
重构经典策略(第十三部分):让我们的交叉策略迈向新维度(2)

在之前关于移动平均线交叉的讨论中,我们探讨了如何尽量减少移动平均线固有的滞后性。移动平均线交叉策略以产生延迟信号而闻名。我们曾分享,通过将两条移动平均线的周期都固定为同一数值(例如在我们之前的讨论中使用的周期数为3),可以获得响应更灵敏的交易信号。这种改进源于将移动平均线指标分别应用于开盘价和收盘价,即使它们周期相同。将它们应用于不同的价格水平,我们仍能确保观察到开盘价移动平均线和收盘价移动平均线之间的交叉。与此同时,通过使用小于5的短周期的方法,减少了系统的滞后性。
我们已经证明,与经典的移动平均线交叉策略相比,该策略具有明显的优势。在初次讨论中,我们将这一新提出的交叉策略与经典策略进行了对比。在本文中,我们将继续改进移动平均线交叉策略,尝试通过探索是否能够预测交叉发生之前的情况,来进一步减少固有的滞后性。这样一来,使我们能够主动交易,更迅速地应对交易机会。典型的市场参与者通常等待确认,在交叉明显后才做出反应。与此不同,我们的日标是构建一个统计模型,它能够提前检测到交叉信号,从而在行情展开前完成账户仓位的调整。
尽管在市场噪音中识别交易信号颇具挑战性,但多项数据科学原理可助力强化我们的策略。例如,我们参考了美国国家航空航天局(NASA)喷气推进实验室团队(JPL)在加州理工学院(Caltech)所做的一场报告,该报告提供了宝贵的见解。报告链接请参见此处。该报告聚焦于大数据领域,并引入了一个与我们此次讨论紧密相关的关键原理。感兴趣的读者可以自行查阅报告幻灯片。简而言之,该原理指出,当把数据科学中的某些难题投影到更高维度的空间时,这些难题会变得更容易解决。为方便读者,我们在下文图1中纳入了与本次讨论相关的报告原文摘录。
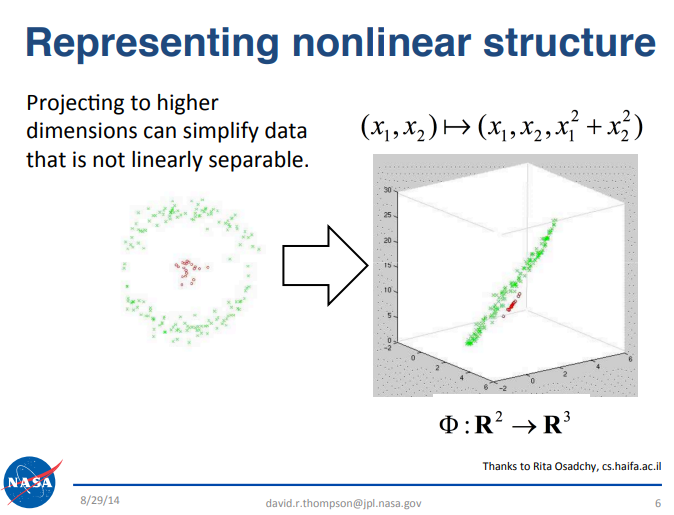
图1:上图幻灯片是2014年9月,美国国家航空航天局(NASA)喷气推进实验室(JPL)团队在加州理工学院(Caltech)进行“大数据分析”公开报告的一部分内容
例如,设想一个包含三个特征的数据集,其目标是区分市场上涨日和下跌日。在这个低维(三维)空间中,要实现较高的分类准确率可能颇具难度。然而,将数据集投影到更高维空间后,性能可以得到提升,这是因为在更高维的特征空间中,一些问题变得更容易分离。尽管机器学习并非在所有情况下都能保证成功,但这种方法往往能取得更好的效果,而且通常值得一试。
这一原理与在该系列相关文章中的过往讨论形成了鲜明的对比,例如在《MQL5中的自优化智能交易系统》一文中,我们探讨了使用UMAP等降维技术将数据集从30个特征降至4个的好处。通常情况下,我们专注于降低维度以简化模型并提高泛化能力。然而,本文将采取相反的途径,即有意识地增加数据集的维度,并将展示这样的操作可能带来的实际价值。
在本文中,我们将阐述一种人工精心设计的方法,用于生成大量新的特征列。在未来的讨论中,我们将采用更灵活的算法技术来生成特征。
MQL5入门指南
首先,我们将编写一个脚本,用于从MetaTrader 5交易终端中获取所有必要的数据。我们先来设定一些与本次讨论相关的常量。例如,将所有移动平均线的周期设置为固定值,并且在本文的讨论中全程使用简单移动平均线。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 2 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 5 //--- Forecast horizon
此外,我们还将定义一些全局变量,比如用于移动平均线指标的句柄和缓冲区。
//--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000;
接下来,我们开始定义脚本的主体部分。脚本执行时,我们将初始化移动平均线句柄,然后将其数值复制到对应的缓冲区中。在准备将数据写入文件时,应当注意的是,需要填充的列非常多。前八列是标准列:开盘价、最高价、最低价、收盘价,以及它们各自对应的移动平均线。除此之外,我们还添加了表示每个价格序列内部增长情况的列。
此外,还有一些列专门用于计算不同价格水平之间的相对变化。例如,除了计算开盘价相对于其历史值的变化外,我们还计算开盘价相对于收盘价的变化、开盘价相对于最低价的变化,以此类推。对移动平均线也重复同样的计算。整个过程在数据集中生成了40列数据。最后,我们存储要写入的实际值,然后关闭文件句柄。
//+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA C", "True MA O", "True MA H", "True MA L", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Close 2", "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2", //--- Grwoth between channels "O - C", "Delta O - C", "O - L", "Delta O - L", "O - H", "Delta O - H", "H - L", "Delta H - L", "C - H", "Delta C - H", "C - L", "Delta C - L", //--- Grwoth between MA channels "MA O - C", "MA Delta O - C", "MA O - L", "MA Delta O - L", "MA O - H", "MA Delta O - H", "MA H - L", "MA Delta H - L", "MA C - H", "MA Delta C - H", "MA C - L", "MA Delta C - L" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_reading[i], ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_reading[i] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), //--- Growth between moving average channels ma_o_reading[i] - ma_reading[i], ma_o_reading[(i + HORIZON)] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_l_reading[i], ma_o_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_o_reading[i] - ma_h_reading[i], ma_o_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_h_reading[i] - ma_l_reading[i], ma_h_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_reading[i] - ma_h_reading[i], ma_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_reading[i] - ma_l_reading[i], ma_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
在Python中分析我们的数据
既然已经完成了将脚本部署到终端并提取所需数据的操作,那么就可以开始分析和处理这些数据了。首先,我们将加载用于数值分析的标准库。
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
接下来,我们将读取数据集。您会发现,该数据集的列数相当多,部分列由于显示空间有限而被截断未显示。
data = pd.read_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\EURUSD Market Data As Series Moving Average.csv")
data 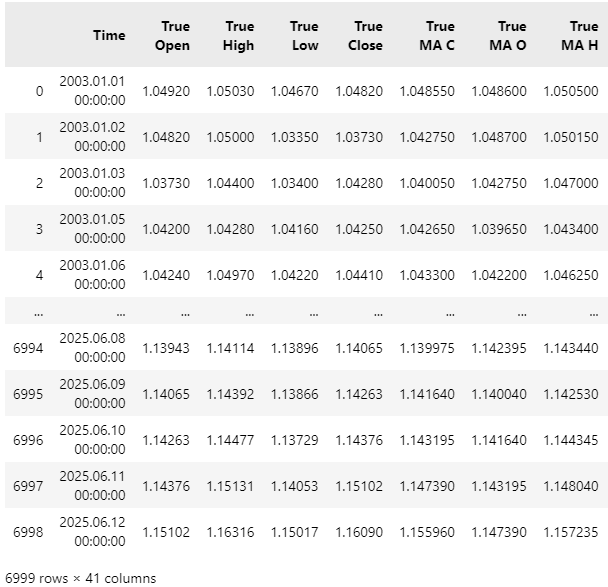
图2:可视化我们从MetaTrader 5交易终端获取的数据
接下来,我们将定义目标变量。回想一下,在这个例子中,目标变量是移动平均线之间的交叉。追踪这一交叉的直接方法是监测两条移动平均线之间的中点。通过观察中点是上升还是下降,我们实际上就为统计模型捕捉到了相同的信息。
HORIZON = 10 #Classical Target data['Target'] = 0 #High Low Mid Point Target data['Target 2'] = 0 #Open Close Mid Point Target data['Target 3'] = 0 data.loc[data['True Close'].shift(-HORIZON) > data['True Close'],'Target'] = 1 #The Mid Point Between The High And The Low Moving Average data.loc[((data['True MA H'].shift(-HORIZON) + data['True MA L'].shift(-HORIZON)) / 2) > ((data['True MA H'] + data['True MA L']) / 2),'Target 2'] = 1 #The Open And Close Mid Point data.loc[((data['True MA O'].shift(-HORIZON) + data['True MA C'].shift(-HORIZON)) / 2) > ((data['True MA O'] + data['True MA C']) / 2),'Target 3'] = 1 data = data.iloc[:-HORIZON,:]
在继续深入探讨之前,我想先简要演示将数据集投影到更高维度的价值。对于可能不熟悉这一原理的读者,此举可作为一个简单证明,以确保我们的理解一致。我们首先创建一个仅包含标准四列(开盘价、最高价、最低价和收盘价)的原始数据集副本。随后,我们将基于这个缩减后的数据集重新计算目标变量。
#Copy the dataset X = data.iloc[:,:5].copy() X['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] X.dropna(inplace=True)
接下来,我们将定义一个函数,该函数接收一个数据集,并追加任意数量的、填充为0的列。例如,如果使用此数据集副本调用该函数,并指定要添加五列,将返回一个新增了五列的数据集,其中每一列的各单元格均填充为0。
def fill_zeros(f_data,f_n): #Copy the original data res = f_data.copy() #We want to keep the target at the end t = 'Target' v = res.pop('Target') #Add columns of zeros for i in np.arange(f_n): name = str(i) + ' Col' res[name] = 0 #Place the target back res[t]= v #Return the new dataframe return(res)
接下来,我们将进行一项简单的测试:在不断增加0填充列的情况下,对模型进行交叉验证,并观察交叉验证误差的变化情况。请注意,生成的图表并不平滑,这表明误差随着维度的增加而波动。
然而,图表清晰地显示,后期达到的误差水平低干前期。在最初阶段,我们观察到的是模型在没有添加任何零填充列时的误差水平。随着0填充列数量的增加,误差通常会先急剧上升,然后下降到之前未曾达到过的更低水平。这一观察结果值得思考:在未提供任何额外信息的情况下(请牢记,0填充列对模型而言不包含任何有用的数据),模型的性能为何还能得到提升?
#Load our libraries from sklearn.neural_network import MLPRegressor from sklearn.model_selection import cross_val_score,TimeSeriesSplit tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) EPOCHS = 50 #Observe what happens to our error levels as we increase the number of columns in the dataset res = [] for i in np.arange(EPOCHS): #Fetch new data with addtional columns of zeros new_data = fill_zeros(X,(1+i)) #Record the new error res.append(np.mean(np.abs(cross_val_score(MLPRegressor(hidden_layer_sizes=(new_data.iloc[:,1:-1].shape[1],2,50,100),random_state=0,shuffle=False),X.iloc[:,1:-1],X.iloc[:,-1],cv=tscv,n_jobs=-1)))) plt.plot(res,color='black') plt.grid() plt.ylabel('RMSE Error') plt.xlabel('Additional Columns of Zero') plt.title('Our Error Levels Can Fall Without Any New Information')
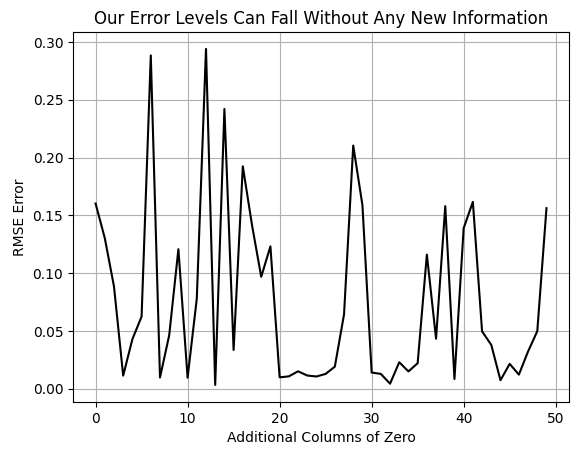
图3:尽管我们并未提供任何额外的信息,但是模型的误差水平却在下降
对于这一现象,存在几种合理的解释。就本次讨论而言,我们将采纳这样一种观点:增加维度具有内在价值。我们认为,这证明了将数据投影到更高维空间是有用的。尽管确实存在其他合理的解释,但就本次讨论而言,这一观察结果为我们数据集创建的32个手工特征列提供了理论依据。我们相信,通过增加更多特征列,我们能够再次将误差降至新的低点。不过,这一次我们打算添加的是有意义的信息,而非0值。
明确目标后,我们现在开始确定输入列与输出列。首先,我们将所有输入列收集起来,并存储在一个名为X的变量中。
X = data.iloc[:,1:-4].columns
接下来,我们列出目标变量。
y2 = data['Target 2']
我们还需要定义一个函数,用于返回我们统计模型的一个全新实例。
return(RandomForestClassifier(random_state=0,n_estimators=500,max_depth=3,min_samples_leaf=20))
接下来,我们将排除与回测期间存在重叠的任何数据,以免模型过度拟合所有可用数据。预留一部分数据专门用于测试,这一点非常重要。完成上述步骤后,我们对数据集进行标准化和缩放处理:针对40列中的每一列,分别减去列均值并除以列标准差。这一过程将生成一个经过缩放的数据集。
data = data.iloc[:-(365*2),:] Z = pd.DataFrame(columns=['Z1','Z2']) Z['Z1'] = data.loc[:,X].mean() Z['Z2'] = data.loc[:,X].std() data.loc[:,X] = (data.loc[:,X] - data.loc[:,X].mean()) / data.loc[:,X].std()
最后,在准备将模型以ONNX格式导出,以便在MQL5中使用之前,我们先将模型拟合到所有训练数据上。
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.ensemble import GradientBoostingRegressor model = GradientBoostingRegressor(random_state=0,max_depth=3) model.fit(data.loc[:,X],data.loc[:,'Target 2']) initial_types = [("FLOAT INPUT",FloatTensorType([1,len(X)]))] model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) onnx.save(model_proto,"EURUSD GBR PRICE D1.onnx")
整合所有环节
现在,我们已准备好开始构建我们的智能交易系统(EA)。我们的首要任务是定义那些不会更改的全局常量。请注意,其中许多定义与我们在之前的数据获取脚本中所设定的相同。具体而言,移动平均线的周期和类型将保持不变,仍采用相同的数值。此外,我们还定义了每笔头寸的持仓时长,以及我们将进行交易的时间框架。
//+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //--- Define our moving average indicator #define MA_PERIOD 2 //Moving Average Period #define MA_TYPE MODE_SMA //Type of moving average we have #define HORIZON 10 //Forecast horizon #define TF PERIOD_D1
接下来,我们声明一些重要的全局变量。例如,对数据集进行标准化和缩放的Z1和Z2分数必须在EA中保留。此外,我们还需要为移动平均线处理器及其对应的缓冲区设置全局变量。
//+------------------------------------------------------------------+ //| Global definitions | //+------------------------------------------------------------------+ float Z1[] = { 1.23933432e+00, 1.24403263e+00, 1.23474846e+00, 1.23936216e+00, 1.23935910e+00, 1.23933128e+00, 1.24402971e+00, 1.23474522e+00, 3.83991053e-05, 3.60920275e-05, 3.66240614e-05, 3.55759706e-05, 3.68749001e-05, 3.98194600e-05, 3.78958300e-05, 3.79070139e-05, -2.78415082e-05, -3.06646429e-05, 4.58586036e-03, 4.58408532e-03, -4.69831123e-03, -4.70061831e-03, 9.28417159e-03, 9.28470363e-03, -4.67046972e-03, -4.66995367e-03, 4.61370187e-03, 4.61474996e-03, -2.78151462e-05, -3.07597060e-05, 4.58606247e-03, 4.58415002e-03, -4.69842067e-03, -4.70034430e-03, 9.28448314e-03, 9.28449433e-03, -4.67060553e-03, -4.66958460e-03, 4.61387762e-03, 4.61490973e-03 }; float Z2[]= { 0.12576155, 0.12640182, 0.125071, 0.12572605, 0.12568469, 0.125719, 0.12636385, 0.12503521, 0.0150256, 0.01494947, 0.01478075, 0.01493629, 0.0141562, 0.01423137, 0.01419596, 0.01404453, 0.00669432, 0.0066951, 0.00482275, 0.004823, 0.00493041, 0.00493002, 0.0063063, 0.00630607, 0.0048614, 0.0048616, 0.00471017, 0.0047104, 0.00471147, 0.00471252, 0.00361188, 0.00361259, 0.00371563, 0.00371488, 0.00513505, 0.00513498, 0.0037117, 0.0037125, 0.00353196, 0.00353191 }; //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; int fetch = HORIZON * 2; int timer = 0; int state = 0;
此外,我们还会将ONNX模型作为资源加载到EA中。
//+------------------------------------------------------------------+ //| Resources | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| DISCLAIMER | //| This ONNX model was trained from 1 January 2003 until 29 January | //| 2023. For reliable results, ensure that all back tests are done | //| beyond the model's training period. | //+------------------------------------------------------------------+ #resource "\\Files\\MA Approximation\\EURUSD GBR MA D1.onnx" as const uchar onnx_proto[];
我们还将加载必要的库和依赖项。例如,有一款专为交易管理设计的MQL5库,以及一个经过长期开发、用于处理ONNX模型和获取交易信息的自定义库。
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; ONNXFloat *onnx_handler; Time *time_handler; TradeInfo *trade_handler;
在初始化EA的过程中,我们将加载所有这些库和技术指标。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- onnx_handler = new ONNXFloat(onnx_proto); time_handler = new Time(Symbol(),TF); trade_handler = new TradeInfo(Symbol(),TF); Print("Onnx Handler Pointer: ",onnx_handler); onnx_handler.DefineOnnxInputShape(0,1,40); onnx_handler.DefineOnnxOutputShape(0,1,1); //---Setup our technical indicators ma_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //--- return(INIT_SUCCEEDED); }
为确保内存的安全管理,我们将删除所有动态创建的对象,并释放不再使用的技术指标。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(ma_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_h_handle); IndicatorRelease(ma_l_handle); delete time_handler; delete trade_handler; delete onnx_handler; }
每当收到价格更新时,我们会验证是否已形成新的K线。如果是,我们将先更新技术指标,再检查是否存在交易信号。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time_handler.NewCandle()) { update(); check_signal(); } }
更新技术指标的方法如下:首先,我们将所有指标读数复制到其关联的缓冲区中。这为我们的ONNX模型准备好了输入向量。该模型将接受与之前分配相同的40个输入参数。在将这些输入传递给模型之前,我们先对它们进行标准化和缩放处理。随后,模型将生成预测结果。
//+------------------------------------------------------------------+ //| Update our technical data | //+------------------------------------------------------------------+ void update(void) { //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); vectorf model_input_vector = { //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0), iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0), //--- MA OHLC ma_reading[0], ma_o_reading[0], ma_h_reading[0], ma_l_reading[0], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), //--- Growth in MA OHLC ma_reading[0] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_o_reading[(0 + HORIZON)], ma_h_reading[0] - ma_h_reading[(0 + HORIZON)], ma_l_reading[0] - ma_l_reading[(0 + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), //--- Growth between moving average channels ma_o_reading[0] - ma_reading[0], ma_o_reading[(0 + HORIZON)] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_l_reading[0], ma_o_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_o_reading[0] - ma_h_reading[0], ma_o_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_h_reading[0] - ma_l_reading[0], ma_h_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_reading[0] - ma_h_reading[0], ma_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_reading[0] - ma_l_reading[0], ma_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)] }; for(int i =0;i<40;i++) { model_input_vector[i] = ((model_input_vector[i] - Z1[i]) / Z2[i]); } onnx_handler.Predict(model_input_vector); }
我们的信号检查函数如预期运行。首先,如果当前没有持仓,我们会重置计时器,从而重置系统状态。如果ONNX模型预测价格将上涨,我们将开立买入头寸;如果预测价格将下跌,我们将开立卖出头寸。请注意,看涨和看跌信号对应于模型输出的类别概率:概率大于0.5预示价格上涨,概率小于0.5预示价格下跌。
除了ONNX模型的信号外,我们还需要确认移动平均线交叉模式。如果已有持仓,我们会跟踪计时器,一旦计时器接近预设的头寸到期时间,我们将所有持仓平仓,并重新开始这一周期。
//+------------------------------------------------------------------+ //| Check if we have oppurtunities to trade | //+------------------------------------------------------------------+ void check_signal(void) { if(PositionsTotal() == 0) { timer = 0; state = 0; if(onnx_handler.GetPrediction() > 0.5 { state =1; Trade.Buy(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetAsk(),0,0,""); } else if(onnx_handler.GetPrediction() < 0.5 && ma_reading[0] < ma_o_reading[0]) { state =-1; Trade.Sell(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetBid(),0,0,""); } } else { timer++; if(timer >= HORIZON) Trade.PositionClose(Symbol()); } }
最后,请务必取消所有系统定义的设定。
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE #undef TF
现在,我们准备使用模型在训练期间未见过的数据进行测试。选择所有不在训练期范围内的日期,请注意,训练期截止于2023年1月29日。
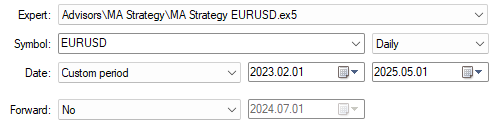
图4:我们的回测日期始终处于向模型展示的训练期的范围之外
请务必选择“随机延迟”,以便有效模拟真实交易时段中不可预测的特性。
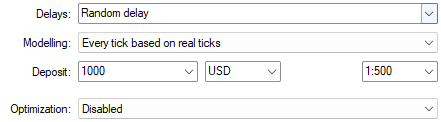
图5:选择“随机延迟”,以获得最稳健的回测设置
我们的策略生成了如图6所示的资金曲线。令我们欣慰的是,即使使用模型未见过的数据进行测试,策略仍然成功地保持了正向上升趋势。通过使用生成的40个数据列,以高分辨率的市场图景训练模型,模型可能因此具备了更好的泛化能力,从而能够适应未曾训练过的市场条件。
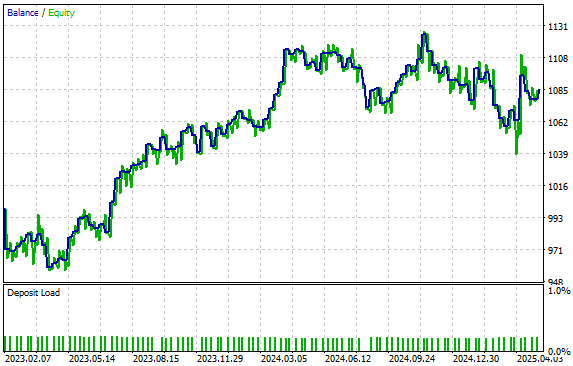
图6:展示我们统计模型生成的资金曲线
最后,我们随时可以查阅策略表现的总结详情。由此可见,该策略所执行的交易中有52.9%实现盈利,且平均盈利通常预期将大于平均亏损。这些统计数据令人鼓舞,证明投入时间精心构建数据集的详细特征虽然可能颇为繁琐,但是当其带来回报时,所有的额外努力都是值得的。
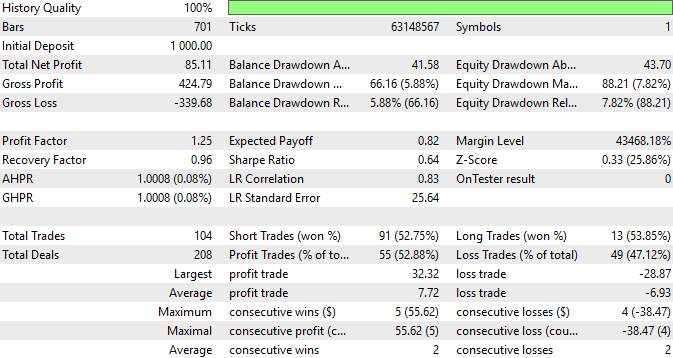
图7:我们交易应用性能表现的深度总结
结论
总之,本文为读者提供了诸多实用见解,阐述了如何对既定策略进行重新构思并赋予其新能力。
通过运用数据科学中广为人知的原理,例如模型有时在高维空间中表现更优的特性,我们得以持续减轻移动平均线交叉策略中的滞后问题。通过手工精心构建丰富的数据集,我们实现了这一点,使模型能够对市场形成高分辨率的理解。尽管这些数据科学原理已经得到充分论证,但是合理设定预期仍然至关重要。
需要注意的是,将数据集扩展至更高维度并不总能保证提升性能。相反,读者们应该认识到,探究将数据集投影至更高维度是否能带来改进始终是有益的。这种方法虽无法保证,但始终值得探索。还需了解到,通过批判性思维和创造力,可以挑战并有效解决技术指标中存在的滞后问题。MetaTrader 5交易终端似乎蕴含着巨大的潜力。
| 文件名 | 文件描述 |
|---|---|
| EURUSD GBR MA D1.onnx | 我们共同使用高维列数据集构建的ONNX模型。 |
| Proof of Case Article.ipynb | 我们共同编写的展示将数据投影至高维空间之优势的Jupyter Notebook。 |
| MA Strategy EURUSD.ex5 | 我们为利用手工制作的数据集而开发的交易应用程序的编译版本。 |
| Fetch Data MA.mq5 | 我们编写的获取高维数据集并将其写入CSV文件的MQL5脚本。 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18525
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
