
Теория категорий в MQL5 (Часть 20): Самовнимание и трансформер
Введение
Я думаю, было бы упущением продолжать серию статей о теории категорий и естественных трансформациях и при этом не затронуть ChatGPT. К настоящему времени все в той или иной форме знакомы с ChatGPT и множеством других платформ искусственного интеллекта и, я надеюсь, оценили, насколько нейронные сети на основе трансформеров упрощают наши исследования и экономят время, которое раньше уходило на рутинные задачи. Поэтому в этой статье я отвлекусь от своих привычных тем и попытаюсь ответить на вопрос, являются ли естественные преобразования теории категорий каким-либо образом ключевыми для алгоритмов генеративных предварительно обученных трансформеров (Generative Pretrained Transformer, GPT), используемых OpenAI.
Помимо поиска синонимов к понятию "преобразование" (трансформация), я думаю, было бы также интересно посмотреть на элементы кода алгоритма GPT в MQL5 и протестировать их при предварительной классификации ряда цен на финансовые инструменты.
Трансформер, представленный в статье "Всё, что вам нужно — это внимание" (русская версия) представлял собой новое слово в нейронных сетях, используемых для перевода разговорной речи (например, с итальянского на французский). Он предоставлял способ избавиться от рекуррентности (recurrence) и сверток (convolutions). Каким образом? С помощью самовнимания (Self-Attention). Многие нынешние платформы искусственного интеллекта являются развитием идей, заложенных в статье.
Фактический алгоритм, используемый OpenAI, конечно, находится в секрете, но, тем не менее, предполагается, что он использует векторное представление слов, позиционное кодирование (positional encoding), самовнимание и нейронную сеть с прямой связью, как часть стека декодирующего трансформера (decode-only transformer). Ничего из этого не подтверждено, поэтому не стоит верить мне на слово. Чтобы внести ясность, всё это относится к части алгоритма, связанной с переводом слов/языка. Действительно, поскольку большая часть входных данных в ChatGPT представляет собой текст, он играет ключевую роль в алгоритме, но ChatGPT умеет не только работать с текстом. Например, если мы загрузим файл Excel, он может не только открыть его, чтобы прочитать его содержимое, но и построить графики и даже сделать выводы по представленной статистике. Алгоритм ChatGPT здесь не представлен полностью. Мы увидим лишь фрагменты того, как он может выглядеть.
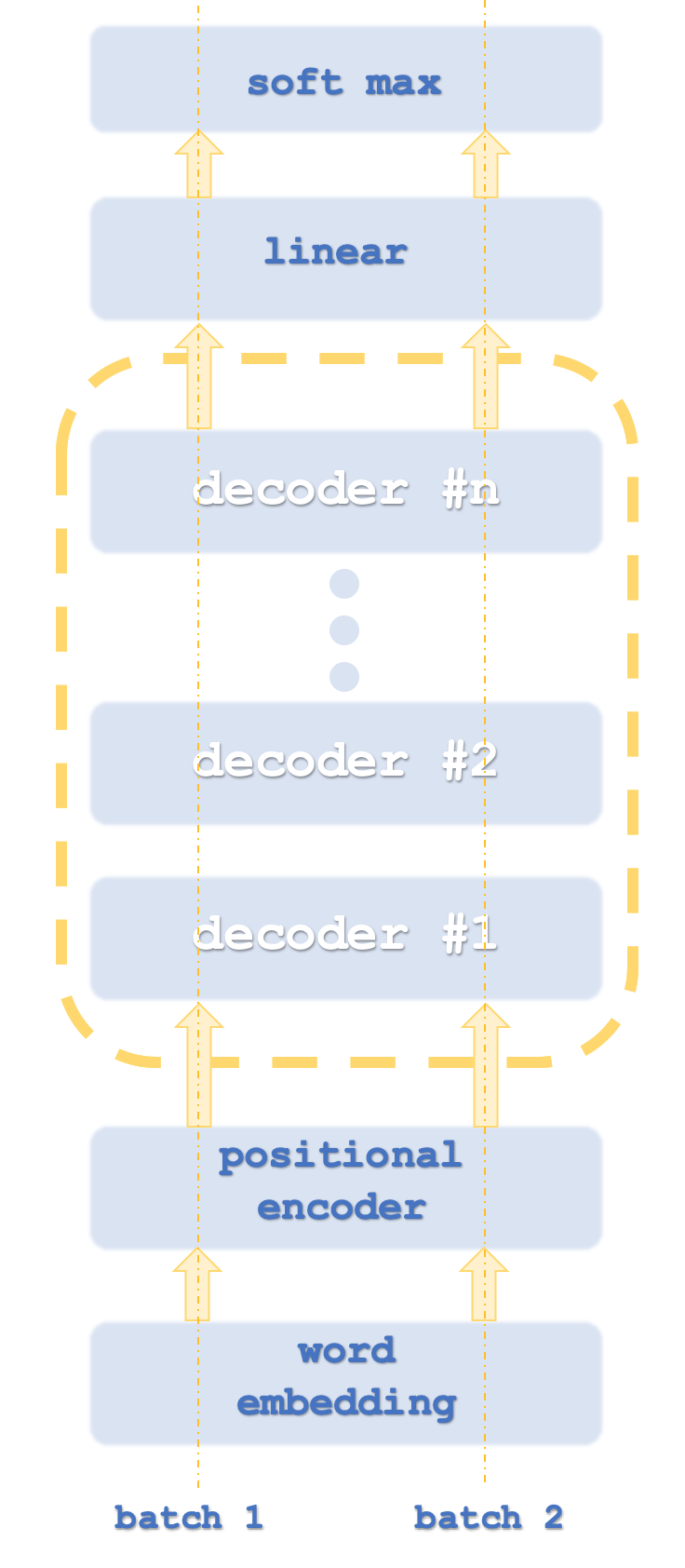
Пакеты (batch) 1 и 2 аналогичны компьютерным потокам, поскольку трансформеры обычно запускают экземпляры сети параллельно.
Поскольку мы классифицируем числа, необходимости в векторном представлении слов не будет. Позиционное кодирование предназначено для того, чтобы уловить абсолютную важность каждого слова в предложении благодаря его положению. Алгоритм прост: каждому слову (то есть токену) присваивается значение синусоидальной волны из массива синусоидальных волн на разных частотах. Значения каждой волны суммируются, чтобы получить кодировку позиции для этого токена. Это значение может быть вектором, что означает, что вы суммируете значения из более чем одного массива частот.
Это подводит нас к самовниманию. При этом вычисляется относительная важность каждого слова в предложении по отношению к словам, которые стоят перед ним в этом предложении. Это, казалось бы, тривиальное усилие важно в предложениях, в которых среди прочего присутствует слово it (это). Например, в предложении ниже:
“The dish washer partly cleaned the glass and it cracked it” (посудомоечная машина частично очистила стекло, и оно треснуло)
К чему в данном случае относятся местоимения it? Для человека понятно, о чем идет речь (в переводе на русский вообще не возникает никаких проблем благодаря грамматической категории рода), а для обучающейся машины — нет. Какой бы рядовой эта проблема ни казалась на первый взгляд, именно способность количественно оценить относительную важность этого слова, возможно, имела решающее значение при запуске нейронных сетей-трансформеров, которые оказались более распараллеливаемыми (parallelizable) и требовали значительно меньше времени для обучения, чем рекуррентные и сверточные сети, их предшественники.
Поэтому в этой статье самовнимание будет ключевым элементом в нашем классе тестовых сигналов. Интересно, что алгоритм самовнимания действительно имеет сходство с тем, как слова соотносятся друг с другом. Отношения между словами, которые используются для количественной оценки относительной важности (сходства), можно рассматривать как морфизмы, в которых сами слова образуют объекты. Связь эта несколько интригующая, поскольку каждому слову необходимо вычислить сходство или важность самого себя. Это очень похоже на тождественный морфизм (identity morphism)! Кроме того, помимо вывода морфизмов и объектов, мы могли бы также связать функторы и категории соответственно, как мы видели в недавних статьях.
Декодер трасформера
Обычно сеть трансформеров содержит стеки как кодирования, так и декодирования, причем каждый стек представляет собой повторение в сетях самовнимания и прямой связи. Это чем-то похоже на то, что показано ниже:
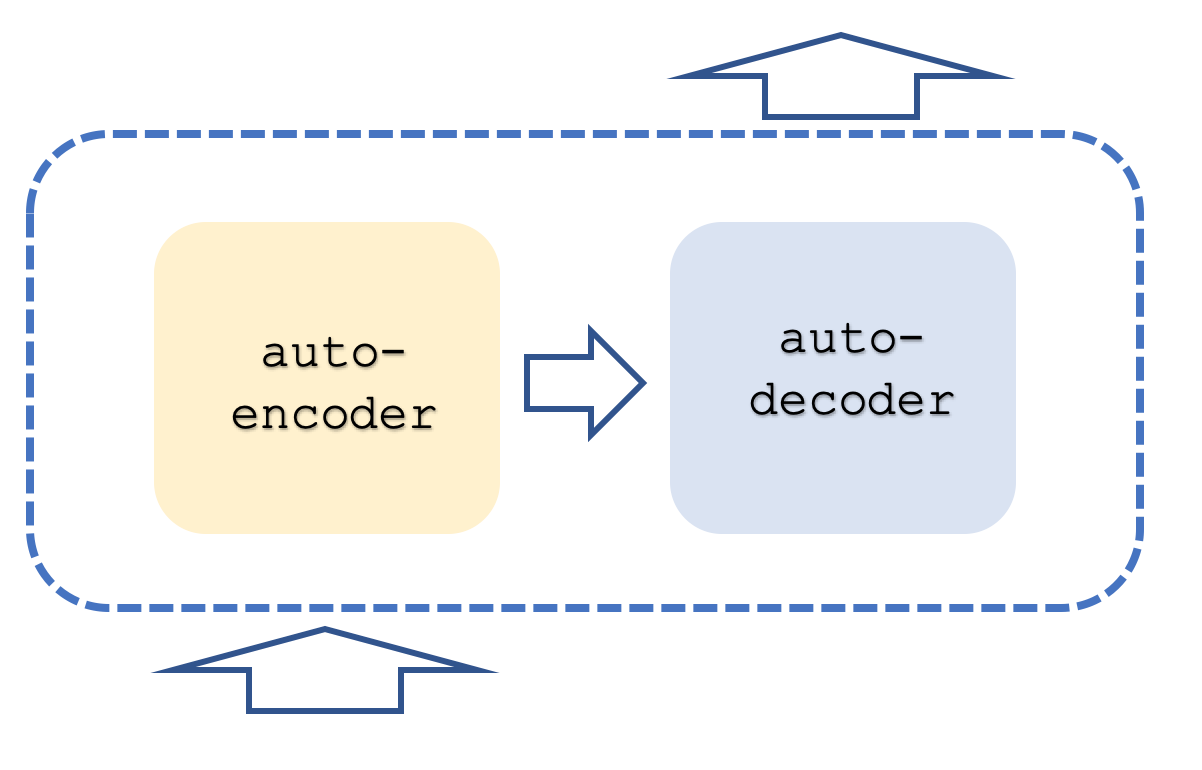
Вдобавок ко всему, каждый шаг выполняется с параллельными "потоками", то есть, если, например, шаг самовнимания и прямой связи может быть представлен многослойным перцептроном, то если бы у трнасформера было 8 потоков, у нас было бы 8 многослойных перцептронов. Очевидно, что это требует больших ресурсов, но именно это дает этому подходу преимущество, поскольку даже при таком использовании ресурсов он по-прежнему более эффективен, чем сверточные сети.
Подход, используемый OpenAI, считается разновидностью этого подхода и предназначен он только для декодирования. Его этапы примерно показаны на первой диаграмме. Использование только декодирования, очевидно, не влияет на точность модели, хотя оно, безусловно, обеспечивает большую производительность, поскольку обрабатывается только "половина" трансформера. Отображение самовнимания при кодировании отличается от отображения при декодировании тем, что при кодировании относительная важность всех слов вычисляется независимо от относительного положения в предложении. Очевидно, что это требует еще больше ресурсов, поскольку, как уже упоминалось, на стороне декодера самовнимание (так называемое вычисление сходства) выполняется только для каждого слова само по себе и только для тех слов, которые стоят перед ним в предложении. Некоторые могут возразить, что это даже отменяет необходимость позиционного кодирования, но для наших целей мы включим его в исходный код. В центре нашего внимания - подход, основанный только на декодировании.
Роль сетей самовнимания, а также сетей с прямой связью и прямой связи на этапе преобразования будет заключаться в том, чтобы брать выходные данные позиционного кодирования или предыдущего стека и создавать входные данные для линейного шага SoftMax входных данных для следующего шага декодера в зависимости от стека.
Кодирование позиции, которое некоторым может показаться излишним для нашего класса сигналов и статьи, включено сюда в информационных целях. Абсолютный порядок входной информации о ценовых столбцах может быть так же важен, как и последовательность слов в предложении. Мы используем простой алгоритм, который возвращает 4-кардинальный вектор двойных значений, выступающий в качестве "координат" каждой входной ценовой точки.
Некоторые могут возразить, почему бы не использовать простую индексацию для каждого ввода. Как выясняется, это приводит к исчезновению градиентов при обучении сетей, и поэтому требуется менее изменчивый и нормализованный формат. Тут можно привести аналогию с ключом шифрования стандартной длины, скажем, 128, независимо от того, что шифруется. Это усложняет взлом скрытого ключа, но также обеспечивает более эффективный способ создания и хранения ключей.
Итак, мы будем использовать 4 синусоидальные волны на разных частотах. Иногда, несмотря на эти 4 частоты, два слова могут иметь одинаковые "координаты", но это не должно доставлять проблем, поскольку, если это действительно происходит, то многие слова (или, в нашем случае, ценовые категории) используются, чтобы свести на нет эту небольшую аномалию. Эти значения координат добавляются к четырем ценовым точкам нашего входного вектора, который представляет собой то, что мы могли бы получить от встраивания слов, но не получили, поскольку мы уже имеем дело с числами в форме цен финансовых инструментов. Наш класс сигналов будет использовать изменения цен. Чтобы "нормализовать" наше кодирование позиции, значения кодирования позиции, которые могут колебаться от +5,0 до -5,0, а иногда и больше, будут умножены на размер пункта рассматриваемого финансового инструмента, прежде чем добавляться к изменению цены.
Как видно из приведенных выше общих гиперссылок, механизм самовнимания отвечает за определение трех векторов, а именно вектора запроса, вектора ключей и вектора значений. Эти векторы получаются в результате умножения выходного вектора кодирования позиции на матрицу весов. Как получены эти веса? С помощью обратного распространения. Однако для наших целей мы будем использовать экземпляры класса многослойного перцептрона для инициализации и обучения этих весов. Только один слой. Схематическое представление этого процесса на этом критическом этапе может быть следующим:
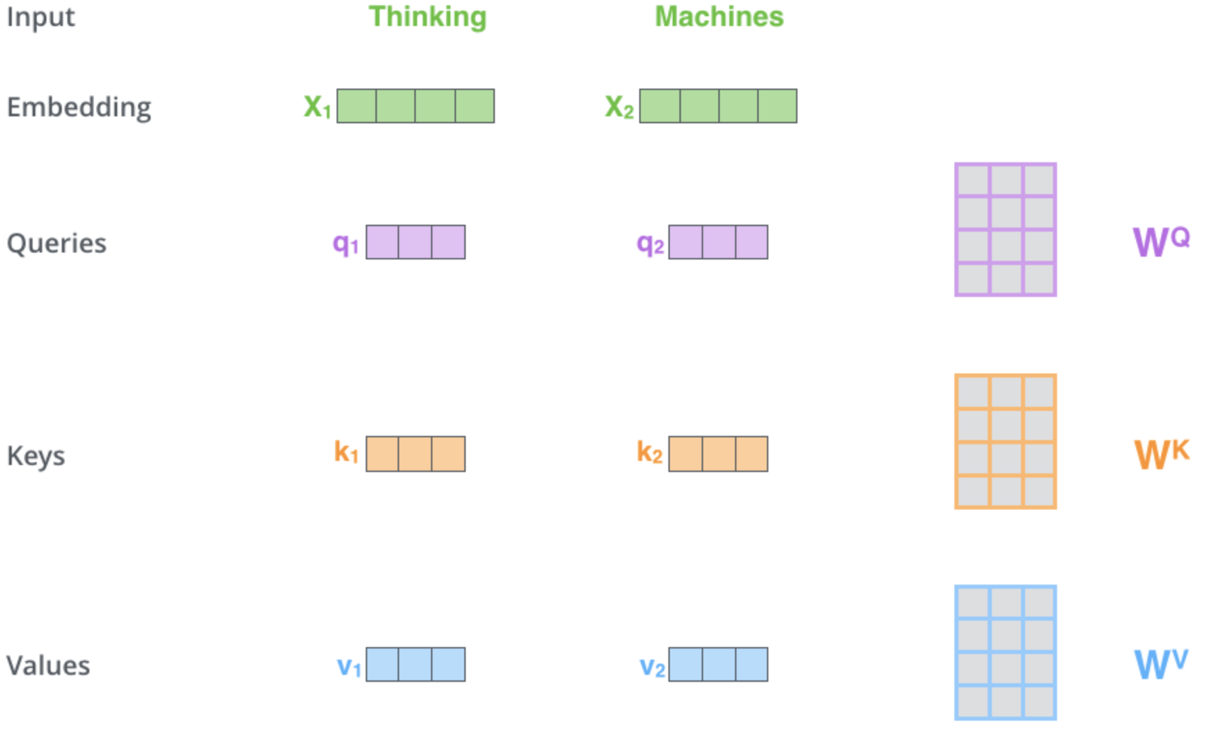
Эта иллюстрация и некоторые темы для обсуждения в этой статье взяты отсюда. На изображении выше в качестве входных данных представлены два слова - Thinking (мышление) и Machines (машины). При встраивании (преобразовании в числовые векторы) они преобразуются в векторы зеленого цвета. Матрицы справа представляют веса, которые мы собираемся получить с помощью многослойных персептронов, как упоминалось выше.
Итак, как только наши сети выполняют прямой проход, получая векторы запроса, ключа и значения, мы делаем скалярное произведение запроса и ключа, делим этот результат на квадратный корень из кардинального числа вектора ключа и получаем сходство между ценой с вектором запроса и ценой с вектором ключа. Эти умножения выполняются во всех ценовых точках в соответствии с картой самовнимания, где мы сравниваем только ценовые точки с самой ценой и с ценами, предшествующими ей. Результаты получили весьма разбросанные значения, поэтому они нормализуются в распределение вероятностей с помощью функции SoftMax. Сумма всех этих весов вероятности, как и ожидалось, равна единице. Происходит эффективное взвешивание. На последнем этапе каждый вес умножается на соответствующее ему векторное значение, и все эти произведения суммируются в один вектор, который формирует выходные данные слоя самовнимания.
Сеть с прямой связью берет выходной вектор самовнимания, обрабатывает его через многослойный перцептрон и выводит другой вектор, аналогичный по размеру входному вектору самовнимания.
Теоретическая основа реализации декодера-трансформера в MQL5 будет основана на простом классе сигналов, а не на советнике. На данный момент эта тема довольно сложна, поскольку некоторые из этих идей существуют менее десяти лет, поэтому чувствуется, что тестирование и знакомство на данный момент более важны, чем исполнение и результаты. Читатель волен брать и применять эти идеи, как ему необходимо.
Класс сигналов MQL5: Взгляд на сети самовнимания и прямой связи
Класс сигналов, прикрепленный к этой статье, предназначен для прогнозирования изменений цен с помощью декодера-трансформера, который имеет только один стек и один поток! Прикрепленный код можно настроить для увеличения количества стеков путем настройки параметра определения ‘__DECODERS’. Как упоминалось выше, стеков обычно несколько, и чаще всего они являются многопоточными. Обычно в декодере используется несколько стеков, что делает необходимым остаточное соединение (residual connection), чтобы избежать проблемы исчезающих и взрывающихся градиентов. Итак, мы работаем с простым трансформером и смотрим, на что он способен. Читатель может продолжить дальнейшую настройку в соответствии со своими потребностями в реализации.
Позиционное кодирование, вероятно, является самой простой из всех перечисленных функций, поскольку оно просто возвращает вектор координат с учетом размера входных данных. Код приведен ниже:
//+------------------------------------------------------------------+ //| Positional Encoding vector given length. | //+------------------------------------------------------------------+ vector CSignalCT::PositionalEncoding(int Positions) { vector _positions; _positions.Init(Positions);_positions.Fill(0.0); for(int i=0;i<Positions;i++) { for(int ii=0;ii<Positions;ii++) { _positions[i]+=MathSin((((ii+1)/Positions)*(i+1))*__PI); } } return(_positions); }
Итак, наш класс сигналов ссылается на ряд функций, но главной из них является функция Decode, источник которой указан ниже:
//+------------------------------------------------------------------+ //| Decode Function. | //+------------------------------------------------------------------+ void CSignalCT::Decode(int &DecoderIndex,matrix &Input,matrix &Sum,matrix &Output) { Input.ReplaceNan(0.0); // //output matrices Sum.Init(1,int(Input.Cols()));Sum.Fill(0.0); Ssimilarity _s[]; ArrayResize(_s,int(Input.Cols())); for(int i=int(Input.Rows())-1;i>=0;i--) { matrix _i;_i.Init(1,int(Input.Cols())); for(int ii=0;ii<int(Input.Cols());ii++) { _i[0][ii]=Input[i][ii]; } // SelfAttention(DecoderIndex,_i,_s[i].queries,_s[i].keys,_s[i].values); } for(int i=int(Input.Cols())-1;i>=0;i--) { for(int ii=i;ii>=0;ii--) { matrix _similarity=DotProduct(_s[i].queries,_s[ii].keys); Sum+=DotProduct(_similarity,_s[i].values); } } // Sum.ReplaceNan(0.0); // FeedForward(DecoderIndex,Sum,Output); }
Как вы можете видеть, он вызывает как функцию самообслуживания, так и функцию прямой связи, а также подготавливает входные данные, необходимые для обеих функций слоя.
Функция самовнимания выполняет фактические вычисления веса матрицы, чтобы получить векторы для запросов, ключей и значений. Мы представили эти "векторы" в виде матриц, хотя для целей нашего класса сигналов мы будем использовать однострочные матрицы, поскольку на практике несколько векторов часто передаются через сеть или умножаются на матричную систему весов, чтобы получить матрицу запросов, ключей и значений. Источник:
//+------------------------------------------------------------------+ //| Self Attention Function. | //+------------------------------------------------------------------+ void CSignalCT::SelfAttention(int &DecoderIndex,matrix &Input,matrix &Queries,matrix &Keys,matrix &Values) { Input.ReplaceNan(0.0); // Queries.Init(int(Input.Rows()),int(Input.Cols()));Queries.Fill(0.0); Keys.Init(int(Input.Rows()),int(Input.Cols()));Keys.Fill(0.0); Values.Init(int(Input.Rows()),int(Input.Cols()));Values.Fill(0.0); for(int i=0;i<int(Input.Rows());i++) { double _x_inputs[],_q_outputs[],_k_outputs[],_v_outputs[]; vector _i=Input.Row(i);ArrayResize(_x_inputs,int(_i.Size())); for(int ii=0;ii<int(_i.Size());ii++){ _x_inputs[ii]=_i[ii]; } m_base_q[DecoderIndex].MLPProcess(m_mlp_q[DecoderIndex],_x_inputs,_q_outputs); m_base_k[DecoderIndex].MLPProcess(m_mlp_k[DecoderIndex],_x_inputs,_k_outputs); m_base_v[DecoderIndex].MLPProcess(m_mlp_v[DecoderIndex],_x_inputs,_v_outputs); for(int ii=0;ii<int(_q_outputs.Size());ii++){ if(!MathIsValidNumber(_q_outputs[ii])){ _q_outputs[ii]=0.0; }} for(int ii=0;ii<int(_k_outputs.Size());ii++){ if(!MathIsValidNumber(_k_outputs[ii])){ _k_outputs[ii]=0.0; }} for(int ii=0;ii<int(_v_outputs.Size());ii++){ if(!MathIsValidNumber(_v_outputs[ii])){ _v_outputs[ii]=0.0; }} for(int ii=0;ii<int(Queries.Cols());ii++){ Queries[i][ii]=_q_outputs[ii]; } Queries.ReplaceNan(0.0); for(int ii=0;ii<int(Keys.Cols());ii++){ Keys[i][ii]=_k_outputs[ii]; } Keys.ReplaceNan(0.0); for(int ii=0;ii<int(Values.Cols());ii++){ Values[i][ii]=_v_outputs[ii]; } Values.ReplaceNan(0.0); } }
Функция прямой связи представляет собой прямую обработку многослойного перцептрона, и, с нашей точки зрения, здесь нет ничего особенного для трансформера декодирования. Конечно, другие реализации могут иметь собственные настройки, такие как несколько скрытых слоев или даже другие типы сетей, такие как машина Больцмана, но для наших целей это простая сеть с одним скрытым слоем.
Функция скалярного произведения интересна тем, что представляет собой специальную реализацию умножения двух матриц. В основном мы используем его для умножения однострочных матриц (так называемых векторов), но он масштабируем и может оказаться полезным, поскольку предварительное тестирование встроенной функции умножения матриц на данный момент она содержит ошибки.
Реализация SoftMax показана в Википедии. Все, что мы делаем, — это возвращаем вектор вероятностей по входному массиву значений. Значения выходного вектора положительны и в сумме дают единицу.
Таким образом, наш класс сигналов загружает данные о ценах с 2020.01.01 по 2023.08.01 для USDJPY. На дневном таймфрейме мы передаем в функцию кодирования позиции вектор из 4 ценовых точек, которые представляют собой просто последние 4 изменения цены закрытия. Эта функция, как уже упоминалось, получает координаты каждого изменения цены, нормализует их, умножая на размер пункта USDJPY, и добавляет их к входным изменениям цены.
Выходной вектор передается в функцию Decode для вычисления запроса, ключа и вектора значений для каждого из 4 входных данных вектора. В ходе самосопоставления (self-mapping), поскольку сходство проверяется только для каждой ценовой точки с самой собой, а цена изменяется до этого, из 4 векторных значений мы получаем 10, которые нуждаются в нормализации SoftMax.
Пропустив через SoftMax, мы получим массив из десяти весов, из которых только один принадлежит первой ценовой точке, 2 — второй, 3 — третьей и 4 — четвертой. Итак, поскольку для каждой ценовой точки у нас также есть вектор значений, который мы получили при выполнении функции самообслуживания, мы умножаем этот вектор на соответствующий вес, полученный от SoftMax, а затем суммируем все эти векторы в один выходной вектор. По замыслу его величина должна соответствовать величине входного вектора, поскольку стеки трансформеров расположены последовательно. Кроме того, поскольку мы используем многослойные перцептроны, важно отметить, что веса, инициализированные для каждой из сетей, будут случайными и будут обучаться (улучшаться) с каждым последующим баром.
Наш класс сигналов, скомпилированный в советник и оптимизированный для первых 5 месяцев 2023 года, а также прошедший пошаговое тестирование с 2023.06.01 по 2023.08.01, представляет нам следующие отчеты:


Эти отчеты были созданы советником с функцией чтения и записи весов сети, которые не используются в прикрепленном коде, поскольку реализация зависит от пользователя. Поскольку веса не считываются из определенного источника при инициализации, результаты обязательно будут разными при каждом запуске.
Практическое применение
Потенциальные применения именно этого класса сигналов, а не декодера-трансформера, могут заключаться в поиске потенциальных ценных бумаг для торговли с декодером-трансформером. Если мы проведем тестирование нескольких ценных бумаг на временных интервалах в течение десятилетий, мы сможем понять, что стоит изучить дальше с помощью дополнительного тестирования и улучшения системы, а чего следует избегать.
В стеке трансформера декодирования уровень самоконтроля имеет решающее значение и обязательно даст нам преимущество, поскольку используемая здесь сеть прямой связи довольно проста. Таким образом, относительная важность каждого предшествующего изменения цены фиксируется таким образом, что корреляционные функции легко скрываются, поскольку они ориентированы на средние значения. Использование многослойных перцептронов для сбора весовых матриц для векторов запроса, ключа и значения — это один из подходов, который можно использовать, поскольку существует множество других промежуточных способов достичь цели с помощью машинного обучения. В целом, понимание чувствительности самовнимания к предсказуемости сети имеет ключевое значение.
Ограничения и недостатки
Обучение сети для нашего класса сигналов выполняется постепенно на каждом новом баре, и возможность загрузки предварительно обученных весов не используется, а это значит, что мы обязательно получим много случайных результатов. Из-за этого читатель должен ожидать разного набора результатов при каждом запуске класса сигнала.
Кроме того, возможность сохранять обученные веса в конце класса сигнала не используется, а это означает, что мы не можем использовать то, что здесь изучили.
Эти ограничения имеют решающее значение и, по моему мнению, их необходимо устранить, прежде чем кто-либо приступит к дальнейшей разработке декодера-трансформера в торговой системе. Мы должны не только использовать обученные веса, но и иметь возможность сохранять обучающие веса, но перед развертыванием системы необходимо провести тестирование данных вне выборки с обученными весами.
Заключение
Связан ли алгоритм ChatGPT с естественными преобразованиями? Возможно. Это связано с тем, что если мы рассматриваем стеки декодера-трансформера как категории, то потоки (параллельные операции, выполняемые через трансформер) будут функторами. По этой аналогии разница между конечными результатами каждой операции будет эквивалентна естественной трансформации.
Наш декодер-трансформер даже без надлежащей записи и считывания весов показал некоторый потенциал. Это, безусловно, интересная система, которую можно было бы развивать дальше и даже добавить в свой набор инструментов по мере наращивания своих преимуществ.
В заключение можно отметить, что алгоритм самовнимания умеет количественно определять относительное сходство между токенами (входными данными трансформера). В нашем случае эти токены представляли собой изменения цен в разные, но последовательные моменты времени. В других моделях это могли бы быть многочисленные экономические индикаторы, новостные события или значения настроений инвесторов и т. д., но процесс был бы таким же, однако результат с этими различными входными данными обязательно раскроет и, таким образом, смоделирует сложную и динамичную взаимосвязь этих входных значений, помогая разработчику лучше понять их. В долгосрочной перспективе это позволит трансформеру адаптивно извлекать соответствующие функции из входных токенов при каждом новом сеансе обучения. Таким образом, даже в нестабильных ситуациях, когда появляется много новостей, модель должна отфильтровывать шум и быть более устойчивой.
Кроме того, алгоритм самообслуживания при столкновении с запаздывающими или входными данными в разные моменты времени (как в приложенном экземпляре класса сигналов) помогает количественно оценить относительную значимость этих различных периодов и, таким образом, фиксирует зависимости на дальних расстояниях. Это приводит к возможности прогнозирования на разных временных горизонтах, что является еще одним преимуществом для трейдеров. Таким образом, подводя итог, относительный вес входных данных токенов должен предоставить трейдерам информацию не только о различных экономических индикаторах, которые могут быть входными данными, но и о различных таймфреймах, если используются индикаторы (или цены) с задержкой по времени.
Дополнительные ресурсы
В основном ссылки на статьи в Википедии, а также публикации Корнеллского университета, Stack Exchange и этого сайта.
Примечание автора
Исходный код, представленный в этой статье, НЕ является кодом, используемым ChatGPT. Это просто реализация трансформера-декодера. Он имеет формат класса сигнала, что означает, что пользователю необходимо скомпилировать его с помощью мастера MQL5, чтобы сформировать тестируемый советник. Руководство можно найти здесь. Кроме того, пользователю необходимо реализовать механизмы чтения и записи для чтения и хранения полученных весов сети.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13348
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Теория категорий в MQL5 (часть 20): Самообман и трансформатор:
Автор: Стивен Нджуки