best_params_['activation'], )
在训练集上拟合模型。
#Fit the models on the train set baseline.fit(train_X.loc[:,['Close']],train_y) default_nn.fit(train_X.loc[:,['Close']],train_y) sgd_regressor.fit(train_X.loc[:,['Close']],train_y) lbfgs_customized_model.fit(residuals_train_X.loc[:,['Open','High','Low']],residuals_train_y)
将模型存储在列表中。
#Store the models in a list
models = [baseline,default_nn,sgd_regressor,lbfgs_customized_model] 创建数据帧来存储我们的误差水平。
#Create a dataframe to store our error ensemble_error = pd.DataFrame(index=np.arange(0,5),columns=['Baseline','Default NN','SGD','Customized NN'])
导入我们需要的库。
from sklearn.model_selection import TimeSeriesSplit from sklearn.metrics import mean_squared_error
创建时间序列拆分对象。
#Create the time-series object tscv = TimeSeriesSplit(n_splits=5,gap=20)
我们需要重置数据索引。
#Reset the indexes so we can perform cross validation
test_y = test_y.reset_index()
residuals_test_y = residuals_test_y.reset_index()
test_X = test_X.reset_index()
residuals_test_X = residuals_test_X.reset_index() 现在我们将执行时间序列交叉验证。请注意,预测残差的模型需要单独训练,而其他只是预测未来收盘价的模型则不需要。
#Cross validate the models for j in np.arange(0,4): model = models[j] for i,(train,test) in enumerate(tscv.split(test_X)): #The model predicting the residuals if(j == 3): model.fit(residuals_test_X.loc[train[0]:train[-1],['Open','High','Low']],residuals_test_y.loc[train[0]:train[-1],'Target']) #Measure the loss ensemble_error.iloc[i,j] = mean_squared_error(residuals_test_y.loc[test[0]:test[-1],'Target' ], model.predict(residuals_test_X.loc[test[0]:test[-1],['Open','High','Low']])) elif(j <= 2): #Fit the model model.fit(test_X.loc[train[0]:train[-1],['Close']],test_y.loc[train[0]:train[-1],'Target']) #Measure the loss ensemble_error.iloc[i,j] = mean_squared_error(test_y.loc[test[0]:test[-1],'Target' ],model.predict(test_X.loc[test[0]:test[-1],['Close']]))
现在让我们分析验证误差水平。遗憾的是,我们未能超越简单线性回归模型的性能,这表明我们的模型可能对数据的方差过于敏感。但好消息是,我们超越了默认的DNN回归器。
ensemble_error.mean().sort_values(ascending=True)
| 模型 | 验证误差 |
|---|---|
| 基线 | 0.004784 |
| 定制L-BFGS-B NN | 0.004891 |
| SGD | 0.005937 |
| 默认NN | 35.35851 |
导出为ONNX格式
开放式神经网络交换(ONNX)是一个开源协议,用于以语言无关的方式构建和部署机器学习模型。ONNX使我们能够轻松地将scikit-learn集成模型到EA中,依靠MQL5 API对ONNX的支持。首先,我们导入所需的库。 #Prepare to export to ONNX import onnx import netron from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
现在让我们基于所有可用的数据拟合模型。
#Fit the SGD model on all the data we have close_model = SGDRegressor(tol= 0.001, shuffle=False, penalty= 'elasticnet', loss= 'huber', learning_rate='adaptive', fit_intercept= True, early_stopping= True, alpha= 1e-05) close_model.fit(nzd_jpy.loc[:,['Close']],nzd_jpy.loc[:,'Target'])
最后我们将拟合DNN回归器。
#Fit the deep neural network on all the data we have residuals_model = MLPRegressor( tol=0.0001, solver= 'lbfgs', shuffle=False, power_t= 0.5, max_iter= 300, learning_rate_init= 0.01, learning_rate='constant', hidden_layer_sizes=(30, 200, 40), early_stopping=False, alpha=1e-05, activation='identity') #Fit the model on the residuals residuals_model.fit(residuals_train_X,residuals_train_y) residuals_model.fit(residuals_test_X,residuals_test_y)
让我们定义两个模型的输入格式。
# Define the input type close_initial_types = [("float_input",FloatTensorType([1,1]))] residuals_initial_types = [("float_input",FloatTensorType([1,3]))]
我们需要创建模型的ONNX表示。
# Create the ONNX representation close_onnx_model = convert_sklearn(close_model,initial_types=close_initial_types,target_opset=12) residuals_onnx_model = convert_sklearn(residuals_model,initial_types=residuals_initial_types,target_opset=12)
最后,我们需要将模型存储为ONNX格式。
#Save the ONNX Models onnx.save_model(close_onnx_model,'close_model.onnx') onnx.save_model(residuals_onnx_model,'residuals_model.onnx')
可视化我们的ONNX模型
让我们也可视化模型,以确保它们具有指定的输入和输出形状。我们将从可视化DNN回归器开始。首先,我们导入所需的库。
#Import netron
import netron 现在我们将可视化DNN。
#Visualizing the residuals model netron.start("/ENTER/YOUR/PATH/residuals_model.onnx")
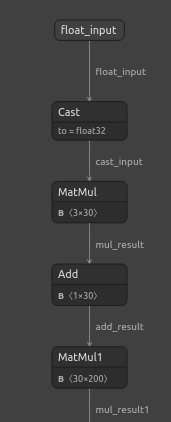
图22:可视化我们的DNN回归器模型
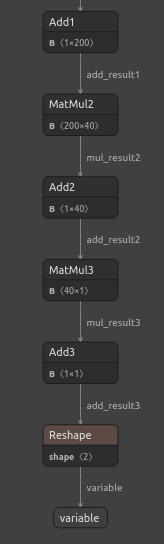
图23:可视化我们的DNN回归器模型
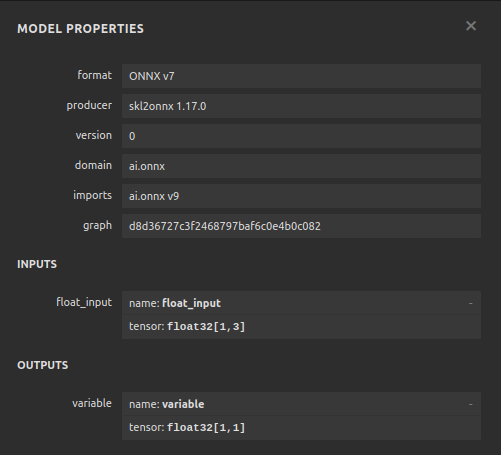
图24:我们的DNN回归器的输入和输出形状符合预期
让我们同样可视化SGD回归器模型。
#Visualizing the close model netron.start("/ENTER/YOUR/PATH/close_model.onnx")

图25:可视化我们的SGD回归器模型

图25:可视化我们的SGD回归器模型
在MQL5中实现
要开始构建AI驱动的EA,我们首先需要将刚刚创建的ONNX文件加载到应用程序中。
//+------------------------------------------------------------------+ //| NZD JPY AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the ONNX models | //+------------------------------------------------------------------+ #resource "\\Files\\residuals_model.onnx" as const uchar residuals_onnx_buffer[]; #resource "\\Files\\close_model.onnx" as const uchar close_onnx_buffer[];
现在,我们需要交易库来帮助我们开仓和平仓。
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
我们还需要创建一些全局变量,这些变量将用于整个程序中。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long residuals_model,close_model; vectorf residuals_forecast = vectorf::Zeros(1); vectorf close_forecast = vectorf::Zeros(1); float forecast = 0; int model_state,system_state; int counter = 0; double bid,ask;
在我们模型的初始化过程中,我们将首先加载我们的两个ONNX模型,然后验证模型是否能够正常工作。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX models if(!load_onnx_models()) { return(INIT_FAILED); } //--- Validate the model is working model_predict(); if(forecast == 0) { Comment("The ONNX models are not working correctly!"); return(INIT_FAILED); } //--- We managed to load our ONNX models return(INIT_SUCCEEDED); }
每当我们的模型从图表中移除时,我们将释放所有不再使用的资源。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we no longer need release_resorces(); }
如果我们接收到了任何新价格,我们首先会更新市场价格。随后,我们将从模型中获取一个预测。一旦有了预测,我们会检查是否有任何持仓。如果没有持仓,只要更高时间框架上的价格变化允许,我们就将遵循模型的预测,否则,如果我们已经有一个持仓,我们将首先等待20根K线图结束,然后才会去检查模型是否预测了反转。回想一下,我们训练模型是为了预测未来20步,因此应该允许一些时间流逝,然后再去检查是否出现反转。
//--- If we have no positions, follow the model's forecast if(PositionsTotal() == 0) { //--- Our model is suggesting we should buy if(model_state == 1) { if(iClose(Symbol(),PERIOD_W1,0) > iClose(Symbol(),PERIOD_W1,12)) { Trade.Buy(0.3,Symbol(),ask,0,0,"NZD JPY AI"); system_state = 1; } } //--- Our model is suggesting we should sell if(model_state == -1) { if(iClose(Symbol(),PERIOD_W1,0) < iClose(Symbol(),PERIOD_W1,12)) { Trade.Sell(0.3,Symbol(),bid,0,0,"NZD JPY AI"); system_state = -1; } } } else { //--- We want to wait 20 mins before forecating again. if(time_stamp != time) { time_stamp= time; counter += 1; } if((system_state!= model_state) && (counter >= 20)) { Alert("Reversal detected by our AI system, closing all positions"); Trade.PositionClose(Symbol()); counter = 0; } } }
让我们定义一个从模型中获取预测的函数,回想一下,我们有两个独立的模型,每个模型都需要依次调用。
//+------------------------------------------------------------------+ //| Fetch a prediction from our models | //+------------------------------------------------------------------+ void model_predict(void) { //--- Define the inputs vectorf close_inputs = vectorf::Zeros(1); vectorf residuals_inputs = vectorf::Zeros(3); close_inputs[0] = (float) iClose(Symbol(),PERIOD_M1,0); residuals_inputs[0] = (float) iOpen(Symbol(),PERIOD_M1,0); residuals_inputs[1] = (float) iHigh(Symbol(),PERIOD_M1,0); residuals_inputs[2] = (float) iLow(Symbol(),PERIOD_M1,0); //--- Fetch predictions OnnxRun(residuals_model,ONNX_DEFAULT,residuals_inputs,residuals_forecast); OnnxRun(close_model,ONNX_DEFAULT,close_inputs,close_forecast); //--- Our forecast forecast = residuals_forecast[0] + close_forecast[0]; Comment("Model forecast: ",forecast); //--- Remember the model's prediction if(forecast > close_inputs[0]) { model_state = 1; } else { model_state = -1; } }
我们还需要一个函数来更新市场价格。
//+------------------------------------------------------------------+ //| Update the market data we have | //+------------------------------------------------------------------+ void update_market_data(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); }
该函数将释放我们不再使用的资源。
//+------------------------------------------------------------------+ //| Rlease the resources we no longer need | //+------------------------------------------------------------------+ void release_resorces(void) { OnnxRelease(residuals_model); OnnxRelease(close_model); ExpertRemove(); }
最后,该函数将从我们在应用程序开始时创建的ONNX缓冲区中准备ONNX模型。
//+------------------------------------------------------------------+ //| This function will load our ONNX models | //+------------------------------------------------------------------+ bool load_onnx_models(void) { //--- Load the ONNX models from the buffers we created residuals_model = OnnxCreateFromBuffer(residuals_onnx_buffer,ONNX_DEFAULT); close_model = OnnxCreateFromBuffer(close_onnx_buffer,ONNX_DEFAULT); //--- Validate the models if((residuals_model == INVALID_HANDLE) || (close_model == INVALID_HANDLE)) { //--- We failed to load the models Comment("Failed to create the ONNX models: ",GetLastError()); return(false); } //--- Set the I/O shapes of the models ulong residuals_inputs[] = {1,3}; ulong close_inputs[] = {1,1}; ulong model_output[] = {1,1}; //---- Validate the I/O shapes if((!OnnxSetInputShape(residuals_model,0,residuals_inputs)) || (!OnnxSetInputShape(close_model,0,close_inputs))) { //--- We failed to set the input shapes Comment("Failed to set model input shapes: ",GetLastError()); return(false); } if((!OnnxSetOutputShape(residuals_model,0,model_output)) || (!OnnxSetOutputShape(close_model,0,model_output))) { //--- We failed to set the output shapes Comment("Failed to set model output shapes: ",GetLastError()); return(false); } //--- Everything went fine return(true); } //+------------------------------------------------------------------+
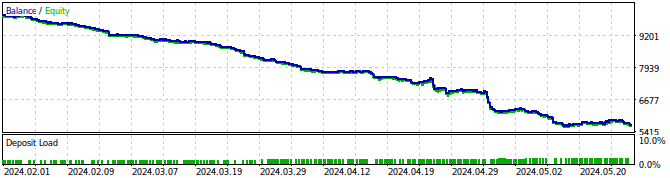
图27:回测我们的EA
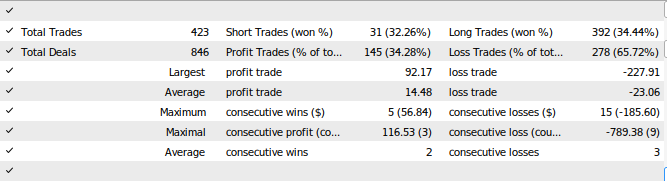
图28:我们的EA测试结果
结论
在本文中,我们展示了如何构建能够自我纠正的交易应用程序。我们的讨论重点在于如何分析模型的残差,以检测机器学习模型中的过拟合和偏差。遗憾的是,我们发现表现最优的模型的残差表现异常。我们可以通过对时间序列数据和目标变量进行差分,直到残差中不再观察到自相关性,来尝试解决这个问题,但这也会使我们的模型更难解释。虽然我们不能保证本文提出的观点能够带来持续的成功,但如果你热衷于将AI应用于交易策略,那么这些观点绝对值得借鉴。请加入我们下一次的探讨,我们将尝试解决今天观察到的缺陷,同时平衡模型的可解释性。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/15886
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

好文章。
非常感谢你,Kikkih,这对我意义重大。