
古典的な戦略を再構築する(第13回):クロスオーバー戦略を新たな次元へ(その2)

前回の移動平均クロスオーバーに関する議論では、移動平均に内在するラグをどのように最小化するかを検討しました。移動平均クロスオーバーは、シグナルの発生が遅れることでよく知られています。そこで、両方の移動平均の期間を同一の値(例えば前回の議論で使用した期間3)に固定することで、より応答性の高い売買シグナルを得ることができると述べました。この改善は、同じ期間を共有しながらも、始値と終値に対して移動平均指標を個別に適用することによって生じます。これらを異なる価格系列に配置することで、始値と終値の移動平均間でクロスオーバーが発生することは引き続き保証されます。同時に、このアプローチは短い期間(通常は5未満)を用いることで、システム全体のラグを低減します。
この戦略は従来の移動平均クロスオーバー手法に対して優位性があることも確認しました。前回は、この新しいクロスオーバー戦略と従来手法を比較しました。本記事では、移動平均クロスオーバー戦略をさらに発展させ、クロスオーバーが発生する前にそれを予測できるかを検討することで、内在するラグをさらに低減することを試みます。これにより、より能動的に取引をおこない、取引機会に対して迅速に対応できるようになります。一般的な市場参加者のように、クロスオーバーの発生を確認してから反応するのではなく、クロスオーバーを事前に検出できる統計モデルを構築し、値動きが展開する前に適切にポジションを取ることを目指します。
市場ノイズの中で売買シグナルを検出することは困難ですが、いくつかのデータサイエンスの原理は戦略の強化に役立ちます。例えば、カリフォルニア工科大学(Caltech)のNASAジェット推進研究所(JPL)チームによるプレゼンテーションでは、貴重な知見が示されています。プレゼンテーションはこちらからご覧いただけます。この発表はビッグデータをテーマとしており、本稿の議論に関連する重要な原理を紹介しています。関心のある読者はスライドをご自身で確認されることを推奨します。 簡単にまとめると、この原理は「データサイエンスにおける一部の困難な問題は、高次元空間へ射影することで解きやすくなる場合がある」というものです。読者の便宜のため、本記事の議論に関連する該当スライドの抜粋を図1に掲載します。
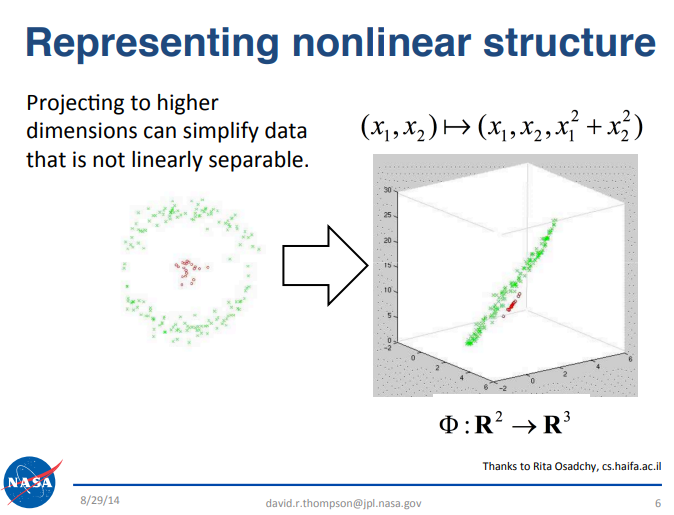
図1:上記のスライドは、2014年9月にカリフォルニア工科大学のNASA JPLチームが公開した『Big Data Analytics』プレゼンテーションの一部である
たとえば、3つの特徴量を持つデータセットで、強気と弱気の市場日を分類する場合を考えます。このような低次元(3次元)の空間では、高い分類精度を達成することは難しい場合があります。しかし、データを高次元に射影することで、問題がより分離可能になり、分類性能が向上する場合があります。機械学習が必ずしもすべててのケースで成功を保証するわけではありませんが、このアプローチは多くの場合有効であり、試す価値があります。
この原理は、これまでの関連連載(例:「MQL5で自己最適化エキスパートアドバイザーを構築する」)で扱ってきた次元削減の手法とは対照的です。これまでの議論では、UMAPなどの次元削減技術を用いて、30次元のデータセットを4次元に圧縮することにより、モデルを単純化し、汎化性能を向上させることを目的としていました。しかし、本稿では逆のアプローチを採用し、意図的にデータセットの次元を増加させることで、実務上の価値を示すことを目指します。
本記事ではまず、多数の新しい特徴量カラムを生成するための手作業による方法を導出します。今後の記事では、より柔軟なアルゴリズムベースの特徴量生成手法についても扱う予定です。
MQL5で始める
まず最初に、MetaTrader 5ターミナルから必要なデータをすべて取得するスクリプトを作成します。その前提として、本記事で扱ういくつかの定数を固定します。たとえば、すべての移動平均の期間を一定値に設定し、以降の議論では単純移動平均(SMA)を使用します。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 2 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 5 //--- Forecast horizon
さらに、移動平均インジケーター用のハンドラやバッファなどのグローバル変数も定義します。
//--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000;
次に、スクリプトの本体部分を定義します。スクリプトが実行されたら、まず移動平均のハンドラを初期化し、それらのハンドラから値を対応するバッファにコピーします。データをファイルに書き出す準備をする際には、多くの列を埋める必要があることに注意してください。最初の8列は標準的なもので、始値、高値、安値、終値およびそれぞれの移動平均が含まれます。これに加えて、各価格フィードで発生する成長を表す列も含めます。
さらに、異なる価格レベル間の相対変化を計算するための列も用意します。たとえば、始値の過去値との変化を計算するだけでなく、始値と終値の相対変化、始値と安値の相対変化なども計算します。同様の計算を移動平均についても繰り返します。このプロセスにより、最終的にデータセットには合計で40個の特徴量列が生成されます。最後に、書き出す対象の実際の値を保存し、ファイルハンドラを閉じます。
//+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA C", "True MA O", "True MA H", "True MA L", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Close 2", "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2", //--- Grwoth between channels "O - C", "Delta O - C", "O - L", "Delta O - L", "O - H", "Delta O - H", "H - L", "Delta H - L", "C - H", "Delta C - H", "C - L", "Delta C - L", //--- Grwoth between MA channels "MA O - C", "MA Delta O - C", "MA O - L", "MA Delta O - L", "MA O - H", "MA Delta O - H", "MA H - L", "MA Delta H - L", "MA C - H", "MA Delta C - H", "MA C - L", "MA Delta C - L" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_reading[i], ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_reading[i] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), //--- Growth between moving average channels ma_o_reading[i] - ma_reading[i], ma_o_reading[(i + HORIZON)] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_l_reading[i], ma_o_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_o_reading[i] - ma_h_reading[i], ma_o_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_h_reading[i] - ma_l_reading[i], ma_h_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_reading[i] - ma_h_reading[i], ma_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_reading[i] - ma_l_reading[i], ma_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Pythonでのデータ分析
スクリプトをターミナルにデプロイし、必要なデータの抽出が完了したので、次はデータの分析と処理を開始します。まず、数値解析のための標準ライブラリを読み込みます。
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
次に、データセットを読み込みます。ご覧の通り、このデータセットは列数が非常に多く、一部の列は表示上省略されています。
data = pd.read_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\EURUSD Market Data As Series Moving Average.csv")
data 
図2:MetaTrader 5ターミナルから取得したデータの可視化
続いて、ターゲット変数を定義します。この例では、ターゲットは移動平均のクロスオーバーです。このクロスオーバーを追跡する簡単な方法として、2本の移動平均の中点を監視します。この中点が上昇したか下降したかを観察することで、統計モデルにとって同等の情報を取得できます。
HORIZON = 10 #Classical Target data['Target'] = 0 #High Low Mid Point Target data['Target 2'] = 0 #Open Close Mid Point Target data['Target 3'] = 0 data.loc[data['True Close'].shift(-HORIZON) > data['True Close'],'Target'] = 1 #The Mid Point Between The High And The Low Moving Average data.loc[((data['True MA H'].shift(-HORIZON) + data['True MA L'].shift(-HORIZON)) / 2) > ((data['True MA H'] + data['True MA L']) / 2),'Target 2'] = 1 #The Open And Close Mid Point data.loc[((data['True MA O'].shift(-HORIZON) + data['True MA C'].shift(-HORIZON)) / 2) > ((data['True MA O'] + data['True MA C']) / 2),'Target 3'] = 1 data = data.iloc[:-HORIZON,:]
さらに処理を進める前に、データセットを高次元に射影することの価値を簡単に示します。この原理に馴染みのない読者のために、全員が同じ理解に立てるような簡単な検証をおこないます。 まず、元のデータセットから標準的な4列(始値・高値・安値・終値)のみを含むコピーを作成します。その後、この縮小されたデータセット上でターゲット変数を再計算します。
#Copy the dataset X = data.iloc[:,:5].copy() X['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] X.dropna(inplace=True)
次に、データセットを受け取り、ゼロで埋められた任意の数の列を追加する関数を定義します。たとえば、データセットのコピーでこの関数を呼び出し、5つの列を指定すると、各列がゼロで埋められた5つの追加列を含むデータセットが返されます。
def fill_zeros(f_data,f_n): #Copy the original data res = f_data.copy() #We want to keep the target at the end t = 'Target' v = res.pop('Target') #Add columns of zeros for i in np.arange(f_n): name = str(i) + ' Col' res[name] = 0 #Place the target back res[t]= v #Return the new dataframe return(res)
その後、ゼロで埋められた列の数を徐々に増やしながらモデルのクロスバリデーションを実行し、誤差への影響を観察します。結果として得られるグラフは滑らかではなく、次元の増加に伴う誤差の変動が見られます。
しかし重要なのは、誤差がこれまで到達できなかった新たな低水準に達している点です。最初は追加列がない状態での誤差が観察されますが、ゼロ列の数が増えるにつれて誤差は一旦増加し、その後これまでより低い値へと低下します。この結果は、モデルに有益な情報を一切追加していないにもかかわらず、なぜ性能が向上するのかという疑問を生じさせます。なお、これらのゼロ列はモデルにとって有用な情報を一切含んでいません。
#Load our libraries from sklearn.neural_network import MLPRegressor from sklearn.model_selection import cross_val_score,TimeSeriesSplit tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) EPOCHS = 50 #Observe what happens to our error levels as we increase the number of columns in the dataset res = [] for i in np.arange(EPOCHS): #Fetch new data with addtional columns of zeros new_data = fill_zeros(X,(1+i)) #Record the new error res.append(np.mean(np.abs(cross_val_score(MLPRegressor(hidden_layer_sizes=(new_data.iloc[:,1:-1].shape[1],2,50,100),random_state=0,shuffle=False),X.iloc[:,1:-1],X.iloc[:,-1],cv=tscv,n_jobs=-1)))) plt.plot(res,color='black') plt.grid() plt.ylabel('RMSE Error') plt.xlabel('Additional Columns of Zero') plt.title('Our Error Levels Can Fall Without Any New Information')
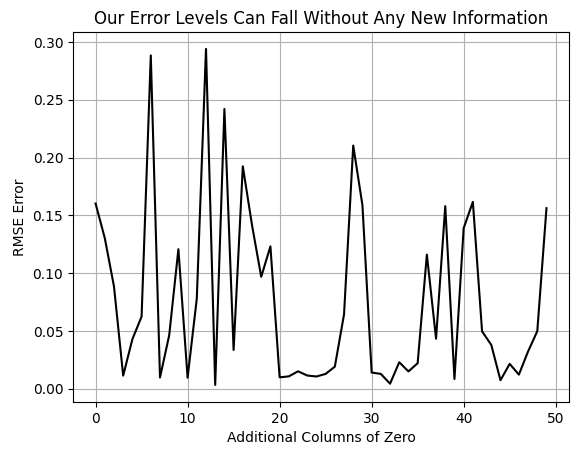
図3:新たな情報を追加していないにもかかわらず、モデルの誤差が低下している
この現象にはいくつかのもっともらしい説明が存在します。本記事では、次元を増やすこと自体に内在的な価値があるという立場を採用します。これは、データをより高次元の空間へ射影することの有用性を支持する証拠であると解釈します。もちろん他にも妥当な説明は存在しますが、本稿においては、この観察結果を、私たちがデータセットのために作成した32個の手作り特徴量列の動機付けとして位置づけます。追加する列数を増やすことで、再び誤差をさらに低減できると考えています。ただし今回は、単にゼロを追加するのではなく、意味のある情報を付加することを目指します。
以上の動機付けを踏まえたうえで、次に入力列と出力列の特定へと進みます。まず、すべての入力列を収集し、変数Xに格納します。
X = data.iloc[:,1:-4].columns
次に、目的変数を定義します。
y2 = data['Target 2']
また、統計モデルの新しいインスタンスを返す関数を定義する必要があります。
return(RandomForestClassifier(random_state=0,n_estimators=500,max_depth=3,min_samples_leaf=20))
さらに、バックテスト期間と重複するデータは除外します。すべての利用可能なデータにモデルを過度に適合させてしまうことを防ぐためであり、一部のデータはテスト専用として確保しておくことが重要です。その後、データセットの標準化およびスケーリングをおこないます。具体的には、各列の平均値を引き、標準偏差で割る処理を、40個すべての特徴量列に対して実施します。この処理により、スケーリングされたデータセットが得られます。
data = data.iloc[:-(365*2),:] Z = pd.DataFrame(columns=['Z1','Z2']) Z['Z1'] = data.loc[:,X].mean() Z['Z2'] = data.loc[:,X].std() data.loc[:,X] = (data.loc[:,X] - data.loc[:,X].mean()) / data.loc[:,X].std()
最後に、すべての訓練データを用いてモデルを学習させ、その後、MQL5で利用可能とするために、モデルをONNX形式でエクスポートする準備をおこないます。
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.ensemble import GradientBoostingRegressor model = GradientBoostingRegressor(random_state=0,max_depth=3) model.fit(data.loc[:,X],data.loc[:,'Target 2']) initial_types = [("FLOAT INPUT",FloatTensorType([1,len(X)]))] model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) onnx.save(model_proto,"EURUSD GBR PRICE D1.onnx")
全体のまとめ
これで、エキスパートアドバイザ(EA)の構築を開始する準備が整いました。まず最初に、変更されることを想定していないグローバル定数を定義します。これらの定義の多くは、先に作成したデータ取得スクリプトで設定したものと同じです。具体的には、移動平均の期間および移動平均の種類は同一の値に固定されています。さらに、各ポジションを保有する期間や、取引をおこなう時間足についても定義しています。
//+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //--- Define our moving average indicator #define MA_PERIOD 2 //Moving Average Period #define MA_TYPE MODE_SMA //Type of moving average we have #define HORIZON 10 //Forecast horizon #define TF PERIOD_D1
次に、重要なグローバル変数を宣言します。たとえば、データセットの標準化およびスケーリングに使用したZ1およびZ2のスコアは、EA内でも保持しておく必要があります。また、移動平均のハンドラや、それに対応するバッファについても、グローバル変数として定義する必要があります。
//+------------------------------------------------------------------+ //| Global definitions | //+------------------------------------------------------------------+ float Z1[] = { 1.23933432e+00, 1.24403263e+00, 1.23474846e+00, 1.23936216e+00, 1.23935910e+00, 1.23933128e+00, 1.24402971e+00, 1.23474522e+00, 3.83991053e-05, 3.60920275e-05, 3.66240614e-05, 3.55759706e-05, 3.68749001e-05, 3.98194600e-05, 3.78958300e-05, 3.79070139e-05, -2.78415082e-05, -3.06646429e-05, 4.58586036e-03, 4.58408532e-03, -4.69831123e-03, -4.70061831e-03, 9.28417159e-03, 9.28470363e-03, -4.67046972e-03, -4.66995367e-03, 4.61370187e-03, 4.61474996e-03, -2.78151462e-05, -3.07597060e-05, 4.58606247e-03, 4.58415002e-03, -4.69842067e-03, -4.70034430e-03, 9.28448314e-03, 9.28449433e-03, -4.67060553e-03, -4.66958460e-03, 4.61387762e-03, 4.61490973e-03 }; float Z2[]= { 0.12576155, 0.12640182, 0.125071, 0.12572605, 0.12568469, 0.125719, 0.12636385, 0.12503521, 0.0150256, 0.01494947, 0.01478075, 0.01493629, 0.0141562, 0.01423137, 0.01419596, 0.01404453, 0.00669432, 0.0066951, 0.00482275, 0.004823, 0.00493041, 0.00493002, 0.0063063, 0.00630607, 0.0048614, 0.0048616, 0.00471017, 0.0047104, 0.00471147, 0.00471252, 0.00361188, 0.00361259, 0.00371563, 0.00371488, 0.00513505, 0.00513498, 0.0037117, 0.0037125, 0.00353196, 0.00353191 }; //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; int fetch = HORIZON * 2; int timer = 0; int state = 0;
さらに、ONNXモデルをリソースとしてEAに読み込みます。
//+------------------------------------------------------------------+ //| Resources | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| DISCLAIMER | //| This ONNX model was trained from 1 January 2003 until 29 January | //| 2023. For reliable results, ensure that all back tests are done | //| beyond the model's training period. | //+------------------------------------------------------------------+ #resource "\\Files\\MA Approximation\\EURUSD GBR MA D1.onnx" as const uchar onnx_proto[];
また、必要なライブラリおよび依存関係も読み込みます。たとえば、取引を管理するための専用のMQL5ライブラリや、ONNXモデルの取り扱いや取引情報の取得をおこなうために、これまでに開発してきたカスタムライブラリがあります。
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; ONNXFloat *onnx_handler; Time *time_handler; TradeInfo *trade_handler;
EAの初期化シーケンス中に、これらすべてのライブラリとテクニカル指標が読み込まれます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- onnx_handler = new ONNXFloat(onnx_proto); time_handler = new Time(Symbol(),TF); trade_handler = new TradeInfo(Symbol(),TF); Print("Onnx Handler Pointer: ",onnx_handler); onnx_handler.DefineOnnxInputShape(0,1,40); onnx_handler.DefineOnnxOutputShape(0,1,1); //---Setup our technical indicators ma_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //--- return(INIT_SUCCEEDED); }
安全なメモリ管理を確保するために、動的に生成されたすべてのオブジェクトを削除し、不要となったテクニカル指標を解放します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(ma_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_h_handle); IndicatorRelease(ma_l_handle); delete time_handler; delete trade_handler; delete onnx_handler; }
新しい価格更新を受信するたびに、新しいローソク足が形成されたかどうかを確認します。もし形成されていれば、取引シグナルを確認する前に、テクニカル指標を更新します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time_handler.NewCandle()) { update(); check_signal(); } }
テクニカル指標を更新する方法は以下のとおりです。まず、すべての指標の値を対応するバッファにコピーします。これにより、ONNXモデルへの入力ベクトルが準備されます。モデルは、前回の課題で使用したものと同じ40個の入力を受け取ります。これらの入力をモデルに渡す前に、標準化およびスケーリングをおこないます。次に、モデルは予測を生成します。
//+------------------------------------------------------------------+ //| Update our technical data | //+------------------------------------------------------------------+ void update(void) { //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); vectorf model_input_vector = { //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0), iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0), //--- MA OHLC ma_reading[0], ma_o_reading[0], ma_h_reading[0], ma_l_reading[0], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), //--- Growth in MA OHLC ma_reading[0] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_o_reading[(0 + HORIZON)], ma_h_reading[0] - ma_h_reading[(0 + HORIZON)], ma_l_reading[0] - ma_l_reading[(0 + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), //--- Growth between moving average channels ma_o_reading[0] - ma_reading[0], ma_o_reading[(0 + HORIZON)] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_l_reading[0], ma_o_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_o_reading[0] - ma_h_reading[0], ma_o_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_h_reading[0] - ma_l_reading[0], ma_h_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_reading[0] - ma_h_reading[0], ma_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_reading[0] - ma_l_reading[0], ma_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)] }; for(int i =0;i<40;i++) { model_input_vector[i] = ((model_input_vector[i] - Z1[i]) / Z2[i]); } onnx_handler.Predict(model_input_vector); }
シグナル確認関数は想定どおりに動作します。まず、現在ポジションが開かれていない場合はタイマーをリセットし、システムの状態を初期化します。ONNXモデルが強気の値動きを予測した場合は買いポジションに入り、弱気の値動きを予測した場合は売りポジションに入ります。なお、強気・弱気の判定はモデルが出力するクラス確率に対応しており、確率が0.5より大きい場合は強気、0.5未満の場合は弱気と判断します。
また、ONNXモデルのシグナルに加えて、移動平均のクロスオーバーパターンによる確認もおこないます。すでにポジションが開かれている場合はタイマーを追跡し、あらかじめ定義した保有期間に近づいた時点で、すべてのポジションをクローズしてサイクルを再開します。
//+------------------------------------------------------------------+ //| Check if we have oppurtunities to trade | //+------------------------------------------------------------------+ void check_signal(void) { if(PositionsTotal() == 0) { timer = 0; state = 0; if(onnx_handler.GetPrediction() > 0.5 { state =1; Trade.Buy(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetAsk(),0,0,""); } else if(onnx_handler.GetPrediction() < 0.5 && ma_reading[0] < ma_o_reading[0]) { state =-1; Trade.Sell(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetBid(),0,0,""); } } else { timer++; if(timer >= HORIZON) Trade.PositionClose(Symbol()); } }
最後に、すべてのシステム定義を必ず解除するようにします。
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE #undef TF
これで、学習時にモデルへ提示しなかったデータを用いてシステムをテストする準備が整いました。学習期間外のすべての日付を選択します。なお、学習期間は2023年1月29日に終了している点に注意します。
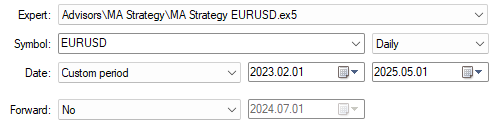
図4:バックテストの日は常に、モデルに提示した学習期間外である
また、実際の取引環境の不確実性をより現実的に再現するために、[ランダム遅延]を選択します。
図5:最も堅牢なバックテスト設定を利用するには、[ランダム遅延]を選択する
本戦略は、図6に示されるエクイティカーブを生成しました。モデルをこれまでに見たことのないデータでテストした場合でも、依然として安定した右肩上がりのトレンドを維持できている点は非常に良い結果です。これは、生成した40個の特徴量列を用いて市場を高解像度で学習させたことで、未学習のデータに対してもモデルがより適切に一般化できている可能性を示しています。
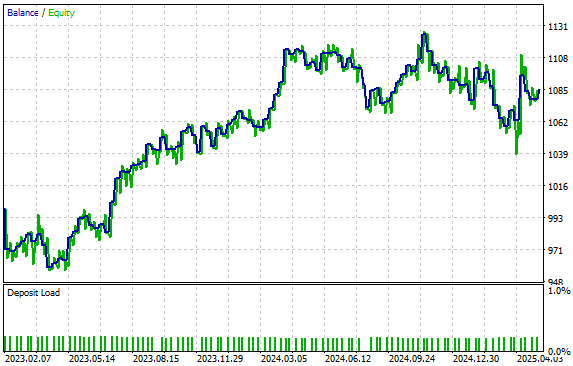
図6:統計モデルによって生成されたエクイティカーブの可視化
さらに、戦略のパフォーマンスに関する詳細な概要も確認できます。全体の取引の中で52.9%が利益を上げており、平均利益が平均損失を上回る傾向にあることが分かります。これらは非常に良好な指標であり、データセットに対して丁寧に特徴量を設計することの重要性を示しています。このプロセスは手間がかかりますが、成果につながるのであれば十分に価値のある取り組みです。
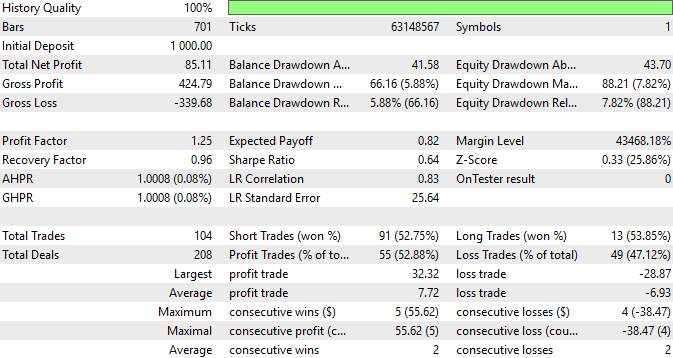
図7:取引アプリケーションのパフォーマンスに関する詳細な概要
結論
本記事では、既存の戦略を再解釈し、新たな機能を付加するための実践的な知見を数多く紹介しました。
データサイエンスの基本的な考え方、特に「高次元空間においてモデルの性能が向上する場合がある」という原則を活用することで、移動平均クロスオーバー戦略における遅延の問題を効果的に軽減することができました。これは、独自に設計したリッチなデータセットを用いることで、モデルに市場を高解像度で理解させることにより実現しました。ただし、これらの手法は広く研究されている一方で、過度な期待は禁物です。
データセットを高次元化することが、必ずしも性能向上を保証するわけではありません。しかしながら、高次元への射影によって改善が得られるかどうかを検証すること自体には大きな価値があります。このアプローチに保証はありませんが、試す価値は常にあります。また、テクニカル指標に伴う遅延は、批判的思考と創造性によって十分に克服可能であることも示されました。MetaTrader 5の可能性は非常に大きいと言えるでしょう。
| ファイル名 | ファイルの説明 |
|---|---|
| EURUSD GBR MA D1.onnx | 高次元列データセットを用いて構築したONNXモデル |
| Proof of Case Article.ipynb | データを高次元へ射影する有用性を示すために作成したJupyter Notebook |
| MA Strategy EURUSD.ex5 | 手作りのデータセットを活用するために開発した取引アプリケーションのコンパイル済みファイル |
| Fetch Data MA.mq5 | 高次元データセットを取得し、CSVとして出力するために作成したMQL5スクリプト |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/18525
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索