
Нейросети в трейдинге: Унифицированное смешивание признаков для торговых решений (Окончание)

Введение
В предыдущих статьях мы последовательно погружались в архитектуру UniMixer, рассматривая фреймворк как практический инструмент для анализа финансовых рынков. Ключевая идея фреймворка — объединение различных подходов к обработке данных в рамках единого механизма параметризованного смешивания. Attention, TokenMixer и модели факторизации здесь выступают как частные случаи одного и того же процесса — управляемого взаимодействия признаков. Такой подход снимает ряд архитектурных ограничений и, что особенно важно для прикладных задач, позволяет модели адаптироваться к структуре данных.
Для трейдера это означает переход на иной уровень работы с данными. Вместо жёстко заданных индикаторов и фиксированных зависимостей получаем модель, способную самостоятельно выявлять значимые взаимосвязи между рыночными сигналами. Причем речь идет не только о локальных паттернах, но и о более сложных, распределенных зависимостях. В условиях рынка, где структура шума часто доминирует над сигналом, подобная гибкость становится необходимостью.
В первой статье заложена теоретическая основа. Рассмотрены принципы построения фреймворка UniMixer, его позиционирование среди современных архитектур и ключевые преимущества. Особое внимание было уделено представлению данных в виде токенов. Этот шаг принципиален. Переход от сырых временных рядов к структурированным элементам позволяет модели работать с осмысленным набором признаков. Фактически формируем пространство, в котором каждая единица данных несет конкретную смысловую нагрузку.
Во второй статье акцент сместился в сторону практической реализации. Разработаны и реализованы базовые компоненты фреймворка средствами MQL5 с использованием OpenCL, это позволило сразу учитывать требования к производительности. Была построена двухуровневая схема обработки данных: на первом этапе выполняется локальное смешивание токенов — анализируются ближайшие взаимозависимости и формируются первичные признаки, на втором этапе происходит глобальное взаимодействие, сопровождаемое сжатием и последующим восстановлением структуры.
Важно подчеркнуть принципиальный момент. Сжатие применяется не к внутреннему представлению токена, а к количеству токенов. Уменьшаем размерность по оси наблюдений, сохраняя информативность самих признаков. Это решение позволяет снизить вычислительные затраты без критической потери качества. С практической точки зрения это выглядит как аккуратная агрегация информации — модель избавляется от избыточности, но сохраняет ключевые рыночные характеристики.
Таким образом, к текущему моменту уже сформирован каркас системы и реализованы механизмы токенизации, локального и глобального взаимодействия, а также базовая логика преобразования данных. Однако сама по себе архитектура — это лишь половина задачи. Не менее важным является обеспечение её устойчивости и управляемости в процессе обучения и последующего применения.
Продолжим работу. Логичным следующим этапом становится завершение фреймворка за счет внедрения компонентов, отвечающих за стабилизацию вычислений и интеграцию модулей в единую систему. Финальным этапом станет тестирование на реальных исторических данных. Это не формальная процедура, а ключевой момент всей работы. Именно здесь проверяется жизнеспособность предложенных решений.

SiameseNorm
В центре внимания оказывается механизм нормализации SiameseNorm. Модуль реализует не просто нормализацию признаков, а более сложную схему стабилизации вычислений, основанную на взаимодействии двух параллельных ветвей состояния. Такой подход позволяет одновременно контролировать распределение исходных данных и сохранять чистоту остаточных связей, что критично при работе с глубокими моделями.
В основе модуля лежит разделение вычислительного процесса на две связанные компоненты, которые условно можно обозначить как ветви X и Y. Эти ветви представляют собой разные формы одного и того же сигнала, участвующие в совместном преобразовании. На первом этапе выполняется нормализация только одной из ветвей (Y). Формируется стабилизированное представление, которое далее используется в процессе смешивания. Важно подчеркнуть, что вторая ветвь (X) на этом этапе остается без изменений, сохраняя исходное распределение признаков.
Далее обе ветви объединяются и поступают в блок параметризованного смешивания UniMixer, который выступает в роли центрального оператора взаимодействия. Он не принадлежит ни одной из ветвей по отдельности, а работает с их суммарным сигналом, формируя общее представление, отражающее выявленные зависимости между признаками.
После этого вычислительный процесс снова разделяется. Обновление состояний выполняется асимметрично для каждой ветви.
Для ветви X используется схема пост-нормализации. Сначала формируется остаточная связь, после чего применяется нормализация. Такой порядок операций позволяет контролировать распределение выходных значений и предотвращает накопление искажений при прохождении сигнала через последующие слои.
Ветвь Y, напротив, обновляется через чистое остаточное соединение. В этом случае нормализация не применяется, что сохраняет неизменный путь распространения сигнала и обеспечивает стабильный градиент при обучении.
Подобная асимметрия является ключевой особенностью SiameseNorm. В отличие от классических подходов, использующих предварительную или последующую нормализацию, здесь оба механизма присутствуют одновременно, но распределены между различными ветвями вычислительного графа. Это позволяет объединить их преимущества: стабилизировать вход в блок смешивания и одновременно контролировать поведение выходных признаков.
Такая схема оказывается полезной при работе с финансовыми данными. Рынок характеризуется нестабильными распределениями, изменчивой волатильностью и частыми сдвигами корреляционной структуры. В этих условиях классические методы нормализации могут либо недостаточно стабилизировать модель, либо, наоборот, чрезмерно сглаживать сигнал. SiameseNorm решает эту задачу более гибко, обеспечивая баланс между адаптивностью и устойчивостью.
Логика модуля напрямую отражена в структуре класса CNeuronSiameseNorm, где каждый компонент соответствует отдельному этапу вычислительного графа.
class CNeuronSiameseNorm : public CNeuronBaseOCL { protected: CNeuronBaseOCL cNormYIn; CNeuronBaseOCL cSumXYIn; CNeuronUniMixer cMixer; CNeuronBaseOCL cYOut; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override; public: CNeuronSiameseNorm(void) {}; ~CNeuronSiameseNorm(void) {}; //--- //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units, uint blocks, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual int Type(void) override const { return defNeuronSiameseNorm; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; //--- virtual CNeuronBaseOCL* GetYOut(void) { return cYOut.AsObject(); } //--- virtual uint GetWindow(void) const { return cMixer.GetWindow(); } virtual uint GetFields(void) const { return cMixer.GetFields(); } };
За предварительную нормализацию ветви Y отвечает объект cNormYIn. Функцию объединения ветвей выполняет компонент cSumXYIn, который формирует суммарное представление. Это подготовка входа для выявления перекрестных зависимостей между признаками.
Центральным элементом выступает объект cMixer, который выполняет параметризованное смешивание, определяя структуру взаимодействий между токенами. В контексте всей архитектуры этот компонент отвечает за извлечение полезного сигнала из объединенного представления признаков.
После получения результата смешивания вычислительный процесс вновь разделяется на две ветви, что соответствует оригинальной формуле SiameseNorm. Обновление ветви X реализует схему пост-нормализации. Сначала формируется остаточная связь, после чего применяется нормализация. Параллельно формируется обновление второй ветви Y через компонент cYOut, реализуемое как чистое остаточное соединение. Этот путь не включает дополнительной нормализации, что сохраняет прямой канал распространения сигнала.
Перед реализацией алгоритмов прямого и обратного проходов необходимо формально задать структуру вычислительного графа модуля. Эта задача полностью фиксируется в методе инициализации, который выполняет концептуально определяющую роль, задавая архитектурную композицию слоя и порядок взаимодействия внутренних компонентов в рамках общего потока обработки данных.
bool CNeuronSiameseNorm::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units, uint blocks, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units, optimization_type, batch)) ReturnFalse; activation = None;
Инициализация начинается с вызова одноименного метода родительского класса, который формирует фундамент слоя как вычислительной единицы в OpenCL-ориентированной среде. На этом уровне задаются базовые параметры. После этого явно фиксируется отсутствие нелинейных преобразований на уровне модуля через отключение функции активации. Это принципиально важно для понимания роли SiameseNorm. Слой не является источником новой нелинейности и не вмешивается в формирование признакового пространства, а работает как стабилизирующий и структурирующий механизм поверх уже существующего оператора смешивания UniMixer.
Далее начинается построение внутренней структуры. Компонент cNormYIn инициализируется первым и отвечает за предварительную нормализацию одной из ветвей состояния, что в терминах вычислительной схемы соответствует операции приведения сигнала Y к устойчивому распределению перед взаимодействием с другой ветвью.
uint index = 0; if(!cNormYIn.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) ReturnFalse; cNormYIn.SetActivationFunction(None);
На практике это означает, что один из потоков получает дополнительный уровень стабилизации ещё до этапа смешивания. Отсутствие активационной функции в этом компоненте подчёркивает строго линейную природу и роль чистого нормализующего преобразования без внесения дополнительной нелинейной динамики.
Следующим шагом инициализируется cSumXYIn, который формирует точку взаимодействия двух ветвей состояния.
index++; if(!cSumXYIn.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) ReturnFalse; cSumXYIn.SetActivationFunction(None);
Здесь происходит объединение нормализованной (Y) и ненормализованной (X) ветвей, что в вычислительном смысле соответствует подготовке входа для блока UniMixer. Это ключевой архитектурный момент, определяющий, какие зависимости между рыночными признаками будут доступны для последующего анализа. Выделение этого этапа в отдельный компонент позволяет явно контролировать структуру взаимодействий и делает поведение модели более интерпретируемым с инженерной точки зрения. Как и в предыдущем случае, здесь отсутствует функция активации, поскольку задача блока ограничена исключительно агрегацией сигналов.
После этого инициализируется центральный элемент архитектуры — cMixer, реализующий блок UniMixer.
index++; if(!cMixer.Init(0, index, OpenCL, window, units, blocks, embed_size, candidates, topK, optimization, iBatch)) ReturnFalse;
Здесь происходит параметризованное смешивание признаков, формализующее взаимодействие токенов в рамках общего представления. Конфигурационные параметры этого блока определяют характер и глубину взаимодействий, включая размер и количество токенов, структуру блоков и механизмы отбора наиболее значимых связей. В контексте финансовых рынков этот этап можно рассматривать как момент, в котором модель переходит от простого агрегирования сигналов к выявлению структурных зависимостей, скрытых в динамике котировок.
Завершается построение внутреннего графа инициализацией компонента cYOut, который отвечает за формирование выходного состояния предварительно нормализованной ветви после применения остаточной связи.
index++; if(!cYOut.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) ReturnFalse; cYOut.SetActivationFunction(None); //--- return true; }
Отсутствие активации на этом этапе сохраняет линейность преобразования и предотвращает искажение статистической структуры выходного сигнала.
Таким образом, метод инициализации фактически задаёт полную топологию вычислительного графа слоя. Фиксирует разделение на нормализованную и ненормализованную ветви, определяет точку их взаимодействия через UniMixer и формирует механизм последующего восстановления стабильного состояния. В условиях финансовых рынков такая структура приобретает особое значение, поскольку позволяет одновременно удерживать устойчивость модели к шуму и сохранять чувствительность к структурным изменениям в данных, что является критическим фактором для любой прикладной торговой системы.
После того как структура вычислительного графа зафиксирована на этапе инициализации, становится возможным последовательно проследить движение данных внутри модуля. Метод прямого прохода выступает точным отражением математической схемы SiameseNorm на уровне операций с буферами и OpenCL-ядрами.
bool CNeuronSiameseNorm::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) { if(!NeuronOCL || NeuronOCL.Neurons() < Neurons()) ReturnFalse; if(!Context) return feedForward(NeuronOCL); if(Context.Total() < Neurons()) ReturnFalse;
Вход в метод организован через два источника данных: первый — NeuronOCL, представляющий ветвь X, то есть основной поток признаков, поступающий из предыдущего слоя; второй — Context, который используется как носитель ветви Y. Уже на этом этапе становится очевидной ключевая особенность архитектуры: слой оперирует не одним, а двумя связанными представлениями данных, что напрямую соответствует оригинальной формуле SiameseNorm.
После базовых проверок корректности входных данных задаются параметры размерности.
uint dimension = cMixer.GetWindow(); uint units = cMixer.GetFields();
Эти величины определяют, каким образом данные будут структурированы при последующих операциях нормализации и смешивания. В контексте финансовых рынков это можно интерпретировать как задание масштаба анализа — сколько наблюдений участвует во взаимодействии и как они агрегируются в пространстве признаков.
Первым вычислительным этапом становится формирование нормализованной ветви Y. Для этого данные из Context копируются в буфер cNormYIn с учётом заданной размерности, после чего применяется процедура нормализации.
//--- Norm(Y) if(!Concat(Context, cNormYIn.getOutput(), cNormYIn.getOutput(), dimension, 0, units)) ReturnFalse; if(!Normalize(cNormYIn.getOutput(), dimension)) ReturnFalse;
Несмотря на кажущуюся простоту, именно здесь происходит критически важное преобразование: поток Y приводится к устойчивому распределению перед взаимодействием с ветвью X. В условиях рыночных данных это снижает влияние выбросов и локальных всплесков волатильности, которые могли бы исказить результат смешивания.
Далее формируется объединённое представление двух ветвей.
//--- X + Norm(Y) if(!SumAndNormalize(NeuronOCL.getOutput(), cNormYIn.getOutput(), cSumXYIn.getOutput(), dimension, false, 0, 0, 0, 1)) ReturnFalse;
Важно, что нормализация здесь отключена (параметр false), и операция выполняет чистое суммирование. Это подчёркивает архитектурный принцип: точка взаимодействия потоков должна быть максимально прозрачной, без дополнительного искажения статистики.
Полученное объединённое представление передаётся в cMixer, где выполняется основной этап — параметризованное смешивание признаков.
//--- Mixing if(!cMixer.FeedForward(cSumXYIn.AsObject())) ReturnFalse;
Здесь модель извлекает структурные зависимости между токенами, выявляя скрытые корреляции и взаимодействия, которые в контексте финансовых рядов могут соответствовать сложным рыночным паттернам.
После получения результата смешивания вычислительный процесс вновь разделяется на две ветви, что строго соответствует оригинальной логике SiameseNorm.
Обновление ветви X выполняется через операцию SumAndNormalize, где к исходному сигналу NeuronOCL добавляется результат cMixer с последующим применением нормализации. Параметр true в данном вызове указывает на использование пост-нормализации.
//--- X if(!SumAndNormalize(NeuronOCL.getOutput(), cMixer.getOutput(), Output, dimension, true, 0, 0, 0, 1)) ReturnFalse;
Это ключевой элемент стабилизации выходного распределения, который предотвращает накопление искажений при прохождении через последующие слои.
Параллельно формируется обновление ветви Y. Здесь также используется SumAndNormalize, но уже с параметром false, отключающим нормализацию.
//--- Y if(!SumAndNormalize(Context, cMixer.getOutput(), cYOut.getOutput(), dimension, false, 0, 0, 0, 1)) ReturnFalse; //--- return true; }
В результате в буфер cYOut записывается чистая остаточная сумма. Сохранение этого неискажённого канала имеет важное значение — он обеспечивает стабильное распространение сигнала и градиента, не подвергаясь дополнительной трансформации.
Если посмотреть на весь процесс в целом, то становится очевидно: метод прямого прохода реализует строго определённую последовательность. Такая схема позволяет одновременно контролировать статистику анализируемых данных и сохранять устойчивость выходного сигнала. Это даёт модели важное преимущество при работе с финансовыми временными рядами. Наличие нормализованного и ненормализованного путей позволяет системе балансировать между адаптацией к текущим условиям рынка и сохранением устойчивости к шуму. В результате поведение модели становится более предсказуемым, а её реакция на изменения рыночной структуры — более взвешенной. Это свойство критично для прикладных торговых решений.
Однако здесь стоит обратить внимание, что на выход модуля подается только одна магистраль X. Для доступа ко второй мы добавили метод GetYOut(void). Но это не ложится в реализованную ранее общую магистраль потока данных в последовательной модели и, как следствие, усложняет процесс интеграции модуля. С целью решения данной проблемы был создан метод-обёртка, работающий с одним объектом на входе.
bool CNeuronSiameseNorm::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse;
Уже в первых строках задаётся базовая проверка корректности входа. Отсутствие источника данных немедленно прерывает выполнение. Это стандартная защита, но в контексте сложной многокомпонентной архитектуры она приобретает особое значение, поскольку любые нарушения целостности входных буферов могут привести к трудноуловимым искажениям на последующих этапах.
Далее следует более содержательный участок логики, который определяет, с каким типом входного источника имеем дело. Если входной объект не является экземпляром CNeuronSiameseNorm, то в качестве контекста используется его стандартный буфер результатов и управление передаётся в выше рассмотренную версию метода feedForward, принимающую дополнительный контекст.
if(NeuronOCL.Type() != Type()) { if(!NeuronOCL.getOutput() || !feedForward(NeuronOCL, NeuronOCL.getOutput())) ReturnFalse; }
По сути, в этом случае модуль работает в классическом режиме: получает готовое представление данных и начинает обработку в соответствии с собственной архитектурой.
Ситуация меняется, если на вход подаётся объект того же типа, то есть другой экземпляр CNeuronSiameseNorm. В этом случае для контекста используется не основной выход, а специализированный буфер.
else { CNeuronSiameseNorm* second = NeuronOCL; if(!second.GetYOut() || !second.GetYOut().getOutput() || !feedForward(NeuronOCL, second.GetYOut().getOutput())) ReturnFalse; } return true; }
Этот момент отражает глубинную особенность архитектуры SiameseNorm. Взаимодействие между слоями происходит через одну из внутренних ветвей состояния. При последовательном соединении таких модулей в модель передаётся не полностью обработанный сигнал, а его определённая составляющая, соответствующая одной из ветвей вычислительного графа.
С инженерной точки зрения это решение выглядит весьма осмысленным. Оно позволяет сохранить разделение на нормализованную и ненормализованную компоненты не только внутри одного слоя, но и на уровне модели. В результате формируется более гибкая система передачи информации, в которой различные аспекты сигнала могут обрабатываться с разной степенью стабилизации.
Вместо того чтобы передавать между уровнями уже сглаженный и усреднённый сигнал, модель сохраняет доступ к его более сырой версии, в которой остаются тонкие, но потенциально значимые колебания. Это позволяет не терять чувствительность к локальным изменениям рынка, одновременно удерживая общую устойчивость системы за счёт внутренней нормализации.
Объект верхнего уровня
Переход к объекту верхнего уровня логично завершает всю предыдущую работу. Класс CNeuronUniMixerBlock выступает как укрупнённая единица обработки, где сходятся все ранее реализованные механизмы — от токенизации до сценарного моделирования и финальной проекции признаков.
class CNeuronUniMixerBlock : public CNeuronPerTokenSwiGLU { protected: CNeuronUniMixerTokenizer cPrepare; CNeuronBaseOCL cLastNonSequence; CLayer cFeatures; CNeuronScenariosToken cScenarios; CLayer cFlow; CLayer cOutputProj; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronUniMixerBlock(void) {}; ~CNeuronUniMixerBlock(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint blocks, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronUniMixerBlock; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; };
Архитектурно данный блок наследуется от CNeuronPerTokenSwiGLU, что сразу задаёт характер его работы. Это означает, что на верхнем уровне дополняем признаки управляемой нелинейностью, работающей на уровне отдельных токенов. Такой шаг выглядит вполне оправданным. Внутри UniMixer мы сознательно избегали избыточной нелинейности ради стабильности, и на уровне агрегированного представления появляется пространство для более гибкой трансформации сигналов.
Первым элементом в структуре блока выступает cPrepare, реализующий токенизацию входного потока. По сути, это точка входа, где сырые рыночные данные приводятся к формату, пригодному для дальнейшей обработки. Здесь формируется базовое представление, с которым будут работать все последующие компоненты. В контексте финансовых рынков это можно рассматривать как переход от последовательности котировок к структурированному набору признаков, где каждая позиция уже несёт определённую смысловую нагрузку.
Далее в архитектуре появляется cLastNonSequence. На этом этапе из общего потока токенов выделяются данные, описывающие контекст текущего рыночного состояния. Речь идет об устойчивых характеристиках, формирующих общее фоновое поведение модели. Фактически происходит отделение двух типов информации: с одной стороны, сохраняется последовательная структура, отражающая динамику движения цены, с другой — извлекается агрегированное представление.
Следующий уровень представлен массивом cFeatures, который формирует пространство признаков. Здесь происходит углубление представления. Последовательные токены преобразуются в более информативные комбинации, пригодные для выявления сложных зависимостей. Это уже начало их интерпретации с точки зрения модели.
Особое место занимает компонент cScenarios, реализующий генерацию сценарных токенов. Именно здесь модель начинает работать в более прикладной логике, близкой к мышлению трейдера. Вместо того чтобы анализировать только текущие значения, она формирует возможные сценарии развития, кодируя различные варианты поведения рынка. Такой подход позволяет учитывать не только факт текущего состояния, но и его потенциальную динамику.
Далее следует блок cFlow, который отвечает за распространение и согласование информации между сформированными признаками и сценариями. Это своего рода транспортный уровень модели, обеспечивающий корректное взаимодействие различных представлений. Здесь происходит перераспределение информации, усиление значимых сигналов и подавление шумовых компонент.
Завершающим этапом выступает cOutputProj, выполняющий проекцию в итоговое пространство признаков. На этом уровне модель формирует уже компактное и согласованное представление, пригодное для последующего использования — будь то прогнозирование, классификация или непосредственное принятие торгового решения.
Метод инициализации логически завершает формирование верхнеуровневой архитектуры UniMixerBlock и показывает, что речь идёт о заранее структурированном вычислительном графе. Каждый компонент которого занимает строго определённую позицию в потоке обработки рыночных данных. Именно на этом этапе фиксируется вся внутренняя топология модуля, определяющая то, как будет интерпретироваться и трансформироваться входной рыночный контекст.
bool CNeuronUniMixerBlock::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint blocks, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(dimensions.Size() <= units_s || layers < 1) ReturnFalse; uint units_ns = dimensions.Size() - units_s; uint inside_embed_size = (embed_size + 1) / 2; //--- if(!CNeuronPerTokenSwiGLU::Init(numOutputs, myIndex, open_cl, embed_size, blocks, inside_embed_size, candidates, topK, optimization_type, batch)) ReturnFalse;
Инициализация начинается с проверки согласованности входных параметров и разделения размерности признакового пространства на две части: последовательную часть и дополнительную контекстную составляющую. Такое разделение уже на уровне архитектуры задаёт различие между локально структурированными рыночными сигналами и более общим контекстом состояния рынка, который не привязан к конкретной последовательности токенов.
Далее вычисляется внутренний размер Embedding-пространства, который формирует баланс между компактностью представления и его выразительной способностью.
Родительский класс инициализируется первым и задаёт фундаментальную нелинейную трансформацию на уровне токенов. Далее формируется блок подготовки данных cPrepare, который отвечает за первичную структуризацию входного потока.
//--- Prepare uint index = 0; if(!cPrepare.Init(0, index, OpenCL, dimensions, units_s + units_ns, embed_size, blocks, candidates, topK, optimization, iBatch)) ReturnFalse;
На этом этапе общий поток рыночных данных раскладывается в формат, пригодный для дальнейшего смешивания, где учитываются последовательные и контекстные признаки. Вслед за этим инициализируется cLastNonSequence, который выделяет из общего потока токенов данные, описывающие контекст текущего рыночного состояния.
index++; if(!cLastNonSequence.Init(0, index, OpenCL, embed_size * units_ns, optimization, iBatch)) ReturnFalse; cLastNonSequence.SetActivationFunction(None);
Это агрегированное представление режима рынка, отражающее его текущую структуру. Отсутствие функции активации в этом компоненте подчёркивает его роль как чистого носителя контекстной информации без дополнительного искажения распределений.
Следующим элементом выступает cScenarios, формирующий сценарные представления на основе анализируемой последовательности.
index++; if(!cScenarios.Init(0, index, OpenCL, embed_size, units_s, embed_size, scenarios, inside_embed_size, candidates, topK, optimization, iBatch)) ReturnFalse; cScenarios.SetActivationFunction(None);
Здесь модель начинает работать с возможными развитиями рыночной ситуации, что в прикладном смысле соответствует построению набора потенциальных траекторий ценового движения. Этот компонент также остаётся линейным по своей природе, поскольку его задача заключается в расширении пространства возможных интерпретаций данных.
После формирования базовых потоков начинается построение вычислительной структуры в контейнер cFeatures. На этом уровне создаётся последовательность модулей, отвечающих за постепенное усложнение представления последовательных данных. Сначала добавляется базовый линейный слой, формирующий начальную проекцию признаков, затем компонент CNeuronAddToStack, который осуществляет агрегацию информации по стеку состояний, что позволяет учитывать многослойный контекст рыночной динамики.
cFeatures.Clear(); cFlow.Clear(); cOutputProj.Clear(); cFeatures.SetOpenCL(OpenCL); cFlow.SetOpenCL(OpenCL); cOutputProj.SetOpenCL(OpenCL); //--- Features index++; CNeuronBaseOCL* neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, embed_size * units_s, optimization, iBatch) || !cFeatures.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++; CNeuronAddToStack* stack = new CNeuronAddToStack(); if(!stack || !stack.Init(0, index, OpenCL, stack_size, embed_size, units_s, optimization, iBatch) || !cFeatures.Add(stack)) DeleteObjAndFalse(stack);
Ключевым элементом внутри этого блока становится CNeuronSiameseNorm, который реализует механизм стабилизации и смешивания последовательных признаков на уровне архитектуры UniMixer.
index++; CNeuronSiameseNorm* mixing = new CNeuronSiameseNorm(); if(!mixing || !mixing.Init(0, index, OpenCL, embed_size, units_s * stack_size, blocks, inside_embed_size, candidates, topK, optimization, iBatch) || !cFeatures.Add(mixing)) DeleteObjAndFalse(mixing);
Здесь происходит основное взаимодействие последовательных токенов с учётом предстоящего ценового движения, накопленного в стеке. Этот компонент фактически связывает локальные и глобальные представления, обеспечивая устойчивость модели к изменениям рыночных режимов и шумовым колебаниям.
Завершает формирование блока cFeatures дополнительный слой, который объединяет данные двух потоков SiameseNorm.
index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, mixing.Neurons(), optimization, iBatch) || !cFeatures.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
После этого формируется блок cFlow, который объединяет результаты работы cFeatures, cScenarios и cLastNonSequence. Здесь происходит ключевая операция консолидации информации. Разнородные представления рыночных данных сводятся в единое пространство, пригодное для глубокой обработки.
//--- Flow index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, mixing.Neurons() + cScenarios.Neurons() + cLastNonSequence.Neurons(), optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
Далее в рамках блока последовательно добавляются слои CNeuronSiameseNorm, формируя глубинную структуру трансформации. Каждый слой усиливает и уточняет представление рынка на разных уровнях абстракции.
for(uint i = 0; i < layers; i++) { index++; mixing = new CNeuronSiameseNorm(); if(!mixing || !mixing.Init(0, index, OpenCL, embed_size, units_s * stack_size + units_ns + scenarios, blocks, inside_embed_size, candidates, topK, optimization, iBatch) || !cFlow.Add(mixing)) DeleteObjAndFalse(mixing); }
Финальным этапом является блок cOutputProj, который отвечает за формирование итогового представления модели. Здесь сначала выполняется линейное преобразование, приводящее данные к единому масштабу, после чего применяется CNeuronFieldAwareConv, формирующий финальную проекцию с учётом пространственной структуры признаков.
//--- Output Projection index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, mixing.Neurons(), optimization, iBatch) || !cOutputProj.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++; uint window_in = neuron.Neurons() / blocks; CNeuronFieldAwareConv* proj = new CNeuronFieldAwareConv(); if(!proj || !proj.Init(0, index, OpenCL, window_in, embed_size, blocks, inside_embed_size, candidates, topK, optimization, iBatch) || !cOutputProj.Add(proj)) DeleteObjAndFalse(proj); //--- return true; }
Этот этап можно рассматривать как переход от внутреннего представления модели к сигналу, пригодному для интерпретации в рамках торговой системы.
Таким образом, метод инициализации фиксирует полноценную архитектуру вычислительного графа, в котором каждая подсистема отвечает за строго определённый уровень интерпретации рыночных данных.
Метод прямого прохода — это алгоритм многоуровневой архитектуры. Каждый этап отражает отдельный слой интерпретации рыночного контекста.
bool CNeuronUniMixerBlock::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPrepare.FeedForward(NeuronOCL)) ReturnFalse;
Входной сигнал сначала поступает в cPrepare, где выполняется первичная токенизация и структурирование данных. На этом этапе формируется базовое представление рынка, которое переходит в форму структурированного набора признаков. Это критически важный момент, поскольку дальнейшая обработка работает не с ценой как временным рядом, а с её внутренней смысловой декомпозицией.
Далее происходит разделение потока на две составляющие.
//--- Features CNeuronBaseOCL* feature = cFeatures[0]; if(!feature || !DeConcat(feature.getOutput(), cLastNonSequence.getOutput(), cPrepare.getOutput(), feature.Neurons(), cLastNonSequence.Neurons(), 1)) ReturnFalse;
Таким образом уже на раннем этапе вычислений модель разделяет фон рынка и его локальную динамику, что соответствует реальной логике принятия решений в трейдинге. Контекст часто важнее отдельного движения цены.
После этого запускается каскад обработки признаков через последовательность модулей cFeatures. Каждый элемент этого контейнера получает результат предыдущего слоя и последовательно трансформирует представление данных.
for(int i = 1; i < cFeatures.Total() - 1; i++) { feature = cFeatures[i]; if(!feature || !feature.FeedForward(cFeatures[i - 1])) ReturnFalse; }
На этом уровне происходит постепенное усложнение структуры признаков. Простые зависимости превращаются в более абстрактные комбинации. Это не линейное преобразование, а постепенное наращивание глубины интерпретации рыночного сигнала.
Особое внимание заслуживает ветка, в которой участвует SiameseNorm. Если текущий слой относится к этому типу, то дополнительно активируется механизм согласования ветвей.
if(feature.Type() == defNeuronSiameseNorm) { CNeuronSiameseNorm* mixing = feature; CNeuronBaseOCL* Y = mixing.GetYOut(); uint dimension = mixing.GetWindow(); uint units = mixing.GetFields(); feature = cFeatures[-1]; if(!feature) ReturnFalse; if(!Concat(Y.getOutput(), Y.getOutput(), feature.getOutput(), dimension, 0, units)) ReturnFalse; if(!Normalize(feature.getOutput(), dimension)) ReturnFalse; if(!SumAndNormalize(mixing.getOutput(), feature.getOutput(), feature.getOutput(), dimension, false, 0, 0, 0, 1)) ReturnFalse; } else { feature = cFeatures[-1]; if(!feature || !feature.FeedForward(cFeatures[-2])) ReturnFalse; }
Извлекается компонент Y, после чего выполняется повторная нормализация и синхронизация с текущим представлением признаков. Здесь реализуется ключевая идея SiameseNorm: разделение и последующее согласование нормализованной и ненормализованной информации. В результате формируется более устойчивое представление, в котором подавляются локальные шумовые колебания и усиливается структурная составляющая сигнала.
Если же текущий слой не относится к SiameseNorm, выполняется стандартное последовательное продвижение по стеку признаков, что обеспечивает универсальность архитектуры и возможность комбинирования различных типов слоёв внутри одного графа.
Следующим этапом является обработка сценарного компонента cScenarios, который получает на вход первичное представление последовательных токенов.
//--- Scenarios if(!cScenarios.FeedForward(cFeatures[0])) ReturnFalse;
На этом уровне модель формирует альтернативные траектории развития рыночной ситуации. Это уже расширение пространства возможных исходов, что особенно важно в условиях высокой неопределённости финансовых рынков.
После этого начинается формирование входа для блока cFlow, который объединяет три ключевых источника информации: контекст текущего состояния рынка, сценарные представления и обработанные признаки.
//--- Flow uint blocks = CNeuronPerTokenSwiGLU::GetFields(); CNeuronBaseOCL* flow = cFlow[0]; if(!flow || !Concat(cLastNonSequence.getOutput(), cScenarios.getOutput(), feature.getOutput(), flow.getOutput(), cLastNonSequence.Neurons() / blocks, cScenarios.Neurons() / blocks, feature.Neurons() / blocks, blocks)) ReturnFalse;
С инженерной точки зрения это момент, в котором модель перестаёт работать с отдельными аспектами данных и переходит к их совместной интерпретации.
Далее поток проходит через каскад слоёв cFlow, начиная с первого комбинированного блока.
flow = cFlow[1]; if(!flow || !flow.FeedForward(cFlow[0], cFlow[0].getOutput())) ReturnFalse; for(int i = 2; i < cFlow.Total(); i++) { flow = cFlow[i]; if(!flow || !flow.FeedForward(cFlow[i - 1])) ReturnFalse; }
Это создаёт эффект постепенного уточнения сигнала, где каждый последующий слой корректирует и перераспределяет информацию, усиливая наиболее значимые компоненты. На этом этапе архитектура начинает напоминать систему последовательного уточнения рыночного сценария, где каждое преобразование добавляет новый уровень интерпретации.
Финальная часть обработки связана с блоком cOutputProj, который отвечает за формирование итогового представления. Здесь снова используется механизм SiameseNorm, что подчёркивает его роль как универсального стабилизирующего элемента всей архитектуры.
//--- Output Projection if(flow.Type() != defNeuronSiameseNorm) ReturnFalse; CNeuronSiameseNorm* mixing = flow; CNeuronBaseOCL* Y = mixing.GetYOut(); uint dimension = mixing.GetWindow(); uint units = mixing.GetFields(); CNeuronBaseOCL* proj = cOutputProj[0]; if(!proj) ReturnFalse; if(!Concat(Y.getOutput(), Y.getOutput(), proj.getOutput(), dimension, 0, units)) ReturnFalse; if(!Normalize(proj.getOutput(), dimension)) ReturnFalse; if(!SumAndNormalize(mixing.getOutput(), proj.getOutput(), proj.getOutput(), dimension, false, 0, 0, 0, 1)) ReturnFalse;
На этом этапе происходит согласование нормализованной и ненормализованной ветвей, после чего данные проходят через завершающие слои проекции.
for(int i = 1; i < cOutputProj.Total(); i++) { proj = cOutputProj[i]; if(!proj || !proj.FeedForward(cOutputProj[i - 1])) ReturnFalse; } if(!CNeuronPerTokenSwiGLU::feedForward(proj)) ReturnFalse; //--- return true; }
Завершает вычислительный процесс вызов базового одноименного метода родительского класса, который формирует финальный выход объекта. Именно этот результат и является тем самым сигналом, который может быть интерпретирован в контексте торговой системы как структурированное представление рыночного состояния, прошедшее через несколько уровней фильтрации, смешивания и сценарного анализа.
Если рассматривать блок в целом, становится очевидно, что CNeuronUniMixerBlock выполняет роль полноценного вычислительного контура. Он принимает на вход поток рыночных данных, последовательно преобразует его через несколько уровней абстракции и выдает структурированный результат.
С практической точки зрения такой уровень абстракции особенно важен. Он позволяет перейти от работы с отдельными операциями к управлению целыми блоками, что значительно упрощает построение и масштабирование модели. В условиях реального рынка это означает возможность быстрее адаптировать систему под новые инструменты, изменять глубину анализа и экспериментировать с конфигурацией без переработки всей архитектуры.
Тестирование
Обучение UniMixer представляет собой последовательное освоение рыночной динамики. Модель проходит путь от исторических данных к реальной рыночной адаптации. На первом этапе — офлайн-обучении — система анализирует архив котировок EURUSD таймфрейма H1 за 2025 год и формирует внутренние представления структуры рынка. Последовательные ценовые движения преобразуются в токенизированные и контекстные представления, после чего проходят через каскад модулей UniMixer, включая механизмы смешивания признаков и стабилизации распределений через SiameseNorm. В результате модель учится выделять устойчивые зависимости между рыночными состояниями.
Следующий этап — онлайн-адаптация в тестере MetaTrader 5. Переводит систему в режим взаимодействия с потоком данных. Здесь модель начинает работать с последовательностью новых рыночных наблюдений, постепенно корректируя внутренние представления. Обновляются веса, уточняются сценарные зависимости. Структура признаков адаптируется под текущий рыночный контекст. В отличие от офлайн-обучения, рынок воспринимается как непрерывный процесс, требующий постоянной подстройки модели.
Финальный этап тестирования на данных января–марта 2026 года служит проверкой устойчивости архитектуры UniMixer. Модель сталкивается с новыми рыночными режимами, не повторяющими структуру обучающего периода.
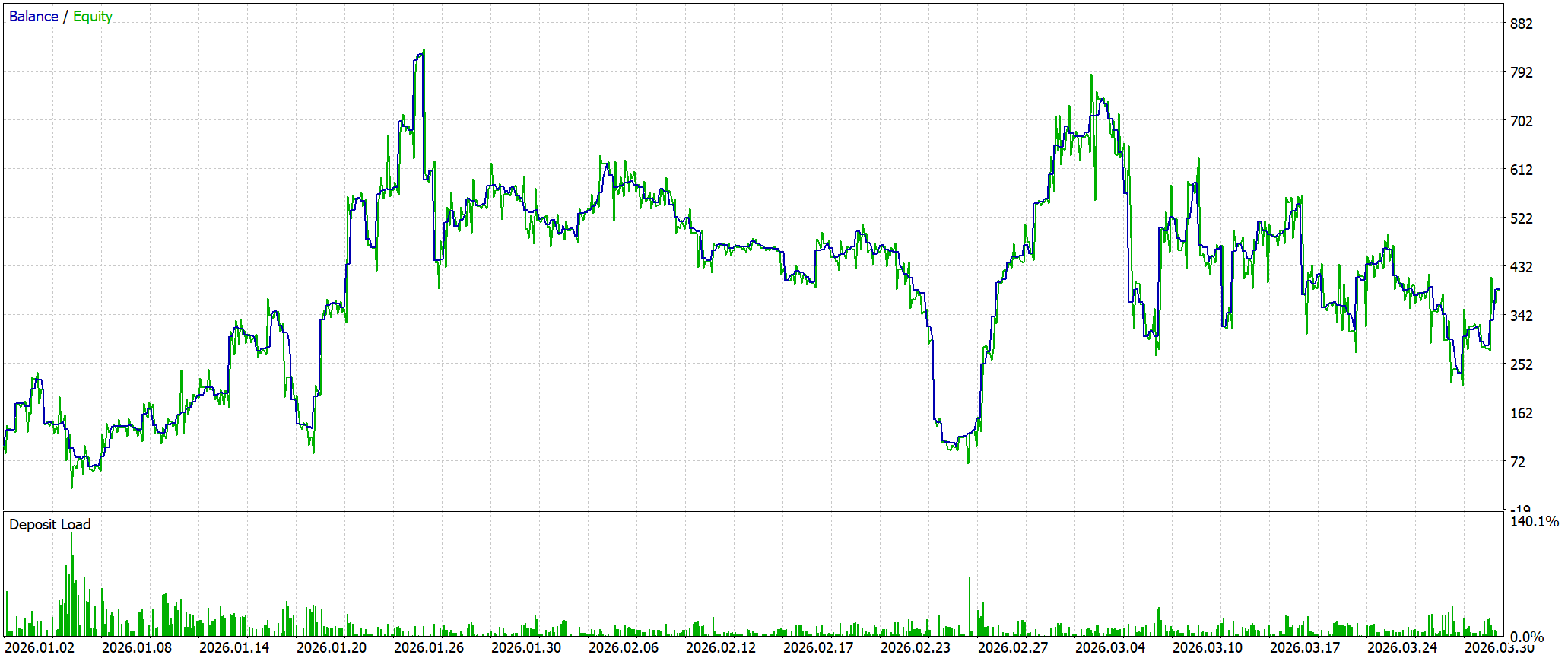
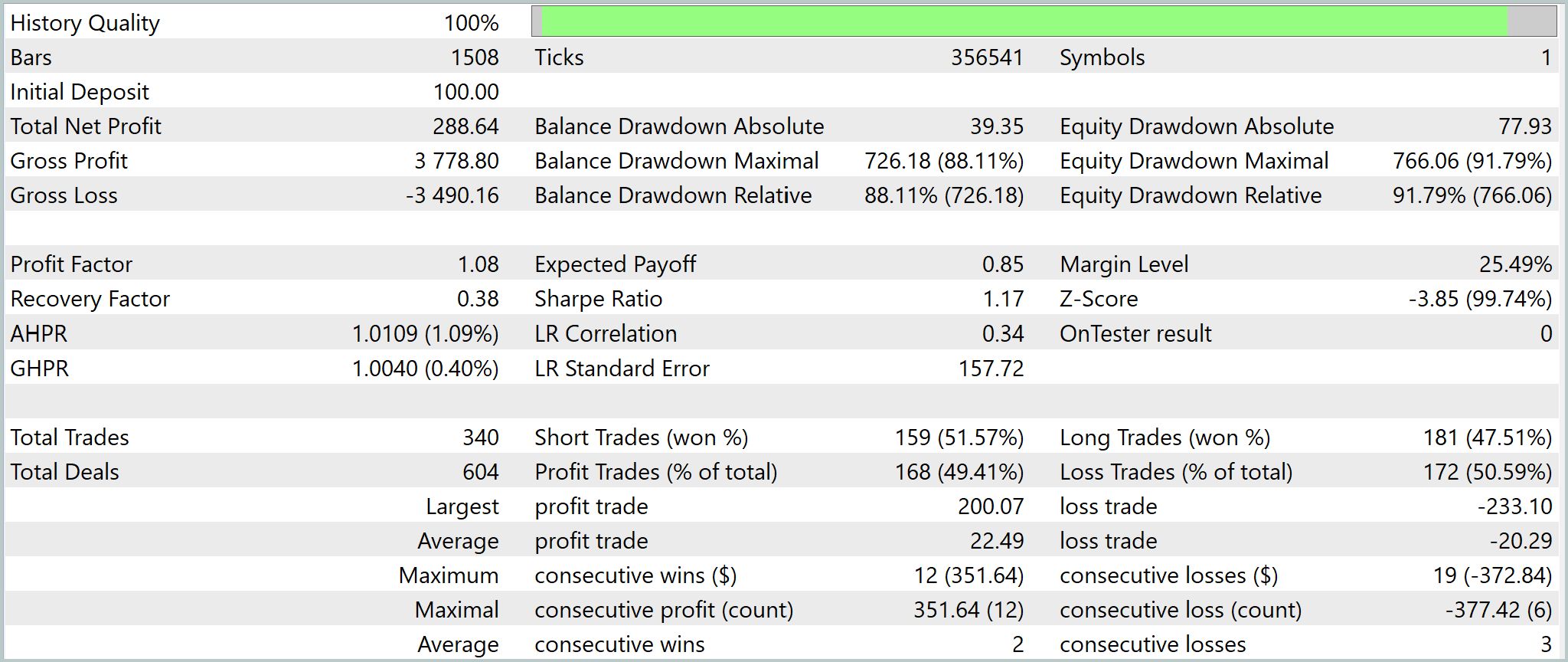
Тестирование на исторических данных показало умеренно положительный, но нестабильный результат. При стартовом депозите 100.0USD итоговая прибыль составила 288.64USD. Однако качество этого роста остаётся слабым: Profit Factor равен 1.08, что указывает на минимальный статистический перевес системы. Количество сделок (340) с практически равным распределением прибыльных и убыточных позиций подтверждает, что преимущество формируется не за счёт высокой точности прогнозов, а за счёт небольшого смещения математического ожидания в сторону прибыли.
Наиболее критическим фактором стала высокая волатильность капитала. Максимальная просадка достигала 88–92%, что фактически означает почти полную потерю накопленной прибыли в отдельных фазах теста. Это указывает на слабую стабилизацию риск-профиля и высокую чувствительность модели к смене рыночных режимов. Несмотря на это, система сохраняет способность восстанавливаться и формировать новые участки роста, что говорит о наличии базовой структурной предсказательной силы.
В целом UniMixer демонстрирует рабочую, но агрессивную торговую динамику. Модель способна извлекать прибыль из рыночных данных, однако текущая конфигурация требует усиления контроля просадки и стабилизации поведения эквити. Результат следует рассматривать как промежуточный этап развития архитектуры, подтверждающий её потенциал, но не готовность к устойчивому промышленному применению без дальнейшей доработки риск-менеджмента.
Заключение
Завершён цикл адаптации фреймворка UniMixer средствами MQL5. Реализованы основные компоненты и система собрана в единый вычислительный граф, обеспечивающий согласованную обработку последовательных и контекстных рыночных сигналов, формирование итогового торгового представления.
Проведённое тестирование на исторических данных подтвердило работоспособность архитектуры и её способность извлекать статистически значимые зависимости из рыночной динамики. Вместе с тем выявлены ограничения, связанные с высокой просадкой и недостаточной стабилизацией риск-профиля, что указывает на необходимость дальнейшей настройки управления капиталом и адаптации к смене рыночных режимов.
В целом UniMixer показал себя как рабочая, но ещё не финализированная торговая архитектура: с выраженным потенциалом к развитию и необходимостью последующей оптимизации для перехода к устойчивому практическому применению.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен на forge.mql5.io/dng.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования