
Создание самооптимизирующихся советников на MQL5 (Часть 14): Преобразования данных как параметры настройки регулятора с обратной связью

Предварительная обработка — это мощный, но зачастую недооцениваемый параметр настройки в любой среде или конвейере машинного обучения.
Это важный регулятор в системе, который часто остается в тени своих более крупных аналогов. Как правило, основное внимание и исследовательские усилия уделяются оптимизаторам или передовым архитектурам моделей, и значительные ресурсы научного сообщества направляются именно в эти области. Однако изучению влияния методов предварительной обработки уделяется мало внимания.
Незаметно для нас, предварительная обработка данных, которую мы проводим, оказывает на эффективность модели влияние, которое может оказаться удивительно значительным. Даже незначительное процентное улучшение, достигнутое на этапе предварительной обработки, со временем может привести к значительным результатам и существенно повлиять на прибыльность и риски наших торговых приложений.
Слишком часто мы спешим с этапом предварительной обработки, не уделяя должного внимания и времени проверке того, действительно ли мы выбрали наилучший вариант преобразования входных данных.
Современные оптимизаторы и архитектуры машинного обучения, на которые мы полагаемся в нашу эпоху, незаметно сдерживаются — либо, напротив, усиливаются благодаря преобразованиям данных. К сожалению, на момент написания данной статьи не существует устоявшейся методологии, позволяющей доказать, что та или иная трансформация является оптимальной. Мало того, у нас нет никакой уверенности в том, что не существует более удачного варианта преобразования. На самом деле, лишь в немногих исследованиях рассматривается возможность объединения различных преобразований в гибридные решения — и именно в этом заключается потенциал для повышения производительности, который пока не используется.
Поэтому наша цель — повысить эффективность регулятора с обратной связью, который мы тщательно разработали вместе в ходе предыдущего обсуждения (ссылка приведена здесь).
Помимо обычной прибыльности, мы стремимся добиться снижения рисков и обеспечить более устойчивое — и в определенной степени более зрелое — поведение нашего торгового приложения. По сути, в данном подходе сама предварительная обработка рассматривается как самостоятельный параметр настройки, который при правильном использовании может существенно повлиять на результаты работы торговых приложений.
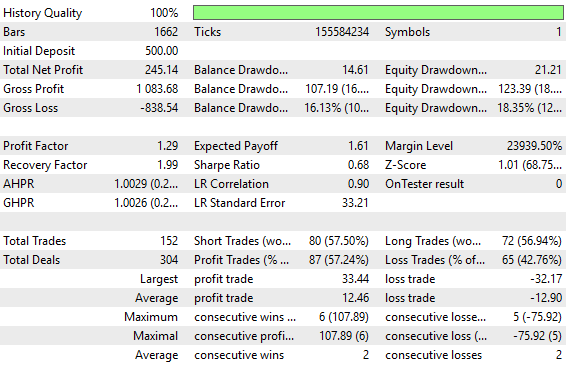
Рисунок 1: Старые настройки статистики бэктеста, заданные в старой версии нашего контроллера с обратной связью
Показатели нашего старого контроллера обратной связи, безусловно, были приемлемыми по всем параметрам; однако, само собой разумеется, мы продемонстрируем, что время, затраченное на поиск правильных преобразований, может потенциально раскрыть в вашей стратегии альфа-доходность, которая ранее оставалась нереализованной из-за недостаточно эффективного использования сигнала.
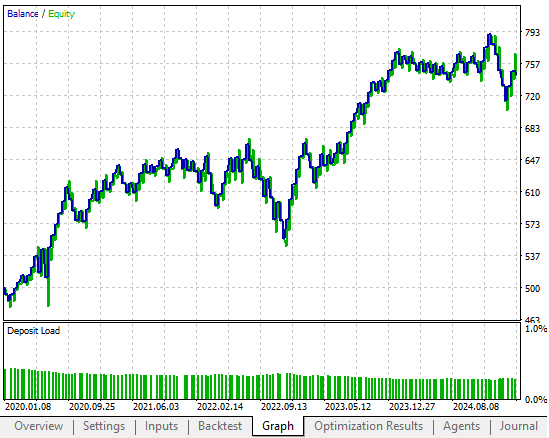
Рисунок 2: Старая кривая капитала, которую мы стремимся превзойти, определив подходящее преобразование для применения к нашим входным данным
Неспособность выявить сложные закономерности в вашем наборе данных со временем приводит к потере инвестиционного капитала. Мы протестировали три различных преобразования входных данных, которые мы подавали на наш регулятор с обратной связью. Чтобы получить контрольную точку сравнения, мы провели бенчмарк-тест на сырых, не преобразованных входных данных, о которых шла речь ранее. Впоследствии каждое из рассмотренных нами преобразований проверялось на идентичном наборе исторических данных при неизменности всех остальных переменных. Эффективность оценивалась по таким показателям, как рентабельность, коэффициент Шарпа, количество совершённых сделок, общая сумма начисленных убытков и общая доля прибыльных сделок. Это позволило нам выделить влияние предварительной обработки, сохранив при этом объективность сравнения по всем трем тестам.
Первым преобразованием, которое мы протестировали, был стандартный статистический z-score (z-нормализация, стандартизация). Z-показатель рассчитывается путем вычитания среднего значения из каждого столбца и деления каждого столбца на его стандартное отклонение. Мы заметили, что эта трансформация привела к снижению уровня нашей рентабельности на 30 процентов по сравнению с исходным показателем. Это ни в коем случае не выглядит привлекательно. Кроме того, это привело к падению нашего коэффициента Шарпа на целых 10 процентов по сравнению с базовым уровнем доходности.
Поэтому преобразование по Z-score не было для нас оптимальным вариантом. Затем мы применили преобразование, заимствованное из области линейной алгебры. Это преобразование называется нормировкой по единичной норме и осуществляется путем деления матрицы на её норму В данном конкретном случае в качестве делителя мы выбрали L1-норму матрицы. После масштабирования с использованием нормы L1 мы заметили, что показатели рентабельности нашего приложения улучшились на 12 процентов по сравнению с базовым уровнем, что является весьма обнадеживающим результатом. Кроме того, коэффициент Шарпа улучшился на 30 процентов за счет нормировки по единичной норме.
Еще одним важным признаком высокого уровня мастерства в торговле является способность нашей стратегии достигать более высоких показателей доходности при меньшем общем количестве сделок. Так произошло и в этот раз: после нормировки по единичной норме общее количество необходимых сделок сократилось на 8 процентов, а общий размер понесенных убытков также снизился на 15 процентов. Наконец, общая доля прибыльных сделок выросла на 5 процентов. Таким образом, это дало нам полную уверенность в том, что нормировка по единичной норме положительно повлияла на производительность нашего регулятора с обратной связью.
В заключение мы протестировали гибридный подход, сочетающий z-score и нормировку по единичной норме. К сожалению, это свело на нет все улучшения, достигнутые исключительно за счет нормировки по единичной норме. Наша доходность упала на 58 процентов по сравнению с базовым показателем, а коэффициент Шарпа снизился на 19 процентов. Поэтому, несмотря на наше сильное предчувствие, объединение этих двух преобразований в гибридную модель оказалось губительным для производительности и не выявило никакой дополнительной структуры, из которой мы могли бы извлечь полезную информацию.
Таким образом, из всего вышесказанного можно легко сделать вывод, что предварительная обработка данных — это не просто еще одно средство для достижения цели при построении моделей машинного обучения для торговли. Скорее, предварительная обработка сама по себе является отдельной стратегией. Выбор метода преобразования незаметно влияет на эффективность наших моделей машинного обучения — он формирует прибыль, искажает убытки и непреднамеренно изменяет нашу подверженность риску способами, которые мы не можем понять напрямую.
Классическое статистическое обучение практически не дает никаких рекомендаций в этом направлении. Не существует универсальных, общепринятых стандартов, кроме метода перебора с использованием перекрестной проверки для разбиений. Это означает, что необходимо уделить время сравнительному анализу конвейеров предварительной обработки и рассматривать их как то, чем они являются на самом деле: параметры настройки, оказывающие значительное влияние на эффективность нашего конвейера машинного обучения.
Это также должно стимулировать других исследователей и авторов статей к изучению всё большего числа преобразований, которые можно применять в нашей области. Поскольку в таких областях, как распознавание изображений и распознавание речи, специалисты по машинному обучению зачастую используют надежные и обширные цепочки преобразований еще до того, как предпринимается попытка прогнозирования. И тем не менее в таких областях, как наша — в сфере финансового машинного обучения — мы зачастую уделяем очень мало времени созданию надёжных конвейеров преобразований на этапе предварительной обработки.
В сложившихся условиях тестирование методом перебора является разумной стратегией. Чем больше мы изучаем, тем лучше понимаем особенности каждого преобразования, которое мы применяем к данному рынку. Это помогает нам определить, какое преобразование из всех наблюдаемых нами может быть наиболее подходящим.
Анализ текущего базового уровня
Прежде чем приступить к работе, важно сначала ознакомиться с настройками управления, которые мы хотим превзойти. Любую оптимизацию сложно оценить без эталонного показателя или базового уровня производительности, с которым можно было бы сравнить результаты. Поэтому для начала мы кратко рассмотрим реализованный нами базовый регулятор с обратной связью. Постоянным читателям следующий код уже будет знаком. Для тех, кто читает эту статью впервые, я кратко изложу основные выводы, сделанные на основе созданного нами приложения и нашего предыдущего обсуждения.
Приложение опирается на небольшой набор системных определений, которые мы сохраняем неизменными на протяжении всего срока его работы. Например, период, за который рассчитываются используемые технические индикаторы, количество торговых дней, данные за которые учитываются до того, как регулятор с обратной связью получает право подавать входной сигнал, а также общее количество признаков, которые регулятор принимает в качестве входных данных. В данном случае контроллер с обратной связью принимает 12 входных признаков. Важно отметить, что в предыдущем примере мы не применяли никаких преобразований, стандартизаций или методов масштабирования ни к одному из 12 входных значений.
В процессе работы приложение также использует ряд глобальных переменных и библиотек, таких как торговая библиотека для открытия и закрытия сделок, библиотека времени для отслеживания формирования свечей, а также библиотека trade-info, содержащая такие сведения, как минимальный размер лота и текущие цены спроса и предложения.
При первом запуске приложение создает новые экземпляры пользовательских библиотек, настраивает технические индикаторы и инициализирует большинство глобальных переменных значениями по умолчанию. Когда приложение больше не используется, динамические объекты и технические индикаторы освобождаются.
При вызове функции on-tick система сначала проверяет, сформировалась ли новая свеча. В этом случае буферы скользящих средних обновляются с учетом последней цены закрытия. Если открытых позиций нет, то применяется следующая торговая логика: канал скользящих средних, образованный верхней и нижней скользящими средними с одинаковым периодом. Каждый раз, когда уровень цен пробивает верхнюю границу канала, мы открываем позицию на покупку. Напротив, при пробое уровня вниз мы открываем короткие позиции. В противном случае мы будем ждать.
В течение первых 90 дней система может осуществлять покупки и продажи практически сразу. Однако по истечении этого периода для выполнения операций требуется прогноз от регулятора обратной связи. Если контроллер уверен, что сделка будет прибыльной, разрешение выдается; в противном случае он приостанавливает работу системы.
В этом и заключается суть регулятора с обратной связью: он выжидает первые 90 дней, прежде чем подавать сигнал в систему. Далее мы определяем метод take_snapshots для периодического сбора данных о производительности системы, а также метод fit_snapshots для поиска линейных решений, опирающихся на эти данные. После получения решений система может приступать к прогнозированию.
Это базовая версия нашей торговой стратегии.
//+------------------------------------------------------------------+ //| Closed Loop Feedback.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" /** Closed Loop Feedback Control allows us to learn how to control our system's dynamics. It is challenging to perform in action, but worth every effort made towards it. Certain tasks, such as deciding when to increase your lot size, are not always easy to plan explicitly. We can rather observe our average loss size after say, 20 trades at minimum lot. From there, we can calculate how much on average, we expect to lose on any trade. And then set meaningful profit targets to accumulate, before increasing out lot size. We do not always know these numbers ahead of time. Additionally, we can train predictive models, that attempt to learn when our system is loosing and keep us out of loosing trades. The models we desire are not directly predicting the market per say. Rather, they are observing the relationship between a fixed strategy and a dynamic market. After allowing a certain number of observations, the predictive model may be permitted to give inputs that override the original strategy only if the model expects the strategy to lose, yet again. These family of algorithms may one day make it possible for us to truly design strategies that require no tuning parameters at all! I am excited to present this to you, but there is a long road ahead. Let us begin. **/ //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define MA_PERIOD 10 #define OBSERVATIONS 90 #define FEATURES 12 #define ACCOUNT_STATES 3 //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_h_handler,ma_l_handler,atr_handler,scenes,b_matrix_scenes; double ma_h[],ma_l[],atr[]; matrix snapshots,OB_SIGMA,OB_VT,OB_U,b_vector,b_matrix; vector S,prediction; vector account_state; bool predict,permission; //+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; Time *DailyTimeHandler; TradeInfo *TradeInfoHandler; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- DailyTimeHandler = new Time(Symbol(),PERIOD_D1); TradeInfoHandler = new TradeInfo(Symbol(),PERIOD_D1); ma_h_handler = iMA(Symbol(),PERIOD_D1,MA_PERIOD,0,MODE_EMA,PRICE_HIGH); ma_l_handler = iMA(Symbol(),PERIOD_D1,MA_PERIOD,0,MODE_EMA,PRICE_LOW); atr_handler = iATR(Symbol(),PERIOD_D1,14); snapshots = matrix::Ones(FEATURES,OBSERVATIONS); scenes = 0; b_matrix_scenes = 0; account_state = vector::Zeros(3); b_matrix = matrix::Zeros(1,1); prediction = vector::Zeros(2); predict = false; permission = true; //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete DailyTimeHandler; delete TradeInfoHandler; IndicatorRelease(ma_h_handler); IndicatorRelease(ma_l_handler); IndicatorRelease(atr_handler); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(DailyTimeHandler.NewCandle()) { CopyBuffer(ma_h_handler,0,0,1,ma_h); CopyBuffer(ma_l_handler,0,0,1,ma_l); CopyBuffer(atr_handler,0,0,1,atr); double c = iClose(Symbol(),PERIOD_D1,0); if(PositionsTotal() == 0) { account_state = vector::Zeros(ACCOUNT_STATES); if(c > ma_h[0]) { if(!predict) { if(permission) Trade.Buy(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetAsk(),(TradeInfoHandler.GetBid()-(atr[0]*2)),(TradeInfoHandler.GetBid()+(atr[0]*2)),""); } account_state[0] = 1; } else if(c < ma_l[0]) { if(!predict) { if(permission) Trade.Sell(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetBid(),(TradeInfoHandler.GetAsk()+(atr[0]*2)),(TradeInfoHandler.GetAsk()-(atr[0]*2)),""); } account_state[1] = 1; } else { account_state[2] = 1; } } if(scenes < OBSERVATIONS) { take_snapshots(); } else { matrix temp; temp.Assign(snapshots); snapshots = matrix::Ones(FEATURES,scenes+1); //--- The first row is the intercept and must be full of ones for(int i=0;i<FEATURES;i++) snapshots.Row(temp.Row(i),i); take_snapshots(); fit_snapshots(); predict = true; permission = false; } scenes++; } } //+------------------------------------------------------------------+ //| Record the current state of our system | //+------------------------------------------------------------------+ void take_snapshots(void) { snapshots[1,scenes] = iOpen(Symbol(),PERIOD_D1,1); snapshots[2,scenes] = iHigh(Symbol(),PERIOD_D1,1); snapshots[3,scenes] = iLow(Symbol(),PERIOD_D1,1); snapshots[4,scenes] = iClose(Symbol(),PERIOD_D1,1); snapshots[5,scenes] = AccountInfoDouble(ACCOUNT_BALANCE); snapshots[6,scenes] = AccountInfoDouble(ACCOUNT_EQUITY); snapshots[7,scenes] = ma_h[0]; snapshots[8,scenes] = ma_l[0]; snapshots[9,scenes] = account_state[0]; snapshots[10,scenes] = account_state[1]; snapshots[11,scenes] = account_state[2]; } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Fit our linear model to our collected snapshots | //+------------------------------------------------------------------+ void fit_snapshots(void) { matrix X,y; X.Reshape(FEATURES,scenes); y.Reshape(FEATURES-1,scenes); for(int i=0;i<scenes;i++) { X[0,i] = snapshots[0,i]; X[1,i] = snapshots[1,i]; X[2,i] = snapshots[2,i]; X[3,i] = snapshots[3,i]; X[4,i] = snapshots[4,i]; X[5,i] = snapshots[5,i]; X[6,i] = snapshots[6,i]; X[7,i] = snapshots[7,i]; X[8,i] = snapshots[8,i]; X[9,i] = snapshots[9,i]; X[10,i] = snapshots[10,i]; X[11,i] = snapshots[11,i]; y[0,i] = snapshots[1,i+1]; y[1,i] = snapshots[2,i+1]; y[2,i] = snapshots[3,i+1]; y[3,i] = snapshots[4,i+1]; y[4,i] = snapshots[5,i+1]; y[5,i] = snapshots[6,i+1]; y[6,i] = snapshots[7,i+1]; y[7,i] = snapshots[8,i+1]; y[8,i] = snapshots[9,i+1]; y[9,i] = snapshots[10,i+1]; y[10,i] = snapshots[11,i+1]; } //--- Find optimal solutions b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); Print(y.Col(scenes-1)); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); if(prediction[4] > AccountInfoDouble(ACCOUNT_BALANCE)) permission = true; else if((account_state[0] == 1) && (prediction[6] > ma_h[0])) permission = true; else if((account_state[1] == 1) && (prediction[7] < ma_l[0])) permission = true; else permission = false; if(permission) { if(PositionsTotal() == 0) { if(account_state[0] == 1) Trade.Buy(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetAsk(),(TradeInfoHandler.GetBid()-(atr[0]*2)),(TradeInfoHandler.GetBid()+(atr[0]*2)),""); else if(account_state[1] == 1) Trade.Sell(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetBid(),(TradeInfoHandler.GetAsk()+(atr[0]*2)),(TradeInfoHandler.GetAsk()-(atr[0]*2)),""); } } Print("Current Balabnce: ",AccountInfoDouble(ACCOUNT_BALANCE)," Predicted Balance: ",prediction[4]," Permission: ",permission); } //+------------------------------------------------------------------+
Даты проведения тестирования нашего приложения — ещё один важный параметр, который должен оставаться неизменным во всех проводимых нами тестах. В ходе предыдущего обсуждения мы провели бэктестинг нашей стратегии с 1 января 2020 года до 2025 года. Поэтому мы будем использовать эти даты во всех тестах.

Рисунок 3: Даты тестирования, которые мы использовали в начальной части обсуждения регуляторов с обратной связью
Ниже приведен скриншот, на котором показаны предыдущие уровни производительности, установленные регулятором с обратной связью. В начале нашего обсуждения мы привели этот скриншот, чтобы читатель мог сравнить его с показателями производительности, которых мы стремимся достичь сегодня.
В введении к статье мы уже дали исчерпывающий обзор основных различий между показателями, достигнутыми ранее, и показателями, к которым мы стремимся сейчас. Скриншот приведён для того, чтобы читатель мог самостоятельно интерпретировать результаты.
Рисунок 4: Подробный анализ показателей эффективности, полученных в ходе 5-летнего бэктеста нашего бенчмарка
Представленная ниже кривая капитала продемонстрировала многообещающий потенциал в ходе нашего вступительного обсуждения. Однако, как читатель сможет убедиться, один из представленных сегодня примеров позволил ускорить рост с гораздо большей рентабельностью, чем это удавалось в прошлом.
Рисунок 5: Кривая капитала, полученная нами с помощью первоначальной версии регулятора с обратной связью, уже соответствовала нашим требованиям
Z-показатель (стандартное статистическое преобразование)
Преобразование по Z-score — это стандартный статистический метод, который обычно считается хорошим первым шагом при работе с любым набором данных. Цель этого преобразования — привести признаки к сопоставимому масштабу, сохранив относительные различия между наблюдениями. Это гарантирует, что ваша модель сможет проводить значимые и последовательные сравнения показателей роста. Если не учитывать масштаб, модель может давать непропорциональные оценки роста в каждом столбце и его влияния на целевой показатель. Преобразование по Z-score решает эту проблему путем вычитания среднего значения (среднего значения каждого столбца) и последующего деления на стандартное отклонение. В результате среднее значение каждого столбца равно нулю, а стандартное отклонение — единице.
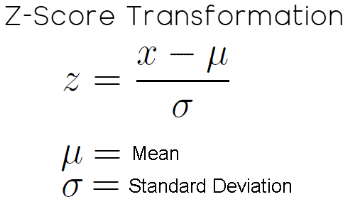
Рисунок 6: Математическая формула для преобразования статистического Z-показателя, которую мы применили к входным данным нашего регулятора с обратной связью
if(PositionsTotal() == 0) { //--- Find optimal solutions //--- Z-Score X = ((X - X.Mean())/X.Std()); b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); Print("Expected Balance at next candle: ",prediction[4],". Expected Balance after 10 candles: ",prediction[8]);
Как указано во введении к нашей статье, даты проведения тестов останутся неизменными для всех тестов. Как показано на рисунке 3 выше, мы будем использовать период с 1 января 2020 года по май 2025 года.
Рисунок 7: Указанные выше даты для бэктеста будут одинаковыми во всех тестах
Как уже упоминалось, преобразование по шкале Z не помогло повысить наши показатели в ходе пятилетнего тестирования. Фактически, это негативно сказалось на всех наших ключевых показателях эффективности.
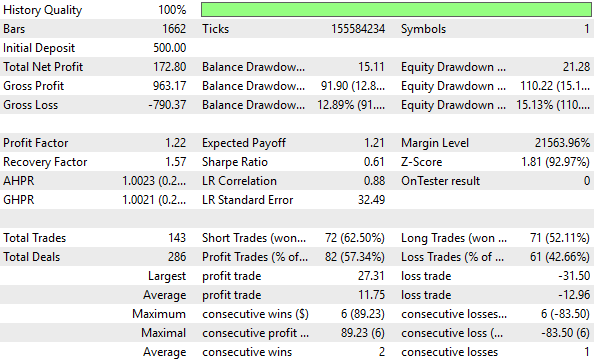
Рисунок 8: Подробный анализ показателей эффективности, полученных с помощью преобразования z-score, не выявил значительного улучшения
Наша контрольная модель, рассмотренная ранее, демонстрирует более высокую доходность по сравнению с кривой капитала, представленной ниже, благодаря примененному нами преобразованию. Таким образом, можно сделать вывод, что данное преобразование привело к утрате сигнала, присутствовавшего в исходных данных.
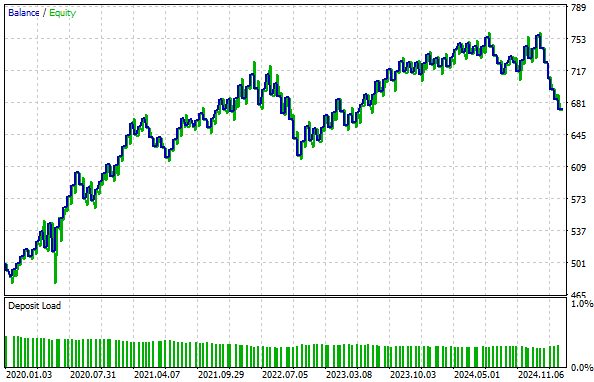
Рисунок 9: Кривая капитала, полученная в результате преобразования по z-показателю, не смогла подняться выше кривой капитала, полученной нами в контрольной конфигурации
Масштабирование единиц (стандартное преобразование линейной алгебры)
Идея масштабирования единиц заимствована из области линейной алгебры. Чтобы полностью понять эту концепцию, необходимо немного контекста, поскольку в нашем обсуждении мы применяем её не в стандартном смысле. Поэтому необходимо дать краткое введение для читателей, которые, возможно, сталкиваются с этой идеей впервые.
Когда у нас есть список чисел — представьте себе простой массив в MQL5, содержащий, скажем, 10 чисел, — существует множество способов оценить, насколько «большой» этот массив. В линейной алгебре эта величина называется нормой объекта. Этот объект может быть вектором или матрицей, но в этом простом примере мы рассмотрим только массив чисел. Далее я буду использовать термины «массив» и «вектор» как синонимы, поскольку они обозначают одно и то же понятие.
Существует множество способов определить размер массива:
- Мы могли бы определить это по количеству элементов, которые в нём сейчас находятся.
- Кроме того, мы могли бы оценить его по тому, сколько элементов он может вместить при максимальной загрузке.
- Чтобы окончательно донести эту мысль, мы могли бы также рассмотреть возможность измерить её, сложив все значения её текущих элементов.
Чтобы этого избежать, можно применить преобразования перед суммированием. Например, мы можем взять абсолютное значение каждого числа или возвести их в квадрат перед сложением. Эти различные подходы образуют семейство норм, известное как Lp-нормы.
Одной из важных норм этого семейства является норма L1, которая представляет собой просто сумму абсолютных значений всех элементов массива. Математически это показано на рисунке 10 ниже.
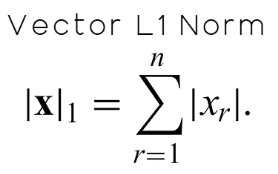
Рисунок 10: Определим L1-норму вектора как абсолютную сумму всех его элементов.
После вычисления нормы L1 мы можем разделить каждое значение в массиве на эту норму. В линейной алгебре этот процесс называется нормированием, и в результате получается нормированный вектор, новая норма которого равна 1. Это означает, что если снова взять норму вектора, результат будет равен ровно единице.
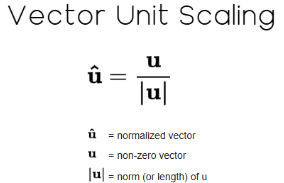
Рисунок 11: Масштабирование вектора с постоянным коэффициентом — это стандартное преобразование в линейной алгебре.
В случае векторов это довольно просто. Однако наш случай немного отличается, поскольку мы имеем дело с матрицей, а не просто с вектором. Напомним, что, как мы уже отмечали в начале нашего обсуждения, матрица данных X содержит 12 признаков. В данном случае нам необходимо использовать L1-норму матрицы, которая отличается от L1-нормы вектора, хотя эти два понятия и связаны между собой.
Согласно действующей на момент написания статьи документации MQL5, норма L1 матрицы определяется следующим образом: «MATRIX_NORM_P1 — это максимальная p1-норма вектора среди горизонтальных векторов матрицы».
Хотя это определение и является точным, поначалу оно может показаться не очень интуитивным, особенно тем читателям, кто сталкивается с этой темой впервые. Поэтому я могу перефразировать документацию для читателя, превратив её в более практические инструкции, которые начинаются с вычисления нормы L1 для каждой строки матрицы. Затем определите строку с наибольшей нормой L1. Тогда это наибольшее значение становится L1-нормой матрицы. Это понятие определено в документации MQL5, а математически оно описывается с помощью нотации, представленной на рисунке 12 ниже:
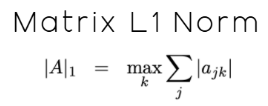
Рисунок 12: L1-норма матрицы отличается от L1-нормы вектора, хотя эти два понятия связаны между собой
После вычисления нормы L1 мы, наконец, делим каждый столбец в наборе данных на это значение, тем самым применяя к данным вариант масштабирования до единицы.
if(PositionsTotal() == 0) { //--- Find optimal solutions //--- We Must Take The Additional Steps Needed To Standardize & Scale Our Inputs X = X/X.Norm(MATRIX_NORM_P1); b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); Print("Expected Balance at next candle: ",prediction[4],". Expected Balance after 10 candles: ",prediction[8]);
Как мы уже отмечали ранее, мы будем использовать одинаковый период для всех тестов, чтобы обеспечить объективное сравнение.
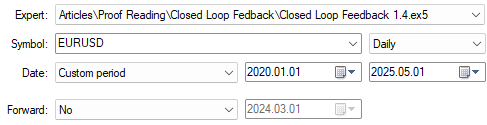
Рисунок 13: Количество дней, использованных для бэктестинга в наших тестах, оставалось неизменным во всех примерах
Как читателю уже известно, изменение масштабирования блоков существенно повысило наши показатели производительности по сравнению с эталонными значениями, выведя их на новый уровень, которого мы ранее не достигали. Это преобразование явно позволило выявить в данных больше полезной информации, что помогло нашей модели обнаружить более значимые закономерности. Не каждое преобразование будет проходить именно так, но когда это происходит, оно приводит к ощутимому улучшению — а ощутимое улучшение — это единственное улучшение, которое действительно имеет значение.
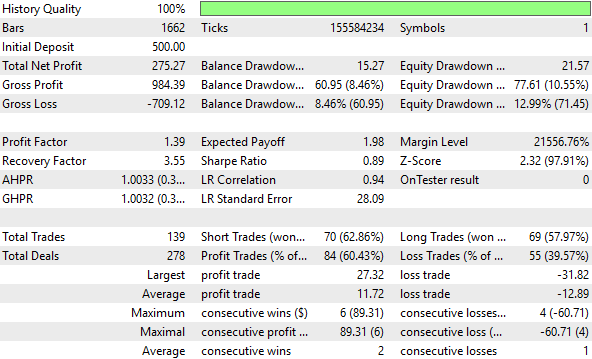
Рисунок 14: Подробный анализ показателей эффективности, достигнутых нашим усовершенствованным регулятором с обратной связью
Если проанализировать полученную кривую капитала, то можно заметить, что наша прибыльность теперь достигает максимумов в 800 — уровней, которых нам не удавалось достичь в предыдущей стратегии. Кроме того, как уже упоминалось во введении, время, необходимое для роста счёта с 500 до 700, сократилось почти на треть — это значительное ускорение темпов роста.
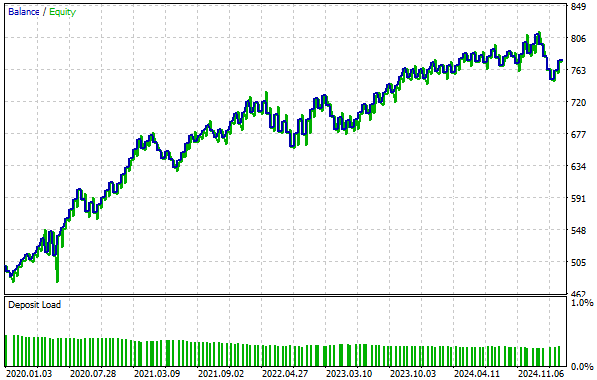
Рисунок 15: Новая кривая капитала, которую мы построили, растёт даже быстрее, чем старый регулятор с обратной связью, с которого мы начинали
Гибридный подход (масштабирование единиц& по Z-баллу)
На данном этапе статьи, как мы уже отмечали во введении, формализованных правил преобразований не существует. В этой области использование метода перебора вполне оправдано, поскольку, кроме как пробовать различные варианты и анализировать их эффективность, мы практически ничего другого сделать не можем. Исходя из этого предположения, мы попытались объединить два преобразования, надеясь добиться ещё более впечатляющего результата.
if(PositionsTotal() == 0) { //--- Find optimal solutions //--- We Must Take The Additional Steps Needed To Standardize & Scale Our Inputs X = X/X.Norm(MATRIX_NORM_P1); X = ((X-X.Mean())/X.Std()); b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); Print("Expected Balance at next candle: ",prediction[4],". Expected Balance after 10 candles: ",prediction[8]);
К сожалению, этот гибридный подход оказался в целом нерентабельным. Хотя поначалу это выглядело многообещающе, совокупность этих изменений негативно отразилась на всех наших ключевых показателях эффективности.
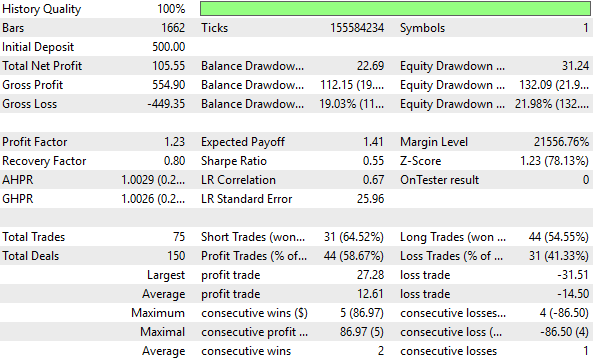
Рисунок 16: Наш гибридный подход показал самые низкие показатели эффективности из всех, которые мы наблюдали в ходе этого теста
Хотя общая доля прибыльных сделок в гибридной модели немного выросла — с 57,24 % до 58,67 % — это не является существенным улучшением. Кроме того, кривая капитала, построенная на основе гибридной стратегии, застряла в диапазоне от 500 до 600, не позволяя с течением времени увеличить капитал счета. Таким образом, можно сделать вывод, что данное преобразование привело к искажению сигнала в наших входных данных и больше не позволяет нашей модели выявить значимые взаимосвязи.
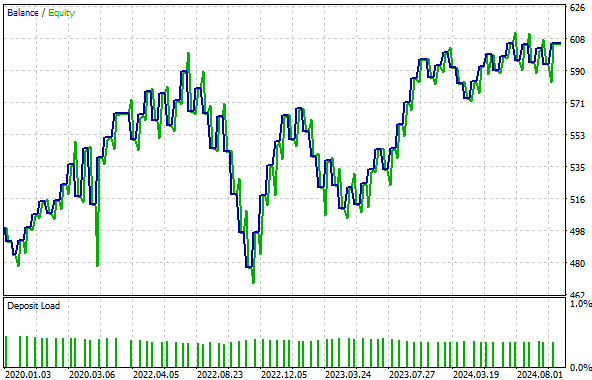
Рисунок 17: Полученная нами кривая капитала больше не растёт, а, напротив, кажется, застряла в убыточном режиме
Заключение
После этого обсуждения читатель должен обрести новое понимание процессов предварительной обработки, которые мы применяем к данным, поступающим в наши модели машинного обучения. Надеюсь, теперь читатель будет рассматривать этот этап конвейера машинного обучения как чрезвычайно важный параметр настройки, который следует использовать с особой тщательностью и настойчивостью, чтобы действительно извлечь из него пользу.
Существует множество преобразований, которые можно применить к тому или иному набору данных, и, к сожалению, мы часто не знаем, какое из них будет оптимальным, да и не всегда можем определить, приносит ли конкретное преобразование пользу. Однако, используя контрольный уровень производительности и последовательно проверяя относительно него новые идеи, мы можем выявить структуры и закономерности, которые, возможно, были скрыты в исходных данных.
Поэтому читателю также важно знакомиться с как можно большим числом преобразований, тестировать разные подходы и выявлять те, что действительно улучшают результат.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/19382
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования