
Teoria das Categorias em MQL5 (Parte 20): autoatenção e transformador
Introdução
Acho que seria imprudente continuar a série de artigos sobre teoria das categorias e transformações naturais sem tocar no ChatGPT. Até o momento, de uma forma ou de outra, todos estão familiarizados com o ChatGPT e muitas outras plataformas de inteligência artificial e, espero, reconheceram o quanto as redes neurais baseadas em transformadores facilitam nossas pesquisas e economizam tempo que antes era gasto em tarefas rotineiras. Por isso, neste artigo, me desviarei dos meus temas habituais e tentarei responder à pergunta: as transformações naturais da teoria das categorias são de alguma forma fundamentais para os algoritmos baseados em transformadores generativos pré-treinados (Generative Pretrained Transformer, GPT) usados pela OpenAI?
Além de procurar sinônimos para o conceito de "transformação" (transformation), acho que também seria interessante olhar para os elementos do código do algoritmo GPT em MQL5 e testá-los durante a classificação prévia de séries de preços de instrumentos financeiros.
O transformador, apresentado no artigo "Tudo que você precisa é autoatenção" (versão em russo), representava uma novidade em redes neurais usadas para tradução de fala (por exemplo, do italiano para o francês). Ele oferecia uma maneira de eliminar a recorrência e as convoluções. De que maneira? Por meio da autoatenção (Self-Attention). Muitas das atuais plataformas de inteligência artificial são desenvolvimentos das ideias apresentadas no artigo.
O algoritmo real usado pela OpenAI, claro, é mantido em segredo, mas, ainda assim, acredita-se que ele utilize representação vetorial de palavras, codificação posicional, autoatenção e rede neural com propagação progressiva, como parte da pilha do decode-only transformer. Nada disso é confirmado, então não acredite cegamente em mim. Para esclarecer, tudo isso se refere à parte do algoritmo relacionada à tradução de palavras/idiomas. De fato, dado que a maior parte dos dados de entrada no ChatGPT é texto, ele desempenha um papel chave no algoritmo, mas o ChatGPT não se limita apenas a trabalhar com texto. Por exemplo, se carregarmos um arquivo Excel, ele pode não apenas abrir para ler seu conteúdo, mas também criar gráficos e até fazer análises estatísticas baseadas nos dados apresentados. O algoritmo do ChatGPT aqui não é totalmente revelado. Vemos apenas fragmentos do que ele poderia ser.
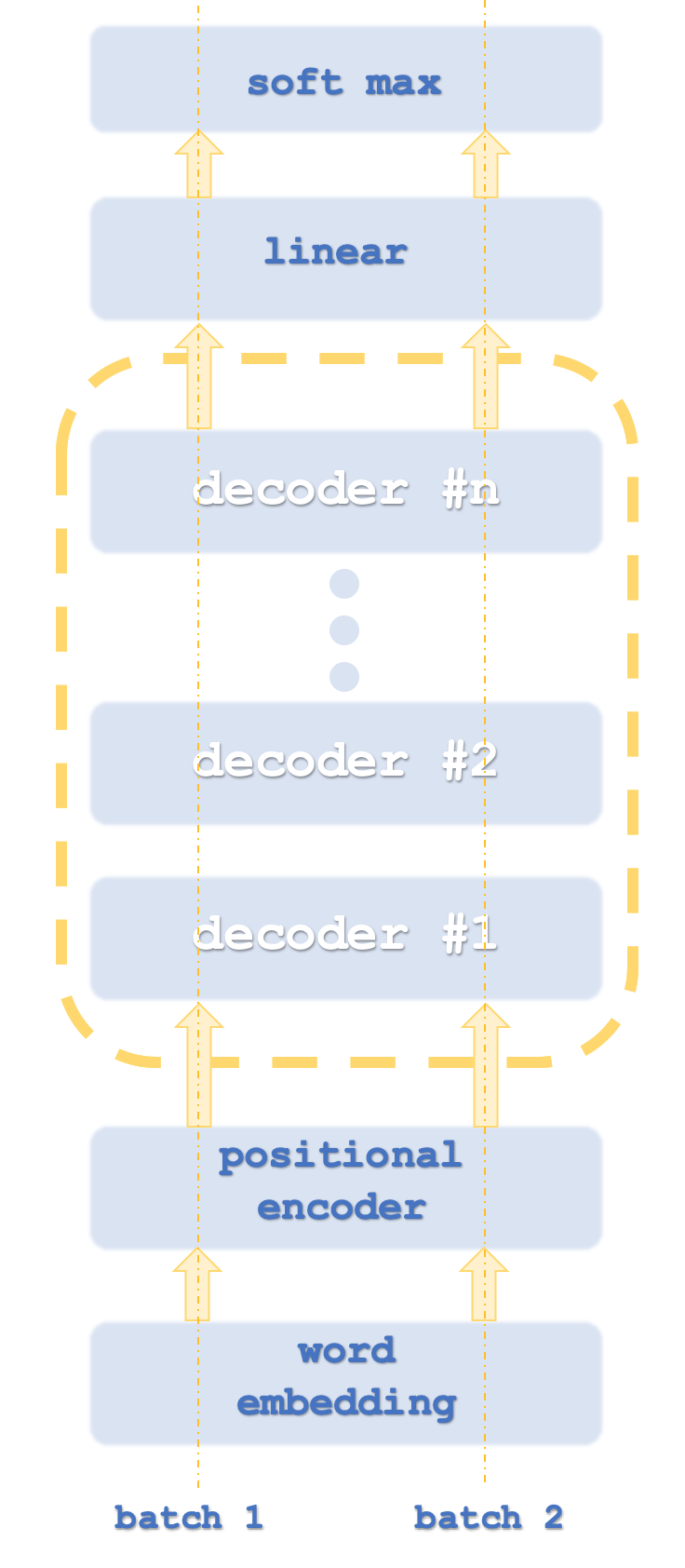
Os pacotes (batches) 1 e 2 são semelhantes a threads de computador, já que os transformadores geralmente executam instâncias de rede em paralelo.
Como estamos classificando números, não haverá necessidade de representação vetorial de palavras. A codificação posicional é projetada para captar a importância absoluta de cada palavra na frase devido à sua posição. O algoritmo é simples: a cada palavra (ou seja, token) é atribuído o valor de uma onda senoidal de um array de ondas senoidais em diferentes frequências. Os valores de cada onda são somados para obter a codificação posicional para esse token. Esse valor pode ser um vetor, o que significa que você soma valores de mais de um array de frequências.
Isso nos leva à autoatenção. Aqui, é calculada a importância relativa de cada palavra na frase em relação às palavras que a precedem na mesma frase. Este esforço, aparentemente trivial, é importante em frases onde, entre outras coisas, a palavra it (isso) está presente. Por exemplo, na frase abaixo:
“The dish washer partly cleaned the glass and it cracked it” (a lava-louças limpou parcialmente o vidro, e ele o trincou)
A que se referem os pronomes it neste caso? Para um humano, é claro sobre o que se trata (na tradução para o português, não surgem problemas devido à categoria gramatical de gênero), mas para uma máquina em treinamento, não é. Por mais comum que esse problema possa parecer à primeira vista, a habilidade de quantificar a importância relativa dessa palavra pode ter sido crucial ao iniciar redes neurais transformadoras, que se mostraram mais paralelizáveis e exigiram significativamente menos tempo para treinamento do que suas predecessores, as redes recorrentes e convolucionais.
Então, neste artigo, a autoatenção será o elemento chave em nossa classe de sinais de teste. É interessante notar que o algoritmo de autoatenção realmente se assemelha à maneira como as palavras se relacionam umas com as outras. As relações entre as palavras, usadas para quantificar a importância relativa (similaridade), podem ser vistas como morfismos nos quais as próprias palavras formam objetos. Essa conexão é bastante intrigante, pois é necessário calcular a similaridade ou importância de cada palavra para si mesma. Isso é muito parecido com o morfismo de identidade (identity morphism)! Além disso, além de inferir morfismos e objetos, também poderíamos relacionar funtores e categorias respectivamente, como vimos em artigos recentes.
Decodificador do transformador
Normalmente, a rede de transformadores contém pilhas tanto de codificação quanto de decodificação, com cada pilha sendo uma repetição nas redes de autoatenção e propagação progressiva. Isso é um pouco semelhante ao que é mostrado abaixo:
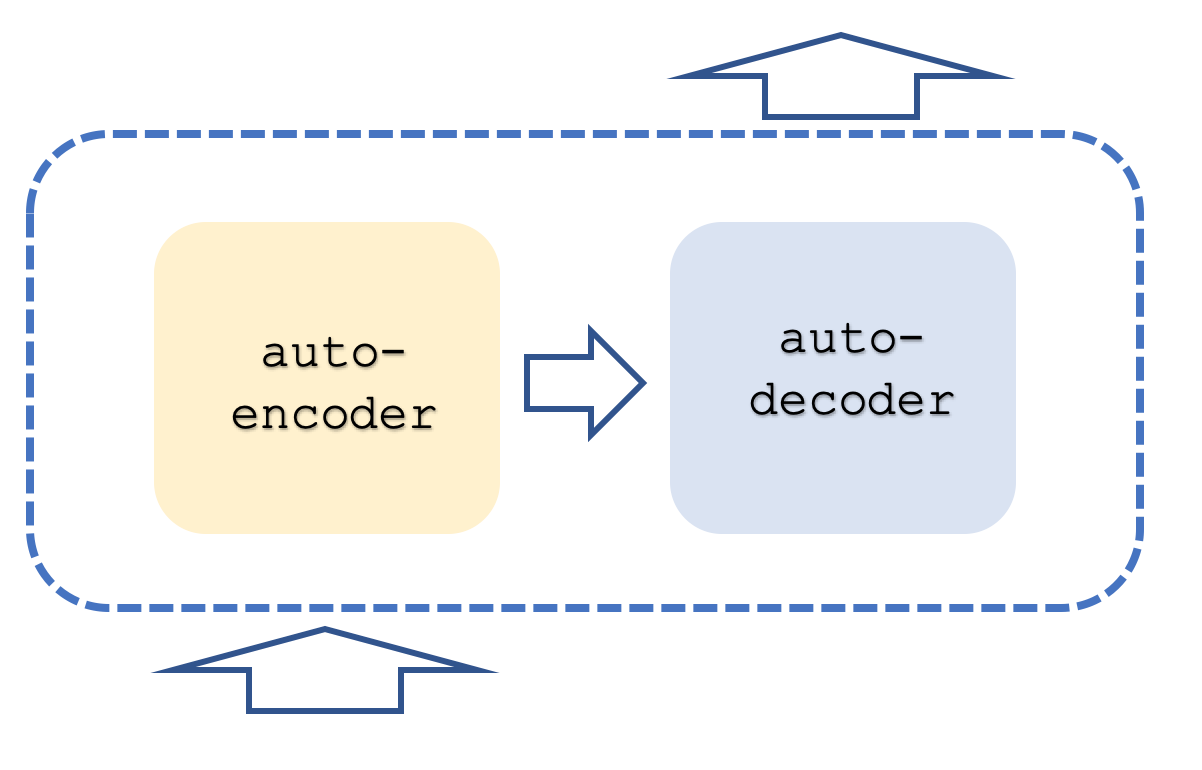
Adicionalmente, cada etapa é realizada com "threads" paralelas, isto é, se, por exemplo, a etapa de autoatenção e propagação progressiva pode ser representada por um perceptron multicamadas, então, se um transformador tivesse 8 threads, teríamos 8 perceptrons multicamadas. É óbvio que isso demanda grandes recursos, mas é justamente isso que confere vantagem a esse método, pois mesmo com tal uso de recursos, ele ainda se mostra mais eficiente que as redes convolucionais.
O método utilizado pela OpenAI é considerado uma variante dessa abordagem e se destina apenas à decodificação. Seus estágios estão aproximadamente ilustrados no primeiro diagrama. O uso exclusivo da decodificação, obviamente, não afeta a precisão do modelo, embora proporcione maior desempenho, já que apenas "metade" do transformador é processada. A representação da autoatenção na codificação difere da representação na decodificação pelo fato de que, na codificação, a importância relativa de todas as palavras é calculada independentemente de sua posição relativa na frase. Claramente, isso requer ainda mais recursos, pois, como já mencionado, no lado do decodificador, a autoatenção (o chamado cálculo de similaridade) é realizado apenas para cada palavra por si só e somente para aquelas palavras que precedem no texto. Alguns podem argumentar que isso até elimina a necessidade de codificação posicional, mas para nossos propósitos, nós a incluiremos no código-fonte. No centro da nossa autoatenção está a abordagem baseada apenas na decodificação.
O papel das redes de autoatenção, bem como das redes com propagação progressiva nesta fase de transformação, será pegar os dados de saída da codificação posicional ou da pilha anterior e criar dados de entrada para o passo linear do SoftMax de entrada para o próximo passo do decodificador, dependendo da pilha.
A codificação de posição, que alguns podem considerar desnecessária para nossa classe de sinais e artigo, está incluída aqui para fins informativos. A ordem absoluta da informação de entrada sobre as colunas de preço pode ser tão importante quanto a sequência de palavras numa frase. Usamos um algoritmo simples que retorna um vetor de quatro direções de valores duplos, atuando como "coordenadas" de cada ponto de entrada de preço.
Alguns podem argumentar, por que não usar uma simples indexação para cada entrada? Como se verifica, isso leva ao desaparecimento dos gradientes durante o treinamento das redes, e, por isso, é necessário um formato menos variável e normalizado. Aqui, pode-se fazer uma analogia com uma chave de criptografia de comprimento padrão, digamos, 128, independentemente do que está sendo criptografado. Isso torna mais difícil decifrar a chave secreta, mas também oferece um meio mais eficiente de criar e armazenar chaves.
Portanto, usaremos 4 ondas senoidais em diferentes frequências. Às vezes, apesar dessas 4 frequências, duas palavras podem ter as mesmas "coordenadas", mas isso não deve causar problemas, pois, se isso realmente acontece, muitas palavras (ou, no nosso caso, categorias de preço) são usadas para neutralizar essa pequena anomalia. Esses valores de coordenadas são adicionados aos quatro pontos de preço do nosso vetor de entrada, que representa o que poderíamos obter da incorporação de palavras, mas não obtivemos, já que já estamos lidando com números na forma de preços de instrumentos financeiros. Nossa classe de sinais usará mudanças de preço. Para "normalizar" nossa codificação posicional, os valores de codificação posicional, que podem variar de +5,0 a -5,0, às vezes até mais, serão multiplicados pelo tamanho do ponto do instrumento financeiro considerado, antes de serem adicionados à mudança de preço.
Como pode ser visto nos hiperlinks genéricos acima, o mecanismo de autoatenção é responsável por definir três vetores, a saber, o vetor de consulta, o vetor de chaves e o vetor de valores. Esses vetores são obtidos como resultado da multiplicação do vetor de saída da codificação posicional por uma matriz de pesos. Como esses pesos são obtidos? Por meio da retropropagação. No entanto, para nossos propósitos, usaremos instâncias da classe de perceptron multicamada para a inicialização e treinamento desses pesos. Apenas uma camada. A representação esquemática desse processo nesta etapa crítica pode ser a seguinte:
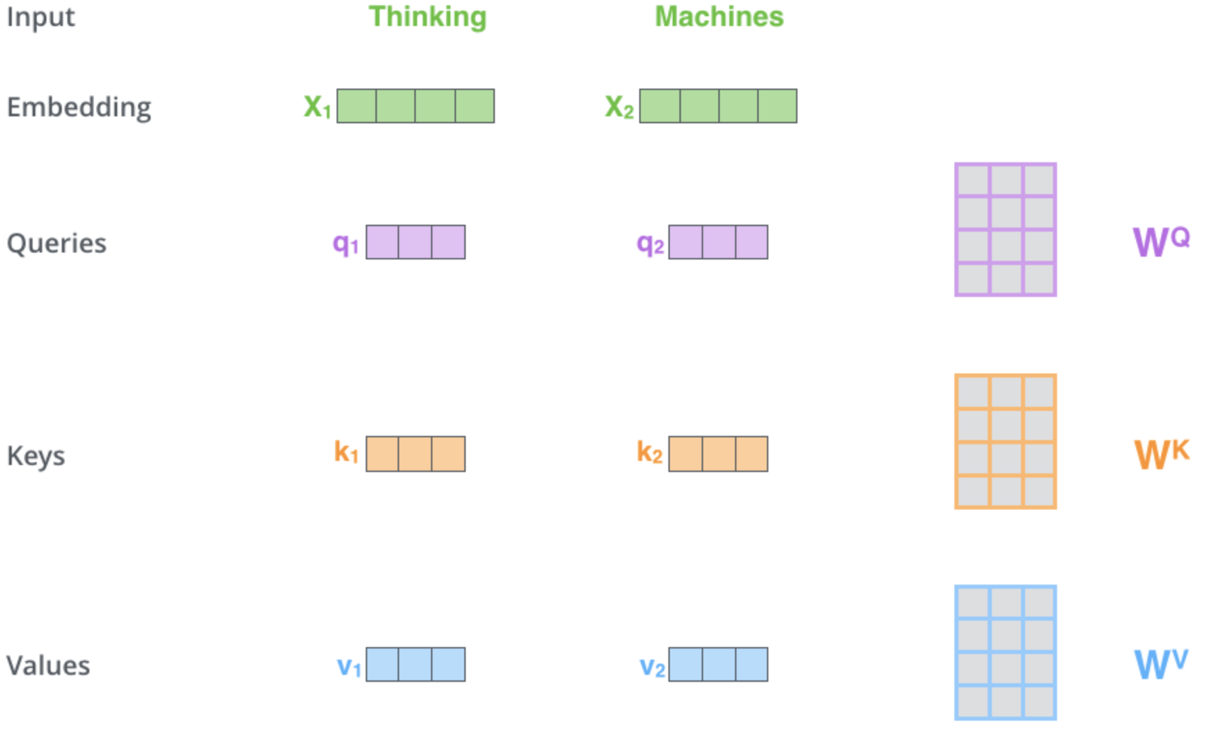
Esta ilustração e alguns temas para discussão neste artigo foram retirados daqui. Na imagem acima, como dados de entrada são apresentadas duas palavras - Thinking (pensamento) e Machines (máquinas). Na incorporação (conversão em vetores numéricos), eles são transformados em vetores de cor verde. As matrizes à direita representam os pesos que pretendemos obter com o uso de perceptrons multicamadas, como mencionado anteriormente.
Assim, assim que nossas redes realizam a propagação, obtendo os vetores de consulta, chave e valor, fazemos o produto escalar da consulta e da chave, dividimos esse resultado pela raiz quadrada do número cardinal do vetor chave e obtemos a semelhança entre o preço com o vetor de consulta e o preço com o vetor chave. Essas multiplicações são realizadas em todos os pontos de preço de acordo com o mapa de autoatenção, onde comparamos apenas pontos de preço com o próprio preço e com os preços que o precedem. Os resultados obtidos são bastante dispersos, por isso, eles são normalizados em uma distribuição de probabilidades usando a função SoftMax. A soma de todos esses pesos de probabilidade, como esperado, é igual a um. Ocorre uma ponderação eficaz. Na última etapa, cada peso é multiplicado pelo seu valor vetorial correspondente, e todos esses produtos são somados em um vetor, que forma os dados de saída da camada de autoatenção.
A rede com propagação progressiva pega o vetor de saída da autoatenção, processa-o através de um perceptron multicamadas e produz outro vetor, semelhante em tamanho ao vetor de entrada da autoatenção.
A base teórica para a implementação do decodificador-transformador em MQL5 será baseada em uma simples classe de sinais, e não em um Expert Advisor (EA). No momento, este tema é bastante complexo, uma vez que algumas dessas ideias existem há menos de dez anos, portanto, sente-se que o teste e o familiarizar-se com elas são mais importantes agora do que a execução e os resultados. O leitor é livre para pegar e aplicar essas ideias conforme necessário.
Classe de sinais MQL5: Uma visão sobre as redes de autoatenção e propagação progressiva
A classe de sinais vinculada a este artigo é destinada a prever mudanças de preço usando um decodificador-transformador que tem apenas uma pilha e um thread! O código anexado pode ser personalizado para aumentar o número de pilhas ajustando o parâmetro de definição ‘__DECODERS’. Como mencionado anteriormente, normalmente existem várias pilhas, e elas são frequentemente multithreaded. Normalmente, vários stacks são usados no decodificador, o que torna necessário a rede residual para evitar o problema de gradientes desaparecendo e explodindo. Assim, trabalhamos com um transformador simples e vemos do que ele é capaz. O leitor pode continuar a ajustar de acordo com suas necessidades de implementação.
A codificação posicional é provavelmente a mais simples de todas as características listadas, pois simplesmente retorna um vetor de coordenadas considerando o tamanho dos dados de entrada. O código é o seguinte:
//+------------------------------------------------------------------+ //| Positional Encoding vector given length. | //+------------------------------------------------------------------+ vector CSignalCT::PositionalEncoding(int Positions) { vector _positions; _positions.Init(Positions);_positions.Fill(0.0); for(int i=0;i<Positions;i++) { for(int ii=0;ii<Positions;ii++) { _positions[i]+=MathSin((((ii+1)/Positions)*(i+1))*__PI); } } return(_positions); }
Assim, nossa classe de sinais se refere a uma série de funções, mas a principal delas é a função Decode, cuja fonte é indicada abaixo:
//+------------------------------------------------------------------+ //| Decode Function. | //+------------------------------------------------------------------+ void CSignalCT::Decode(int &DecoderIndex,matrix &Input,matrix &Sum,matrix &Output) { Input.ReplaceNan(0.0); // //output matrices Sum.Init(1,int(Input.Cols()));Sum.Fill(0.0); Ssimilarity _s[]; ArrayResize(_s,int(Input.Cols())); for(int i=int(Input.Rows())-1;i>=0;i--) { matrix _i;_i.Init(1,int(Input.Cols())); for(int ii=0;ii<int(Input.Cols());ii++) { _i[0][ii]=Input[i][ii]; } // SelfAttention(DecoderIndex,_i,_s[i].queries,_s[i].keys,_s[i].values); } for(int i=int(Input.Cols())-1;i>=0;i--) { for(int ii=i;ii>=0;ii--) { matrix _similarity=DotProduct(_s[i].queries,_s[ii].keys); Sum+=DotProduct(_similarity,_s[i].values); } } // Sum.ReplaceNan(0.0); // FeedForward(DecoderIndex,Sum,Output); }
Como você pode ver, ela chama tanto a função de autoatenção quanto a função de propagação progressiva, além de preparar os dados de entrada necessários para ambas as funções da camada.
A função de autoatenção realiza os cálculos efetivos do peso da matriz para obter vetores para consultas, chaves e valores. Nós representamos esses "vetores" como matrizes, embora para os propósitos da nossa classe de sinais, usaremos matrizes de linha única, já que na prática, vários vetores são frequentemente passados através da rede ou multiplicados por um sistema de pesos matriciais para obter a matriz de consultas, chaves e valores. Fonte:
//+------------------------------------------------------------------+ //| Self Attention Function. | //+------------------------------------------------------------------+ void CSignalCT::SelfAttention(int &DecoderIndex,matrix &Input,matrix &Queries,matrix &Keys,matrix &Values) { Input.ReplaceNan(0.0); // Queries.Init(int(Input.Rows()),int(Input.Cols()));Queries.Fill(0.0); Keys.Init(int(Input.Rows()),int(Input.Cols()));Keys.Fill(0.0); Values.Init(int(Input.Rows()),int(Input.Cols()));Values.Fill(0.0); for(int i=0;i<int(Input.Rows());i++) { double _x_inputs[],_q_outputs[],_k_outputs[],_v_outputs[]; vector _i=Input.Row(i);ArrayResize(_x_inputs,int(_i.Size())); for(int ii=0;ii<int(_i.Size());ii++){ _x_inputs[ii]=_i[ii]; } m_base_q[DecoderIndex].MLPProcess(m_mlp_q[DecoderIndex],_x_inputs,_q_outputs); m_base_k[DecoderIndex].MLPProcess(m_mlp_k[DecoderIndex],_x_inputs,_k_outputs); m_base_v[DecoderIndex].MLPProcess(m_mlp_v[DecoderIndex],_x_inputs,_v_outputs); for(int ii=0;ii<int(_q_outputs.Size());ii++){ if(!MathIsValidNumber(_q_outputs[ii])){ _q_outputs[ii]=0.0; }} for(int ii=0;ii<int(_k_outputs.Size());ii++){ if(!MathIsValidNumber(_k_outputs[ii])){ _k_outputs[ii]=0.0; }} for(int ii=0;ii<int(_v_outputs.Size());ii++){ if(!MathIsValidNumber(_v_outputs[ii])){ _v_outputs[ii]=0.0; }} for(int ii=0;ii<int(Queries.Cols());ii++){ Queries[i][ii]=_q_outputs[ii]; } Queries.ReplaceNan(0.0); for(int ii=0;ii<int(Keys.Cols());ii++){ Keys[i][ii]=_k_outputs[ii]; } Keys.ReplaceNan(0.0); for(int ii=0;ii<int(Values.Cols());ii++){ Values[i][ii]=_v_outputs[ii]; } Values.ReplaceNan(0.0); } }
A função de propagação progressiva consiste no processamento direto de um perceptron multicamadas, e, do nosso ponto de vista, não há nada particularmente especial para o transformador de decodificação aqui. Claro, outras implementações podem ter suas próprias configurações, como várias camadas ocultas ou até mesmo outros tipos de redes, como a máquina de Boltzmann, mas para nossos propósitos, é uma rede simples com uma única camada oculta
A função do produto escalar é interessante porque representa uma implementação especial da multiplicação de duas matrizes. Principalmente, usamos isso para multiplicar matrizes de uma única linha (os chamados vetores), mas é escalável e pode se mostrar útil, já que o teste preliminar da função de multiplicação de matrizes embutida contém erros no momento.
A implementação do SoftMax é mostrada na Wikipédia. Tudo o que fazemos é retornar um vetor de probabilidades para um array de valores de entrada. Os valores do vetor de saída são positivos e somam um.
Assim, nossa classe de sinais carrega dados de preço de 2020.01.01 a 2023.08.01 para USDJPY. No timeframe diário, passamos para a função de codificação posicional um vetor de 4 pontos de preço, que representam simplesmente as últimas 4 mudanças de preço de fechamento. Esta função, como já mencionado, obtém as coordenadas de cada mudança de preço, normaliza-as multiplicando pelo tamanho do pip do USDJPY, e as adiciona às mudanças de preço de entrada.
O vetor de saída é passado para a função Decode para calcular a consulta, chave e vetor de valores para cada uma das 4 entradas do vetor. Durante o automapeamento, já que a semelhança é verificada apenas para cada ponto de preço consigo mesmo, e o preço muda antes disso, dos 4 valores vetoriais obtemos 10, que precisam de normalização pelo SoftMax.
Após passar pelo SoftMax, obtemos um array de dez pesos, dos quais apenas um pertence ao primeiro ponto de preço, 2 ao segundo, 3 ao terceiro e 4 ao quarto. Então, uma vez que para cada ponto de preço também temos um vetor de valores que obtivemos ao executar a função de autoatenção, multiplicamos este vetor pelo peso correspondente obtido do SoftMax, e então somamos todos esses vetores em um vetor de saída único. O propósito é que sua magnitude corresponda à magnitude do vetor de entrada, pois as pilhas dos transformadores são colocadas sequencialmente. Além disso, como estamos usando perceptrons multicamadas, é importante notar que os pesos, inicializados para cada uma das redes, serão aleatórios e serão treinados (melhorados) com cada barra subsequente.
Nossa classe de sinais, compilada em um EA e otimizada para os primeiros 5 meses de 2023, bem como submetida a testes passo a passo de 2023.06.01 a 2023.08.01, nos apresenta os seguintes relatórios:


Esses relatórios foram criados por um EA com a função de leitura e escrita dos pesos da rede, que não são utilizados no código anexado, uma vez que a implementação depende do usuário. Como os pesos não são lidos de uma fonte específica na inicialização, os resultados necessariamente serão diferentes a cada execução.
Aplicação prática
As aplicações potenciais deste classe de sinais, e não do decodificador-transformador, podem incluir a busca por títulos financeiros potenciais para negociação com o decodificador-transformador. Se realizarmos testes com várias ações em intervalos de tempo ao longo de décadas, poderemos entender o que vale a pena explorar mais com testes adicionais e melhorias no sistema e o que deve ser evitado.
Na pilha do decodificador-transformador, o nível de autocontrole é crucial e certamente nos dará uma vantagem, já que a rede de propagação progressiva usada aqui é bastante simples. Assim, a importância relativa de cada mudança de preço anterior é registrada de tal forma que as funções correlacionais são facilmente ocultadas, pois estão focadas em médias. O uso de perceptrons multicamadas para coletar matrizes de pesos para vetores de consulta, chave e valor é um dos métodos que podem ser utilizados, já que existem muitas outras maneiras intermediárias de alcançar o objetivo por meio do aprendizado de máquina. Em geral, compreender a sensibilidade da autoatenção à previsibilidade da rede é fundamental.
Limitações e desvantagens
O treinamento da rede para a nossa classe de sinais é feito de forma incremental em cada nova barra, e a capacidade de carregar pesos pré-treinados não é usada, o que significa inevitavelmente que teremos muitos resultados aleatórios. Devido a isso, o leitor deve esperar um conjunto diferente de resultados a cada execução da classe de sinais.
Além disso, a capacidade de armazenar os pesos treinados no final da classe de sinal não é utilizada, o que significa que não podemos utilizar o que aprendemos aqui.
Essas limitações são críticas e, na minha opinião, precisam ser abordadas antes que alguém prossiga com o desenvolvimento adicional do decodificador-transformador em um sistema de negociação. Não só precisamos de utilizar pesos treinados, como de armazenar os pesos de treinamento, mas também de testar dados fora da amostra com pesos treinados antes de implementar o sistema.
Considerações finais
O algoritmo ChatGPT está relacionado a transformações naturais? Possivelmente. Isso se deve ao fato de que, se considerarmos as pilhas do decodificador-transformador como categorias, então os threads (operações paralelas realizadas através do transformador) seriam funtores. Por esta analogia, a diferença entre os resultados finais de cada operação seria equivalente a uma transformação natural.
Nosso decodificador-transformador, mesmo sem uma adequada gravação e leitura de pesos, demonstrou algum potencial. Isso é, sem dúvida, um sistema interessante que pode continuar a ser desenvolvido e, inclusivamente, ser acrescentado ao seu conjunto de ferramentas à medida que as suas vantagens aumentam.
Para concluir, é notável que o algoritmo de autoatenção seja capaz de quantificar o grau de semelhança relativa entre tokens (dados de entrada do transformador). No nosso caso, esses tokens representavam mudanças de preços em momentos diferentes, mas sequenciais. Em outros modelos, poderiam ser vários indicadores econômicos, eventos de notícias ou sentimentos de investidores, etc., mas o processo seria o mesmo, embora o resultado com essas diferentes entradas inevitavelmente revelaria e, assim, modelaria a complexa e dinâmica relação dessas entradas, ajudando o desenvolvedor a entender melhor. A longo prazo, isso permitiria que o transformador adaptativamente extraísse as características relevantes dos tokens de entrada a cada nova sessão de treinamento. Assim, mesmo em situações voláteis em que há muitas notícias, o modelo deve filtrar o ruído e ser mais robusto.
Além disso, o algoritmo de autoatenção, ao lidar com dados atrasados ou de diferentes momentos no tempo (como no exemplo da classe de sinais anexa), ajuda a quantificar a importância relativa desses diferentes períodos e, assim, captura dependências de longo alcance. Isso leva à capacidade de fazer previsões em diferentes horizontes de tempo, o que representa outra vantagem para os traders. Portanto, resumindo, o peso relativo dos tokens de entrada deve fornecer aos traders informações não apenas sobre os diferentes indicadores econômicos que podem ser as entradas, mas também sobre diferentes timeframes, caso sejam usados indicadores (ou preços) com atraso temporal.
Recursos adicionais
Principalmente referências a artigos na Wikipédia, publicações da Universidade de Cornell, Stack Exchange e este site.
Nota do autor
O código-fonte fornecido neste artigo NÃO é o código usado pelo ChatGPT. É apenas uma implementação de um transformador-decodificador. Ele possui o formato de classe de sinal, o que significa que o usuário precisa compilá-lo usando o assistente MQL5 para montar um Expert Advisor testável. O manual pode ser encontrado aqui. Além disso, o usuário precisa implementar mecanismos de leitura e gravação para ler e armazenar os pesos de rede resultantes.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13348
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Artigo publicado Teoria da categoria em MQL5 (Parte 20): Auto-atenção e transformador:
Autor: Stephen Njuki