
Нейросети в трейдинге: Пространственно-управляемая агрегация рыночных событий (Окончание)

Введение
Когда мы говорим о рынке, мы по-прежнему слишком часто говорим языком баров, таймфреймов и усреднений. Это во многом объясняет, почему большинство алгоритмов так хорошо выглядят в учебниках и так плохо переживают реальную торговлю. Рынок не думает свечами. Он живёт событиями. Он реагирует не на закрытие бара, а на появление дисбаланса. На всплеск ликвидности. На ускорение или затухание импульса. Временная сетка, к которой мы привыкли, — лишь костыль, позволяющий человеку упорядочить поток данных. Для самого рынка она вторична.
Именно здесь возникает ключевая проблема. Как только мы жёстко фиксируем время, мы начинаем терять информацию. Асинхронные события попадают в одинаковые контейнеры, быстрые движения размываются, медленные процессы искажаются, шум и сигнал смешиваются, и модели вынуждены угадывать, что из этого действительно важно. Классические индикаторы пытаются компенсировать это фильтрами и сглаживанием, машинное обучение — сложными архитектурами, но первоисточник искажения остаётся прежним: рынок описывается не так, как он существует.
Фреймворк STFlow предлагает взглянуть на задачу с другой стороны. Он не пытается улучшить обработку временного ряда, он предлагает отказаться от самой идеи временного ряда как основной формы представления. В центре подхода — поток событий, разворачивающийся в пространстве рыночной структуры. Цена здесь перестаёт быть просто значением во времени, она становится координатой, а каждое событие — это не точка на оси времени, а элемент движения внутри этой структуры.
Такой взгляд интуитивно близок практикующему трейдеру. Опытный участник рынка всегда смотрит не только на то, что произошло, но и где это произошло. Один и тот же тик на разных уровнях цены имеет разный смысл. Один и тот же объём в разном контексте даёт противоположные сигналы. STFlow формализует эту интуицию и превращает её в строгую вычислительную схему.
Ключевое преимущество фреймворка — пространственно-управляемая агрегация событий. В классических моделях время диктует правила, здесь — правила задаёт структура. Сначала формируется опорное представление рынка — его пространственный каркас. Затем поток событий не просто накапливается, а сопоставляется с этим каркасом. Значимость события определяется не моментом его появления, а тем, как оно вписывается в текущую конфигурацию рынка.
Это даёт сразу несколько эффектов. Во-первых, модель становится устойчивой к неравномерности потока данных: периоды высокой активности и затишья обрабатываются одинаково корректно. Во-вторых, исчезает необходимость агрессивного сглаживания: шум отсекается не фильтром, а контекстом. В-третьих, появляется интерпретируемость: мы можем понять, какие зоны структуры активны, какие события формируют движение и где рынок теряет импульс.
Важно и то, что STFlow хорошо масштабируется. Он одинаково применим к тиковым данным, к агрегациям более высокого уровня и к смешанным источникам информации. Это не индикатор и не торговая стратегия, это фундаментальный способ организации данных. Он не навязывает правила входа и выхода, он даёт более чистое и более честное представление о том, что происходит в рынке прямо сейчас.
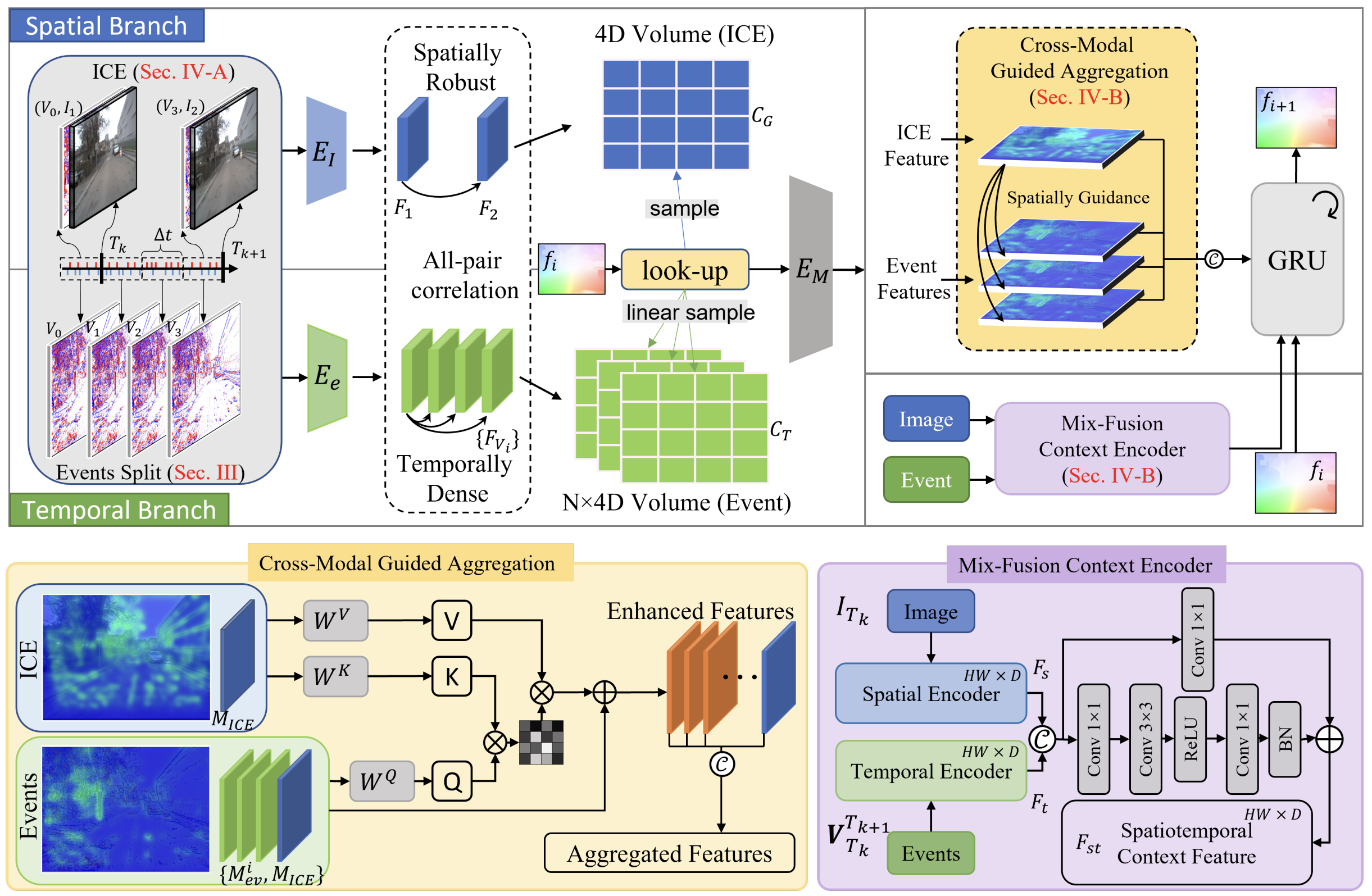
В предыдущих статьях мы шаг за шагом адаптировали этот академический подход к практическим задачам алгоритмического трейдинга. Сначала была сформулирована сама идея перехода от временного ряда к пространственно-временному потоку рыночных событий. Мы показали, что ценовая структура может и должна выступать в роли пространственного контекста. Это стало нашей отправной точкой.
Затем был реализован базовый механизм сопряжения структуры и событий. Мы построили каркас, в котором ценовое представление и поток событий приводятся к общей форме и начинают взаимодействовать. Это позволило отказаться от наивного накопления данных и перейти к согласованному представлению, где каждый элемент имеет своё место и свой вес.
Следующим шагом стала работа с динамикой. Мы перешли от статического сопоставления к кодированию движения. Появились первые элементы, отвечающие за направление, скорость и характер изменений. Была показана возможность совместной обработки нескольких модальностей и организации остаточных связей, которые сохраняют информацию о предыдущих состояниях рынка без её искажения.
К текущему моменту у нас есть каркас STFlow. Он включает пространственное представление рынка, поток событий, механизмы их согласования и первичную обработку динамики. Именно здесь начинается следующий, самый важный этап. Отдельные модули могут быть сколь угодно изящными, но практическую ценность даёт только согласованная система. Рынок не делится на слои и классы, он действует целиком, значит, и наша модель должна вести себя так же — непрерывно, последовательно, без внутренних разрывов.
Объект верхнего уровня
В предыдущей статье мы начали знакомство с объектом верхнего уровня. Мы наметили его роль и обсудили общую логику. Сегодня мы продолжаем эту работу и переходим к сути. Разберём, как внутри этого объекта организуются процессы, как взаимодействуют модули, как данные проходят путь от сырого потока событий до согласованного представления состояния рынка.
Речь пойдёт не о формальных связях. Нас интересует логика жизни системы: кто за что отвечает, в каком порядке принимаются решения, где данные трансформируются, а где лишь передаются дальше. Именно в этих деталях архитектура либо начинает работать как часы, либо рассыпается под нагрузкой реального рынка.
Вначале спокойно и последовательно разберем, как живёт и работает метод прямого прохода в объекте верхнего уровня. Здесь уже нет абстракций, это рабочая логика, в которой каждый шаг имеет смысл и своё место в общем потоке.
bool CNeuronSTFlow::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Create Flow if(!cNorm.FeedForward(NeuronOCL)) ReturnFalse;
Прямой проход начинается с формирования базового потока данных. Сначала выполняется нормализация входа — это важный, но часто недооценённый этап. Мы приводим сырой рыночный сигнал к устойчивому масштабу и форме, в которой дальнейшая обработка становится предсказуемой. Без этого любые последующие вычисления будут зависеть от масштаба и плотности данных, а не от их содержания.
После нормализации входных данных в работу вступает ICE-модуль (CNeuronCreateICEFlow). И здесь принципиально важно правильно понять его роль. Он не просто формирует абстрактный опорный контекст, его задача гораздо конкретнее и, что особенно ценно, очень близка к реальной рыночной логике.
if(!cICE.FeedForward(cNorm.AsObject()))
ReturnFalse;
На вход ICE-модуля подаётся нормализованный вектор описания текущего состояния рынка. Внутри модуля этот вектор сопоставляется с аналогичным вектором предыдущего шага. Таким образом, мы явно вычисляем изменение состояния. Именно это изменение и интерпретируется как событие последнего шага. Не бар, не внешняя эвристика, а чистое, наблюдаемое смещение состояния системы.
Далее это событие не живёт отдельно, оно сразу же конкатенируется с текущим вектором описания окружающей среды, полученным на входе. В результате формируется объединённое представление: в нем одновременно присутствует и то, где рынок находится сейчас, и то, как он изменился по сравнению с предыдущим состоянием. Это ключевой момент. Мы не пытаемся угадать событие, мы его вычисляем и сразу помещаем в контекст.
После конкатенации формируется эмбеддинг совместного представления. На этом этапе сырые признаки превращаются в компактную, согласованную форму, пригодную для накопления и дальнейшего анализа. Полученный эмбеддинг добавляется в стек состояний. Таким образом модель накапливает последовательность событийно-контекстных срезов, каждый из которых уже содержит информацию о структуре и динамике.
Такой подход снимает необходимость в отдельном детекторе событий. Событие здесь — это естественное следствие изменения состояния, а не внешняя интерпретация. Для рынка это особенно важно. Он не сообщает о событиях заранее. Он просто меняется. STFlow фиксирует этот факт напрямую.
Следует обратить внимание, что архитектурно STFlow изначально предполагает отдельную магистраль кодирования потока событий. Это принципиальный момент. События в этой модели — не побочный продукт обработки состояния, а самостоятельный носитель информации о динамике. В классической схеме они могли бы вычисляться параллельно, из тех же исходных данных о состоянии среды.
Однако в нашей реализации мы сознательно уходим от дублирования вычислений. Событие уже было сформировано внутри ICE-модуля как разность текущего и предыдущего состояний. Оно уже прошло первичную интерпретацию и существует в латентном виде. Повторно вычислять его — значит тратить ресурсы и вносить расхождения в представления. Именно поэтому мы аккуратно извлекаем их из латентного состояния ICE-модуля.
if(!cEvents.FeedForward(cICE.GetState()))
ReturnFalse;
Мы берём уже сформированное событие, не трогая логику его определения, и запускаем отдельную ветку кодирования. Сначала формируется собственный эмбеддинг события. Затем этот эмбеддинг добавляется в стек, так же как и представление состояния.
В результате мы получаем два согласованных, но независимых потока: поток состояния среды и поток событий. Они происходят из одного источника, но кодируются разными магистралями. Это позволяет сохранить чистоту архитектуры STFlow и одновременно оптимизировать вычисления. Событие не теряет связи с контекстом, но и не растворяется в нём.
Такой подход хорошо отражает поведение реального рынка. Изменение состояния и само состояние всегда связаны, но их влияние на дальнейшее движение различно. STFlow учитывает это различие на уровне архитектуры, а cEvents аккуратно поддерживает его на уровне реализации.
После этого начинается работа энкодера признаков. В оригинальной архитектуре STFlow авторы изначально закладывают две независимые магистрали кодирования. Одна отвечает за представление состояния и контекста, формируемого ICE-модулем. Вторая — за кодирование потока событий. Эти магистрали не объединяются на ранних этапах. Напротив, они обрабатываются раздельными энкодерами, хотя и построенными по схожему архитектурному шаблону. Такой подход подчёркивает концептуальное различие между состоянием среды и динамикой её изменений.
Однако у этого решения есть практическая цена. Даже при идентичной архитектуре энкодеров вычисления выполняются последовательно. Сначала обрабатывается один поток, затем другой. Для офлайн-задач это допустимо, а для онлайна — уже проблема. Задержка накапливается, а рынок ждать не умеет.
Именно поэтому в нашей реализации мы сознательно отходим от буквального следования схеме авторов, не нарушая её смысл. Вместо отдельных энкодеров мы формируем один многомерный тензор, в котором поток ICE и поток событий существуют как независимые подпространства. Они не смешиваются логически, но обрабатываются параллельно в рамках единого энкодера.
CNeuronBaseOCL* prev = cEncoder[0]; CNeuronBaseOCL* curr = NULL; uint bottleneck = cICE.GetDimension(); uint units = cICE.GetStackSize(); uint correl = cICECorrelation.Neurons() / units; //--- Feature Encoder if(!prev || !Concat(cICE.getOutput(), cEvents.getOutput(), prev.getOutput(), bottleneck, bottleneck, units)) ReturnFalse; for(int i = 1; i < cEncoder.Total(); i++) { curr = cEncoder[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Ключевой момент здесь — устройство самого энкодера. Мы используем сверточные слои без перекрытия окон свёртки. Это не случайный выбор и не компромисс. Такая конфигурация гарантирует, что каждый поток обрабатывается автономно. Свертка не захватывает соседние области. Не смешивает признаки и не разрушает границы между магистралями. По сути, внутри одного вычислительного графа работают несколько независимых каналов.
В результате мы получаем сразу несколько преимуществ. Архитектурная чистота STFlow сохраняется, состояние и события остаются раздельными по смыслу. При этом вычисления выполняются параллельно, что критично для работы в реальном времени. Энкодер становится не точкой слияния, а точкой синхронной обработки.
Именно в этом месте реализация начинает отличаться от академического описания — не концептуально, а инженерно. Мы не упрощаем модель, мы адаптируем её к условиям живого рынка, где задержка важнее формальной симметрии архитектуры.
Когда базовое представление сформировано, мы переходим к блоку, который отвечает за динамику. Выход энкодера разделяется на несколько смысловых частей: пространственный контекст сохраняется отдельно, признаки событий переходят в эмбеддинг, который далее используется для анализа движения.
//--- Moution Encoder if(!DeConcat(cICEEmbedding.getOutput(), cContext.getOutput(), cEventsEmbedding.getOutput(), prev.getOutput(), bottleneck, 2 * bottleneck, bottleneck, units)) ReturnFalse;
Такой декомпозицией мы избегаем смешения статической структуры и динамических изменений.
Затем следует один из ключевых моментов всей архитектуры — вычисление разреженной корреляции с дилатацией. Мы отдельно строим корреляционные объёмы для пространственного представления и для событий.
if(!DilatedCorrelation(cICEEmbedding.AsObject(), cICECorrelation.AsObject(), ibShifts, bottleneck, units)) ReturnFalse; if(!DilatedCorrelation(cEventsEmbedding.AsObject(), cEventsCorrelation.AsObject(), ibShifts, bottleneck, units)) ReturnFalse;
Это позволяет оценить не просто наличие изменений, а их характер во времени и пространстве. Дилатация даёт возможность смотреть шире, не увеличивая вычислительную нагрузку линейно. По сути, мы оцениваем движение сразу на нескольких масштабах.
После этого признаки и корреляции снова объединяются в многомерный тензор. Формируется комплексное представление, в котором локальные особенности сочетаются с динамическими связями.
if(!Concat(cICEEmbedding.getOutput(), cICECorrelation.getOutput(),
cEventsEmbedding.getOutput(), cEventsCorrelation.getOutput(),
cFeatureVsCorrelation.getOutput(),
bottleneck, correl, bottleneck, correl, units))
ReturnFalse;
Именно этот тензор поступает на вход Motion-энкодера. Здесь модель начинает понимать, как рынок движется, а не просто где он находится.
if(!cMoutionEncoder.FeedForward(cFeatureVsCorrelation.AsObject()))
ReturnFalse;
Когда мы доходим до cMoutionEncoder (CNeuronSpikeMFE), архитектура снова подчёркивает свою изначальную идею — параллельность анализа, а не последовательное переваривание признаков. Motion-энкодер здесь не является точкой слияния потоков в привычном смысле. Он не смешивает признаки ICE и событий в одну неразличимую массу. Напротив, внутри него организован параллельный анализ движения для каждой модальности.
К этому моменту у нас уже есть чётко разделённые представления. С одной стороны — эмбеддинги, отражающие изменение и структуру ICE. С другой — эмбеддинги событийного потока. Обе модальности дополненны корреляционными объёмами. Они находятся в одном тензоре, но занимают разные области. Это важно. Motion-энкодер воспринимает их как независимые источники динамики.
Архитектурно CNeuronSpikeMFE устроен так, что вычисления для этих частей выполняются параллельно: ICE-поток отвечает за эволюцию структуры состояния рынка, событийный поток — за характер и интенсивность изменений. Оба процесса идут одновременно, не мешая друг другу и не навязывая общий ритм.
Именно поэтому Motion-энкодер не учит рынок двигаться, а распознаёт движение в уже согласованных координатах. Он не теряет информацию о том, откуда пришло изменение — из структуры или из событий. Это особенно важно в онлайне, где задержка и искажение динамики сразу отражаются на качестве решений.
Таким образом, cMoutionEncoder продолжает ту же инженерную линию, что была заложена ранее. Параллельные магистрали сохраняются, вычисления синхронизируются, но не сериализуются. STFlow здесь окончательно перестаёт быть каскадом слоёв и начинает работать как система, которая анализирует рынок сразу в нескольких измерениях движения.
Далее следует этап агрегации. Это место, где пространственный и событийный контексты начинают активно влиять друг на друга. Модель учится выделять те движения, которые действительно подтверждаются структурой рынка.
В оригинальной архитектуре STFlow для агрегации признаков двух модальностей используется модуль кросс-внимания. При этом авторы явно задают роли: признаки ICE выступают в качестве контекста, а конкатенированный тензор — в качестве запроса. Идея проста и здравая. Движение интерпретируется не само по себе, а через призму текущей структуры состояния. Контекст задаёт рамку, в которой события либо подтверждаются, либо теряют значимость.
В классической реализации это приводит к необходимости разделять потоки, формировать отдельные тензоры и затем снова связывать их на этапе внимания. Архитектурно это корректно, но с инженерной точки зрения не оптимально для онлайна. Каждый такой шаг — это дополнительное копирование данных, дополнительные синхронизации и, как следствие, лишняя задержка.
В нашей реализации мы решаем эту задачу проще и, что важно, без нарушения исходного смысла модели. Поскольку на предыдущих этапах мы уже сформировали единый конкатенированный тензор, разделять его обратно нет никакого практического смысла. Вместо этого мы просто меняем порядок данных в памяти. Модальность, которая должна выступать в роли контекста, перемещается в начало буфера. После этого указатель на соответствующую область передаётся в модуль кросс-внимания именно как контекст.
//--- Aggregation if(!cTranspose.FeedForward(cMoutionEncoder.AsObject())) return false; if(!cCrossModalAggregation.FeedForward(cMoutionEncoder.AsObject(), cTranspose.getOutput())) ReturnFalse;
С точки зрения алгоритма ничего не меняется. ICE-признаки по-прежнему определяют контекст, событийные признаки по-прежнему агрегируются относительно этого контекста, меняется лишь способ организации данных. Мы работаем не с логическим разделением потоков, а с их физическим размещением в памяти. Это тонкий, но принципиально важный инженерный момент.
Такой подход хорошо укладывается в общую философию всей реализации STFlow. Мы сохраняем параллельность вычислений, избегаем лишней сериализации и минимизируем задержки. Архитектура остаётся чистой, модель — интерпретируемой, а система в целом — пригодной для работы в реальном времени, где каждая лишняя операция имеет цену.
Параллельно с кросс-вниманием в системе работает ещё один важный элемент — блок смешанной фьюжн-агрегации. Его роль часто ускользает при поверхностном рассмотрении, но именно он делает итоговое представление по-настоящему устойчивым.
if(!cMixFusion.FeedForward(cContext.AsObject()))
ReturnFalse;
Фьюжн-агрегация не задаёт ведущую модальность заранее. Вместо этого блок адаптивно смешивает контексты двух модальностей, оценивая их вклад в текущем состоянии рынка. В одних ситуациях доминирует структура. В других — динамика событий. Модель не выбирает это решение вручную. Она учится ему. В результате на выходе мы имеем согласованное представление, в котором учтены и структура, и события, и их текущий баланс.
Финальный этап — формирование потока. Результаты кросс-модальной агрегации и контекстной фьюжн-обработки объединяются и подаются в стек блоков обновления потока.
//--- Flow prev = cFlow[0]; if(!prev || !Concat(cCrossModalAggregation.getOutput(), cMixFusion.getOutput(), prev.getOutput(), 2 * bottleneck, bottleneck, units)) ReturnFalse; for(int i = 1; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; } if(!CNeuronSpikeConvBlock::feedForward(prev)) ReturnFalse; //--- return true; }
Здесь представление доводится до формы, пригодной для дальнейшего использования — будь то прогноз, фильтрация сигналов или подача в торговую логику. Завершается прямой проход финальным блоком, который замыкает архитектуру и возвращает управление вызывающей стороне.
В результате мы получаем не просто выход нейросети, мы получаем согласованное представление состояния рынка, сформированное из структуры, событий и динамики. Именно так STFlow перестаёт быть набором модулей и начинает работать как цельная система.
Как бы аккуратно ни была выстроена архитектура, анализ рынка на случайных параметрах остаётся упражнением в форме, а не в содержании. Модель может быть сложной, параллельной и инженерно выверенной. Но без обучения она лишь отражает собственную структуру, а не закономерности рынка, поэтому следующим логичным шагом становится организация корректного обратного прохода и распространения градиентов по всей системе STFlow.
Метод обратного распространения в объекте верхнего уровня выстроен строго зеркально по отношению к прямому проходу. Это не формальность, а принципиальный момент. Каждый блок получает ровно тот градиент, который соответствует его роли в формировании итогового представления, без искажений и искусственных связей.
bool CNeuronSTFlow::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse; //--- if(!CNeuronSpikeConvBlock::calcInputGradients(cFlow[-1])) ReturnFalse; //--- Flow CNeuronBaseOCL* next = cFlow[-1]; CNeuronBaseOCL*curr = NULL; for(int i = cFlow.Total() - 2; i >= 0; i--) { curr = cFlow[i]; if(!curr || !curr.CalcHiddenGradients(next)) ReturnFalse; next = curr; }
Обратный проход начинается с финального выходного блока. Здесь вычисляется градиент по отношению к последнему состоянию потока, уже после всех преобразований. Далее этот градиент последовательно передаётся назад через стек Flow-блоков. Логика здесь классическая и хорошо знакомая: каждый слой получает сигнал ошибки от последующего, корректирует собственные параметры и передаёт градиент дальше. На этом этапе мы ещё работаем с агрегированным представлением рынка.
После завершения обратного прохода по магистрали Flow, мы возвращаемся к точке агрегации модальностей. Градиент, пришедший из потока, распределяется между двумя параллельными ветками — кросс-модальной агрегацией признаокв и блоком смешанной фьюжн-агрегации контекста.
//--- Aggregation uint bottleneck = cICE.GetDimension(); uint units = cICE.GetStackSize(); uint correl = cICECorrelation.Neurons() / units; //--- if(!DeConcat(cCrossModalAggregation.getGradient(), cMixFusion.getGradient(), next.getGradient(), 2 * bottleneck, bottleneck, units)) ReturnFalse; Deactivation(cCrossModalAggregation); Deactivation(cMixFusion);
Это важный момент. Ошибка не навязывает приоритет одной модальности, она распределяется между механизмами, которые по-разному интерпретируют контекст рынка.
Далее выполняется деактивация соответствующих блоков и градиент фьюжн-агрегации передаётся в контекстный тензор.
if(!cContext.CalcHiddenGradients(cMixFusion.AsObject()))
ReturnFalse;
Параллельно начинается обратный проход через Motion-энкодер. Здесь архитектура снова демонстрирует свою ключевую особенность. Градиенты для ICE-признаков и событийного потока обрабатываются параллельно, в тех же независимых подпространствах, что и при прямом анализе движения.
//--- Moution Encoder if(!cMoutionEncoder.CalcHiddenGradients(cCrossModalAggregation.AsObject(), cTranspose.getOutput(), cTranspose.getGradient(), (ENUM_ACTIVATION)cTranspose.Activation())) ReturnFalse;
Особого внимания заслуживает обработка корреляционных объёмов. Градиенты сначала проходят через блок объединённых признаков и корреляций, затем корректно раскладываются обратно на эмбеддинги ICE и событий. После этого выполняется обратный проход через дилатированную корреляцию. Таким образом модель учится не просто реагировать на движение, а уточнять, на каких временных и пространственных масштабах это движение действительно значимо.
CBufferFloat* temp = cMoutionEncoder.getGradient(); if(!cMoutionEncoder.SetGradient(cMoutionEncoder.getPrevOutput(), false) || !cMoutionEncoder.CalcHiddenGradients(cTranspose.AsObject()) || !SumAndNormilize(cMoutionEncoder.getGradient(), temp, temp, bottleneck, false, 0, 0, 0, 1) || !cMoutionEncoder.SetGradient(temp, false)) ReturnFalse; if(!cFeatureVsCorrelation.CalcHiddenGradients(cMoutionEncoder.AsObject())) ReturnFalse; if(!DeConcat(cICEEmbedding.getPrevOutput(), cICECorrelation.getGradient(), cEventsEmbedding.getPrevOutput(), cEventsCorrelation.getGradient(), cFeatureVsCorrelation.getGradient(), bottleneck, correl, bottleneck, correl, units)) ReturnFalse; if(!DilatedCorrelationGrad(cICEEmbedding.AsObject(), cICECorrelation.AsObject(), ibShifts, bottleneck, units)) ReturnFalse; if(!DilatedCorrelationGrad(cEventsEmbedding.AsObject(), cEventsCorrelation.AsObject(), ibShifts, bottleneck, units)) ReturnFalse; if(!SumAndNormilize(cICEEmbedding.getGradient(), cICEEmbedding.getPrevOutput(), cICEEmbedding.getGradient(), bottleneck, false, 0, 0, 0, 1) || !SumAndNormilize(cEventsEmbedding.getGradient(), cEventsEmbedding.getPrevOutput(), cEventsEmbedding.getGradient(), bottleneck, false, 0, 0, 0, 1)) ReturnFalse; Deactivation(cICEEmbedding); Deactivation(cEventsEmbedding);
Следующий этап — возврат к Feature-энкодеру. Здесь градиенты, относящиеся к контексту и событиям, снова объединяются в общий тензор, точно так же, как это делалось при прямом проходе. Это принципиально важно для согласованного обучения. Мы не нарушаем параллельность магистралей, но и не разрываем вычислительный граф. Каждый слой получает градиент в той форме, в которой он видел данные на входе.
//--- Feature Encoder next = cEncoder[-1]; if(!next || !Concat(cICEEmbedding.getGradient(), cContext.getGradient(), cEventsEmbedding.getGradient(), next.getGradient(), bottleneck, 2 * bottleneck, bottleneck, units)) ReturnFalse; Deactivation(next); for(int i = cEncoder.Total() - 2; i >= 0; i--) { curr = cEncoder[i]; if(!curr || !curr.CalcHiddenGradients(next)) ReturnFalse; next = curr; }
После прохождения всех слоёв энкодера градиент разделяется между ICE-модулем и модулем событий. Оба блока деактивируются и получают собственные сигналы ошибки.
//--- Create Flow if(!DeConcat(cICE.getGradient(), cEvents.getGradient(), next.getGradient(), bottleneck, bottleneck, units)) ReturnFalse; Deactivation(cICE); Deactivation(cEvents);
Далее градиент передаётся в состояние ICE, где корректируется механизм вычисления события как разности состояний. Это тонкий, но важный момент. Модель учится не только интерпретировать события, но и формировать их более информативно.
curr = cICE.GetState();
if(!curr ||
!curr.CalcHiddenGradients(cEvents.AsObject()))
ReturnFalse;
Завершается обратный проход возвратом к нормализации и, наконец, к исходному входному нейрону. На этом этапе замыкается полный цикл обучения. Градиент прошёл через все уровни архитектуры, сохранив их смысловую независимость и параллельность.
if(!cNorm.CalcHiddenGradients(cICE.AsObject())) ReturnFalse; //--- if(!NeuronOCL.CalcHiddenGradients(cNorm.AsObject())) ReturnFalse; //--- return true; }
В результате мы получаем не просто обучаемую модель, а систему, в которой обучение подчинено той же логике, что и прямой анализ. Параллельные магистрали остаются параллельными, контекст и события не смешиваются насильно, а STFlow начинает постепенно настраиваться под реальный рынок, а не под абстрактную задачу оптимизации.
Архитектура модели
Мы подошли к важной границе. Работа по формированию собственного взгляда на идеи, предложенные авторами STFlow, завершена. Теория больше не висит в воздухе, архитектурные решения получили конкретную реализацию средствами MQL5 и превратились в рабочий инструмент. Мы подходим к самому интересному и самому честному этапу — проверка того, как этот инструмент ведёт себя в реальных торговых задачах.
Как и в предыдущих работах, мы строим торговую модель, способную самостоятельно анализировать рыночную ситуацию и принимать решения без жёстко заданных правил. Нас по-прежнему интересует не набор эвристик, а поведение системы в целом. Важно, что внедрение STFlow не требует пересмотра всей торговой архитектуры. Мы не ломаем уже отлаженную схему и не усложняем её без необходимости.
Подходы, предложенные в рамках STFlow, интегрируются точечно. Они встраиваются в энкодер анализа окружающей среды, где и раскрывают свою основную силу. В ранее используемой модели мы заменяем лишь последний слой, подключая новый объект верхнего уровня CNeuronSTFlow. Этого оказывается достаточно, чтобы изменить способ восприятия рынка всей системой, не затрагивая остальные компоненты.
Такой подход позволяет сосредоточиться на главном — на качестве представления рыночного состояния и динамики. Модели Актера и Критика перенесены из предыдущих работ без изменений. Полный код архитектурного решения приведён во вложении, что даёт возможность воспроизвести эксперимент и, при необходимости, адаптировать его под собственные задачи.
Тестирование
Экспериментальная часть нашей работы началась с этапа офлайн-обучения на исторических данных EURUSD с таймфреймом H1 за период с Января 2024 по Июнь 2025 года. Модель работала в спокойном, контролируемом режиме, словно исследователь, постепенно осваивающий новую территорию. Она училась распознавать повторяющиеся паттерны, отслеживать динамику изменения цен и выявлять устойчивые связи между ключевыми признаками. Постепенно внутри модели формировалось целостное видение рынка, готовое к встрече с его реальной, непредсказуемой природой.
После офлайн-обучения пришёл этап тонкой онлайн-настройки в тестере стратегий MetaTrader 5. Здесь поток данных уже не был статичным. Рынок шумел, давал резкие ценовые импульсы, сменял режимы поведения. Модель, словно опытный трейдер, училась подстраиваться под текущую динамику, аккуратно корректируя внутренние представления, не разрушая ранее накопленный опыт. Такой подход позволял связать исторические знания с реальной ситуацией, обеспечивая более точные и своевременные торговые решения.
Финальный этап проверки проводился на полностью новых данных за период с Июля по Декабрь 2025 года. Все параметры модели оставались без изменений, что гарантировало объективность оценки. В этих условиях проверялась способность модели обобщать накопленный опыт, верно интерпретировать незнакомые рыночные ситуации и сохранять устойчивость за пределами обучающей выборки.
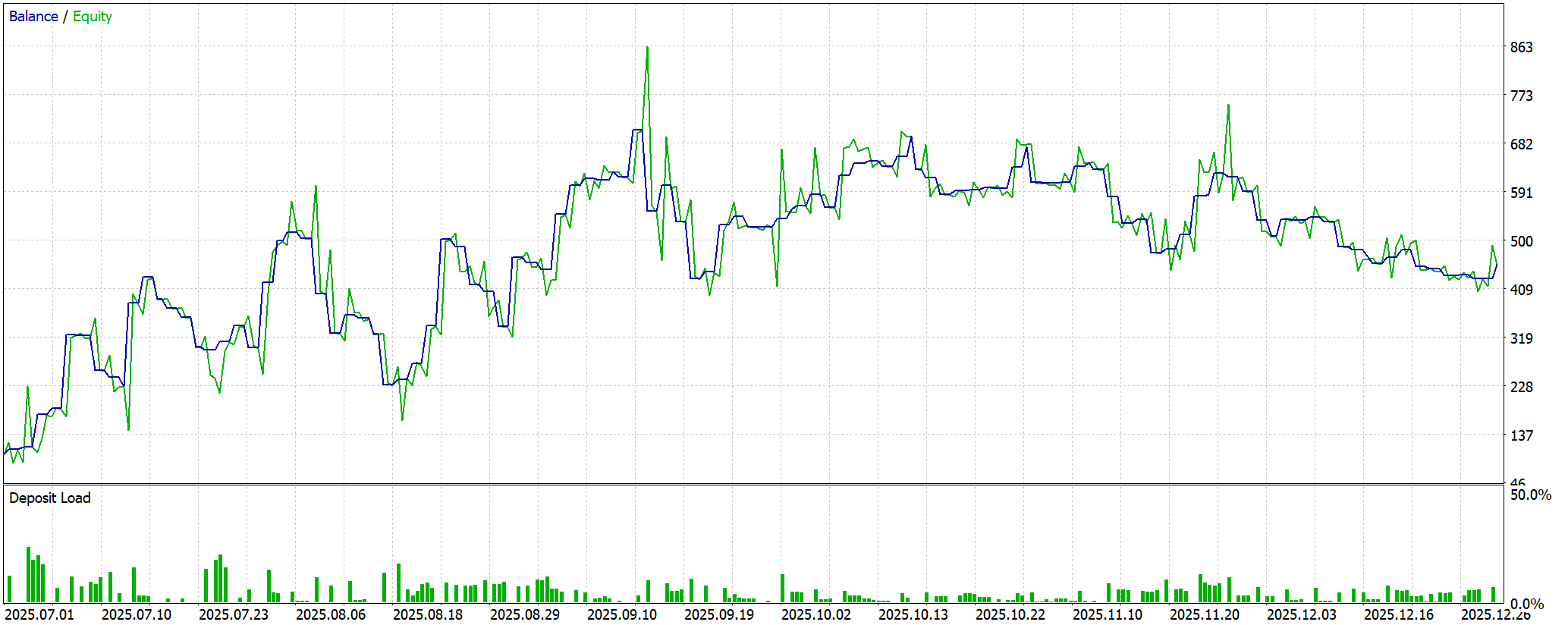
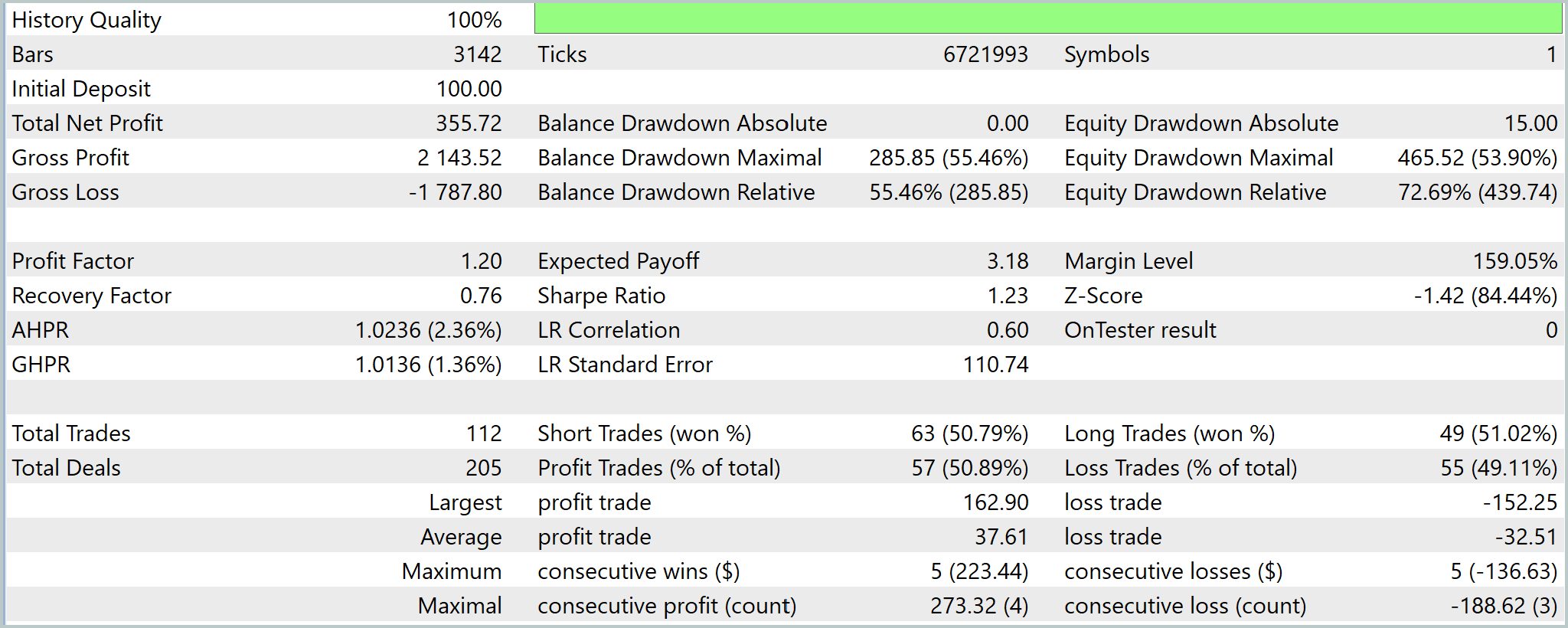
Тестирование показало впечатляющую динамику, одновременно демонстрируя сильные и слабые стороны модели в условиях реального рынка. В течение периода тестирования модель обработала более 6.7 миллионов тиков и 3.1 тысячи баров, начиная с начального депозита $100. Финансовый результат оказался заметным. Чистая прибыль составила $355.72, что увеличило баланс почти в 4.5 раза и обеспечило относительную доходность 356%. Валовая прибыль была $2143.52 при валовом убытке $1787.80, что дало Profit Factor на уровне 1.20. Такой показатель подтверждает положительное математическое ожидание системы, хотя запас устойчивости остаётся умеренным.
Одновременно тест выявил серьёзные риски. Максимальная просадка баланса достигла $285.85 (55.46%), а плавающая просадка Equity — 72.69%, что указывает на агрессивную стратегию удержания позиций и высокую волатильность капитала. Recovery Factor равен 0.76, демонстрируя, что восстановление после экстремальных просадок происходит недостаточно быстро.
Статистические характеристики доходности показывают, что средняя прибыль на сделку составляет $3.18, а коэффициент Шарпа равен 1.23 — приемлемое соотношение риск/доходность, но не на уровне высокостабильных систем.
Серии выигрышей и проигрышей демонстрируют умеренную последовательность — до пяти сделок подряд с прибылью $223.44 и столько же с убытком $136.63. Максимальная накопленная прибыль за четыре сделки составила $273.32, а максимальный последовательный убыток за три сделки — $188.62.
Динамика доходности по месяцам показала рост убытков с удалением от периода обучения, подчёркивая ограниченность накопленного опыта модели в изменяющихся условиях рынка. Чтобы снизить эту зависимость, необходимо расширить обучающую выборку, включив более длинный исторический период или дополнительные рыночные инструменты, чтобы модель получила более разнообразные паттерны.
Альтернативно, или дополнительно, стоит увеличить частоту дообучения модели на новых данных. Регулярное обновление внутренних представлений позволяет STFlow поддерживать актуальное понимание рыночной динамики, корректируя эмбеддинги ICE и событийного потока в соответствии с текущими условиями. Такой подход уменьшает риск деградации доходности по мере отдаления от исходного периода обучения и делает стратегию более устойчивой к смене рыночных фаз.
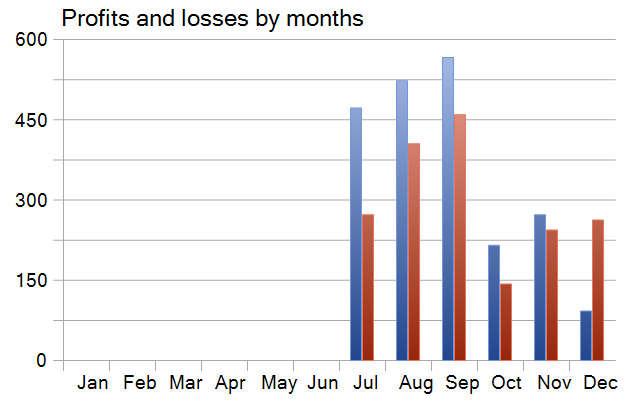
В итоге стратегия проявляет спекулятивно-агрессивный профиль с высокой доходностью ценой экстремальных рисков. Она подходит не для консервативного капитала, но представляет интерес как компонент ансамбля стратегий, основа для оптимизации risk-management и кандидат на внедрение адаптивного контроля позиции.
Заключение
Работа продемонстрировала, что фреймворк STFlow позволяет построить торговую модель нового уровня, способную самостоятельно анализировать рыночное состояние и принимать решения без жёстко заданных правил. Основное преимущество подхода заключается в организации параллельных магистралей обработки информации. ICE-признаки и поток событий кодируются независимо, но внутри единого вычислительного графа. Это обеспечивает минимальные задержки и высокую оперативность реакций на изменения рынка.
Использование отдельных, но согласованных энкодеров позволяет модели сохранять структурное понимание состояния рынка, одновременно отслеживая динамику ключевых событий. Motion-энкодер и блоки агрегации, включая кросс-внимание и адаптивный фьюжн, формируют богатое и согласованное представление рынка, способное учитывать текущую структуру и её изменения во времени. Такая архитектура делает анализ рынка более точным, а принятие решений — обоснованным и гибким.
Тестирование показало, что система способна формировать положительное математическое ожидание, эффективно использовать накопленный опыт и адаптироваться к новым рыночным условиям. При этом интеграция STFlow в существующую торговую систему не требует глобальной перестройки. Достаточно точечной замены верхнего слоя на объект CNeuronSTFlow, что делает подход практичным для внедрения и масштабирования.
В целом, предложенная реализация демонстрирует, что STFlow — это рабочий инструмент анализа рыночной микроструктуры, сочетающий гибкость, скорость реакции и высокую информативность признаков. Фреймворк обеспечивает фундамент для дальнейшего развития адаптивных стратегий и оптимизации управления рисками, открывая новые возможности для применения нейросетевых подходов в трейдинге.
Ссылки
- Spatially-guided Temporal Aggregation for Robust Event-RGB Optical Flow Estimation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования