
Брутфорс-подход к поиску закономерностей (Часть II): Погружение

Введение
Я решил продолжить тему, затронутую в предыдущей статье, и провести глубокий анализ нескольких валютных пар, используя модифицированную версию своей программы. В этой связи хочу поблагодарить пользователя Aleksey Vyazmikin за вклад в развитие идеи. Советы Алексея очень помогли в техническом плане и были толчком для развития идеи. В следующей статье я продолжу работу в этом направлении и обеспечу аудиторию гораздо более интересными данными и результатами. Считаю, что очень важно показать и рассказать насколько эффективен анализ той или иной валютной пары в глобальном масштабе в целом, а также показать различия в будущем при анализе временных промежутков максимальной и минимальной длительности. Конечно, ввиду того что мое время ограничено, да и вычислительные возможности тоже, я смог осветить лишь несколько валютных пар и всего 1 таймфрейм, но я считаю что этого вполне достаточно для первого знакомства с глобальными закономерностями. При анализе данных дополнительно буду использовать и данные предыдущей статьи.
Почему на мой взгляд эта тема настолько интересна?
В итоге для любого программиста советников на MetaTrader 4 и MetaTrader 5 все сводится к бесчисленным строкам кода, бесчисленным тестам, оптимизациям, бэк- и форвард проверкам, и в большинстве случаев мы получаем не то, что хотим видеть. Какой то части программистов этот расклад надоедает и им становится скучно. Процесс исследования и поисков превращается в рутину. Ведь если работа не приносит должного морального удовлетворения, не говоря уже о деньгах, то через какое-то время вы бросите ее. Так же и тут. Для меня наступил момент, когда я захотел распрощаться с рутиной и начать автоматизировать действия, которые на самом деле может с успехом исполнять машина. У машины нет эмоций и она идеальный работник в отличие от меня. Конечно, у машины нет такой широты мышления как у человека, но зато у нее есть куча вычислительных мощностей, и те же вещи, которые может сделать сложнее и оригинальнее человек, она может сделать проще, но быстрее чем человек. У меня был выбор — начать писать свою архитектуру нейросети способную к эволоюции или начать с простейшего подхода к решению задачи. Я остановился на данном подходе. Несмотря на всю просто, тут есть простор для творчества, есть интерес какой-то, в отличие от простого программирования MQL продуктов. Почему не работать над универсальным шаблоном и просто не улучшать его, добавляя постепенно нужный функционал? Начать можно с простого шаблона, а дальше создавать новые шаблоны под конкретный принцип работы. Таким образом мы можем избавиться от скучной рутины и пойти дальше в своем развитии. Воистину, человеческая лень — двигатель прогресса ).
Новая версия программы брутфорса и список ее изменений
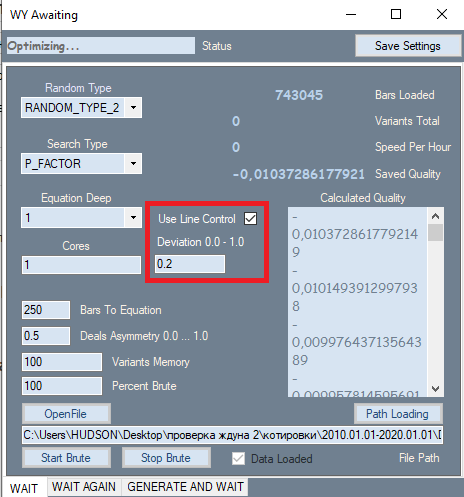
В программе было лишь одно, на первый взгляд незначительное, изменение, оно выделено красной рамкой на рисунке. Эта настройка взята со второй вкладки, где показала себя с лучшей стороны. Причина, по которой я добавил данную настройку, на самом деле оказывает очень сильное влияние на качество итоговых результатов. Дело в том, что при анализе на первой вкладке все результаты изначально сортировались по показателю качества. Профит-фактор либо математическое ожидание в пунктах использовались в качестве критерия качества. Но программа не позволяла оценить форму графика, в качестве критерия формы я использовал фактор линейности (схожесть с прямой), что избавляет нас от необходимости визуальной проверки каждого варианта. Если хорошенько подумать, то можно прийти к выводу, что более прямые и ровные графики в итоге имеют большую вероятность дать качественный вариант на второй вкладке, а также уменьшает количество вариантов, которые будут отброшены аналогичным фильтром на второй вкладке. Для вычисления этого показателя нужен второй прогон. В случае активности этого фильтра скорость брута понижается примерно в 2 раза, но нам то важна не скорость, а суммарное качество полученных первичных результатов, ведь от их качества зависит все, что будет дальше.
Кроме введенного фильтра был изменен и сам полином. Теперь полином принимает в качестве аргументов не только Close[i]-Open[i] значения конкретных баров, а еще следующие величины:
- Close[i]-Open[i]
- High[i]-Open[i]
- Low[i]-Close[i]
- Low[i]-Open[i]
- High[i]-Close[i]
Теперь получается, что в формуле присутствуют все ценовые данные конкретного бара, в отличие от предыдущей версии программы. Конечно сложность полинома от этого сильно возрастает, да и, как следствие, скорость брута падает, зато мы теперь можем подбирать более качественные и эффективные формулы рынка, при условии наличия достаточных вычислительных мощностей. Можно конечно придумать другие переменные с участием этих данных, но при использовании этих величин в полиноме получается реализация и тех величин, которые могут являться линейной комбинацией представленных, к примеру
- C1*(High[i]-Close[i]) + C2*(Low[i]-Close[i]) = NewQuant
- если C1 = 1 и C2 = -1
- NewQuant = (High[i]-Close[i]) - (Low[i]-Close[i]) = High[i]-Low[i]
- в остальных случаях
- NewQuant = (C1-C3)*(High[i]-Close[i])+(C2+C3)*(Low[i]-Close[i]) + C3*((High[i]-Close[i]) - (Low[i]-Close[i])) = (C1-C3)*(High[i]-Close[i])+(C2-C3)*(Low[i]-Close[i]) + C3*(High[i]-Low[i])
Иначе говоря, из линейной комбинации переменных, которые в свою очередь состоят из линейных комбинаций других переменных, можно составить новые переменные, даже не включая их в базовую формулу, и самым верным шагом будет постараться не включать те переменные, которые могут образоваться из других, которые уже есть в формуле. Они появятся в процессе подбора коэффициентов, в зависимости от значений самих коэффициентов.
Новый полином будет гораздо сложнее в итоге:
- Y = Сумма(0,NC-1)( C[i]*Вариант произведения(x[1]^p[1]*x[2]^p[2]...*x[N]^p[N]) )
- Сумм(0,N)(p[i])=MaxPowOfPolinom
- NC - общее количество слагаемых в полиноме, что равно количеству подбираемых коэффициентов
где x[i] - аргументы которые принимает полином, p[i] - степень в которую мы возводим данный аргумент. Суммарная степень всех составляющих множителей не должна превышать то число, которое мы разрешаем нашему полиному, потому как ни один компьютер не осилит такие сложные разложения. Лично я почти всегда использую 1 степень, в крайнем случае 2 или 3, когда количество баров для формулы близится к минимуму. Но истина такова, что использование более старших степеней неэффективно даже на серверах. Недостаточно вычислительной мощности.
Ниже приведены варианты аргументов. В конечную сумму входят в итоге все возможные комбинации произведений:
- x[i] =Close[i]-Open[i]
- x[i] =High[i]-Open[i]
- x[i] =Low[i]-Close[i]
- x[i] =High[i]-Open[i]
- x[i] =High[i]-Close[i]
Еще хотелось бы сказать, почему все пляски вокруг этого пресловутого полинома. Дело в том, что любая система в итоге сводится к набору условий, одно условие или несколько, это неважно, потому что условия — это логическая функция. Набор условий в конечном итоге можно преобразовать в логическое выражение, которое дает либо истину, либо ложь. Интерпретировать такой сигнал нельзя, кроме как Да или Нет, невозможно определить насколько сильный сигнал, невозможно его отрегулировать. Конечно, если в качестве сигнала вы используете несколько индикаторов, то вы можете отдельно отрегулировать входные параметры этих индикаторов, и в итоге это приведет к изменению итогового логического выражения, или к изменению сигнала, что в свою очередь повлияет на торговлю. Но я считаю, что это крайне неудобно хотя-бы по той причине, что меняя тот или иной параметр конкретного индикатора, мы не будем знать как это повлияет на торговлю.
Основной идеей использования данного подхода была простота и эффективность. Почему именно такой подход ? Существует несколько плюсов:
- Единственность оптимизируемой функции
- Зависимость силы сигнала от значения функции
- Простота в использовании
- Единственным оптимизируемым параметром становится значение полинома
Самое важное в том, что нам не нужно подбирать количество условий, их вид. Все потому, что мы изначально свыкаемся с мыслью о том, что вместо поиска бесконечного множества условий мы можем свести все эти условия к единственной функции, которая на выходе даёт либо положительное дробное, либо отрицательное дробное число. В зависимости от достоверности той или иной функции возможно будет требовать более сильного сигнала по модулю. В некоторых формулах это приведёт к возможности масштабирования. Под масштабированием я понимаю возможность усиления сигнала, при уменьшении количества сделок.
Вообще говоря мои исследования, как думаю и у других людей, приводят к одному единственному выводу. Стремление усилить входной сигнал неизбежно порождает уменьшение количества сделок на фиксированный отрезок времени. Говоря простым языком, для любой функции, где неизбежно присутствует случайная составляющая, всегда присутствуют точки с более предсказуемым исходом, чем другие точки. Если наша функция достаточно эффективна, то она может достигать определённых показателей предсказуемости при увеличении требований к сигналу от этой функции. Так, конечно, происходит далеко не с каждой функцией, что удовлетворила нашим первичным требованиям, но чем более жёсткие эти первичные требования, тем более высоки математические ожидания показателей прибыльности тех вариантов формул, которые нам удастся найти, используя перебор коэффициентов. Это будет справедливо и для градиентного бустинга, и для других методов поиска закономерностей, для нейросетей тоже.
Очень многое зависит от того, какова выборка данных. Чем меньше выборка, тем больше шанс получить случайный результат. Под случайным результатом понимается результат, который не работает, либо работает крайне неэффективно, если тестировать итоговую систему на глобальной истории символа, на котором производился поиск закономерности.
Постараемся ответить на вопрос, как же зависит качество итоговой торговой системы в будущем от размера анализируемого участка и количества трудозатрат на поиск этой системы. Сначала определим формулу математического ожидания количества найденных стратегий за фиксированный промежуток времени:
- Mn(t) = W(t,F)*Ef(T,N,L)
- Mn - математическое ожидание количества найденных стратегий? удовлетворяющих выставленным требованиям
- W(t,F) = F*t - итоговое количество перебранных вариантов за единицу времени
- Ef(T,N,L) = ? - эффективность перебора, зависящее от длины участка, вида котировки, требуемого количества закрытых ордеров и требуемого фактора линейности, если он учитывается при поиске (данная величина эквивалентна вероятности того, что показатели текущего варианта примут необходимые и достаточные значения)
- N - минимально допустимое количество сделок, которое нас устроит для нашего теста
- L - максимально допустимый фактор линейности (как дополнительный критерий контроля)
- F - частота перебора вариантов стратегий
Крайне тяжело определить вид функции Ef, но можно примерно оценить как она будет выглядеть и какими свойствами обладает:
")
Для того чтобы иметь возможность изобразить многомерную функцию на плоскости, необходимо зафиксировать все ее аргументы какими то числами, кроме одного аргумента, по которому строим сам график. В нашем случае интересна переменная T, которая означает длительность анализируемой выборки по времени, если учесть что мы анализируем какой-то один таймфрейм. Если отбросить это допущение, то в качестве T можно взять размер выборки, от этого внешний вид графиков не изменится. Естественно, что нам интересно как будут влиять и остальные 2 аргумента на вид графика, я все изобразил на рисунке. Чем больше ордеров мы хотим в итоговом варианте, тем меньше мы найдем систем, удовлетворяющих нашим требованиям, просто потому, что гораздо легче найти систему с меньшим количеством ордеров. То же соображение относится и к фактору линейности(отклонение от прямой), с той лишь разницей, что более лучший фактор линейности тот, что меньше (стремится к нулю).
Если не фиксировать понятие качества системы, ведь эта величина может быть как профит-фактором, так и математическим ожиданием, то можно так же ввести понятие максимального качества найденной системы. Точно так же примерно можно описать от чего оно зависит:
- Mq=Mq(T,N,S)
- S - выбранная конфигурация формулы
Иначе говоря, максимально возможное качество стратегии напрямую зависит от эффективности нашей формулы, а также от наших требований и сложности участка. При этом мы все так же предполагаем, что начало участка фиксировано, и каждая вариация точки начала обучения уникальна и дает уникальные стартовые параметры. Иначе говоря, выбрав разную дату старта нашего отрезка обучения, мы получим различную эффективность и прочие параметры, как и итоговое качество полученных систем.
Можно также прийти к пониманию того, что у каждого вида качества есть максимальное значение, например, у профит-фактора это бесконечность, но я не люблю использовать этот показатель для анализа ввиду того, что он не ограничен сверху, и какие-то графические модели с его участием будут тяжелее восприниматься. Поэтому я использую P_FACTOR, собственный аналог этой величины, который я использую вместо оригинального, он ничем ему не уступает, только лежит в диапазоне [-1,1] .
- P_FACTOR=(Profit-Loss)/(Profit+Loss)
У этой величины максимум равен 1, а значит, с этим показателем гораздо удобнее работать. В данной связи можно ввести функцию, которая описывает максимум этого показателя в зависимости от T (выбранного участка и его выборки).
- Mx=Mx(T)
Если показателем или критерием качества выбран P_FACTOR, то Mx(T)=1, если к примеру математическое ожидание, то вид этой функции неизвестен, но известно, что Mx'(T) > 0 , на всей положительной части оcи T. То есть производная положительна в любой точке, что говорит о том, что график все время возрастающий.
Для профит фактора все это будет выглядеть так:

Тут для примера просто верхняя граница профит фактора и 2 графика, символизирующие 2 разных формулы, с разными требованиями. На графике лучше та формула, что имеет лаймовый цвет, так как она гораздо меньше подвержена затуханию качества при стремлении "T" к бесконечности.
Для математического ожидания это все будет выглядеть так:

Здесь как и в предыдущем графике 2 варианта символизирующие 2 разные формулы с разными требованиями, только еще присутствует Mx(T), который выполняет роль асимптоты, в том плане, что Mq(T,N,S) не в состоянии преодолеть этот барьер. Идеальная Mq(T,N,S) сольется с графиком Mx(T) и будет обозначать, что мы нашли "Грааль". Этого, конечно, в реальности никогда не случится, но это важно для понимания. Я считаю, что для правильного отношения к рынку это очень важно, если конечно вы действительно хотите разобраться в том, что такое рынок и вам дорого свое время.
На форексе, как и на любой другой бирже, наиболее правильно и точно возможно оперировать только понятиями теории вероятностей. Даже напишу ниже несколько основных правил математического анализа на форексе:
- Практически все величины не фиксированы и заменяются их математическими ожиданиями
- Математические ожидания величин от большей выборки стремятся к результату глобальной выборки
- Используйте вероятности почаще
Достоверность данных участка не что иное, как показатель выборки. Чем больше выборка, тем обширнее набор входных данных, тем справедливое итоговая формула. Дело в том, что при стремлении выборки к бесконечности итоговый результат будет стремиться к фиксированной предельной величине.
Изменения в шаблоне и зачем они нужны?
Раз логика работы усовершенствована, то необходимо будет править функции в шаблоне для того, чтобы они работали правильно и принимали новые параметры, реализация этих функций идентична как в программе, так и в коде шаблона, иначе это все попросту не будет работать. Исходные функции были заточены под одну величину, но добавились еще 4, поэтому придется их доработать. В первую очередь эти изменения должны давать более качественные формулы, насколько качественные оценить не представляется возможным, но должно быть очевидно, что станет только лучше. Чем больше данных используется в формуле, тем выше ее возможности по поиску.
Во время написания статьи я нашел недоработку в своем коде, связанную с тем, что комбинации множителей могут повторяться, просто порядок следования этих множителей хаотичен в виду особенностей построения функции, которая реализует многомерный полином. Эта функция строит дерево вызовов, но не может проконтролировать перестановки элементов местами. Избежать этой ситуации можно двумя путями:
- Контролировать все возможные перестановки множителей
- Скомпенсировать количество повторяющихся множителей в формуле, поделив общий коэффициент на их количество
Лично я выбрал второй вариант. Он не очень оригинален, и минус в том, что средний коэффициент будет стремиться к 0.5, но хотя бы эти множители будут небесполезны. Для статьи я использовал полином 1 степени, на который эта ошибка не влияет, на счет этого можно не волноваться. Посчитать количество комбинаций для множителя с фиксированной суммарной степенью не составит труда:
- Comb=n!/(n-k)!
- n - количество возможных независимых подмножителей
- k - суммарная степень итогового слагаемого
Ниже реализация этой формулы в коде:
double Combinations(int k,int n) { int i1=1; int i2=1; for ( int i=n; i<n-k; i-- ) i1*=i; for ( int i=n-k; i>1; i-- ) i2*=i; return double(i1/i2); }
А вот так преобразилась главная функция итогового полинома, изменения связаны с частью для одномерного полинома, ведь теперь мы зависим не от 1 параметра бара, а от 5. Конечно, исходных массивов 4, но в голом виде ценовые данные нельзя использовать как просто данные, а необходимо преобразовать их в какие-то более гибкие величины, коими является разница соседних цен, а соседние цены могут быть как открытиями баров, так и закрытиями, какими угодно, лишь бы в итоговой квантованной величине содержалась разница близких цен.
double Val; int iterator; double PolinomTrade()//полином для торговли { Val=0; iterator=0; if ( DeepBruteX <= 1 ) { for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(Close[i+1]-Open[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(High[i+1]-Open[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(Open[i+1]-Low[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(High[i+1]-Close[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(Close[i+1]-Low[i+1])/Point; iterator++; } return Val; } else { CalcDeep(C1,CNum,DeepBruteX); return ValStart; } } ///фрактальный подсчет чисел double ValW;//число куда умножаем все(а потом его прибавляем к ValStart) uint NumC;//текущее число для коэффициента double ValStart;//число куда суммируем все void Deep(double &Ci0[],int Nums,int deepC,int deepStart,double Val0=1.0)//промежуточный фрактал { for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(Close[i+1]-Open[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(Close[i+1]-Open[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(High[i+1]-Open[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(High[i+1]-Open[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(Open[i+1]-Low[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(Open[i+1]-Low[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(High[i+1]-Close[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(High[i+1]-Close[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(Close[i+1]-Low[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(Close[i+1]-Low[i+1])*Val0/Point; NumC++; } } } void CalcDeep(double &Ci0[],int Nums,int deepC=1) { NumC=0; ValStart=0.0; for ( int i=0; i<deepC; i++ ) Deep(Ci0,Nums,i+1,i+1); }
Небольшому изменению подверглась и функция для вычисления размера массива коэффициентов. Просто теперь цикл в 5 раз длиннее:
int NumCAll=0;//размер массива коэффициентов void DeepN(int Nums,int deepC=1)//промежуточный фрактал { for ( int i=0; i<Nums*5; i++ ) { if (deepC > 1) DeepN(Nums,deepC-1); else NumCAll++; } } void CalcDeepN(int Nums,int deepC=1) { NumCAll=0; for ( int i=0; i<deepC; i++ ) DeepN(Nums,i+1); }
Все эти функции нужны для реализации итогового полинома, ООП здесь избыточно, для построения дерева вызовов лучше использовать подобные функции, особенно для формул, которые невозможно написать в явном виде, многомерные разложения тому пример. Понять их логику довольно сложно, но возможно. Аналоги этих функций реализованы и внутри программы на C#. Советники, приложенные к статье, к сожалению, не будут иметь внутри этого кода, будет предыдущий вариант, но он вполне работоспособен, хоть и довольно коряв. Программа находится на стадии прототипа, многое еще не продумано, да и многие детали опущены, в дальнейшем все будет приведено в презентабельный вид. Пока что программа не годится для анализа глобальных закономерностей на обычных ПК, но я ее постоянно модернизирую, и скоро ее функциональность сильно вырастет. Очень много недочетов еще и на стороне моей программы, но постепенно ошибки выявляются и устраняются. Программа приходит к хорошей функциональности.
Анализ найденных закономерностей
Опять же в связи с тем, что мои вычислительные возможности ограничены, как и время, пришлось ограничить объем данных, но я думаю, его все равно будет достаточно для каких-то выводов. В частности, для анализа глобальных закономерностей пришлось использовать только часовые графики, и только ограниченное время для анализа. Все тесты будут проведены в MetaTrader 4. Все дело в том что математическое ожидание найденных закономерностей находится на уровне спреда, а в MetaTrader 5 даже при использованиии опции Собственные настройки символа тестирования тестер применяет спред, который не меньше того значения, который был зафиксирован на истории. Значение корректируется исходя из реальных тиковых данных текущего брокера и спреда на выбранном участке. Это сделано для того чтобы уберечь пользователя от слишком оптимистичных результатов тестирования. Мне необходимо было абстрагироваться от этих механизмов, для чего и был выбран тестер MetaTrader 4.
Начну с глобальных закономерностей. Их математическое ожидание получилось всего в районе 8 пунктов. Это обусловлено тем, что было взято 50 свечей для формулы, и проверено всего около 200 000 вариантов на первой вкладке, для каждой валютной пары и всего на 1 ядре. Был бы сервер хороший, было бы проще намного. Пока так. Следующая версия программы будет менее зависима от вычислительных мощностей. В данной ветке я хочу сосредоточиться не столько на том, какое математическое ожидание в пунктах у результатов, а на том, как влияют его показатели на то, как он себя поведет в будущем.
Начнем с пары EURUSD H1. Все это тестировалось на участке 2010.01.01-2020.01.01 для того чтобы иметь шанс найти глобальную закономерность:

Результаты не больно-то радуют глаз, но это все, что удалось выжать из пары в заданный промежуток времени. Можно увидеть глобальную закономерность, хоть она и не так ярко выражена, учитывая профит-фактор, но можно увидеть, что что-то рабочее тут есть. Для брута брал 50 свечек в формуле. На самом деле далеко не самый хороший результат, который можно получить, но он нужен. Почему — будет понятно дальше. Протестируем этот же участок на форвард периоде 2020.01.01-2020.11.01, чтобы понять, как он будет вести себя в будущем:

Это не то, чего я ожидал, но и это вполне объяснимо. Оказалось, что данного анализа недостаточно для того, чтобы можно было выиграть что-то на продолжении закономерности. Да и вообще, мне кажется, уж если анализировать глобальные закономерности, то только исходя из расчета, что это будет работать еще по крайней мере несколько лет, иначе такой анализ вообще не имеет смысла. В начале графика видно, что закономерность продолжает работать, но через полгода фактически инвертируется, в целом такого анализа может хватить для торговли на несколько месяцев, если конечно найти достаточно хорошие параметры исходного теста. В данном случае я анализировал по величине P_Factor. Эта величина аналогична Profit Factor, с тем лишь отличием что принимает значения [0...1] . 1 - 100% прибыли. На первой вкладке максимум этого показателя был около 0.029 . Соответственно, среднее значение всех найденных вариантов было около 0.02, что и дало подобный результат.
Следующий график EURCHF:

Максимальный результат для вариантов графиков на первой вкладке данной программы был в районе 0.057, его степень предсказуемости в 2 раза выше, чем у предыдущего графика, что оказало влияние и на итоговый Profit Factor, который фактически на 0.09 выше чем у предыдущего. Посмотрим, повлияет ли улучшение глобальных показателей на форвард периоде:

Видно что закономерность продолжается весь год, может быть не так ровно, да и профит-фактор ниже, но тем не менее уже можно сделать предварительные выводы. На самом деле профит фактор ниже из-за того, что на глобальном тесте были довольно большие участки резкого прироста баланса, они и увеличили итоговый профит фактор. А на ближайших годах если протестировать, уверен, что он будет практически такой же. Предварительный вывод такой, что повышение качества и внешнего вида графика повлияло на его работоспособность в будущем, не важно какая это валютная пара, а важно, что в данном случае наши настройки были более применимы именно к этой валютной паре и это дало результат. Причину волн на графике, если присмотреться, можно увидеть на глобальном тесте, там как раз последние годы сильно увеличились колебания баланса и это просто их продолжение.
Переходим к графику USDJPY:

График самый безобразный из всех, посмотрим что на форвард периоде:

Вроде как в плюс вышел, но вот вторая половина очень похожа на вторую половину первого графика EURUSD H1, так же движение вверх в начале, а потом разворот и ровное движение вниз практически по прямой. Собственно выводы те же, что и у первого графика. Недостаточное качество итогового результата. Но тем не менее можно рассчитывать на пару месяцев прибыльной торговли, используя эту закономерность, если бы конечно было достаточно хорошее математическое ожидание и профит фактор.
Последний график USDCHF:

Не густо, но как есть, теперь поглядим на форвард период:

Картина мне видится такой же, как и у других графиков, кроме EURCHF. Работоспособность сохраняется до середины года, а дальше разворот и инверт закономерности.
Предварительные выводы можно сделать такие:
- Очевидно, что график EURCHF оказался лучшим
- EURCHF превзошел всех как по участку обучения, так и по форвард тесту
- На всех графиках закономерность работает до середины года, кроме EURCHF
Из всего этого можно сделать вывод о том, что показатели качества на участке обучения напрямую влияют на то, что мы увидим на форвард периоде, в частности, увеличение профит-фактора итогового результата может свидетельствовать о том, что результат гораздо менее случайный, чем на других графиках, что может говорить о успешном нахождении глобальной закономерности. Есть такая поговорка: "в каждой шутке есть доля шутки". Это можно перефразировать для форекса или любого другого рынка :"в каждой закономерности есть доля закономерности". Чем сильнее показатели теста, тем эта доля и выше.
Теперь я попробую изменить размер выборки. Возьму 1 год. Промежуток 2017.01.01-2018.01.01 EURJPY H1. И посмотрю как себя будет вести закономерность на месяц в будущее:

График выглядит не очень, но итоговый профит фактор и математическое ожидание конечно выше чем у вариантов на 10 лет. Выборка в 12 раз меньше чем первоначальные варианты, тем не менее эти данные тоже данные, и не стоит их игнорировать.
Форвард период возьму на месяц в будущее. Промежуток 2018.01.01-2018.02.01:

Этот вариант я взял для примера, для того чтобы были более понятны рассуждения, которые будут дальше. Видно, что практически сразу происходит инверт закономерности. К сожалению, не удалось предоставить больше данных. Очень много времени занимают вычисления и настройка ПО. Но этой информации должно хватить для первого анализа.
Анализ информации
После того как советники протестированы, можно сделать некоторые выводы:
- Построение роботов, реализующих глобальные закономерности и имеющих достаточную длительность работы, возможно с использованием простого перебора чисел
- Длительность работы в будущем напрямую зависит от размера выборки данных
- Длительность работы напрямую зависит от качества теста на участке обучения
- При тестировании на форвард периоде на всех графиках работоспособность для глобальных закономерностей сохраняется по крайней мере 2-3 месяца
- Вероятность найти закономерность, которая будет работать еще хотя-бы несколько лет, стремится к максимуму при стремлении качества итогового результата на участке брута к 100 %
- Для поиска глобальных закономерностей разные настройки работают по разному на разных валютных парах
Что до локальных закономерностей, например месяц-год, тут все совсем иначе. В прошлой статье я анализировал локальные закономерности, но без новшеств, которые привнесла эта версия программы. Любые модернизации позволяют более ясно взглянуть на те же вопросы, отсеяв лишнюю информацию. В целом относительно локальных закономерностей:
- Всегда следует играть на смену закономерности
- Можно применять мартингейл, но аккуратно
То есть чем больше выборка, тем больше в будущем она сохранит работоспособность, и наоборот чем меньше выборка то тем быстрее в будущем наступит инверт закономерности, это конечно при условии отсутствия форвард оптимизации, которую к слову я думаю прикручу таки, но не в следующей статье, пока есть более приоритетные задачи. При этом инверт закономерности в случае короткого участка наступает гарантированно. Из всех этих мыслей следуют выводы которые диктуют 2 вида торговли:
- Эксплуатация глобальных закономерностей
- Эксплуатация локальных закономерностей
При этом следует понимать что в первом случае, чем больший участок для обучения берем, тем дольше это все будет работать. Но все равно нужно помнить, что лучше проводить поиски новых формул каждые 2- 3 месяца. В случае же локальных закономерностей следует производить поиски каждую неделю, пока рынок находится в заморозке. Качество результатов будет небольшое, но зато вам не надо волноваться за результат, вы будете знать, что хоть какую-то прибыль да получится выжать.
Теперь я попытаюсь обобщить все полученные данные в результате своего исследования закономерностей разных масштабов. Для этого, по моему мнению, стоит ввести некую функцию, которая отражает математическое ожидание прибыли конкретного ордера, а также функцию, отражающую профит-фактор, исходя из того факта, что нам неизвестно будущее, или известно, но частично. При желании можно ввести функции, характеризующие и иные менее важные величины. Пространством событий или случайной величиной, как хотите, будут являться все возможные варианты событий развития будущего. В данной связи, мы только лишь знаем:
- Существует бесчисленное множество возможного развития событий для "F"-го бара в будущее (открылся на нем ордер или не открылся)
- Для всех вариантов развития будущего, в которых на конкретном баре открылся ордер, у этого ордера будет математическое ожидание в пунктах и профит фактор (представьте, что вы проводите тест на одном баре, только следующие бары всегда разные для каждого ордера)
- Для каждой формулы все эти величины будут различны
- Для участков с разными датами начала будущего (начало будущего совпадает с концом участка обучения) и разной длительностью участка обучения (что эквивалентно разной дате старта участка обучения) итоговые искомые параметры примут уникальные значения
Все эти утверждения можно трансформировать в математические формулы. Языком математики это будет написано так:
- MF=MF(T,I,F,S,R) — математическое ожидание ордеров на конкретном баре в будущем.
- PF=PF(T,I,F,S,R) — профит фактор ордеров на конкретном баре в будущем.
- T — длительность участка обучения (в данном случае размер выборки или количество баров что то же самое)
- I — дата конца участка обучения
- F — номер бара в будущее, если считать от даты конца обучения
- S — уникальный полином или алгоритм (в случае если закономерность найдена руками или программированием нового робота)
- R — результаты достигнутые с использованием конкретного полинома или стратегии (иначе говоря, насколько хорошо проведена работа по оптимизации его сигнала), они включают как количество сделок на участке обучения, так и такие показатели, как математическое ожидание, профит-фактор и иные параметры.
Исходя из данных, полученных при брутфорсе на разных инструментах и разных датах, я могу нарисовать, как примерно будут выглядеть функции, которые я ввел выше на графике, если в качестве аргумента использовать "F":

На данном графике 2 уникальных варианта стратегий, которые обучались на разных участках с использованием разных настроек и достигнувшие разных результатов. Очень важно понимать, что таких вариантов бесчисленное множество, но все они отличаются длительностью и качеством работы исходной закономерности. Еще очень важно понимать, что после всегда происходит инверт закономерности. Это правило может не работать только для очень сильных закономерностей, и даже для них всегда есть риск, что график развернется, пусть даже через лет 5, но он развернется. Здесь самыми живучими будут те формулы, которые были найдены из самой большой по размеру выборки. А если они найдены руками и изначально в эти формулы вкладывалась какая-то теория, то эти формулы в перспективе могут работать и до бесконечности. В случае брутфорса или иных методов машинного обучения у нас нет никаких гарантий. Все что у нас есть — это оценка времени работоспособности, которую можно произвести только на основе статистических данных. С помощью моей программы такой анализ возможен, но недоступен для одного человека в силу ограниченного времени и вычислительных мощностей.
Что дальше ?
Анализ глобальных закономерностей показал что мощности обычного компьютера недостаточно для глубокого и качественного анализа больших выборок длинной скажем лет 10 и выше, а ведь для качественного поиска нужно брать очень большие выборки. Возможно если погонять программу пару месяцев на сервере то мы и найдем один или 2 хороших варианта, но это не задача для стационарного компьютера уж точно. Следовательно нужно повышать эффективность и одновременно повышать скорость перебора вариантов. Дальнейшее развитие программы мне видится так:
- Добавление возможности анализа фиксированных окон серверного времени
- Добавление возможности анализа в фиксированные дни недели
- Добавление возможности рандомной генерации временных окон
- Добавление возможности рандомной генерации массива разрешенных дней недели для торговли
- Совершенствование второй ступени анализа(вкладка оптимизации), в частности реализация многоядерных вычислений и исправление ошибок оптимизатора.
Перечисленные изменения по задумке должны очень сильно повысить как скорость программы, так и вариативность и качество найденных вариантов, и уже, наконец, обеспечить наличие более-менее нормального инструментария для анализа рынка.
Заключение
Я надеюсь, данная статья привнесла какую-то пользу читателю. Как мне кажется, очень важно было коснуться глобальных закономерностей в статье, сделать это было крайне трудно, учитывая что мощи программы еще недостаточно для подобного рода анализа. Был бы у меня хороший сервер ядер на 30, это не составило бы труда. По хорошему нужно было тратить на этот анализ в несколько раз больше времени, может и на порядок выше.
Надеюсь, в будущем удастся нарастить вычислительные мощности. В следующей статье будет интереснее. Была и кое-какая математика для общего понимания, ведь без этого понимания невозможен эффективный анализ даже с использованием полезного софта, я не говорю уже о ручном переборе, оптимизации.
В целом суть статьи была в том, чтобы дать информацию тем, кому пока не удалось даже руками достигнуть даже таких крайне скромных результатов, чтобы люди получили хоть какое-то понимание, на основе каких соображений стоит заниматься написанием роботов, и стоит ли вообще это все вашего времени.
Хочу еще на последок сказать, что мне представляется, что не так важно, как найдена закономерность, руками вы ее нашли или с помощью машины. Если закономерность имеет определенные показатели прибыльности, то мы в полной мере можем считать ее рабочей. Всё равно, так или иначе, определенные параметры закономерности дают нам некие прогнозы, хотя бы на минимальное время в будущее, но этого времени вполне хватит для того, чтобы заработать. Также не стоит думать, что если вы нашли какую-то рабочую закономерность, как вам кажется, и что она будет работать и дальше. Чтобы это утверждать, вам понадобится очень большая выборка с очень хорошими показателями торговли по всей выборке и достаточным количеством ордеров относительно размера этой выборки. Одно дело найти закономерность, а другое — оценить предположительное время ее работы в будущем. Этот вопрос краеугольный, на мой взгляд. Какой смысл искать закономерность, если нет понимания, сколько она еще будет работать и насколько качественно. Да и я решил поделиться со всеми своей программой, она будет в архиве. Вопросы по настройке можете задавать в ЛС.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Использование электронных таблиц для построения торговых стратегий
Использование электронных таблиц для построения торговых стратегий
 Продвинутый ресемплинг и выбор CatBoost моделей брутфорс методом
Продвинутый ресемплинг и выбор CatBoost моделей брутфорс методом
 Разработка самоадаптирующегося алгоритма (Часть I): Поиск базовой закономерности
Разработка самоадаптирующегося алгоритма (Часть I): Поиск базовой закономерности
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Согласен, но мы же с вами умнее чем большинство ) . Мы не будем лезть в толкучку ). Вот посмотрите на графики закономерностей, по сути это толкучка, а мы можем быстренько что нибудь урвать и слинять пока нас не затоптали, а можем посидеть на заборе и дождаться когда все начнет идти в обратную сторону, и тогда тоже можем урвать немножко и снова выскочить. Только так и работает)) . По чуть чуть и аккуратно можно, а как только начинаем жадничать мы тут же становимся частью толпы
А ещё мы всех красивей и моложе) Ну ладно, просто красивей)
Наверное, больше уповаю на то, что из-за неэффективности реальных рынков есть моменты (состояния рынка), когда правым оказывается именно большинство. Соответственно, вероятность выигрыша возрастает. Правда при этом возрастает и величина возможного проигрыша в случае ошибки (хотя её вероятность и уменьшается).
А ещё мы всех красивей и моложе) Ну ладно, просто красивей)
Наверное, больше уповаю на то, что из-за неэффективности реальных рынков есть моменты (состояния рынка), когда правым оказывается именно большинство. Соответственно, вероятность выигрыша возрастает. Правда при этом возрастает и величина возможного проигрыша в случае ошибки (хотя её вероятность и уменьшается).
Тут надо оперировать математическим ожиданием выйгрыша ) это еще как отдельный инструмент манипуляции игроками, дают им чуть чуть выйграть мелкими сделками а потом ловите все жирного лося ) . На психологическом уровне такой проигрыш даже легче переносится мол вот у нас 10 выйгрышей подряд и один лось который все съел )) а дак это просто не повезло, "себя убеждаем в том что такого лося не будет потому что мы повелители рынка" )), или щас мартина включим и полюбому отыграемся ))) . По этому толпа всегда в минусе будет ) а мы при должной сноровке это и должны абузить
!!! А можно всех поименно узнать?
Я старый человек. Начинал торговать на Форекс лет пятнадцать назад. Сейчас, если поверхностно поискать информацию о Форекс, то вам втюхают примерно такое: " На рынке Forex нет организации, которая бы им управляла. А где же находится центральный офис Форекс? У рынка Forex нет центрального офиса и быть не может. Сделки заключаются на межбанковском рынке непосредственно между продавцом и покупателем. Так же есть другой вариант, когда сделки заключаются брокерскими компаниями. Итак, центральный офис Форекс – не существует, рынок Форекс самоуправляемый и децентрализован. Как правило, трейдинг на рынке Форекс происходит при помощи посредников – брокерских компаний, которые предоставляют трейдерам необходимые инструменты для работы. Вот говоря о таких компаниях, можно подразумевать центральные офисы и филиалы. Представительства и филиалы подобных организаций рассредоточены в различных странах. "
А в то время, когда я начинал, еще попадалась информация о истории возникновения Форекс, компании или группе компаний - первом владельце Форекс, в каком году и кому он был перепродан. Очевидно речь шла о первой или самой большой площадке, так как спустя несколько лет попадалась информация о том что Форекс состоит из примерно пяти независимых основных площадок и они перечислялись. Существует небольшое различие в курсах на этих отдельных площадках. И существуют компании, которые специализируются на арбитражных операциях между этими площадками - это их бизнес - что способствует нивелированию разницы в курсах. Меня Форекс интересовал только с практической стороны как трейдера, поэтому детали такой информации в голове не задержались.
Если вас это действительно интересует, а не просто по тролить меня, дерзайте, ищите.
Вышла новая статья Насильственные методы поиска паттернов (часть 2): в деталях:
Автор Евгений Ильин