
Создание самооптимизирующихся советников на MQL5 (Часть 11): Введение в основы линейной алгебры

В нашей вводной беседе о факторизации матриц мы рассмотрели многочисленные преимущества использования команд линейной алгебры, доступных в API MQL5. В том первоначальном обсуждении предполагалось, что читатель обладает некоторыми базовыми знаниями, а именно: базовым пониманием моделирования временных рядов и статистического анализа. Однако, оглядываясь назад, становится ясно, что это предположение может оказаться верным не для всех читателей.
Если вы впервые сталкиваетесь с подобными темами, возможно, вводная статья оказалась не столь полезной, как предполагалось. Материал продвигался быстро, и многие понятия вводились одно за другим. Поэтому в этой статье я хочу сосредоточить внимание на читателях, не имеющих абсолютно никакого опыта в области описываемых математических методов.
Я расскажу об этих методах, исходя из того, что у читателей нет предварительных знаний, чтобы каждый мог понять изложение и оценить преимущества API матриц и векторов. API для работы с матрицами и векторами, предоставляемый MQL5, действительно мощный, но сам по себе он недостаточен. Он не работает автономно. Только понимая принципы линейной алгебры, мы сможем грамотно и эффективно использовать этот API.
Эта статья станет подспорьем для читателей, не имеющих формального математического образования. Мы будем использовать сравнительный подход к обучению: Для начала я приведу пример кода, который мог бы написать разработчик MQL5, не имеющий представления о линейной алгебре, а затем сравню его с кодом, написанным человеком, который хорошо понимает лежащие в его основе математические принципы. Такой параллельный подход позволит ясно и интуитивно продемонстрировать преимущества линейной алгебры.
Все представленные теоретические концепции будут непосредственно связаны с практическим применением в торговле, которое мы продемонстрируем прямо здесь, в терминале MetaTrader 5. Используя реальные рыночные данные, мы применим математическую теорию на практике, продемонстрировав универсальность и практическую ценность этих команд линейной алгебры.
Сегодня мы построим статистическую модель, которая позволяет одновременно прогнозировать несколько целевых показателей. Как правило, модели линейной регрессии используются для прогнозирования одного целевого показателя — например, будущего изменения цены. Однако в данном случае мы ставим перед собой задачу предсказать четыре различных целевых показателя:
- Скользящее среднее будущих цен закрытия
- Скользящее среднее будущего максимума
- Будущая скользящая средняя от минимума
- Будущее значение цены
Мы учтём эти прогнозы в нашей торговой стратегии, чтобы определить правила входа и выхода, а также фильтры для закрытия позиций. API Matrix и Vector MQL5 предоставляет нам мощные инструменты для создания современных приложений в области машинного обучения. Однако для того, чтобы в полной мере использовать возможности API, необходимо понимать основные правила линейной алгебры, лежащие в основе правильного применения этих специальных методов.
Линейная алгебра зачастую представляет собой абстрактную математическую дисциплину. Однако я хочу, чтобы вы лучше представили себе эту тему, чтобы вы могли ясно увидеть преимущества того, что мы сейчас рассмотрим, а к математической части мы перейдем ближе к середине беседы. Наконец, после того как станет ясна цель нашего обсуждения и будут разъяснены все необходимые математические обозначения, мы продемонстрируем один из примеров того, как с помощью линейной алгебры можно создавать торговые алгоритмы, основанные на численных данных и способные одновременно прогнозировать несколько целевых показателей.
Удобная для сопровождения кодовая база
В большинстве случаев при работе с рыночными ценами — например, с наборами значений цен открытия, максимальной, минимальной и закрытия — удобно хранить эти данные в виде матрицы. В MQL5 матрицы индексируются сначала по строкам, а затем по столбцам. Поэтому для начала определим новую матрицу A размером 3 на 5, заполненную нулями. Это означает, что матрица A будет состоять из трёх строк и пяти столбцов, а все элементы изначально будут равны нулю. Затем мы отображаем матрицу A в её текущем состоянии, которое, как показано на Рисунке 1, действительно заполнено нулями.
//--- Let's first create an empty matrix matrix A=matrix::Zeros(3,5); //--- Peek at the matrix Print("Original A matrix"); Print(A);

Рисунок 1: Визуализация нашей пустой матрицы A
Далее мы присваиваем значения каждой строке: в первую строку будут внесены постоянные значения "1", во вторую — "2", а в третью — "3".
Как читатель может заметить, нотация, используемая для обращения к элементам матрицы в MQL5, всегда начинается с индекса строки, за которым следует индекс столбца в квадратных скобках, расположенных рядом с идентификатором, связанным с матрицей. Мы можем ещё раз проверить матрицу A, чтобы убедиться, что она заполнена правильно — Рисунок 2 подтверждает, что это так.
//--- The notation A[R,C] describes the Row and Column we want to manipulate //--- We will set all the values in Row 1 to be 1 A[0,0] = 1; A[0,1] = 1; A[0,2] = 1; A[0,3] = 1; A[0,4] = 1; //--- We will set all the values in Row 2 to be 2 A[1,0] = 2; A[1,1] = 2; A[1,2] = 2; A[1,3] = 2; A[1,4] = 2; //--- We will set all the values in Row 3 to be 3 A[2,0] = 3; A[2,1] = 3; A[2,2] = 3; A[2,3] = 3; A[2,4] = 3; Print("Current A matrix"); Print(A);

Рисунок 2: Обозначение строк в нашей матрице A для данного упражнения
А теперь давайте поработаем со значениями внутри нашей матрицы. Предположим, что мы хотим умножить все значения во второй строке матрицы A на пять. В простой реализации можно было бы создать цикл for для прохождения по каждой записи во второй строке, умножить каждую из них на пять и сохранить результат. Как видно, этот подход позволяет достичь желаемого результата и пройдет любую функциональную проверку.
Однако может ли читатель придумать причины, по которым нам, возможно, не стоит использовать цикл for для решения этой задачи?
//--- Let's multiply all the values of Row 2 by 5 and leave all the other rows the same. //--- Bad performing code //--- Copy matrix A matrix example_1; example_1.Assign(A); //--- Loop over matrix A and multiply each element by 5 and then replace the original elements for(int i =0;i<5;i++) { example_1[1,i] = example_1[1,i] * 5; } //--- Done Print("Example 1: "); Print(example_1);

Рисунок 3: Обработка матрицы A с помощью цикла for может стать слишком медленной по мере увеличения размера A
Рассмотрим несколько усовершенствованный подход. Вместо использования цикла мы могли бы выбрать вторую строку матрицы в виде строчного вектора, умножить его на пять, а затем присвоить результат обратно в исходное место. Это дает тот же результат и выглядит более элегантно. Тем не менее, я снова обращаюсь к читателю: не приходит ли вам в голову, почему даже этот подход может оказаться не самым оптимальным?
//--- Slightly better code //--- Copy the row, multiply it and then put it back matrix example_2; vector copy_vector; example_2.Assign(A); copy_vector = example_2.Row(1); example_2.Row(copy_vector*5,1); Print("Example 2"); Print(example_2);

Рисунок 4: Обработка матрицы A с помощью векторных методов эффективнее, чем использование традиционного цикла for, но не является оптимальным решением
В заключение я покажу, какой подход считается подходящим в данном контексте: сначала создаем вектор масштабирования, а затем с помощью умножения матриц применяем этот вектор к матрице A. Как видно, все три фрагмента кода дают одинаковый результат. Однако читателю следует обратить внимание на несколько важных отличий.
Третий подход требует наименьшего количества строк кода. Это демонстрирует одно из ключевых преимуществ использования линейной алгебры в повседневной торговой деятельности: она позволяет нам писать более лаконичный и код, удобный для сопровождения. Я полагаю, что для большинства разработчиков уже одно это должно стать весомой причиной, чтобы уделить время изучению линейной алгебры. Однако есть ещё много других преимуществ, которые я продемонстрирую по ходу изложения. Это просто хорошее место для начала
//--- Reliable code matrix example_3,scaler; vector scale = {1,5,1}; scaler.Diag(scale); example_3 = scaler.MatMul(A); //--- Done Print("Example 3"); Print(example_3);

Рисунок 5: Лучше всего всегда использовать специальные методы для работы с матрицами и векторами, если таковые имеются
А теперь давайте расширим этот пример. Сначала мы умножили на пять только вторую строку. Давайте теперь умножим первую строку на два, последнюю — на десять, а среднюю оставим без изменений. На этом этапе читатель, возможно, начнёт понимать, в чём заключаются проблемы использования цикла for. По мере увеличения количества операций над матрицей A увеличивается и длина нашего цикла — а значит, и количество строк, которые нам предстоит написать. Кроме того, если матрица A достаточно велика, поочередная обработка каждого элемента — как это предполагает цикл — может значительно замедлить выполнение, особенно при тестировании на исторических данных.
//--- Now, multiply the first and last rows by 2 and 10, but leave the middle row as it is. //--- Loops can slow us down during backtests, especially if they must be repeated often. for(int i =0;i<5;i++) { example_1[0,i] = example_1[0,i] * 2; example_1[2,i] = example_1[2,i] * 10; } //--- Done Print("Example 1"); Print(example_1);

Рисунок 6: Нам приходится добавлять в цикл for дополнительные строки кода, чтобы добиться того же результата
Аналогичным образом, использование метода выделения и переназначения отдельных строк становится всё более сложным по мере увеличения количества операций. Хотя этот метод и превосходит обычный цикл for, он всё же приводит к раздутому коду, что увеличивает вероятность ошибок.
//--- The difference between example 2 and 3 starts to show //--- Copy the row, multiply it and then put it back vector copy_vector_2; copy_vector = example_2.Row(0); copy_vector_2 = example_2.Row(2); example_2.Row(copy_vector*2,0); example_2.Row(copy_vector_2*10,2); //--- Done Print("Example 2"); Print(example_2);

Рисунок 7: Совместное использование общих методов работы с матрицами и векторами по-прежнему позволяет решить задачу, но мы можем добиться лучшего результата
Мы можем добиться ещё лучших результатов, воспользовавшись умножением матриц. При таком подходе меняются только значения масштабирования. Остальная часть кода остается практически неизменной, независимо от количества строк. Все три метода дают одинаковый результат, но, увидев их в сравнении, я задаю читателю вопрос: какой подход кажется наиболее подходящим при работе с большими объёмами исторических рыночных данных?
//--- Reliable code vector scale_2 = {2,1,10}; scaler.Diag(scale_2); example_3 = scaler.MatMul(example_3); //--- Done Print("Example 3"); Print(example_3);

Рисунок 8: Мы можем получить тот же результат, написав меньше кода, если программировать более лаконично
Время, необходимое для бэктеста
При использовании традиционных циклов for мы можем оказаться не в состоянии эффективно обработать все данные, особенно при выполнении операций, где время имеет решающее значение, таких как бэктестинг. Это подводит нас ко второму ключевому моменту: при правильном использовании матричных и векторных API не только упрощается обслуживание нашего кода, но и повышается эффективность выполнения наших торговых стратегий.
В конечном итоге, большинство читателей, вероятно, заинтересованы в создании мощных моделей искусственного интеллекта для торговли — моделей, способных принимать обоснованные решения. Однако для того, чтобы ваша модель искусственного интеллекта могла принимать такие решения, ей необходим доступ к большим объёмам данных. И прежде чем мы введем эти данные в модель, нам необходимо выполнить определенные этапы предварительной обработки и манипуляции.
Если мы выполняем эти операции неэффективно, количество строк, необходимых для создания приложения, быстро растёт — особенно если мы используем циклы for. По мере увеличения объема кода увеличивается и время, необходимое для тестирования на исторических данных.
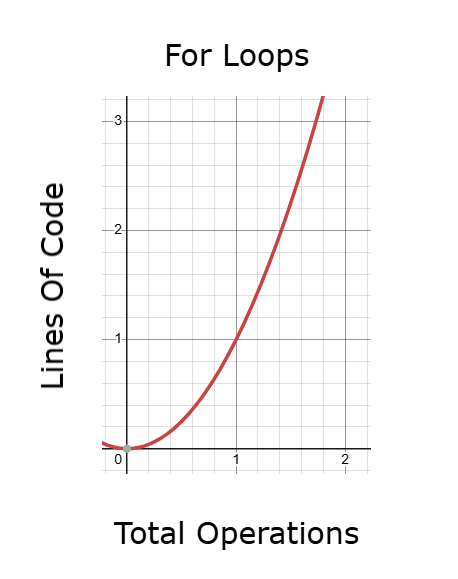
Рисунок 9: Циклы for могут генерировать код, выполнение которого занимает слишком много времени при тестировании на исторических данных
Лучшей альтернативой является использование цепочки операций над векторами и матрицами. Этот метод работает гораздо быстрее, чем традиционные циклы, но даже он может оказаться обременительным, если требует многократного копирования, изменения и переназначения строк. Если количество таких операций увеличивается, то увеличивается и время, необходимое для выполнения кода, что вновь сказывается на результатах бэктеста и оптимизации модели.
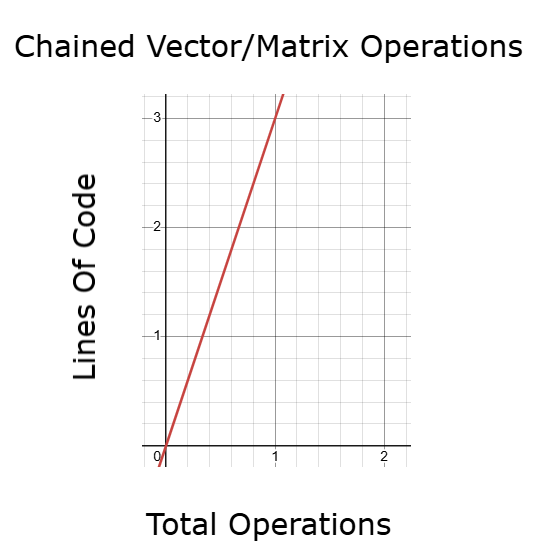
Рисунок 10: Использование API для цепочки матриц и векторов будет быстрее, чем цикл for, но, возможно, мы сможем добиться ещё лучших результатов
С другой стороны, используя соответствующие векторные и матричные операции, основанные на линейной алгебре, мы можем контролировать время выполнения и поддерживать постоянными длину кода и время бэктестирования — даже при увеличении объема данных. Это чрезвычайно ценное качество в любой области применения. Это означает, что мы можем выполнять больше операций, не прибегая к написанию пропорционально большего объема кода и не увеличивая время выполнения, что позволяет нам более эффективно проводить итерации и оптимизировать модели машинного обучения. Я полагаю, что большинство читателей будут удивлены тем, каких успехов можно достичь, просто освоив несколько основных понятий линейной алгебры. Нам не нужны сложные теории, чтобы начать замечать существенные улучшения в наших приложениях.
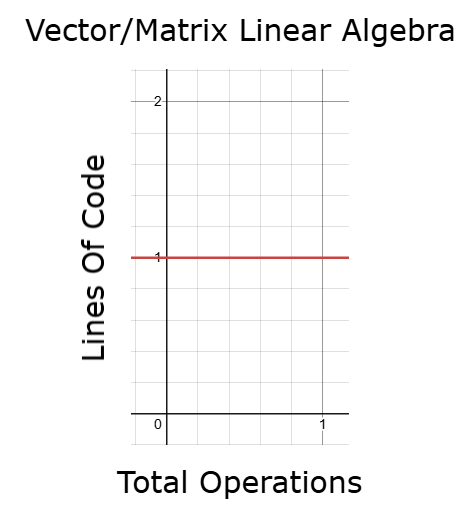
Рисунок 11: Использование линейной алгебры может помочь нам обеспечить постоянную длительность выполнения наших приложений
Точность
Я также хотел бы обратить внимание на важный аспект, который, на мой взгляд, часто упускается из виду в технических дискуссиях: точность. Я считаю, что этой теме не уделяется того внимания и не проводится того тщательного анализа, которых она по-настоящему заслуживает. Точность — один из ключевых компонентов при разработке надежной торговой стратегии. Результаты, полученные в ходе бэктестинга, должны быть точными, а внутренние вычисления и решения, принимаемые приложением, должны быть точными и достоверными. Представьте себе следующую ситуацию: в приведенном ниже фрагменте кода мы выполняем простое вычитание чисел с плавающей запятой — 0,3 – 0,1. Компьютер выдает результат 0,199999... вместо ожидаемого 0,2. Это хорошо известная проблема в информатике, связанная с арифметикой с плавающей запятой, и она не является особенностью только MQL5.
Я хочу подчеркнуть следующее: представьте, что вы выполняете такую операцию вычитания внутри цикла. А теперь представьте, что вы просматриваете матрицу типа A, которая может содержать более миллиона строк, и выполняете эту операцию над каждой из них. Становится очевидным, как эти небольшие погрешности в точности могут накапливаться и усугубляться, в конечном итоге приводя к значительной численной нестабильности результатов.
Небрежное выполнение арифметических операций — например, прямого вычитания, как в данном случае, с большими матрицами — неэффективно и не даст точных или численно устойчивых результатов.
Кроме того, если рассмотреть алгоритмы, подобные приведенным в предыдущих примерах — где значения многократно копируются из одного места в другое, создаются новые объекты, происходит переназначение данных, а память постоянно выделяется и освобождается — эта проблема становится ещё более актуальной. У компьютеров объем памяти ограничен. Когда мы выполняем матричные операции неэффективно, постоянно создавая и уничтожая объекты, мы без необходимости увеличиваем нагрузку на память. Попытки управлять памятью столь бессистемно влекут за собой серьезные последствия, которые мы часто упускаем из виду.
Кроме того, существуют алгоритмы — многие из которых уже реализованы в матричном и векторном API MQL5, а также в вспомогательных библиотеках, которые мы рассмотрим, — разработанные именно с учетом этих задач. Эти реализации оптимизированы с целью минимизации погрешности при работе с числами с плавающей запятой и обеспечения максимальной численной устойчивости. Напротив, когда разработчики выбирают менее эффективные методы — например, ручные циклы for для обработки данных — они, сами того не подозревая, повышают вероятность возникновения этих проблем.
//--- Why should you care? //--- Let's start with an often overlooked need, precision! Print("Our computers have limited memory to store numbers with precision"); Print("What is 0.3 - 0.1"); Print(0.3-0.1); Print("You and I know the correct answer is 0.2");

Рисунок 12: Использование соответствующих матриц и векторов в линейной алгебре может помочь нам свести такие ошибки к минимуму
Как мы, трейдеры, можем использовать линейную алгебру?
Теперь, когда читатель смог оценить преимущества изучения линейной алгебры, пришло время рассмотреть некоторые основополагающие правила, определяющие, как мы принимаем решения с её помощью. Понимание этих основных правил — ценный навык.
Чтобы начать понимать линейную алгебру, нам сначала необходимо хорошо освоить основы алгебры. Алгебра — это, по сути, математика неизвестных величин. Начнём с простого примера, представленного на рисунке 13: Это уравнение означает: некоторое неизвестное значение, умноженное на 2, дает 4. Чтобы найти значение x, делим обе части уравнения на 2. Если мы хотим проверить наше решение, достаточно подставить в исходное уравнение значение 2 вместо x, а затем убедиться, что 2 умноженное на 2 действительно равно 4. Хотя это может показаться элементарным, оно закладывает основу для более сложных понятий.

Рисунок 13: Визуализация простой алгебраической задачи, в которой значение x равно 2
А теперь давайте рассмотрим небольшое изменение: что, если уравнение будет выглядеть так: A умножить на 2 равняется 4. Мы разделим обе части уравнения на A и получим решение: x равен 4, деленному на A. Поскольку нам не известно, чему равно A, на этом решение задачи завершено.

Рисунок 14: Рассмотрим несколько более сложный вариант задачи, изображённой на Рисунке 13
А что будет, если A — не просто число, а матрица? Именно здесь мы переходим от алгебры, изучаемой в старших классах школы, к линейной алгебре. Вот матрица A. У нас может возникнуть соблазн разделить обе части на A, как мы делали ранее. Однако в линейной алгебре деление на матрицу не определено. Вместо этого мы используем обратную матрицу. Если матрица имеет обратную, мы решаем уравнение, умножив обе части на обратную матрицу A.

Рисунок 15: Линейная алгебра основана на той же логике, которую мы использовали в наших простых примерах, но нам нужно лишь немного изменить некоторые правила
Что это означает в контексте рыночных данных? Предположим, что матрица A отражает текущие рыночные данные, такие как уровни цен. Вектор y представляет собой будущую цену, которую вы пытаетесь предсказать. Вы хотите найти вектор коэффициентов, при умножении которого текущие данные дадут будущие уровни цен.
Но вот в чём проблема: не у каждой матрицы существует обратная. На самом деле, обращение матрицы, которая не является обратимой, может привести к сбою вашего торгового алгоритма или к получению недостоверных результатов. По этой причине мы не "слепо" инвертируем любую матрицу, с которой сталкиваемся. Вместо этого зачастую безопаснее и стабильнее работать с меньшими подматрицами — частями данных, которые мы можем надежно обратить или обработать с помощью других численно устойчивых методов, таких как факторизация матриц (например, QR, SVD или псевдообратные матрицы).

Рисунок 16: Обобщение решения на любую линейную систему уравнений
Использование линейной алгебры для улучшения наших торговых результатов
Теперь, когда мы достаточно хорошо освоили основные принципы решения линейных систем уравнений с помощью линейной алгебры, мы готовы приступить к применению полученных знаний для нахождения вектора коэффициентов x. В этом конкретном примере я хочу показать вам, что формула, которую мы обсуждали, позволяет с такой же легкостью находить несколько значений y, как и одно. Итак, давайте начнём с определения констант нашей системы. Сегодня нам нужно определить, сколько входных данных будет принимать наша модель. Эта конкретная модель принимает восемь входных данных.
//+------------------------------------------------------------------+ //| Linear Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define TOTAL_INPUTS 8
Затем необходимо задать важные системные параметры. Например, количество исторических баров, которые необходимо загрузить, на какой период в будущем мы хотим сделать прогноз, используемые временные интервалы и другие связанные настройки. Все эти данные будут сохранены в системных параметрах.
//+------------------------------------------------------------------+ //| System parameters | //+------------------------------------------------------------------+ int bars = 90; //Number of historical bars to fetch int horizon = 1; //How far into the future should we forecast int MA_PERIOD = 2; //Moving average period ENUM_TIMEFRAMES TIME_FRAME = PERIOD_D1; //User Time Frame ENUM_TIMEFRAMES RISK_TIME_FRAME = PERIOD_D1; //Time Frame for our ATR stop loss double sl_size = 2; //ATR Stop loss size
Зависимости в любом приложении играют важную роль, поскольку позволяют сократить общий объем кода, который приходится переписывать при переходе от одного проекта к другому. Поэтому мы загрузим несколько ключевых зависимостей, таких как библиотека Trade, входящая в MetaTrader 5, которая по умолчанию установлена в каждой версии MetaTrader 5. Остальные две зависимости были разработаны специально для нашей торговой деятельности.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
Наша система также определит важные глобальные переменные, которые будут использоваться в различных контекстах приложения. Например, мы будем использовать глобальные переменные для хранения текущих показаний индикаторов. Одни будут хранить значения, используемые зависимостями, а другие — коэффициенты, полученные на основе данных. К ним относятся такие показатели, как значение ATR, а также многие другие компоненты нашей системы.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ int ma_close_handler,ma_high_handler,ma_low_handler; double ma_close[],ma_high[],ma_low[]; Time *Timer; TradeInfo *TradeInformation; vector bias,temp,temp_2,temp_3,temp_4,temp_5,Z1,Z2; matrix X,y,prediction,b; int time; CTrade Trade; int state; int atr_handler; double atr[];
При инициализации система создаст новые объекты для загруженных нами пользовательских зависимостей. Таймер отвечает за отслеживание появления новых свечей. Торговый модуль возвращает важную информацию, такую как минимальный объем сделки, цена предложения и цена спроса. Кроме того, мы создадим обработчики для отслеживания наших скользящих средних, а также инициализируем наши матрицы и векторы, задав в качестве начальных значений единицу, чтобы просто приступить к работе.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Timer = new Time(Symbol(),TIME_FRAME); TradeInformation = new TradeInfo(Symbol(),TIME_FRAME); ma_close_handler = iMA(Symbol(),TIME_FRAME,MA_PERIOD,0,MODE_SMA,PRICE_CLOSE); ma_high_handler = iMA(Symbol(),TIME_FRAME,MA_PERIOD,0,MODE_SMA,PRICE_HIGH); ma_low_handler = iMA(Symbol(),TIME_FRAME,MA_PERIOD,0,MODE_SMA,PRICE_LOW); bias = vector::Ones(TOTAL_INPUTS); Z1 = vector::Ones(TOTAL_INPUTS); Z2 = vector::Ones(TOTAL_INPUTS); X = matrix::Ones(TOTAL_INPUTS,bars); y = matrix::Ones(1,bars); time = 0; state = 0; atr_handler = iATR(Symbol(),RISK_TIME_FRAME,14); //--- return(INIT_SUCCEEDED); }
Когда наше приложение перестанет использоваться, мы освободим все объекты, связанные с ресурсами памяти. Это хорошая практика в MQL5, и мы всегда будем ей следовать.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(atr_handler); IndicatorRelease(ma_close_handler); IndicatorRelease(ma_high_handler); IndicatorRelease(ma_low_handler); }
Каждый раз, когда в обработчике OnTick поступают обновленные цены, мы сначала проверяем, полностью ли сформировалась новая свеча. Если да, то мы копируем все показания индикаторов в соответствующие массивы и подготавливаем модель к прогнозированию рынка. После этого мы отслеживаем текущую цену закрытия и рассчитываем уровень стоп-лосса — как для позиций на продажу, так и для позиций на покупку.
Далее мы отображаем прогнозируемые уровни цен, которые ожидает наша модель. Напомним, что мы прогнозируем скользящую среднюю цены закрытия, скользящую среднюю максимальной цены, скользящую среднюю минимальной цены и саму цену. Если в данный момент нет открытых позиций, мы сначала сбрасываем соответствующие переменные состояния. Затем мы проверяем соотношение между ожидаемой ценой закрытия и ожидаемой скользящей средней цены закрытия в будущем.
В целом, нам нужно убедиться, что наш алгоритм предполагает, что скользящее среднее цены закрытия будет выше текущей цены закрытия. Это позволяет предположить, что в настоящее время цены занижены, поскольку они торгуются ниже уровня, который модель считает справедливой стоимостью.
Для дополнительного подтверждения мы также хотим убедиться, что вероятность срабатывания нашего стоп-лосса минимальна — как для позиций на покупку, так и для позиций на продажу. При условиях покупки мы проверяем, что нижняя скользящая средняя, по прогнозам, не опустится ниже уровня стоп-лосса по покупке. При условиях продажи мы проверяем, не ожидается ли, что скользящая средняя по максимальным значениям поднимется выше уровня стоп-лосса по продаже. Если нарушается любое из этих условий, мы воздерживаемся от открытия позиции.
Кроме того, мы сравниваем каждую скользящую среднюю с соответствующим ей текущим значением. При покупке мы ожидаем, что будущее значение скользящей средней, будет выше её текущего значения. При продаже мы ожидаем, что будущее значение скользящей средней будет ниже её текущего значения. Точно так же при покупке мы хотим, чтобы будущее значение скользящей средней превышало её текущее значение.
Когда приходит время закрыть позицию, мы сначала проверяем, не ожидается ли движение цен в невыгодном для нас направлении. Если мы предполагаем, что любая скользящая средняя может превысить уровень стоп-лосса, мы немедленно закрываем сделку. В противном случае мы позволяем стоп-лоссу продолжать следовать за ценой в более прибыльную зону.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(Timer.NewCandle()) { CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_close_handler,0,0,1,ma_close); CopyBuffer(ma_low_handler,0,0,1,ma_low); CopyBuffer(ma_high_handler,0,0,1,ma_high); setup(); double c = iClose(Symbol(),TIME_FRAME,0); double buy_sl = (TradeInformation.GetBid() - (sl_size * atr[0])); double sell_sl = (TradeInformation.GetAsk() + (sl_size * atr[0])); Comment("Forecasted MA: ",prediction[0,0],"\nForecasted MA High: ",prediction[1,0],"\nForecasted MA Low: ",prediction[2,0],"\nForecasted Price: ",prediction[3,0]); if(PositionsTotal() == 0) { state = 0; if((prediction[0,0] > c) && (prediction[2,0] > buy_sl) && (prediction[3,0] > c) && (prediction[2,0] > ma_low[0]) && (prediction[1,0] > ma_high[0])) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),buy_sl,0); state = 1; } if((prediction[0,0] < c) && (prediction[1,0] < sell_sl) && (prediction[3,0] < c) && (prediction[2,0] < ma_low[0]) && (prediction[1,0] < ma_high[0])) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),sell_sl,0); state = -1; } } if(PositionsTotal() > 0) { double current_sl = PositionGetDouble(POSITION_SL); if(((state == -1) && (prediction[0,0] > c) && (prediction[1,0] > current_sl)) || ((state == 1)&&(prediction[0,0] < c)&& (prediction[2,0] < current_sl))) Trade.PositionClose(Symbol()); if(PositionSelect(Symbol())) { if((state == 1) && ((ma_close[0] - (2 * atr[0]))>current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] - (2 * atr[0])),0); } else if((state == -1) && ((ma_close[0] + (1 * atr[0]))<current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] + (2 * atr[0])),0); } } } } }
Далее нам необходимо рассмотреть некоторые отдельные функции, предназначенные для решения вышеуказанных задач. Первая функция — prepare_data(). Эта функция выполняет одну основную задачу: она копирует все необходимые нам уровни цен в матрицу входных данных x. Он извлекает цену открытия, вычисляет среднее значение и стандартное отклонение цены открытия, а затем нормализует данные, вычитая среднее значение и деля на стандартное отклонение. Этот процесс повторяется для всех входных данных. Все значения обработчика скользящего среднего также копируются и сохраняются в целевом массиве y.
//+------------------------------------------------------------------+ //| Prepare the training data for our model | //+------------------------------------------------------------------+ void prepare_data(void) { //--- Reshape the matrix X = matrix::Ones(TOTAL_INPUTS,bars); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,horizon,bars); Z1[0] = temp.Mean(); Z2[0] = temp.Std(); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,horizon,bars); Z1[1] = temp.Mean(); Z2[1] = temp.Std(); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,horizon,bars); Z1[2] = temp.Mean(); Z2[2] = temp.Std(); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); Z1[3] = temp.Mean(); Z2[3] = temp.Std(); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); //--- Store the Z-scores temp.CopyIndicatorBuffer(ma_close_handler,0,horizon,bars); Z1[4] = temp.Mean(); Z2[4] = temp.Std(); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); //--- Store the Z-scores temp.CopyIndicatorBuffer(ma_high_handler,0,horizon,bars); Z1[5] = temp.Mean(); Z2[5] = temp.Std(); temp = ((temp - Z1[5]) / Z2[5]); X.Row(temp,6); //--- Store the Z-scores temp.CopyIndicatorBuffer(ma_low_handler,0,horizon,bars); Z1[6] = temp.Mean(); Z2[6] = temp.Std(); temp = ((temp - Z1[6]) / Z2[6]); X.Row(temp,7); //--- Labelling our targets temp.CopyIndicatorBuffer(ma_close_handler,0,0,bars); temp_2.CopyIndicatorBuffer(ma_high_handler,0,0,bars); temp_3.CopyIndicatorBuffer(ma_low_handler,0,0,bars); temp_4.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,bars); //--- Reshape y y.Reshape(4,bars); //--- Store the targets y.Row(temp,0); y.Row(temp_2,1); y.Row(temp_3,2); y.Row(temp_4,3); }
Затем мы определяем функцию для подгонки модели. Эта функция начинается с создания соответствующих матриц и векторов. Мы разлагаем (или факторизуем) матрицу x с помощью библиотеки OpenBlass и сохраняем факторизованные матрицы в переменных, которые мы ввели ранее. Используя готовое решение, мы можем вычислить B по x, а затем вывести на экран коэффициенты, полученные в результате обучения, из матрицы B.
//+------------------------------------------------------------------+ //| Fit our model | //+------------------------------------------------------------------+ void fit(void) { //--- Fit the model matrix OB_U,OB_VT,OB_SIGMA; vector OB_S; PrintFormat("Computing Singular Value Decomposition of %s Data using OpenBLAS",Symbol()); X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); OB_SIGMA.Diag(OB_S); b = y.MatMul(OB_VT.Transpose().MatMul(OB_SIGMA.Inv()).MatMul(OB_U.Transpose())); Print("OLS Solutions: "); Print(b); }
Чтобы сгенерировать прогноз, мы снова загружаем все входные данные — точно так же, как мы делали в функции "prepare_data" — и выполняем одно последнее умножение матриц, чтобы получить прогноз из матрицы B. То есть мы умножаем коэффициенты на входные данные.
//+------------------------------------------------------------------+ //| Get a prediction from our multiple output model | //+------------------------------------------------------------------+ void predict(void) { //--- Prepare to get a prediction //--- Reshape the data X = matrix::Ones(TOTAL_INPUTS,1); //--- Get a prediction temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,0,1); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,0,1); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,0,1); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,1); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); temp.CopyIndicatorBuffer(ma_close_handler,0,0,1); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); temp.CopyIndicatorBuffer(ma_high_handler,0,0,1); temp = ((temp - Z1[5]) / Z2[5]); X.Row(temp,6); temp.CopyIndicatorBuffer(ma_low_handler,0,0,1); temp = ((temp - Z1[6]) / Z2[6]); X.Row(temp,7); Print("Prediction Inputs: "); Print(X); //--- Get a prediction prediction.Reshape(1,4); prediction = b.MatMul(X); Print("Prediction"); Print(prediction); }
Наконец, каждый раз, когда мы получаем обновленные цены в обработчике OnTick, мы вызываем функцию setup. Эта функция вызывает три основные функции, которые мы только что описали. Он подготавливает данные, обучает модель и получает прогноз.
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void setup(void) { prepare_data(); fit(); Print("Training Input Data: "); Print(X); Print("Training Target"); Print(y); predict(); } //+------------------------------------------------------------------+ #undef TOTAL_INPUTS //+------------------------------------------------------------------+
Теперь, когда всё готово, мы можем приступить к тестированию нашего приложения на исторических данных. Как показано ниже на Рисунке 17, мы применили нашу модель к рынку EUR/USD за период с 2022 по 2025 год. Мы проводим бэктестинг на основе двухлетних исторических данных.

Рисунок 17: Наш бэктест охватывает 2 года исторических рыночных данных по паре EURUSD
Мы также выбрали случайные настройки задержки на основе реальных тиков, чтобы получить максимально точное отражение рыночной ситуации. Обязательно используйте те же настройки, если хотите получить реалистичную эмуляцию производительности вашего приложения.
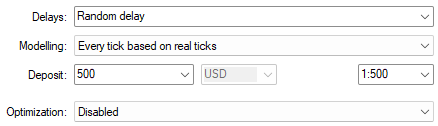
Рисунок 18: Выбор настроек случайной задержки для тестирования нашего торгового приложения в реалистичных рыночных условиях
На Рисунке 18 видно, что наше приложение успешно генерирует четыре независимых прогноза — по одному для каждого интересующего нас уровня цен. Он использует фильтры, разработанные в основной части приложения, для открытия позиций на основе всех четырёх прогнозов.
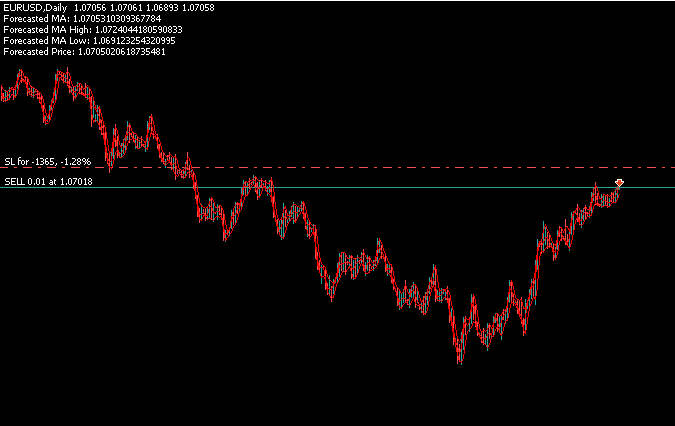
Рисунок 19: Бэктестинг нашего торгового алгоритма для проверки его способности прогнозировать сразу 4 различных целевых уровня
Я приложил скриншот журнала терминала, чтобы показать, что наше приложение действительно обучилось матрице коэффициентов. Как видно, матрица решений состоит из четырёх строк, что означает, что наше приложение обучилось одному уникальному набору коэффициентов для каждой из четырёх целей, которые мы прогнозируем. Приложение обучается каждой цели независимо.
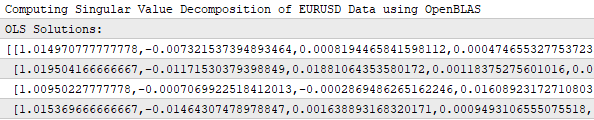
Рисунок 20: Наше торговое приложение обучается уникальному набору коэффициентов для каждой из 4 целей, которые мы ему задали
Кроме того, наше приложение демонстрирует положительную динамику остатка на счете с течением времени. Хотя мы хотели бы сгладить неровности в этом балансе, мы будем продолжать совершенствовать систему, чтобы обеспечить более стабильный рост.
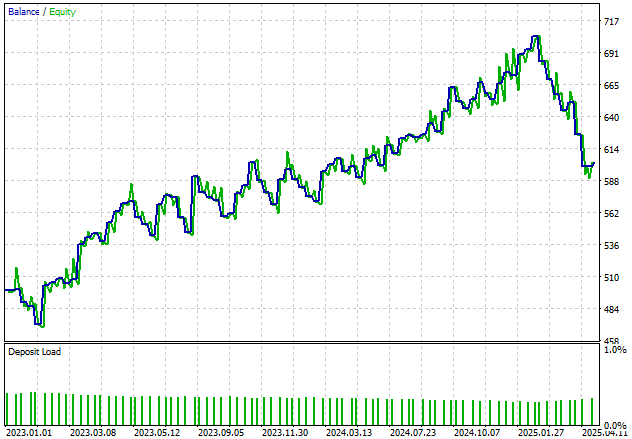
Рисунок 21: Визуализация роста кривой капитала нашего счета за двухлетний период бэктестирования
При детальном анализе результатов работы счета мы обнаружили, что 51 % наших сделок оказались прибыльными. Хотя это неплохой старт, в будущем мы намерены довести этот показатель до 55 % или даже 60 %. Пока что у нас все идет хорошо: наша средняя прибыль превышает средний убыток, а максимальная прибыль почти вдвое превышает максимальный убыток. Это свидетельствует о том, что система работает надежно, хотя мы по-прежнему планируем её усовершенствовать.
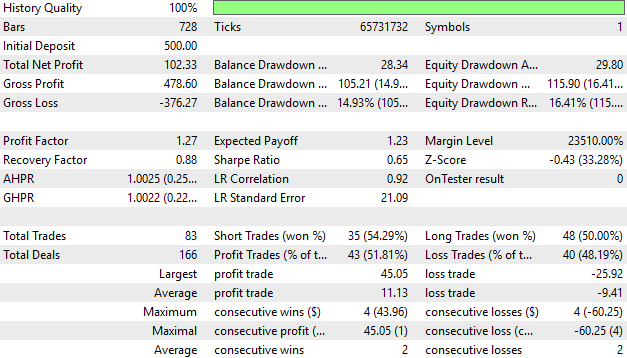
Рисунок 22: Подробный анализ производительности нашего торгового приложения в ходе тестирования на исторических данных
Заключение
В заключение, в данной статье читателю было продемонстрировано, насколько важно глубоко понимать концепции линейной алгебры и как они напрямую влияют на нашу способность работать с рыночными данными в терминале MetaTrader 5. Без этого понимания анализ больших объемов рыночных данных становится чрезвычайно сложной задачей. Освоив всего несколько ключевых принципов линейной алгебры и увидев, как они реализуются в MQL5, мы получаем возможность гораздо быстрее и надежнее извлекать полезную информацию из рынка.В ходе дальнейшего обсуждения мы расскажем читателю, как использовать инструменты линейной алгебры и адаптировать их для MQL5 с целью создания численно устойчивых и быстрых торговых алгоритмов. Прочитав эту статью, читатель теперь сможет разрабатывать алгоритмы, работающие за практически постоянное время, что позволит быстро проводить бэктестинг и совершенствовать свои приложения, даже если ему потребуется одновременно прогнозировать несколько целевых показателей.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18974
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования