
Нейросети в трейдинге: Пространственно-управляемая агрегация рыночных событий (Основные модули)

Введение
Рынок сегодня — это не аккуратный временной ряд с равномерными шагами, а плотный поток асинхронных событий: активность то вспыхивает, то замирает, цена может долго стоять на месте, а затем пройти значимое расстояние за считанные миллисекунды. В таких условиях привычные инструменты (скользящие средние, фиксированные окна, стандартные индикаторы) либо запаздывают, либо реагируют на шум, принимая его за сигнал. Трейдеру приходится постоянно выбирать между чувствительностью и устойчивостью, и этот компромисс почти всегда оказывается не в его пользу.
Именно эта проблема и лежит в основе всей логики STFlow. Рынок нельзя адекватно описывать только через время. Время — лишь одна из осей, и далеко не всегда главная. Намного важнее структура цены, то есть где именно происходят события. Один и тот же тик имеет разный смысл в зависимости от того, возник ли он внутри узкого диапазона, на границе консолидации или в момент пробоя. Классические модели этого не видят. Они усредняют события во временных окнах и тем самым стирают контекст. STFlow, напротив, делает ставку на контекст как на первичную сущность.
В предыдущей статье мы подробно разобрали идеи STFlow, пришедшего из области компьютерного зрения, где давно научились работать с потоками событий, плотными и разреженными данными, и извлекать движение через согласование структуры и динамики. Для рынка это особенно актуально. Цена формирует своеобразное пространство, а тики, объемы и всплески активности — это события, которые наполняют это пространство движением. Если попытаться анализировать их по отдельности, результат будет либо слишком шумным, либо слишком инертным. Сила STFlow именно в том, что он изначально строится как система совместного анализа структуры и динамики.
Ключевая проблема, с которой сталкивается практикующий трейдер, — нестабильность сигналов. То, что работало вчера, сегодня дает серию ложных входов. Причина проста: рынок меняет режим. Меняется плотность тиков, характер движения, глубина коррекций. Большинство индикаторов не адаптируются к этим изменениям, потому что у них нет механизма понимания текущего состояния рынка. STFlow решает эту задачу на более фундаментальном уровне. Он не пытается угадывать будущее на основе прошлого среднего значения. Он формирует текущее состояние рынка как согласованное представление пространственной структуры цены и временной активности событий.
Важно подчеркнуть, что STFlow — это не очередной умный индикатор и не набор эвристик. Это фреймворк, то есть способ мышления и построения моделей. Его основное преимущество — отказ от слепой временной агрегации в пользу контекста происходящих событий. Это принципиально меняет картину. Сигналы перестают быть абстрактными числами и начинают отражать реальное положение цены в ее текущей структуре.
Еще одно важное преимущество STFlow — устойчивость к шуму без потери чувствительности. В традиционных системах эту задачу решают фильтрами, сглаживанием или увеличением таймфрейма. Все эти методы работают, но ценой задержки. STFlow идет другим путем. Пространственный контекст цены выступает в роли естественного фильтра. События, которые не вписываются в текущую структуру, автоматически получают меньший вес. При этом значимые импульсы, возникающие в ключевых зонах, наоборот, усиливаются. В результате система реагирует быстро, но не дергается на каждом случайном тике. Для трейдера это означает более чистые сигналы и меньше психологического давления.
Отдельного внимания заслуживает вопрос интерпретируемости. Многие современные методы, особенно основанные на нейросетях, грешат тем, что превращаются в черный ящик. STFlow, несмотря на свою сложность, сохраняет понятную логику. Мы всегда можем проследить, как пространственная структура цены направляет агрегацию событий, и почему в конкретный момент система делает тот или иной вывод. Это особенно важно в реальной торговле. Где доверие к инструменту играет не меньшую роль, чем его формальная эффективность. Трейдер должен понимать, что именно он видит на экране и почему.
Важно сразу обозначить ожидания. STFlow не обещает чудес и не превращает торговлю в кнопку деньги. Это инструмент для тех, кто понимает природу рынка и готов работать с его структурой. Он дает более адекватное представление текущего состояния рынка. Он позволяет видеть не просто движение цены, а согласованное движение структуры и активности.
Авторская визуализация фреймворка STFlow представлена ниже.
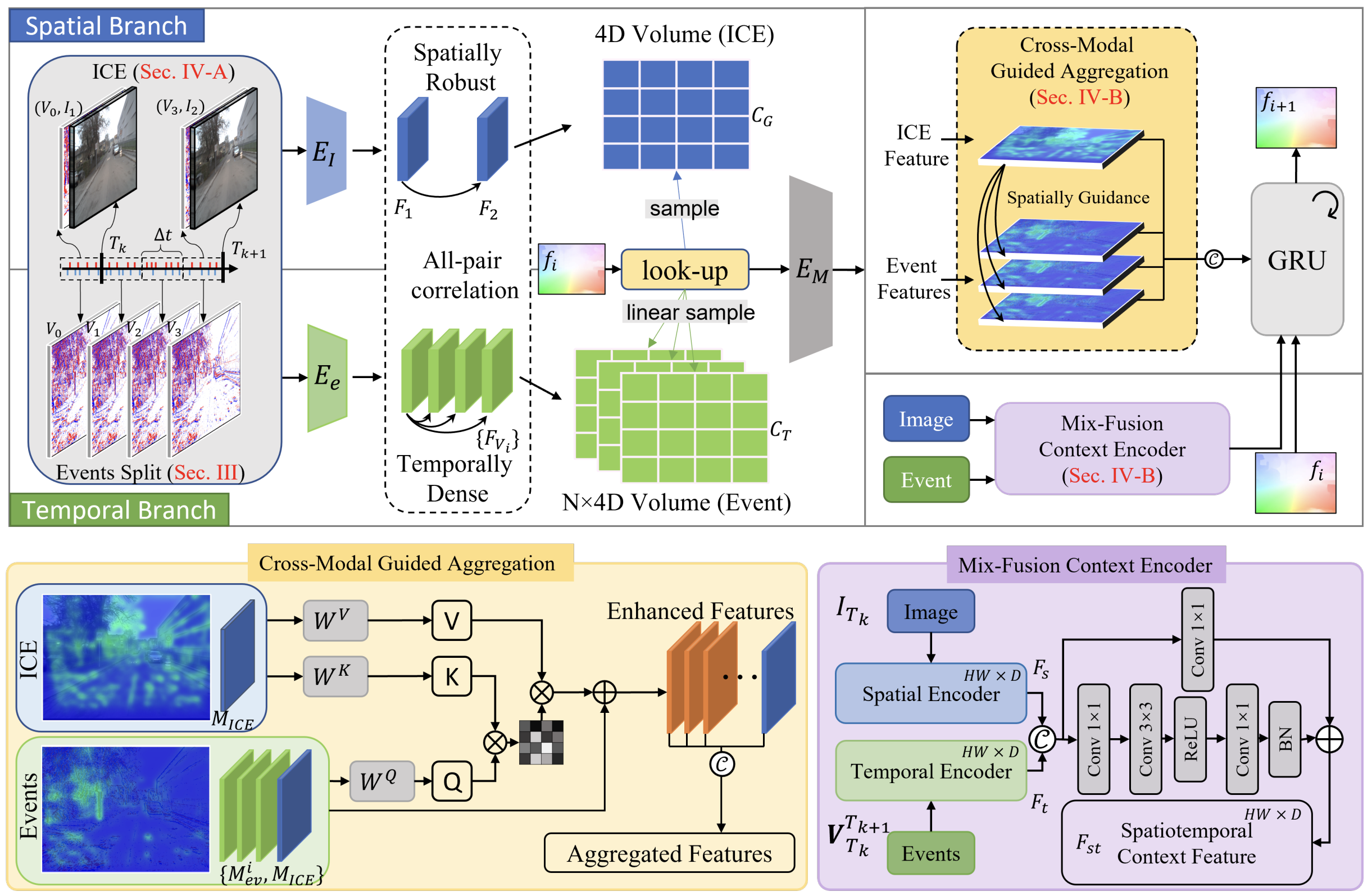
Мы начали реализацию STFlow сразу после ознакомления с его теоретическими аспектами. И это было принципиально важно. Только работающий код позволяет по-настоящему понять глубину идей пространственно-управляемой агрегации.
Наша цель изначально заключалась не в механическом переносе архитектур из компьютерного зрения в трейдинг. Такой путь, как правило, не работает. Мы адаптировали сами принципы (пространственную устойчивость, управляемую агрегацию и кросс-модальное взаимодействие) под природу финансовых данных. В этом виде они и начали воплощаться в коде.
Первым элементом стал модуль ICE (Image-Event Connection). Это не просто технический блок, а интеллектуальный фильтр. Он объединяет нормализованное ценовое представление с асинхронным потоком рыночных событий и наделяет каждый ценовой элемент собственным событийным контекстом. Только после этого данные передаются на последующие этапы агрегации, уже в осмысленном и структурированном виде.
Модуль кодирования движения
Продолжая практическую реализацию подходов, предложенных авторами фреймворка STFlow, мы переходим к построению модуля Motion Encoder. Этот этап выглядит логичным и своевременным. Базовое пространственно-событийное представление уже сформировано, теперь настало время научить систему извлекать из него осмысленное движение.
Motion Encoder превращает согласованный поток цены и событий в компактное, информативное описание текущей динамики рынка. Здесь рынок перестаёт быть набором разрозненных изменений и начинает восприниматься как направленный процесс. Именно на этом уровне фиксируются микроимпульсы, накапливаемое давление и смена режимов движения, которые на графике часто ощущаются интуитивно. Но плохо формализуются классическими средствами.
Как и во многих фреймворках анализа оптического потока, авторы STFlow строят кодирование движения через объединение признаков и корреляций. Однако здесь есть принципиальное отличие. Нам предстоит работать сразу с двумя модальностями, и для каждой из них формируются собственные корреляционные структуры. Это усложняет задачу, но одновременно открывает более глубокий уровень согласования данных.
Ключевой акцент авторы фреймворка делают на кодировании движения обеих модальностей одним и тем же Motion Encoder. Это не техническая деталь, а важное архитектурное решение. Общий модуль вынуждает систему учиться извлекать движение в едином пространстве признаков, не разрывая логику между модальностями. В результате мы получаем не два разрозненных описания, а согласованное представление движения. Пространственная структура и событийная динамика интерпретируются в одном контексте.
При этом нам важно организовать работу с обеими модальностями не последовательно, а одновременно. Именно поэтому следующим шагом становится создание отдельного объекта, внутри которого будет сосредоточена вся логика совместной обработки. В этом объекте мы работаем уже не с разрозненными массивами, а с единым многомерным тензором, объединяющим представления признаков и корреляций обеих модальностей.
Ключевой момент заключается в том, что все вычисления переносятся на сторону OpenCL-контекста. Это прагматичный шаг, позволяющий обрабатывать большие объёмы данных согласованно и без лишних копирований. Совместный тензор обеспечивает синхронность вычислений, сохраняет согласование модальностей и создаёт надёжную основу для работы Motion Encoder.
Речь идёт о классе CNeuronSpikeMFE, который логически продолжает ранее заложенную архитектуру и аккуратно встраивается в существующую иерархию вычислительных блоков.
class CNeuronSpikeMFE : public CNeuronSpikeConvBlock { protected: CLayer cEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeMFE(void) {}; ~CNeuronSpikeMFE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &windows[], uint window_out, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeMFE; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; };
Класс наследуется от CNeuronSpikeConvBlock, и это наследование здесь не формальное. Мы сразу задаём правильный контекст. Motion Feature Encoder остаётся свёрточным по своей природе и работает в парадигме нейронного блока, уже адаптированного под событийные данные и OpenCL-вычисления. Это позволяет не изобретать новый фундамент, а развивать уже проверенную конструкцию, расширяя её возможности для работы с несколькими модальностями.
Внутри класса ключевым элементом является объект динамического массива cEncoder. Именно в нем мы сохраним указатели на внутренние объекты, отвечающие за непосредственное кодирование движения. На практике cEncoder выступает магистралью универсального обработчика многомерного тензора, в котором уже объединены признаки и корреляции обеих модальностей. Это важный момент. Motion Encoder не знает и не должен знать, откуда пришли данные. Для него существует только согласованное представление, с которым он и работает.
Метод инициализации объекта играет ключевую роль в конфигурации Motion Encoder. Он задаёт архитектуру блока, формирует внутренние слои и связывает их с OpenCL-контекстом, обеспечивая работу с многомерным тензором признаков и корреляций обеих модальностей.
bool CNeuronSpikeMFE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &windows[], uint window_out, ENUM_OPTIMIZATION optimization_type, uint batch) { uint wsize = windows.Size(); if(wsize < 2 || wsize % 2 != 0) return false; uint modals = wsize / 2;
Сначала метод проверяет корректность входных параметров. Массив windows должен содержать хотя бы 2 элемента и быть чётным. Это важно, поскольку каждая модальность должна быть представлена собственными признаками и коэффициентами корреляции. При этом архитектура не ограничивает число модальностей. Массив окон может быть любого чётного размера, и каждая пара окон формирует отдельную модальность. Такая гибкость делает модуль универсальным и готовым к расширению, позволяя подключать новые потоки данных без изменения логики Motion Encoder.
Далее вызывается одноименный метод родительского класса, где задаются базовые параметры свёрточного блока. Это позволяет встроить Motion Encoder в общую архитектуру STFlow и сразу подготовить его к обработке нескольких модальностей одновременно.
if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, 2 * window_out, 2 * window_out, window_out, modals * units, 1, optimization_type, batch)) return false;
Динамический массив cEncoder очищается и получает привязку к OpenCL. Он служит контейнером для последовательности слоёв кодирования движения.
uint index = 0; cEncoder.Clear(); cEncoder.SetOpenCL(OpenCL);
Первый блок — CNeuronMultiWindowsConvOCL — выполняет независимую локальную свёртку признаков и корреляций отдельных модальностей.
CNeuronMultiWindowsConvOCL* mw_conv = NULL; CNeuronBatchNormOCL* normal = NULL; CNeuronSpikeActivation* activat = NULL; //--- mw_conv = new CNeuronMultiWindowsConvOCL(); if(!mw_conv || !mw_conv.Init(0, index, OpenCL, windows, 2 * window_out, units, 1, optimization, iBatch) || !cEncoder.Add(mw_conv)) { DeleteObj(mw_conv) return false; } mw_conv.SetActivationFunction(None);
Функция активации на этом этапе отключена, чтобы сохранить линейное представление для последующей нормализации.
Следующий слой, CNeuronBatchNormOCL, стабилизирует распределение признаков, облегчая обучение.
index++; normal = new CNeuronBatchNormOCL(); if(!normal || !normal.Init(0, index, OpenCL, mw_conv.Neurons(), iBatch, optimization) || !cEncoder.Add(normal)) { DeleteObj(normal) return false; }
А CNeuronSpikeActivation добавляет нелинейность и позволяет системе выделять значимые микроимпульсы на фоне шумов.
index++; activat = new CNeuronSpikeActivation(); if(!activat || !activat.Init(0, index, OpenCL, normal.Neurons(), optimization, iBatch) || !cEncoder.Add(activat)) { DeleteObj(activat) return false; } index++;
После первой цепочки создаётся вторая с немного изменёнными параметрами окон, что обеспечивает дополнительное кодирование локальных признаков и корреляций.
uint temp[]; if(ArrayResize(temp, wsize) < int(wsize)) return false; ArrayFill(temp, 0, 0, 2 * window_out); mw_conv = new CNeuronMultiWindowsConvOCL(); if(!mw_conv || !mw_conv.Init(0, index, OpenCL, temp, window_out, units, 1, optimization, iBatch) || !cEncoder.Add(mw_conv)) { DeleteObj(mw_conv) return false; } mw_conv.SetActivationFunction(None); index++; normal = new CNeuronBatchNormOCL(); if(!normal || !normal.Init(0, index, OpenCL, mw_conv.Neurons(), iBatch, optimization) || !cEncoder.Add(normal)) { DeleteObj(normal) return false; } //--- return true; }
Таким образом Motion Encoder формирует согласованное и богатое представление движения для обеих модальностей.
Каждый слой проверяется на успешную инициализацию, а при ошибке объект удаляется. Это предотвращает некорректную работу на уровне OpenCL.
В итоге метод инициализации формирует полностью готовый к работе Motion Encoder, способный одновременно обрабатывать несколько модальностей, строить согласованное представление движения и обеспечивать устойчивое и информативное кодирование для последующей пространственно-временной агрегации.
Алгоритм прямого прохода реализован в методе feedForward и отражает ключевую архитектурную идею STFlow — аккуратное согласование признаков и корреляций без преждевременного смешивания модальностей.
bool CNeuronSpikeMFE::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; //--- for(int i = 0; i < cEncoder.Total(); i++) { curr = cEncoder[i]; if(!curr || !curr.FeedForward(prev)) return false; prev = curr; }
На первом этапе входное представление последовательно проходит через внутреннюю цепочку cEncoder. Каждый слой обрабатывает данные независимо, применяя одинаковую логику кодирования к признакам и корреляциям каждой модальности. Здесь не происходит их слияния. Модальности сохраняют свою самостоятельность, но приводятся к единому масштабу и статистике. Это обеспечивает согласованность формы представлений без потери их смысловой чистоты.
После завершения этой независимой обработки управление передаётся родительскому классу. Именно на этом шаге выполняется объединение признаков и корреляций в общее представление движения.
if(!CNeuronSpikeConvBlock::feedForward(prev)) return false; //--- return true; }
Важно отметить, объединение происходит не через прямое смешивание модальностей, а за счёт согласованной свёрточной обработки. Модальности остаются различимыми на уровне каналов, но начинают интерпретироваться в едином пространственно-временном контексте.
В результате прямой проход формирует целостное и устойчивое описание движения, в котором каждая модальность сохраняет свои особенности. Признаки и корреляции работают совместно. Такой подход позволяет Motion Encoder извлекать динамику рынка аккуратно и последовательно, не разрушая структуру данных и не внося лишнего шума. Это критически важно при работе с асинхронными и высокочастотными потоками.
Кросс-модальная агрегация
Следующим логичным шагом становится построение модуля кросс-модальной агрегации. Именно здесь разрозненные, уже согласованные представления начинают работать как ансамбль, а не как набор отдельных голосов. Если Motion Encoder аккуратно выровнял признаки и корреляции внутри каждой модальности, то новый модуль берёт на себя более тонкую задачу — выявить и зафиксировать их взаимосвязи.
С практической точки зрения это переход от параллельной обработки к осмысленному взаимодействию модальностей. Мы по-прежнему избегаем грубого смешивания данных. Агрегация строится как контролируемый обмен информацией, где каждая модальность усиливает другие ровно настолько, насколько это оправдано текущей рыночной динамикой.
В контексте финансовых рынков такой этап особенно важен. Цена, объём, производные сигналы и их корреляционные структуры редко работают изолированно. Настоящее движение проявляется именно в их согласованных изменениях. Модуль кросс-модальной агрегации позволяет зафиксировать эти моменты и перевести их в компактное, информативное представление, готовое к дальнейшему анализу и принятию решений.
Авторы фреймворка STFlow для агрегации модальностей предлагают использовать трансформерный модуль кросс-внимания. Подход вполне ожидаемый и, надо признать, проверенный временем. Механизм внимания хорошо справляется с задачей согласования разнородных представлений. В нашей библиотеке уже есть несколько подобных реализаций, и при желании можно было бы ограничиться их прямым применением.
Однако в контексте оценки потока такой путь был бы слишком прямолинейным. Мы идём дальше и строим спайковую версию модуля кросс-внимания. Это позволяет сохранить событийную природу данных, работать с асинхронной динамикой рынка и не терять чувствительность к микроимпульсам.
Класс CNeuronSpikeMHCrossAttention аккуратно встраивается в уже знакомую нам иерархию и наследуется от CNeuronMSRes, что сразу задаёт правильную философию.
class CNeuronSpikeMHCrossAttention : public CNeuronMSRes { protected: uint iHeads; //--- CNeuronSpikeConvBlock cQ_Embedding; CNeuronSpikeConvBlock cKV_Embedding; int ibScoreIndex; CNeuronBaseOCL cMHAttentionOut; CNeuronSpikeConvBlock cW0; CNeuronBaseOCL cAttentionOut; CNeuronBaseOCL cContext; //--- virtual bool Attention(void); virtual bool AttentionGradients(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override; public: CNeuronSpikeMHCrossAttention(void) {}; ~CNeuronSpikeMHCrossAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSpikeMHCrossAttention; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
Внутренняя структура модуля предельно прагматична. Сначала признаки одной модальности проецируются в пространство запросов через блок cQ_Embedding. Параллельно другая модальность кодируется в ключи и значения с помощью cKV_Embedding. Оба блока реализованы как спайковые сверточные структуры, что позволяет сохранить событийную природу сигнала и не размазывать динамику во времени. Количество голов внимания задаётся явно, а значит мы можем контролировать, насколько детально модуль будет разбирать различные аспекты взаимодействия модальностей.
Архитектура модуля формируется в методе инициализации. И именно здесь становится ясно, как авторская идея кросс-внимания переводится в рабочую, спайковую конструкцию.
bool CNeuronSpikeMHCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMSRes::Init(numOutputs, myIndex, open_cl, units_count, window, 1, optimization_type, batch)) return false;
Метод начинается с инициализации родительского класса, что сразу задаёт общий каркас: фиксированное окно, остаточную схему и согласованное число выходных признаков. Это классическая, надёжная отправная точка — без сюрпризов и скрытой магии.
Далее явно фиксируется число голов внимания. Параметр iHeads не просто декоративный — он напрямую влияет на размерность всех последующих представлений.
iHeads = heads; uint index = 0; if(!cQ_Embedding.Init(0, index, OpenCL, window, window, iHeads * window_key, units_count, 1, optimization, iBatch)) return false;
Блок cQ_Embedding отвечает за формирование запросов. Он принимает входное представление основной модальности и проецирует его в пространство запросов сразу для всех голов внимания. Здесь мы сознательно используем спайковый сверточный блок: движение кодируется локально, устойчиво и без потери временной структуры.
Параллельно инициализируется cKV_Embedding. Этот блок обрабатывает вторую модальность и формирует ключи и значения в едином проходе. Размерность удваивается, поскольку каждая голова внимания требует и ключ, и значение.
index++; if(!cKV_Embedding.Init(0, index, OpenCL, window_k, window_k, 2 * iHeads * window_key, units_k, 1, optimization, iBatch)) return false;
Таким образом, уже на этапе инициализации архитектура строго разделяет роли модальностей: одна задаёт вопросы рынку, другая предоставляет контекст.
Отдельного внимания заслуживает объект cContext. Это буфер, для временного хранения контекста, получаемого для анализа.
index++; if(!cContext.Init(0, index, OpenCL, cKV_Embedding.GetWindow() * cKV_Embedding.GetUnits() * cKV_Embedding.GetVariables(), optimization, iBatch)) return false; cContext.SetActivationFunction(None);
Здесь отключена функция активации — данные должны поступать в чистом виде, без дополнительных нелинейностей.
Рядом создаётся буфер оценок ibScoreIndex, размещённый напрямую в OpenCL-контексте.
index++; ibScoreIndex = OpenCL.AddBuffer(sizeof(float) * cQ_Embedding.GetUnits() * cKV_Embedding.GetUnits() * iHeads, CL_MEM_READ_WRITE); if(ibScoreIndex == INVALID_HANDLE) return false;
Именно в нём будут храниться коэффициенты внимания для всех голов. Это решение позволяет избежать лишних копирований и сохранить вычисления на стороне GPU.
После этого формируется выход многоголового внимания cMHAttentionOut. Он аккумулирует результаты всех голов в единое спайковое представление.
if(!cMHAttentionOut.Init(0, index, OpenCL, cQ_Embedding.GetFilters() * cQ_Embedding.GetUnits() * cQ_Embedding.GetVariables(), optimization, iBatch)) return false; cMHAttentionOut.SetActivationFunction(None);
Снова без активации — мы фиксируем чистый результат агрегации.
Завершающим штрихом становится блок cW0, выполняющий линейную проекцию и возвращающий размерность к удобному для последующей обработки виду.
index++; if(!cW0.Init(0, index, OpenCL, cQ_Embedding.GetFilters(), cQ_Embedding.GetFilters(), cQ_Embedding.GetWindow(), cQ_Embedding.GetUnits(), cQ_Embedding.GetVariables(), optimization, iBatch)) return false;
Финальный слой cAttentionOut служит для организации механизма остаточных связей и подготавливает результат к передаче дальше.
В итоге метод инициализации пошагово выстраивает логичную и прозрачную архитектуру кросс-модального внимания, где каждая часть знает свою роль. Ничего лишнего. Всё на своих местах. Именно так и должна выглядеть практическая реализация сложных идей — спокойно, строго и с прицелом на реальное применение в торговых системах.
Прямой проход в модуле кросс-внимания организован максимально последовательно и без лишних усложнений.
bool CNeuronSpikeMHCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) { if(cContext.getOutput() != Context) if(!cContext.SetOutput(Context)) return false;
Метод сразу начинает с привязки внешнего контекста. Мы явно проверяем, что входной Context используется как выход буфера cContext. Это важный момент. Вторая модальность не копируется и не трансформируется заранее. Она аккуратно подключается к вычислительному графу ровно там, где это необходимо.
Далее поток обработки естественно разделяется. Основная модальность проходит через блок cQ_Embedding, формируя запросы для всех голов внимания.
if(!cQ_Embedding.FeedForward(NeuronOCL)) return false;
Параллельно контекстная модальность обрабатывается в cKV_Embedding, где из неё извлекаются ключи и значения.
if(!cKV_Embedding.FeedForward(cContext.AsObject())) return false;
Эти два шага независимы и подчёркивают принципиальную идею модуля. Каждая сущность обрабатывается своим путём и не смешивается с другой на ранних этапах.
После этого управление передаётся в метод Attention. Именно здесь вычисляются оценки соответствия, формируется карта внимания и выполняется взвешенное агрегирование значений. Результат собирается в cMHAttentionOut — компактное, но информативное представление кросс-модального взаимодействия.
if(!Attention()) return false;
Следующим шагом результат многоголового внимания проходит через выходную проекцию cW0.
if(!cW0.FeedForward(cMHAttentionOut.AsObject())) return false;
Это возвращает представление в согласованное пространство признаков, удобное для дальнейшей обработки. Затем выполняется операция SumAndNormilize, где выход внимания аккуратно объединяется с исходным сигналом основной модальности. Здесь реализуется остаточная связь. Модель не теряет исходную динамику, а лишь корректирует её с учётом контекста.
if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cAttentionOut.getOutput(), cW0.GetFilters(), true, 0, 0, 0, 1)) return false;
Финальный вызов одноименного метода родительского класса завершает прямой проход. Он нормализует и стабилизирует результат, подготавливая его к следующему этапу сети.
if(!CNeuronMSRes::feedForward(cAttentionOut.AsObject())) return false; //--- return true; }
В итоге весь процесс выглядит строго и предсказуемо: независимое кодирование, контролируемое внимание, аккуратное объединение и стабильный выход. Без хаоса, без лишних эффектов. Именно такой подход и нужен при работе с чувствительными рыночными данными.
Работа с двумя модальностями и наличие остаточной связи требуют особенно аккуратного подхода на этапе обучения. Здесь важно не просто протолкнуть ошибку назад, а распределить её так, чтобы каждая ветка получила ровно ту долю информации, за которую она отвечает. В нашем случае эта логика сосредоточена в методе calcInputGradients.
bool CNeuronSpikeMHCrossAttention::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!prevLayer) return false; if(cContext.getGradient() != SecondGradient) if(!cContext.SetGradient(SecondGradient)) return false; cContext.SetActivationFunction(SecondActivation);
Метод начинается с явной фиксации буферов градиентов для второй модальности. Буфер SecondGradient напрямую привязывается к cContext, а функция активации задаётся отдельно. Это позволяет гибко управлять поведением контекстной ветки и не навязывать ей жёстких ограничений со стороны основной модальности.
Далее обратный проход запускается с верхнего уровня через, начиная с родительского класса.
if(!CNeuronMSRes::calcInputGradients(cAttentionOut.AsObject())) return false; if(!DeActivation(cW0.getOutput(), cW0.getGradient(), cAttentionOut.getGradient(), cW0.Activation())) return false;
Таким образом корректно учитывается вклад остаточной связи и нормализации, сформированных на этапе прямого прохода. После этого градиент аккуратно проводится через выходной проекционный блок cW0. Здесь явно выполняется деактивация, чтобы корректно восстановить сигнал ошибки до пространства многоголового внимания.
if(!cMHAttentionOut.CalcHiddenGradients(cW0.AsObject())) return false;
Следующий шаг — распространение градиента в cMHAttentionOut, а затем в сам механизм внимания через AttentionGradients.
if(!AttentionGradients()) return false; Deactivation(cQ_Embedding) Deactivation(cKV_Embedding)
Именно здесь распределяется ответственность между головами внимания и формируется корректная обратная связь для запросов, ключей и значений. Это критический момент. Модель учится понимать, какие кросс-модальные связи действительно влияют на движение, а какие можно игнорировать.
После этого градиенты разделяются по веткам. Блоки cQ_Embedding и cKV_Embedding обрабатываются независимо, без смешивания сигналов ошибки. Контекстная модальность получает свой градиент через cContext, что сохраняет чистоту обучения и предотвращает паразитное влияние основной ветки.
if(!cContext.CalcHiddenGradients(cKV_Embedding.AsObject())) return false; Deactivation(cContext)
Завершающая часть метода отвечает за корректную обработку остаточной связи с предыдущим слоем. Градиент передаётся в prevLayer через ветку запросов.
if(!prevLayer.CalcHiddenGradients(cQ_Embedding.AsObject())) return false; if(!DeActivation(prevLayer.getOutput(), cAttentionOut.getPrevOutput(), cAttentionOut.getGradient(), prevLayer.Activation())) if(!SumAndNormilize(prevLayer.getGradient(), cAttentionOut.getPrevOutput(), prevLayer.getGradient(), cQ_Embedding.GetWindow(), false, 0, 0, 0, 1)) return false; //--- return true; }
После чего выполняется деактивация и суммирование с магистралью остаточных связей.
Таким образом ошибка возвращается назад в сеть в согласованном виде, без перекосов и потерь информации. Метод выстраивает строгую и предсказуемую схему обратного распространения. Каждая модальность обучается на своём сигнале, внимание корректируется осмысленно. А остаточная связь остаётся стабильной.
В итоге мы получаем не просто трансформерный блок, а аккуратно адаптированный к задачам STFlow модуль кросс-внимания. Он сохраняет независимость модальностей, уважает событийную структуру данных и при этом формирует общее представление движения рынка. Без лишней экзотики, но с ясной архитектурной логикой.
Заключение
В результате работы мы продвинулись от концептуальных идей фреймворка STFlow к их практической реализации средствами MQL5, создав полноценные спайковые модули Motion Encoder и кросс-модальной агрегации. На каждом этапе мы сохраняли баланс между чистотой архитектуры и адаптацией к особенностям финансовых данных. Признаки и корреляции каждой модальности обрабатываются независимо, но формируются в согласованное, информативное представление движения, готовое к дальнейшей агрегации.
Спайковая природа реализованных блоков позволяет работать с асинхронными событиями рынка, не теряя чувствительности к микроимпульсам и сохраняя высокую точность кодирования динамики. Использование остаточных связей и аккуратное распределение градиентов делает процесс обучения стабильным и воспроизводимым, минимизируя риск искажения информации при объединении модальностей.
Практическая ценность предложенной реализации заключается в том, что она объединяет проверенные архитектурные принципы трансформеров и многоголового внимания с особенностями спайковых сетей, адаптированных к задачам трейдинга.
В следующей статье мы завершим реализацию всех ключевых компонентов, предложенных авторами фреймворка STFlow, и перейдём к их практической оценке. Мы посмотрим, насколько согласованные представления признаков и корреляций обеих модальностей позволяют извлекать скрытую динамику рынка. Как спайковая структура сохраняет чувствительность к микроимпульсам.
Оценка будет проведена с точки зрения практической применимости в условиях реального рыночного потока.
Ссылки
- Spatially-guided Temporal Aggregation for Robust Event-RGB Optical Flow Estimation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования