数据科学与机器学习(第 11 部分):朴素贝叶斯(Bayes),交易中的概率论

热力学第四定律:如果成功的概率并非近乎为一,那么它就该死地接近于零。
大卫·罗斯(David J. Rose)
概述
朴素贝叶斯分类器是一种概率算法,用于机器学习中的分类任务。 它基于贝叶斯定理,该定理根据给定证据计算假设的概率。 这种概率分类器在各种情况下都是一种简单而有效的算法。 它假定进行分类的特征彼此独立。 例如:如果您希望此模型在给定身高、脚大小、体重和肩长的情况下对人类(男性和女性)进行分类,则该模型将所有这些变量视为彼此独立,在这种情况下,它甚至并不认可脚的大小和身高与人类有关。
由于这个模型不会费心去理解自变量之间的范式,我认为我们应该给它一个机会,尝试用它来做出明智的交易决策。 我相信在交易领域,没有人完全理解这些范式,所以,我们来看看朴素贝叶斯的表现如何。

事不宜迟,我们调用模型实例并立即使用它。 稍后我们将讨论这个模型是由什么组成的。
准备训练数据
对于此示例,我选择了 5 个指标,其中大多数是振荡器和交易量,因为我认为它们是很好的分类变量,而且它们具有有限数额,这令它们适合正态分布,这是该算法的核心思想之一,不过您不必受限于这些指标,如此请随意探索您喜欢的各种指标和数据。
最重要的先做:
matrix Matrix(TrainBars, 6); int handles[5]; double buffer[]; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Preparing Data handles[0] = iBearsPower(Symbol(),TF, bears_period); handles[1] = iBullsPower(Symbol(),TF, bulls_period); handles[2] = iRSI(Symbol(),TF,rsi_period, rsi_price); handles[3] = iVolumes(Symbol(),TF,VOLUME_TICK); handles[4] = iMFI(Symbol(),TF,mfi_period,VOLUME_TICK ); //--- vector col_v; for (ulong i=0; i<5; i++) //Independent vars { CopyBuffer(handles[i],0,0,TrainBars, buffer); col_v = matrix_utils.ArrayToVector(buffer); Matrix.Col(col_v, i); } //-- Target var vector open, close; col_v.Resize(TrainBars); close.CopyRates(Symbol(),TF, COPY_RATES_CLOSE,0,TrainBars); open.CopyRates(Symbol(),TF, COPY_RATES_OPEN,0,TrainBars); for (int i=0; i<TrainBars; i++) { if (close[i] > open[i]) //price went up col_v[i] = 1; else col_v[i] = 0; } Matrix.Col(col_v, 5); //Adding independent variable to the last column of matrix //---
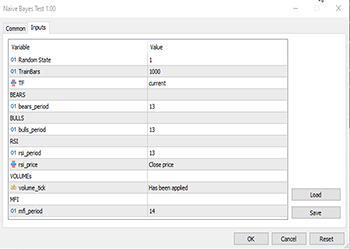
变量 TF、bears_period 等。 在上述代码顶端找到的输入定义的变量:
由于这是监督学习,我不得不编造目标变量,其逻辑很简单。 如果收盘价高于开盘价,则目标变量设置为 class 1,否则 class 为 0。 这就是目标变量的设置方式。 下面是数据集矩阵外貌的概览:
CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) "Bears" "Bulls" "Rsi" "Volumes" "MFI" "Target Var" CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-3.753148029472797e-06,0.008786246851970603,67.65238281791684,13489,55.24611392389958,0] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.002513216984025402,0.005616783015974569,50.29835423473968,12226,49.47293811405203,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.001829900272021678,0.0009700997279782353,47.33479153312328,7192,46.84320886771249,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.004718485947447171,-0.0001584859474472733,39.04848493977027,6267,44.61564654651691,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.004517273669240485,-0.001367273669240276,45.4127802340401,3867,47.8438816641815,0]
然后,我决定在分布图中可视化数据,看看它们是否遵循概率分布:





对于那些想要了解不同种类的概率分布的人来说,有一整篇文章链接在此。
如果您仔细查看所有自变量的相关系数矩阵:
string header[5] = {"Bears","Bulls","Rsi","Volumes","MFI"}; matrix vars_matrix = Matrix; //Independent variables only matrix_utils.RemoveCol(vars_matrix, 5); //remove target variable ArrayPrint(header); Print(vars_matrix.CorrCoef(false));
输出:
CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) "Bears" "Bulls" "Rsi" "Volumes" "MFI" CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [[1,0.7784600081627714,0.8201955846987788,-0.2874457184671095,0.6211980865273238] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.7784600081627714,1,0.8257210032763984,0.2650418244580489,0.6554288778228361] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.8201955846987788,0.8257210032763984,1,-0.01205084357067248,0.7578863565293196] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [-0.2874457184671095,0.2650418244580489,-0.01205084357067248,1,0.0531475992791923] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.6211980865273238,0.6554288778228361,0.7578863565293196,0.0531475992791923,1]]
您会注意到,除了交易量与其它变量的相关性外,所有变量都彼此密切相关,有些是巧合,例如 RSI 与牛势和熊势的相关性约为 82%。 交易量和 MFI 都有共同的素材,它们都是由交易量组成的,所以它们有 62% 的相关性就很合情合理。 由于高斯朴素贝叶斯不关心这些素材,我们就继续前进,但我认为检查和分析变量是个好主意。
训练模型
训练高斯朴素贝叶斯很简单,只需花费很短的时间。 我们先看看如何正确执行此操作:
Print("\n---> Training the Model\n"); matrix x_train, x_test; vector y_train, y_test; matrix_utils.TrainTestSplitMatrices(Matrix,x_train,y_train,x_test,y_test,0.7,rand_state); //--- Train gaussian_naive = new CGaussianNaiveBayes(x_train,y_train); //Initializing and Training the model vector train_pred = gaussian_naive.GaussianNaiveBayes(x_train); //making predictions on trained data vector c= gaussian_naive.classes; //Classes in a dataset that was detected by mode metrics.confusion_matrix(y_train,train_pred,c); //analyzing the predictions in confusion matrix //---
函数 TrainTestSplitMatrices 将数据拆分为 x 训练矩阵,和 x 测试矩阵,及其各自的目标向量。 就像 sklearn python 中的 train_test_split 一样。 它的核心函数是这样的:
void CMatrixutils::TrainTestSplitMatrices(matrix &matrix_,matrix &x_train,vector &y_train,matrix &x_test, vector &y_test,double train_size=0.7,int random_state=-1)
默认情况下,70% 的数据将被拆分为训练数据,其余数据将保留为测试数据集,请参阅有关此拆分的详细信息。
很多人发现,在这个函数中令人困惑的是 random_state,人们经常在 Python ML 社区中选择 random_state=42,即使任何数字都可以,选取这个数字只是为了确保每次都生成相同的随机/洗牌矩阵,以便于调试,因为它设置了 Random 种子用于生成随机数字,从而将矩阵中的行洗牌。
您也许会注意到,此函数获得的输出矩阵并非默认顺序。 关于选择这个 42 数字有若干讨论。
下面是此代码块的输出:
CS 0 14:33:04.001 Naive Bayes Test (EURUSD,H1) ---> Training the Model CS 0 14:33:04.001 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) ---> GROUPS [0,1] CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) ---> Prior_proba [0.5457142857142857,0.4542857142857143] Evidence [382,318] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Confusion Matrix CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) [[236,146] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) [145,173]] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Classification Report CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) 0.0 0.62 0.62 0.54 0.62 382.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) 1.0 0.54 0.54 0.62 0.54 318.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Accuracy 0.58 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Average 0.58 0.58 0.58 0.58 700.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) W Avg 0.58 0.58 0.58 0.58 700.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1)
根据混淆矩阵分类报告,训练模型的准确率为 58%。 您可以从该报告中了解很多,例如精度,其能告之每个已分类的准确性,请参阅更多。 基本上,Class 0 的分类似乎比 class 1 更好,这是有道理的,因为模型比其它 class 1 预测得更多,更不用说先验概率了,这是数据集的主要概率或看一眼估计的概率。 在此数据集中,先验概率为:
Prior_proba [0.5457142857142857,0.4542857142857143] Evidence [382,318]. 此先验概率的计算如下:
先验概率 = 证据/事件总数/结果
在本例中,先验概率 [382/700, 318/700]。 还记得我们拆分 1000 个数据的 70% 后得到的训练数据集大小 700 吗?
高斯朴素贝叶斯模型首先查看数据集中出现的各类概率,然后用这些概率来猜测未来可能发生的事情,这是基于证据计算出的。 在训练和测试时,算法将青睐具有较高证据的类,导致比其他类更高的概率。 有道理吧?这是此算法的缺点之一,因为当训练数据中不存在类时,模型会假设该类不会发生,因此它给出的概率为零,这意味着它不会在测试数据集中或将来的任何时候被预测。
测试模型
测试模型也很容易。 您所需要的只是将新数据插入到函数 GaussianNaiveBayes 当中,该函数已经含有至此刻的训练模型参数。
//--- Test Print("\n---> Testing the model\n"); vector test_pred = gaussian_naive.GaussianNaiveBayes(x_test); //giving the model test data to predict and obtain predictions to a vector metrics.confusion_matrix(y_test,test_pred, c); //analyzing the tested model
输出:
CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) ---> Testing the model CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Confusion Matrix CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) [[96,54] CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) [65,85]] CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Classification Report CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) 0.0 0.60 0.64 0.57 0.62 150.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) 1.0 0.61 0.57 0.64 0.59 150.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Accuracy 0.60 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Average 0.60 0.60 0.60 0.60 300.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) W Avg 0.60 0.60 0.60 0.60 300.0
太棒了,如此该模型在测试数据集上的表现略好,比之训练数据的准确度 60% 再次提高了 2%,故此这是个好消息。
策略测试器中的高斯朴素贝叶斯模型
在策略测试器上使用机器学习模型通常表现不佳,不是因为它们无法做出预测,而是因为我们通常会查看策略测试器上的利润图。 能够猜测市场下一步走向的机器学习模型并不一定意味着会让您从中赚钱,尤其是使用我用来收集和准备数据集的简单逻辑。 查看 TF 输入 PERIOD_H1(一小时)时给出的在每根柱线上收集的数据集。
close.CopyRates(Symbol(),TF, COPY_RATES_CLOSE,0,TrainBars); open.CopyRates(Symbol(),TF, COPY_RATES_OPEN,0,TrainBars);
我从一小时的时间帧内收集了 1000 根柱线,读取它们的指标值,作为自变量。 然后,我通过查看蜡烛来创建目标变量,如果看涨我们的 EA 设置 class 1,否则设置 class 0。因此,当我创建进行交易的函数时,我考虑到了这一点。 由于我们的模型将预测下一根蜡烛,因此我在每根新蜡烛上开仓,并将以前的持仓平仓。 基本上,我们的 EA 在每根柱线中的每个信号上进行交易。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if (!train_state) TrainTest(); train_state = true; //--- vector v_inputs(5); //5 independent variables double buff[1]; //current indicator value for (ulong i=0; i<5; i++) //Independent vars { CopyBuffer(handles[i],0,0,1, buff); v_inputs[i] = buff[0]; } //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); int signal = -1; double min_volume = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (isNewBar()) { signal = gaussian_naive.GaussianNaiveBayes(v_inputs); Comment("SIGNAL ",signal); CloseAll(); if (signal == 1) { if (!PosExist()) m_trade.Buy(min_volume, Symbol(), ticks.ask, 0 , 0,"Naive Buy"); } else if (signal == 0) { if (!PosExist()) m_trade.Sell(min_volume, Symbol(), ticks.bid, 0 , 0,"Naive Sell"); } } }
为了令该函数在实时交易和策略测试器中都能工作,我不得不稍微改变一下逻辑,指标 CopyBuffer() 和训练现在于 TrainTest() 函数中进行。 该函数在 OnTick 函数上运行一次,您可以让它经常运行以便训练模型,但我将其留给您作为练习。
由于 Init 函数并不适合所有这些 CopyBuffer 和 CopyRates 方法(当以这种方式使用时,它们在策略测试器上返回零值),现在所有内容都移到函数 TrainTest() 当中。
int OnInit() { handles[0] = iBearsPower(Symbol(),TF, bears_period); handles[1] = iBullsPower(Symbol(),TF, bulls_period); handles[2] = iRSI(Symbol(),TF,rsi_period, rsi_price); handles[3] = iVolumes(Symbol(),TF,VOLUME_TICK); handles[4] = iMFI(Symbol(),TF,mfi_period,VOLUME_TICK ); //--- m_trade.SetExpertMagicNumber(MAGIC_NUMBER); m_trade.SetTypeFillingBySymbol(Symbol()); m_trade.SetMarginMode(); m_trade.SetDeviationInPoints(slippage); return(INIT_SUCCEEDED); }
单次测试:1 小时时间帧
我进行了两个月测试,从 2023 年 1 月 1 日到 2023 年 2 月 14 日(昨天):
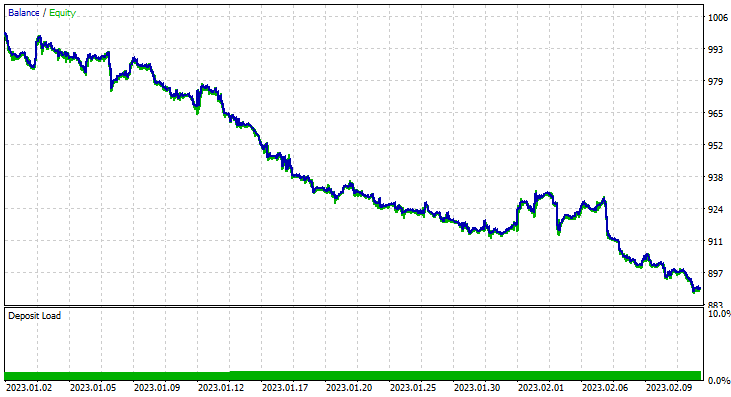
我决定在这么短的时间内(2 个月)进行测试,因为 1000 根一小时的柱线,将近 41 天,并不是一段很长的训练期,训练期很短,测试也如此。 由于 TrainTest() 函数也是在测试器上运行。 训练模型的蜡烛是 700 根柱线。
出了什么问题?
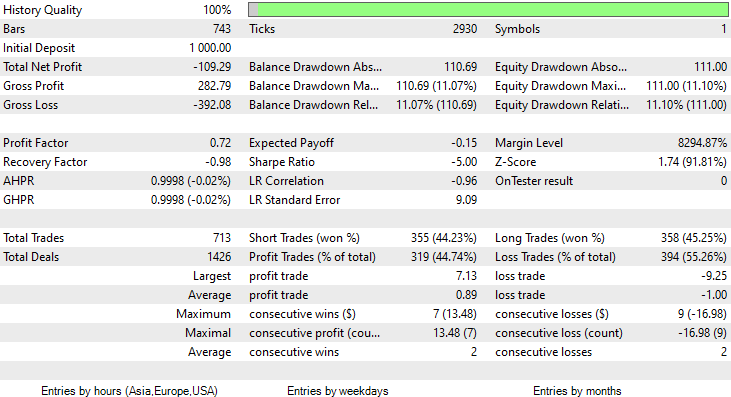
在策略测试器上,该模型给人留下的第一印象,基于训练数据给出了令人印象深刻的 60% 准确率。
CS 0 08:30:13.816 Tester initial deposit 1000.00 USD, leverage 1:100 CS 0 08:30:13.818 Tester successfully initialized CS 0 08:30:13.818 Network 80 Kb of total initialization data received CS 0 08:30:13.819 Tester Intel Core i5 660 @ 3.33GHz, 6007 MB CS 0 08:30:13.900 Symbols EURUSD: symbol to be synchronized CS 0 08:30:13.901 Symbols EURUSD: symbol synchronized, 3720 bytes of symbol info received CS 0 08:30:13.901 History EURUSD: history synchronization started .... .... .... CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> Training the Model CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> GROUPS [0,1] CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> Prior_proba [0.4728571428571429,0.5271428571428571] Evidence [331,369] CS 0 08:30:14.377 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Confusion Matrix CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 [[200,131] CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 [150,219]] CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Classification Report CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 _ Precision Recall Specificity F1 score Support CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 0.0 0.57 0.60 0.59 0.59 331.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 1.0 0.63 0.59 0.60 0.61 369.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Accuracy 0.60 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Average 0.60 0.60 0.60 0.60 700.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 W Avg 0.60 0.60 0.60 0.60 700.0
然而,它无法承诺盈利交易达到该准确度,或任何接近的准确度。 以下是我的观察:
- 逻辑在某种程度上是盲目的,它用数量换取质量。 在两个月的过程中,有 713 笔交易。 天啊,交易太多了。 这需要往相反方向改变 我们需要在更高的时间帧内训练这个模型,并在更高的时间帧内进行交易,成果则是较少的高质量交易。
- 对于此测试,必须减少训练条,我想根据最近的数据训练模型。
为了达成这一点,我在 6H 时间帧上运行了优化,且参数 Train Bars = 80,TF = 12 hours,然后我运行了测试(按新参数测试 2 个月)。 本文末尾链接的 *set 文件中可查看所有参数。
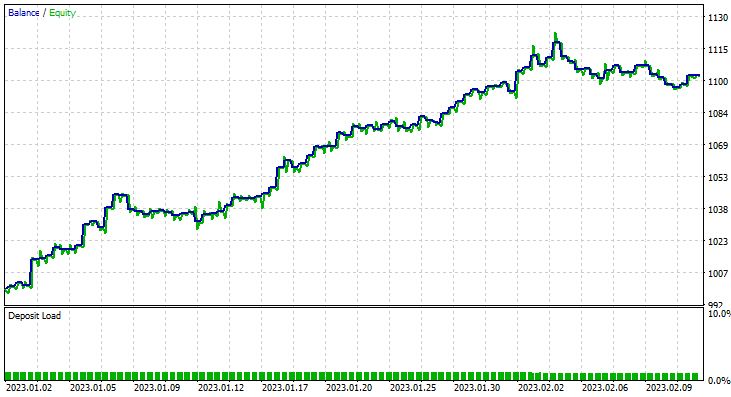
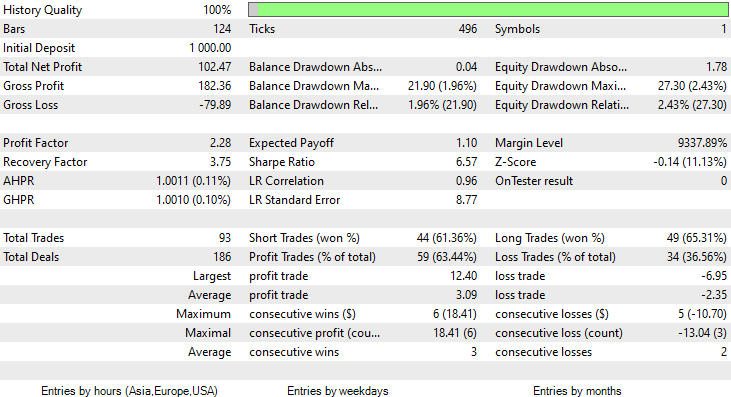
一次,高斯朴素贝叶斯模型的训练准确率为 58%。
93 在 2 个月内进行了 93 笔交易,这就是我所说的健康交易活动,平均每天 2.3 笔交易。 这次高斯朴素贝叶斯 EA 做到了 63% 的交易胜率,更不用说 10% 的利润了。
现在您已经见识到如何使用高斯朴素贝叶斯模型来制定明智的交易决策,我们来看看是什么让它律动。
朴素贝叶斯理论
不要与高斯朴素贝叶斯混淆。
该算法称为
- 朴素,因为它假设变量/特征是独立的,这种情况很罕见
-
贝叶斯,因为它基于贝叶斯定理
贝叶斯定理的公式如下:
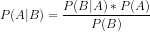
其中:
P(A|B) = 观测事件 B 的后验概率或假设 A 的概率
P(B|A) = 似然概率:给定证据的概率,假设概率为真。 简言之,B 的概率给定 A 为真
P(A) = 是观察证据之前的 A 的先验概率或假设的概率
P(B) = 边际概率:证据的概率
公式中的这些术语起初可能看起来令人困惑。 它们会在行动中变得清晰,故请紧跟我。
使用分类器操作
我们看一下天气数据集上的一个简单示例。 我们专注于单个第一列 “展望”,一旦理解了这一点,那么再添加其它列为自变量就是完全相同的过程。
| 展望 | 打网球 |
|---|---|
| 晴天 | 否 |
| 晴天 | 否 |
| 阴天 | 是 |
| 雨天 | 是 |
| 雨天 | 是 |
| 雨天 | 否 |
| 阴天 | 是 |
| 晴天 | 否 |
| 晴天 | 是 |
| 雨天 | 是 |
| 晴天 | 是 |
| 阴天 | 是 |
| 阴天 | 是 |
| 雨天 | 否 |
现在,我们在 MetaEditor 中做同样的事情:
void OnStart() { //--- matrix Matrix = matrix_utils.ReadCsvEncode("weather dataset.csv"); int cols[3] = {1,2,3}; matrix_utils.RemoveMultCols(Matrix, cols); //removing Temperature Humidity and Wind ArrayRemove(matrix_utils.csv_header,1,3); //removing column headers ArrayPrint(matrix_utils.csv_header); Print(Matrix); matrix x_matrix; vector y_vector; matrix_utils.XandYSplitMatrices(Matrix, x_matrix, y_vector); }
请记住,朴素贝叶斯仅适用于离散/非连续变量。 不要与我们在上面行动中看到的高斯朴素贝叶斯混淆,它可以处理连续变量;而这个朴素贝叶斯模型的情况不同,这就是为什么在这个示例中我决定使用这个数据集,其中包含由字符串值编码的离散值。 以下是上述操作的输出
CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) "Outlook" "Play" CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [[0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,0]]
话虽如此,我们在朴素贝叶斯类构造函数中找到先验概率:
CNaiveBayes::CNaiveBayes(matrix &x_matrix, vector &y_vector) { XMatrix.Copy(x_matrix); YVector.Copy(y_vector); classes = matrix_utils.Classes(YVector); c_evidence.Resize((ulong)classes.Size()); n = YVector.Size(); if (n==0) { Print("--> n == 0 | Naive Bayes class failed"); return; } //--- vector v = {}; for (ulong i=0; i<c_evidence.Size(); i++) { v = matrix_utils.Search(YVector,(int)classes[i]); c_evidence[i] = (int)v.Size(); } //--- c_prior_proba.Resize(classes.Size()); for (ulong i=0; i<classes.Size(); i++) c_prior_proba[i] = c_evidence[i]/(double)n; #ifdef DEBUG_MODE Print("---> GROUPS ",classes); Print("Prior Class Proba ",c_prior_proba,"\nEvidence ",c_evidence); #endif }
输出:
CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) ---> GROUPS [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) Prior Class Proba [0.3571428571428572,0.6428571428571429] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) Evidence [5,9]
[否,是] 的先验概率约为 [0.36, 0.64]
现在,若说您想知道一个人在晴天打网球的概率,此处就是您要做的:
P(是 | 晴天) = P(晴天 | 是) * P(是) / P(晴天)
简单陈述更多细节:
某些人在晴天打球的概率 = 在晴天和一些傻瓜打球概率项的倍数 * 该条件下概率项的倍数,人们打网球 / 一般晴天打球概率项的倍数。
P(晴天 | 是) = 2/9
P(是) = 0.64
P(晴天) = 5/14 = 0.357
如此,最后 P(是 | 晴天) = 0.333 x 0.64 / 0.357 = 0.4
而 P(否| 晴天): 您可以取 1- 是的概率 = 1 - 0.5972 = 0.4027 作为捷径来计算它,但我们也看看它;
P(否|晴天) = (3/5) x 0.36 / (0.357) = 0.6
以下是执行此操作的代码:
vector CNaiveBayes::calcProba(vector &v_features) { vector proba_v(classes.Size()); //vector to return if (v_features.Size() != XMatrix.Cols()) { printf("FATAL | Can't calculate probability, features columns size = %d is not equal to XMatrix columns =%d",v_features.Size(),XMatrix.Cols()); return proba_v; } //--- vector v = {}; for (ulong c=0; c<classes.Size(); c++) { double proba = 1; for (ulong i=0; i<XMatrix.Cols(); i++) { v = XMatrix.Col(i); int count =0; for (ulong j=0; j<v.Size(); j++) { if (v_features[i] == v[j] && classes[c] == YVector[j]) count++; } proba *= count==0 ? 1 : count/(double)c_evidence[c]; //do not calculate if there isn't enough evidence' } proba_v[c] = proba*c_prior_proba[c]; } return proba_v; }
此函数为晴天提供的概率向量为:
2023.02.15 16:34:21.519 Naive Bayes theory script (EURUSD,H1) Probabilities [0.6,0.4]
正是我们所期望的,但不要误会,这个函数没有给出我们概率。 我来解释一下,当您尝试在该场景中预测的数据集中只有两个类时,得到的是概率,但其它明智的是,该函数的输出需要验证为概率项,要实现这一点很简单:
取此函数得出的向量总和,然后将每个元素除以总和,剩余的向量就是实际概率值,当合计时应等于一。
probability_v = v[i]/probability_v.Sum()
这个小过程在函数 NaiveBayes() 中执行,该函数预测结果类或具有较高概率的类:
int CNaiveBayes::NaiveBayes(vector &x_vector) { vector v = calcProba(x_vector); double sum = v.Sum(); for (ulong i=0; i<v.Size(); i++) //converting the values into probabilities v[i] = NormalizeDouble(v[i]/sum,2); vector p = v; #ifdef DEBUG_MODE Print("Probabilities ",p); #endif return((int)classes[p.ArgMax()]); }
嗯,就是这样。 朴素贝叶斯是一个简单的算法,现在我们将焦点转移到高斯朴素贝叶斯上,这是我们在本文前面使用的算法。
高斯朴素贝叶斯
高斯朴素贝叶斯假设特征服从正态分布,这意味着如果预测变量采用连续变量,替代离散变量,那么假设这些采样值来自高斯分布。
正态分布回顾
正态分布是围绕其平均值对称的连续概率分布,大多数观测值围绕中心峰值聚集,并且远离平均值的概率值在两个方向上均等地逐渐减小。 处于分布两个尾部的极值同样不太可能。

这个钟形概率曲线非常强大,它是很实用的统计分析工具之一。 它表明,在距离平均值一个标准差的地方找到某物的概率约为 34%,在钟形曲线的另一侧找到某物的概率约为 34%。 这意味着大约有 68% 的机会找到一个与双方平均值相差一个标准的值。 那些以前忽略数学课的人应该继续参阅。
从这个正态分布/高斯分布中,我们想找到概率密度。 它是采用以下公式计算的。
![]()
其中:
μ = 算术均值
𝜎 = 标准差
x = 输入值
好了,由于高斯朴素贝叶斯依赖于此,我们来为它编码。
class CNormDistribution { public: double m_mean; //Assign the value of the mean double m_std; //Assign the value of Variance CNormDistribution(void); ~CNormDistribution(void); double PDF(double x); //Probability density function }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CNormDistribution::CNormDistribution(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CNormDistribution::~CNormDistribution(void) { ZeroMemory(m_mean); ZeroMemory(m_std); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CNormDistribution::PDF(double x) { double nurm = MathPow((x - m_mean),2)/(2*MathPow(m_std,2)); nurm = exp(-nurm); double denorm = 1.0/(MathSqrt(2*M_PI*MathPow(m_std,2))); return(nurm*denorm); }
创建高斯朴素贝叶斯模型
高斯朴素贝叶斯的类构造函数看起来与朴素贝叶斯的类构造函数相似。 需在此处显示和解释构造函数代码。 下面就是我们负责计算概率的主要函数。
vector CGaussianNaiveBayes::calcProba(vector &v_features) { vector proba_v(classes.Size()); //vector to return if (v_features.Size() != XMatrix.Cols()) { printf("FATAL | Can't calculate probability, features columns size = %d is not equal to XMatrix columns =%d",v_features.Size(),XMatrix.Cols()); return proba_v; } //--- vector v = {}; for (ulong c=0; c<classes.Size(); c++) { double proba = 1; for (ulong i=0; i<XMatrix.Cols(); i++) { v = XMatrix.Col(i); int count =0; vector calc_v = {}; for (ulong j=0; j<v.Size(); j++) { if (classes[c] == YVector[j]) { count++; calc_v.Resize(count); calc_v[count-1] = v[j]; } } norm_distribution.m_mean = calc_v.Mean(); //Assign these to Gaussian Normal distribution norm_distribution.m_std = calc_v.Std(); #ifdef DEBUG_MODE printf("mean %.5f std %.5f ",norm_distribution.m_mean,norm_distribution.m_std); #endif proba *= count==0 ? 1 : norm_distribution.PDF(v_features[i]); //do not calculate if there isn't enought evidence' } proba_v[c] = proba*c_prior_proba[c]; //Turning the probability density into probability #ifdef DEBUG_MODE Print(">> Proba ",proba," prior proba ",c_prior_proba); #endif } return proba_v; }
我们来看看这个模型在行动中的表现。
使用性别数据集。
| 高度(英尺) | 体重(磅) | 脚尺寸(英寸) | 人(0 男,1 女) |
|---|---|---|---|
| 6 | 180 | 12 | 0 |
| 5.92 | 190 | 11 | 0 |
| 5.58 | 170 | 12 | 0 |
| 5.92 | 165 | 10 | 0 |
| 5 | 100 | 6 | 1 |
| 5.5 | 150 | 8 | 1 |
| 5.42 | 130 | 7 | 1 |
| 5.75 | 150 | 9 | 1 |
//--- Gaussian naive bayes Matrix = matrix_utils.ReadCsv("gender dataset.csv"); ArrayPrint(matrix_utils.csv_header); Print(Matrix); matrix_utils.XandYSplitMatrices(Matrix, x_matrix, y_vector); gaussian_naive = new CGaussianNaiveBayes(x_matrix, y_vector);
输出:
CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) ---> GROUPS [0,1] CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) ---> Prior_proba [0.5,0.5] Evidence [4,4]
由于 8 人中有 4 人是男性,其余 4 人是女性,因此模型主要预测男性或女性的几率为 50-50。
我们用这个新数据来尝试这个模型,某人身高为 5.3,体重为 140,脚大小为 7.5。 您和我都知道这个人很可能是女性。
vector person = {5.3, 140, 7.5}; Print("The Person is a ",gaussian_naive.GaussianNaiveBayes(person));
输出:
2023.02.15 19:14:40.424 Naive Bayes theory script (EURUSD,H1) The Person is a 1
太棒了,已经正确预测了这个人是女性。
测试高斯朴素贝叶斯模型相对简单。 只需传递训练的矩阵,并使用混淆矩阵测量预测的准确性。
CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Confusion Matrix CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) [[4,0] CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) [0,4]] CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Classification Report CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) 0.0 1.00 1.00 1.00 1.00 4.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 4.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Accuracy 1.00 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Average 1.00 1.00 1.00 1.00 8.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) W Avg 1.00 1.00 1.00 1.00 8.0
嗯,是的,训练准确率为 100%,当所有数据都用作训练数据时,我们的模型就可以对一个人是男性还是女性进行分类。
朴素和高斯贝叶斯分类器的优点
- 它们是针对数据集进行分类的最简单、最快捷的机器学习算法之一
- 它们可用于二元和多级分类
- 尽管它们很简单,但它们通常在大多数算法的多级分类中表现良好
- 它是文本分类问题最受欢迎的选择
这些分类器的缺点。
虽然朴素贝叶斯是一种简单有效的机器学习分类算法,但它有一些应该考虑到的局限性和缺点。
朴素贝叶斯。
- 独立性假设:朴素贝叶斯假设所有特征都彼此独立,这在实践中可能并不总是正确的。 如果特征彼此高度依赖,则此假设可能会导致分类精度降低。
- 数据稀疏性:朴素贝叶斯依赖于每个类有足够的训练样本存在,以便准确估算类的先验和条件概率。 如果数据集太小,则估算值可能不准确,并导致分类性能不佳。
- 对不相关特征的敏感性:朴素贝叶斯对所有特征一视同仁,无论它们与分类任务的相关性如何。 如果数据集中包含不相关的要素,则可能会导致分类性能不佳。 不可否认的事实是,数据集中的某些特征比其它特征更重要。
- 无法处理连续变量:朴素贝叶斯假设所有特征都是离散的或有类别的,并且不能直接处理连续变量。 若要将朴素贝叶斯与连续变量一起使用,数据必须离散化,这可能导致信息丢失和分类准确性降低。
- 表现力有限:朴素贝叶斯只能对线性决策边界进行建模,这可能不足以完成更复杂的分类任务。 当决策边界为非线性时,这可能会导致性能不佳。
- 分类不平衡:当类间示例的分布高度不平衡时,朴素贝叶斯可能表现不佳,因为它可能导致有偏差的类先验,和对少数类的条件概率估算不准,如果没有足够的证据,则不会预测分类 — 间歇。
高斯朴素贝叶斯。
高斯朴素贝叶斯共有上述缺点,且还有另外两个;
- 对异常值敏感:高斯朴素贝叶斯假设特征呈正态分布,这意味着极值或异常值会对均值和方差的估算值产生重大影响。 如果数据集包含异常值,这可能会导致分类性能不佳。
- 不适用于具有重尾的特征:高斯朴素贝叶斯假设特征具有正态分布,该正态分布具有有限方差。 如果特征具有较重的尾部(例如柯西分布),则算法可能无法很好地执行。
结束语
为了让机器学习模型在策略测试器上生成结果,需要的不仅仅是训练模型,您还需要追求性能,同时确保最终获得节节高的盈利图。 即使您不一定需要在策略测试器里测试机器学习模型,因为某些模型的计算成本太高而无法测试,但您肯定需要出于其它原因去那里,例如优化您的交易量、时间帧、等等。 在决定以任何模式进行实时交易之前,需要对逻辑进行仔细分析。
此致敬礼。
在我的 GitHub 存储库 https://github.com/MegaJoctan/MALE5 上跟踪此算法的发展和更改
| 文件 | 内容 & 用法 |
|---|---|
| Naive Bayes.mqh | 包含朴素贝叶斯模型类 |
| Naive Bayes theory script.mq5 | 测试脚本 |
| Naive Bayes Test.mq5 | 运用所讨论模型进行交易的 EA |
| matrix_utils.mqh | 包含附加的矩阵函数 |
| metrics.mqh | 包含用于分析 ML 模型性能的函数;如混乱矩阵 |
| naive bayes visualize.py | 依据所用模型的所有自变量绘制分布图的 Python 脚本 |
| gender datasets.csv & weather dataset.csv | 本文中示例的数据集 |
免责声明:本文仅用于教学目的,交易是一种有风险的游戏,希望您知道与之相关的风险。 对于使用本文中讨论的类方法可能造成的任何损失或损害,作者概不负责。请记住伙计们, 资金损失风险必须在您能承受的范围之内。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/12184
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

一切都好,一切都妙,但唯一的问题是,这些指标并不是独立的,它们是同一事物的相互转换。从一个指标的读数可以推导出其他指标的读数,而公式是已知的。
贝叶斯不会做任何事情。
,仅仅下载并在测试器中运行就有点耗费精力。在文章中,我没有找到 "要教学,请按 X "的说明
又是学术方面的东西。
一切都好,一切都妙,但唯一的问题是,这些指标并不是独立的,它们是同一事物的相互转换。一个指标的读数可以用来推导其他指标,其公式是众所周知的
贝叶斯不会做任何事情。
"它 "是如何工作的? ,仅仅下载并在测试器中运行就有点耗费精力。我在 "要训练,按 X "一文中没有找到说明 又是学术方面的东西
我在大学攻读财务规划学位时确实学过概率。
我从未在交易中使用过传统意义上的 "概率 公式"--"概率=有利结果数/结果总数"--来分析概率,尽管我可能应该这么做!
话虽如此,但实际上这就是标准偏差的意义所在,因为它提供了在给定时间范围内交易与均值的偏差(因此也提供了反转或继续交易的概率)。(例如,如果价格接近 SD1,则返回均值的概率为 68%;如果达到 SD2,则概率为 95.5%;如果达到 SD3,则概率为 99.7%),因此,在衡量交易头寸何时可能转向相反方向时,标准差非常方便,尤其是在使用标准差通道等工具时。
不过,当涉及到神经网络分析时,我肯定能看到概率在神经网络训练和反思中的可能应用!