
Нейросети в трейдинге: Пространственно-управляемая агрегация рыночных событий (Энкодеры)

Введение
Рынок на самом деле передаёт информацию не в виде аккуратных баров и не в виде ровных временных рядов, как непрерывный поток событий. Неравномерный, асинхронный, иногда хаотичный, но при этом удивительно структурированный. Классические модели анализа привыкли закрывать на это глаза — им удобнее работать с фиксированным временем, проще усреднять. Но рынок за эту простоту отвечает шумом, трейдер же — платит запаздыванием и потерей смысла.
Любой практикующий трейдер знает это на интуитивном уровне. Цена может стоять на месте, но внутри уровня идёт ожесточённая борьба. Может пройти одна сделка, но именно она меняет баланс. Может появиться короткий импульс, который исчезнет на минутном баре, но определит направление на часы вперёд. В таких моментах традиционные представления рынка дают сбой. Они видят время, но не видят пространство. Они фиксируют факт движения, но не понимают, где именно это движение произошло и почему оно важно.
Именно здесь появляется STFlow. Не как ещё один нейросетевой блок и не как попытка предсказать рынок умнее. Это фреймворк с более взрослым взглядом на данные. Его ключевая идея проста и потому сильна. События имеют смысл только в контексте структуры. Время должно подчиняться пространству, а не наоборот. В оригинальной работе авторы приходят к этому выводу, анализируя задачи компьютерного зрения и оптического потока. Но финансовый рынок, как ни странно, устроен очень похоже. Он тоже живёт событиями. Он тоже асинхронен. И он тоже имеет выраженную пространственную организацию.
Цена — это не просто число. Это координата. Это уровень, диапазон, граница интересов. События — это не просто тики. Это столкновения заявок, всплески объёма, резкие изменения скорости движения. Когда мы механически агрегируем всё это по времени, мы теряем главное — связь между тем, что произошло, и тем, где это произошло. STFlow предлагает иной порядок мышления. Сначала мы формируем устойчивое представление пространства рынка. Затем именно оно начинает направлять агрегацию событий во времени. Не всё подряд, не равномерно, а избирательно и осмысленно.
Практическое преимущество такого подхода чувствуется почти сразу. Модель перестаёт быть чувствительной к случайному шуму, но при этом не глохнет к микроимпульсам. Она начинает различать движение внутри диапазона и движение на его границе. Начинает по-разному воспринимать одинаковые по величине изменения цены, если они происходят в разных контекстах. Для трейдера это означает более стабильные сигналы, меньше ложных срабатываний и, что особенно важно, более интерпретируемое поведение модели.
STFlow не пытается заменить классический анализ. Напротив, он во многом продолжает его традиции, просто на другом уровне абстракции. Поддержки, сопротивления, зоны накопления — всё это естественным образом ложится в пространственное представление, а события, которые раньше терялись в усреднении, наконец получают свой вес. Можно сказать, что фреймворк возвращает рынку его физику. Он снова становится средой, в которой что-то происходит, а не просто рядом чисел в таблице.
В этом и заключается его главное достоинство. Он не борется со временем, а перестаёт делать вид, что время — единственная ось, которая имеет значение. Он вводит второй каркас — пространственный — и заставляет временную динамику работать в его рамках. И именно поэтому он так интересен.
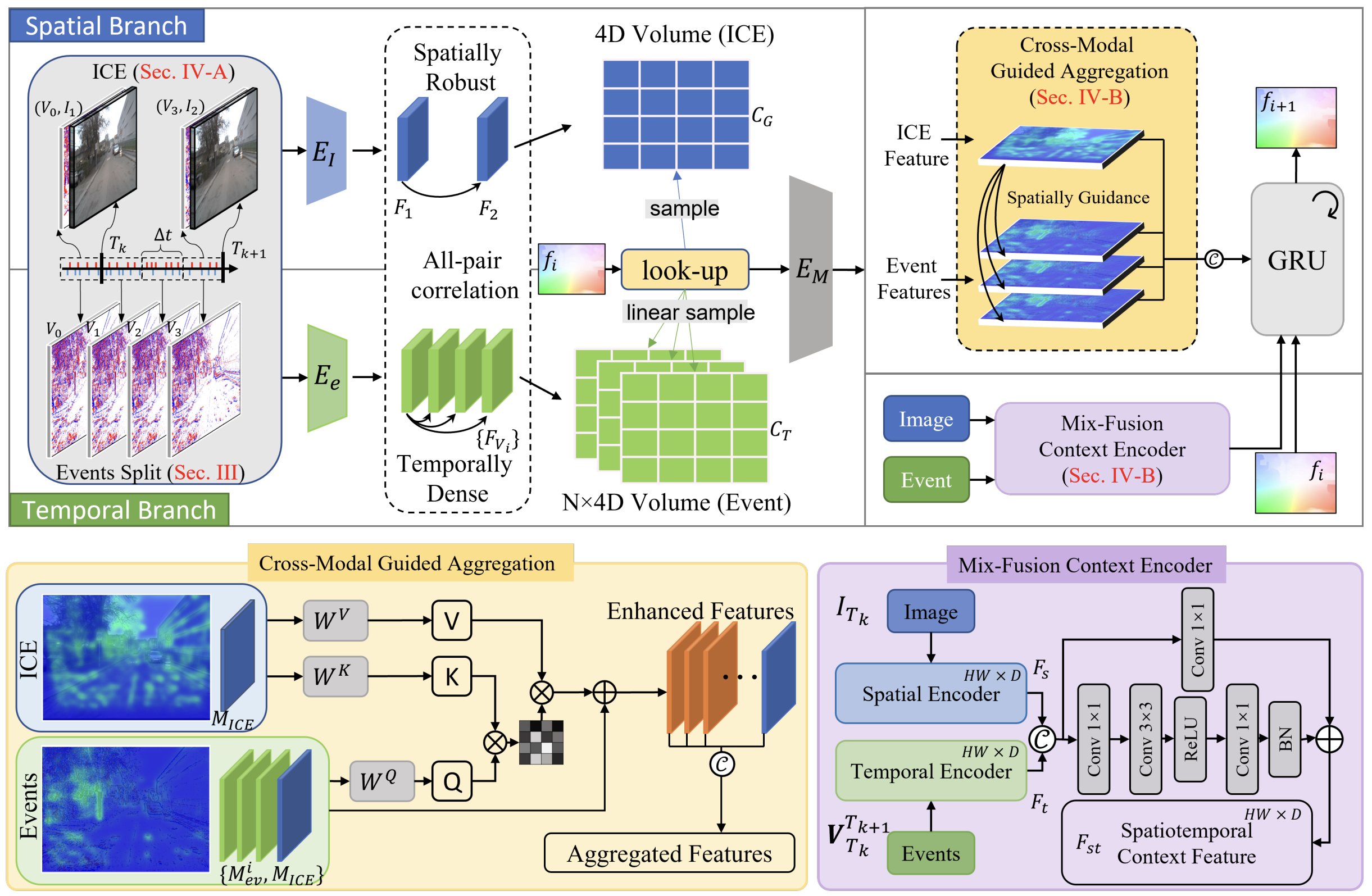
В предыдущих статьях мы уже начали двигаться в этом направлении. Мы не ограничились пересказом оригинальной статьи, а попытались аккуратно и последовательно адаптировать идеи STFlow к реальным финансовым данным. Без магии. Без обещаний мгновенной прибыли. С холодной головой и инженерным подходом. Сначала мы разобрали саму проблему. Затем перешли к формированию пространственного представления рынка. Показали, как можно связать ценовые уровни и события в единую структуру. Как нормализовать данные так, чтобы разные модальности перестали тянуть одеяло на себя. Как подготовить исходные данные для последующей совместной обработки. Это был важный этап. Без него любые разговоры о пространственно-временной агрегации остаются теорией.
Далее мы начали собирать сам каркас STFlow. Реализовали базовые модули, отвечающие за связывание пространственных и событийных признаков. Показали, как формируется совместное представление, в котором динамика перестаёт быть слепой, а структура — статичной.
Важно подчеркнуть, что на этом этапе речь не шла о торговых стратегиях в привычном смысле. Мы сознательно держались подальше от входов и выходов. Нас интересовал фундамент. То, на чём потом можно строить решения.
Текущая статья продолжает эту линию. Мы последовательно углубляем реализацию STFlow, уточняем архитектурные решения и готовим почву для следующего логичного шага — полноценной оценки поведения фреймворка на исторических данных.
Важно сразу задать правильный ракурс. Кодирование сигнала во внутренние представления STFlow — это не линейный конвейер и не последовательность слоёв один за другим. Здесь уместнее думать в категориях параллельной обработки, где несколько потоков анализа развиваются одновременно, каждый со своей логикой и своей задачей. Такой подход хорошо знаком тем, кто работал с реальными рынками. Разные аспекты происходящего нельзя свести к одному измерению без потерь.
STFlow изначально устроен как многопоточный процесс. Пространственно-временные структуры и поток событий обрабатываются независимо. Преждевременное объединение делает модель слепой. Пространственная модальность отвечает за форму рынка. За устойчивые уровни. За диапазоны, границы и зоны концентрации интереса. Событийная модальность, напротив, живёт в режиме повышенной чувствительности. Она фиксирует импульсы, сдвиги, ускорения и локальные всплески активности. Смешивать их на раннем этапе — всё равно что усреднять дневной график с тиками. Формально можно, практически — бесполезно.
На каждом уровне обработки внутри своей модальности сигнал сначала проходит этап внутреннего упорядочивания. Модель пытается понять, что в текущем потоке является динамикой, а что — контекстом. Это принципиальный момент. Динамика — это изменения. Контекст — это фон, относительно которого изменения приобретают смысл. В рынке мы постоянно имеем дело с этим дуализмом. Одно и то же движение цены может быть либо шумом, либо началом тренда. Всё решает окружение. STFlow делает ровно то же самое, только формализованно и последовательно.
При кодировании пространственно-временных структур модель учится выделять устойчивые паттерны. Не отдельные бары и не отдельные свечи, а именно состояния. Состояние рынка — это не мгновенный снимок, а короткая история, собранная в компактное представление. Здесь важно, что корреляция между состояниями рассматривается не как простая временная зависимость. Модель ищет сходства, повторяемость форм, характер переходов. Это очень близко к тому, как опытный трейдер узнаёт рынок с первого взгляда, даже не глядя на конкретные цифры.
Событийный поток проходит похожий. Здесь меньше устойчивости и больше резкости. События редко бывают равномерными. Они приходят пачками, исчезают, возвращаются. В этом потоке модель также разделяет контекст и динамику. Контекст — это текущая плотность событий, их распределение по пространству цены. Динамика — это всплески, ускорения, резкие смещения. И снова важен не сам факт события, а его положение относительно общей структуры рынка.
И только после того, как каждая модальность прошла собственный путь анализа, начинается самое интересное — управляемое слияние. Ключевое слово здесь именно управляемое. STFlow не складывает признаки механически и не усредняет их. Пространственное представление начинает направлять интерпретацию событийного потока. Оно задаёт рамку, внутри которой события получают вес. События, происходящие в структурно значимых зонах, усиливаются. Те, что выпадают из контекста, ослабляются или игнорируются.
В результате формируется согласованное представление, в котором нет конфликта между формой и движением. Рынок перестаёт выглядеть как набор случайных импульсов, но и не превращается в застывшую картинку. Динамика сохраняется, но становится осмысленной. Контекст остаётся стабильным, но не мёртвым.
Энкодер смешивания контекста
Сегодня мы начинаем работу с построением Энкодера управляемого смешивания контекста различных модальностей — Mix-Fusion Context Encoder. Это тот самый узел, где разрозненные потоки анализа перестают существовать сами по себе и начинают говорить на одном языке. Не громко. Без суеты. Но достаточно чётко, чтобы модель могла принимать согласованные решения.
Mix-Fusion Context Encoder не занимается созданием новых признаков в привычном смысле. Его задача тоньше и важнее. Он выстраивает правила взаимодействия уже полученных представлений. Определяет, какая информация в текущий момент должна усиливаться, а какая — отойти на второй план. По сути, он реализует формализованную версию того, что опытный трейдер делает интуитивно, оценивая рынок в комплексе, а не по одному индикатору.
Ключевой момент здесь — контекст. Пространственный контекст задаёт рамку интерпретации. Он определяет, где рынок находится относительно своих ключевых состояний. Событийный контекст сообщает, что именно сейчас происходит внутри этой рамки. Один без другого бесполезен. Вместе они образуют целостную картину.
Управляемость этого процесса принципиальна. Mix-Fusion не работает по принципу всё со всем. Он использует внутренние механизмы, чтобы сохранять баланс между модальностями. Если рынок спокоен, структура выходит на первый план. Если начинается активное движение, событийный поток получает больший вес. Но при этом ни одна из модальностей не доминирует полностью. Модель не впадает ни в слепую реактивность, ни в излишнюю инерционность.
Важно отметить, что на вход Mix-Fusion Context Encoder поступают компактные, устойчивые представления состояний. Это снижает чувствительность к выбросам и делает процесс слияния предсказуемым. Для практического трейдинга это означает меньшую вероятность резких и необъяснимых решений модели вблизи шумовых участков рынка.
Mix-Fusion Context Encoder также играет роль стабилизатора. Он сглаживает резкие переходы между режимами рынка. Когда структура ещё не успела измениться, а события уже сигнализируют о возможном сдвиге, энкодер удерживает баланс. Он не игнорирует сигнал, но и не позволяет ему мгновенно перевернуть картину. Это очень похоже на работу профессионального риск-менеджмента, только на уровне признаков.
Алгоритм Mix-Fusion мы выстраиваем как вполне конкретный вычислительный узел. В нашей реализации он оформляется в виде отдельного класса CNeuronSpikeMixFusion, который логически и архитектурно продолжает уже знакомую нам иерархию. Это не случайный выбор. Такой энкодер по своей природе ближе всего к сверточному блоку, но с расширенной ответственностью и более строгой дисциплиной обработки сигнала.
class CNeuronSpikeMixFusion : public CNeuronSpikeConvBlock { protected: CLayer cMain; CNeuronConvOCL cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeMixFusion(void); ~CNeuronSpikeMixFusion(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension_in, uint dimension_out, uint units_count, uint depth, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeMixFusion; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual uint GetWindow(void) const { return cResidual.GetWindow(); } //--- virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
Наследование от CNeuronSpikeConvBlock здесь задаёт правильный фундамент. Мы сразу остаёмся в парадигме локальной обработки, оконного анализа и контролируемого распространения признаков. Но при этом Mix-Fusion выходит за рамки обычной свёртки. Он не просто извлекает признаки, он управляет тем, как контексты разных модальностей взаимодействуют друг с другом внутри общего представления.
Внутренняя структура класса это хорошо подчёркивает. cMain выступает в роли основного вычислительного ядра, где формируется согласованное контекстное представление. Именно здесь происходит то самое управляемое смешивание. Не грубое объединение каналов, а аккуратная настройка влияния. cResidual, в свою очередь, реализует остаточную ветку. Это классическое, проверенное временем решение. Остаточные связи гарантируют, что исходная информация не будет потеряна. Даже если механизм смешивания временно снижает вклад одной из модальностей. Старый добрый принцип не навреди в чистом виде.
Метод инициализации объекта хорошо показывает, что Mix-Fusion изначально задуман как самостоятельный, универсальный модуль, который можно безболезненно встраивать в разные участки архитектуры. Здесь нет жёсткой привязки к конкретной размерности или типу входа. Напротив, всё построено так, чтобы энкодер одинаково уверенно работал и на ранних уровнях, и глубже, где представления уже компактны и насыщены смыслом.
bool CNeuronSpikeMixFusion::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension_in, uint dimension_out, uint units_count, uint depth, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, dimension_out, dimension_out, dimension_out, units_count, 1, optimization_type, batch)) ReturnFalse;
Первое, на что стоит обратить внимание, — инициализация унаследованного функционала родительского класса. Мы сознательно используем размерность признаков на выходе сразу во всех ключевых параметрах. Это подчёркивает роль Mix-Fusion как блока, который работает уже с приведёнными к общему масштабу представлениями. Здесь нет задачи менять форму данных, задача другая — перераспределить влияние и выстроить взаимодействие. Такой подход снижает риск скрытых перекосов и делает поведение блока более предсказуемым.
Далее инициализируем остаточную ветку cResidual. Она получает на вход исходную размерность dimension_in и проецирует её в пространство dimension_out.
//--- Residual uint index = 0; if(!cResidual.Init(0, index, OpenCL, dimension_in, dimension_in, dimension_out, units_count, 1, optimization, iBatch)) ReturnFalse; cResidual.SetActivationFunction(None);
Это важный момент. Остаточная связь здесь не просто копирует сигнал. Она аккуратно выравнивает его по размерности, подготавливая к корректному сложению с основным потоком. Активация намеренно отключена. Остаточный путь должен быть прозрачным. Он не интерпретирует. Он страхует.
Затем начинается формирование основного вычислительного ядра cMain. Оно собирается явно и последовательно, что сразу повышает читаемость и управляемость архитектуры. Сначала обычный сверточный блок. Он отвечает за первичное согласование контекстов и перевод входных признаков в общее представление.
//--- Main cMain.Clear(); cMain.SetOpenCL(OpenCL); CNeuronSpikeConvBlock* conv = NULL; CNeuronSpikeDepthWiseConv* dw_conv = NULL; index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, dimension_in, dimension_in, dimension_out, units_count, 1, optimization, iBatch) || !cMain.Add(conv)) DeleteObjAndFalse(conv);
Здесь происходит базовое смешивание. Ещё без тонкой настройки, но уже с учётом пространственной структуры.
Следом добавляется Depth-Wise свёртка. И это решение далеко не случайно. Depth-Wise слой позволяет работать с каждым каналом отдельно, не разрушая их внутреннюю специфику. В контексте Mix-Fusion это критично. Мы уже говорили, что модальности не должны растворяться друг в друге. Они должны взаимодействовать, сохраняя идентичность. Depth-Wise свёртка идеально подходит для этой роли. Она усиливает локальные зависимости внутри каналов и позволяет модели уточнять контекст без агрессивного перемешивания.
index++; dw_conv = new CNeuronSpikeDepthWiseConv(); if(!dw_conv || !dw_conv.Init(0, index, OpenCL, dimension_out, dimension_out, depth, 1, units_count, 1, optimization, iBatch) || !cMain.Add(dw_conv)) DeleteObjAndFalse(dw_conv); //--- return true; }
Параметр depth здесь задаёт глубину контекстного анализа. Это тот самый регулятор, который позволяет управлять компромиссом между чувствительностью и устойчивостью. На малой глубине блок реагирует быстрее. На большей — аккуратнее и стабильнее. И что особенно приятно, всё это достигается без изменения общей логики блока.
Алгоритм прямого прохода в Mix-Fusion выглядит на удивление спокойно. Здесь нет сложных ветвлений, нет скрытой магии и нет попытки перехитрить рынок вычислительными трюками. И это хороший знак. Такие участки кода, как правило, и оказываются самыми надёжными в реальной эксплуатации.
bool CNeuronSpikeMixFusion::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; //--- if(!cResidual.FeedForward(prev)) ReturnFalse;
Прямой проход начинается с остаточной ветки. Мы сразу пропускаем входной сигнал через cResidual, не дожидаясь обработки в основном контуре. Тем самым мы фиксируем исходное состояние контекста до любого смешивания.
В терминах рынка это похоже на сохранение эталонного снимка текущей структуры, к которому мы сможем вернуться позже. Если на каком-то этапе основной поток начнёт искажать сигнал, residual-ветка не даст модели потерять опору.
Далее начинается последовательная обработка в cMain. Здесь всё выстроено максимально прозрачно. Мы берём выход предыдущего слоя и передаём его следующему. Никаких параллельных прыжков. Никаких скрытых усреднений.
for(int i = 0; i < cMain.Total(); i++) { curr = cMain[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Такой порядок важен именно для Mix-Fusion, потому что каждый слой уточняет контекст, полученный на предыдущем шаге. Сначала грубое согласование модальностей. Затем более тонкая настройка на уровне каналов. Это похоже на последовательное уточнение рыночной картины — от общего взгляда к деталям.
После завершения основного контура управление передается родительскому классу. Здесь происходит финальная обработка перед формированием выхода блока. Этот шаг играет роль стабилизатора. Он приводит выход основного пути к ожидаемому формату и обеспечивает совместимость с остальной архитектурой STFlow.
if(!CNeuronSpikeConvBlock::feedForward(prev))
ReturnFalse;
Важно, что этот этап выполняется уже после полного прохождения через cMain. Таким образом, весь смысловой вес смешивания сохраняется.
Кульминация прямого прохода — это операция суммирования результатов работы основного потока и остаточных связей. Именно здесь сходятся два мира. Без резких скачков. Без подавления одного за счёт другого.
if(!SumAndNormilize(Output, cResidual.getOutput(), Output, GetFilters(), true, 0, 0, 0, 1)) ReturnFalse; //--- return true; }
Нормализация здесь критична. Она гарантирует, что ни структурный контекст, ни событийная динамика не получат неконтролируемого преимущества. Для модели это означает устойчивое поведение. Для трейдера — отсутствие внезапных нервных срывов вблизи шумовых участков рынка.
Обратите внимание, что суммирование происходит уже на уровне готовых представлений. Это осознанный выбор. Мы не смешиваем сырые признаки, а объединяем интерпретированные контексты. Такой подход резко снижает чувствительность к локальным выбросам и делает отклик блока более инерционным, но не медленным. Это тот самый баланс, который так трудно поймать в классических архитектурах.
Однако одного лишь аккуратного прямого прохода недостаточно. Без обучения вся эта конструкция останется красивой, но бесполезной. Рынок не прощает зафиксированных правил, он требует адаптации. Поэтому после формирования выхода Mix-Fusion, мы неизбежно переходим к работе над ошибками — к обратному распространению градиентов, где и формируется настоящая память модели.
Метод calcInputGradients сразу задаёт правильный тон. Он не пытается пересчитать всё заново и не ломает логику прямого прохода. Напротив, он аккуратно разворачивает вычислительный граф в обратную сторону, сохраняя ту же дисциплину, что и на прямом ходе. Это важно. Несогласованность между этими двумя фазами почти всегда приводит к нестабильному обучению.
bool CNeuronSpikeMixFusion::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse;
Обратный проход начинается с последнего элемента основного контура cMain. Мы берём самый глубокий уровень контекстного смешивания и именно от него начинаем распространять ошибку назад. Сначала используется базовая логика родительского класса. Это позволяет корректно распределить градиенты на выходе блока и обеспечить совместимость с остальной архитектурой STFlow. Здесь нет места экспериментам. Основа должна быть надёжной.
CNeuronBaseOCL* next = cMain[-1]; CNeuronBaseOCL* curr = NULL; //--- if(!CNeuronSpikeConvBlock::calcInputGradients(next)) ReturnFalse;
Далее мы видим работу с остаточной веткой. Вызов метода DeActivation играет здесь ключевую роль. Остаточный путь хоть и прозрачен на прямом проходе, но при обучении он обязан подчиняться тем же правилам нелинейности, что и основной поток. Мы аккуратно вычисляем градиенты с учётом функции активации residual-ветки, не позволяя ей превратиться в неконтролируемый канал утечки ошибки.
if(!DeActivation(cResidual.getOutput(), cResidual.getGradient(), Gradient, cResidual.Activation()))
ReturnFalse;
Это тонкий момент, который часто упускают в упрощённых реализациях.
Затем начинается поэтапное распространение ошибки через cMain в обратном порядке. Мы движемся от более глубоких уровней к более поверхностным. Каждый слой уточняет свою долю ответственности за итоговую ошибку.
for(int i = cMain.Total() - 2; i >= 0; i--) { curr = cMain[i]; if(!curr || !curr.CalcHiddenGradients(next)) ReturnFalse; next = curr; }
Такой порядок не случаен. Именно на глубинных уровнях формируются самые абстрактные представления контекста, и именно они должны первыми скорректироваться. Поверхностные слои лишь подстраиваются под эти изменения.
После этого градиенты доходят до объекта исходных данных NeuronOCL. Здесь происходит, пожалуй, самый интересный момент всего алгоритма. Мы пересчитываем вклад основного пути, затем временно сохраняем полученный градиент и оцениваем вклад остаточной ветки. Только после этого аккуратно суммируем их.
if(!NeuronOCL.CalcHiddenGradients(next)) ReturnFalse; CBufferFloat* temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(NeuronOCL.getPrevOutput(), false) || !NeuronOCL.CalcHiddenGradients(cResidual.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), temp, temp, GetWindow(), false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) ReturnFalse; //--- return true; }
Это зеркальное отражение логики прямого прохода. Там мы объединяли контексты. Здесь мы объединяем ответственность. В результате обучение идёт ровно, без рывков, без внезапных перекосов.
Важно отметить, что такой подход делает Mix-Fusion особенно устойчивым к сложным рыночным режимам. В моменты резких изменений событийный поток может генерировать сильные ошибки, но структурный контекст не позволяет этим ошибкам разрушить всю модель. С другой стороны, при длительных спокойных участках residual-ветка не даёт обучению застыть.
В итоге calcInputGradients превращает Mix-Fusion из пассивного фильтра в обучаемый механизм согласования. Он не просто реагирует на рынок, он учится понимать, какие сочетания структуры и динамики приводят к ошибкам, а какие — к устойчивым состояниям. Именно здесь фреймворк STFlow окончательно перестаёт быть статической архитектурой и начинает вести себя как живая система, способная адаптироваться к реальному рынку.
Такой энкодер не навязывает модели жёсткое поведение, он задаёт рамки, внутри которых модель может адаптироваться к рынку. Именно поэтому Mix-Fusion хорошо масштабируется и не теряет устойчивости при усложнении архитектуры.
Если посмотреть на этот класс с более высокого уровня, становится понятно, что он играет роль своеобразного диспетчера контекста. Он не решает, куда пойдёт рынок. Он следит за тем, чтобы модель одинаково хорошо слышала и форму, и движение. Чтобы ни одна из модальностей не перетянула управление на себя. Чтобы динамика не разрушила структуру, а структура не задушила динамику.
Объект верхнего уровня
Нужно понимать, что Mix-Fusion — это лишь один из энкодеров в общей архитектуре STFlow, пусть и один из самых выразительных. Фреймворк изначально устроен богаче: для каждой модальности здесь предусмотрены собственные энкодеры динамики и контекста. Это осознанное решение. Рынок не однороден, и разные аспекты сигнала требуют разного взгляда. Где-то важна скорость изменений, где-то — устойчивое состояние среды, в которой эти изменения происходят.
Мы сознательно не останавливались на этих энкодерах подробно, потому что с архитектурной точки зрения они хорошо знакомы. Их логика во многом повторяет решения, применяемые в современных фреймворках анализа оптического потока, с которыми мы уже сталкивались ранее.
На этапе проектирования у нас было несколько очевидных вариантов. Можно было создать отдельные объекты для каждого энкодера. Можно было попытаться переиспользовать уже существующие модули, просто вызывая их последовательно. Формально это решало задачу. Но как это часто бывает, формальная корректность быстро упирается в практические ограничения.
В нашем случае этих энкодеров получается четыре. Две модальности: в каждой — отдельный энкодер динамики и отдельный энкодер контекста. Если использовать их последовательно, время обработки одного состояния начинает расти линейно. Для оффлайн-анализа это ещё допустимо, а для онлайн-модели, работающей в реальном времени, — уже нет. Здесь каждая лишняя миллисекунда имеет значение. Рынок не ждёт, пока модель аккуратно всё посчитает.
Другой вариант — создать единый объект с несколькими головами на выходе. На бумаге выглядит красиво, на практике — плохо ложится в уже выстроенную структуру. Мы изначально проектировали архитектуру как последовательность согласованных блоков, где каждый модуль возвращает одно целостное представление. Встраивать туда объект с четырьмя разными выходами означало бы ломать интерфейсы, усложнять логику связей и терять прозрачность вычислительного графа. А это почти всегда аукнется при отладке и масштабировании.
Поэтому мы пошли третьим путём. Самым, пожалуй, консервативным, но и самым надёжным. Мы вынесли координацию этих энкодеров на уровень выше. Не стали городить новые сущности и не стали дробить модель на мелкие, слабо связанные компоненты. Вместо этого, управление динамикой и контекстом разных модальностей было решено в рамках объекта верхнего уровня, который уже отвечает за согласование потоков.
Такой подход позволил сохранить целостность архитектуры и избежать лишних вычислительных накладных расходов. Энкодеры остаются логически независимыми, но физически работают согласованно. Общие операции выполняются один раз. Повторяющиеся шаги не дублируются. В результате модель остаётся быстрой, предсказуемой и пригодной для практического применения в онлайн-режиме.
И это, пожалуй, важный момент, который стоит подчеркнуть отдельно. STFlow — это не демонстрация архитектурных изысков, это инженерное решение. Здесь каждый модуль существует не ради красоты, а ради устойчивой работы в условиях реального рынка. Иногда это означает отказ от избыточной абстракции в пользу более жёсткой, но честной структуры.
Практическая реализация этого решения хорошо видна в объекте верхнего уровня CNeuronSTFlow. Именно здесь архитектура перестаёт быть набором отдельных идей и превращается в цельный вычислительный организм. Этот класс задаёт порядок мышления всей модели и определяет, как разные представления рынка встречаются, взаимодействуют и в итоге формируют поток признаков.
class CNeuronSTFlow : public CNeuronSpikeConvBlock { protected: uint iMaxDisplacement; int ibShifts; //--- CNeuronBatchNormOCL cNorm; CNeuronCreateICEFlow cICE; CNeuronSpikePatchStak cEvents; CLayer cEncoder; CNeuronBaseOCL cICEEmbedding; CNeuronBaseOCL cEventsEmbedding; CNeuronBaseOCL cContext; CNeuronBaseOCL cICECorrelation; CNeuronBaseOCL cEventsCorrelation; CNeuronBaseOCL cFeatureVsCorrelation; CNeuronSpikeMFE cMoutionEncoder; CNeuronTransposeRCDOCL cTranspose; CNeuronSpikeMHCrossAttention cCrossModalAggregation; CNeuronSpikeMixFusion cMixFusion; CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSTFlow(void) {}; ~CNeuronSTFlow(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension_in, uint units_in, uint bottleneck, uint dimension_out, uint units_out, uint max_displacement, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSTFlow; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual CBufferFloat *getWeights(void) override; };
Если посмотреть на состав внутренних объектов класса, сразу видно, что здесь собраны все ключевые элементы фреймворка. Нормализация, формирование ICE-представления, обработка событий, кодирование, корреляционный анализ, энкодер движения, кросс-модальная агрегация и, наконец, Mix-Fusion. Это не случайный набор, а строго выстроенная цепочка, где каждый элемент отвечает за свой участок работы и не лезет в чужую зону ответственности.
Обратите внимание, что энкодеры динамики и контекста не вынесены в отдельные самостоятельные объекты с собственным жизненным циклом. Они представлены здесь как логические роли, реализуемые через комбинацию базовых нейронных блоков. Такой подход позволяет избежать лишних проходов по данным. Общие операции, такие как нормализация, преобразование размерностей и оконный доступ, выполняются один раз и используются сразу несколькими подсистемами.
Такой дизайн особенно хорошо проявляет себя при работе онлайн. Мы не гоняем данные по четырём независимым энкодерам и не дублируем вычисления. Все ветки используют общую основу и расходятся только там, где это действительно необходимо. В результате, задержка обработки одного состояния остаётся в разумных пределах, даже при усложнении архитектуры.
Модули cMoutionEncoder, cCrossModalAggregation и cMixFusion образуют верхний уровень принятия решений. Здесь динамика уже осмыслена, контекст уже сформирован, и модель может позволить себе более тонкие операции. Сначала — оценка движения, затем — согласование модальностей, и только потом — управляемое смешивание контекста, о котором мы подробно говорили выше. Такой порядок не перегружает модель и позволяет сохранять стабильность даже при резких изменениях рыночного режима.
Метод инициализации объекта верхнего уровня демонстрирует, насколько тщательно спроектирована архитектура STFlow. Здесь каждая деталь рассчитана на последовательное формирование согласованного представления рыночного состояния при сохранении высокой эффективности вычислений.
bool CNeuronSTFlow::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension_in, uint units_in, uint bottleneck, uint dimension_out, uint units_out, uint max_displacement, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, bottleneck, bottleneck, dimension_out, units_out, 1, optimization_type, batch)) ReturnFalse;
Инициализация начинается с передачи управления родительскому классу и создания вектора сдвигов ibShifts, которые задают смещение и окно анализа для работы с динамикой модальностей.
//--- Shifts int count = 0; ibShifts = CreateShifts(max_displacement, count); if(ibShifts == INVALID_HANDLE) ReturnFalse; iMaxDisplacement = max_displacement;
Этот шаг критичен. Именно здесь формируется сетка, по которой будет анализироваться движение сигналов. iMaxDisplacement фиксирует границы, чтобы последующие вычисления оставались предсказуемыми.
Далее создаются основные блоки потока: нормализация исходных данных через cNorm, формирование стеков ICE-представлений и событийных патчей.
//--- Create Flow uint index = 0; if(!cNorm.Init(0, index, OpenCL, dimension_in, iBatch, optimization)) ReturnFalse; SetActivationFunction(None); index++; if(!cICE.Init(0, index, OpenCL, units_in, dimension_in, bottleneck, 1, optimization, iBatch)) ReturnFalse; index++; if(!cEvents.Init(0, index, OpenCL, units_in, dimension_in, bottleneck, 1, optimization, iBatch)) ReturnFalse; index++;
Эти компоненты подготавливают сырые исходные данные, приводя их к сопоставимому виду, что снижает шум и упрощает последующее кодирование. Важно, что каждому блоку явно назначен индекс и связка с OpenCL-контекстом, что обеспечивает корректную и ускоренную параллельную обработку.
После этого формируется блок Энкодеров, где происходит первичное кодирование признаков. Этот этап обеспечивает адаптацию пространственно-временных представлений под дальнейшее согласование модальностей.
Вначале мы создаем базовый нейронный слой который служит для формирования конкатенированного представления стеков двух анализируемых модальностей.
cEncoder.Clear(); cEncoder.SetOpenCL(OpenCL); cFlow.Clear(); cFlow.SetOpenCL(OpenCL); //--- CNeuronBaseOCL* neuron = NULL; CNeuronBatchNormOCL* norm = NULL; CNeuronMultiWindowsConvWPadOCL* mw_conv = NULL; CNeuronSpikeConvBlock* conv = NULL; CNeuronTransposeOCL* transp = NULL; CNeuronSpikeConvGRU2D* gru = NULL; //--- Feature Encoder neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, 2 * bottleneck * units_in, optimization, iBatch) || !cEncoder.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++;
Далее используется сверточный блок для первичного извлечения признаков. Важно отметить, на данном этапе мы не смешиваем данные ни между модальностями, ни по временной шкале.
conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, bottleneck, bottleneck, bottleneck, 2 * units_in, 1, optimization, iBatch) || !cEncoder.Add(conv)) DeleteObjAndFalse(conv); index++;
Затем мы транспонируем тензор для возможности независимого анализа временной динамики отдельных признаков и модальностей.
transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units_in, 2 * bottleneck, optimization, iBatch) || !cEncoder.Add(transp)) DeleteObjAndFalse(transp); index++;
За анализ динамических изменений отвечают 2 последовательных сверточных блока, которые работают с добавлением нулевого паддинга.
uint windows_depth[] = { iMaxDisplacement }; for(int i = 0; i < 2; i++) { mw_conv = new CNeuronMultiWindowsConvWPadOCL(); if(!mw_conv || !mw_conv.Init(0, index, OpenCL, windows_depth, 1, 1, units_in, 2 * bottleneck, optimization, iBatch) || !cEncoder.Add(mw_conv)) DeleteObjAndFalse(mw_conv); mw_conv.SetActivationFunction(SoftPlus); index++; }
Обогащенные информацией о временной динамике данные возвращаются в исходное представление.
transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units_in, 2 * bottleneck, optimization, iBatch) || !cEncoder.Add(transp)) DeleteObjAndFalse(transp); index++;
Следующий сверточный блок объединяет данные динамики отдельных признаков в согласованное представление независимых модальностей.
conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, bottleneck, bottleneck, bottleneck, 2 * units_in, 1, optimization, iBatch) || !cEncoder.Add(conv)) DeleteObjAndFalse(conv); index++;
На данном этапе мы практически получили параллельную работу двух независимых энкодеров отдельных модальностей в рамках единого потока операций. Однако здесь следует вспомнить, что нам необходимо по 2 энкодера для каждой модальности. Поэтому следующий сверточныый блок расширяет пространство признаков каждой модальности, формируя эмбеддинги динамики и контекста.
conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, bottleneck, bottleneck, 2 * bottleneck, 2 * units_in, 1, optimization, iBatch) || !cEncoder.Add(conv)) DeleteObjAndFalse(conv); index++;
Следующие блоки — cICEEmbedding, cEventsEmbedding, cContext — предназначены для разделения сформированных эмбедингов на параллельные потоки обработки данных.
if(!cICEEmbedding.Init(0, index, OpenCL, bottleneck * units_in, optimization, iBatch)) ReturnFalse; cICEEmbedding.SetActivationFunction(None); index++; if(!cEventsEmbedding.Init(0, index, OpenCL, bottleneck * units_in, optimization, iBatch)) ReturnFalse; cEventsEmbedding.SetActivationFunction(None); index++; if(!cContext.Init(0, index, OpenCL, 2 * bottleneck * units_in, optimization, iBatch)) ReturnFalse; cContext.SetActivationFunction(None); index++;
Информация о корреляции состояний сохраняется в объектах cICECorrelation, cEventsCorrelation.
if(!cICECorrelation.Init(0, index, OpenCL, count * units_in, optimization, iBatch)) ReturnFalse; cICECorrelation.SetActivationFunction(None); index++; if(!cEventsCorrelation.Init(0, index, OpenCL, count * units_in, optimization, iBatch)) ReturnFalse; cEventsCorrelation.SetActivationFunction(None); index++; if(!cFeatureVsCorrelation.Init(0, index, OpenCL, 2 * (bottleneck + count)*units_in, optimization, iBatch)) ReturnFalse; cFeatureVsCorrelation.SetActivationFunction(None); index++;
А cFeatureVsCorrelation объединяет представления динамики и корреляции двух модальностей в единый конкатенированный тензор.
На этапе кодирования движения и межмодальной агрегации включаются cMoutionEncoder, cTranspose и cCrossModalAggregation.
uint windows[] = { bottleneck, count, bottleneck, count }; if(!cMoutionEncoder.Init(0, index, OpenCL, units_in, windows, bottleneck, optimization, iBatch)) ReturnFalse; index++; if(!cTranspose.Init(0, index, OpenCL, units_in, 2, bottleneck, optimization, iBatch)) return false; index++; if(!cCrossModalAggregation.Init(0, index, OpenCL, bottleneck, (bottleneck + 3) / 4, 4, 2 * units_in, bottleneck, units_in, optimization, iBatch)) ReturnFalse; index++;
Эти блоки отвечают за согласование динамики, выравнивание размерностей. Порядок включения элементов строго выстроен: сначала локальные признаки, затем глобальная агрегация.
Управляемое смешивание контекста модальностей осуществляется в cMixFusion.
if(!cMixFusion.Init(0, index, OpenCL, 2 * bottleneck, bottleneck, units_in, iMaxDisplacement, optimization, iBatch)) ReturnFalse; index++;
Это отражает принцип STFlow: сначала формируем устойчивые представления, потом аккуратно смешиваем их.
Наконец, блок cFlow объединяет все предыдущие представления и формирует окончательный выход. Здесь используется комбинация базовых нейронов, сверточных блоков, GRU и транспозиций.
//--- Flow neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, 3 * bottleneck * units_in, optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, 3 * bottleneck, 3 * bottleneck, bottleneck, units_in, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv); index++; gru = new CNeuronSpikeConvGRU2D(); if(!gru || !gru.Init(0, index, OpenCL, units_in, bottleneck, bottleneck, optimization, iBatch) || !cFlow.Add(gru)) DeleteObjAndFalse(gru); index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units_in, bottleneck, optimization, iBatch) || !cFlow.Add(transp)) DeleteObjAndFalse(transp); index++; conv = CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, units_in, units_in, units_out, bottleneck, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv); index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, bottleneck, units_out, optimization, iBatch) || !cFlow.Add(transp)) DeleteObjAndFalse(transp); //--- return true; }
GRU обеспечивает сохранение временной последовательности и устойчивость модели к шуму, а транспозиции корректируют размерности для совместимости с остальными слоями. В итоге cFlow выдаёт уже полностью согласованное представление состояния рынка, готовое к использованию для последующих задач прогнозирования и анализа.
Архитектура CNeuronSTFlow получилась насыщенной и многослойной, с аккуратно выстроенными этапами подготовки, кодирования и смешивания контекстов. Каждая ветвь, каждый энкодер и каждая трансформация играют свою роль, и поток данных через эту конструкцию требует вдумчивого подхода, чтобы ничего не потерялось и все градиенты корректно распространились.
Сейчас самое время сделать паузу, дать мыслям улежатся. К разбору прямого и обратного проходов, равно как и к тонкостям согласования модальностей, предлагаю вернуться с новыми силами. Это позволит продолжить работу уже с ясной картиной архитектуры и с минимальным риском упустить важные детали.
Заключение
В этой статье мы подробно рассмотрели архитектуру верхнего уровня и работу компонента — Mix-Fusion, который обеспечивает управляемое смешивание контекста разных модальностей.
Особое внимание уделено инженерной стороне решения: структура объекта верхнего уровня позволяет избежать избыточных вычислений, эффективно использовать четыре энкодера без потери скорости и сохранить прозрачность вычислительного графа. Это делает STFlow пригодным для практического применения в онлайн-режиме, где время обработки одного состояния критично.
Представленные подходы подтверждают, что сочетание аккуратно выстроенной архитектуры, остаточных связей и управляемого смешивания контекста обеспечивает модели высокую адаптивность и стабильность. Фреймворк STFlow не только повторяет проверенные концепции анализа оптического потока, но и расширяет их, создавая инструмент, способный работать с высокочастотными финансовыми данными в реальном времени.
Ссылки
- Spatially-guided Temporal Aggregation for Robust Event-RGB Optical Flow Estimation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования