
Нейронные сети на практике: Практика ведет к совершенству

Введение
Здравствуйте и добро пожаловать в очередную статью о нейронных сетях.
В предыдущей статье, Нейронные сети на практике: Первый нейрон, мы создали наш первый нейрон. Однако в программировании не всё так просто. Многие просто создают, или, скорее, копируют какой-то код и начинают его использовать. Это определенно не является проблемой, ни в коем случае, в этом нет ничего плохого, даже наоборот. Это довольно разумная практика, при условии, конечно, что мы изучим код и попытаемся улучшить его, чтобы он соответствовал нашим потребностям. Неправильным является использование чего-либо без понимания того, как это работает. Или, что ещё хуже, пожаловаться на что-нибудь, или начать рассказывать о том, что мы совершенно не знаем.
Несмотря на свою работоспособность, тот код, который мы рассматривали в предыдущей статье, ни при каких обстоятельствах не следует использовать в более сложных приложениях. Это необходимо для того, чтобы всё делалось своевременно или, по крайней мере, в рамках определенных ожиданий относительно результатов.
Чтобы вы, уважаемые читатели, поняли, о чём я говорю, давайте посмотрим, как обстоят дела и какие проблемы могут возникнуть, если мы внесем немного изменений. Но чтобы было понятнее, давайте рассмотрим это в рамках новой темы.
Делаем время выполнения нецелесообразным.
Отлично, наш простой и уникальный нейрон можно увидеть в следующем коде.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) 06. //+------------------------------------------------------------------+ 07. double Train[][3] { 08. {0, 0, 0}, 09. {0, 1, 0}, 10. {1, 0, 0}, 11. {1, 1, 1}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 3; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w0, const double w1, const double b) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double w0, w1, err, ew0, ew1, eb, bias; 31. ulong count, it0, it1; 32. 33. Print("The Neuron - Tutor ..."); 34. MathSrand(512); 35. w0 = (double)macroRandom; 36. w1 = (double)macroRandom; 37. bias = (double)macroRandom; 38. 39. it0 = GetTickCount(); 40. 41. for (count = 0; (count < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); count++) 42. { 43. ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; 44. ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; 45. eb = (Cost(w0, w1, bias + eps) - err) / eps; 46. w0 -= (ew0 * eps); 47. w1 -= (ew1 * eps); 48. bias -= (eb * eps); 49. } 50. 51. it1 = GetTickCount(); 52. Print("Time: ", (it1 - it0) / 1000.0, " seconds."); 53. PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", count, w0, ew0, w1, ew1, bias, eb, err); 54. Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); 55. Print("Error Weight 0: ", ew0); 56. Print("Error Weight 1: ", ew1); 57. Print("Error Bias: ", eb); 58. Print("Error: ", err); 59. 60. Print("Testing the neuron..."); 61. for (uchar p0 = 0; p0 < 2; p0++) 62. for (uchar p1 = 0; p1 < 2; p1++) 63. PrintFormat("%d AND %d IS %f", p0, p1, macroSigmoid((p0 * w0) + (p1 * w1) + bias)); 64. 65. Print("************************************"); 66. } 67. //+------------------------------------------------------------------+
Мы внесли некоторые изменения в код по сравнению с тем, что было опубликовано в предыдущей статье. А причина довольно проста. Мы хотим показать, как простое изменение может заметно повлиять на общее время выполнения, а также на ожидаемые результаты. При выполнении приведенного выше кода в MetaTrader 5 будет сгенерировано нечто очень похожее на это:
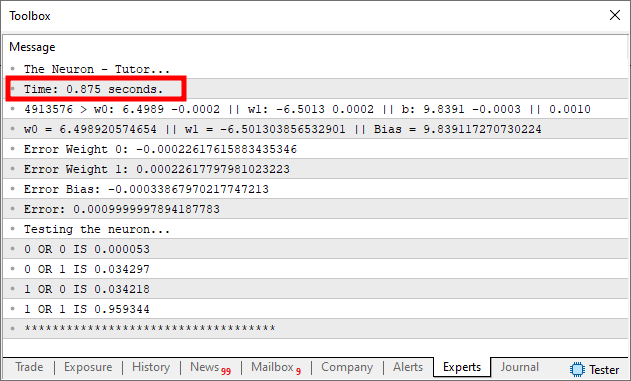
Обратите внимание на некоторые данные, представленные на изображении выше. Самый очевидный из них, который мы и хотим выделить, — это, конечно же, время выполнения кода. Это время учитывает только тот факт, что мы проводим подгонку параметров. Это можно увидеть, взглянув на код. Обратите внимание, что в строке 39 мы фиксируем точный момент времени непосредственно перед началом подгонки обучающих данных нейрона. А в строке 51 мы снова запечатлели тот самый момент, когда обучение закончилось. Разница между этими двумя значениями дает нам время выполнения обучения. Прошу заметить, что в строке 52 мы выполняем небольшое вычисление. Поскольку зафиксированное время измеряется в миллисекундах, разделив разницу значений между моментами времени на тысячу, мы получим приблизительное значение времени в секундах. Именно данный период времени и выделен на изображении выше.
Теперь давайте посмотрим, что мы сделаем. В строке 15 того же кода, мы задаем ошибку как 0,001. А что произойдет с точки зрения времени выполнения данного же кода, если мы изменим ошибку на 0,0001 или 1e-4?
Хорошо, попробуйте это на своем компьютере, чтобы посмотреть, что получится. В любом случае, вы получите нечто очень похожее на это:
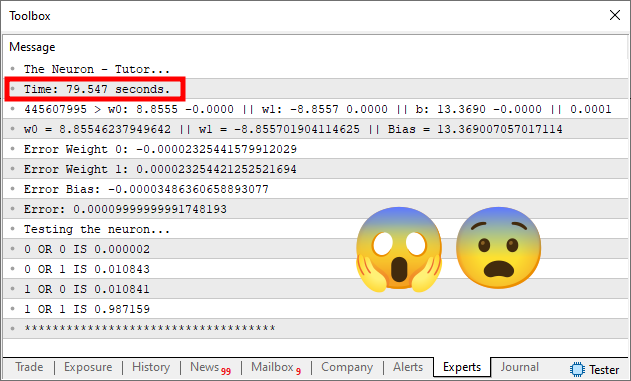
Теперь обратите внимание: Простая замена ошибки с 1e-3 на 1e-4 позволяет сократить время выполнения с менее 1 секунды до почти 80 секунд. Совершенно верно, всё именно так, как вы это видите. Простое изменение точности всего в 10 раз привело к увеличению времени выполнения более чем в 80 раз.
Именно подобные моменты в конечном итоге разрушают мечты многих новичков, но в основном тех, кто понятия не имеет, что программирование — это отнюдь не самая простая задача. Когда мы говорим, что каждая программа часто предназначена для выполнения конкретной задачи, многие люди удивляются, тем более когда кто-то говорит, что нейронная сеть может делать что угодно очень быстро, хотя на самом деле это не совсем так.
Хочу обратить ваше внимание на этот факт, уважаемые читатели. Прежде чем перейти к вопросу добавления новых нейронов в сеть, крайне важно понимать, как будет построена сеть и для каких целей. Чтобы это продемонстрировать, мы возьмём тот же самый простой нейрон и заменим его на нечто немного другое, но предназначенное для решения той же проблемы, что и в коде. Иными словами, мы собираемся сделать из этого нейрона специалиста в той области, в которой он должен работать, не с точки зрения подгонки, а с точки зрения количества входов. Чтобы разграничить эти темы, рассмотрим это в отдельном разделе.
Корректировка кода для достижения лучших результатов
Итак, давайте подумаем о следующем: какой смысл в том, чтобы одному нейрону потребовалось в 80 раз больше времени для повышения точности всего лишь в 10 раз? Подобные моменты не имеют никакого смысла. Однако, если нам заранее известно, что нейрон на протяжении всей жизни будет работать с двумя входами и одним выходом, мы можем улучшить его код. Это ускорит процесс, и нейрон сможет учиться более эффективно.
Внесение этих изменений может показаться очень сложным, и только человек, обладающий обширными знаниями, сможет осуществить такой подвиг. Однако это не совсем так. Всё, что нужно понять, уважаемые читатели, это как работает программа и какова её цель. Если вы это знаете и понимаете, как программа была написана на конкретном языке, то вы сможете (хотя это и может занять некоторое время) реализовать гораздо лучшее решение.
Чтобы это продемонстрировать, мы изменим код из предыдущей темы, но при этом сохраним исходный код. Наша цель — понять, движемся ли мы в правильном направлении или нет. Хороший программист никогда не пытается изменить неизвестный код. Сначала он постарается понять код, разобраться в его работе, а затем попробует внести в него некоторые улучшения. Исходя из этих соображений, новый код представлен ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) 06. //+------------------------------------------------------------------+ 07. #define def_Fast 08. //+------------------------------------------------------------------+ 09. double Train[][3] { 10. {0, 0, 0}, 11. {0, 1, 0}, 12. {1, 0, 0}, 13. {1, 1, 1}, 14. }; 15. //+------------------------------------------------------------------+ 16. const uint nTrain = Train.Size() / 3; 17. const double eps = 1e-4; 18. //+------------------------------------------------------------------+ 19. double Cost(const double w0, const double w1, const double b) 20. { 21. double err; 22. 23. err = 0; 24. for (uint c = 0; c < nTrain; c++) 25. err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 26. 27. return err / nTrain; 28. } 29. //+------------------------------------------------------------------+ 30. double Cost_2(double &w0, double &w1, double &b) 31. { 32. double err, ew0, ew1, eb; 33. 34. err = ew0 = ew1 = eb = 0; 35. for (uint c = 0; c < nTrain; c++) 36. { 37. err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 38. ew0 += MathPow((macroSigmoid((Train[c][0] * (w0 + eps)) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 39. ew1 += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * (w1 + eps)) + b) - Train[c][2]), 2); 40. eb += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + (b + eps)) - Train[c][2]), 2); 41. } 42. 43. w0 -= (((ew0 - err)/ eps) * eps); 44. w1 -= (((ew1 - err)/ eps) * eps); 45. b -= (((eb - err)/ eps) * eps); 46. 47. return err / nTrain; 48. } 49. //+------------------------------------------------------------------+ 50. void OnStart() 51. { 52. double w0, w1, err, ew0, ew1, eb, bias; 53. ulong count, it0, it1; 54. 55. Print("The Neuron - Tutor..."); 56. MathSrand(512); 57. w0 = (double)macroRandom; 58. w1 = (double)macroRandom; 59. bias = (double)macroRandom; 60. 61. it0 = GetTickCount(); 62. #ifdef def_Fast 63. for (count = 0; (count < ULONG_MAX) && ((err = Cost_2(w0, w1, bias)) > eps); count++); 64. #else 65. for (count = 0; (count < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); count++) 66. { 67. ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; 68. ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; 69. eb = (Cost(w0, w1, bias + eps) - err) / eps; 70. w0 -= (ew0 * eps); 71. w1 -= (ew1 * eps); 72. bias -= (eb * eps); 73. } 74. #endif 75. it1 = GetTickCount(); 76. Print("Time: ", (it1 - it0) / 1000.0, " seconds."); 77. PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", count, w0, ew0, w1, ew1, bias, eb, err); 78. Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); 79. Print("Error Weight 0: ", ew0); 80. Print("Error Weight 1: ", ew1); 81. Print("Error Bias: ", eb); 82. Print("Error: ", err); 83. 84. Print("Testing the neuron..."); 85. for (uchar p0 = 0; p0 < 2; p0++) 86. for (uchar p1 = 0; p1 < 2; p1++) 87. PrintFormat("%d AND %d IS %f", p0, p1, macroSigmoid((p0 * w0) + (p1 * w1) + bias)); 88. 89. Print("************************************"); 90. } 91. //+------------------------------------------------------------------+
Не беспокойтесь о написании данного кода. При желании можно сделать это, чтобы лучше понять, как программировать на MQL5, поскольку, когда мы пишем код, мы лучше понимаем, как он создается. Кроме того, мы также проработали различные другие вопросы, связанные с синтаксисом нашего языка программирования. Но можно получить к нему доступ в приложении. Так что от вас зависит, как вы будете использовать эти знания.
Давайте теперь посмотрим, что мы получим с точки зрения времени выполнения. Это можно увидеть на изображении ниже.
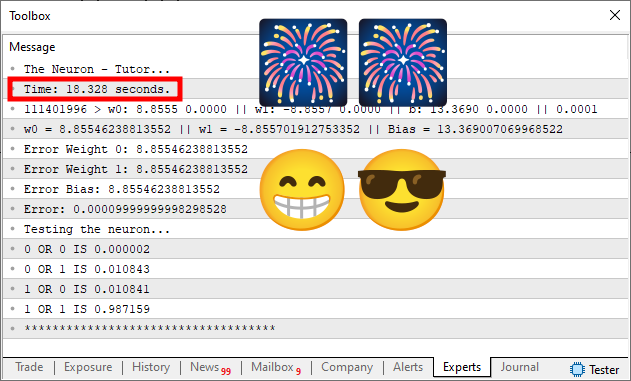
"Что? Но как это стало возможным? Как время сократилось с почти 80 секунд до чуть более 18 секунд? Это совершенно невозможно. Ах, я знаю, вы сменили компьютер, вы использовали для этого другой, более совершенный. Или, что почти наверняка, вы каким-то образом схитрили, внеся в систему другую ошибку или изменив что-то ещё. Таким образом, первое выполнение займет больше времени, как видно на первом изображении, но тогда вы бы потратили гораздо меньше времени, используя какой-нибудь трюк. Таким образом, вы получите изображение, которое можно увидеть на втором рисунке".
Что ж, уважаемые читатели. Возможно, мы могли бы сделать и это. Но нет, именно поэтому мы оставили код в приложении. Таким образом, попробовав тот же код на своем компьютере, вы сможете понять, что произошло. Но прежде чем сделать это, давайте сначала разберем, почему код, который раньше выполнялся почти 80 секунд, теперь отрабатывает чуть более чем за 18 секунд. Сначала я скажу, что здесь нет никакой магии или чего-то подобного. Речь идёт о понимании того, чему должен научиться нейрон.
Если посмотреть на код, может показаться, что он очень сложный, тем более, если вы только начинаете заниматься программированием. Однако не волнуйтесь, это довольно просто. Я позаботился о том, чтобы всё так и оставалось. Это делает объяснение принципа работы более наглядным и практичным.
Начнём со строки 07. В ней содержится определение, и это один из немногих моментов, где вам, как новичкам, придётся изменять код, без риска сделать его нестабильным. Если удалить строку 07, код останется точно таким же, как и в предыдущем разделе. Иными словами, медленный и неуклюжий, но при этом универсальный. Однако, если строка 07 выглядит так, как представлено здесь в статье, будет использоваться быстрая версия кода, и вы увидите результат, показанный на изображении выше.
Теперь я хочу, чтобы вы сравнили изображение из этой темы с изображениями из предыдущей, но обращая внимание на величину ошибки. Прошу заметить, насколько они похожи. Особенно последнее изображение из предыдущей темы и то, что было показано в ней. То есть в обоих случаях мы используем ошибку 1e-4. "Подождите минутку. Вы хотите сказать, что, несмотря на использование одинаковой точности, время выполнения резко сократилось?" Да, такое возможно, уважаемые читатели. Именно это и произошло. "Но почему это произошло? Не могли бы вы мне рассказать?"
Хорошо, чтобы это понять, необходимо взглянуть на некоторые моменты в коде. Давайте пропустим большую часть кода и перейдем к процедуре OnStart, которая находится в строке 50. Сейчас нам нужно немного терпения, но понять, что происходит, совсем несложно. Прошу заметить, что большая часть кода в этой процедуре уже была рассмотрена в предыдущем разделе. Именно эти равные части делают нейрон идентичным тому, который мы видели раньше. Однако именно в строке 62 мы просим компилятор выполнить проверку перед созданием окончательного исполняемого файла. Данный тест проверит, существует ли строка 07 или нет.
Если её нет, то создаваемый код будет идентичен тому, что рассматривался в предыдущей теме. Если существует строка 07, код из предыдущей темы будет заменен кодом, находящимся в строке 63. Обратите внимание на это. Мы заменяем код между строками 65 и 73 кодом из строки 63. Всё остальное останется неизменным и нетронутым.
Но теперь, взглянув на содержимое строки 63, заметно, что это цикл for. Это очень похоже на код в строке 65. Конечно, разница в том, что в строке 65 мы вызываем Cost, а в строке 63 — Cost_2. Во всём остальном код идентичен. "Но это не объясняет, почему в одном случае это занимает почти 80 секунд, а в другом — всего 18 секунд. Подобные вещи совершенно бессмысленны". Но именно здесь вы ошибаетесь, уважаемые читатели. Это простое изменение может иметь решающее значение. Прошу заметить, что, хотя мы смотрим только на строку 65, функция Cost фактически вызывается четыре раза: в строке 65, в строке 67, в строке 68 и в строке 69.
При каждом из этих вызовов необходимо анализировать всю таблицу, базу данных или, в нашем случае, обучающий массив. Задумайтесь об этом на мгновение. Обратите внимание, что наш обучающий массив содержит всего четыре строки данных. Это можно увидеть в строке 09 из кода. Всего четыре строки данных. Однако каждый раз, когда необходимо вызвать функцию Cost, расположенную в строке 19, цикл в строке 24 будет считывать и вычислять всё заново. Это относится ко всем вызовам, присутствующим в процедуре OnStart.
Такой способ программирования значительно упрощает задачу, но он, как правило, не очень эффективен. Однако, такой же способ программирования делает нейрон гораздо более универсальным. Это объясняется тем, что мы можем разместить столько входов или выходов, сколько необходимо. И всё это без необходимости вносить какие-либо изменения в код. Именно здесь знание того, что мы делаем, или знание ожидаемого или предполагаемого результата, имеет решающее значение. Многие взяли бы данную функцию из строки 19 и преобразовали бы её в код OpenCL. Или даже в код, который мог бы работать на параллельных системах. В некоторых случаях машины, на которых выполняются параллельные приложения, могут быть довольно дорогими.
В других случаях справится даже хорошая видеокарта. Тем не менее, мы бы просто заменили одну вещь другой, поскольку код всё равно остался бы неэффективным. И мы говорим это, потому что при каждом вызове для расчета стоимости нам пришлось бы просматривать всю базу данных, использованную для обучения. Представьте себе базу данных, содержащую тысячи мегабайт данных.
Теперь вернёмся к строке 63. Хотя в этом нет ничего необычного, здесь содержится вызов специализированной функции. Это значительно ускоряет выполнение по сравнению с неспециализированным выполнением. Однако наличие специализированного нейрона несколько усложняет программирование, поскольку, если нам нужно что-то изменить в нейроне (будь то количество входов или количество выходов), нам придется полностью изменить код функции Cost_2, которая вызывается реже, в строке 63. А причина кроется именно в её подходе к работе. Давайте посмотрим, как это работает, и перейдём к строке 30, где реализуется Cost_2. Но чтобы сделать объяснение более наглядным, давайте рассмотрим данную функцию в рамках новой темы.
Специализация одного нейрона
Итак, для тех, кто хочет изучить всё более спокойно и, по сути, понять, как это работает, давайте разделим функцию Cost_2 на две части. Так будет проще объяснить, почему он работает быстрее стандартной версии.
Хорошо, первая часть находится между строками 35 и 41. И что делает код в этих строках? Итак, он делает то же самое, что раньше делали строки 65, 67, 68 и 69. Кроме того, разумеется, выполняется то же самое, что и в цикле for в строке 24. Другими словами, в итоге мы выполняем строку 25. Однако, в отличие от того, что делалось раньше, теперь мы делаем всё одновременно. Таким образом, нам нужно больше переменных, чем было необходимо раньше. Каждая из переменных, объявленных в строке 32, служит для ускорения выполнения кода. Таким образом, в строке 37 мы вычисляем общую ошибку нейрона. Это не ускорит процесс, но в строках 38, 39 и 40 мы вычисляем все остальные ошибки, которые были ранее измерены в цикле for, расположенном в строке 65.
Теперь переходим к сложной части вопроса. Строка 40 является частью каждого нейрона. Другими словами, это универсальный код, как и строка 37. Но строки 38 и 39 этого не делают. Именно они специализируют нейроны. Иными словами, если нужно добавить больше входов к нейрону, нам придётся добавить больше таких строк в код, и нейрон, созданный для одной цели, скорее всего, не будет полезен ни для чего другого. Однако именно такой способ написания кода делает его намного быстрее, чем очень похожий, но плохо оптимизированный код для определенной цели.
Вторая часть кода находится на строках 43, 44 и 45. Там мы исправляем значения для следующего вызова функции стоимости. Ранее это было сделано на строках 70, 71 и 72.
Простое внесение этих небольших изменений в код позволило нейрону значительно ускорить работу, позволяя ему обучаться или, скорее, возвращать набор значений, которые давали возможность хранить базу предварительных знаний. И в этом-то и заключается настоящая прелесть такого вида программирования. Не ради самого вызова как испытания, а ради удовольствия от осознания того, что можно делать всё гораздо эффективнее. Прошу заметить, что даже не было необходимости использовать OpenCL или программировать с целью распараллеливания вычислений. Это куда увлекательнее и веселее всей той тоски, которую многие показывают, особенно когда речь заходит о нейросетях.
Хорошо, это был довольно простой пример того, как можно это делать, но мы можем пойти немного дальше в этом же вопросе. Хотя данный простой нейрон способен на многое, и его единственным ограничением является необходимость постоянно увеличивать или уменьшать количество входов, стремясь, конечно же, всегда делать это как можно быстрее, он всё же недостаточно «интеллектуален», чтобы справляться с определенными типами ситуаций. Поэтому искусственный интеллект или нейронные сети — это не такое простое дело, как многие считают. Аналогично, нельзя предполагать, что нейрон сможет справиться с любой ситуацией в рамках конкретного сценария.
Чтобы это проиллюстрировать, давайте проведём небольшое мысленное упражнение. Ничего сложного, я просто хочу показать вам то, что многие упускают из виду при изучении нейронных сетей. Об этом многие молчат или не хотят говорить, но если вы это поймёте, то осознаете: ни одна программа не сможет превзойти разум, который её создал.
Давайте рассмотрим данные, используемые для обучения. Бывают ситуации, когда нейрон не способен обработать данные. И дело не в том, что данные чрезвычайно сложны или что-то в этом роде, по сути, это простые данные. Но один нейрон не решает проблему, и я повторюсь, НЕ решает её, поэтому необходимо использовать для этого более одного нейрона. Итак, мы кратко изложим тему, которая будет обсуждаться позже. Однако в отдельных случаях допустимо моделировать небольшую нейронную сеть, используя один нейрон. Всё зависит от типа задачи, для которой мы ищем решение.
Таким образом, во многих случаях — и фактически в большинстве из них — нейрон можно построить или, лучше сказать, запрограммировать так, чтобы в будущем его можно было использовать для реализации нейронной сети. И я сейчас говорю не о нейросетях вроде чат-ботов или чем-то подобном, я говорю о чем-то гораздо более простом. Однако бывают случаи, когда мы можем заставить один нейрон решить задачу, для решения которой обычно требуется небольшая нейронная сеть. И нам не потребуется создавать BIG DATA с огромным объемом данных, чтобы найти ситуацию, в которой это происходит. Это можно сделать, используя тот же код, который показан в этой статье.
"Ого, теперь всё действительно сильно усложнилось. Почему? Посмотрим, правильно ли я вас понял. Вы хотите сказать, что этот нейрон, с которым мы работаем, не справится с чем-то, что можно представить в этой же базе данных, но если мы будем знать, как с ним обращаться, мы сможем заставить его имитировать небольшую нейронную сеть и таким образом решить задачу, которая ему в одиночку не под силу? Так ли это?" Да, всё верно. Прошу заметить, что используемая нами база данных напоминает таблицу логических гейтов. Иными словами, мы можем подавать в него комбинации нулей и единиц и просить нейрон попытаться найти уравнение или, точнее, линейную регрессию, которая могла бы представлять логический гейт.
Тем не менее, есть два случая, хотя мы можем рассматривать их как один. Это связано с тем, что они оба являются обратными друг другу. В этих случаях этот простой нейрон не сможет найти правильное уравнение, но если заставить его работать определённым образом, то удастся найти правильное уравнение.
Чтобы проще понять то, что я хочу объяснить, посмотрите на следующее изображение.
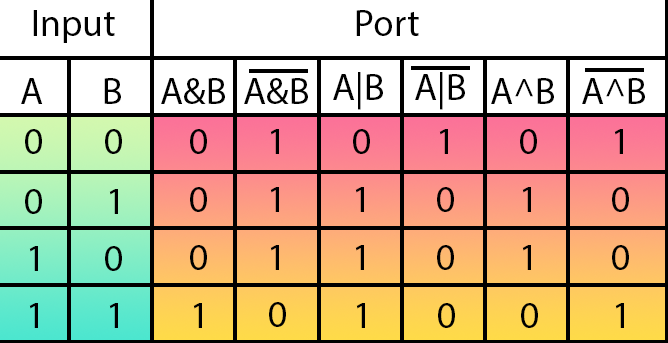
На этом изображении показаны все существующие логические гейты. В зелёной части находятся входы гейта. Выходы из каждого гейта выполнены в красных и оранжевых тонах. Тип логического гейта определяется в верхней части каждого логического гейта.
Что ж, давайте посмотрим, что это значит. Слева направо гейты расположены в следующем порядке: AND, NAND, OR, NOR, XOR и NXOR.
И какое значение для нас имеет эта таблица на изображении, если наша тема — нейронные сети? Чтобы это понять, давайте ещё раз взглянем на код нейрона. Обратите внимание, что в строке 09, где мы определяем правила обучения, мы имеем нечто в точности похожее на таблицу, показанную на изображении.
Теперь самое интересное: Первые два значения являются входными данными. Третье значение, с другой стороны, — это результат. Сравните то, что видите в коде, с таблицей, показанной на изображении. Что вы замечаете? Хорошо, если вы немного присмотритесь, то заметите, что в процессе обучения мы определяем гейт AND.
Можно поэкспериментировать, изменив значения третьего аргумента, используемого при обучении. И вы увидите, что сможете заставить нейрон обучиться или сгенерировать уравнение, способное представить почти все гейты. Я говорю "почти", потому что нейрон не сможет выучить даже два из них. Эти гейты - как раз XOR и его инверсия, то есть NXOR.
"Ух ты! Но подождите-ка. Почему нейрон не сможет научиться генерировать гейты XOR и NXOR? Вы что, шутите? Все значения состоят исключительно из нулей и единиц. Это может быть только шутка или розыгрыш. Вы надо мной издеваетесь".
Мне бы даже хотелось пошутить, подколоть вас, но на самом деле это не так. Это факт, и вы можете его проверить. Если попытаться обучить один нейрон, используя только нули и единицы, то в некоторых случаях нейрон не сможет научиться справляться с ситуацией. Это объясняется тем, что решение намного сложнее, чем может быть смоделировано с помощью одного нейрона.
Вряд ли вы когда-нибудь услышите, чтобы кто-то говорил о подобных вещах или даже упоминал их. Это происходит, когда тема, которую мы изучаем, так или иначе связана с искусственным интеллектом, нейросетями или программированием нейронов. Люди не задумываются о том, чтобы попробовать все альтернативные варианты. Если это срабатывает в конкретном случае, они немедленно начинают распространять информацию об этом. Но если расспрашивать их о конкретных ситуациях, они начинают ходить вокруг да около или игнорируют вопрос.
Однако существует способ заставить нейрон научиться справляться с подобными ситуациями, например, когда нам нужно решить задачу гейта XOR или его обратного гейта NXOR. Поскольку эту тему довольно сложно объяснить в рамках данной статьи, в следующей публикации мы разберем, как решить этот вопрос. Но пока не вышла следующая статья, может быть вы, мои дорогие читатели, сможете сами придумать способ решить проблему гейта XOR и его инверсии, гейта NXOR. Примечание: нельзя использовать более одного нейрона, это было бы обманом. Правило такое: для реализации решения можно использовать только один нейрон.
Заключительные идеи
В этой статье мы показали, как небольшое изменение в коде, направленное на специализацию нейрона, может сделать фазу обучения значительно быстрее. Поскольку, как только нейрон или нейросеть, как мы увидим позже, пройдет обучение, его работа станет гораздо быстрее. Настолько, что в представленном коде — как в самой статье, так и в приложении — вы можете заметить, что генерация результатов на основе входных данных происходит очень быстро. Разумеется, при условии, что мы уже знаем, какие значения следует использовать в расчете.
Здесь мы также упомянули о существующей проблеме, о которой почти никто не говорит и не упоминает. Речь идет именно о том, что нейрон не способен справиться со всеми возможными сценариями, вопреки тому, что многие привыкли считать. Машина не настолько совершенна и не способна превзойти живое существо. Один живой нейрон способен решить любую простую задачу. Тем не менее, запрограммированный или реализованный в кремнии нейрон не способен на такой подвиг.
Итак, в следующей статье мы продолжим рассматривать этот вопрос. Увидимся позже, до скорой встречи.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/13748
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования