
Самооптимизирующиеся советники на MQL5 (Часть 12): Построение линейных классификаторов с использованием факторизации матриц

Факторизация матриц — важный инструмент для алгоритмических трейдеров, заинтересованных в создании приложений, основанных на численных методах. Эти инструменты помогут нам создавать различные типы алгоритмов машинного обучения и не только. До сих пор в ходе нашего обсуждения мы рассматривали только задачи регрессионного анализа. Обратимся к вопросу классификации. В ходе сегодняшнего обсуждения мы попробуем создать классификатор рынков. Этот классификатор сможет различать восходящие и нисходящие движения на рынке. Мы хотим, чтобы это помогало нам правильно открывать сделки. Задача классификатора состоит в том, чтобы на основе исторических данных о поведении рынка сделать вывод о том, какие действия нам следует предпринять в конкретный торговый день.
Наша торговая стратегия работает следующим образом. Цель состоит в том, чтобы предсказать движения рынка на основе ожидаемого поведения индикатора скользящей средней. Кроме того, мы хотим, чтобы цена двигалась в соответствии со скользящей средней. То есть, если наша классификационная модель прогнозирует снижение скользящей средней, мы также хотим наблюдать, как ценовые уровни опускаются ниже этого индикатора. Если мы ожидаем, что и скользящая средняя, и цена будут снижаться, мы откроем позиции на продажу. Скользящая средняя указывает направление движения цены, но перед открытием позиции мы также хотим, чтобы цена ускоренно ушла ниже этого индикатора.
Та же логика применима и к длинным позициям. Мы хотим увидеть, что скользящая средняя начнёт расти, и цены должны резко ускорить рост, значительно превысив её уровень, чтобы мы могли открыть позицию на покупку.
Из этого описания видно, что наша модель будет одновременно прогнозировать два категориальных результата. Однако это не следует путать с многоклассовой классификационной моделью. Каждая из двух переменных, которые прогнозирует наша модель, представляет собой бинарный результат. Другими словами, модель отслеживает два отдельных бинарных исхода. Архитектура, которую мы здесь опишем, не подходит для одновременной классификации более двух классов.
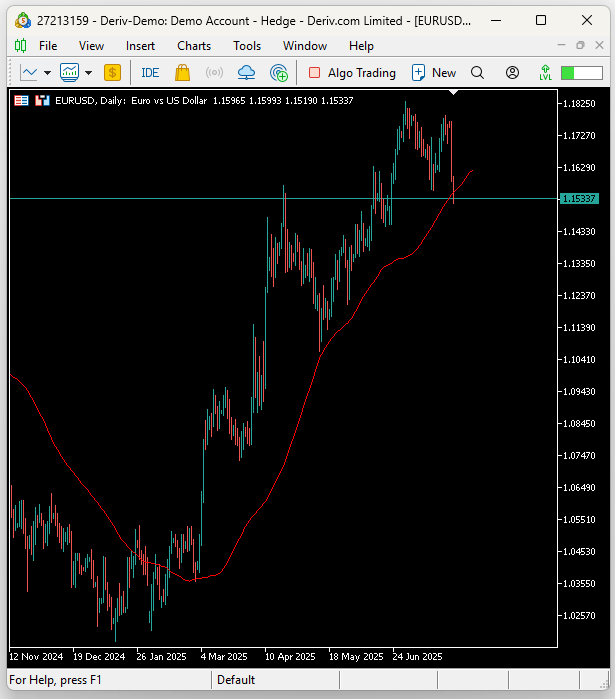
Рисунок 1: Визуализация нашей торговой стратегии в действии
Факторизация матриц для построения линейных классификаторов
Как и в большинстве наших торговых приложений, мы начнем с определения системных параметров. В данном конкретном случае у нас будет шесть входных значений, которые мы будем отслеживать в нашей матрице входных данных X.
//+------------------------------------------------------------------+ //| Linear Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define TOTAL_INPUTS 6
Продолжим: после того как мы определили системные настройки, теперь определим пользовательские настройки, которые конечный пользователь может изменять. В частности, мы хотим, чтобы конечный пользователь мог выбрать подходящий временной интервал и размер нашего стоп-лосса.
//+------------------------------------------------------------------+ //| System Inputs | //+------------------------------------------------------------------+ int bars = 200;//Number of historical bars to fetch int horizon = 1;//How far into the future should we forecast int MA_PERIOD = 50; //Moving average period ENUM_TIMEFRAMES TIME_FRAME = PERIOD_D1;//User Time Frame input ENUM_TIMEFRAMES RISK_TIME_FRAME = PERIOD_D1; input double sl_size = 2;
Кроме того, нам необходимо включить важные системные библиотеки, которые нам понадобятся, такие как библиотека для торговли и две пользовательские библиотеки, которые я написал для отслеживания времени и получения важной торговой информации.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
Далее, наша система также зависит от того, создадим ли мы важные глобальные переменные для нашего примера. В данном конкретном случае нам нужны глобальные переменные, которые будут хранить хендлы технических индикаторов. Нам нужны глобальные переменные для отслеживания входных и выходных данных по мере их поступления с рынка. Кроме того, нам нужны буферы для наших технических индикаторов, чтобы получить их текущие значения.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ int ma_close_handler; double ma_close[]; Time *Timer; TradeInfo *TradeInformation; vector bias,temp,Z1,Z2; matrix X,y,prediction,b; int time; CTrade Trade; int state; int atr_handler; double atr[];
При первом запуске нашей системы будет вызван специальный метод initialize, который инициализирует все системные переменные.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- initialize(); //--- return(INIT_SUCCEEDED); }
Когда наша система перестанет использоваться, мы освободим память, которая была занята техническими индикаторами.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(atr_handler); IndicatorRelease(ma_close_handler); }
При появлении новых свечей с обновлёнными ценами мы будем вызывать два специальных метода. Первый метод — это метод setup, а последний — модуль findSetup. Мы подробно обсудим это позже, по мере продвижения вперед.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(Timer.NewCandle()) { setup(); find_setup(); } }
При первоначальной инициализации нашей системы мы загрузим новые экземпляры обработчиков в соответствующие им идентификаторы. Так, например, мы динамически создадим новый объект для нашей библиотеки времени, который будет отслеживать формирование свечей. Мы также создаем новый объект для нашего класса торговой информации. Напомним, что этот класс отвечает за отслеживание важных сведений, таких как минимальный размер лота, разрешенный на текущем рынке для торговли, а также текущие цены спроса и предложения. Кроме того, функция initialize отвечает за загрузку всех значений по умолчанию в наши матрицы и связанные с ними идентификаторы.
//+------------------------------------------------------------------+ //| Initialize our system variables | //+------------------------------------------------------------------+ void initialize(void) { Timer = new Time(Symbol(),TIME_FRAME); TradeInformation = new TradeInfo(Symbol(),TIME_FRAME); ma_close_handler = iMA(Symbol(),TIME_FRAME,MA_PERIOD,0,MODE_SMA,PRICE_CLOSE); atr_handler = iATR(Symbol(),RISK_TIME_FRAME,14); bias = vector::Ones(TOTAL_INPUTS); Z1 = vector::Ones(TOTAL_INPUTS); Z2 = vector::Ones(TOTAL_INPUTS); X = matrix::Ones(TOTAL_INPUTS,bars); y = matrix::Ones(1,bars); time = 0; state = 0; }
Функция "find_setup()" является гораздо более сложной, чем другие функции, которые мы рассматривали до сих пор. Сначала функция findSetup будет отслеживать текущую цену закрытия, а затем мы скопируем текущие значения наших индикаторов. Поэтому мы скопируем значения ATR и скользящей средней в соответствующие буферы. После этого, если у нас нет открытых позиций, мы сбрасываем состояние системы. Теперь нам необходимо рассмотреть прогноз, полученный от нашего линейного классификатора.
Напомним, что наш классификатор моделирует два выходных сигнала одновременно. Первый прогноз касается направления, в котором, как ожидается, будет двигаться индикатор скользящей средней в будущем, а второй прогноз будет касаться разницы между ценой и скользящей средней. Поэтому мы хотим, чтобы эти два прогноза согласовывались друг с другом. Если ожидается, что индикатор скользящей средней пойдет вниз, мы также хотим увидеть, что ценовые уровни опустятся ниже него. А если ожидается рост скользящей средней, мы хотим, чтобы ценовые уровни поднялись выше нее.
Эти два параметра составляют основу нашей торговой стратегии. Чтобы мы приняли решение о покупке, оба прогноза должны быть выше 0,5. Кроме того, оба прогноза должны быть ниже 0,5, чтобы мы могли продать. В противном случае, если у нас уже есть открытые позиции, мы просто будем отслеживать состояние наших позиций и прогнозы нашего линейного классификатора. Если мы открыли позицию на продажу, но наша модель прогнозирует рост индикатора скользящей средней, то мы закроем позицию. И то же самое верно, если мы что-то покупаем.
В противном случае, если всё выглядит нормально, мы просто скорректируем наш стоп-лосс в более выгодную сторону и продолжим торговлю.
//+------------------------------------------------------------------+ //| Find a trading setup for our linear classifier model | //+------------------------------------------------------------------+ void find_setup(void) { double c = iClose(Symbol(),TIME_FRAME,0); CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_close_handler,0,0,1,ma_close); if(PositionsTotal() == 0) { state = 0; if((prediction[0,0] > 0.5) && (prediction[1,0] > 0.5)) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),(TradeInformation.GetBid() - (sl_size * atr[0])),0); state = 1; } if((prediction[0,0] < 0.5) && (prediction[1,0] < 0.5)) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),(TradeInformation.GetAsk() + (sl_size * atr[0])),0); state = -1; } } if(PositionsTotal() > 0) { if(((state == -1) && (prediction[0,0] > 0.5)) || ((state == 1)&&(prediction[0,0] < 0.5))) Trade.PositionClose(Symbol()); if(PositionSelect(Symbol())) { double current_sl = PositionGetDouble(POSITION_SL); if((state == 1) && ((ma_close[0] - (2 * atr[0]))>current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] - (2 * atr[0])),0); } else if((state == -1) && ((ma_close[0] + (2 * atr[0]))<current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] + (2 * atr[0])),0); } } } }
У нас есть специальные методы, которые мы используем для обучения нашего линейного классификатора. Метод подгонки, как показано ниже, позволит подобрать модель для наших данных, сопоставив входные данные о предыдущих ценах с двумя целевыми показателями, за которыми мы хотим следить. Напомним, что мы используем метод сингулярного разложения (SVD), содержащийся в библиотеке OpenBLAS, чтобы быстро разложить нашу модель на факторы в виде, позволяющем найти оптимальные коэффициенты и сохранить их в массиве B.
//+------------------------------------------------------------------+ //| Fir our classification model | //+------------------------------------------------------------------+ void fit(void) { //--- Fit the model matrix OB_U,OB_VT,OB_SIGMA; vector OB_S; X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); OB_SIGMA.Diag(OB_S); b = y.MatMul(OB_VT.Transpose().MatMul(OB_SIGMA.Inv()).MatMul(OB_U.Transpose())); }
Как и всегда, извлечение и хранение данных являются важной частью любой модели машинного обучения. Мы вычтем среднее значение и разделим на стандартное отклонение для каждой записи в наших данных.
Например, мы хотим отслеживать цену открытия, максимальную цену, минимальную цену и значения технических индикаторов. Прежде чем сохранить эти значения в матрице данных X, их необходимо вычесть из среднего значения и разделить на стандартное отклонение.
Затем, после копирования и преобразования нашей матрицы Y, нам необходимо сохранить результаты либо в виде нулей (чтобы показать падение цен), либо в виде единиц (чтобы показать рост цен). Вот как мы создаём модель классификации.
//+------------------------------------------------------------------+ //| Prepare the data needed for our classifier | //+------------------------------------------------------------------+ void fetch_data(void) { //--- Reshape the matrix X = matrix::Ones(TOTAL_INPUTS,bars); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,horizon,bars); Z1[0] = temp.Mean(); Z2[0] = temp.Std(); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,horizon,bars); Z1[1] = temp.Mean(); Z2[1] = temp.Std(); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,horizon,bars); Z1[2] = temp.Mean(); Z2[2] = temp.Std(); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); Z1[3] = temp.Mean(); Z2[3] = temp.Std(); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); //--- Store the Z-scores temp.CopyIndicatorBuffer(ma_close_handler,0,horizon,bars); Z1[4] = temp.Mean(); Z2[4] = temp.Std(); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); //--- Reshape the output target y.Reshape(2,bars); vector temp_2,temp_3,temp_4; //--- Prepare to label the target accordingly temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); temp_4.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,bars); temp_2.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,bars); temp_3.CopyIndicatorBuffer(ma_close_handler,0,0,bars); for(int i=0;i<bars;i++) { //--- Record if price levels appreciated or depreciated if(temp[i] > temp_4[i]) y[0,i] = 0; else if(temp[i] < temp_4[i]) y[0,i] = 1; //--- Record if price levels remained above the moving average indicator, or fell beneath it. if(temp_2[i] < temp_3[i]) y[1,i] = 0; if(temp_2[i] > temp_3[i]) y[1,i] = 1; } Print("Training Input Data: "); Print(X); Print("Training Target"); Print(y); }
Теперь мы готовы приступить к получению прогнозов с помощью нашей модели классификации. Чтобы просто получить прогноз от нашей модели классификации, нам нужна последняя строка в наших входных данных X. В качестве альтернативы можно рассматривать её как текущие рыночные показатели — текущую рыночную конъюнктуру. Мы берем текущие рыночные условия и умножаем их на коэффициенты, полученные на основе исторических данных, и это даст нам прогноз.
//+------------------------------------------------------------------+ //| Obtain a prediction from our classification model | //+------------------------------------------------------------------+ void predict(void) { //--- Prepare to get a prediction //--- Reshape the data X = matrix::Ones(TOTAL_INPUTS,1); //--- Get a prediction temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,0,1); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,0,1); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,0,1); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,1); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); temp.CopyIndicatorBuffer(ma_close_handler,0,0,1); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); Print("Prediction Inputs: "); Print(X); //--- Get a prediction prediction = b.MatMul(X); Print("Prediction"); Print(prediction); }
Однако вызов каждого из этих методов по очереди может оказаться обременительным. Поэтому мы разработали специальный метод настройки, который будет вызывать каждый из этих трёх методов в том порядке, в котором они нам нужны. Сначала мы загрузим данные. Затем мы подгоним нашу модель под данные. И, наконец, мы получим прогноз.
Этот простой метод настройки позволяет выполнять все три шага — всегда в правильном порядке.
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void setup(void) { fetch_data(); fit(); predict(); } //+------------------------------------------------------------------+
И, наконец, нам необходимо унифицировать системные определения, которые мы создали в начале разработки нашего приложения.
#undef TOTAL_INPUTS Наш бэктест начнется в январе 2020 года и продлится пять лет на дневном таймфрейме, до 2025 года. Мы будем тестировать наше приложение на паре EURUSD.
Рисунок 2: Выбор дней для бэктеста и оптимизации
Кроме того, для получения максимально точных результатов мы всегда используем случайные значения задержки, чтобы условия тестирования нашего приложения соответствовали реальным рыночным условиям, которые мы ожидаем увидеть в будущем.
Рисунок 3: Важно также правильно выбрать условия для бэктеста
Я сделал скриншот показателей работы нашего приложения во время бэктеста. Как мы видим, приложение показывает нам входные данные для прогнозирования, которые ему были предоставлены. Напомним, что первый признак всегда равен единице и представляет свободный член модели (intercept). Но на самом деле мы уделяем внимание в основном тем прогнозам, которые дает наша модель.
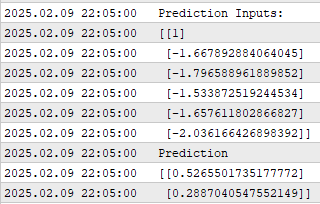
Рисунок 4: Результат, полученный при запуске нашего алгоритма линейного классификатора
Как мы видим, наша модель дает нам два прогноза, как мы уже отмечали ранее. Первый прогноз связан с изменением положения скользящей средней в будущем, а второй — с изменением отношения цены к скользящей средней. И не забывайте, что мы хотим, чтобы оба этих изменения шли в одном направлении.
Мы также можем проследить за кривой капитала, сформированной нашей торговой стратегией. Как видно, кривая капитала демонстрирует восходящую динамику с течением времени, хотя и не совсем стабильную.
Кроме того, читателю следует иметь в виду, что на этой кривой изображены две линии. Синяя линия отражает наш баланс во времени, а зеленая линия — собственный капитал на счете во времени. Итак, как мы видим, существует множество случаев, когда мы наблюдаем, как кривая собственного капитала — зеленая линия — резко поднимается выше синей линии.
Исходя из моего опыта в качестве автора, это означает упущенную прибыль или сигналы в нашей торговой стратегии, которые мы по-прежнему не можем уловить. Этот сигнал ускользает от внимания нашей торговой стратегии, и мы не используем эти возможности для получения прибыли. Это говорит о том, что наша стратегия по-прежнему требует доработки.
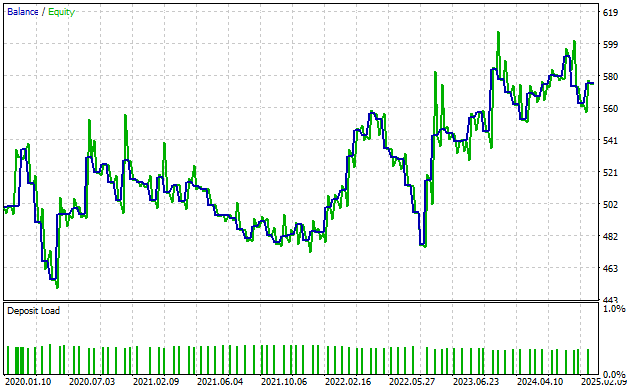
Рисунок 5: Наша кривая капитала указывает на то, что мы по-прежнему упускаем какой-то важный сигнал.
Наконец, мы можем рассмотреть подробную статистику наших результатов за определенный период времени. И, как мы видим, в среднем наша средняя прибыльная сделка превышает нашу среднюю убыточную сделку. Наибольшая прибыль, полученная нами в результате реализации нашей стратегии, также превышает наибольший убыток, что не может не радовать.
Однако, если посмотреть на долю прибыльных сделок, то мы увидим, что их доля составляет 43 %, что меньше половины. Это подтверждает то, на что я обратил внимание читателя, когда мы рассматривали кривую капитала и видели те скачки упущенной прибыли, которые наша система не смогла реализовать.
Это только укрепляет нашу уверенность в том, что систему можно улучшить ещё больше — что есть информация, которую мы пока упускаем. Несмотря на то, что это хороший старт, есть ещё много сигналов, которые мы можем обнаружить и изучить.
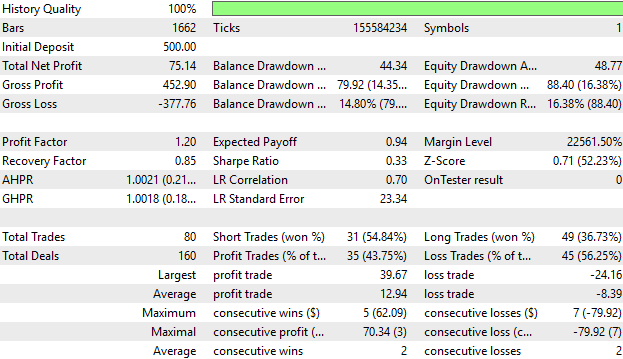
Рисунок 6: Подробные статистические данные о нашей работе подтверждают наши предыдущие выводы о том, что система требует доработки
Заключение
В заключение, в данной статье читателю были продемонстрированы многочисленные возможности факторизации матриц, которые мы, как алгоритмические трейдеры, можем использовать в своих приложениях на MQL5. Когда мы впервые заговорили о факторизации матриц, мы рассматривали его как инструмент, который можно использовать для регрессионного анализа. Сейчас мы рассматриваем это как инструмент, который можно использовать для классификации.
Но я даю читателю только одно обещание — что нам ещё предстоит обсудить многое. Это лишь основы. На мой взгляд, как автора, это простые примеры, которые быстро демонстрируют ценность факторизации матриц. Если вы следили за этой серией статей, то теперь вы знаете, как построить регрессионную модель с использованием факторизации матриц, классификаторную модель или их комбинацию — модели, которые не ограничиваются прогнозированием одного показателя за раз, а способны прогнозировать сразу несколько целевых показателей.
И все же я обещаю вам, уважаемый читатель, что у факторизации матриц есть еще много других преимуществ, о которых мы пока не говорили. Но прежде чем приступить к изучению этих преимуществ, нам необходимо освоить основы. Кроме того, вы убедились, насколько это просто — благодаря специальным функциям, доступным нам в API MQL5. Вы убедились, насколько легко интегрировать эти мощные матричные методы в ваши торговые приложения.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18987
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования