
Брутфорс-подход к поиску закономерностей

Введение
В данной статье мы будем искать закономерности на рынке, создавать советников на их основе и проверять, как долго эти закономерности сохраняют работоспособность и вообще, сохраняют ли они ее. Я решил, что данная статья будет крайне полезна тем, кто создает самоадаптирующиеся торговые системы. Хочу рассказать немного о брутфорсе, а также о том, что я вкладываю в это понятие в контексте торговли на форексе. Вообще, брутфорс подход (полный перебор) — это когда мы хотим определить какую-то последовательность чисел для кода или любой другой цели, которая в итоге позволит с максимальной вероятностью либо же с максимально доступной вероятностью, используя эту последовательность, прийти к желаемому результату. Например, добыть криптовалюту или взломать пароль от аккаунта или вайфая. Применений может быть масса. В случае форекса наша последовательность должна давать максимальную прибыль, работая максимально возможное время. Последовательность может быть любого типа и длины, главное — был бы толк. А вообще, вид этой последовательности в конечном итоге зависит от нашего алгоритма.
Почему я решил осветить именно эту тему и что в ней такого особенного?
Я вообще стараюсь излагать свои мысли так, чтобы они имели максимальное практическое применение у других трейдеров. Зачем оно мне нужно ? Хороший вопрос. В первую очередь я хочу поделиться своим опытом на бескорыстных началах. Мне было бы приятно, если бы у кого-то получилось применить мои идеи и сделать что-то интересное и прибыльное, независимо от того что от этого получу я. При этом я конечно понимаю, может быть это совсем не мои идеи и может быть я изобретаю велосипед, или может быть хочу верить как агент Малдер, не важно. Я считаю, что нужно делиться опытом и максимально продуктивно сотрудничать. Возможно, в этом и есть секрет успеха. Можно всю жизнь сидеть в 4-х стенах и строить себе в голове воздушные замки, но результата от этого не будет. На мой взгляд, тема закономерностей и вообще, как их находить и зачем их находить, имеет краеугольное значение для понимания физики рынка. Поверьте, то что я пытаюсь сказать — очень важно, и даже от элементарного понимания этих вещей может зависеть ваша трейдерская карьера, хотя, конечно, само словосочетание "трейдерская карьера" для меня звучит очень смешно ). Я надеюсь, что я смогу привнести какую-то пользу людям, которые этими вопросами до сих пор болеют.
О брутфорс подходе и его отличиях от нейросети
Вообще по сути, нейросеть — это тоже своего рода брутфорс. Просто ее алгоритмы сильно отличаются от алгоритмов простого брутфорса. Я сейчас не буду рассматривать какие-то отдельные архитектуры нейросетей и виды ее составных элементов типа перцептрона, а постараюсь осветить вопрос в общем. Вообще, если мы привязываемся к некой архитектуре, то мы заранее уже ограничиваем возможности нашего алгоритма. А фиксированная архитектура — это уже непоправимое ограничение. Нейросеть это некая архитектура возможной стратегии в нашем случае. В итоге конфигурации некой нейросети всегда соответствует некий файл с картой сети. По сути, это всегда указания на сборку некой единицы. Это как 3D принтер. Задай параметры детали и он тебе ее соберет. Если проще, то нейросеть это общий код, который не имеет смысла без карты. Это как если взять любой язык программирования, все его возможности, и просто создать пустой проект. В итоге язык есть, но шаблон пустой и, следовательно, он ничего не делает. Так и здесь. Просто в отличие от брутфорса, нейросеть может дать практически неограниченую вариативность наших стратегий, любое количество критериев и более высокую эффективность. Единственный минус такого подхода в том, что если вы небрежно составите этот общий код, то его эффективность может даже в итоге уступить брутфорсу. Возрастает возможная сложность системы, значит — возрастает прожорливость программы. В итоге мы превращаем нашу стратегию в карту сети, которая является ее эквивалентом. В брутфорс подходе мы делаем то же самое, только превращается это все в простую последовательность каких-то чисел. Эта последовательность намного проще карты сети, вычисляется проще, но и имеет свой потолок в плане эффективности. Схематично изображу сказанное ниже.
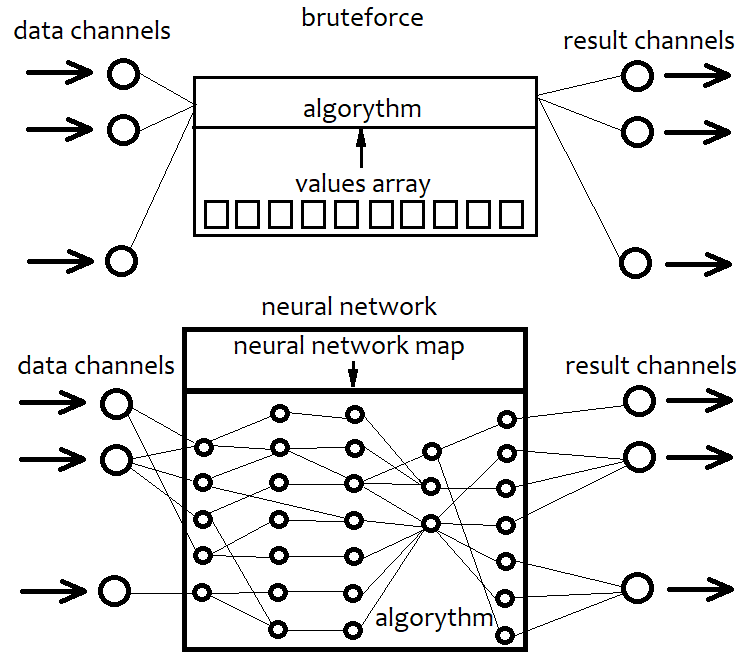
Иными словами, в случае брутфорс подхода мы подбираем последовательность чисел, которая при взаимодействии с нашим кодом будет давать разный результат. Но так как алгоритм фиксирован, то вся его гибкость содержится в массиве наших чисел. Его длина фиксирована и структура очень проста. В случае нейросети мы ищем такую карту сети, которая даст лучший результат. И в том и в том случае мы всегда ищем какую-то последовательность байт. Какие-то данные, которые преобразуются в итоге в результирующий алгоритм. Разница только в их возможностях и сложности.
Мой алгоритм брутфорса и оптимизации
Я использовал в своем алгоритме многомерное разложение в ряд Тейлора. Выбор данного подхода обусловлен следующими соображениями. Мне хотелось обеспечить такой алгоритм, который был бы максимально вариативен при всей своей простоте, не очень-то хотелось привязываться к какой-то конкретной формуле, так как в конечном итоге любую функцию можно разложить в ряд Тейлора либо ряд Фурье. Но мне представляется, что ряд Фурье не совсем подходит для этой задачи, да и многомерный эквивалент мне не знаком. Поэтому я остановился на первом варианте, да и программно его реализовать гораздо проще. Одномерный ряд тейлора выглядит вот так:
Y = Cs[0]+Cs[1]*(x-x0)^1 + Cs[2]*(x-x0) ^2 + ... + Cs[i]*(x-x0)^n
где коэффициенты перед степенями играют роль производных порядка от 0 до n. Что можно преобразовать к более простому виду раскрыв все скобки:
Y = C[0]+C[1]*x^1 + C[2]*x^2 + ... + C[i]*x^n + ...= Сумма(0,+бесконечность)(C[i]x^i)
В данном случае у нас всего одна переменная. Данный ряд может имитировать любую непрерывную и дифференцируемую функцию в окрестности любой выбранной точки x0. Чем больше слагаемых в этой формуле, тем точнее она описывает нашу функцию. Если их число равно бесконечности, то это абсолютный эквивалент нашей функции. Я не буду здесь показывать как разложить любую функцию в ряд Тейлора в окрестности любой точки. Это вы найдете в любом учебнике математики. Но нам недостаточно одномерного варианта, ведь мы хотим использовать данные не одного бара, а нескольких, что повысит вариативность общей формулы. Тогда нам стоит использовать многомерный вариант:
Y = Сумма(0,+бесконечность)( C[i]*Вариант произведения(x1^p1*x2^p2...*xN^pN) )
Эту формулу написать здесь иначе довольно трудно. Ее логика та же, как и у одномерного варианта. Мы должны обеспечить все возможные частные производные. Если ограничить старшую степень слагаемых, то можно комбинаторно вычислить общее число таких слагаемых с помощью сочетаний и сумм, но я не думаю, что стоит здесь приводить эти вычисления, в нашем случае они бесполезны. В нашем алгоритме мы будем использовать как раз ограничение старшей степени, потому как мы не хотим чтобы наш компьютер погиб ).
Но этого еще не достаточно для того, чтобы наша брутфорс функция имела удобный вид. Нам лучше убрать первое слагаемое С[0], так как лучше, чтобы функция имела максимальную симметрию относительно отрицательных либо положительных значений, которые мы будем ей скармливать. Плюс к этому лучше сделать так, чтобы если функция дает положительное число, то мы будем это интерпретировать как сигнал на покупку, а если функция отрицательна — то на продажу. Увеличение нижней границы модуля этого сигнала должно в идеале давать увеличение матожидания и профит фактора, но и неизбежно приводить к уменьшению количества сигналов. Чем ближе наша функция будет к нашим требованиям, тем лучше. В качестве переменных, которые мы будем туда передавать, будут (Close[i]-Open[i]) значения конкретной свечи.
Все, что нам осталось, это просто случайно генерировать варианты этих коэффициентов и проверять, как тот или иной вариант ведет себя в тестере. Но по понятным причинам никто в здравом уме не будет перебирать эти коэффициенты вручную, следовательно, либо нужен хитрый советник, который способен производить такие варианты и одновременно сопровождать тысячи таких вариантов, либо сторонний софт, частично реализующий функционал тестера стратегий. Изначально мне пришлось написать такой советник на MQL4 и пробовать сначала на нем, он будет приложен к статье вместе с инструкцией, все желающие смогут им пользоваться, может даже модифицировать. Но использовать я буду не его, а другое приложение, которое разработал сам на языке C#. К сожалению, предоставить в свободный доступ это приложение я не могу по понятным причинам. Его возможности выходят далеко за область исследования. Но я расскажу о его возможностях и продемонстрирую на практике, так что все, кто умеет программировать, я думаю, смогут повторить это приложение, кто-то даже написать лучше, если будет на то причина. Скриншоты я приведу ниже в части статьи, где мы будем анализировать результаты ее работы.
Расскажу о ее главных особенностях. Поиск массивов коэффициентов выполняется в 2 ступени. Первая ступень просто ищет в загруженной котировке такие массивы, которые дают либо максимальное матожидание, либо максимальный профит-фактор на следующей свече, проводя прогоны как в тестере стратегий. То есть по сути просто пытается подобрать формулу, которая с максимальной точностью предсказывает направление следующего бара. Какое-то количество лучших результатов в виде вариантов массивов сохраняются в памяти и на диске. Тестировать можно лишь часть загруженной котировки, указав ее величину в процентах относительно загруженного файла котировок. Это нужно для того, чтобы во второй ступени отсеять случайные результаты, которые не являются закономерностями. Во второй ступени уже имитируются рыночные ордера и строится кривая баланса, все это проводится полностью для всего загруженного участка. Одновременно с этим производится плавное увеличение величины сигнала, поиск более качественных вариантов. Так же там присутствует множество фильтров, которые нужны для получения более ровных и плавных графиков. Чем плавнее график, тем более лучшую формулу мы нашли. По завершении второй ступени поиска останется какое-то количество самых лучших вариантов, которые еще визуально можно будет увидеть, листая кнопками по списку. Выбрав нужный вариант, можно будет в третьей вкладке сгенерировать робота для MetaTrader 4 и MetaTrader 5 . Генерация происходит по заранее составленному шаблону, в котором просто заполняются числа в определенные места.
Построение простейшего шаблона для данной задачи
Шаблон изначально был сделан на MQL4, потом на MQL5 . Код как и в прошлой статье максимально адаптирован под обе платформы. Я делаю так специально для того, чтобы тратить меньше времени на адаптацию. Чтобы использовать предопределенные массивы как в MQL4, нужно добавить кое-какой код в советника, а какой — я описывал в прошлой статье. Не буду повторяться. Буду писать с предположением, что вы знаете, как все это делается. Да и, если честно, там сложного ничего нет, и любой разработчик с легкостью это реализует, даже получше чем я, если будет на то потребность. Начнем с того, что опишем переменные и массивы, которые будут заполняться автоматически в момент генерации робота и для чего они нужны.
double C1[] = { %%%CVALUES%%% };//массив для коэффициентов int CNum=%%%CNUMVALUE%%%;//количество свечей в формуле int DeepBruteX=%%%DEEPVALUE%%%;//глубина формулы int DatetimeStart=%%%DATETIMESTART%%%;//стартовая точка времени input bool bInvert=%%%INVERT%%%;//инверт торговли input double DaysToTrade=%%%DAYS%%%;//дней можно торговать в будущее
Здесь С1 это как раз массив коэффициентов перед степенями, который мы подбирали. CNum — это количество последних свечей на графике цены, которые мы будем использовать для вычисления значения нашего полинома. Дальше идет глубина формулы или, если проще, максимальная степень нашего многомерного полинома. Я обычно использую 1, потому что в отличие от одномерного ряда Тейлора, у многомерного неимоверно возрастает сложность вычисления с повышением степени в виду того, что суммарное количество коэффициентов с повышением степени лавинообразно возрастает. Стартовая точка времени нужна нам для того, чтобы ограничивать время работы нашего советника, а чтобы его ограничить, надо знать, от какой точки времени отсчитывать само время. Ну и инверт нужен, во-первых, для того чтобы обеспечить работу нашего полинома в нужном направлении. Ведь, если все знаки перед коэффициентами степеней инвертировать, то, по сути сам, полином не изменится, а просто все числа, которые он выдает, поменяют знак. Самое главное — это соотношение коэффициентов. Если отрицательное значение полинома говорит о продаже, а положительное о покупке, то инверт false. Если нет — то true. Те самым мы говорим алгоритму "используй значения полинома, но только знак инвертни". Ну и второй момент — лучше сделать эту переменную как входное значение, так как нам может понадобиться возможность инвертировать торговлю, как и количество дней, которое мы разрешим ему торговать в будущее.
В случае, если надо вычислить размер массива с коэффициентами, можно сделать это так:
int NumCAll=0;//размер массива коэффициентов void DeepN(int Nums,int deepC=1)//промежуточный фрактал { for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { DeepN(Nums,deepC-1); } else { NumCAll++; } } } void CalcDeepN(int Nums,int deepC=1)//для запуска вычислений { NumCAll=0; for ( int i=0; i<deepC; i++ ) { DeepN(Nums,i+1); } }
Здесь функция, названная промежуточным фракталом, считает количество тех слагаемых, которые имеют одну и то же суммарную степень всех множителей. Это сделано для простоты, ведь нам не так важно, в каком порядке суммировать наши слагаемые, а только то, чтобы это было реализовано максимально просто в виде кода. Вторая функция просто вызывает первую в цикле столько раз, сколько всего видов слагаемых. Например, если наше многомерное разложение в ряд ограничено скажем числом 4, то мы вызываем первую функцию со всеми натуральными числами начиная от 1 и заканчивая 4.
Функция, которая будет уже считать само значение полинома, будет практически идентична, только в нашем случае массив генерируется сам и его размер не нужно задавать, вот так она будет выглядеть:
double ValW;//число куда умножаем все(а потом его прибавляем к ValStart) uint NumC;//текущее число для коэффициента double ValStart;//число куда суммируем все void Deep(double &Ci0[],int Nums,int deepC=1,double Val0=1.0)//вычислим сумму для одной степени { for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(Close[i+1]-Open[i+1])*Val0; Deep(Ci0,Nums,deepC-1,ValW); } else { ValStart+=Ci0[NumC]*(Close[i+1]-Open[i+1])*Val0/Point; NumC++; } } } void CalcDeep(double &Ci0[],int Nums,int deepC=1)//вычислим весь полином { NumC=0; ValStart=0.0; for ( int i=0; i<deepC; i++ ) { Deep(Ci0,Nums,i+1); } }
Все, что мы посчитаем, будем добавлять к ValStart, то есть результат будем складывать в глобальную переменную. Также нам понадобится еще одна глобальная переменная ValW, она нужна для того, чтобы домножить уже имеющееся произведение на некоторую величину. В нашем случае это движение соответствующего бара в пунктах. Движение может быть как вверх, так и вниз, что учитывается знаком. Видно, что эти функции имеют очень интересную структуру. Они вызывают самих себя внутри, и количество и структура этих вызовов всегда различна. Получается своего рода дерево вызовов. Я очень люблю применять такие функции, так как они очень вариативны. В нашем случае мы реализовали многомерный ряд Тейлора просто и изящно.
Можно так же реализовать дополнительную функцию на случай использования лишь одномерного варианта полинома. В этом случае весь ряд сильно упрощается и превращается в сумму коэффициентов, умноженных на движение какого-то из баров в первой степени. И их количество становится идентичным количеству используемых баров. Этим можно немного упростить вычисления. Если наша степень единица, то используем упрощенный вариант, а если нет, то более универсальный метод для любой степени.
double Val; double PolinomTrade()//оптимизированный полином { Val=0; if ( DeepBruteX <= 1 ) { for ( int i=0; i<ArraySize(C1); i++ ) { Val+=C1[i]*(Close[i+1]-Open[i+1])/Point; } return Val; } else { CalcDeep(C1,CNum,DeepBruteX); return ValStart; } }
В случае простого варианта будем складывать результат в другую переменную Val.
Теперь напишем основной метод, который будем вызывать при появлении нового бара:
void Trade() { double Value; Value=PolinomTrade(); if ( Value > ValueCloseE) { if ( !bInvert ) { CloseBuyF(); } else { CloseSellF(); } } if ( Value < -ValueCloseE) { if ( !bInvert ) { CloseSellF(); } else { CloseBuyF(); } } if ( double(TimeCurrent()-DatetimeStart)/86400.0 <= DaysToTrade && Value > ValueOpenE && Value <= ValueOpenEMax ) { if ( !bInvert ) SellF(); else BuyF(); } if ( double(TimeCurrent()-DatetimeStart)/86400.0 <= DaysToTrade && Value < -ValueOpenE && Value >= -ValueOpenEMax ) { if ( !bInvert ) BuyF(); else SellF(); } }
Как видно, функция максимально простая, и все что вам остается, это реализовать подходящие вам функции открытия и закрытия позиций.
Засечь появление бара можно вот так:
void CalcTimer() { if ( Time[1] > PrevTimeAlpha ) { if ( PrevTimeAlpha > 0 ) { Trade(); } PrevTimeAlpha=Time[1]; } }
Я думаю, код максимально прост и понятен любому.
Коэффициенты, которые генерирует мой, код создаются по 4-ем моделям, которые я объяснял выше. Для удобочитаемости и чтобы глаз не резало, эти коэффициенты лежат в диапазоне [-1,1] , так как нам важны не столько сами значения, а их соотношения. Функция, генерирующая эти числа из прототипа моей программы на MQL5, выглядит так:
void GenerateC() { double RX; if ( DeepBrute > 1 ) CalcDeepN(CandlesE,DeepBrute); else NumCAll=CandlesE; for ( int j=0; j<VariantsE; j++ ) { ArrayResize(Variants[j].Ci,NumCAll,0); Variants[j].CNum=CandlesE; Variants[j].ANum=NumCAll; Variants[j].DeepBruteX=DeepBrute; RX=MathRand()/32767.0; for ( int i=0; i<Variants[j].ANum; i++ ) { if ( RE == RANDOM_TYPE_1 ) Variants[j].Ci[i]=double(MathRand())/32767.0; if ( RE == RANDOM_TYPE_2 ) { if ( MathRand()/32767.0 >= 0.5 ) { Variants[j].Ci[i]=double(MathRand())/32767.0; } else { Variants[j].Ci[i]=double(-MathRand())/32767.0; } } if ( RE == RANDOM_TYPE_3 ) { if ( MathRand()/32767.0 >= RX ) { if ( MathRand()/32767.0 >= RX+(1.0-RX)/2.0 ) { Variants[j].Ci[i]=double(MathRand())/32767.0; ///Print(Variants[j].Ci[i]); } else { Variants[j].Ci[i]=double(-MathRand())/32767.0; } } else { Variants[j].Ci[i]=0.0; } } if ( RE == RANDOM_TYPE_4 ) { if ( MathRand()/32767.0 >= RX ) { Variants[j].Ci[i]=double(MathRand())/32767.0; } else { Variants[j].Ci[i]=0.0; } } } } }
Прототип бруттера на MQL4 и MQL5 будет приложен к статье. Я не стал приводить свои реализации торговых функций, так как это неинтересно, да и не нужно. Я хотел просто показать, как реализовывается мой подход в рамках шаблона. Если кому-то станет интересно, как реализовывается остальная часть, то вы сможете увидеть это в приложенных советниках к статье. Все советники и материалы будут приложены к статье. Вообще, в моем шаблоне довольно много лишнего, в том числе и ненужных функций, где-то можно оптимизировать, где-то какие то переменные лишние убрать. Лично я не заморачиваюсь на счет этого. Что будет мешать — вырежу. Главное — работает, и мне этого достаточно. Я постоянно что-то разрабатываю и у меня нет времени вылизывать каждую мелочь. В классы все процедуры и переменные складировать тоже не вижу смысла, разве что только ради порядка и читаемости. Шаблон очень простой и считаю что мудрить нет смысла. Файлы с котировками, которые будет использовать наша программа, будут сгенерированы специальным советником, который просто при прогоне по истории записывает данные баров в текстовый файл со структурой, удобной для чтения нашей программой. Его код я наверное приводить не буду, сделать такой советник легче легкого.
Используем нашу программу для поиска и анализа закономерностей
В качестве анализируемых участков рынка я выбрал 3 участка по месяцу длиной, которые следуют друг за другом. Пара EURUSD, период M5.
- Первый участок 2020.01.13 - 2020. 02.16
- Второй участок 2020.02.13 - 2020.03.15
- Третий участок 2020.03.13 - 2020.04.18
Участки выбраны так, что последний день участка всегда пятница. А в пятницу, как известно, последний торговый день недели. Если брать участки таким образом, то у нас будет целых 2 дня на поиск закономерностей, пока биржа снова не начала торги. Ну это так небольшой лайфхак, наверное, скорее. В нашем случае это конечно не будет играть роли, так как мы все равно на тестере это все проверять будем. Я решил осветить 12 вариантов найденных закономерностей. Из них 6 вариантов будут на полиномы с максимальной степенью 1. И 6 вариантов с максимальной степенью 2. Думаю, что этого будет достаточно.
Так выглядит первая вкладка моей программы:
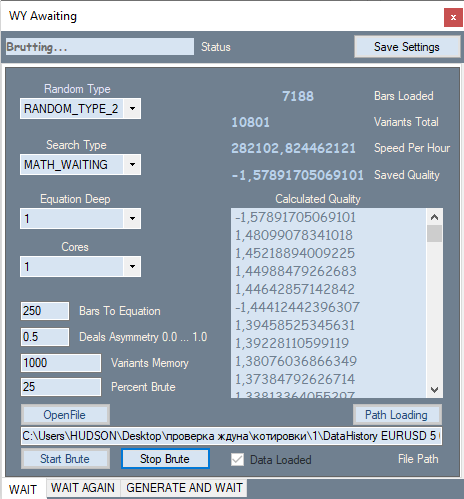
На ней присутствует возможность менять тип генерации наших чисел, например, только положительные, положительные и отрицательные, положительные и нули; положительные? отрицательные и нули. Во втором ComboBox настраивается критерий поиска. Есть 2 варианта: мат. ожидание в пунктах и мой аналог формулы профит-фактора. Только в моей формуле эта величина колеблется от -1 до +1. И не может быть случаев, когда нельзя посчитать профит-фактор из-за деления на ноль.
P_Factor=(Profit-Loss)/(Profit+Loss).
Ну а дальше идет максимальная степень полинома и сколько ядер процессора использовать для вычисления. В текстовых боксах задаем, соответственно, количество баров для нашего полинома, ну или что то же, самое количество измерений, далее тоже мной придуманный коэффициент асимметрии сделок, который очень похож на предыдущую формулу
D_Asymmetry=|(BuyTrades-SellTrades)|/(BuyTrades+SellTrades).
Только его значения лежат в диапазоне от 0 до 1. Этот фильтр нужен для того, чтобы можно было потребовать, чтобы вариант содержал похожее количество сигналов на покупку и продажу во избежание ситуаций, когда просто идет глобальный тренд и все сделки в одну сторону. Далее идет количество лучших вариантов из всех найденных, которые мы храним в памяти, и сколько процентов от загруженной котировки мы используем для брута. Этот кусок отсчитывается от последнего бара по времени открытия, а тот кусок что сзади — он останется для оптимизации. Остальные индикаторы и лист с вариантами не буду объяснять, там и так написано что есть что.
Вторая вкладка выглядит вот так:
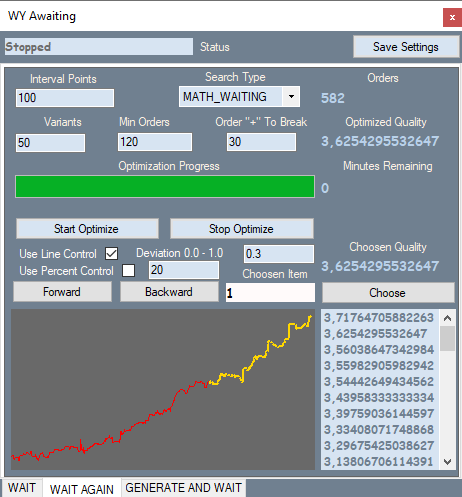
Вкладка соответствует первому варианту для первого участка из тех роботов, которые я буду приводить. Вы сможете сравнить график в моей программе с графиком из тестера. Все это будет ниже. Желтым здесь рисуются ордера на части котировки, где проводился брут, а красным сами догадаетесь. Скришноты всех вариантов я не буду здесь приводить, для того чтобы не заваливать статью лишними картинками, они будут приложены к статье.
Теперь опишу что на этой вкладке. Interval Points — это дробление интервала значений нашего полинома. Дело в том, что когда мы проводим брут на первой вкладке, то помимо основных параметров варианта еще и высчитывается максимальное значение этого полинома по модулю для того, чтобы мы знали окно значений нашего полинома и могли потом, подробив это окно на равные части, постепенно увеличивая значение, попытаться обнаружить более сильные сигналы. Это и делает вторая вкладка. Также есть тип поиска как на первой вкладке и количество лучших вариантов, которые мы храним в памяти оптимизации. Дальше идут фильтры, которые позволяют отсеять ненужные варианты, которые не вписываются в наше определение закономерности. Line Control включает дополнительный прогон для каждого варианта, в котором считает относительное отклонение линии графика от прямой соединяющей начало и конец графика.
Deviation = Max(|Profit[i]-LineProfit[i]|)/EndProfit.
Здесь Profit[i] — значение кривой баланса на i-ом ордере, LineProfit[i] - то же значение, только нашей прямой, EndProfit - значение профита в конце графика.
Все величины измеряются в пунктах. Use Percent Control — это процент красной части графика, но я не использовал в данном случае этот фильтр. Также есть фильтр минимального количества ордеров.
Так выглядит вкладка для генерации бота:
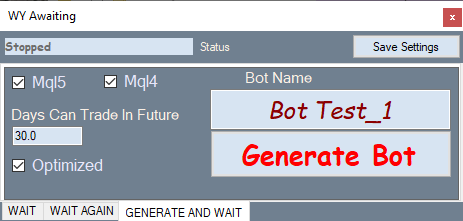
Работает все по принципу: на вкладке оптимизации выбрал понравившийся вариант, перешел на эту и сгенерировал советник.
Переходим к проверке сгенерированных мной роботов в тестере стратегий MetaTrader 4. Я выбрал его потому, что там можно выставить спред 1, тем самым практически нивелируя его влияние на отображение графика. Дело в том, что у большинства найденных таким способом роботов будет матожидание чуть выше среднего спреда на паре, а это не позволит нам визуально проанализировать закономерности с маленьким матожиданием. Каждый вариант я брутил и оптимизировал где-то по 2 часа и, естественно, этого недостаточно, чтобы найти очень качественную закономерность. Если по нормальному, то надо сутки-двое. Но в данном случае и так сойдет, ведь цель этой статьи не найти супер-пупер закономерность, а только проанализировать, как эти закономерности себя поведут в дальнейшем. Добавлю еще что если вы будете тестировать мои роботы в тестере, то обязательно обратите внимание на переменную DaysToTrade. По умолчанию там всего 3 дня стоит. Поэтому не удивляйтесь, что сделок почти нет после участка брута.
Сначала рассмотрим роботы сгенерированные на основе полинома первой степени.
Первый участок. 2020.01.13 - 2020. 02.16
Бот 1:
Участок брутфорса
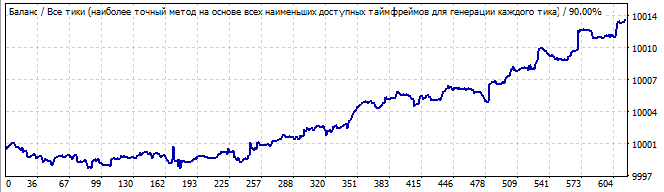
В будущее на 10 дней
На первом графике вариант со скриншота второй вкладки моей программы. А второй график — это тест того же робота в будущее на 10 дней. Думаю, 10 дней вполне достаточно, чтобы увидеть все, что нужно. Здесь мы видим, что закономерность продолжается еще какое то время, а потом резко разворачивается и идет в обратную сторону. На первый взгляд все хорошо — закономерность работает достаточно, чтобы получить из нее прибыль за пару тройку дней. Посмотрим второй робот с того же участка рынка:
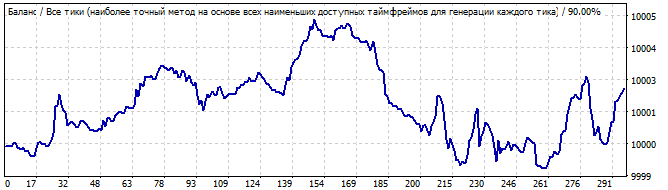
Участок брутфорса
В будущее на 10 дней
Здесь не все так гладко. Почему? Казалось бы, закономерность должна отработать еще хотя бы день или два, но она с первых же секунд идет на спад хотя и разворот достаточно плавный. Вероятно, это не те результаты, которых многие ждали ). Но все это довольно легко объясняется. В конце я покажу, как.
Переходим на второй участок тестирования. 2020.02.13 - 2020.03.15
Идем к третьему роботу:
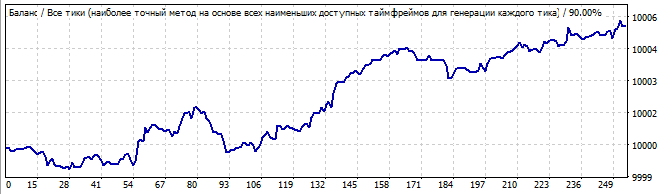
Участок брутфорса
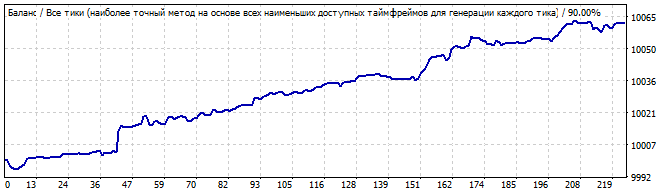
В будущее на 10 дней
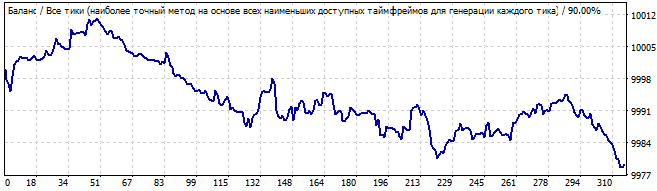
Первая картинка из трех, которая выглядит неплохо. График очень ровный и очень близок к прямой линии. Что лично мне говорит о том, что закономерность очень стабильна и с большей вероятностью еще какое то время продолжит движение. Так и произошло. Даже если внимательно понаблюдать, то мы увидим что даже в будущем это движение напоминает линию, иначе говоря многие параметры этой закономерности продолжали работать.
Посмотрим на четвертый робот:
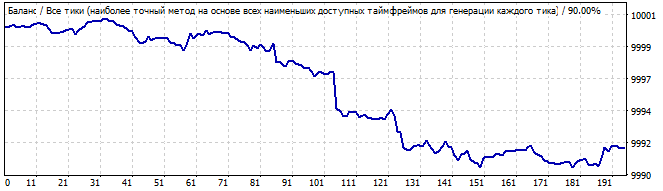
Участок брутфорса
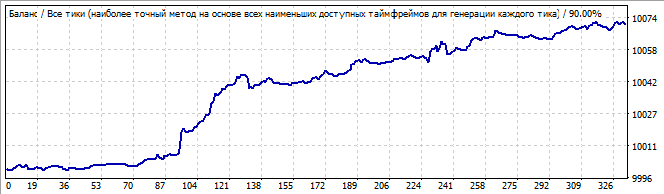
В будущее на 10 дней
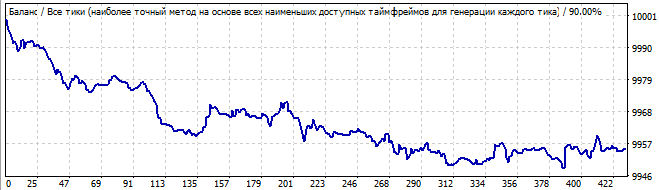
Здесь наблюдается довольно хорошее движение вверх, и на первый взгляд все довольно плавно и стабильно, если не считать резкого подъема в начале графика. Но вот как раз его то и надо замечать, потому что, на мой взгляд, эта асимметрия уже сразу должна сказать нам, что это возможно просто стечение обстоятельств или случайный результат. И в будущем мы видим сразу с первых секунд инверт всей закономерности в обратную сторону, чему я, в принципе, не удивлен.
Переходим на третий участок тестирования. 2020.03.13 - 2020.04.18
Пятый робот:
Участок брутфорса
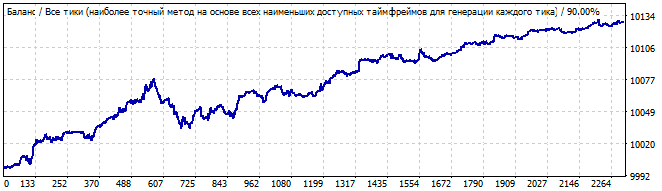
В будущее на 10 дней
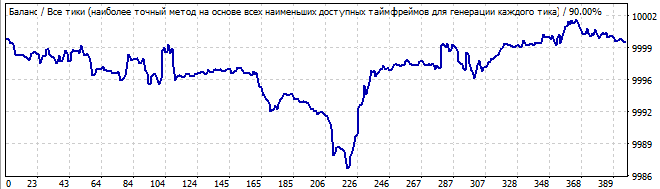
Здесь примерно та же картина. Та же видимая асимметрия, какие-то волны вначале, затухание под конец. Вроде бы и напоминает какую-то закономерность, но очень спорно лично для меня. Я бы не рискнул торговать на продолжение. Ну и ожидаемо немедленный разворот графика в будущем и инверт всей формулы. Шестой робот я не буду здесь показывать, его график будет в архиве. Он там практически идентичен с этим графиком.
Теперь переходим к роботам на основе полинома второй степени.
Первый участок. 2020.01.13 - 2020. 02.16
Посмотрим на 7-ой робот:
Участок брутфорса
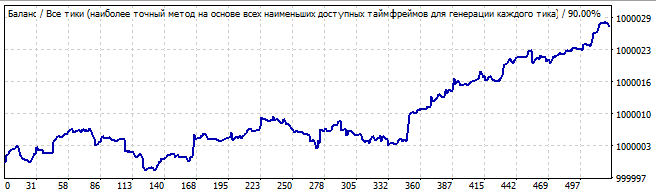
В будущее на 10 дней
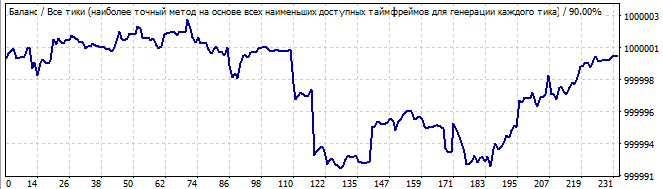
Ярко выраженной особенностью данных роботов является, как и можно предположить, более качественная работа робота на участке брута. Менее качественно все это выглядит на участке, предшествующему участку брута. То есть на том участке, где мы брутили, всегда наблюдается резкая положительная полуволна. Тогда как на оставшемся участке какой-то сумбур, и в лучшем случае небольшое движение вверх. Тем не менее, это лишь показатели конкретной формулы, как видно дальше, все ведет себя похоже. Небольшая хаотичность в начале, а потом движение в обратную сторону.
Поглядим на восьмой вариант:
Участок брутфорса
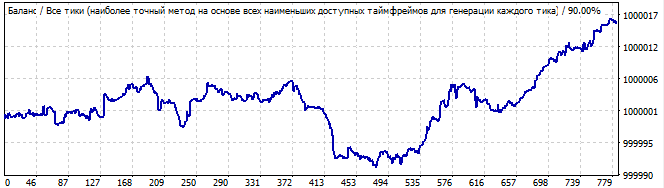
В будущее на 10 дней
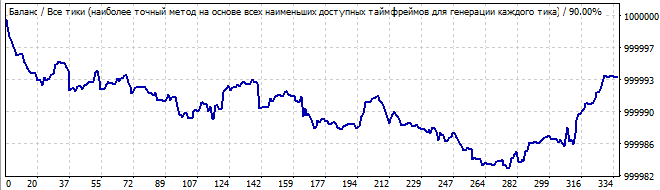
Здесь все намного хуже. глобальной закономерности нет, но, как и в прошлом варианте, есть движение вверх на участке брута. Тут и в помине нет никакой глобальной закономерности, поэтому ожидаемо, график сразу идет вниз.
Переходим на второй участок тестирования. 2020.02.13 - 2020.03.15
Девятый робот:
Участок брутфорса
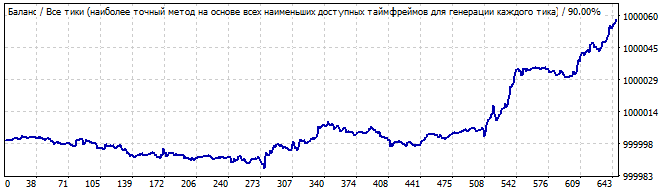
В будущее на 10 дней
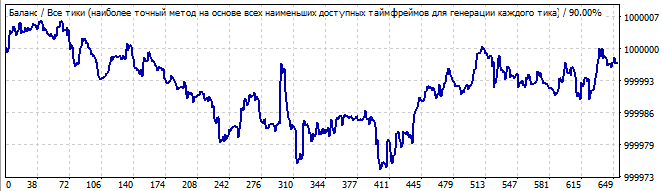
Лично я на первом графике вижу начало волны, а в будущем ее окончание. Никакой глобальной закономерности здесь нет, тем не менее разворот достаточно плавный, чтобы успеть что-то даже заработать — крохи, но все же.
Посмотрим на 10 робот:
Участок брутфорса
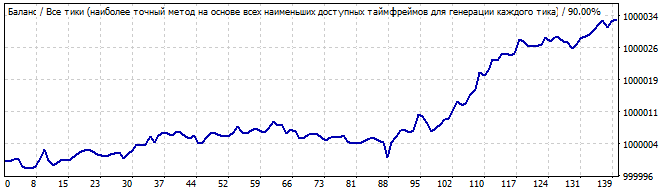
В будущее на 10 дней
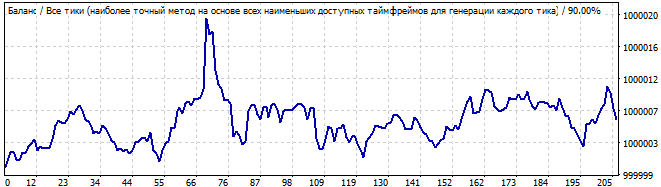
Здесь получше. Больше похоже на закономерность. Продолжается закономерность день-два максимум. Но я бы, если честно все равно, не стал рисковать с таким графиком. Отклонение от прямой слишком выраженное.
Переходим на третий участок тестирования. 2020.03.13 - 2020.04.18
Одиннадцатый робот:
Участок брутфорса
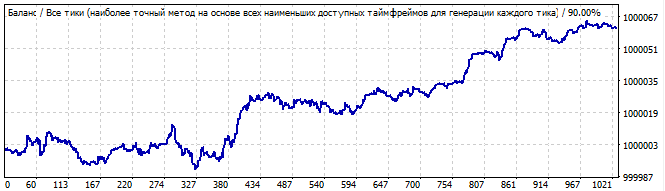
В будущее на 10 дней
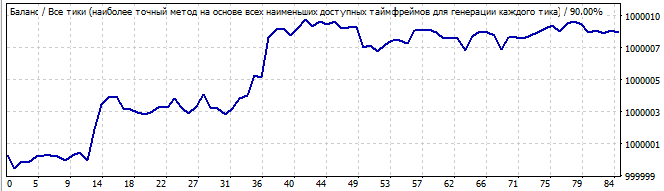
Картинка не очень-то красивая, но тем не менее можно увидеть некоторое сходство с прямой. В будущем закономерность продолжается, но на мой взгляд это скорее везение, чем результат, слишком много случайных шумов. Или может быть даже это не шумы, а какие-то более мелкие волны, непонятно.
Двенадцатый робот:
Участок брутфорса
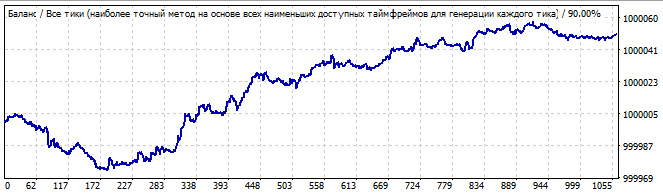
В будущее на 10 дней
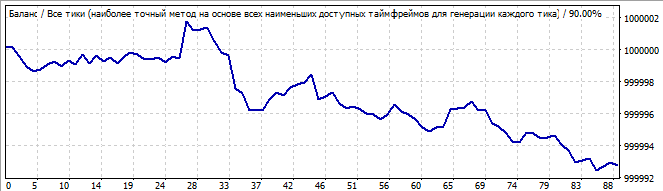
Довольно безобразный график, но можно увидеть ярко выраженный конец одной волны и другую огромную следующую за ней. В будущем эта огромная волна потихоньку разворачивается и в какой-то момент окончательно инвертируется. Мне показалось, что на роботах с полиномом старше степени 2 более плавно происходил разворот тенденции. Меньше сюрпризов, что называется. Я думаю, если потратить побольше времени и протестировать третью степень, то там будет получше. По идее должно быть именно так, так как закономерность должна лучше описываться тем полиномом, у которого выше старшая суммарная степень множителей в слагаемых.
Выводы и математические истины, следующие из нашего исследования
Теперь мы можем обобщить все результаты тестов наших советников. На первый взгляд это сделать трудно, так как вроде бы на участке брута и оптимизации все идет вверх, а на участках брута в целом какой-то сумбур. На самом деле нет:
- На каждом из тестов в будущее всегда есть точка, где график разворачивается и формула инвертируется.
- Разворот может происходить плавно или мгновенно, но он всегда есть.
- Подавляющее большинство графиков в будущем идет вниз в целом.
- Иногда закономерность продолжается некоторое время в начале.
- В целом по всем тестам в будущее очевидно, что там закономерность работает в обратную сторону.
- Если кривая баланса отклоняется от прямой, то шансы на продолжение значительно ниже.
- На лучшем из найденных вариантов закономерность работает еще пару-дней.
Все эти факты я сейчас постараюсь объяснить. Начнем с первого и самого важного факта, к которому я пришел давно, кстати говоря, когда таких программ у меня и в мыслях не было. Это довольно простая математическая истина. Ниже я нарисовал график баланса произвольной стратегии. Черная линия с маленькой закономерностью, а фиолетовая с большой, и их примерное поведение, если бы мы их торговали по всей истории, а не только на участке брута:
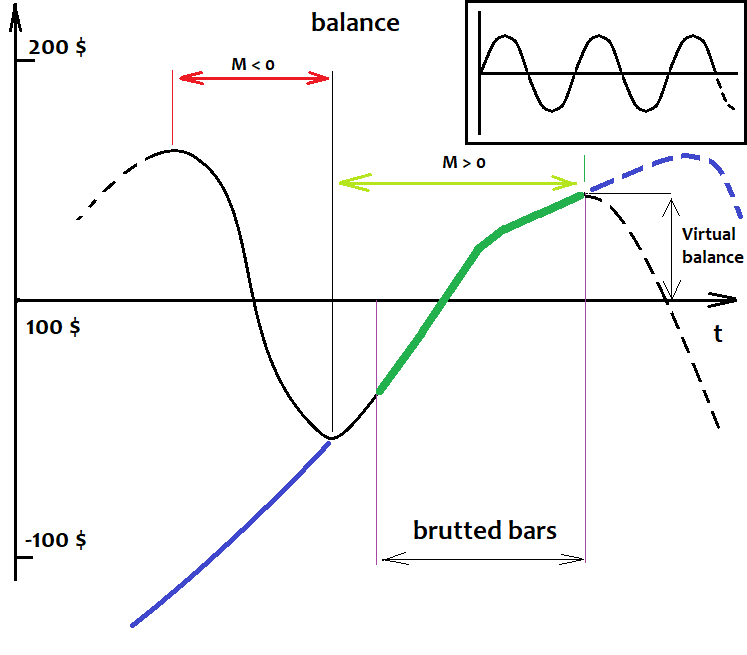
Я специально не вставляю сюда котировки, так как в нашем случае анализируемой базой может являться график баланса. Нас не должно волновать, как там эта котировка рисуется и что там на ней. Мы все равно не увидим в ней больше, чем наша стратегия.
Представьте, если бы мы тестировали всех наших роботов с самого начала истории и еще в будущее, но, хотя у нас еще нет котировок из будущего, мы ведь можем все равно предположить, что там у нас будет с точностью 100 %. Бред, скажете вы ? )). Нет, не бред. Сначала представим, что мы тестируем роботов по всей имеющейся истории котировок. Что мы увидим? Какой-то сумбур вверх-вниз, потом опять вверх, потом вниз. И что мы должны увидеть в этой каше, спросите вы? А я отвечу: волны. Неважно, какой они формы, какой длины волны и амплитуды. И это уж точно не синусоида, но нам это неважно. Нам важно лишь то, что этот процесс периодический. Если бы мы еще к тому же предположили, что котировка бесконечная, то мы могли бы сказать, основываясь на математических изысканиях моей прошлой статьи, что взяв рандомную стратегию с рандомной формулой, ее матожидание по всей истории будет стремиться к нулю при стремлении количества исторических данных к бесконечности. Что это нам дает? А то, что мы теперь можем сказать, что любая кривая баланса при бесконечном количестве сделок бесконечное число раз пересечет линию стартового баланса. И даже если по каким-то причинам баланс сразу уходит вверх или вниз и держится там все время, то мы вправе немного сдвинуть эту линию вниз или вверх, и все равно найдем эту точку равновесия, возле которой и происходят колебания баланса.
Мы не будем брать во внимание те формулы, которые приводят к ярко выраженному выигрышу или убытку по всей истории, хотя эти варианты тоже можно отнести в эту категорию, просто в данном случае мы попали на положительную или отрицательную полуволну огромной волны размером больше, чем вся наша история. А в рамках наших допущений получается, что найденные мной закономерности не что иное, как найденные части положительных полуволн. А чем больше найденная часть, тем больше вероятность того, что точка равновесия находится далеко внизу. Исходя из этого, раз сейчас положительная полуволна, то скоро должна появиться отрицательная. Если языком математики — то вероятность движения в отрицательную сторону тем больше, чем больше та полуволна, которую мы поймали. И наоборот — если мы поймали отрицательную полуволну, то чем больше эта полуволна, тем больше возрастает вероятность того, что дальше начнется положительная полуволна. Можно проще: если у нас есть стратегия с нулевым матожиданием по всей истории, то вся эта история состоит из сегментов с отрицательным и положительным матожиданием, которые следуют друг за другом и постоянно чередуются. У меня даже есть советник, реализующий этот принцип, и он работает по любой валютной паре по всей истории котировок. Так что мои доводы подтверждаются не только исследованиями, которые мы здесь провели, но и советниками. Вообще, этот принцип можно не только масштабировать, но и бесконечно наслаивать как матрешку, увеличивая эффективность системы. Можно, конечно, играть на продолжение тенденции, но я советую делать это только в том случае, если закономерность ну уж очень красивая и ровная, и то — не более 5-10 % от найденной закономерности в будущее. Риски очень велики. Да и к тому же вы будете играть против математики, а это глупо. Если бы как-то было можно оценить даже приблизительное оставшееся время работы данной закономерности, то так можно было бы поступить. Но в нашем случае это сделать невозможно, так как природа закономерности нам не ясна. Да и даже если природа закономерности ясна, то даже в этом случае такой анализ провести крайне трудно.
Как определить уровень, относительно которого происходят колебания ?
Продолжая тему колебаний, постараюсь ответить читателю, как же все-таки определить этот чертов уровень, относительно которого нужно определять волны и их движение относительно самого уровня ? Ответ до безобразия прост ). Да никак ). Но это совсем не значит, что этого уровня нет и что это знание нам не сможет помочь правильно провести торговую сделку ). Важно понимать то, что этот уровень не фиксирован, он лишь в нашей голове. Еще более важно понимать следующее: при стремлении размера полуволны к бесконечности, отношение размера этой полуволны к удалению этого уровня от стартового баланса стремится к бесконечности. Иначе говоря, чем сильнее полуволна, которую мы нашли, тем меньше мы можем думать о том, где этот уровень находится, так как все равно при увеличении количества сделок этот уровень стремится к нулевой точке. Все, что нам нужно, это находить максимально сильные полуволны. Еще один факт, свидетельствующий в пользу этого, это то, что чем больше и совершеннее полуволна, тем меньше вероятность, что в оставшейся части виртуального теста найдется волна амплитудой сопоставимая с нашей ). Постараюсь визуально изобразить сказанное на рисунке:
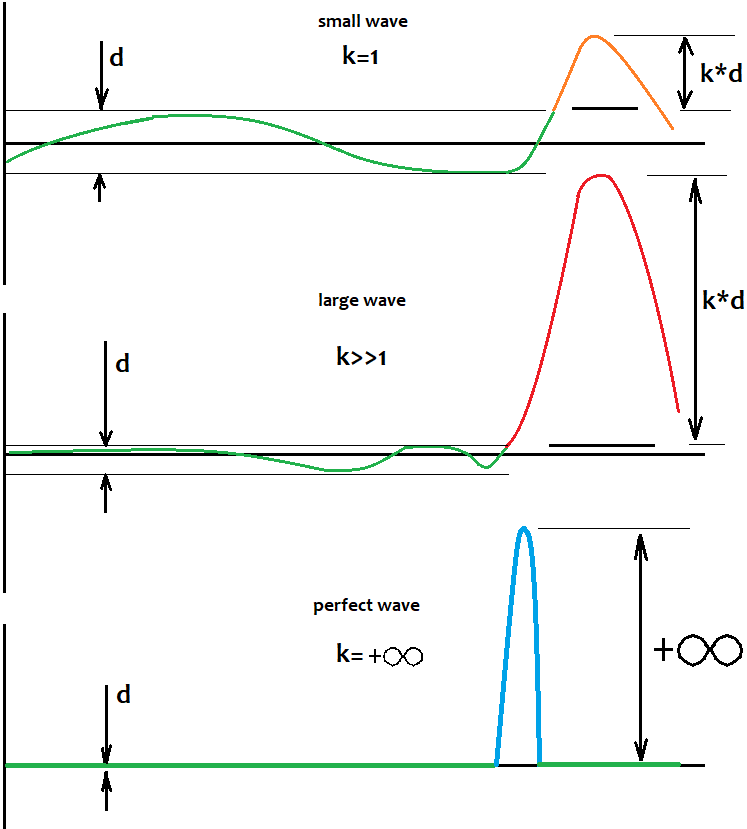
Сам по себе этот уровень не гарантирует, что закономерность 100% туда развернется и пойдет шустро, но, что важнее, сам факт наличия закономерности, которая является частью полуволны, говорит нам о том, что скорее всего таких волн будет не одна, и даже возможно, они присутствуют по всей истории, если бы мы протестировали советника по всей истории. В этом случае есть довольно большой шанс, что будет большое откатное движение. Его то и нужно ловить. Даже когда я тестировал различных советников, которые не работали в глобальном масштабе, локально много где находились участки, где это работало или работало с инвертом. Там были явно выраженные волны и график мало был похож на какой-то сумбур, он был четко структурирован.
Для полноты картины
Постараюсь приближенно рассказать, как на мой взгляд наиболее эффективно проторговывать эти волны. Сначала приведу кое-какие иллюстрации:
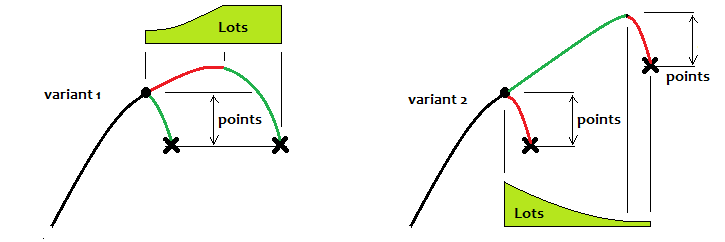
Первый вариант здесь — торговля на инверт закономерности, а второй-на продолжение. Если рассматривать первый вариант, то в идеале нужно всегда достигать определенного уровня и там прекращать торговый цикл, а дальше ждать следующего. В случае использования частичного мартингейла улучшение конечно будет, но в том случае, если известно, что график скоро должен развернуться. Если нет, то матожидание все равно будет "0". На продолжение тенденции можно играть только тогда, когда закономерность близка к идеальной, и то — самое минимально возможное время. Во втором варианте, на мой взгляд, можно использовать обратный мартингейл. Вообще, если честно, все стратегии, которые я проверял, говорят об одном факте, математическом неоспоримом: при торговле фиксированным лотом, если мы не знаем, как себя поведет цена в будущем ( а мы почти всегда не знаем этого), то мы получим "0", как не вертись.
Но бывают все же ситуации, когда мы случайно ловим глобальную закономерность и она работает еще очень далеко, но на мой взгляд, таких ситуаций лучше не ждать. Лучше выбрать какую-то одну схему торговли и следовать ей. Однозначно тут сказать нельзя. У меня пока не было времени протестировать это даже на демо-счетах, так как тут мне понадобится месяца 2-3. В месяце по четыре недели, и каждые выходные по 2 дня я должен брутить ). И еще потом тестировать на каком-то компьютере, который круглосуточно работает, у меня пока нет такой возможности к сожалению. Один есть нетбук, но он занят другими роботами. Возможно в будущем, как появится машинка помощнее, проведу эксперименты на демо счете и сделаю отдельный сигнал.
Заключение
В этой статье мы сделали простые, но очень важные выводы относительно закономерностей и их физики применительно к рынку. А именно: Рынок не хаотичен и в нем внутри спрятано множество закономерностей на различных периодах графиков, просто, наслаиваясь, они создают иллюзию хаотичности. Закономерности есть периодический процесс, который может повторяться и инвертироваться. Раз закономерности повторяются, то у этих волн может быть ограничение по амплитуде, которое мы можем использовать для своих стратегий. Я старался эту статью сделать максимально понятной и приводить минимум математики, чтобы донести основную ее мысль. Надеюсь, что кому-то данная информация поможет при разработке собственных торговых систем. Кто-то возможно видит больше в этих результатах, если да, то активно комментируйте. К сожалению, мне не удалось провести брут по более высоким таймфреймам в виду того, что это все занимает массу времени даже с использованием моего софта. Если возникнет интерес или потребность в таком более глубоком анализе, то я готов продолжить эту тему, но уже в рамках другой статьи. Эта статья, скорее, вводная и демонстрационная получилась.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Нейросети — это просто (Часть 4): Рекуррентные сети
Нейросети — это просто (Часть 4): Рекуррентные сети
 Пишем Twitter-клиент для MetaTrader: Часть 2
Пишем Twitter-клиент для MetaTrader: Часть 2
 Пишем Twitter-клиент для MetaTrader 4 и MetaTrader 5 без использования DLL
Пишем Twitter-клиент для MetaTrader 4 и MetaTrader 5 без использования DLL
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Я просто обязан ответить на эту статью. Выкройки - это лишь маленькая часть общей картины.
Полином первой степени лучше выглядит.
Соотношение периода оптимизации к профитности 4 к 1, уже не первый раз вижу.
Полуволны, это из теории вероятностей, есть формулы для максимального размаха, количества пересечения 0, вероятности возвращения в 0.
Посмотрите ссылку, оставляя только 1 степень, вы делаете линеаризацию, можно заменить брутфорс на решение уравнений.
Полином первой степени лучше выглядит.
Соотношение периода оптимизации к профитности 4 к 1, уже не первый раз вижу.
Полуволны, это из теории вероятностей, есть формулы для максимального размаха, количества пересечения 0, вероятности возвращения в 0.
Посмотрите ссылку, оставляя только 1 степень, вы делаете линеаризацию, можно заменить брутфорс на решение уравнений.
оставляя вторую степень работаем с каналом регрессии, с 3-й начинаем учитывать отклонения внутри канала
как-то так вот примерно, без деталей и фанатизма
Полином первой степени лучше выглядит.
Соотношение периода оптимизации к профитности 4 к 1, уже не первый раз вижу.
Полуволны, это из теории вероятностей, есть формулы для максимального размаха, количества пересечения 0, вероятности возвращения в 0.
Посмотрите ссылку, оставляя только 1 степень, вы делаете линеаризацию, можно заменить брутфорс на решение уравнений.
Классический ряд Тейлора составлен для функции одной переменной, у меня используется версия для функции с неограниченным количеством измерений. Хотя если честно я конечно использую только первую степень. просто полином превращается в сумму коэффициентов умноженных на смещения цен на каждом баре. В итоге решающим фактором является не вид самой формулы а частота перебора. В целом какая разница, это дает результат. Дальше можно модификации накатывать, что-то править.
Здравствуйте, очень интересна ваша работа и особенно ваши мысли. Вы написали, что прилагаются версии mt4 и mt5. Я не могу найти версию mt5! ?
Пожалуйста, добавьте, если это возможно.
Большое спасибо