
Die Grenzen des maschinellen Lernens überwinden (Teil 6): Effektive Speichervalidierung

In der vorangegangenen Diskussion über die Kreuzvalidierung haben wir den klassischen Ansatz und seine Anwendung auf Zeitreihendaten besprochen, um Modelle zu optimieren und eine Überanpassung zu vermeiden. Ein Link zu dieser Diskussion ist hier für Sie bereitgestellt. Wir haben auch vorgeschlagen, dass wir eine bessere Leistung erzielen können, als es die traditionelle Auslegung nahelegt. In diesem Artikel untersuchen wir die blinden Flecken herkömmlicher Kreuzvalidierungsverfahren und zeigen, wie sie durch domänenspezifische Validierungsmethoden verbessert werden können.
Um dies zu verdeutlichen, sollten Sie ein Gedankenexperiment durchführen. Stellen Sie sich vor, Sie könnten eine Zeitreise von 400 Jahren in die Zukunft machen. Bei Ihrer Ankunft finden Sie sich in einem Raum wieder, in dem für jeden Tag, den Sie verpasst haben, eine Zeitung liegt – ein Berg von Zeitungen, die das Weltgeschehen der letzten Jahrhunderte abdecken. Neben diesem Berg befindet sich ein MetaTrader 5-Terminal. Bevor Sie Handel treiben, müssen Sie sich zunächst anhand dieser Zeitungen über die Welt informieren.
In welcher Reihenfolge würden Sie sie lesen? Ist es notwendig, alle verfügbaren Zeitungen zu lesen, oder können Sie auch dann gute Leistungen erbringen, wenn Sie die neuesten Informationen aufnehmen? Wie weit sollte man zurückgehen, bevor die Informationen in den Preis „eingebrannt“ sind und nicht mehr hilfreich sind?
Diese Art von Fragen lassen sich am besten mit einer Kreuzvalidierung beantworten. Bei den klassischen Formen der Kreuzvalidierung wird jedoch davon ausgegangen, dass alle in der Vergangenheit enthaltenen Informationen notwendig sind. Wir möchten eine neue Form der Kreuzvalidierung einführen, um zu prüfen, ob diese Annahme zutrifft.
Bevor wir auf die Ergebnisse eingehen, die wir mit unserem MetaTrader 5-Terminal erzielt haben, sollten wir zunächst die Gründe für diese Angelegenheit darlegen, um dem Leser ein klares Gefühl für die Motivation zu vermitteln. Im Allgemeinen wäre es sinnlos, mit der ältesten Zeitung im Raum zu beginnen und dann weiterzulesen.
Abbildung 1: Ist es immer das Beste für uns, alle historischen Daten zu lesen, die wir haben und die einen Markt beschreiben?
Ein intelligenter Händler beginnt lieber mit den neuesten Informationen und bewegt sich rückwärts, da ältere Informationen auf den Finanzmärkten schnell an Bedeutung verlieren. Dies verdeutlicht eine subtile Wahrheit, die es nur im Finanzwesen gibt: Informationen verfallen.
Abbildung 2: Oder sollten wir besser davon ausgehen, dass die Finanzmärkte den neuesten verfügbaren Informationen mehr Gewicht beimessen?
In den Naturwissenschaften zerfällt die Information nicht. Newtons Aufzeichnungen über die Schwerkraft liefern noch Jahrhunderte später die gleichen Ergebnisse. Doch auf den Finanzmärkten können Strategien, die in den 1950er Jahren noch funktionierten, heute versagen. Die Marktbedingungen ändern sich, und was einst wertvolle Informationen waren, wird oft „eingepreist“ oder veraltet.
Dies führt uns zu einer wichtigen Frage: Verbessert die Verwendung von mehr historischen Daten immer die Vorhersageleistung unserer statistischen Modelle? Unsere Ergebnisse legen das Gegenteil nahe. Wenn ein Modell mit zu vielen Daten aus der fernen Vergangenheit gefüttert wird, kann dies seine Genauigkeit beeinträchtigen. Wie bei dem Gedankenexperiment, das wir durchgeführt haben, muss man nicht jede Zeitung lesen, die jemals gedruckt wurde, sondern nur diejenigen, die für die Gegenwart noch relevant sind.
Professionelle menschliche Händler beginnen ihre Analyse nicht mit der ersten aufgezeichneten Kerze in jedem Markt, den sie handeln. Beim maschinellen Lernen erwarten wir jedoch, dass unsere Modelle dies tun, in der blinden Annahme, dass mehr besser ist. In dieser Diskussion wird diese Annahme in Frage gestellt und untersucht, ob die Finanzmärkte über ein effektives Gedächtnis verfügen – eine Grenze, jenseits derer ältere Informationen an Bedeutung verlieren.
Unser Ziel ist es, die Beziehung zwischen der Menge der für das Training verwendeten historischen Daten und unserer Out-of-Sample-Leistung zu untersuchen. Wir konzentrieren uns auf die Frage, ob eine kleinere, neuere Teilmenge von Daten mit einem auf dem gesamten Datensatz trainierten Modell mithalten oder es sogar übertreffen kann. Um dies zu untersuchen, haben wir etwa acht Jahre an Marktdaten verwendet und diese in zwei Hälften geteilt. Die Trainingsmenge wurde in inkrementelle Segmente aufgeteilt – 10 %, 20 %, 30 % usw. – ergänzt mit immer älteren Daten. Wir haben dann den Fehler jedes Modells über einen festen Testsatz von etwa 4 Jahren gemessen.
Die Ergebnisse waren eindeutig: Der geringste Out-of-Sample-Fehler trat bei dem Modell auf, das nur mit 80 % der verfügbaren Trainingsdaten angepasst wurde, nicht mit allen. Die Hinzufügung älterer Daten über diesen Punkt hinaus verschlechterte nur die Genauigkeit. Dies zeigt, dass Modelle mit weniger Daten besser lernen können, insbesondere wenn ältere Beobachtungen nicht mehr die aktuellen Marktgegebenheiten widerspiegeln.
Die Datenmenge, die zum Trainieren des Modells verwendet wird, soll ein Indikator für die Kosten sein, die mit der Erstellung des Modells verbunden sind. Im Allgemeinen gilt: Je mehr Daten wir zum Trainieren des Modells verwenden, desto teurer wird es, das Modell zu erhalten. Daher haben diese Ergebnisse wichtige Auswirkungen für Praktiker auf allen Ebenen. Wenn man sie versteht, kann man Rechenkosten und Kosten für die Cloud-Infrastruktur senken, Entwicklungszyklen verkürzen und die Modelleffizienz verbessern.
Erste Schritte mit unserer Analyse in Python
Wir werden nun damit beginnen, die vom MetaTrader 5 exportierten Daten mit Hilfe der Standard-Python-Bibliotheken zu analysieren, auf die wir normalerweise zurückgreifen.
#Import the standard python libraries import numpy as np import pandas as pd import seaborn as sns import MetaTrader5 as mt5 import matplotlib.pyplot as plt
Melden wir uns nun am MetaTrader 5-Terminal an.
#Log in to our MT5 Terminal if(mt5.initialize()): #User feedback print("Logged In") else: print("Failed To Log In")
Eingeloggt
Bevor wir historische Daten zu einem Sybol abrufen, müssen wir zunächst das Symbol aus der Marktbeobachtung auswählen.
#Fetch Data on the EURUSD Symbol #First select the EURUSD symbol from the Market Watch if(mt5.symbol_select("EURUSD")): #Found the symbol print("Found the EURUSD Symbol")
Das EURUSD-Symbol gefunden
Jetzt können wir die Kurse von unserem Broker abrufen.
#Fetch the historical EURUSD data we need data = pd.DataFrame(mt5.copy_rates_from_pos("EURUSD",mt5.TIMEFRAME_D1,0,3000)) data
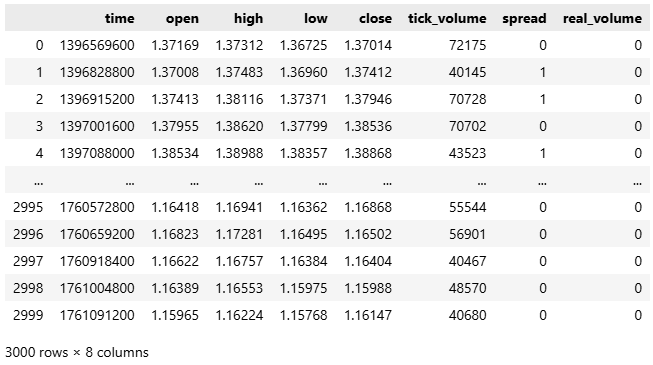
Abbildung 1: Wir beginnen mit der Analyse der historischen EURUSD-Marktdaten.
Die Daten kommen bei uns in Unix-Zeit an, da die meisten Broker Linux-Server einsetzen. Wir werden daher die Zeit von Sekunden in ein für Menschen lesbares Format von Jahr-Monat-Datum umwandeln.
#Convert the time from seconds to human readable data['time'] = pd.to_datetime(data['time'],unit='s') #Make sure the correct changes were made data
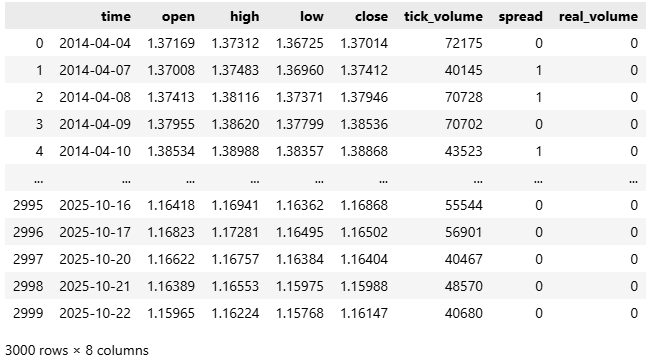
Abbildung 2: Konvertierung unserer Zeitangabe von Sekunden in ein für Menschen lesbares Format.
Konzentrieren wir uns nun auf die 4 Spalten, die den Eröffnungs-, Hoch-, Tief- und Schlusskurs enthalten.
#Select the OHLC columns data = data.iloc[:,:-3] data
Abbildung 3: Verkleinern wir den Datensatz, damit wir unsere Analyse auf die vier wichtigsten Preisniveaus konzentrieren können.
Dann beginnen wir mit der Erstellung eines klassischen Zeitreihenprognosemodells, bei dem die Vorhersagen einen Schritt in die Zukunft reichen.
#Define the classical horizon HORIZON = 1
Nach diesem Aufbau beschriften wir unsere Daten.
#Label the data data['Target'] = data['True Close'].shift(HORIZON)
Entfernen wir alle fehlenden Zeilen, da fehlende Werte bei der Anpassung von Modellen aus scikit-learn zu Fehlern führen können.
#Drop missing rows data.dropna(inplace=True)
Als Nächstes importieren wir die erforderlichen Bibliotheken für maschinelles Lernen.
#Import cross validation tools from sklearn.linear_model import Ridge,LinearRegression from sklearn.metrics import root_mean_squared_error from sklearn.neural_network import MLPRegressor
Teilen wir unseren Datensatz in zwei gleiche Teile auf – einen zum Trainieren und einen zum Testen.
#The big picture of what we want to test train , test = data.iloc[:data.shape[0]//2,:] , data.iloc[data.shape[0]//2:,:]
Dann trennen wir die Eingangsmerkmale und die Ausgangsziele.
#Define inputs and target X = data.columns[1:-1] y = data.columns[-1]
Um unseren Arbeitsablauf modular zu halten, definieren wir eine Funktion namens get_model(), die einen Random Forest Regressor zurückgibt. Random Forests sind leistungsstarke Schätzer, die in der Lage sind, komplexe, nichtlineare Wechselwirkungen zwischen Variablen zu erfassen, die bei einfacheren Modellen möglicherweise übersehen werden.
#Fetch a new copy of the model def get_model(): return(RandomForestRegressor(random_state=0,n_jobs=-1))
Nachdem wir unser Modell definiert haben, fahren wir mit dem Hauptteil des Programms fort. Hier erstellen wir eine Liste, in der wir die Leistungswerte des Modells aufzeichnen und die Gesamtzahl der Iterationen angeben, die wir durchführen möchten. Es steht den Nutzern frei, mit diesem Parameter zu experimentieren – größere Iterationszahlen liefern detailliertere Erkenntnisse.
In jeder Iteration der Schleife trainieren wir das Modell mit einem zunehmenden Anteil der Trainingsdaten. Mit der Funktion arange von NumPy erstellen wir Brüche zwischen 0,1 und 1,0 in Schritten von 0,1. Für jeden dieser Brüche trainieren wir das Modell nur mit dem jüngsten Teil der verfügbaren Trainingsdaten und bewerten es anhand eines festen Testsatzes. Dieser Vorgang wird so lange wiederholt, bis das Modell auf der gesamten Trainingspartition trainiert wurde.
Nachdem alle Iterationen abgeschlossen sind, wird die Leistung des Modells gegen den Trainingsanteil aufgetragen. Die rote Markierung im Diagramm hebt den niedrigsten Testfehler hervor, der bei der 80 %-Marke beobachtet wurde. Das bedeutet, dass das Modell seine beste Out-of-Sample-Leistung erreichte, als es auf nur 80 % der verfügbaren Daten trainiert wurde.
Es ist wichtig zu beachten, dass dieses Verfahren nicht dasselbe ist wie die klassische k-fache Kreuzvalidierung. In unserem Setup überschneiden sich die Trainings- und Testmengen nicht. Die Trainingsmenge wird einfach um ältere Daten erweitert, während die Testmenge unverändert bleibt. Die Beobachtung eines Leistungsminimums vor Erreichen von 100 % deutet darauf hin, dass die ältesten Daten keinen zusätzlichen Vorhersagewert haben.
Zusammenfassend zeigt unser Experiment, dass ein kleineres, kostengünstigeres Modell, das auf einem begrenzten, neueren Teil der Daten trainiert wurde, ein Modell, das auf dem gesamten historischen Datensatz trainiert wurde, übertreffen kann.
#Store our performance error = [] #Define the total number of iterations we wish to perform ITERATIONS = 10 #Let us perform the line search for i in np.arange(ITERATIONS): #Training fraction fraction =((i+1)/10) #Partition the data to select the most recent information partition_index = train.shape[0] - int(train.shape[0]*fraction) train_X_partition = train.loc[partition_index:,X] train_y_partition = train.loc[partition_index:,y] #Fit a model model = get_model() #Fit the model model.fit(train_X_partition,train_y_partition) #Cross validate the model out of sample score = root_mean_squared_error(test.loc[:,y],model.predict(test.loc[:,X])) #Append the error levels error.append(score) #Plot the results plt.title('Improvements Made By Historical Data') plt.plot(error,color='black') plt.grid() plt.ylabel('Out of Sample RMSE') plt.xlabel('Progressivley Fitting On All Historical Data') plt.scatter(np.argmin(error),np.min(error),color='red')
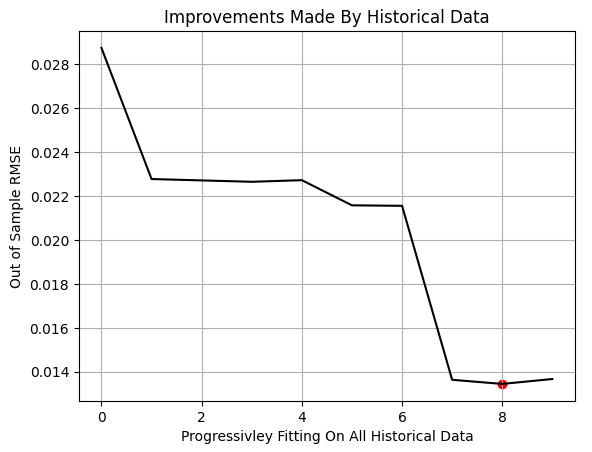
Abbildung 4: Die Ergebnisse, die wir mit unserem MetaTrader 5-Terminal erzielt haben, zeigen, dass die Einspeisung von mehr historischen Daten die Leistung nicht immer verbessert.
Wir ermitteln nun den optimalen Partitionsindex, der sich aus unserer Zeilensuche ergibt.
#Let us select the partition of interest partition_index = train.shape[0] - int(train.shape[0]*(0.8))
Unsere Methodik zeigt, dass die ersten 300 Beobachtungen – Daten von etwa einem Jahr – im Trainingssatz nicht für die Vorhersage geeignet waren.
train.loc[partition_index:,:]
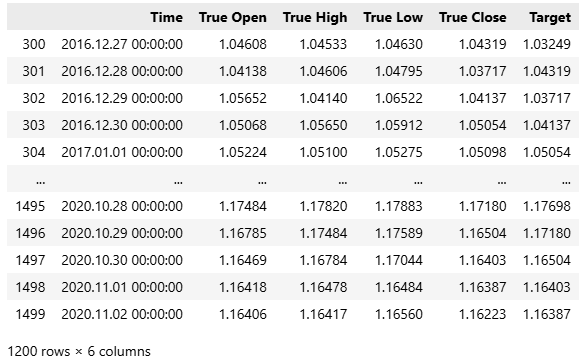
Abbildung 5: Wir haben die oben genannte Teilmenge unserer Trainingsdaten als für den aktuellen Markt am relevantesten eingestuft.
Daher werden wir die Leistung von zwei Modellen vergleichen:
- Klassisches Modell: trainiert auf allen verfügbaren Daten mit der Vorhersage von einem Schritt.
- Moderne Variante: Trainiert nur mit dem optimalen Teil aller verfügbaren historischen Daten und darauf ausgelegt, mehr als einen Schritt in die Zukunft vorauszusagen.
Lassen Sie uns zunächst ein Basis-Leistungsniveau nach dem klassischen Schema festlegen. Zu diesem Zweck wird ein neues Modell initialisiert.
#Prepare the baseline model
model = LinearRegression() Passen wir das Modell an den gesamten Datensatz an, wie es der klassische Aufbau vorsieht.
#Fit the baseline model on all the data
model.fit(train.loc[:,X],train.loc[:,y]) Als Nächstes bereiten wir den Export des Modells in das ONNX-Format (Open Neural Network Exchange) vor. ONNX bietet eine rahmenunabhängige Methode zur Darstellung und Bereitstellung von Modellen für maschinelles Lernen, sodass sie unabhängig von ihrer Trainingsumgebung auf verschiedenen Plattformen ausgeführt werden können.
#Prepare to export to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Nachdem wir die erforderlichen Abhängigkeiten geladen haben, definieren wir die Eingabe- und Ausgabeformen unseres Modells.
#Define ONNX model input and output dimensions initial_types = [("FLOAT INPUT",FloatTensorType([1,4]))] final_types = [("FLOAT OUTPUT",FloatTensorType([1,1]))]
Wir konvertieren das Modell sklearn mit der Funktion convert_sklearn in sein ONNX-Prototyp-Format.
#Convert the model to its ONNX prototype onnx_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
Nach der Konvertierung speichern wir das ONNX-Modell mit onnx.save() auf der Festplatte.
#Save the ONNX model onnx.save(onnx_proto,"EURUSD Baseline LR.onnx")
Erste Schritte in MQL5
In diesem Stadium sind wir in der Lage, unseren grundlegenden Leistungsmaßstab festzulegen. Der erste Schritt besteht darin, die Systemkonstanten festzulegen, die während beider Tests unverändert bleiben, um sicherzustellen, dass Leistungsunterschiede ausschließlich auf unsere Modellierungsentscheidungen zurückzuführen sind.//+------------------------------------------------------------------+ //| Information Decay.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define SYMBOL "EURUSD" #define SYSTEM_TIMEFRAME PERIOD_D1 #define SYSTEM_DATA COPY_RATES_OHLC #define TOTAL_MODEL_INPUTS 4 #define TOTAL_MODEL_OUTPUTS 1 #define ATR_PERIOD 14 #define PADDING 2
Laden wir das ONNX-Modell. Es sei daran erinnert, dass dieses Basismodell mit allen historischen Daten trainiert wurde und so konfiguriert ist, dass es einen Schritt voraussagt.
//+------------------------------------------------------------------+ //| System resources we need | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD Baseline LR.onnx" as const uchar onnx_buffer[];
Als Nächstes laden wir die erforderlichen Bibliotheken – die für die Handelsausführung und unsere nutzerdefinierte Hilfsbibliothek, die wichtige Handelsinformationen wie die Mindestlosgröße und die aktuellen Geld- und Briefkurse abruft.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; TradeInfo *TradeHelper;
Wir definieren auch eine Reihe von globalen Variablen, die in der gesamten Anwendung verwendet werden.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; vectorf onnx_inputs,onnx_output; MqlDateTime current_time,time_stamp; int atr_handler; double atr[];
Sobald die Einrichtung abgeschlossen ist, fahren wir mit der Initialisierungsphase der Anwendung fort. Hier erstellen wir die ONNX-Modellinstanz aus dem im Programmkopf definierten Puffer. Wir führen eine Fehlerprüfung durch, indem wir bestätigen, dass der Modell-Handle gültig ist. Wird ein ungültiges Handle erkannt, wird eine Fehlermeldung angezeigt und die Initialisierung abgebrochen. Andernfalls fahren wir damit fort, die Eingangs- und Ausgangsformen des Modells zu definieren. Fehler, die hier auftreten, werden dem Nutzer ebenfalls mitgeteilt. Wenn die Initialisierung erfolgreich war, setzen wir die Anfangswerte wichtiger globaler Variablen wie der aktuellen Uhrzeit, erstellen neue Klasseninstanzen und initialisieren den technischen Indikator, von dem unsere Anwendung abhängt.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Create the ONNX model from its buffer onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DATA_TYPE_FLOAT); //--- Check for errors if(onnx_model == INVALID_HANDLE) { //--- User feedback Print("An error occured loading the ONNX model:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Setup the ONNX handler input shape else { //--- Define the I/O shapes ulong input_shape[] = {1,4}; ulong output_shape[] = {1,1}; //--- Attempt to set input shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { //--- User feedback Print("Failed to specify the correct ONNX model input shape:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Attempt to set output shape if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { //--- User feedback Print("Failed to specify the correct ONNX model output shape:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Mark the current time TimeLocal(current_time); TimeLocal(time_stamp); //--- Setup the trade helper TradeHelper = new TradeInfo(SYMBOL,SYSTEM_TIMEFRAME); //--- Setup our technical indicators atr_handler = iATR(Symbol(),SYSTEM_TIMEFRAME,ATR_PERIOD); //--- Success return(INIT_SUCCEEDED); } }
Wenn die Anwendung nicht mehr verwendet wird, sorgen wir für eine ordnungsgemäße Bereinigung der Ressourcen, indem wir den dem ONNX-Modell, dem technischen Indikator und anderen während der Laufzeit erstellten dynamischen Objekten zugewiesenen Speicher freigeben.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- OnnxRelease(onnx_model); IndicatorRelease(atr_handler); delete(TradeHelper); }
Die Hauptlogik der Anwendung befindet sich in der Funktion OnTick(). Jedes Mal, wenn ein neuer Marktpreis eintrifft, aktualisieren wir die aktuelle Zeit mit Hilfe der Funktion TimeLocal(), die die lokale Zeit des Computers zurückgibt, auf dem das MetaTrader 5 Terminal läuft. Wir vergleichen dann currenttime.dayofyear mit timestamp.dayofyear.
Da der Zeitstempel zuletzt während der Initialisierung aktualisiert wurde, wird diese Bedingung erst erfüllt, wenn ein ganzer Tag vergangen ist. Wenn die Bedingung nicht erfüllt ist, aktualisieren wir den Zeitstempel auf die aktuelle Zeit, aktualisieren die Puffer für die technischen Indikatoren und bereiten die Eingangs- und Ausgangsvektoren für das ONNX-Modell vor.
Anschließend fordern wir mit dem Befehl OnnxRun() eine neue Vorhersage von dem Modell an. Diese Funktion nimmt die ONNX-Modellinstanz, Flag-Parameter für spezielle Modellattribute und die vorbereiteten Eingabe- und Ausgabevektoren.
Nachdem wir die Vorhersage erhalten haben, zeigen wir dem Nutzer eine Rückmeldung an. Wenn es keine offenen Handelsbedingungen gibt, führen wir auf der Grundlage des Modells Aktionen aus. Wenn das Modell jedoch keine Vorhersage treffen kann, wird der Nutzer über einen Fehler informiert.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check for updated candles TimeLocal(current_time); //--- Periodic one day test if(current_time.day_of_year != time_stamp.day_of_year) { //--- Update the time stamp TimeLocal(time_stamp); //--- Update technical indicators CopyBuffer(atr_handler,0,0,1,atr); //--- Prepare a prediction from our model onnx_inputs = vectorf::Zeros(TOTAL_MODEL_INPUTS); onnx_inputs[0] = (float) iOpen(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[1] = (float) iHigh(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[2] = (float) iLow(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[3] = (float) iClose(Symbol(),SYSTEM_TIMEFRAME,0); //--- Also prepare the outputs onnx_output = vectorf::Zeros(TOTAL_MODEL_OUTPUTS); //--- Fetch a prediction from our model if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_inputs,onnx_output)) { //--- Give user feedback Comment("Trading Day: ",time_stamp.year," ",time_stamp.mon," ",time_stamp.day_of_week,"\nForecast: ",onnx_output[0]); //--- Check if we have an open position if(PositionsTotal() == 0) { //--- Long condition if(onnx_output[0] > iClose(SYMBOL,SYSTEM_TIMEFRAME,0)) Trade.Buy(TradeHelper.MinVolume(),SYMBOL,TradeHelper.GetAsk(),TradeHelper.GetBid()-(atr[0]*PADDING),TradeHelper.GetBid()+(atr[0]*PADDING),""); //--- Short condition if(onnx_output[0] < iClose(SYMBOL,SYSTEM_TIMEFRAME,0)) Trade.Sell(TradeHelper.MinVolume(),SYMBOL,TradeHelper.GetBid(),TradeHelper.GetAsk()+(atr[0]*PADDING),TradeHelper.GetAsk()-(atr[0]*PADDING),""); } //--- Manage our open position else { //--- This control branch remains empty for now } } //--- Something went wrong else { Comment("Failed to obtain a prediction from our model. ",GetLastError()); } } } //+------------------------------------------------------------------+
Schließlich müssen Sie alle zuvor erstellten Systemkonstanten zurücksetzen.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef SYMBOL #undef SYSTEM_DATA #undef SYSTEM_TIMEFRAME #undef ATR_PERIOD #undef PADDING #undef TOTAL_MODEL_INPUTS #undef TOTAL_MODEL_OUTPUTS
Nachdem wir unsere Anwendung definiert haben, können wir nun mit den Tests beginnen. Wir führen unsere Bewertung über das zuvor festgelegte fünfjährige Backtest-Fenster durch. Wir beginnen mit der Auswahl der Basisversion der Anwendung, die wir gerade erstellt haben, und legen die entsprechenden Trainingsdaten fest.

Abbildung 6: Die Daten, die wir für unseren Backtestzeitraum ausgewählt haben, liegen außerhalb des in Abbildung 3 identifizierten Trainingszeitraums.
Als Nächstes legen wir die Emulationsbedingungen fest, unter denen der Backtest ablaufen soll. Es sei daran erinnert, dass wir jeden Tick auf der Grundlage echter Ticks verwenden, um eine realistische Entwicklung der Marktbedingungen zu erfassen. Die Verzögerungseinstellung ist auf zufällige Verzögerung konfiguriert; dies ermöglicht uns eine zuverlässige Emulation der unvorhersehbaren Natur von Live-Handelsumgebungen.

Abbildung 7: Die von uns gewählten Backtest-Bedingungen sollen das Chaos der realen Marktbedingungen nachahmen.
Bei der Überprüfung der Basisleistung stellen wir fest, dass die ursprüngliche Version unserer Anwendung über den fünfjährigen Backtest-Zeitraum einen Gesamtgewinn von 90 $ erzielte. Dieses Ergebnis ist zwar nicht ganz schlecht, aber bei weitem nicht beeindruckend. Bei näherer Betrachtung fällt ein alarmierendes Merkmal in der Handelszusammensetzung auf: Die Anwendung führte während des gesamten Backtests keinerlei Käufe aus. Alle getätigten Handelsgeschäfte waren ausschließlich Verkäufe. Dieses Verhalten wurde bei der Entwicklung weder erwartet noch beabsichtigt, und es gibt keine eindeutige Erklärung dafür, warum sich das Modell so verhalten hat. Außerdem lag die Genauigkeit der Strategie bei etwa 50 % und damit knapp über dem Zufall. Noch besorgniserregender war, dass der erwartete Gewinn negativ war, was darauf hindeutet, dass die Anwendung auf lange Sicht wahrscheinlich Geld verlieren würde.
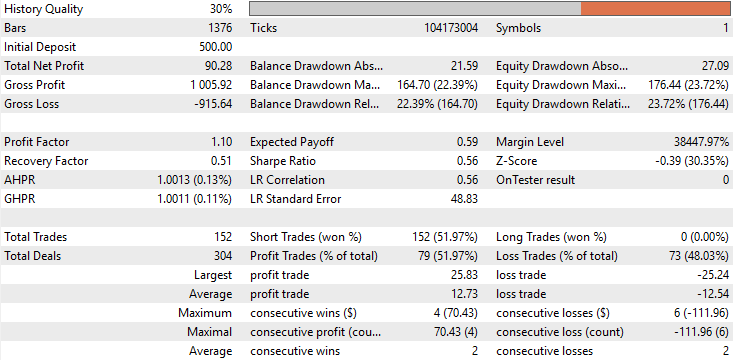
Abbildung 8: Eine detaillierte statistische Analyse der Ergebnisse, die wir durch den Backtest erhalten haben.
Bei der Betrachtung der Kapitalkurve ist eine ausgeprägte Volatilität und Instabilität während des gesamten Testzeitraums zu erkennen. Wenn wir uns dem November 2022 nähern, hört der Kontostand auf zu wachsen und tritt in eine lang anhaltende Konsolidierungsphase ein, die innerhalb des Backtest-Fensters fast drei Jahre lang anhält. Insgesamt gelingt es dem Basismodell nicht, das Konto sinnvoll zu erweitern, und es gibt wenig Vertrauen in seine langfristige Lebensfähigkeit.
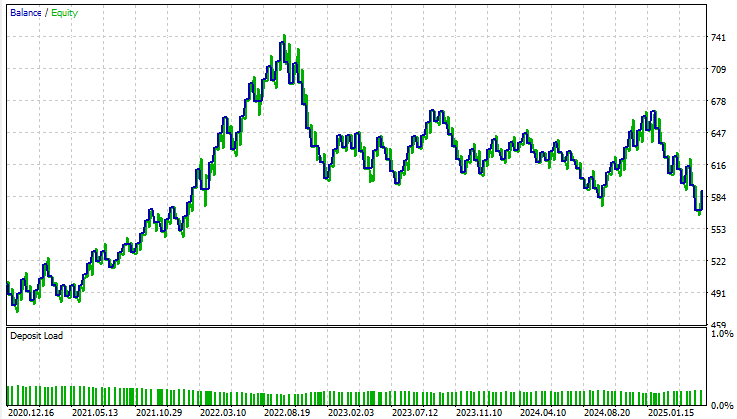
Abbildung 9: Die Visualisierung der Kapitalkurve ergibt sich aus den traditionellen Leitlinien für die Erstellung eines statistischen Modells.
Modifizierung unseres ONNX-Modells
Nachdem wir nun diese Basisleistung – die unter den klassischen Bedingungen erzielt wurde – ermittelt haben, wollen wir über den traditionellen Rahmen hinausgehen und unser ONNX-Modell so modifizieren, dass es besser widerspiegelt, wie professionelle menschliche Händler tatsächlich handeln. Die erste große Änderung weicht von der konventionellen Designphilosophie ab. Anstatt Modelle zu entwickeln, die nur einen Schritt in die Zukunft blicken, entwerfen wir unser Modell nun so, dass es zehn Schritte in die Zukunft vorausschaut. Menschliche Händler handeln nicht Kerze für Kerze; sie handeln auf der Grundlage eines umfassenderen Bildes der erwarteten Marktbewegung. Unser Modell sollte daher dieselbe vorausschauende Intuition widerspiegeln. HORIZON = 10 Anschließend ermitteln wir die optimale Datenpartition, die mit Hilfe von Kreuzvalidierungstechniken geschätzt wird.
#Let us select the partition of interest partition_index = train.shape[0] - int(train.shape[0]*(0.8)) train.loc[partition_index:,:]
Anschließend laden wir ein neues Modell, das von der Architektur her mit dem Basismodell identisch ist.
#Prepare the improved baseline model
model = LinearRegression() Wir trainieren das neue Modell ausschließlich auf dieser optimalen Partition der Daten.
#Fit the improved baseline model
model.fit(train.loc[partition_index:,X],train.loc[partition_index:,y]) Nach dem Training wandeln wir dieses verbesserte Modell in seinen ONNX-Prototyp um. Es sei jedoch daran erinnert, dass beide Modelle die gleiche Komplexität aufweisen.
#Convert the model to its ONNX prototype onnx_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
Schließlich speichern wir das ONNX-Modell in einer Datei.
#Save the ONNX model onnx.save(onnx_proto,"EURUSD Improved Baseline LR.onnx")
Die Verbesserung unserer ersten Ergebnisse
Der Nutzer sollte beachten, dass die einzige Komponente, die geändert werden muss, der Verweis auf die ONNX-Datei-Ressource ist, die sich in der Kopfzeile der Anwendung befindet. Der Rest des Systems bleibt unverändert und funktioniert genauso wie zuvor. //+------------------------------------------------------------------+ //| System resources we need | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD Improved Baseline LR.onnx" as const uchar onnx_buffer[];
Wir wählen dann diese verbesserte Version der Anwendung aus, um sie in demselben Fünfjahreszeitraum wie das Basismodell zu testen. Wichtig ist, dass alle Backtest-Bedingungen – einschließlich der zufälligen Verzögerung und der tickbasierten Ausführung – mit denen in Abbildung 7 identisch sind, um die Vergleichbarkeit zu gewährleisten.
Abbildung 10: Auswahl unserer neuen und verbesserten Version der Anwendung, um die Verbesserungen zu vergleichen, die wir erzielt haben.
Bei der Analyse der detaillierten Leistungsstatistiken wird der Unterschied zwischen den beiden Anwendungen sofort deutlich. Der Gesamtnettogewinn des verbesserten Modells hat sich mehr als verdreifacht und ist von etwa 90 Dollar auf 330 Dollar gestiegen. Wir können nun feststellen, dass die anfängliche Schieflage in der Verteilung der Abschlüsse vollständig korrigiert wurde. In der Basisversion unserer Anwendung waren alle Handelsgeschäfte ausschließlich Verkäufe – ein unbeabsichtigtes Ungleichgewicht im Verhalten des Modells. Im Gegensatz dazu platziert die verbesserte Version nun sowohl Käufe als auch Verkäufe in ausgewogener Weise und spiegelt damit den natürlicheren Entscheidungsprozess eines echten menschlichen Händlers wider.
Darüber hinaus ist eine bemerkenswerte Verbesserung der Genauigkeit festzustellen, die von etwa 52 % auf fast 60 % gestiegen ist. Dies ist eine ermutigende Entwicklung, die darauf hindeutet, dass die interne Entscheidungslogik des Modells konsistenter und anspruchsvoller geworden ist.
Was mich bei dieser Analyse jedoch am meisten überrascht hat, ist die Tatsache, dass die Gesamtzahl der Abschlüsse bei beiden Modellen identisch ist. Jede Version führte während des Backtests genau 152 Trades aus. Trotzdem erzielte das verbesserte Modell mehr als das Dreifache des gesamten Nettogewinns, was eine deutliche Effizienzsteigerung darstellt. Mit anderen Worten: Bei der gleichen Anzahl von Handelsgeschäften erzielte das verbesserte Modell wesentlich höhere Renditen. Darüber hinaus sind sowohl die Sharpe Ratio als auch die erwartete Auszahlung deutlich gestiegen – ein weiterer Beweis dafür, dass das Modell sein Kapital intelligenter einsetzt und seine Handelsgeschäfte zeitlich besser abstimmt.
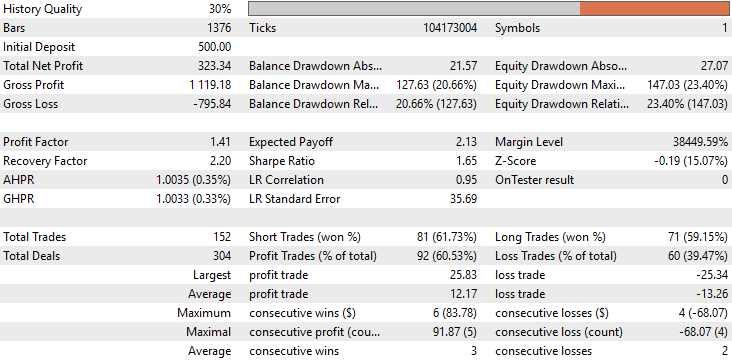
Abbildung 11: Eine detaillierte Analyse der erzielten Ergebnisse zeigt, dass die von uns vorgenommenen Änderungen angemessen waren.
Bei der Betrachtung der Kapitalkurve der verbesserten Version ist der Unterschied frappierend. Die langwierige Konsolidierungsphase, die bei der ersten Anwendung fast drei Jahre dauerte, ist vollständig verschwunden. Das neue Modell weist ein stetiges und konsistentes Wachstum auf, was darauf hindeutet, dass die strukturellen Beschränkungen oder blinden Flecken, die in der früheren Version vorhanden waren, nun wirksam beseitigt wurden. Dieses Ergebnis ist sowohl ermutigend als auch validierend und bestätigt, dass die von uns eingeführten Verbesserungen eine bedeutende Wirkung hatten.
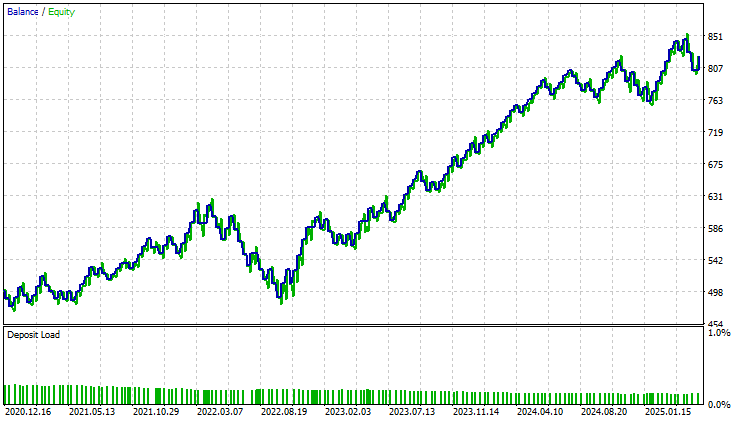
Abbildung 12: Die verbesserte Kapitalkurve, die wir erstellt haben, zeigt, dass die von uns vorgenommenen Änderungen über einen 5-Jahres-Test Stabilität in unser System gebracht haben.
Schlussfolgerung
Nach der Lektüre dieses Artikels sollte der Leser mit umsetzbaren Erkenntnissen über die wahre Natur des statistischen Lernens im algorithmischen Handel ausgestattet sein. Eine wichtige Erkenntnis ist, dass das blinde Festhalten an traditionellen statistischen Prinzipien für uns als algorithmische Händler nicht unbedingt hilfreich ist. Wir können nicht einfach die Heuristiken von „Big Data“ übernehmen und erwarten, dass sie in unserem Bereich, in dem die Relevanz von Daten stark auf die Gegenwart ausgerichtet ist, unverändert funktionieren.
Dieser Artikel enthält auch praktische Hinweise zur Einsparung von Kapital, das andernfalls für die Anschaffung übermäßig komplexer oder ineffizienter Modelle missbraucht werden könnte. Die hier vorgestellten Erkenntnisse können sich direkt in echten finanziellen Einsparungen niederschlagen, nicht nur bei den Investitionsausgaben, sondern auch bei den Rechenressourcen, der Entwicklungszeit und den Infrastrukturkosten, die mit dem Einsatz fortschrittlicher maschineller Lernsysteme verbunden sind.
Schließlich sollte der Leser nun einen klareren Blick für die blinden Flecken haben, die den klassischen Kreuzvalidierungsparadigmen innewohnen. Wir übersehen oft, ob alle Daten, die wir einbeziehen, wirklich zur Erreichung unseres Ziels beitragen. Die hier vorgestellte Analyse deckt eine neue Form der Überanpassung auf – eine, für die das klassische statistische Lernen wenig Anhaltspunkte bietet. Es zeigt, dass der Versuch, ein Modell auf allen verfügbaren Daten zu trainieren, selbst eine unerkannte Quelle der Ineffizienz sein kann. Zusammengenommen geben uns diese Erkenntnisse die Möglichkeit, effektivere, effizientere und profitablere maschinelle Lernmodelle für den algorithmischen Handel zu entwickeln.
| Dateiname | Beschreibung der Datei |
|---|---|
| Information Decay Baseline.mq5 | Die Basisanwendung für den Handel, die auf klassischen Paradigmen des maschinellen Lernens basiert. |
| Information Decay Improved Baseline.mq5 | Die verbesserte Anwendung wurde mit Hilfe der Effective Memory Cross-Validation (EMCV) entwickelt, einer in dieser Arbeit vorgestellten domänengebundenen Technik. |
| Limitations of Cross Validation 1.ipynb | Das Jupyter-Notebook, das für die Analyse von Marktdaten und die Erstellung unserer ONNX-Modelle verwendet wird. |
| EURUSD Baseline LR.onnx | Das klassische ONNX-Modell, das nach klassischen Best Practices aufgebaut ist. |
| EURUSD Improved Baseline LR.onnx | Das verbesserte ONNX-Modell, das den klassischen Benchmark übertrifft, indem es die hier diskutierten neuen bereichsgebundenen Best Practices befolgt. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20010
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.