
Переосмысливаем классические стратегии (Часть 13): Обновление стратегии по пересечению скользящих (Часть 2)

В предыдущем обсуждении пересечений скользящих средних мы рассмотрели способы снижения задержки, присущей скользящим средним. Как мы все знаем, стратегии на основе пересечения скользящих генерируют запаздывающие сигналы. Но зафиксировав периоды обеих скользящих средних на одном значении (например, периоде три, как в предыдущей статье) можно получить значительно более оперативные торговые сигналы. Это достигается благодаря тому, что мы применяем индикаторы скользящих отдельно к ценам открытия и закрытия, и при этом они используют один и тот же период. И затем мы наблюдаем пересечения между скользящими средними по цене открытия и цене закрытия. Задержка также уменьшается благодаря использованию коротких периодов, как правило менее пяти.
Итак, мы увидели, что данная стратегия обладает преимуществами по сравнению с классическим подходом на основе пересечения скользящих. В первой публикации мы сравнили предложенную новую стратегию пересечения с классическим вариантом. Сегодня мы продолжим развивать стратегию по пересечения скользящих и попытаемся еще больше сократить задержку. Для этого исследуем возможность прогнозирования пересечений до их фактического возникновения. Это позволит быстрее реагировать на торговые возможности. В отличие от большинства участников рынка, которые ждут подтверждения и реагируют лишь после того, как пересечение становится очевидным, наша цель — построить статистические модели, способные обнаруживать пересечения заранее, что позволит заранее выставлять сделки еще до начала движения.
Поиск торговых сигналов на фоне рыночного шума может быть сложной задачей. Существует ряд принципов работы с данными, которые могут помочь в этом. В частности, обратимся к презентации команды Лаборатории реактивного движения NASA (NASA Jet Propulsion Laboratory) при Калифорнийском технологическом институте (Caltech), которая содержит ряд полезных идей. Ссылка на презентацию доступна здесь. Эта презентация была посвящена анализу больших данных. В ней содержится ключевой принцип, который относится к нашей теме. Если вам стало интересно, рекомендую самостоятельно ознакомиться с этой презентацией. Вкратце, принцип заключается в том, что некоторые сложные задачи в области анализа данных могут становиться проще при проецировании данных в пространства большей размерности. На рисунке 1 ниже приведен фрагмент оригинальной презентации, о котором я говорю.
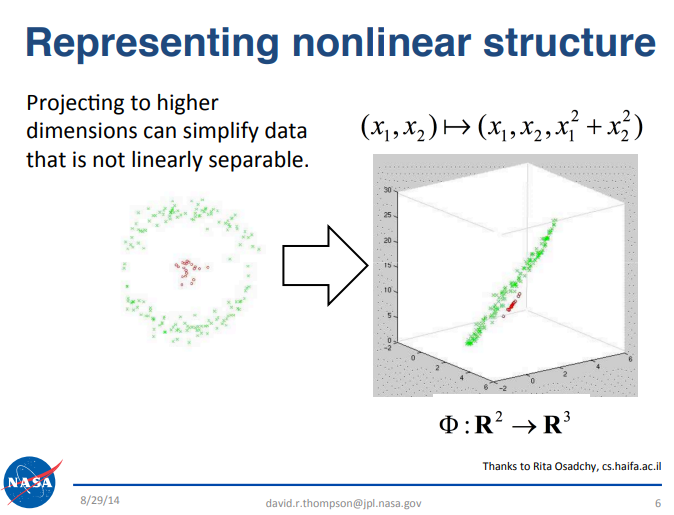
Рисунок 1: Слайд является частью общедоступной презентации "Big Data Analytics", представленной командой NASA JPL в Калифорнийском технологическом институте (Caltech), сентябрь 2014 года.
Для примера рассмотрим набор данных с тремя признаками, где задача состоит в классификации бычьих и медвежьих дней. Достичь высокой точности классификации в таком низком трехмерном пространстве может быть трудно. Но при проецировании набора данных в пространство более высокой размерности результаты могут стать лучше, поскольку некоторые задачи легче разделять в пространствах признаков большей размерности. Хотя методы машинного обучения не гарантируют успеха во всех случаях, как минимум стоит проверить такой подход.
Этот принцип противопоставляется обсуждениям в смежной серии статей о создании самооптимизирующихся советников на MQL5, где мы рассматривали преимущества методов уменьшения размерности, таких как UMAP, позволяющих сократить набор данных с 30 признаков до четырех. Обычно мы стремимся уменьшить размерность, чтобы упростить модели и улучшить их обобщающую способность. Однако в сегодняшней статье мы пойдем противоположным путем и намеренно увеличим размерность набора данных, чтобы посмотреть, что это нам даст.
Мы добавим разработанный вручную метод генерации большого количества новых столбцов признаков. В будущих работах будем использовать более гибкие алгоритмические методы генерации признаков.
Начало работы в MQL5
Для начала мы создадим скрипт, чтобы получать необходимые данные из терминала MetaTrader 5. Прежде всего зафиксируем нужные константы. Например, период для всех скользящих средних будет установлен на фиксированное значение, и во всей статье мы будем использовать простые скользящие средние (Simple Moving Average).
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 2 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 5 //--- Forecast horizon
Кроме того, определим глобальные переменные, обработчики и буферы для скользящих средних.
//--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000;
Далее переходим к определению основной логики нашего скрипта. При выполнении скрипта инициализируем обработчики скользящих средних, после чего скопируем значения из этих обработчиков в соответствующие буферы. При подготовке записи данных в файл помним, что нам придется заполнить большое количество столбцов. Первые восемь столбцов стандартные: цены open, high, low, close, а также соответствующие им значения скользящих средних. Также добавим столбцы для обозначения роста внутри каждого ценового диапазона.
Также есть столбцы, предназначенные для вычисления относительных изменений между различными ценовыми уровнями. Например, помимо расчета изменения цены открытия относительно ее исторического значения, мы также вычисляем изменение цены открытия относительно цены закрытия, изменение цены открытия относительно минимальной цены и так далее. Аналогичные вычисления делаем и для скользящих средних. В итоге мы получим 40 столбцов в наборе данных. В конце сохраняем фактические значения, которые нужно записать, и закрываем обработчик.
//+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA C", "True MA O", "True MA H", "True MA L", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Close 2", "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2", //--- Grwoth between channels "O - C", "Delta O - C", "O - L", "Delta O - L", "O - H", "Delta O - H", "H - L", "Delta H - L", "C - H", "Delta C - H", "C - L", "Delta C - L", //--- Grwoth between MA channels "MA O - C", "MA Delta O - C", "MA O - L", "MA Delta O - L", "MA O - H", "MA Delta O - H", "MA H - L", "MA Delta H - L", "MA C - H", "MA Delta C - H", "MA C - L", "MA Delta C - L" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_reading[i], ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_reading[i] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), //--- Growth between moving average channels ma_o_reading[i] - ma_reading[i], ma_o_reading[(i + HORIZON)] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_l_reading[i], ma_o_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_o_reading[i] - ma_h_reading[i], ma_o_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_h_reading[i] - ma_l_reading[i], ma_h_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_reading[i] - ma_h_reading[i], ma_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_reading[i] - ma_l_reading[i], ma_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Анализ данных в Python
После запуска скрипта в терминале и получения необходимые данные, можно переходить к анализу и обработке данных. Начнем с загрузки стандартных библиотек для численного анализа.
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Далее нужно прочитать наборы данных. Можно заметить, что набор данных имеет значительную ширину, и некоторые столбцы обрезаны при отображении.
data = pd.read_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\EURUSD Market Data As Series Moving Average.csv")
data 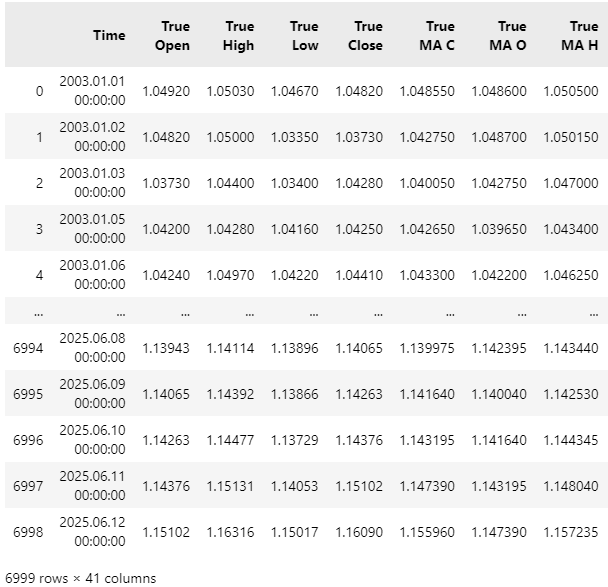
Рисунок 2: Визуализация данных, полученных из MetaTrader 5.
Затем определим целевую переменную. Напомню, что в нашем примере целевой переменной является пересечение скользящих средних. Простой способ отслеживания этого пересечения заключается в наблюдении за средней точкой (midpoint) между двумя скользящими средними. Отслеживаем, повышается или понижается эта средняя точка, и используем эту информацию для наших статистических моделей.
HORIZON = 10 #Classical Target data['Target'] = 0 #High Low Mid Point Target data['Target 2'] = 0 #Open Close Mid Point Target data['Target 3'] = 0 data.loc[data['True Close'].shift(-HORIZON) > data['True Close'],'Target'] = 1 #The Mid Point Between The High And The Low Moving Average data.loc[((data['True MA H'].shift(-HORIZON) + data['True MA L'].shift(-HORIZON)) / 2) > ((data['True MA H'] + data['True MA L']) / 2),'Target 2'] = 1 #The Open And Close Mid Point data.loc[((data['True MA O'].shift(-HORIZON) + data['True MA C'].shift(-HORIZON)) / 2) > ((data['True MA O'] + data['True MA C']) / 2),'Target 3'] = 1 data = data.iloc[:-HORIZON,:]
Прежде чем двигаться дальше, я хотел бы привести краткую демонстрацию, иллюстрирующую ценность проецирования наборов данных в пространства большей размерности. Поэтому если вы не знакомы с данным принципом, такая демонстрация может быть вполне убедительной. Сначала мы создадим копию исходного набора данных, содержащую только стандартные четыре столбца: цены open, high, low и close. И пересчитаем нашу целевую переменную на этом сокращенном наборе данных.
#Copy the dataset X = data.iloc[:,:5].copy() X['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] X.dropna(inplace=True)
Далее определим функцию, которая принимает набор данных и добавляет к нему произвольное количество столбцов, заполненных нулями. Например, если вызовем функцию для копии нашего набора данных и укажем пять столбцов, она вернет набор данных с пятью дополнительными столбцами, каждый из которых будет заполнен нулями.
def fill_zeros(f_data,f_n): #Copy the original data res = f_data.copy() #We want to keep the target at the end t = 'Target' v = res.pop('Target') #Add columns of zeros for i in np.arange(f_n): name = str(i) + ' Col' res[name] = 0 #Place the target back res[t]= v #Return the new dataframe return(res)
Проведем простой тест, выполнив кросс-валидацию модели при постепенно увеличивающемся количестве столбцов, заполненных нулями, и понаблюдаем за тем, как это влияет на ошибку кросс-валидации. График точно нельзя назвать гладким, и это указывает на вариативность ошибки по мере увеличения размерности.
Тем не менее ясно видно, что график достигает новых минимумов, которых не удавалось достичь ранее. В самом начале показан уровень ошибки модели без дополнительных столбцов, заполненных нулями. По мере увеличения количества нулевых столбцов ошибка сначала резко возрастает, а затем снижается до новых минимумов, которых ранее не было. Можно задуматься, почему производительность модели улучшается, несмотря на то, что ей не предоставляется никакой дополнительной информации — напомню, нулевые столбцы не содержат полезных данных для модели.
#Load our libraries from sklearn.neural_network import MLPRegressor from sklearn.model_selection import cross_val_score,TimeSeriesSplit tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) EPOCHS = 50 #Observe what happens to our error levels as we increase the number of columns in the dataset res = [] for i in np.arange(EPOCHS): #Fetch new data with addtional columns of zeros new_data = fill_zeros(X,(1+i)) #Record the new error res.append(np.mean(np.abs(cross_val_score(MLPRegressor(hidden_layer_sizes=(new_data.iloc[:,1:-1].shape[1],2,50,100),random_state=0,shuffle=False),X.iloc[:,1:-1],X.iloc[:,-1],cv=tscv,n_jobs=-1)))) plt.plot(res,color='black') plt.grid() plt.ylabel('RMSE Error') plt.xlabel('Additional Columns of Zero') plt.title('Our Error Levels Can Fall Without Any New Information')
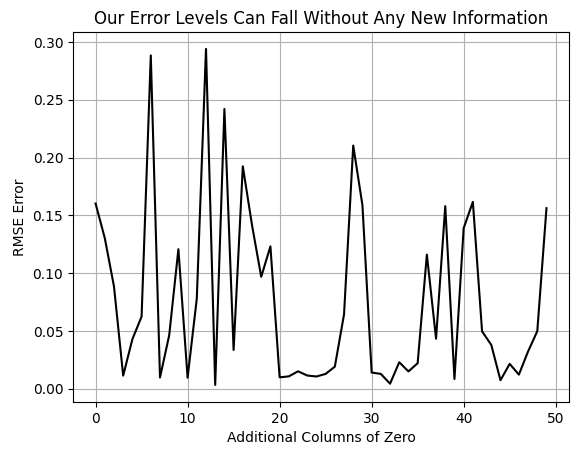
Рисунок 3: Уровень ошибок модели снижается, даже несмотря на то, что мы не предоставляем никакой дополнительной информации.
Существует несколько достаточно правдоподобных объяснений этого явления. В рамках данной статьи будем придерживаться точки зрения, что увеличение размерности обладает собственной ценностью. И просто интерпретируем это как подтверждение полезности проецирования данных в пространства более высокой размерности. Хотя существуют и другие корректные объяснения, для целей нашего обсуждения эксперимент выше будет служить достаточным обоснованием, чтобы создать 32 дополнительных столбца в нашей выборке. Предполагаем, что, увеличивая количество дополнительных столбцов, сможем достичь новых минимумов ошибки. Но вместо добавления нулей будем добавлять осмысленную информацию.
Далее перейдем к определению входных и выходных столбцов. Сначала соберем все входные столбцы и сохраняем их в переменной с именем X.
X = data.iloc[:,1:-4].columns
Перечислим целевые переменные.
y2 = data['Target 2']
Также нужно определить функцию, которая вернет новый экземпляр статистической модели.
return(RandomForestClassifier(random_state=0,n_estimators=500,max_depth=3,min_samples_leaf=20))
Затем исключаем любые данные периода бэктеста, чтобы не переобучить модель на всех доступных данных. Важно зарезервировать часть данных исключительно для тестирования. Далее стандартизируем и масштабируем набор данных. Для этого отнимем средние значения столбцов и поделим на стандартные отклонения столбцов для каждого из 40 столбцов. В результате получается масштабированная выборка.
data = data.iloc[:-(365*2),:] Z = pd.DataFrame(columns=['Z1','Z2']) Z['Z1'] = data.loc[:,X].mean() Z['Z2'] = data.loc[:,X].std() data.loc[:,X] = (data.loc[:,X] - data.loc[:,X].mean()) / data.loc[:,X].std()
Обучим модель на обучающих данных, после чего подготовим для экспорта в формат ONNX, чтобы использовать ее в MQL5.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.ensemble import GradientBoostingRegressor model = GradientBoostingRegressor(random_state=0,max_depth=3) model.fit(data.loc[:,X],data.loc[:,'Target 2']) initial_types = [("FLOAT INPUT",FloatTensorType([1,len(X)]))] model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) onnx.save(model_proto,"EURUSD GBR PRICE D1.onnx")
Соберем все вместе
Теперь приступим к сборке советника. Первая задача — определить глобальные константы, которые не предполагается изменять. Обратите внимание, что многие из этих определений совпадают с теми, которые мы задали ранее в нашем скрипте для получения данных. Период скользящей средней и ее тип остаются фиксированными на тех же значениях. Кроме того, установим длительность удержания каждой позиции, а также таймфрейм, на котором будет вестись торговля.
//+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //--- Define our moving average indicator #define MA_PERIOD 2 //Moving Average Period #define MA_TYPE MODE_SMA //Type of moving average we have #define HORIZON 10 //Forecast horizon #define TF PERIOD_D1
Далее объявим важные глобальные переменные. Например, значения Z1 и Z2, используемые для стандартизации и масштабирования нашего набора данных, нужно хранить в советнике. Также нужны глобальные переменные для обработчиков скользящих средних и соответствующих буферов.
//+------------------------------------------------------------------+ //| Global definitions | //+------------------------------------------------------------------+ float Z1[] = { 1.23933432e+00, 1.24403263e+00, 1.23474846e+00, 1.23936216e+00, 1.23935910e+00, 1.23933128e+00, 1.24402971e+00, 1.23474522e+00, 3.83991053e-05, 3.60920275e-05, 3.66240614e-05, 3.55759706e-05, 3.68749001e-05, 3.98194600e-05, 3.78958300e-05, 3.79070139e-05, -2.78415082e-05, -3.06646429e-05, 4.58586036e-03, 4.58408532e-03, -4.69831123e-03, -4.70061831e-03, 9.28417159e-03, 9.28470363e-03, -4.67046972e-03, -4.66995367e-03, 4.61370187e-03, 4.61474996e-03, -2.78151462e-05, -3.07597060e-05, 4.58606247e-03, 4.58415002e-03, -4.69842067e-03, -4.70034430e-03, 9.28448314e-03, 9.28449433e-03, -4.67060553e-03, -4.66958460e-03, 4.61387762e-03, 4.61490973e-03 }; float Z2[]= { 0.12576155, 0.12640182, 0.125071, 0.12572605, 0.12568469, 0.125719, 0.12636385, 0.12503521, 0.0150256, 0.01494947, 0.01478075, 0.01493629, 0.0141562, 0.01423137, 0.01419596, 0.01404453, 0.00669432, 0.0066951, 0.00482275, 0.004823, 0.00493041, 0.00493002, 0.0063063, 0.00630607, 0.0048614, 0.0048616, 0.00471017, 0.0047104, 0.00471147, 0.00471252, 0.00361188, 0.00361259, 0.00371563, 0.00371488, 0.00513505, 0.00513498, 0.0037117, 0.0037125, 0.00353196, 0.00353191 }; //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; int fetch = HORIZON * 2; int timer = 0; int state = 0;
Загрузим нашу ONNX-модель в советника в виде ресурса.
//+------------------------------------------------------------------+ //| Resources | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| DISCLAIMER | //| This ONNX model was trained from 1 January 2003 until 29 January | //| 2023. For reliable results, ensure that all back tests are done | //| beyond the model's training period. | //+------------------------------------------------------------------+ #resource "\\Files\\MA Approximation\\EURUSD GBR MA D1.onnx" as const uchar onnx_proto[];
Подключим необходимые библиотеки и зависимости. Нужна библиотека MQL5 для управления торговыми операциями, а также пользовательская библиотека для работы с моделями ONNX и получения информации о сделках.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; ONNXFloat *onnx_handler; Time *time_handler; TradeInfo *trade_handler;
В процессе инициализации советника загрузим все эти библиотеки и технические индикаторы.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- onnx_handler = new ONNXFloat(onnx_proto); time_handler = new Time(Symbol(),TF); trade_handler = new TradeInfo(Symbol(),TF); Print("Onnx Handler Pointer: ",onnx_handler); onnx_handler.DefineOnnxInputShape(0,1,40); onnx_handler.DefineOnnxOutputShape(0,1,1); //---Setup our technical indicators ma_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //--- return(INIT_SUCCEEDED); }
Добавим удаление всех динамически созданных объектов и освободим технические индикаторы, которые больше не используются.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(ma_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_h_handle); IndicatorRelease(ma_l_handle); delete time_handler; delete trade_handler; delete onnx_handler; }
При получении новых цен будем проверять, сформировалась ли новая свеча. Если свеча сформировалась, обновляем технические индикаторы перед проверкой торговых сигналов.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time_handler.NewCandle()) { update(); check_signal(); } }
Метод обновления технических индикаторов следующий: сначала копируем все значения индикаторов в соответствующие буферы. Это подготавливает входной вектор для нашей ONNX-модели. Модель принимает тот же набор из 40 входных параметров, который мы использовали в предыдущем задании. Перед тем, как передать данные в модель, выполняем их стандартизацию и масштабирование. После этого модель генерирует прогноз.
//+------------------------------------------------------------------+ //| Update our technical data | //+------------------------------------------------------------------+ void update(void) { //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); vectorf model_input_vector = { //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0), iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0), //--- MA OHLC ma_reading[0], ma_o_reading[0], ma_h_reading[0], ma_l_reading[0], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), //--- Growth in MA OHLC ma_reading[0] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_o_reading[(0 + HORIZON)], ma_h_reading[0] - ma_h_reading[(0 + HORIZON)], ma_l_reading[0] - ma_l_reading[(0 + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), //--- Growth between moving average channels ma_o_reading[0] - ma_reading[0], ma_o_reading[(0 + HORIZON)] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_l_reading[0], ma_o_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_o_reading[0] - ma_h_reading[0], ma_o_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_h_reading[0] - ma_l_reading[0], ma_h_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_reading[0] - ma_h_reading[0], ma_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_reading[0] - ma_l_reading[0], ma_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)] }; for(int i =0;i<40;i++) { model_input_vector[i] = ((model_input_vector[i] - Z1[i]) / Z2[i]); } onnx_handler.Predict(model_input_vector); }
Наша функция проверки сигналов работает как и ожидалось. Сначала сбросим таймер, если в данный момент нет открытых позиций, тем самым вернем систему в исходное состояние. Если модель ONNX прогнозирует бычье движение цены, открываем позицию buy. Если прогнозирует медвежье движение — позицию sell. Обратите внимание, что бычьи и медвежьи сигналы соответствуют вероятностям классов, которые выдает модель: вероятность больше 0.5 указывает на ожидаемое бычье движение, а вероятность меньше 0.5 указывает на ожидаемое медвежье движение.
Помимо сигнала модели ONNX, мы также ищем подтверждение со стороны паттерна пересечения скользящих средних. Если позиция уже открыта, отслеживаем таймер и, когда достигается определенное время зрелости позиции, закрываем все открытые позиции и перезапускаем цикл.
//+------------------------------------------------------------------+ //| Check if we have oppurtunities to trade | //+------------------------------------------------------------------+ void check_signal(void) { if(PositionsTotal() == 0) { timer = 0; state = 0; if(onnx_handler.GetPrediction() > 0.5 { state =1; Trade.Buy(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetAsk(),0,0,""); } else if(onnx_handler.GetPrediction() < 0.5 && ma_reading[0] < ma_o_reading[0]) { state =-1; Trade.Sell(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetBid(),0,0,""); } } else { timer++; if(timer >= HORIZON) Trade.PositionClose(Symbol()); } }
Не забывайте делать undefine.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE #undef TF
Теперь протестируем систему на данных, которые были скрыты от модели во время обучения. Выберем все даты за пределами нашего обучающего периода. Напомню, что период обучения завершился 29 января 2023 года.
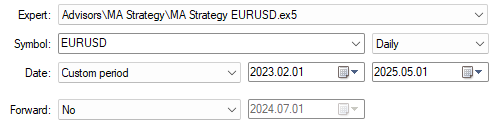
Рисунок 4: Период тестирования не совпадает с периодом обучения, который модель видела.
Обязательно выбираем случайную задержку (Random delay), чтобы реалистично смоделировать непредсказуемую природу реальных торговых сессий.
Рисунок 5: Random delay для реалистичного тестирования.
Кривая доходности от нашей стратегии показана на рисунке 6. Нам удалось сохранить положительную восходящую тенденцию даже при тестировании модели на не известных ей данных. Возможно, благодаря обучению модели на высокодетализированном представлении рынка, созданном с использованием 40 сгенерированных столбцов, она способна лучше обобщать и адаптироваться к условиям, на которых не была обучена.
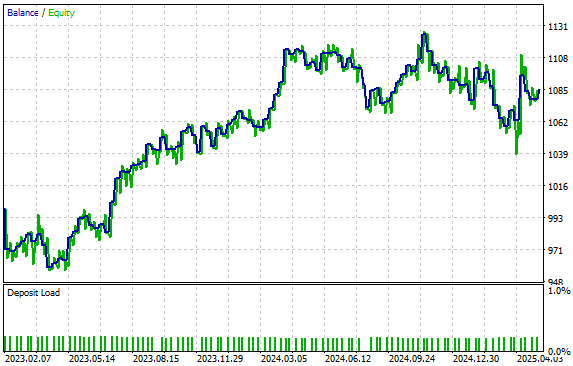
Рисунок 6: Визуализация кривой средств от нашей модели.
Наконец, мы всегда можем просмотреть подробные отчеты об эффективности нашей стратегии. Видим, что 52,9% сделок нашей стратегии оказались прибыльными, а средняя прибыль превышает средний убыток. Это вполне обнадеживающие показатели. Вероятно, тщательная разработка детализированных признаков для наборов данных может иметь положительный эффект. И хотя сам процесс может быть трудоемким и утомительным, дополнительные усилия могут оправдаться.
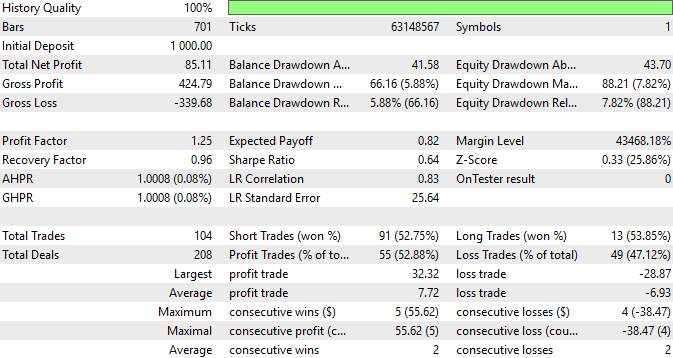
Рисунок 7: Отчеты результатов работы нашей торговой стратегии.
Заключение
Итак, мы предоставили множество практических идей о том, как устоявшиеся стратегии можно переосмыслить и наделить новыми возможностями.
Мы использовали предположение, что модели иногда могут работать лучше в пространствах более высокой размерности, и последовательно снизили задержку в стратегии по пересечению скользящих средних. Для этого мы принудительно обогатили набор данных, что позволило модели получить высокодетализированное представление о рынке. При этом не забывайте, что важно сохранять реалистичные ожидания.
Важно понимать, что увеличение размерности набора данных не всегда гарантирует повышение эффективности модели. Скорее, следует рассматривать это как полезную гипотезу, которую стоит проверить: иногда проецирование данных в пространства большей размерности может дать улучшения. Такой подход не дает гарантий, однако его стоит исследовать. Кроме того, мы увидели, что с задержкой, присущей техническим индикаторам, можно работать, и ее можно снизить благодаря критическому мышлению и творческому подходу. Потенциал терминала MetaTrader 5, по-видимому, действительно огромен.
| Название файла | Описание файла |
|---|---|
| EURUSD GBR MA D1.onnx | Модель ONNX, которую мы создали, используя многомерный набор данных с новыми столбцами. |
| Proof of Case Article.ipynb | Созданный блокнот Jupyter, который демонстрирует преимущества проецирования данных в многомерное пространство. |
| MA Strategy EURUSD.ex5 | Скомпилированная версия советника, разработанного для работы с моделью с увеличенным набором данных. |
| Fetch Data MA.mq5 | MQL5-скрипт для получения многомерного набора данных и записи в CSV-файл. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18525
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования