
Нейросети в трейдинге: Многодоменная архитектура анализа финансовых данных (Окончание)

Введение
Новизна фреймворка MDL в том, что он переносит контекст из роли внешней надстройки в саму ткань вычислений. В оригинальной работе сценарий и задача представлены как специализированные токены, встроенные в единое токенизированное пространство вместе с признаками. Для этого используется модуль Unified Information Tokenization, который приводит признаки, сценарии и задачи к общему формату. После чего модель организует их взаимодействие через три связанных механизма: Feature Token Self-Iteration, Domain-Feature Attention и Domain-Fused Aggregation. Такая схема позволяет MDL последовательно активировать релевантные части параметрического пространства и обрабатывать различные распределения в едином каркасе.

Это важно для решения прикладных финансовых задач. Рынок не любит прямолинейности: один и тот же сигнал в разных режимах может работать по-разному, а иногда и с точностью до наоборот. Поэтому в предыдущих двух статьях был выбран путь содержательной адаптации архитектуры MDL средствами MQL5.
Вначале сформулировали логику применения MDL к финансовым данным как к многодоменной среде. Затем разобрали и реализовали ключевые компоненты: адаптивной генерации сценарных токенов, Unified Tokenizer, Domain-Aware Attention. В этой конструкции контекст и исходные данные не проходят одинаковые преобразования, они обрабатываются параллельно, но затем сходятся в едином токенизированном вычислительном конвейере.
На текущем этапе фундамент уже заложен. Реализованы единый способ представления разнородных данных, механизм контекстно-зависимого внимания и архитектурная основа для последовательного усложнения модели без потери структурной ясности. Это позволяет перейти от отдельных узлов к построению целостной модели MDL средствами MQL5. Важно добиться согласованной работы всех компонентов в условиях онлайн-анализа рыночных данных.
Модуль агрегации задачи-сценарии
Мы подошли к этапу, когда основные компоненты фреймворка MDL уже реализованы. И прежде чем переходить к построению объекта верхнего уровня, полезно еще раз вернуться к авторской схеме и посмотреть на нее как на рабочую инженерную конструкцию.
В оригинальной архитектуре отчетливо видны три магистрали потока информации: признаки, сценарии и задачи. При этом признаки формируют базовый слой представления. Сценарии и задачи выступают как контекстные токены, которые включаются в процесс взаимодействия наравне с остальными элементами модели. Такой токенизированный подход и задает характерный стиль MDL — контекст здесь встраивается в сам ход вычислений.
Особый интерес вызывает практическое сходство двух контекстных магистралей — сценариев и задач. В обоих случаях авторы используют механизм Domain-Feature Attention, после которого следуют собственные Per-Token FFN блоки для дальнейшего преобразования токенов. Иными словами, сценарии и задачи проходят почти одинаковую вычислительную траекторию.
Из этого следует важный практический вывод: ветви сценариев и задач желательно рассматривать как единый контекстный поток. Это удобно для выполнения вычислений на стороне OpenCL-контекста. Совместная организация вычислений позволяет сократить накладные расходы на обслуживание раздельных ветвей, упростить маршрутизацию данных и лучше загрузить вычислительные ресурсы при онлайн-анализе рыночной ситуации. Это уже не вопрос эстетики архитектуры, а вопрос скорости реакции модели. В рыночной среде задержка часто обходится дороже лишней строки кода.
Но здесь возникает главное отличие, которое не позволяет напрямую объединить сценарии и задачи. В магистрали задач присутствует модуль Domain-Fused Aggregation. В оригинальной работе авторы предлагают сначала выбрать релевантные сценарные токены для конкретной задачи, затем усреднить их и суммировать полученное агрегированное представление с задачным токеном. Тем самым задача получает адресно собранное сценарное сопровождение, что сохраняет привязку к конкретной комбинации сценарий–задача и делает итоговое предсказание устойчивым к различиям между доменами.
Но мы не привыкли останавливаться при первом же ограничении — тем более когда оно носит архитектурный характер. Если внимательно посмотреть на роль Domain-Fused Aggregation, становится ясно: проблема в том, что для токенов задач требуется дополнительный этап уточнения на основе сценарного контекста.
Вместо раздельной реализации ветвей имеет смысл ввести промежуточный уровень абстракции. Построим объект, который принимает на вход объединённый тензор токенов сценариев и задач. Внутри выполняются две функции. Сначала выделяем задачи как подмножество токенов и для каждой из них формируем агрегированное представление релевантных сценариев. Затем выполним их слияние. Тем самым реализуем логику Domain-Fused Aggregation уже внутри единого потока вычислений.
Таким образом встраиваем критический элемент архитектуры в единый контекстный канал. Сценарные токены продолжают проходить свой путь без изменений, сохраняя исходное представление домена. Токены задач, в свою очередь, получают уточнение за счёт агрегированного сценарного окружения. В результате на выходе формируется конкатенированный тензор, где одна часть содержит неизменённые сценарии, а другая — уже уточнённые задачи, готовые к дальнейшей обработке.
Такой подход даёт сразу несколько практических преимуществ. Во-первых, сохраняем архитектурную точность относительно оригинального MDL, не жертвуя механизмом агрегации сценарий–задача. Во-вторых, делаем вычислительный граф компактнее и получаем естественную параллелизацию: единый тензор и единый поток вычислений лучше ложатся на модель OpenCL-исполнения. Снижаем накладные расходы и повышаем пропускную способность при работе в реальном времени.
Предложенный подход логично оформить в виде отдельного вычислительного узла, который инкапсулирует логику взаимодействия токенов задач и сценариев. Этот узел реализован в классе CNeuronDomainFused, унаследованном от CNeuronPerTokenFFN.
class CNeuronDomainFused : public CNeuronPerTokenFFN { protected: CNeuronBaseOCL cTasks; CNeuronBaseOCL cScenarios; CLayer cSelector; CNeuronBaseOCL cScenariosToTask; CNeuronBaseOCL cConcat; //--- //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronDomainFused(void) {}; ~CNeuronDomainFused(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint tasks, uint scenarios, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual int Type(void) override const { return defNeuronDomainFused; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; };
Внутренняя структура класса отражает двухуровневую организацию, о которой шла речь выше. Объекты cTasks и cScenarios отвечают за декомпозицию объединённого тензора на две логические части. Это важный момент. На уровне интерфейса работаем с единым потоком, но внутри фиксируем семантику токенов. Такой подход сохраняет компактность вычислений без потери управляемости.
Блок cSelector выполняет функцию отбора релевантных сценариев для каждой задачи. Здесь важна локальность отбора. Каждая задача получает собственное контекстное окружение.
По результатам работы селектора токены сценариев агрегируются в cScenariosToTask с последующим переносом в пространство задач. Здесь реализуется логика Domain-Fused Aggregation. Это управляемое слияние, в котором сохраняется структура признаков задач и сценариев.
Метод инициализации задаёт архитектуру блока без лишней суеты, но с чёткой логикой.
bool CNeuronDomainFused::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint tasks, uint scenarios, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPerTokenFFN::Init(numOutputs, myIndex, open_cl, dimension, tasks + scenarios, embed_size, candidates, topK, optimization_type, batch)) ReturnFalse;
Сначала управление передается родительскому классу. Это важный момент. Сразу фиксируем, что узел работает с уже объединённым потоком контекстной информации. Иначе говоря, фундамент закладывается заранее, без архитектурной импровизации на последующих этапах.
Далее метод аккуратно разделяет этот поток на две самостоятельные ветви. Объект cTasks берет на себя токены задач, а cScenarios — токены сценариев.
uint index = 0; if(!cTasks.Init(0, index, OpenCL, dimension * tasks, optimization, iBatch)) ReturnFalse; cTasks.SetActivationFunction(None); index++; if(!cScenarios.Init(0, index, OpenCL, dimension * scenarios, optimization, iBatch)) ReturnFalse; cScenarios.SetActivationFunction(None);
Для обеих ветвей функция активации отключается. И это сделано осознанно. На данном этапе не нужно подкрашивать данные нелинейностью. Здесь важно сохранить исходную структуру токенов и подготовить их к дальнейшему взаимодействию.
Следующий шаг — инициализация cSelector. Этот объект играет роль связующего звена между задачами и сценарием. Внутри него создаются два блока CNeuronFieldAwareConv.
cSelector.Clear(); cSelector.SetOpenCL(OpenCL); index++; CNeuronFieldAwareConv* conv = new CNeuronFieldAwareConv(); if(!conv || !conv.Init(0, index, OpenCL, dimension, 2 * dimension, tasks, embed_size, candidates, topK, optimization, iBatch) || !cSelector.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(SoftPlus); index++; conv = new CNeuronFieldAwareConv(); if(!conv || !conv.Init(0, index, OpenCL, 2 * dimension, scenarios, tasks, embed_size, candidates, topK, optimization, iBatch) || !cSelector.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(None); index++;
Здесь начинается настоящая работа по сопоставлению контекста. Первый сверточный блок формирует промежуточное представление, в котором учитывается поле задач и подготавливается пространство для сравнения. Второй углубляет это сопоставление и помогает выделить действительно значимые зависимости между задачами и сценариями. Это целенаправленный поиск релевантного контекста.
После этого подключается CNeuronSparseSoftMax. Его роль особенно важна. Он выбирает наиболее значимые сценарии для каждой задачи. Тем самым модель не распыляет внимание на все подряд, а работает точечно, по существу.
CNeuronSparseSoftMax* sofmax = new CNeuronSparseSoftMax(); if(!sofmax || !sofmax.Init(0, index, OpenCL, tasks, scenarios, (scenarios + 2) / 3, optimization, iBatch) || !cSelector.Add(sofmax)) DeleteObjAndFalse(sofmax);
В финансовой задаче это особенно ценно. Рынок редко прощает широкие, но размытые решения, здесь выигрывает тот, кто умеет быстро отсеивать шум и удерживать внимание на действительно полезных сигналах.
Затем инициализируется cScenariosToTask. Этот модуль получает уже отобранный сценарный контекст и переносит его в пространство задач.
index++; if(!cScenariosToTask.Init(0, index, OpenCL, dimension * tasks, optimization, iBatch)) ReturnFalse; cScenariosToTask.SetActivationFunction(None);
Именно на этом этапе сценарии перестают быть сопутствующим фоном и начинают уточнять задачу. Можно сказать, что здесь контекст становится прикладным инструментом. Он начинает работать на смысл, а не объем.
Завершает сборку cConcat, который формирует итоговый тензор. В него входят исходные сценарии и уже уточненные задачи.
index++; if(!cConcat.Init(0, index, OpenCL, dimension * (tasks + scenarios), optimization, iBatch)) ReturnFalse; cConcat.SetActivationFunction(None); //--- return true; }
Получается удобная конструкция. Сценарии сохраняют собственную структуру, а задачи проходят через механизм контекстного уточнения и возвращаются в общий поток в более зрелом виде. Для следующего уровня модели это полезно, потому что она получает согласованное представление. Контекст учтен и встроен в вычислительный результат.
В итоге метод инициализации выстраивает логику узла по шагам:
- общий поток,
- разбиение на ветви,
- отбор релевантных сценариев,
- уточнение задачи,
- сборка нового представления.
В этом и состоит сильная сторона данного решения. Архитектура не прыгает через ступеньки и не пытается умничать раньше времени.
Алгоритм прямого прохода реализован в методе feedForward.
bool CNeuronDomainFused::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || NeuronOCL.Neurons() < Neurons()) ReturnFalse;
В начале метода сразу проверяем корректность полученного объекта и сопоставляет его размерность с числом нейронов текущего блока. Это базовая, но принципиально важная защита. Узел не должен работать с неполным или некорректным входом.
Далее определяются параметры рабочих тензоров.
uint dimension = GetWindow(); uint tasks = cTasks.Neurons() / dimension; uint scenarios = cScenarios.Neurons() / dimension;
После этого выполняется разделение тензора исходных данных на две части — cTasks и cScenarios.
if(!DeConcat(cTasks.getOutput(), cScenarios.getOutput(), NeuronOCL.getOutput(), dimension * tasks, dimension * scenarios, 1)) ReturnFalse;
На этом этапе данные приобретают свою внутреннюю семантику. Задачи и сценарии получают собственные контуры обработки, не смешиваясь преждевременно в одном вычислительном канале.
Затем начинается работа по отбору релевантных сценариев. Внутренние слои блока cSelector последовательно обрабатывают токены задач и формируют разреженное соответствие между задачами и сценариями.
//--- Selector CNeuronBaseOCL* prev = cTasks.AsObject(); CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cSelector.Total(); i++) { curr = cSelector[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Завершающий слой CNeuronSparseSoftMax выделяет наиболее значимые сценарии для каждой задачи и тем самым задаёт адресный характер последующего уточнения.
Дальше используется SparseMatMul. Здесь уже не рассматриваются все сценарии подряд — берутся только отобранные селектором. Это делает вычисление компактным и содержательным одновременно.
if(prev.Type() != defNeuronSparseSoftMax) ReturnFalse; CNeuronSparseSoftMax* softmax = prev; if(!SparseMatMul(softmax.GetIndexes(), softmax.getOutput(), cScenarios.getOutput(), cScenariosToTask.getOutput(), tasks, softmax.DimensionOut(), scenarios, dimension)) ReturnFalse;
Для каждой задачи формируется агрегированное сценарное представление, которое затем суммируется с токенами соответствующих задач. В результате задача уточняется на основе релевантного контекста, но не подменяется им.
if(!SumAndNormalize(cTasks.getOutput(), cScenariosToTask.getOutput(), cScenariosToTask.getOutput(), dimension, false, 0, 0, 0, 1)) ReturnFalse;
Так в архитектуре MDL и реализуется логика Domain-Fused Aggregation: сценарий не растворяет задачу, а помогает ей раскрыться точнее.
После этого снова собираем поток в единый тензор.
if(!Concat(cScenariosToTask.getOutput(), cScenarios.getOutput(), cConcat.getOutput(), dimension * tasks, dimension * scenarios, 1)) ReturnFalse;
На выходе остаются исходные сценарии и уже уточнённые задачи. Такое разделение сохраняет обе линии информации. Сценарии продолжают нести доменный контекст, а задачи получают дополнительную настройку под него.
Завершается алгоритм вызовом одноименного метода родительского класса. В нем полученное представление проходит токеновую обработку на следующем уровне иерархии.
if(!CNeuronPerTokenFFN::feedForward(cConcat.AsObject())) ReturnFalse; //--- return true; }
В итоге CNeuronDomainFused выступает связующим звеном всей архитектуры. Он снимает противоречие между желанием объединить потоки и необходимостью учитывать их различия. С инженерной точки зрения это аккуратная точка сборки. Раздельные магистрали окончательно сходятся в единый вычислительный процесс, не теряя при этом своей семантики.
Объект верхнего уровня
Теперь, когда все преграды сняты, переходим к построению объекта верхнего уровня. Здесь разрозненные компоненты архитектуры MDL собираются в цельную модель. Отдельные механизмы начинают работать как части единого вычислительного организма.
До этого момента мы последовательно выстраивали внутреннюю логику фреймворка. Сначала выделили базовые токены, затем реализовали контекстные ветви, после этого связали сценарии и задачи через механизм Domain-Fused Aggregation. Это была необходимая подготовка, без которой объект верхнего уровня оказался бы оболочкой, лишенной содержательной опоры. Теперь же у нас есть все компоненты, и можно переходить к их объединению в рабочую архитектуру. Каждый модуль займет свое место и будет выполнять строго определенную роль.
На этом этапе особенно важно не потерять основную идею MDL. Верхний уровень не должен превращаться в механическую сборку слоев ради самой сборки. Его задача куда серьезнее: обеспечить согласованное прохождение данных через все уже реализованные блоки, сохранить смысловую связь между признаками, сценариями и задачами, а затем передать на выход уже структурированное представление рыночной ситуации.
Структура объекта верхнего уровня сразу выдает его назначение.
class CNeuronMDL : public CNeuronPerTokenFFN { protected: CNeuronUnifiedTokenizer cPrepare; CNeuronBaseOCL cLastNonSequence; CLayer cFeatures; CNeuronScenariosToken cScenarios; CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMDL(void) {}; ~CNeuronMDL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint heads, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronMDL; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; };
Компонент cPrepare реализует этап Unified Tokenizer и отвечает за приведение исходных данных к единому токенизированному представлению. Это точка входа модели. Здесь разнородные рыночные данные переводятся в согласованный формат, пригодный для дальнейшей обработки. Ошибка на этом уровне обходится дорого.
Далее следует объект cLastNonSequence, который выполняет более прикладную задачу — выделяет из исходных данных токены задач. На этом этапе отделяем то, что будет интерпретироваться как целевая постановка. Такой подход хорошо согласуется с логикой MDL. Токены задач с самого начала становятся частью вычислительного процесса.
Блок cFeatures формирует магистраль обработки признаков исторических данных. Здесь разворачивается работа с Feature-токенами, включая их последовательное преобразование и подготовку к взаимодействию с контекстом.
Объект cScenarios отвечает за генерацию сценарных токенов. Здесь формируется набор сценариев, отражающих текущее состояние рынка.
Блок cFlow объединяет сценарии и задачи в единый вычислительный поток. Внутри этого блока работают ранее реализованные механизмы, включая CNeuronDomainFused, который обеспечивает сцепление задач с релевантным сценарным контекстом. По сути, cFlow — это операционное ядро модели, где и происходит основная логика MDL.
Метод инициализации объекта собирает модель последовательно.
bool CNeuronMDL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint heads, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(dimensions.Size() <= units_s || layers < 1) ReturnFalse; uint units_ns = dimensions.Size() - units_s;
Алгоритм начинается с проверки полученных параметров. Сразу отсекаются некорректные конфигурации. Число элементов в анализируемой последовательности (units_s) должно быть меньше размера массива dimensions, и модель должна иметь хотя бы один MDL-блок. После этого определяется число задач units_ns — именно здесь происходит фактическое разделение входного пространства на две части: последовательную и контекстную.
Далее инициализируется родительский класс.
if(!CNeuronPerTokenFFN::Init(numOutputs, myIndex, open_cl, embed_size, units_ns, (embed_size + 1) / 2, candidates, topK, optimization_type, batch)) ReturnFalse;
Важно, что в качестве числа токенов передается число задач (units_ns). Это означает, что на верхнем уровне модель ориентируется на токены задач, которые уточняются в процессе анализа данных. Такой ход выглядит сдержанно, но логически точен. Именно задачи становятся точкой сборки архитектуры MDL.
Следующий шаг — cPrepare. Этот блок выполняет полную токенизацию исходных данных: он принимает размерности dimensions и приводит их к единому embedding-пространству.
uint index = 0; if(!cPrepare.Init(0, index, OpenCL, dimensions, units_s + units_ns, embed_size, candidates, topK, optimization, iBatch)) ReturnFalse;
Здесь происходит ключевое преобразование. Сырые данные рынка превращаются в набор токенов, пригодных для дальнейшей обработки внутри MDL.
Сразу после этого инициализируется cLastNonSequence. И вот здесь как раз реализуется выделение задачных токенов.
index++; if(!cLastNonSequence.Init(0, index, OpenCL, embed_size * units_ns, optimization, iBatch)) ReturnFalse; cLastNonSequence.SetActivationFunction(None);
Блок берет токенизированное представление и извлекает из него контекстную часть, формируя набор задач. Активация отключена — важно сохранить исходную структуру без искажений.
Параллельно формируется блок cScenarios, который генерирует сценарные токены на основе последовательной части анализируемых данных (units_s).
index++; if(!cScenarios.Init(0, index, OpenCL, embed_size, units_s, embed_size, scenarios, (embed_size + 1) / 2, candidates, topK, optimization, iBatch)) ReturnFalse; cScenarios.SetActivationFunction(None);
По сути, здесь модель строит контекст. Из временной структуры рынка извлекаются сценарии, которые затем будут использоваться для уточнения задач.
После этого начинается сборка двух магистралей: cFeatures и cFlow. Первая отвечает за анализ признаков исторической последовательности. Вторая — за совместную обработку токенов задач и сценариев.
cFeatures.Clear(); cFlow.Clear(); cFeatures.SetOpenCL(OpenCL); cFlow.SetOpenCL(OpenCL);
Оба блока очищаются и привязываются к OpenCL-контексту, что важно для дальнейшей параллелизации.
Далее добавляются входные буферы для обеих ветвей. В cFeatures помещается представление последовательных токенов, а в cFlow — объединённый поток задач и сценариев.
index++; CNeuronBaseOCL* neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, embed_size * units_s, optimization, iBatch) || !cFeatures.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, embed_size * (units_ns + scenarios), optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
Это точка, где архитектура окончательно расходится на два параллельных контура обработки.
Основная часть метода — цикл по слоям. На каждой итерации в cFeatures добавляется CNeuronFeatureSelfIteration, который последовательно уточняет признаки с учетом их внутренней структуры и накопленной истории.
CNeuronFeatureSelfIteration* feature = NULL; CNeuronDomainAwareAttention* domain = NULL; CNeuronDomainFused* fused = NULL; for(uint i = 0; i < layers; i++) { index++; feature = new CNeuronFeatureSelfIteration(); if(!feature || !feature.Init(0, index, OpenCL, embed_size, units_s, heads, stack_size, (embed_size + 1) / 2, candidates, topK, optimization, iBatch) || !cFeatures.Add(feature)) DeleteObjAndFalse(feature);
Параллельно в cFlow добавляются два блока: CNeuronDomainAwareAttention и CNeuronDomainFused. Первый отвечает за контекстное взаимодействие задач и сценариев с анализируемой исторической последовательностью. Второй — за уточнение токенов задач через Domain-Fused Aggregation.
index++; domain = new CNeuronDomainAwareAttention(); if(!domain || !domain.Init(0, index, OpenCL, embed_size, units_ns + scenarios, heads, embed_size, stack_size * units_s, (embed_size + 1) / 2, candidates, topK, optimization, iBatch) || !cFlow.Add(domain)) DeleteObjAndFalse(domain); index++; fused = new CNeuronDomainFused(); if(!fused || !fused.Init(0, index, OpenCL, embed_size, units_ns, scenarios, (embed_size + 1) / 2, candidates, topK, optimization, iBatch) || !cFlow.Add(fused)) DeleteObjAndFalse(fused); }
Важно, что эти блоки добавляются синхронно. Архитектура растет слоями, а не отдельными фрагментами.
Завершается инициализация добавлением CNeuronAddToStack в ветвь cFeatures.
index++; CNeuronAddToStack* stack = new CNeuronAddToStack(); if(!stack || !stack.Init(0, index, OpenCL, stack_size, embed_size, units_s, optimization, iBatch) || !cFeatures.Add(stack)) DeleteObjAndFalse(stack); //--- return true; }
Этот элемент фиксирует состояние последовательных токенов и позволяет аккумулировать информацию по мере прохождения. В контексте временных рядов это критично. Модель получает возможность учитывать историю без потери структуры.
В результате метод инициализации не просто задает параметры, а буквально собирает архитектуру по шагам.
Метод прямого прохода — это уже полноценный сценарий прохождения данных через архитектуру модуля. Здесь хорошо видно, как ранее реализованные блоки начинают работать согласованно, без разрывов и лишних переходов.
bool CNeuronMDL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPrepare.FeedForward(NeuronOCL)) ReturnFalse;
Алгоритм начинается с вызова Unified Tokenizer, который превращает сырые исходные данные в единый набор токенов. Это точка входа модели. После неё остаётся только нормализованное представление, пригодное для дальнейших операций.
Далее определяется количество слоёв в блоке.
uint layers = cFeatures.Total() - 2;
Это небольшая, но характерная деталь. Архитектура заранее включает служебные элементы, и рабочая глубина извлекается динамически. Такой подход избавляет от жёстких зависимостей и делает модель гибче при конфигурации.
Следующий этап — разделение потока. Токенизированные данные разбиваются на две части: последовательные признаки и контекстные, которые мы уже трактуем как задачи.
//--- Features CNeuronBaseOCL* feature = cFeatures[0]; if(!feature || !DeConcat(feature.getOutput(), cLastNonSequence.getOutput(), cPrepare.getOutput(), feature.Neurons(), cLastNonSequence.Neurons(), 1)) ReturnFalse;
Здесь архитектура впервые разделяет роли данных. До этого всё было единым потоком, теперь появляется семантика.
После этого запускается магистраль признаков. Компоненты cFeatures последовательно обрабатывают данные, передавая результат от слоя к слою.
for(int i = 1; i < cFeatures.Total(); i++) { feature = cFeatures[i]; if(!feature || !feature.FeedForward(cFeatures[i - 1])) ReturnFalse; }
Это базовая линия модели — отвечает за формирование устойчивого представления рынка на уровне признаков. Важно, что здесь накапливается состояние, которое затем будет использоваться в контекстных взаимодействиях.
Параллельно формируются сценарии. Сценарные токены строятся именно из последовательной части данных. Это логично. Сценарий — это функция времени и структуры рынка.
//--- Scenarios if(!cScenarios.FeedForward(cFeatures[0])) ReturnFalse;
Далее начинается сборка общего потока для контекстной обработки. Конкатенируем задачи со сценариями и подаем на вход cFlow.
CNeuronBaseOCL* flow = cFlow[0]; if(!flow || !Concat(cLastNonSequence.getOutput(), cScenarios.getOutput(), flow.getOutput(), cLastNonSequence.Neurons(), cScenarios.Neurons(), 1)) ReturnFalse;
Это важная точка. Именно здесь формируется тот самый объединённый контекстный тензор, с которым дальше работает MDL.
Основная логика разворачивается в цикле. На каждой итерации происходит синхронное взаимодействие двух магистралей. Сначала извлекается текущее состояние признаков. Если слой — это CNeuronFeatureSelfIteration, получаем доступ к стеку через GetStack.
//--- Flow for(uint i = 0; i < layers; i++) { uint shift_domain = i * 2 + 1; uint shift_feature = i + 2; if(!cFeatures[shift_feature]) ReturnFalse; if(cFeatures[shift_feature].Type() == defNeuronFeatureSelfIteration) feature = ((CNeuronFeatureSelfIteration*)cFeatures[shift_feature]).GetStack(); else feature = cFeatures[shift_feature];
Это позволяет учитывать накопленную историю. Аккуратная, но сильная деталь. Модель работает не только с текущим состоянием, но и с его эволюцией.
Затем управление передаётся в cFlow. Сначала вызывается CNeuronDomainAwareAttention, который получает два входа: текущий поток задач+сценариев и состояние признаков анализируемой последовательности.
flow = cFlow[shift_domain]; if(!flow || !flow.FeedForward(cFlow[shift_domain - 1], feature.getOutput())) ReturnFalse;
Здесь происходит контекстное переосмысление — задачи и сценарии смотрят на признаки и уточняют своё взаимодействие. Сразу после этого вызывается CNeuronDomainFused, который завершает цикл, объединяя задачи с релевантными сценариями через механизм Domain-Fused Aggregation.
flow = cFlow[shift_domain + 1]; if(!flow || !flow.FeedForward(cFlow[shift_domain])) ReturnFalse; }
Такой двухшаговый проход внутри каждого слоя повторяет логику оригинального MDL, но уже в инженерной форме. Причём оба шага встроены в единый поток, без лишних копирований и переключений контекста.
После завершения всех слоёв итоговый поток передаётся в родительский класс.
if(!CNeuronPerTokenFFN::feedForward(flow)) ReturnFalse; //--- return true; }
Это финальная стадия, где уже уточнённые и согласованные токены задач проходят нелинейную обработку перед выдачей результата.
В результате CNeuronMDL становится точкой сборки архитектуры. Объединяет токенизацию, обработку признаков, генерацию токенов сценариев и контекстное уточнение задач в единый поток вычислений. Именно на этом уровне фреймворк перестает быть набором идей и превращается в инструмент, готовый к обучению и работе с реальными рыночными данными.
Создание объекта верхнего уровня позволяет максимально упростить интеграцию всех компонентов MDL в архитектурное решение торговых моделей. Достаточно заменить существующий блок анализа данных на этот объект, и модель сразу получает всю логику работы с признаками, сценариями и задачами в готовом виде. В рамках данной статьи мы не будем подробно разбирать внутреннюю архитектуру обучаемых моделей — при желании с ней можно ознакомиться в приложенном материале.
Тестирование
Итогом проекта становится торговая модель, которая анализирует рынок и доводит этот анализ до практического действия, самостоятельно принимает торговые решения и совершает операции. Обучение мы сознательно выстроили в два этапа.
На этапе офлайн-обучения модель проходит по всей истории EURUSD за 2024–2025 годы на таймфрейме H1 и постепенно формирует собственное представление о рынке. Она не ограничивается отдельными сигналами, а учится работать с более крупными структурами: последовательностями, контекстными признаками, эмбеддингами сценариев. Всё это последовательно собирается в единый поток и аккуратно распределяется по внутренним стекам модели. Так закладывается база, на которой затем строится более тонкая рыночная интерпретация.
После этого модель переходит к онлайн-обучению в тестере стратегий MetaTrader 5. Здесь среда уже заметно динамичнее. Новые данные поступают непрерывно, и каждый новый бар может влиять на текущее состояние модели. Параметры начинают корректироваться почти в реальном времени. Обновляются стеки, уточняются сценарии, а накопленный опыт сразу включается в новые прогнозы. Именно на этом этапе модель учится различать краткий импульс и более протяжённое движение, распознавать коррекцию и менять поведение в зависимости от контекста.
Финальная проверка логично завершает весь цикл. На данных за Январь–Февраль 2026 года модель уже сталкивается с новой рыночной обстановкой.
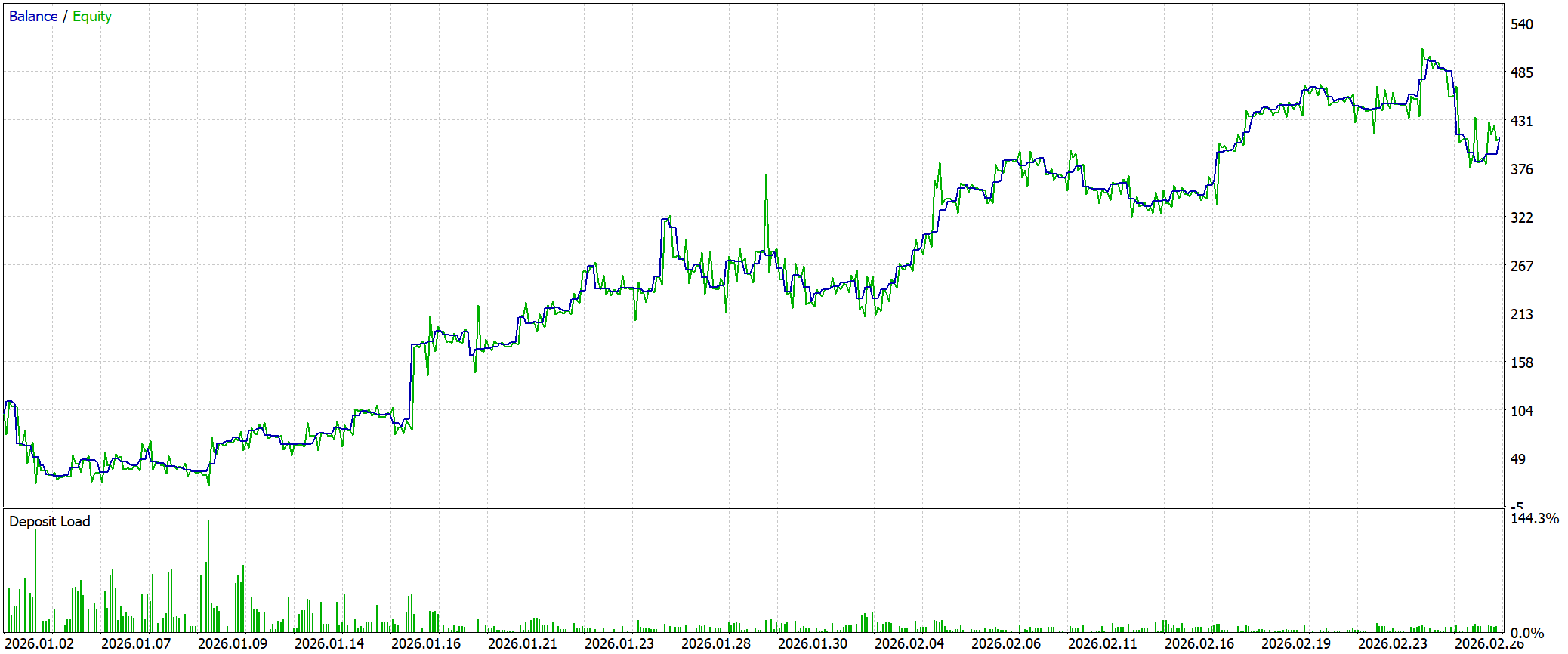
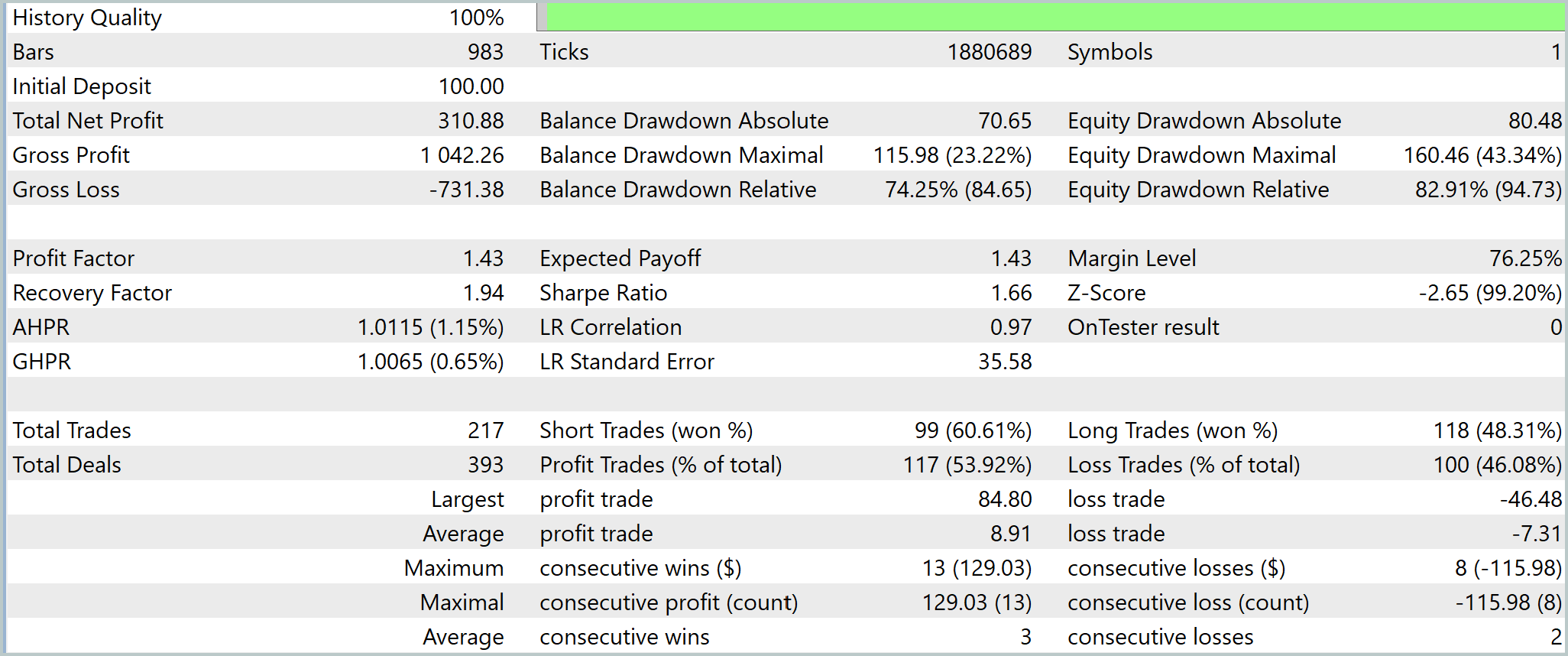
Результаты тестирования демонстрируют уверенную, хотя и не агрессивную динамику. При стартовом депозите 100.0 USD модель формирует чистую прибыль 310.88 USD, сохраняя восходящую структуру баланса. Кривая растёт без хаотичных скачков. Периоды роста чередуются с контролируемыми откатами, что указывает на осмысленную логику принятия решений. Profit Factor на уровне 1.43 и Sharpe Ratio1.66 подтверждают, что модель работает в сбалансированном режиме, извлекая преимущество за счёт качества сделок.
При этом риск-профиль остаётся напряжённым. Максимальная просадка по Equity превышает 40%, что говорит об активном использовании капитала. Однако просадки не разрушают общую структуру доходности. Модель демонстрирует способность к восстановлению, что подтверждается Recovery Factor около 1.94. Торговая статистика также выглядит устойчиво. Около 54% прибыльных сделок при среднем профите выше среднего убытка формируют положительное математическое ожидание без перекоса в сторону избыточной точности.
Модель последовательно интерпретирует рыночное состояние, корректируя поведение по мере поступления новых данных. Финальный участок с заметной просадкой и последующим восстановлением особенно показателен. Модель не теряет устойчивость при смене рыночного режима, а продолжает работать в рамках своей внутренней логики.
Заключение
В рамках данной статьи завершён этап переноса подходов фреймворка MDL в область анализа рыночной ситуации. Были реализованы механизмы объединения потоков задач и сценариев. Сформирован объект верхнего уровня и выстроен согласованный вычислительный конвейер, в котором признаки исторической последовательности, контекст и целевая постановка работают как единая система. Концепция MDL получила инженерное воплощение средствами MQL5 и OpenCL.
Тестирование на реальных исторических данных подтвердило работоспособность выбранного подхода. Модель демонстрирует устойчивую положительную динамику, сохраняет структурную целостность при смене рыночных условий и способна адаптироваться. При этом выявленные просадки и особенности риск-профиля указывают на направления для дальнейшей оптимизации, что является естественным этапом развития любой сложной системы.
Главный результат — сформирован универсальный архитектурный каркас, который позволяет работать с рынком как с многодоменной средой. Это открывает возможности для более глубокого анализа, гибкой настройки и последующего расширения фреймворка.
Ссылки
- MDL: A Unified Multi-Distribution Learner in Large-scale Industrial Recommendation through Tokenization
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен на forge.mql5.io/dng.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования