
在任何市场中获得优势(第四部分):CBOE欧元和黄金波动率指数

在大数据时代,有数亿个数据集,每个数据集都可能在预测金融市场时提供尚未获知的准确性。不幸的是,并非所有现有的数据集都能达到这种潜力。在本系列文章中,我们的目标是帮助您穿越可能的数据集的广阔领域,在讨论结束时,您将能够很好地判断是否应在交易策略中包含建议的替代数据,或者还是不包含为好。
交易策略概览
我们将分析XAUEUR市场。该货币对跟踪以欧元计价的黄金价格。除了南极洲外,地球上每个大陆都开采黄金。全球相当一部分黄金由伦敦金银市场协会(LBMA)交易,以设定全球公认的黄金价格基准。芝加哥期权交易所(CBOE)是一家美国公司,提供全球市场基础设施。CBOE利用其网络创建跟踪全球主要市场的波动率指数。我们将分析CBOE的两个波动率指数,它们分别跟踪欧元和黄金市场。
多年来,交易者已经实现了各种策略,以成功交易波动性市场,同时最小化风险。一般来说,当市场波动时,交易者有可能在相对较短的时间内实现利润目标。另一方面,由于价格水平的大缺口可能无法及时触发止损订单,也有可能迅速损失大量资本。
粗略地说,一些交易者更倾向于开设较少的头寸,或者比他们通常愿意在更多头寸上冒险的资本要少,以期从有利的价格走势中获利,同时最小化市场风险暴露。一般来说,经验丰富的交易者在波动性市场中往往会比在平静市场中更快地获利了结。其他交易者则等待价格水平首先被限制在支撑和阻力水平之间的区间内。当价格水平最终突破区间时,交易者可能会开设头寸,预期价格会从可识别的区间中出现更强烈的走势。
在正常市场条件下,从支撑和阻力区域的突破可能会迅速失去动力并开始漂移。然而,当市场条件波动时,突破可能会伴随着同一方向的剧烈价格变化,为遵循上述策略的交易者提供高于平均水平的回报。遗憾的是,这些策略容易出现虚假突破,可能会剧烈反转,使一些交易者处于不利地位,持有重大损失。
方法论概述
我们使用了由圣路易斯联邦储备银行维护的联邦储备经济数据库(FRED)Python API来获取CBOE欧元和黄金波动率经济时间序列数据。这些数据以每日格式提供,并且包含缺失值。
不幸的是,随数据集提供的描述中没有任何内容解释这些缺失值。因此,我们对这两个数据集中的所有缺失值进行了均值填充。
在我们的MetaTrader 5终端中,我们使用我们用MQL5编写的自定义脚本,获取了XAUEUR货币对大约4000行的每日市场报价,包括开盘价、最高价、最低价和收盘价(OHLC)。
当我们分析CBOE替代数据与MetaTrader 5市场数据之间的相关性时,我们发现相关性水平并没有显著偏离0。值得注意的是,两个替代数据集之间的相关性水平为0.4。正相关水平可能表明存在相互作用或共同的市场参与者影响着这两个市场。
当我们使用任一替代数据集作为x轴,XAUEUR的收盘价作为y轴绘制散点图时,似乎存在一个高波动率水平的阈值,该阈值始终导致价格水平上升。遗憾的是,我们的小数据集,在与替代数据集合并后总共大约3000行,可能是一个很好的理由,让我们谨慎对待数据中可能并不存在的模式。
有效地查看高维数据可能具有挑战性。因此,我们采用了两步程序来查看我们的数据。最初,我们使用两个CBOE数据集分别作为x轴和y轴,XAUEUR收盘价作为z轴,创建了3D散点图。我们在2D散点图中观察到的上涨K线簇仍然清晰可见。
最后,我们总是可以利用旨在将高维数据映射到低维子空间的算法。一个著名的降维算法是主成分分析。我们选择使用scikit-learn实现的t分布随机邻域嵌入(t-SNE),为我们6维数据集创建一个2维表示。结果图表明我们的数据集中可能存在4个不同的聚类。此外,我们观察到看似我们数据集中存在序列依赖效应,表明CBOE和MetaTrader 5数据集之间可能存在正在发展的关系。
我们使用的最后一种可视化技术是自相关图。我们创建的所有自相关图都显示出强烈的拖尾现象,这可能表明我们的序列中存在长期数据持续性。这可能是由强烈的趋势或季节性效应造成的。我们的部分自相关图表明,只有少数几个滞后项解释了我们观察到的大部分自相关。这表明时间序列数据可能可以成功地建模为移动平均模型。
在可视化我们的数据后,我们创建了3组预测因子:
- MetaTrader 5市场数据的OHLC
- FRED CBOE替代数据集
- 上述两组的数据集合
我们使用三个相同的深度神经网络,通过5折时间序列交叉验证(不随机打乱)来比较这3组预测因子。最后一组预测因子在预测XAUEUR货币对未来收盘价时产生了最低的误差率。这可能表明这两个数据集之间存在关系,有助于我们的模型。
在第一次测试的结果让我们充满信心后,我们尝试评估深度神经网络的全局特征重要性。我们选择了累积局部效应(ALE)和SHAP值加性解释(SHAP)方法,以了解我们的模型最依赖哪些模型。我们使用的方法都没有拒绝所选择的替代数据集。
我们在训练集上对模型的超参数进行了调整,这是一个创建了两个模型的两步过程。最初,我们对模型参数的选择进行了500次随机搜索迭代。在第二步中,我们使用有限记忆Broyden-Fletcher-Goldfarb-Shanno(L-BFGS-B)算法,对随机搜索中模型的连续参数的最佳值进行了优化。所有剩余的非连续模型参数在第二阶段保持固定。
这两个定制模型在验证数据上的表现都优于默认的神经网络。然而,在测试集上表现最好的是通过随机搜索得到的模型。这表明我们可能已经成功地优化了我们的模型,使其适应训练数据,而没有过度拟合我们的参数。
从那里开始,我们准备将我们最好的模型导出为ONNX格式,以便集成到一个定制的MetaTrader 5程序中,最后,编写了一个Python脚本,通过共享CSV文件将最新的FRED数据共享到我们的终端。
获取数据
我附上了一个用MQL5编写的实用脚本,用于获取市场数据,并将其以CSV格式输出。该脚本有一个输入参数,用于指定要获取的数据条数。只需将脚本拖放到您的图表上,您就可以开始跟随操作了。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
准备数据
在获取我们的MetaTrader 5的OHLC市场数据后,我们开始对数据进行清理和格式化的过程。我们的第一步是导入用于机器学习的标准Python库。#Import the libraries we need import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import statsmodels from statsmodels.graphics.tsaplots import plot_acf,plot_pacf from fredapi import Fred from datetime import datetime import time
这些是我们所使用的库的版本信息。
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}") print(f"Seaborn version {sns.__version__}") print(f"Statsmodels version {statsmodels.__version__}")
Numpy 版本:1.26.4
Seaborn 版本:0.13.1
Statsmodels 版本: 0.14
现在,我们可以读取我们刚刚创建的CSV文件,并将时间列设置为我们的索引。这样做将使我们能够以时间顺序合并MetaTrader 5和CBOE的数据。
#Read in the data xau_eur = pd.read_csv("Market Data XAUEUR.csv") xau_eur = xau_eur.loc[96911:,:] xau_eur.set_index("Time",inplace=True) xau_eur.index = pd.to_datetime(xau_eur.index)
让我们现在从FRED获取替代的CBOE市场数据。请注意,在您能够继续之前,您必须首先在FRED网站上创建一个免费账户,以便您能够获得一个私人API密钥。完成这个过程很容易,没有任何隐藏费用。
#Fetch FRED data
fred = Fred(api_key='ENTER YOUR API KEY HERE')
fred_euro_data = pd.DataFrame(fred.get_series('EVZCLS'),columns=["EVZCLS"])
fred_gold_data = pd.DataFrame(fred.get_series('GVZCLS'),columns=["GVZCLS"])
#Fill in any missing values with the column mean
fred_euro_data = fred_euro_data.fillna(fred_euro_data.mean())
fred_gold_data = fred_gold_data.fillna(fred_gold_data.mean()) Pandas有类似于SQL的命令用于合并数据框。我们只在两个时间序列共有的日期上合并了数据。
#Merge the data
merged_data = pd.merge(xau_eur,fred_euro_data,left_index=True,right_index=True)
merged_data = pd.merge(merged_data,fred_gold_data,left_index=True,right_index=True)
merged_data 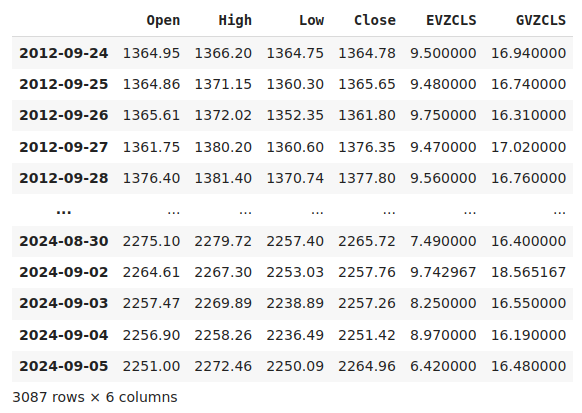
图1:我们合并后的数据集
在任何监督式机器学习项目中,标记数据都是一个重要的步骤。首先,我们定义了我们的预测范围,在这个案例中是未来20天。然后,我们将目标定义为XAUEUR货币对的未来收盘价。我们还创建了二进制目标来总结价格水平是升值还是贬值。二进制目标将仅用于可视化目的。
#Let us label the data look_ahead = 20 #Define the labels merged_data["Target"] = merged_data["Close"].shift(-look_ahead) merged_data["Binary Target"] = np.nan merged_data.loc[merged_data["Target"] > merged_data["Close"],"Binary Target"] = 1 merged_data.loc[merged_data["Target"] <= merged_data["Close"],"Binary Target"] = 0 merged_data.dropna(inplace=True) merged_data
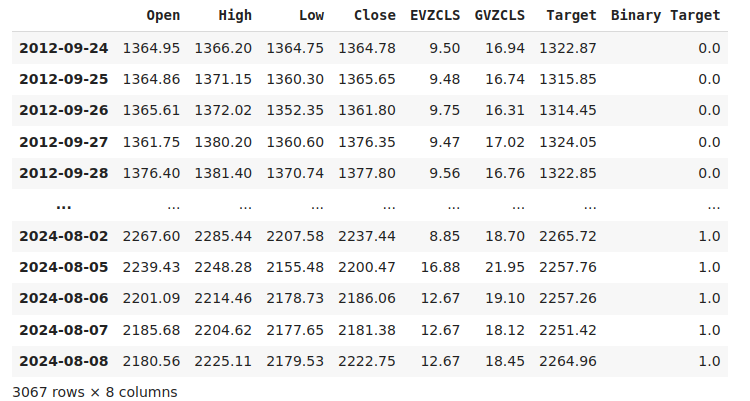
图2:包含目标的数据集
最后,我们定义了将要进行实证比较的3组预测因子。
#Let us define the predictors and target ohlc_predictors = ["Open","High","Low","Close"] fred_predictors = ["EVZCLS","GVZCLS"] predictors = ohlc_predictors + fred_predictors target = "Target" binary_target = "Binary Target"
探索性数据分析
强相关性的存在或缺失并不一定意味着所分析数据之间关系的存在或缺失。我们的替代数据似乎与XAUEUR数据集存在间歇性相关性。然而,在两个替代数据集之间似乎存在较强的相关性。
#Exploratory Data Analysis #Analyzing correlation levels sns.heatmap(merged_data[predictors].corr(),annot=True)
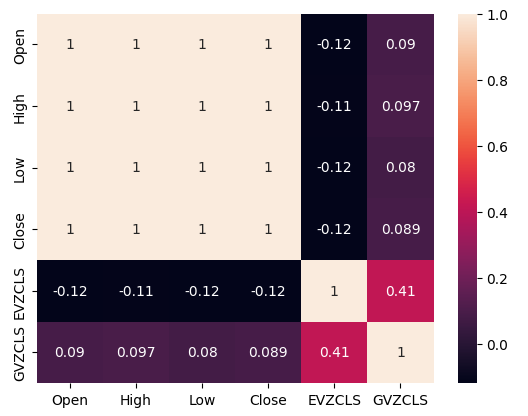
图3:我们的相关性热力图
我们创建了3个散点图。前两个散点图使用黄金和欧元波动率指数作为x轴,两个图的y轴均为XAUEUR的收盘价。在我们的第一个散点图中,当黄金波动率水平超过30-35时,我们一致观察到看涨的价格走势。
#Let's create scatter plots sns.scatterplot(data=merged_data,x="GVZCLS",y="Close",hue="Binary Target")
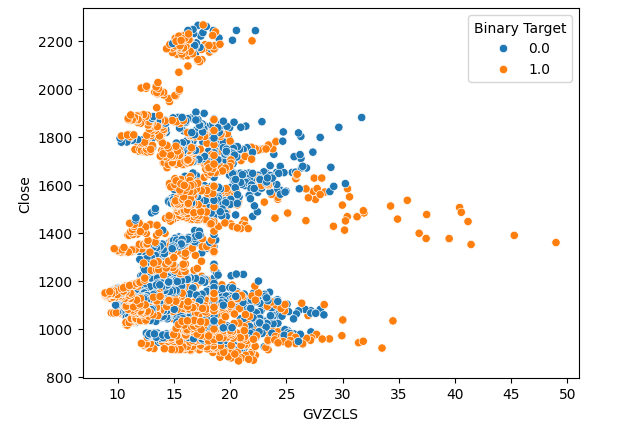
图4:我们的第一个散点图
在第二个散点图中也观察到了同样的现象。当欧元波动率水平超过14-16时,价格水平一致上升。然而,我们的数据集是有限的,可能无法完全代表两个市场之间的真正关系。
#Let's create scatter plots sns.scatterplot(data=merged_data,x="EVZCLS",y="Close",hue="Binary Target")
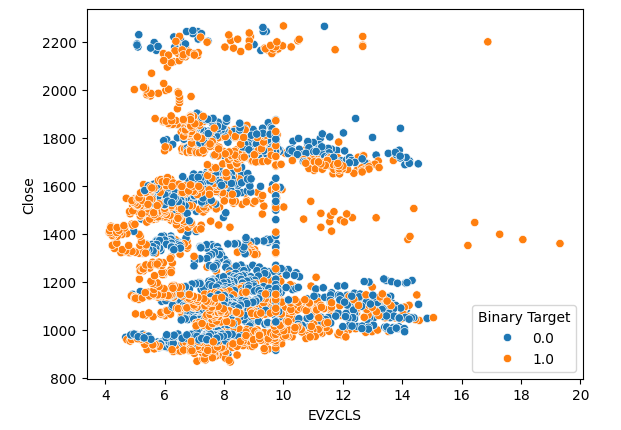
图5:我们的第二个散点图
最后,我们使用两个替代数据集在两个轴上创建了一个散点图。我们的数据形成了一个类似圆锥的结构,看涨K线的集合仍然清晰可见且分离良好。
#Let's create scatter plots sns.scatterplot(data=merged_data,x="GVZCLS",y="EVZCLS",hue="Binary Target")
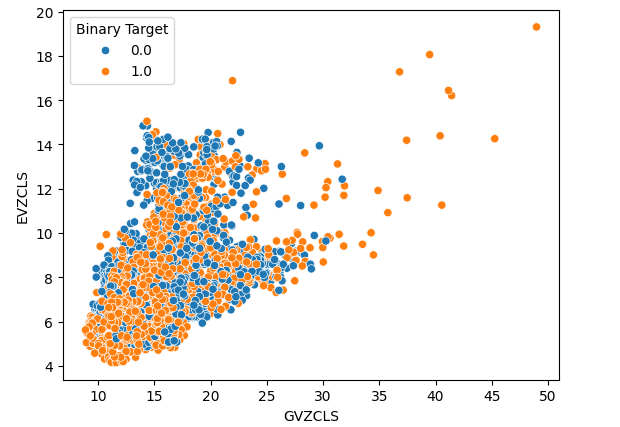
图6:我们的最终散点图
我们的数据中可能存在无法在二维空间中可视化的隐藏结构。因此,我们创建了一个3D散点图,以可视化两个替代数据集对XAUEUR的影响。在3D图中仍然可以清晰地看到看涨K线集合。这可能表明我们的替代数据在某些点上很好地分离了数据。
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(merged_data["GVZCLS"],merged_data["EVZCLS"],merged_data["Close"],c=merged_data["Binary Target"],cmap="plasma") ax.set_xlabel("GVZCLS") ax.set_ylabel("EVZCLS") ax.set_zlabel("Close")
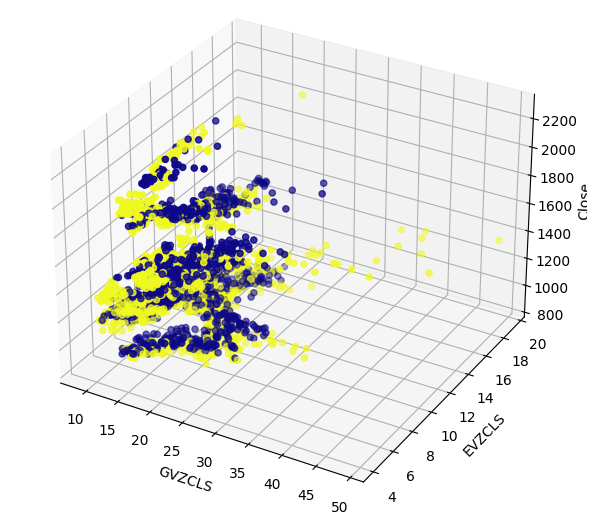
图7:我们的市场数据的3D散点图
我们还可以使用降维技术,为我们6维的市场数据创建一个二维表示。我们将使用t-SNE算法来完成这项任务。该算法最初由Geoffrey Hinton等人在2002年发表的一篇论文中提出。原始论文可以通过这个链接找到,这里。Hinton被认为是机器学习领域的先驱,这主要归功于他1986年的论文,该论文展示了如何使用反向传播算法训练神经网络来预测句子向量表示中的下一个词。他的贡献帮助普及了反向传播算法的广泛采用。

图8:Geoffrey Hinton博士
t-SNE算法旨在创建高维数据的紧凑表示,其中高维空间中所有数据点之间的接近性在新的低维表示中得以保留。为了实现这一目标,该算法最小化了一个专门的成本函数,该函数衡量两个分布之间的差异。通常,这种优化过程是通过梯度下降实现的。首先,该算法创建原始高维数据的低秩矩阵。然后,它迭代移动数据点以最小化成本,记住成本是低秩矩阵中数据的分布与原始数据分布之间的差异。t-SNE算法有助于可视化隐藏在高维空间中的数据集合。
我们将导入所需的库。
#Let's create a TSNE Plot from sklearn.manifold import TS
然后我们将实例化t-SNE对象,并让它创建数据的二维表示。
#Create a TSNE object which will reduce the data to 2 dimensions tsne = TSNE(n_components=2,perplexity=30)
将t-SNE对象拟合到我们的数据中。
#Apply TSNE to the data
tsne_data = tsne.fit_transform(merged_data[predictors]) 绘制数据的新表示形式。
#Create a scatter plot plt.scatter(tsne_data[:,0],tsne_data[:,1])
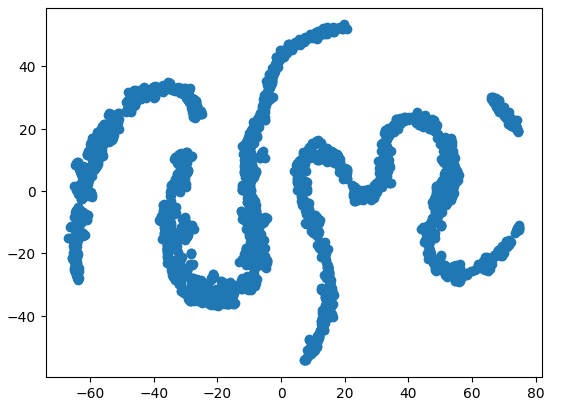
图9:我们的市场数据的t-SNE图
由于迭代优化过程的随机性,重现我们在本次讨论中获得的图可能会很困难。此外,如果我们再次执行该过程,如果获得不同的散点图,我们也不会感到惊讶。我们特别感兴趣的是算法试图保留的聚类数量。我们的数据集似乎有4个不同的聚类,此外,图的弯曲性质可能表明聚类内随时间存在依赖关系。
自相关(ACF)图在时间序列分析中被广泛使用,用于检查数据是否平稳、是否存在季节性波动等。ACF图展示了时间序列当前值与其先前值之间的相关性水平。我们对XAUEUR收盘价和两个CBOE替代数据集进行了3个ACF图的绘制。所有3个图都表明数据具有持久性成分,这与我们之前绘制的热力图所显示的结果一致。当ACF图的尾部很长且缓慢衰减至0时,我们会自然地考虑数据中是否存在强烈的趋势或季节性成分。
#Let's look at an autocorrelation plot of the data close_acf = plot_acf(merged_data["Close"])
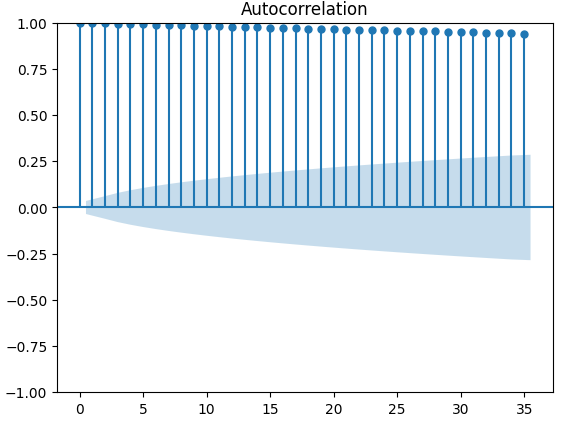
图10:XAUEUR收盘价的自相关(ACF)图
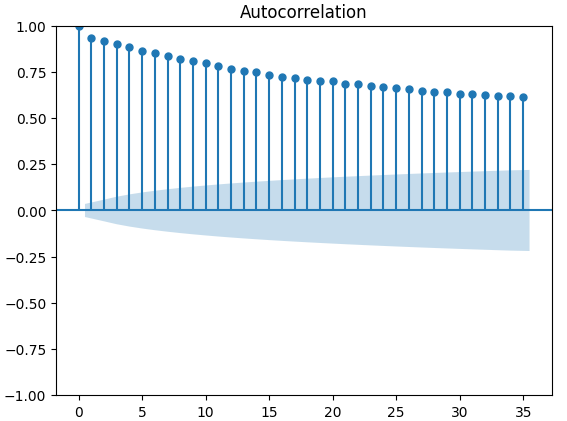
图11:CBOE欧元波动性指数自相关(ACF)图
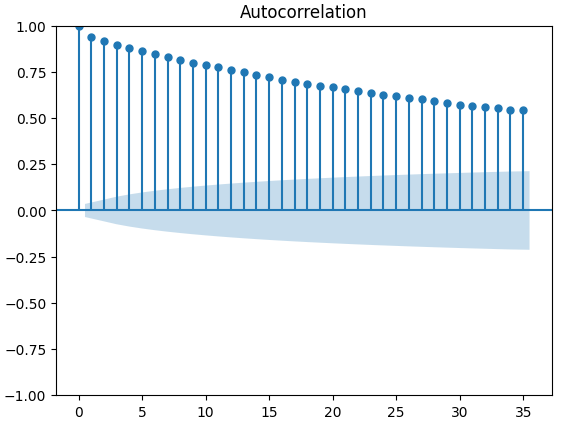
图12:CBOE黄金波动性指数自相关(ACF)图
偏自相关(PACF)图告诉我们,为了解释时间序列与其滞后项之间观察到的大部分相关性,我们需要回溯多长时间。换句话说,滞后3期观察到的相关性中有多少并没有从滞后2期延续过来?我们的3个PACF图都表明,最多4个滞后项可以解释时间序列数据中的大部分自相关性。
#Let's look at an partial autocorrelation plot of the close data close_pacf = plot_pacf(merged_data["Close"])
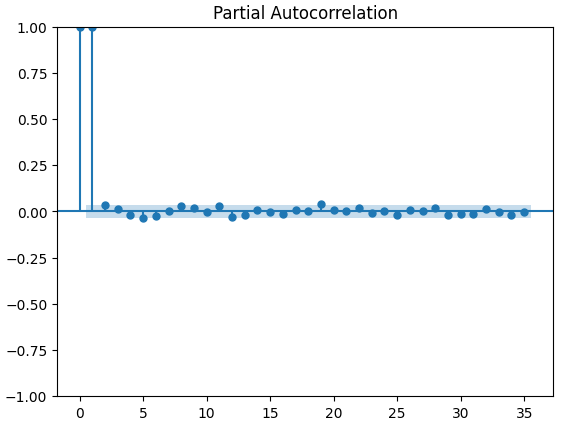
图13:XAUEUR收盘价的偏自相关(PACF)图
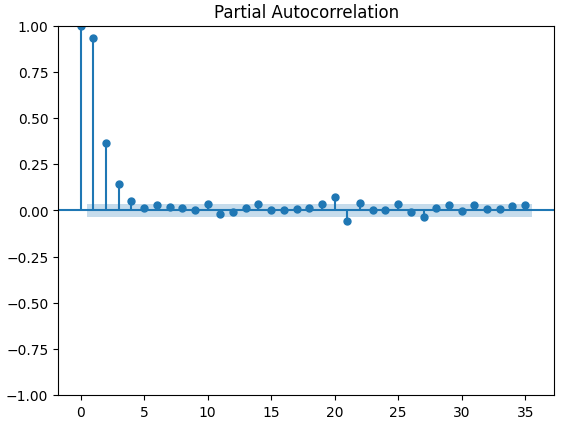
图15:CBOE欧元波动率指数的偏自相关(PACF)图
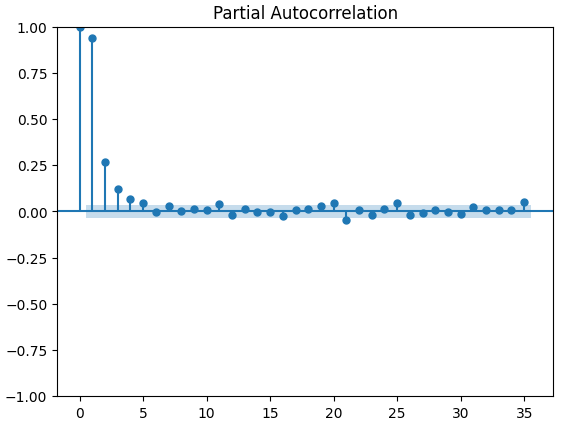
图15:CBOE黄金波动率指数的偏自相关(PACF)图
准备建模
在我们开始用深度神经网络对数据进行建模之前,我们必须先做一些准备工作。
#Preparing to model the data from sklearn.preprocessing import RobustScaler from sklearn.model_selection import TimeSeriesSplit,train_test_split from sklearn.metrics import mean_squared_error from sklearn.neural_network import MLPRegressor
第一步是标准化和缩放输入数据,以便我们的模型能够有效地学习。
#Reset the index of our data merged_data.reset_index(inplace=True) X = merged_data.loc[:,predictors] y = merged_data.loc[:,target] #Scale our data scaler = RobustScaler() X = pd.DataFrame(scaler.fit_transform(merged_data[predictors]),columns=predictors)
现在我们需要为我们的三组预测因子创建训练集和测试集。在这一步中,切勿随机打乱数据。否则,我们会破坏分析的完整性。
#Perform train test splits ohlc_train_X,ohlc_test_X,train_y,test_y = train_test_split(X.loc[:,ohlc_predictors],y,shuffle=False,train_size=0.5) fred_train_X,fred_test_X,_,_ = train_test_split(X.loc[:,fred_predictors],y,shuffle=False,train_size=0.5) train_X,test_X,_,_ = train_test_split(X.loc[:,predictors],y,shuffle=False,train_size=0.5)
最后,我们需要创建时间序列对象,并随后创建一个数据框来存储验证误差水平。
#Let's now cross-validate each of the predictors #Create the time-series split object tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead) validation_error = pd.DataFrame(columns=["OHLC Predictors","FRED Predictors","All Predictors"],index=np.arange(0,5))
数据建模
我们现在可以开始对数据进行建模,并对模型进行交叉验证。
#Performing cross validation model = MLPRegressor(hidden_layer_sizes=(20,5)) for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],:],train_y.loc[train[0]:train[-1]]) validation_error.iloc[i,2] = mean_squared_error(train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],:]))
我们的验证误差水平。
#Our validation error
validation_error | MetaTrader 5 OHLC 数据 | FRED CBOE 替代数据 | 所有数据 |
|---|---|---|
| 875423.637167 | 881892.498319 | 857846.11554 |
| 794999.120981 | 831138.370726 | 946193.178747 |
| 1058884.292095 | 474744.732539 | 631259.842972 |
| 419566.842693 | 882615.372658 | 483408.373559 |
| 96693.318078 | 618647.934237 | 237935.04009 |
我们可能无法立即判断哪个模型表现最好,但当我们分析各列的平均值时,可以清楚地看到最后一个模型表现异常出色。在下面的图表中,我们将第一列的平均值从其余各列中减去。通过这种方式,第一列的值变为0,所有表现不佳的模型都将具有大于0的列值。因此,我们可以清楚地看到最后一个模型表现相当出色。
#Our mean error levels val_err = validation_error.mean() val_err = val_err.iloc[:] - val_err.iloc[0] val_err.plot(kind="bar")
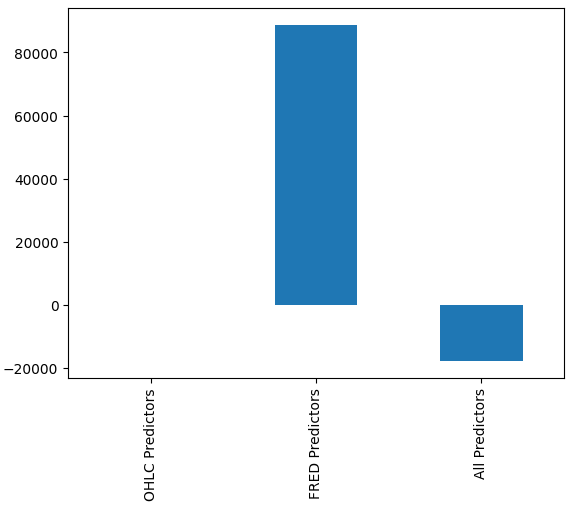
图16:使用3种不同数据集的模型性能
对模型性能进行箱线图分析进一步表明,最后一组预测因子似乎是我们的最佳选择,平均误差率最低,且方差不像仅使用OHCL数据时那么大。
#Let's perform boxplots of our validation error sns.boxplot(validation_error)
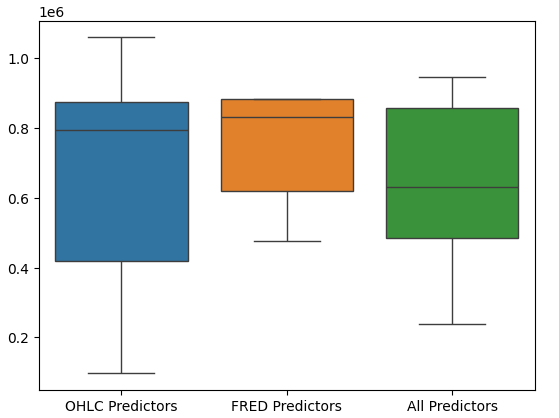
图17:以箱线图形式展示的模型性能
特征重要性
我们永远不应盲目信任任何模型,仅仅因为它产生了低误差指标就将其部署到生产环境中。让我们检查模型所学到的关系。我们希望了解模型的全局特征重要性。我们将从创建累积局部效应(ALE)图开始。ALE旨在为在高度相关数据上训练的机器学习模型提供稳健的解释。ALE试图隔离每个输入对模型输出的影响。
#Feature importance
from alibi.explainers import ALE , plot_ale 我们现在将实例化ALE对象,并为我们的深度神经网络获取全局特征重要性的解释。这将帮助我们理解每个输入对模型预测的影响。
#Explaining our deep neural network model = MLPRegressor(hidden_layer_sizes=(20,5)) model.fit(train_X,train_y) dnn_ale = ALE(model.predict,feature_names=predictors,target_names=["XAUEUR Close"])
让我们现在计算并绘制模型每个输入的ALE值。
#Obtaining the explanation
ale_X = X.to_numpy()
dnn_explanations = dnn_ale.explain(ale_X)
#Plotting feature importance
plot_ale(dnn_explanations,n_cols=3,fig_kw={'figwidth':8,'figheight':8},sharey=None) 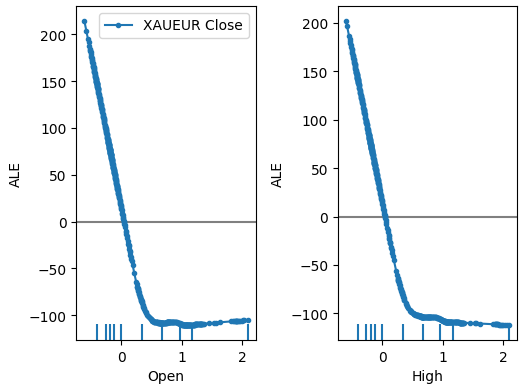
图18:XAUEUR开盘和最高价预测因子的部分ALE图
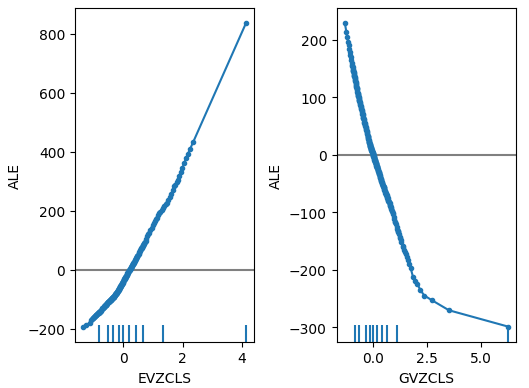
图19:FRED CBOE波动率指数的ALE图
解读ALE图相当直观,该图展示了随着每个预测因子值的变化,模型预测的变化情况。正如我们所见,随着开盘价和最高价的增加,模型的预测最初下降。然而,随着价格水平的持续上升,模型变得不那么敏感。尽管我们这里没有包括,最低价和收盘价的ALE图与我们展示的两个图看起来完全相同。
当我们现在将注意力转向替代数据的ALE图时,我们观察到欧元波动率指数创建了一个ALE图,覆盖了其他变量未能覆盖的部分图表。换句话说,该预测因子似乎解释了我们之前无法解释的目标变量的方差。此外,ALE图的向上斜率表明,随着预测因子值的增加,模型的预测也增加。
接下来我们将获取模型性能的SHAP解释。SHAP值帮助我们量化模型的每个输入与模型的平均预测相比,对特定预测的贡献。SHAP值基于博弈论的数学原理。该算法考虑了所有可能的预测因子组合,然后计算输入在所有可能组合中的平均影响。
首先,我们将导入SHAP库。
#SHAP Values
import shap 计算SHAP值。
#Calculating SHAP values explainer = shap.Explainer(model.predict,train_X) shap_values = explainer(test_X)#Calculating SHAP values
绘制SHAP值。
#Plot the beeswarm plot
shap.plots.beeswarm(shap_values) 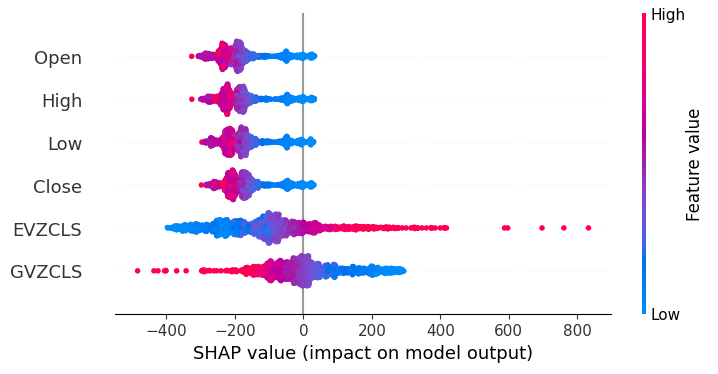
图20:我们的SHAP解释
根据我们的SHAP解释,从XAUEUR市场本身获取的市场数据是我们拥有的最重要的数据。此外,SHAP图还表明,随着当前市场价格的增加,目标变量倾向于下降。
参数调优
让我们尝试从模型中获得更多性能,我们先从导入所需的库开始。
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV 初始化模型。
#Reinitialize the model model = MLPRegressor(hidden_layer_sizes=(20,5))
定义调优器对象。
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"activation" : ["relu","logistic","tanh","identity"],
"solver":["adam","sgd","lbfgs"],
"alpha":[0.1,0.01,0.001,0.0001,0.00001,0.00001,0.0000001],
"tol":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"learning_rate":['constant','adaptive','invscaling'],
"shuffle": [True,False]
},
n_iter=500,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) 拟合调优器。
#Fit the tuner
tuner_results = tuner.fit(train_X,train_y) 这些是我们找到的最佳参数。
#The best parameters we found
tuner_results.best_params_ 'solver': 'lbfgs',
'shuffle': True,
'learning_rate': 'adaptive',
'alpha': 0.1,
'activation': 'identity'}
Scipy在其minimize模块中包含了优化程序。这些程序需要一个优化过程的起始点。我们将使用随机搜索找到的最佳参数值作为我们第二阶段优化的起始点。
#Deeper optimization
from scipy.optimize import minimize 现在,我们将创建一个数据框对象来存储我们在验证中的误差水平。
#Create a dataframe to store our accuracy current_error_rate = pd.DataFrame(index = np.arange(0,5),columns=["Current Error"])
每个优化算法都需要一个目标函数使之运作。在我们的情况下,目标函数是模型在训练集上的平均交叉验证误差。我们的优化过程将寻找使我们的平均误差最小化的模型参数。
#Define the objective function def objective(x): #The parameter x represents a new value for our neural network's settings #In order to find optimal settings, we will perform 10 fold cross validation using the new setting #And return the average RMSE from all 10 tests #We will first turn the model's Alpha parameter, which controls the amount of L2 regularization model = MLPRegressor(hidden_layer_sizes=(20,5),activation='identity',learning_rate='adaptive',solver='lbfgs',shuffle=True,alpha=x[0],tol=x[1]) #Now we will cross validate the model for i,(train,test) in enumerate(tscv.split(train_X)): #Train the model model.fit(train_X.loc[train[0]:train[-1],:],train_y.loc[train[0]:train[-1]]) #Measure the RMSE current_error_rate.iloc[i,0] = mean_squared_error(train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],:])) #Return the Mean CV RMSE return(current_error_rate.iloc[:,0].mean())
让我们定义优化过程的起始点,并且我们也应该定义允许输入值的范围。
#Define the starting point pt = [0.1,0.00000001] bnds = ((0.0000000000000000001,10000000000),(0.0000000000000000001,10000000000))
优化模型。
#Searchin deeper for parameters result = minimize(objective,pt,method="L-BFGS-B",bounds=bnds)
过拟合测试
过拟合是任何机器学习项目中都可能出现的问题。当我们的模型未能对数据进行有意义的泛化,而是开始学习数据中的噪声和其他无意义的关联时,就会出现过拟合。为了测试过拟合,我们将比较我们定制的两个模型的准确性,与默认模型进行对比。
#Testing for overfitting default_model = MLPRegressor(hidden_layer_sizes=(20,5)) customized_model = MLPRegressor(hidden_layer_sizes=(20,5),activation='identity',learning_rate='adaptive',solver='lbfgs',shuffle=True,alpha=0.1,tol=0.0000001) customized_lbfgs_model = MLPRegressor(hidden_layer_sizes=(20,5),activation='identity',learning_rate='adaptive',solver='lbfgs',shuffle=True,alpha=result.x[0],tol=result.x[1])
现在让我们准备好对每个模型进行交叉验证。
#Preparing to cross validate the models models = [ default_model, customized_model, customized_lbfgs_model ] #We will store our validation error here validation_error = pd.DataFrame(columns=["Default Model","Customized Model","L-BFGS Model"],index=np.arange(0,5)) #We will now reset the indexes test_y = test_y.reset_index() test_X = test_X.reset_index()
我们要在训练集上对每个模型进行拟合。
#Fit each of the models for m in models: m.fit(train_X,train_y)
现在,让我们对我们模型在未见数据上的性能进行交叉验证,也就是我们一直保留到现在的测试集。
#Cross validating each model for j in np.arange(0,len(models)): model = models[j] for i,(train,test) in enumerate(tscv.split(test_X)): model.fit(test_X.loc[train[0]:train[-1],:],test_y.loc[train[0]:train[-1],"Target"]) validation_error.iloc[i,j] = mean_squared_error(test_y.loc[test[0]:test[-1],"Target"],model.predict(test_X.loc[test[0]:test[-1],:]))
我们的验证误差水平。
#Our validation error
validation_error | 默认模型 | 随机搜索模型 | L-BFGS-B 模型 |
|---|---|---|
| 22360.060721 | 5917.062055 | 3734.212826 |
| 17385.289026 | 36726.684574 | 35886.972729 |
| 13782.649037 | 5128.022626 | 20886.845316 |
| 3082484.290698 | 6950.786438 | 5789.948045 |
| 4076009.132941 | 27729.589769 | 22931.572161 |
表现最好的模型是随机搜索模型。
#Plotting the difference in our performance levels mean = validation_error.mean() mean = mean.iloc[:] - mean.iloc[0] mean.plot(kind="bar")
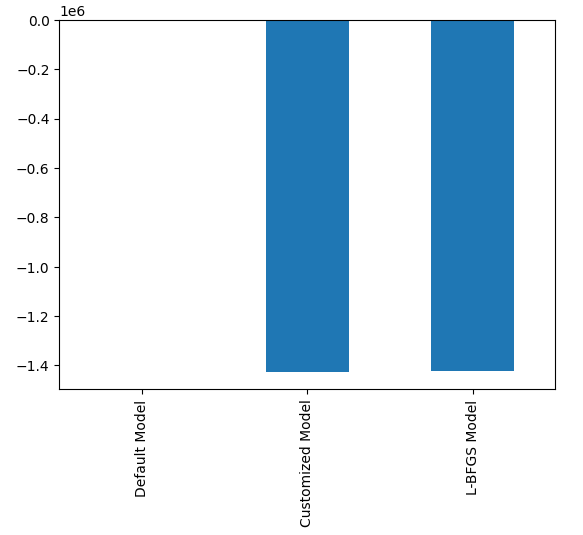
图21:我们的交叉验证误差水平
可视化我们模型的性能,清楚地展示了默认模型对数据处理得有多差。
#Visualizing the results
validation_error.plot() 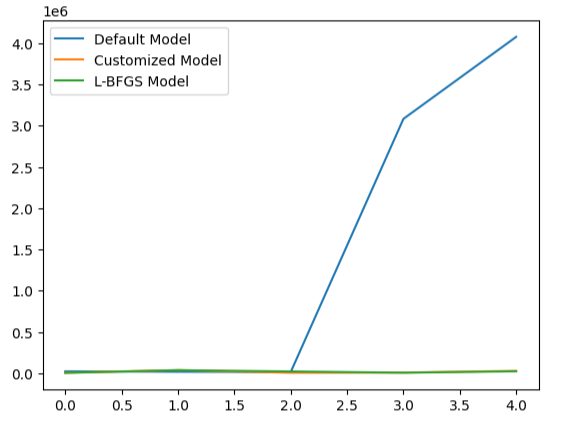
图22:测试过拟合
这一点通过我们的箱线图进一步得到了加强。我们可以看出,我们已经以相当大的幅度超过了默认模型。
#Visualizing our results
sns.boxplot(validation_error) 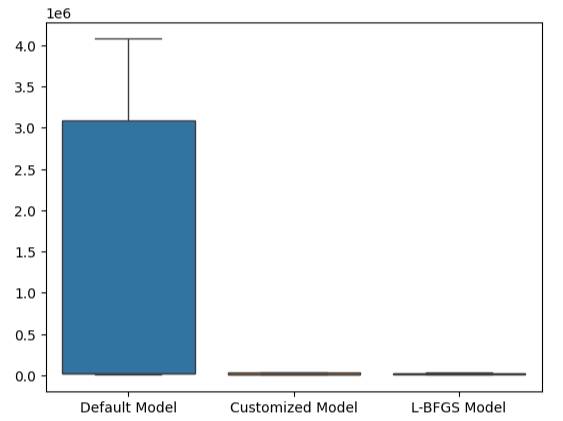
图23:我们以很大的幅度超过了默认模型
准备导出为ONNX格式
在我们将模型导出为ONNX格式之前,我们必须首先以一种可以在MetaTrader 5终端中复现的方式标准化和缩放我们的数据。为了实现这一点,我们将从每一列中减去列的均值,然后最终将每一列除以其标准差。我们将以CSV格式写出我们的缩放因子,以便我们可以在MetaTrader 5终端中检索它们来缩放我们的模型输入。
#Let us now prepare to export our model to onnx format scale_factors = pd.DataFrame(columns=predictors,index=["mean","standard deviation"]) for i in np.arange(0,len(predictors)): scale_factors.iloc[0,i] = merged_data.loc[:,predictors[i]].mean() scale_factors.iloc[1,i] = merged_data.loc[:,predictors[i]].std() merged_data.loc[:,predictors[i]] = (merged_data.loc[:,predictors[i]] - merged_data.loc[:,predictors[i]].mean())/merged_data.loc[:,predictors[i]].std() scale_factors
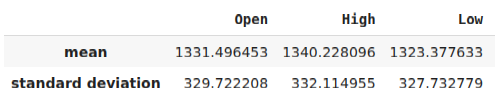
图24:我们的部分缩放因子
现在我们将以CSV格式写出数据。
#Save the scale factors to CSV scale_factors.to_csv("scale_factors.csv")
导出为ONNX格式
ONNX是一种跨不同编程语言构建和共享机器学习模型的协议。ONNX协议允许我们无缝地将深度神经网络嵌入到我们的EA中,使用MQL5 ONNX API。
让我们先加载我们需要的库。
#Exporting to ONNX format
import onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType 在所有数据上训练模型。
#Fit the model on all the data we have
customized_model.fit(merged_data.loc[:,predictors],merged_data.loc[:,target]) 在导出ONNX模型时,输入形状可能会丢失。因此,让我们明确指定输入形状。
# Define the input type initial_types = [("float_input",FloatTensorType([1,6]))]
创建模型的ONNX表示。
# Create the ONNX representation onnx_model = convert_sklearn(customized_model,initial_types=initial_types,target_opset=12)
将ONNX表示保存到扩展名为".onnx"的文件中。
# Save the ONNX model onnx_name = "XAUEUR FRED D1.onnx" onnx.save_model(onnx_model,onnx_name)
获取最新的FRED数据
在我们开始构建EA之前,我们需要创建一个Python脚本,该脚本将不断与我们的终端共享最新的FRED数据。我们将创建一个脚本,该脚本每天获取一次最新数据,并将其以CSV格式写入“Files”文件夹中,以便我们的交易应用程序可以访问这些数据。
#A function to write out our alternative data to CSV def write_out_alternative_data(): euro = fred.get_series("EVZCLS") euro = euro.iloc[-1] gold = fred.get_series("GVZCLS") gold = gold.iloc[-1] data = pd.DataFrame(np.array([euro,gold]),columns=["Data"],index=["Fred Euro","Fred Gold"]) data.to_csv("C:\\ENTER\\YOUR\\PATH\\HERE\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\fred_xau_eur.csv")
现在我们将写出一个无限循环,写出数据,然后休眠一天。
while True: #Update the fred data for our MT5 EA write_out_alternative_data() #If we have finished all checks then we can wait for one day before checking for new data time.sleep(24 * 60 * 60)
构建我们的EA
我们现在可以开始构建我们的EA了。我们首先需要我们刚刚创建的ONNX文件。
//+------------------------------------------------------------------+ //| EURXAU Fred AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Volatility Doctor" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Require the ONNX file | //+------------------------------------------------------------------+ #resource "\\Files\\XAUEUR FRED D1.onnx" as const uchar onnx_buffer[];
加载交易类帮助我们管理头寸。
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
这些全局变量将在我们应用程序的许多不同部分中共享。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; vector mean_values = vector::Zeros(6); vector std_values = vector::Zeros(6); vectorf model_inputs = vectorf::Zeros(6); vectorf model_output = vectorf::Zeros(1); double bid,ask; int system_state,model_sate;
现在,我们需要一个函数,从我们在应用程序开头创建的ONNX缓冲区中创建我们的ONNX模型。我们的函数将首先创建并验证ONNX模型,最后它将设置并验证模型的输入和输出形状。如果我们在任何步骤失败,该函数将返回false,这反过来将停止初始化过程。
//+------------------------------------------------------------------+ //| Load the ONNX file | //+------------------------------------------------------------------+ bool load_onnx_file(void) { //--- Create the ONNX model from the buffer we loaded earlier onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the model we just created if(onnx_model == INVALID_HANDLE) { //--- Give the user feedback on the error Comment("Failed to create the ONNX model: ",GetLastError()); //--- Break initialization return(false); } //--- Define the I/O shape ulong input_shape [] = {1,6}; //--- Validate the input shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { //--- Give the user feedback Comment("Failed to define the ONNX input shape: ",GetLastError()); //--- Break initialization return(false); } ulong output_shape [] = {1,1}; //--- Validate the output shape if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { //--- Give the user feedback Comment("Failed to define the ONNX output shape: ",GetLastError()); //--- Break initialization return(false); } //--- We've finished return(true); } //+------------------------------------------------------------------+
从那里开始,我们将定义用于归一化模型输入的缩放因子。
//+------------------------------------------------------------------+ //| Load our scaling factors | //+------------------------------------------------------------------+ bool load_scaling_factors(void) { //--- Load the scaling values mean_values[0] = 1331.4964525595044; mean_values[1] = 1340.2280958591457; mean_values[2] = 1323.3776328659928; mean_values[3] = 1331.706768829475; mean_values[4] = 8.258127607767035; mean_values[5] = 16.35582438284101; std_values[0] = 329.7222075527991; std_values[1] = 332.11495530642173; std_values[2] = 327.732778866831; std_values[3] = 330.1146052811378; std_values[4] = 2.199782202942867; std_values[5] = 4.241112965400358; //--- Validate the values loaded correctly if((mean_values.Sum() > 0) && (std_values.Sum() > 0)) { return(true); } //--- We failed to load the scaling values return(false); }
当我们的应用程序不再使用时,我们将释放不再使用的资源。
//+------------------------------------------------------------------+ //| Free up the resources we no longer need | //+------------------------------------------------------------------+ void release_resources(void) { //--- Free up all the resources we have used so far OnnxRelease(onnx_model); ExpertRemove(); Print("Thank you for choosing Volatility Doctor"); }
这个函数将负责更新我们的市场价格信息。
//+------------------------------------------------------------------+ //| Fetch market data | //+------------------------------------------------------------------+ void fetch_market_data(void) { //--- Update the market data bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); }
以下函数负责从我们的模型中获取预测。首先,我们将使用MQL5的CopyRates()函数获取XAUEUR货币对的当前OHLC数据。在获取数据后,我们将对其进行归一化处理,并将其存储在我们之前定义的输入向量中。从这里开始,我们将调用另一个函数来读取我们文件中最新的FRED数据。
//+------------------------------------------------------------------+ //| This function will fetch a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { //--- Get the input data ready for(int i =0; i < 6; i++) { //--- The first 4 inputs will be fetched from the market matrix xau_eur_ohlc = matrix::Zeros(1,4); xau_eur_ohlc.CopyRates(Symbol(),PERIOD_D1,COPY_RATES_OHLC,0,1); //--- Fill in the data if(i<4) { model_inputs[i] = (float)((xau_eur_ohlc[i,0] - mean_values[i])/ std_values[i]); } //--- We have to read in the fred alternative data else { read_fred_data(); } } }
下面定义的函数将读取包含最新FRED数据的CSV文件,并在将数据存储到输入向量并从我们的模型中获取预测之前对其进行归一化处理。我们将使用一个整数来表示模型的预测。这将帮助我们快速发现潜在的反转,并关闭我们的头寸,希望是在市场的正确一侧。
//+-------------------------------------------------------------------+ //| Read in the FRED data | //+-------------------------------------------------------------------+ void read_fred_data(void) { //--- Read in the file string file_name = "fred_xau_eur.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 10) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Counter: "); Print(counter); Print("Trying to read string: ",value); if(counter == 3) { Print("Fred Euro data: ",value); model_inputs[4] = (float)((((float) value) - mean_values[4])/std_values[4]); } if(counter == 5) { Print("Fred Gold data: ",value); model_inputs[5] = (float)((((float) value) - mean_values[5])/std_values[5]); } if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //--- Show the input and Fred data Print("Input Data: "); Print(model_inputs); //---Close the file FileClose(result); //--- Store the model prediction OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_output); Comment("Model Forecast",model_output[0]); if(model_output[0] > iClose(Symbol(),PERIOD_D1,0)) { model_sate = 1; } else { model_sate = -1; } } //--- We failed to find the file else { //--- Give the user feedback Print("We failed to find the file with the FRED data"); } }
让我们现在定义我们的应用程序应该如何启动。我们的应用程序应该首先创建ONNX模型,然后加载我们需要的缩放因子。如果这些步骤中的任何一个失败,我们将完全中止初始化过程。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX model if(!load_onnx_file()) { //--- We failed to load our ONNX model return(INIT_FAILED); } //--- Load the scaling factors if(!load_scaling_factors()) { //--- We failed to read in the scaling factors return(INIT_FAILED); } //--- We mamnaged to load our model return(INIT_SUCCEEDED); }
当我们的程序被从图标上移出后,释放我们不再需要的资源。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we no longer need release_resources(); }
最后,每当我们收到更新的市场报价时,我们首先会将更新的市场价格存储在内存中。随后,如果我们没有持仓,我们只会在更高时间框架的价格走势支持我们的模型预测时,才会跟随我们的模型预测。或者,如果我们已经有持仓,当我们的模型预期价格水平将出现反转时,我们将平仓。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update market data fetch_market_data(); //--- Fetch a prediction from our model model_predict(); //--- If we have no positions follow the model's lead if(PositionsTotal() == 0) { //--- Buy position if(model_sate == 1) { if(iClose(Symbol(),PERIOD_W1,0) > iClose(Symbol(),PERIOD_W1,12)) { Trade.Buy(0.3,Symbol(),ask,0,0,"XAUEUR Fred AI"); system_state = 1; } }; //--- Sell position if(model_sate == -1) { if(iClose(Symbol(),PERIOD_W1,0) < iClose(Symbol(),PERIOD_W1,12)) { Trade.Sell(0.3,Symbol(),bid,0,0,"XAUEUR Fred AI"); system_state = -1; } }; } //--- If we allready have positions open, let's manage them if(model_sate != system_state) { Trade.PositionClose(Symbol()); } } //+------------------------------------------------------------------+

图25:运行我们的EA
结论
在这篇文章中,我们已经证明,将 FRED CBOE 波动率指数纳入其中可能会提高你的机器学习模型的准确性。虽然我们无法保证本文提供的信息能始终如一地带来成功,但如果你已准备好将另类数据纳入你的交易策略中,那么这绝对值得考虑。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/15841
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
