
Нейросети в трейдинге: Единая архитектура взаимодействия рыночных признаков и торгового контекста (Окончание)

Введение
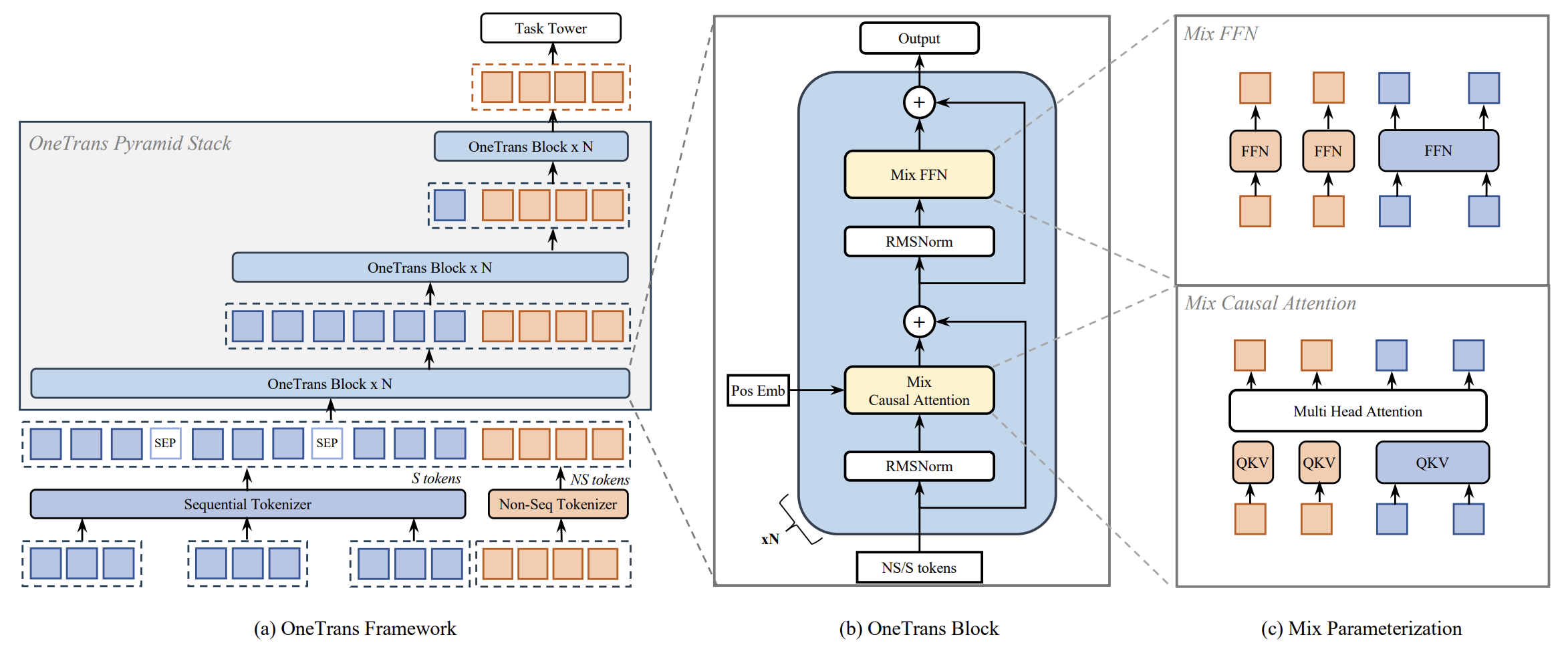
Продолжаем работу над переносом фреймворка OneTrans в область анализа финансовых рынков. В предыдущих статьях мы подробно рассмотрели предложенный авторами фреймворк и начали его практическую реализацию средствами MQL5. Напомним, что центральная идея фреймворка OneTrans заключается в решении важной концептуальной задачи — объединении в рамках одной модели двух принципиально разных типов информации: последовательности событий и признаков, не представленных временным рядом.
Для финансовых рынков такое разделение вполне естественно. С одной стороны, мы имеем поток последовательных наблюдений — изменения цены, объёмы торгов, динамику индикаторов и другие временные ряды, описывающие развитие рыночной ситуации. Именно эти данные традиционно служат основой большинства моделей прогнозирования.
С другой стороны, существует целый класс признаков, которые не формируют собственную временную последовательность, но при этом напрямую влияют на контекст принятия торговых решений. К таким факторам можно отнести текущее состояние торгового счёта, наличие открытых позиций и их накопленный финансовый результат, параметры управления рисками, особенности текущей торговой сессии или внешний информационный фон. Эти признаки не являются временным рядом в классическом смысле, однако они формируют условия, в которых анализируется рынок и принимаются торговые решения.
Авторы фреймворка OneTrans предложили элегантный способ объединить эти два уровня информации. В рамках одного трансформерного механизма модель получает возможность одновременно учитывать последовательность событий (Sequence) и контекстные признаки среды (Non-Sequence). Последовательные наблюдения и характеристики контекста переводятся в единое токенизированное представление и обрабатываются общей трансформерной архитектурой. Благодаря этому модель может рассматривать историю событий и текущие условия среды как взаимосвязанные элементы единой информационной структуры.
Подобный подход открывает интересные возможности для задач алгоритмического трейдинга. В реальной торговле решения редко принимаются исключительно на основе исторических ценовых изменений. На выбор действий влияют и дополнительные факторы: текущая загрузка капитала, структура уже открытых позиций, стадия торговой сессии или общий информационный фон рынка. Совместный анализ последовательности событий и состояния среды позволяет значительно расширить информационную основу модели и приблизить её к реальной логике принятия торговых решений.
В первой статье мы познакомились с архитектурными принципами оригинального фреймворка и проработали возможности его адаптации для задач анализа финансовых рынков. Были рассмотрены ключевые идеи фреймворка OneTrans, а также определены основные направления его практической реализации средствами MQL5.
Во второй статье работа приобрела более прикладной характер. Мы перешли от архитектурного анализа к реализации отдельных компонентов модели. Были разработаны специализированные классы, реализующие ключевые механизмы архитектуры, включая операции многоголового FlashAttention. Кроме того, были подготовлены решения, обеспечивающие эффективное выполнение наиболее ресурсоёмких операций на графических устройствах. Параллельно формировалась структура программных компонентов, позволяющая объединять реализованные элементы в единую вычислительную систему.
Таким образом, к настоящему моменту создана необходимая технологическая база для дальнейшего развития модели. Реализованы основные строительные элементы архитектуры, подготовлены механизмы ускоренных вычислений и сформирована программная инфраструктура, позволяющая интегрировать отдельные нейронные блоки в более сложные структуры.
Архитектура моделей
После реализации отдельных вычислительных компонентов и формирования объекта верхнего уровня фреймворка OneTrans следующим естественным шагом становится построение обучаемых моделей. Теперь необходимо объединить созданные элементы в целостную систему, способную обрабатывать исходные данные и формировать на их основе осмысленное торговое поведение.
Как и ранее, мы остаёмся верны исходной идее проекта — созданию автономного торгового робота, который способен самостоятельно оценивать текущую рыночную ситуацию и принимать торговые решения. Иными словами, наша задача — сформировать систему, которая вырабатывает собственную стратегию действий и адаптируется к изменяющимся условиям рынка.
Для обучения такой стратегии мы используем схему Актёр–Критик, хорошо зарекомендовавшую себя в задачах обучения поведения. В рамках этой схемы используются две взаимосвязанные модели: Актёр формирует действие, а Критик оценивает качество принятых решений и направляет процесс обучения.
Использование фреймворка OneTrans позволяет внести в такую архитектуру одно важное упрощение. В классических системах обучения с подкреплением наблюдаемое состояние среды обычно предварительно обрабатывается отдельным Энкодером — специализированным блоком, который преобразует исходные данные в компактное представление, удобное для дальнейшего анализа. Ранее мы выделяли его в отдельную модель, результаты работы использовали Актёр и Критик в качестве исходных данных.
В данном случае необходимость в подобном промежуточном компоненте исчезает. Архитектура OneTrans изначально рассчитана на совместный анализ последовательных данных и контекстных признаков среды, не представленных временным рядом. Благодаря этому динамика рынка и текущие условия торговли могут анализироваться непосредственно внутри единой модели.
Фактически функции энкодера состояния окружающей среды естественным образом интегрируются в архитектуру Актёра. История рыночных событий и контекст торговой среды образуют единое входное пространство модели, которое обрабатывается общим механизмом внимания. В результате система получает целостное представление анализируемой ситуации без необходимости вводить дополнительный специализированный блок кодирования состояния.
Архитектура обучаемых моделей формируется в методе CreateDescriptions, который создаёт и заполняет описания слоёв для двух нейронных сетей — Актёра и Критика. Метод получает ссылки на массивы описаний слоёв и последовательно формирует структуру обеих моделей.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Работа начинается с подготовки массивов actor и critic, которые будут хранить последовательность описаний нейронных слоёв. Если соответствующие объекты ещё не созданы, метод инициализирует их. Далее выполняется очистка массивов, после чего начинается построение архитектуры.
Модель Актёра начинается с входного слоя, принимающего полный набор признаков состояния среды.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) DeleteObjAndFalse(descr); iLatentLayer = 0;
Размер входного пространства определяется суммой описаний исторических баров и дополнительных характеристик торговой среды. Таким образом на вход модели подаётся объединённое представление последовательности рыночных наблюдений и контекстных признаков.
Ключевым элементом архитектуры является следующий слой СNeuronOneTrans. Именно он реализует основную идею рассматриваемого фреймворка.
//--- layer 1 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronOneTrans; { if(ArrayResize(descr.windows, BarDescr + 4) < (BarDescr + 4)) ReturnFalse; ArrayFill(descr.windows, 0, BarDescr, HistoryBars); descr.windows[BarDescr] = 4; // Account descr.windows[BarDescr + 1] = 5; // Positions descr.windows[BarDescr + 2] = 4; // Time label descr.windows[BarDescr + 3] = EmbeddingSize; // Output dimension } { uint temp[] = {BarDescr, // Sequence units NActions / 3 // Output units }; if(ArrayCopy(descr.units, temp, 0, 0, temp.Size()) < int(temp.Size())) ReturnFalse; } descr.step = NHeads; descr.count = StackSize; descr.layers = 12; // Inside layers descr.window_out = EmbeddingSize; // Inside embedding's size descr.variables = NExperts; // Candidates descr.probability = TopK; // Top-K descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) DeleteObjAndFalse(descr); iLatentLayer++; uint count = prev_count = descr.units[1]; uint prev_out = descr.windows[BarDescr + 3]; uint window = prev_out;
В рамках этого слоя происходит совместная обработка двух типов информации: последовательности рыночных данных и набора контекстных признаков среды.
Для последовательной части исходных данных используется окно размером HistoryBars, соответствующее глубине анализируемой рыночной истории. Дополнительные окна выделяются для описания состояния счёта, открытых позиций и временных характеристик торговой среды. В результате модель получает возможность анализировать динамику рынка и контекст принятия решения в едином вычислительном пространстве.
Слой OneTrans формирует набор латентных представлений, соответствующих различным контекстам торговых действий. В рассматриваемой конфигурации таких контекстов два — контекст покупки и продажи. Каждый из них описывает собственное пространство параметров будущего торгового решения.
В представленном описании архитектуры модели число таких контекстов задаётся через макроподстановку NActions/3. Деление на три здесь имеет вполне прикладной смысл. Каждое потенциальное действие на рынке описывается тремя параметрами — объёмом позиции (Lot), уровнем фиксации прибыли (Take Profit) и уровнем ограничения риска (Stop Loss).
В текущей реализации это приводит к формированию двух базовых вариантов поведения системы — открытия длинной и короткой позиций. Механизм OneTrans обрабатывает исходные данные и формирует для каждого такого контекста собственное латентное представление. Эти представления можно рассматривать как внутренние сценарии действий, в которых модель оценивает возможные комбинации объёма позиции и уровней управления риском.
Полученные латентные векторы затем передаются в блок SpikeConvBlock. Этот компонент выполняет агрегацию полученных признаков и преобразует их в компактное представление фиксированной размерности.
//--- layer 2 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronSpikeConvBlock; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; descr.window_out = (LatentCount + prev_count - 1) / prev_count; descr.variables = 1; descr.batch = BatchSize; descr.optimization = ADAM; if(!actor.Add(descr)) DeleteObjAndFalse(descr);
Далее данные поступают в последовательность полносвязных слоёв, где формируется параметрическое описание распределения возможных действий модели. На этом этапе модель получает всю необходимую информацию для описания пространства действий в каждом торговом контексте.
//--- layer 3 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) DeleteObjAndFalse(descr); //--- layer 4 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) DeleteObjAndFalse(descr);
На завершающем этапе архитектуры Актёра используется вариационный слой CNeuronVAEOCL, выполняющий сэмплирование действий из заданного распределения.
//--- layer 5 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) DeleteObjAndFalse(descr);
Для каждого торгового контекста генерируются три значения — объём позиции (Lot), уровень фиксации прибыли (Take Profit) и уровень ограничения убытка (Stop Loss). На начальном этапе обучения это сэмплирование даёт модели возможность активно изучать пространство действий, проверяя разные комбинации параметров. По мере обучения параметры распределения сужаются, и выбор действий постепенно переходит от случайного к осмысленному, соответствующему эффективной торговой стратегии.
Далее сэмплированные значения проходят через сверточный слой СNeuronConvOCL, который согласовывает параметры между собой и приводит их в допустимый диапазон значений с помощью функции активации.
//--- layer 6 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) DeleteObjAndFalse(descr);
В итоге латентные представления модели превращаются в конкретные, корректные и пригодные к исполнению торговые решения.
Модель Критика предназначена для оценки качества действий, которые формирует Актёр, с учётом текущей рыночной ситуации. На вход Критика подаётся вектор действий, а также латентное состояние того же Актёра, сформированное на выходе слоя OneTrans. Это ключевое отличие. Критик оценивает действия в полной взаимосвязи с текущей динамикой рынка и параметрами торговой среды.
Первый полносвязный слой принимает вектор действий Актёра и служит базой для формирования признаков, необходимых для последующей оценки.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) DeleteObjAndFalse(descr);
Следующий слой реализован как механизм перекрёстного внимания CNeuronMHCrossFAT. Здесь каждый элемент вектора действий сопоставляется с соответствующим фрагментом латентного состояния Актёра. В результате Критик получает контекстуально обогащённое представление действий, отражающее, как конкретные торговые решения соотносятся с текущей рыночной ситуацией и признаками торговой среды.
//--- layer 1 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronMHCrossFAT; { uint temp[] = {3, // Inputs window EmbeddingSize, // Key Dimension window, // Cross window EmbeddingSize // Embedding size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {NActions / 3, // Query units count // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = NHeads; // Heads descr.batch = 1e4; descr.layers = NExperts; // Candidates descr.variables = TopK; // Top-K descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) DeleteObjAndFalse(descr);
Далее информация проходит через несколько сверточных блоков SpikeConvBlock, которые агрегируют признаки и формируют компактное латентное пространство, готовое к финальной оценке.
//--- layer 2 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronSpikeConvBlock; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = EmbeddingSize; descr.variables = 1; descr.batch = BatchSize; descr.optimization = ADAM; if(!critic.Add(descr)) DeleteObjAndFalse(descr); //--- layer 4 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronSpikeConvBlock; descr.count = NActions / 3; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = EmbeddingSize; descr.variables = 1; descr.batch = BatchSize; descr.optimization = ADAM; if(!critic.Add(descr)) DeleteObjAndFalse(descr);
При этом использование окон без перекрытия позволяет проводить независимую обработку длинных и коротких позиций. Каждый блок анализирует соответствующий торговый контекст отдельно, сохраняя критически важную информацию о взаимозависимости действий Актёра с рыночной ситуацией, не смешивая сигналы между различными типами позиций. Эта независимость обеспечивает более точную оценку и помогает Критику формировать корректные сигналы обучения для разных торговых сценариев.
После сверточных блоков данные поступают в последовательность полносвязных слоёв, где латентное представление преобразуется в итоговые параметры оценки.
//--- layer 5 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = SIGMOID; descr.batch = BatchSize; descr.optimization = ADAM; if(!critic.Add(descr)) DeleteObjAndFalse(descr); //--- layer 6 if(!(descr = new CLayerDescription())) DeleteObjAndFalse(descr); descr.type = defNeuronBaseOCL; prev_count = descr.count = NRewards; descr.activation = None; descr.batch = BatchSize; descr.optimization = ADAM; if(!critic.Add(descr)) DeleteObjAndFalse(descr); //--- return true; }
Один из слоёв формирует скрытое латентное пространство фиксированной размерности, а завершающий слой выдаёт оценку ожидаемого вознаграждения для каждого действия Актёра. Эта оценка становится сигналом обучения, позволяя Актёру корректировать свои действия и постепенно переходить от случайных проб к осмысленным торговым решениям.
Таким образом, архитектура Критика полностью опирается на вектор действий Актёра и его латентное состояние, объединяющее рыночную динамику и контекст принятия решения. Обработка через перекрёстное внимание и сверточные блоки обеспечивает точную оценку действий, позволяя модели последовательно сужать пространство сэмплирования и концентрироваться на оптимальных торговых решениях.
Метод CreateDescriptions формирует две взаимосвязанные модели. Актёр анализирует состояние рынка и формирует торговые действия, тогда как Критик оценивает качество этих действий с учётом рыночного контекста. Использование фреймворка OneTrans позволяет встроить анализ последовательных рыночных данных и контекстных признаков среды непосредственно в архитектуру Актера, что упрощает общую структуру системы и избавляет от необходимости вводить отдельный энкодер состояния.
Обучение моделей
Следующим этапом после формирования архитектуры моделей становится их обучение. Стоит отметить, что изменение числа обучаемых моделей и структуры исходных данных повлекло за собой соответствующие корректировки в алгоритмах программ обучения и тестирования. Эти изменения требуют гибкости и точного согласования всех компонентов системы.
Как и ранее, обучение планируется проводить в два этапа — офлайн и онлайн. На первом этапе мы не создаём отдельную обучаемую выборку, вместо этого обучение осуществляется непосредственно на фактических исторических данных, загружаемых из терминала MetaTrader 5. Такой подход позволяет моделям сразу работать с реалистичными рыночными условиями, формируя собственные стратегии на основе уже произошедших событий, без искусственного разбиения данных и позволяет гибко менять период обучения.
Основным инструментом на данном этапе выступает советник Study.mq5. В рамках статьи мы рассмотрим лишь метод Train, который оживляет модели Актёра и Критика на исторических данных, погружая их в прошлое рынка, как в учебную лабораторию.
void Train(void) { int start = iBarShift(Symb.Name(), TimeFrame, Start); int end = iBarShift(Symb.Name(), TimeFrame, End); int bars = CopyRates(Symb.Name(), TimeFrame, 0, start, Rates);
Сначала алгоритм подготавливает основу: определяет количество баров в диапазоне обучающей выборки, заданной пользователем, загружает котировки и индикаторы, такие как RSI, CCI, ATR и MACD.
if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } //--- int count = -1; bool calculated = false; do { calculated = (RSI.BarsCalculated() >= bars && CCI.BarsCalculated() >= bars && ATR.BarsCalculated() >= bars && MACD.BarsCalculated() >= bars ); Sleep(100); count++; } while(!calculated && count < 100); if(!calculated) { PrintFormat("%s -> %d The training data has not been loaded", __FUNCTION__, __LINE__); ExpertRemove(); return; } RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Алгоритм аккуратно проверяет готовность каждого индикатора и только после полной уверенности в корректности данных переходит к обучению. Благодаря многопоточности терминала MetaTrader 5, этот процесс не мешает другим советникам и операциям.
После загрузки данных и индикаторов, они приводятся в формат, удобный для обработки. Корректируется количество баров с учётом длины истории и прогнозного окна. Если итоговое количество баров оказывается отрицательным, метод завершает работу, так как обучение на неполных данных было бы бессмысленным.
if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } bars -= end + HistoryBars + NForecast; if(bars < 0) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Далее создаются локальные буферы для хранения состояния модели, целевых действий и промежуточных результатов. Здесь же определяется контрольный флаг Stop, который позволит корректно завершить обучение в случае ошибок.
vector<float> result, target, neg_target; bool Stop = false;
Непосредственно обучение моделей реализуется через систему вложенных циклов. Внешний цикл отвечает за эпохи, количество которых задаёт пользователь.
uint ticks = GetTickCount(); //--- for(int epoch = 0; (epoch < Epochs && !IsStopped() && !Stop); epoch ++) { if(!cActor.Clear() || !cCritic.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Внутренний цикл проходит шаг за шагом по историческим данным. На каждом шаге создаются буферы состояния, включающие текущий баланс, открытые позиции, временные метки и небольшую часть будущего ценового движения.
for(int posit = start - HistoryBars - NForecast - 1; posit >= end; posit--) { if(!CreateBuffers(posit, GetPointer(bState), GetPointer(bTime), Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } const vector<float> account = SampleAccount(GetPointer(bState), datetime(bTime[0]), MaxBalance, MinBalance); const vector<float> target_action = OraculAction(account, Result); if(!bState.AddArray(account)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Стоит подчеркнуть, что на стадии офлайн-обучения модель фактически не совершает реальных торговых операций. Все открытые позиции и параметры состояния счета лишь сэмплируются в пределах диапазона, заданного пользователем. Таким образом, Актёр формирует вектор действий и латентное состояние на основе подготовленных данных, включая историю цен и контекст торговой среды, не влияя на реальный баланс и не подвергая риску средства пользователя. Это позволяет безопасно исследовать пространство возможных действий и выстраивать осмысленные стратегии, прежде чем переходить к онлайн-обучению.
После подготовки исходных данных выполняется прямой проход через Актёра.
//--- Feed Forward if(!cActor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Модель оценивает текущую ситуацию и генерирует вектор действий, сэмплируя возможные стратегии.
Критик получает на вход вектор действий, сформированный Актёром, и его латентное состояние.
if(!cCritic.feedForward(GetPointer(cActor), -1, GetPointer(cActor), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Сверточные блоки и механизм внимания позволяют критически оценивать каждое действие, при этом длинные и короткие позиции обрабатываются независимо, что предотвращает смешение оценок.
После получения прогнозных значений мы переходим к непосредственному обучению моделей. На этом этапе Актёр уже сформировал вектор действий для конкретного исторического состояния. Но в отличие от Актёра, мы точно знаем, как затем изменилась цена в анализируемом периоде и какой финансовый результат могли бы дать эти действия. Используя эти данные, вычисляем фактическое вознаграждение.
//--- Study cActor.getResults(Action); double equity = account[2] * account[0] * EtalonBalance / (1 + account[1]); double reward = CheckAction(Action, equity, posit - NForecast + 1) / EtalonBalance;
Следующий шаг — обратное распространение ошибки. Критик корректирует свои параметры, минимизируя расхождение между собственной оценкой и фактическим вознаграждением, которое мы нашли выше.
Result.Clear(); if(!Result.Add(float(reward))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.backProp(Result, GetPointer(cActor), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее процесс обучения выходит за рамки случайного исследования пространства действий Актёра. Используя известное нам последующее ценовое движение, мы формируем псевдо идеальное действие Оракула, которое отражает оптимальные решения для конкретного состояния. Это действие передаётся Актёру в качестве эталонного сигнала.
//--- Oracul if(!Action.AssignArray(target_action)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } reward = CheckAction(Action, equity, posit - NForecast + 1) / EtalonBalance; if((MathRand() % ActorUpdate) == 0 || reward > 0) if(!cActor.backProp(Action, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Предложенный алгоритм позволяет Актёру корректировать свои градиенты не только на основе оценки Критика, но и опираясь на идеальный ориентир. Обучение становится более целенаправленным. Актёр постепенно учится выбирать действия, приближённые к оптимальным, сокращая случайность и повышая согласованность стратегий с исторически успешными результатами.
Аналогичным образом расширяются знания Критика. Для оценки он получает действие Оракула как эталон и корректирует свои параметры в соответствии с этим сигналом. Такой подход позволяет Критику постепенно расширять область своих оценок, смещая их в зону положительных вознаграждений. Благодаря этому модель не только точнее предсказывает эффективность действий Актёра, но и формирует более устойчивое понимание того, какие решения приводят к положительному финансовому результату, ускоряя обучение и повышая согласованность стратегий.
if(!cActor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime)) || !cCritic.feedForward(Action, 1, false, GetPointer(cActor), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Result.Update(0, float(reward))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.backProp(Result, GetPointer(cActor), LatentLayer) || !cActor.backPropGradient((CBufferFloat*)GetPointer(bTime), (CBufferFloat*)NULL, LatentLayer, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
По мере освоения рынка область сэмплирования сужается, и действия Актера становятся осмысленными и согласованными с динамикой рынка.
На протяжении обучения метод периодически выводит прогресс и ошибки моделей, позволяя наблюдать, как Актёр и Критик вживаются в рынок и постепенно формируют устойчивую торговую стратегию.
if(GetTickCount() - ticks > 500) { double percent = (epoch + 1.0 - double(posit - end) / (start - end - HistoryBars - NForecast)) / Epochs * 100.0; string str = ""; str += StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Actor", percent, cActor.getRecentAverageError()); str += StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Critic", percent, cCritic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Когда все эпохи и шаги завершены, метод выводит итоговые значения ошибок Актёра и Критика. После чего аккуратно завершает работу, оставляя подготовленные модели готовыми к следующему этапу — онлайн-обучению и реальному анализу рынка.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", cActor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", cCritic.getRecentAverageError()); ExpertRemove(); //--- }
Так метод Train создаёт безопасное и живое обучение. Актёр и Критик взаимодействуют между собой и с историческими данными, постепенно формируя устойчивую торговую стратегию, которая учитывает одновременно динамику рынка и контекст торговой среды. Фрагменты будущего ценового движения служат ориентиром для оценки действий. А сэмплирование параметров счета обеспечивает практически безграничное расширение обучающей выборки.
Даже на одном и том же участке исторических данных модель каждый раз получает новый контекст для принятия решений. Это создаёт разнообразие ситуаций, позволяя Актёру безопасно исследовать пространство возможных действий и вырабатывать осмысленные стратегии, не подвергаясь риску реальных торговых операций. В результате на выходе мы получаем подготовленные модели, способные к онлайн-адаптации, когда они смогут анализировать реальные рыночные данные в реальном времени и принимать осмысленные решения, продолжая логику, заложенную в архитектуре OneTrans.
Подобные изменения были внесены в программы онлайн-обучения (StudyOnline.mq5) и тестирования (Test.mq5). Детали их работы мы оставляем для самостоятельного изучения. Полный код всех программ, использованных при подготовке данной статьи, представлен во вложении, что позволяет читателю полностью проследить реализацию алгоритмов и повторить эксперименты при необходимости.
Тестирование
И вот мы подошли к финальному этапу проекта. Архитектура моделей полностью собрана, все модули согласованы и готовы к совместной работе. Программы обучения подготовлены. Настало время проверить, как система ведёт себя в реальных рыночных условиях.
Офлайн-обучение стартовало на исторических данных EURUSD таймфрейм H1 за весь 2025 год. Эта фаза выполняла роль тренировочного полигона. Модель училась выявлять закономерности в поведении цены, различать импульсные движения и периоды консолидации, а также корректно интерпретировать сочетание динамических и контекстных характеристик. На этом этапе создавалось базовое представление о состоянии рынка.
Следующий этап — онлайн-обучение в тестере стратегий MetaTrader 5. Он перевёл систему в режим адаптации в реальном времени. Параметры моделей динамически корректировались по мере поступления новых данных. Система училась различать короткие импульсы и длинные тренды, учитывать периоды коррекции и смену рыночных сценариев, при этом сохраняя накопленный опыт.
Финальная проверка проводилась на новых данных за период Январь–Февраль 2026 года. Это был полноценный тест, где модели не могли подстраиваться под уже изученные события. Здесь проявилась способность OneTrans выделять значимые паттерны и принимать адекватные торговые решения, демонстрируя эффективность совместного анализа исторических и контекстных признаков в единой архитектуре.
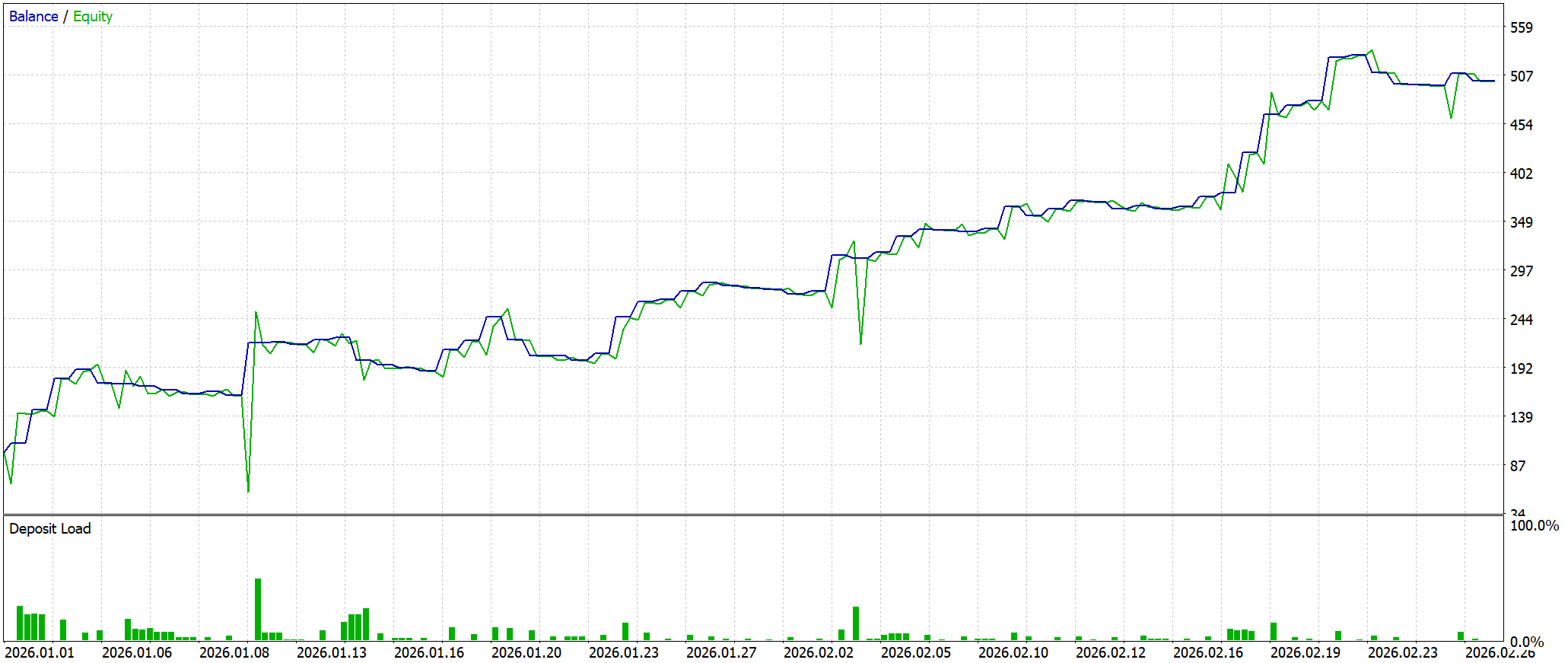
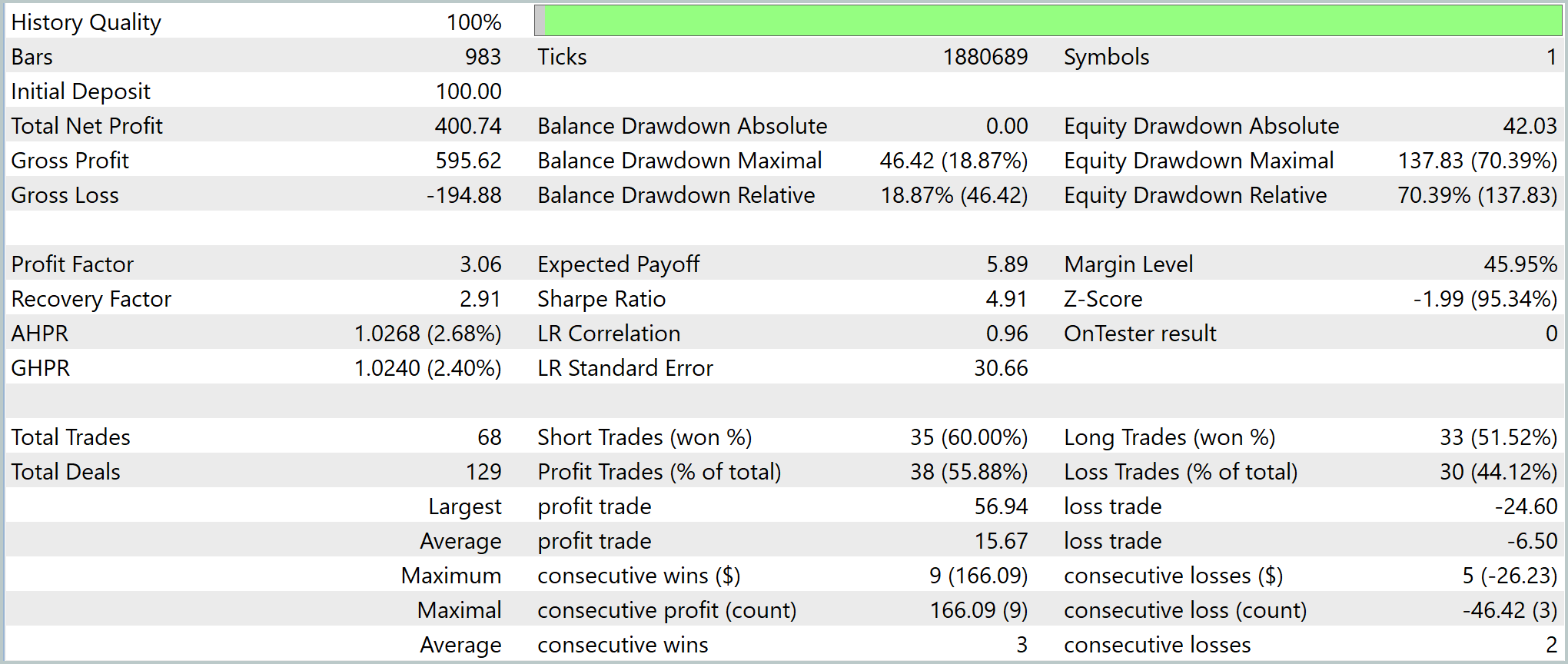
Тестирование показало, что стратегия на исторических данных за период тестирования увеличила депозит со 100 USD до 500,74 USD. Доходность около 400%. Тест проводился на реальных тиках, кривая капитала демонстрирует ступенчатый рост. Сначала накопление. Затем линейный рост и ускорение на тренде, с последующей коррекцией.
Показатели стратегии высокие. Profit Factor 3,06, средняя прибыль на сделку 5,89 USD, отношение прибыль/убыток 2,41. Сделки стабильны: 68 операций, выигрыши 55,9%. При этом short-позиции работают лучше long. Максимальная серия выигрышей 9, проигрышей 5, что подтверждает системность сигналов.
Основные риски — высокая Equity-просадка (~70%) и возможные глубокие плавающие убытки. В целом стратегия высокодоходная, с хорошей стабильностью и потенциалом при контроле риска.
Заключение
Завершая работу, можно отметить, что реализация фреймворка OneTrans средствами MQL5 продемонстрировала его практическую ценность. Созданная архитектура моделей успешно объединила анализ рыночной динамики и контекстных признаков, исключив необходимость отдельного энкодера состояния, что позволило существенно упростить систему и повысить эффективность обработки информации.
Использование схемы Актёр–Критик обеспечило стабильное обучение стратегии. Актёр формирует осмысленные действия, а Критик корректно оценивает их эффективность, учитывая как исторические данные, так и текущий контекст торговли. Такой подход позволил системе адаптироваться к изменяющимся условиям рынка и формировать устойчивые торговые решения без ручного вмешательства.
Тестирование показало доходность стратегии, согласованность сигналов и способность выделять значимые рыночные паттерны. Вместе с тем, сохранённая гибкость модели открывает возможность дальнейшей оптимизации управления капиталом и масштабирования на другие инструменты. В итоге реализация OneTrans в MQL5 подтверждает концептуальные преимущества фреймворка и создаёт практическую основу для построения автономных, адаптивных торговых систем.
Ссылки
- OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Добрый вечер, Дмитрий!
Вероятно в код модуля Test надо внести изменения:
2026.03.11 19:48:35.320 TestOneTrans (EURUSD,M5) OpenBLAS threads limit is 7
2026.03.11 19:48:35.333 TestOneTrans (EURUSD,M5) OneTransEnc.nnw
2026.03.11 19:48:35.333 TestOneTrans (EURUSD,M5) Error at CNet::Load line 12454
2026.03.11 19:48:35.333 TestOneTrans (EURUSD,M5) Cann't load pretrained models
Добрый вечер, Дмитрий!
Вероятно в код модуля Test надо внести изменения:
2026.03.11 19:48:35.320 TestOneTrans (EURUSD,M5) OpenBLAS threads limit is 7
2026.03.11 19:48:35.333 TestOneTrans (EURUSD,M5) OneTransEnc.nnw
2026.03.11 19:48:35.333 TestOneTrans (EURUSD,M5) Error at CNet::Load line 12454
2026.03.11 19:48:35.333 TestOneTrans (EURUSD,M5) Cann't load pretrained models
Добрый вечер, Андрей.
Архив в статье обновлен.
Попробовал OneTrans на AMD Radeon RX 7900 XTX. Проблема: максимальный размер work-group на AMD = 256 (у NVIDIA = 1024). Без изменений — OpenCL error 65536 (SparseMatMulGrad, local = {1, 384, 1}).
Мое решение: ограничил GetMaxLocalSize до 256 и добавил ClampLocal() в макрос kernelExecuteLoc.
Study.mq5 отработал 100 эпох (~36 часов), ошибка Actor упала с 0.15 до 0.035. Но выходы Actor одинаковые на каждом баре: Buy≈0.005, Sell≈0.005, TP≈0.12, SL≈0.13 — нет разницы между трендом и флэтом. В результате — ноль сделок в Test.mq5.
Вопрос: может ли ограничение work-group size до 256 нарушить корректность обучения? Или после Study такие uniform-выходы — нормально, и дифференциация приходит только после StudyOnline?
Спасибо!