
Redes neurais em trading: Modelo de consultas temporais (Final)

Introdução
O framework TQNet representa uma das abordagens mais elegantes e flexíveis para a construção de modelos de redes neurais capazes de processar séries temporais e dados estruturados com eficiência. Sua principal vantagem está na capacidade de combinar dependências locais e globais, criando uma espécie de equilíbrio entre profundidade de análise e eficiência computacional. Diferentemente das arquiteturas tradicionais, o TQNet integra de forma natural mecanismos de processamento sequencial de dados e métodos para capturar dependências de longo prazo. Isso é especialmente valioso ao trabalhar com séries temporais financeiras, nas quais importam tanto as oscilações imediatas quanto as tendências distribuídas ao longo do tempo.
A base do algoritmo está em uma lógica computacional original. O tensor de correlações globais desempenha um papel central nessa lógica. Ele forma uma espécie de mapa de relações entre os elementos da sequência, permitindo que o modelo capture padrões locais e construa uma representação completa da estrutura dos dados.
Os cálculos dentro do TQNet podem ser descritos como uma sequência de etapas coordenadas. Na primeira etapa, os dados de entrada passam por uma camada de geração de características locais, na qual são extraídas as principais características do estado atual. Em seguida, é ativado o mecanismo de correlação global, que sobrepõe a essas características as dependências estruturais acumuladas ao longo de todos os passos anteriores. Esse esquema iterativo permite que o modelo se ajuste com flexibilidade às condições em mudança e leve em conta padrões ocultos. O diferencial da abordagem está no fato de que o modelo não fica limitado a uma ordem rígida no fluxo dos dados: as relações podem ser formadas em qualquer direção dentro da sequência, ampliando suas possibilidades em tarefas de previsão e análise.
O valor prático do TQNet se manifesta em condições nas quais os dados estão sujeitos a ruído ou têm uma estrutura interna complexa. Mercados financeiros, previsões meteorológicas, análise de processos industriais: em todos esses casos, importa não apenas o nível de precisão da previsão, mas também a robustez do modelo diante de valores atípicos inesperados e mudanças na dinâmica. Graças a um algoritmo bem estruturado de atualização de parâmetros e ao uso eficiente dos recursos computacionais, o TQNet opera de forma estável mesmo em grandes datasets, sem exigir custos excessivos de treinamento.
A visualização do framework elaborada pelos autores é apresentada abaixo.
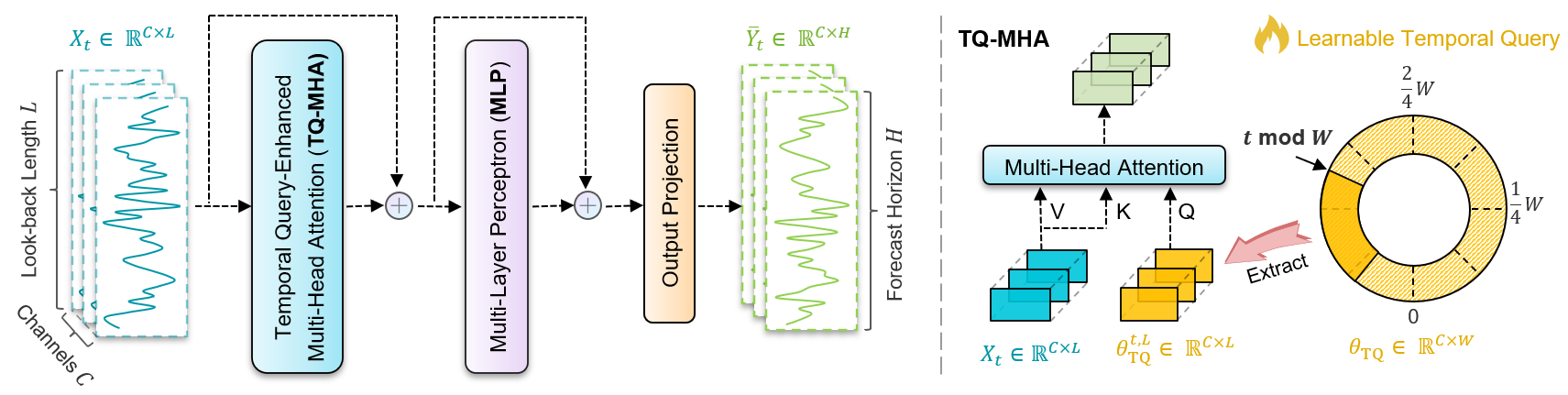
No artigo anterior, conhecemos os aspectos teóricos do framework TQNet: sua arquitetura modular, sua capacidade de se adaptar com flexibilidade às realidades do mercado e seu uso econômico dos recursos. No entanto, a teoria é apenas o esqueleto. Também analisamos o objeto CCircleParams, que permite armazenar correlações globais na forma de objetos alternados dinamicamente a cada passo temporal. Hoje, continuamos, em MQL5, a construir as abordagens propostas pelos autores do framework TQNet.
Módulo TQ-MHA
A próxima etapa lógica, à qual chegamos depois de implementar com sucesso o algoritmo que organiza o carrossel de tensores de parâmetros de correlação, é a criação do módulo TQ-MHA. Na concepção dos autores, esse módulo desempenha um papel especial: ele funciona como um filtro inteligente, capaz de analisar os parâmetros de correlação acumulados não de forma isolada, mas em estreita relação com os dados de entrada analisados. Em outras palavras, ele processa as estatísticas e tenta captar o tecido vivo das relações, complementando essas relações com o contexto de mercado atual. Essa abordagem pode ser comparada ao trabalho de um analista experiente, que não se limita a tabelas e gráficos frios, mas sempre põe os números à prova, confrontando-os com eventos reais e com a dinâmica do mercado.
Se compararmos com soluções arquiteturais já conhecidas, o TQ-MHA é, em muitos aspectos, próximo ao módulo de atenção cruzada. No entanto, há aqui uma particularidade: em vez de uma comparação direta entre dois fluxos de informação, Chaves e Consultas, temos um processo mais refinado. O módulo TQ-MHA sobrepõe os dados de entrada às matrizes de dependências de correlação, destacando as interseções mais significativas. Isso não é apenas uma otimização técnica, mas um novo nível de análise, que permite ao framework interpretar os sinais de mercado em um contexto mais amplo.
Aqui vale destacar outro ponto interessante. Nos módulos de atenção cruzada que implementamos anteriormente, seguindo os cânones das arquiteturas transformer, sempre havia um bloco FeedForward: um elemento compacto, mas importante, que atua como transformador não linear dos dados entre as camadas de atenção. Já os autores do framework TQNet omitem formalmente esse bloco, como se deixassem fora de cena uma etapa inteira da cadeia habitual. À primeira vista, isso pode parecer uma simplificação, mas, ao examinar com mais atenção a lógica interna do framework, descobrimos que, após o TQ-MHA, vem um módulo MLP que, na prática, reproduz toda a funcionalidade do bloco FeedForward clássico.
A diferença está apenas em um detalhe: as funções de ativação. Para nós, porém, isso não representa um obstáculo; pelo contrário, abre espaço para experimentação. Podemos, sem grande dificuldade, substituir a função de ativação por aquela que melhor se alinhe às nossas tarefas e às especificidades das séries temporais financeiras.
Assim, chegamos ao desenvolvimento do objeto especializado CNeuronTQMHA, que combina a lógica da atenção cruzada com o uso dos parâmetros de correlação acumulados e garante uma interação fluida com os demais módulos do framework. A estrutura da nova classe é apresentada abaixo.
class CNeuronTQMHA : public CNeuronCrossAttention { protected: uint iTimeframe; CCircleParams cParams; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); public: CNeuronTQMHA(void) {}; ~CNeuronTQMHA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_in, uint period, uint timeframe, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronTQMHA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj); };
A classe CNeuronTQMHA herda a funcionalidade-base e a maior parte dos objetos internos do objeto de atenção cruzada CNeuronCrossAttention. Mas, diferentemente da variante básica da atenção cruzada, ela é voltada a operar com parâmetros de correlação recebidos do carrossel de tensores.
No corpo da classe, declaramos apenas dois elementos-chave. O primeiro é iTimeframe, que fixa o tamanho do passo temporal para a troca da matriz de correlações em nosso carrossel. O segundo é cParams, uma instância da classe CCircleParams, responsável pelos parâmetros de correlação acumulados. São justamente esses parâmetros que se tornam a matéria-prima que a atenção multicabeça analisará no contexto dos dados de entrada.
Os objetos internos da nossa classe são declarados estaticamente, portanto o construtor e o destrutor podem permanecer vazios: nada desnecessário acontece durante a criação ou a destruição do objeto. Todas as operações pesadas são transferidas para o método de inicialização. Isso proporciona uma semântica limpa e previsível para o ciclo de vida do objeto: a criação tem baixo custo, enquanto a preparação para uso é controlada e explícita.
O método Init executa várias etapas importantes e verifica cuidadosamente o resultado de cada uma delas.
bool CNeuronTQMHA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint period, uint timeframe, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, heads, units_count, window, units_count, optimization_type, batch)) return false;
Primeiro, o controle é passado para o método homônimo da classe-base, o que permite herdar e configurar a lógica básica da atenção cruzada. Se a inicialização básica falhar por algum motivo, o método retorna false imediatamente. Essa saída antecipada protege contra a propagação de um estado incorreto pela pilha e simplifica a depuração.
Em seguida, configuramos a função de ativação entre as camadas do bloco FeedForward.
FF[0].SetActivationFunction(GELU);
Como já discutimos acima, o MLP usado pelos autores do framework após o TQ-MHA cumpre, em essência, o papel do bloco FeedForward clássico. E a troca da função de ativação permite escolher com flexibilidade a não linearidade mais adequada às especificidades das séries financeiras. A GeLU oferece uma aproximação mais suave e, em dados ruidosos, muitas vezes se comporta de forma mais estável do que o comportamento mais abrupto da ReLU. Os impulsos instantâneos do mercado não afetam essa função de maneira tão brusca, o que torna o treinamento mais regular.
O parâmetro iTimeframe é protegido por um limite inferior de valores. Trata-se de uma proteção simples, mas importante: o valor do parâmetro não pode cair para zero. Na prática, isso significa que, mesmo em caso de configuração incorreta, o módulo funcionará no modo minimamente aceitável.
iTimeframe = MathMax(1, timeframe); if(!cParams.Init(0, 0, OpenCL, window * units_count, period, optimization, iBatch)) return false; if(!cParams.Zeros()) return false; //--- return true; }
A etapa central da inicialização é a preparação do objeto cParams. Aqui, criamos explicitamente a estrutura interna das correlações globais. Para cada janela temporal (window) e para cada sequência unitária analisada (units_count), é criado o elemento correspondente no tensor de correlações. A inicialização vincula esses buffers ao contexto OpenCL, garantindo eficiência nas etapas posteriores de processamento de grandes volumes de dados.
Por fim, a chamada cParams.Zeros define a estratégia de inicialização recomendada pelos autores: todos os parâmetros da memória global são definidos como zero. Essa é uma decisão importante de design: a inicialização com zeros remove vieses iniciais nas correlações e dá ao modelo uma folha em branco limpa, na qual ele próprio constrói as relações com base apenas nos dados do conjunto de treinamento. Esse ponto de partida muitas vezes é preferível à inicialização aleatória em tarefas nas quais não queremos introduzir ruídos externos no nível dos parâmetros de memória.
Se todas as etapas forem concluídas com sucesso, o método retorna true: o objeto está totalmente preparado para uso: os buffers foram criados, a função de ativação foi configurada e a memória periódica está pronta e limpa. Em conjunto, esse método estabelece uma base robusta, previsível e eficiente para as operações seguintes, nas quais CNeuronTQMHA começará de fato a associar os vetores θ acumulados aos dados analisados e a aprender com cotações históricas.
Depois de descrever a estrutura da classe, é natural passar à análise de sua principal rotina de execução: o algoritmo de propagação para frente. O método começa pela etapa mais simples, mas fundamental: verificar se o ponteiro recebido para o buffer SecondInput é válido.
bool CNeuronTQMHA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
Nesse buffer, esperamos receber um marcador para posicionar o carrossel de parâmetros de correlação. Se ele estiver ausente, a execução é interrompida imediatamente e o método retorna false. Essa verificação protege o módulo contra chamadas incorretas e evita cálculos posteriores sem sentido.
Em seguida, determinamos a posição atual no carrossel. Para isso, lemos o elemento de índice zero do buffer SecondInput. Na prática, esperamos obter aqui o horário de abertura da última barra.
int pos = int(SecondInput[0]); pos = (pos / int(iTimeframe)) % cParams.GetPeriod(); if(!cParams.SetPosition(pos) || !cParams.FeedForward()) return false;
O valor inteiro obtido é então convertido em um índice de posição no carrossel de parâmetros. Primeiro, ao dividi-lo por iTimeframe, agrupamos os passos sequenciais em blocos do tamanho definido, obtendo assim o número do bloco. Em seguida, o resto da divisão pelo tamanho do período dos dados fornece o índice do elemento correspondente no carrossel de parâmetros de correlação. Em conjunto, essas duas operações implementam a ideia de memória periódica: para instantes que pertencem ao mesmo bloco e estão separados pelo comprimento do período, será usado o mesmo conjunto de vetores TQ.
O bloco seguinte seleciona de forma estrita a versão ativa dos parâmetros e executa nela a propagação para frente, durante a qual os parâmetros de correlação são preparados para uso. Se ocorrer um erro em qualquer uma dessas etapas, o método encerra a execução retornando false. Esse comportamento garante que, adiante, trabalhemos sempre com um conjunto de parâmetros globais corretamente preparado.
As etapas seguintes repetem a lógica do módulo de atenção cruzada. E poderíamos passar o controle para o método homônimo da classe-base, mas isso gera um problema semântico. Na implementação básica, as conexões residuais passam pelo caminho principal das consultas (Query). No nosso caso, Query não é uma representação local da janela atual, mas sim os vetores TQ acumulados, ou seja, a memória global. Se encaminharmos essa mesma memória pelo caminho das conexões residuais, corremos o risco de apagar o sinal local atual de Key/Value e suprimir características importantes vindas dos dados de entrada. Nos mercados financeiros, isso se manifestaria rapidamente: o modelo passaria a depender mais da estrutura histórica e reagiria pior a impulsos recentes, levando à queda da precisão.
Por isso, reutilizamos conscientemente a lógica de baixo nível do cálculo de atenção, mas implementamos nossa própria lógica de conexões residuais e normalização dos resultados. Isso preserva a influência dos dados atuais e, ao mesmo tempo, usa a informação global dos vetores TQ no cálculo dos pesos de atenção.
Depois que os vetores globais de correlação são ativados e preparados, nós os projetamos no espaço das Consultas.
if(!Q_Embedding.FeedForward(cParams.AsObject())) return false; //--- if(!KV_Embedding.FeedForward(NeuronOCL)) return false;
Aqui, Q_Embedding executa a projeção linear das correlações globais e as distribui pelas cabeças de atenção.
Em paralelo, são formadas as chaves e os valores com base nos dados de entrada recebidos do programa externo. Como resultado, temos dois fluxos: Consultas globais, que carregam a "memória" das dependências de longo prazo, e Key/Value locais, que refletem o comportamento atual do mercado.
A chamada seguinte do método herdado attentionOut é responsável pelo cálculo da atenção multicabeça. Nessa etapa, ocorre a operação MHA padrão. O resultado é uma matriz de atenção por cabeça, agregada no buffer geral MHAttentionOut.
É importante notar que aqui é implementada justamente a lógica de combinar o global, Query a partir de θTQ, com o local, Key/Value a partir dos dados de entrada. Esse é o núcleo da abordagem TQ.
if(!attentionOut()) return false; //--- if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false; //--- if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
Depois de obtidos os resultados da atenção, eles passam pela projeção de saída. Trata-se da mesma matriz WO, que combina as saídas de todas as cabeças de atenção de volta à dimensionalidade do espaço dos dados de entrada.
Em seguida, somam-se os dados dos dois fluxos de informação e normalizam-se os resultados obtidos. Esse é o passo padrão das conexões residuais. À projeção da atenção é adicionado o tensor dos dados de entrada, e depois o resultado é normalizado ao longo da janela iWindow. Essa construção estabiliza o treinamento, preserva a informação da entrada e impede o enfraquecimento dos sinais. A normalização aqui também atua como proteção contra a deriva da distribuição, algo crítico para séries financeiras com volatilidade variável.
Em seguida, é iniciada a sequência do bloco MLP.
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false; //--- if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
São duas etapas de perceptron multicamadas com uma não linearidade intermediária; em nossa implementação, usamos GeLU. Em termos de função, essas camadas desempenham o mesmo papel do FeedForward tradicional nos transformers: ampliam a representação, introduzem não linearidade, reforçam características úteis e ajustam o espectro de frequências ao qual o modelo é sensível no sinal.
Por fim, a segunda chamada de SumAndNormilize combina a saída do MLP com a representação anterior, normaliza e gera o resultado final. Esse passo conclui o ciclo completo de processamento: da extração dos vetores TQ globais até a obtenção de uma representação adaptada e normalizada para o próximo nível do modelo.
Se todas as etapas forem concluídas com sucesso, o método retorna true, sinalizando a execução correta da propagação para frente e que os resultados estão prontos para uso.
Um detalhe arquitetural importante é a sequência de verificações antecipadas e retornos de emergência: elas economizam recursos e impedem o uso inconsistente dos buffers OpenCL, algo crítico em ambientes de produção.
Após a discussão da propagação para frente, chegamos à etapa espelhada: a distribuição dos gradientes de erro dentro de CNeuronTQMHA. Aqui seguimos na ordem inversa dos cálculos: das saídas do bloco de volta aos dados de entrada, acumulando cuidadosamente os sinais de erro e distribuindo-os por todos os componentes: MLP, Attention, projeções e memória global cParams.
bool CNeuronTQMHA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!prevLayer) return false;
No corpo do método, verificamos imediatamente se o ponteiro recebido para o objeto dos dados de entrada é válido. Esse passo funciona como uma proteção simples, mas criticamente importante. Se não houver camada anterior, não é possível continuar uma cadeia de cálculo inválida.
Em seguida, começamos a extrair os gradientes a partir do fim da cadeia MLP. Os parâmetros internos do MLP recebem a contribuição correta do erro, enquanto os gradientes são preparados cuidadosamente para seguir adiante pela cadeia.
if(!FF[0].CalcHiddenGradients(FF[1].AsObject())) return false; if(!AttentionOut.CalcHiddenGradients(FF[0].AsObject())) return false;
A próxima linha de código transfere o sinal do MLP de volta ao ponto em que o MLP recebeu os dados, ou seja, para AttentionOut. Em outras palavras, informamos ao bloco de atenção: esta é a parte do erro explicada pelo processamento realizado pelo MLP; distribua-a entre suas entradas. Isso garante a consistência entre o refinamento não linear da representação e a própria representação formada pela Attention.
Mas, antes de avançar, precisamos calcular os gradientes de erro do segundo fluxo de informação das conexões residuais, a fim de formar o gradiente para a projeção W0 e preparar a propagação desse gradiente para as camadas inferiores.
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false; if(!MHAttentionOut.CalcHiddenGradients(W0.AsObject())) return false; if(!AttentionInsideGradients()) return false;
O passo seguinte propaga o gradiente para a saída da atenção multicabeça, formada antes da projeção W0. Em outras palavras, "desfazemos" a projeção W0: seu gradiente já foi calculado, agora precisamos saber quais sinais de erro chegam às próprias cabeças de atenção.
A chamada AttentionInsideGradients é a operação-chave para decompor os componentes internos da Attention. Aqui são calculados os gradientes de todos os componentes internos do mecanismo de atenção, chegando ao final aos tensores Query, Key e Value. Esse passo é responsável por transformar o sinal de erro agregado, vindo do espaço das cabeças de atenção combinadas, em contribuições separadas para as Consultas globais e as Chaves/Valores locais.
Em seguida, transmitimos os gradientes acumulados em direção aos dados de entrada, isto é, ao prevLayer, a entrada local. Chamamos o método correspondente para distribuir corretamente o erro entre os pesos e preparar os gradientes para o próprio prevLayer.
if(!prevLayer.CalcHiddenGradients(KV_Embedding.AsObject())) return false; if(!cParams.CalcHiddenGradients(Q_Embedding.AsObject())) return false;
Em paralelo, realizamos a atualização espelhada da memória global: os gradientes obtidos para as Consultas (Query) são propagados para cParams. Assim, o treinamento afeta não apenas as projeções locais, mas também os próprios parâmetros da memória global de correlação: a contribuição de erro é acumulada cuidadosamente em θTQ, que depois será usada na atualização dos pesos.
Depois de separar as contribuições, precisamos complementar o gradiente de erro dos dados de entrada com os valores provenientes da via principal dos dados de entrada. Antes disso, porém, corrigimos esses valores pela derivada da função de ativação da camada anterior. Só então podemos somar os resultados dos dois fluxos de informação.
if(!DeActivation(prevLayer.getOutput(), W0.getPrevOutput(), W0.getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), W0.getPrevOutput(), prevLayer.getGradient(), iWindow_K, false)) return false; //--- return true; }
Esse é um passo importante: ele garante que o gradiente final transmitido para prevLayer leve em conta tanto a influência da entrada local quanto a contribuição da projeção W0, distribuída corretamente considerando a normalização aplicada na propagação para frente.
Após a execução bem-sucedida de todas essas etapas, o método sinaliza a distribuição correta dos gradientes por todos os componentes internos do módulo e que tudo está pronto para a etapa de atualização dos pesos.
Depois da distribuição cuidadosa dos gradientes de erro por todas as estruturas internas do neurônio, vem a etapa natural de aplicá-los na prática: a atualização dos parâmetros. O método updateInputWeights fecha o ciclo de treinamento. Ele recebe os gradientes calculados e os aplica sequencialmente às projeções, ao MLP e, o que é especialmente importante, à própria memória global de correlação.
A abordagem modular que usamos permite criar um método de atualização de parâmetros bastante conciso. Apenas passamos sequencialmente o controle para os métodos homônimos dos objetos internos, passando os ponteiros corretos para os buffers correspondentes dos dados de entrada.
bool CNeuronTQMHA::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cParams.UpdateInputWeights()) return false; if(!Q_Embedding.UpdateInputWeights(cParams.AsObject())) return false; if(!KV_Embedding.UpdateInputWeights(NeuronOCL)) return false; if(!W0.UpdateInputWeights(GetPointer(MHAttentionOut))) return false; if(!FF[0].UpdateInputWeights(GetPointer(AttentionOut))) return false; if(!FF[1].UpdateInputWeights(GetPointer(FF[0]))) return false; //--- return true; }
O método updateInputWeights é o fechamento controlado do ciclo de treinamento. Ele garante que a memória global de correlações e todas as suas projeções, com as transformações subsequentes, recebam atualizações corretas e consistentes, algo especialmente importante para a aplicação robusta e confiável do TQNet em tarefas de previsão de séries temporais financeiras.
O código completo da classe CNeuronTQMHA e de todos os seus métodos é apresentado no arquivo anexo.
Arquitetura do modelo
Depois de montar todos os componentes principais do framework TQNet, passamos à etapa seguinte: descrever a arquitetura dos modelos treináveis. Como antes, nosso objetivo é treinar um sistema de trading capaz de analisar autonomamente o contexto de mercado e tomar decisões de negociação. O treinamento é conduzido no paradigma Ator-Crítico, em que o TQNet atua como Codificador do estado do ambiente. Ele gera uma representação compacta e informativa da situação atual do mercado, na qual o Ator se apoia para escolher ações e o Crítico para avaliar a qualidade dessas ações.
Diferentemente da versão inicial do TQNet, ampliamos o modelo na parte de preparação dos dados e geração de características: foram adicionados blocos de pré-processamento e agregação de informações contextuais, o que aumenta a robustez e a capacidade de generalização do sistema. A descrição da arquitetura dos modelos é criada no método CreateDescriptions. Nele, é montada a sequência-base de camadas que sustenta toda a lógica posterior de treinamento e inferência.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&actor, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
O método começa com uma tarefa simples, mas importante: se os ponteiros para os contêineres de camadas estiverem vazios, ele cria novos objetos. Isso não é apenas uma formalidade: garantimos que cada um dos três blocos da arquitetura receba sua própria coleção independente de descrições de camadas, pronta para ser preenchida sequencialmente. Essa alocação explícita torna o fluxo mais claro. O código posterior pode assumir a presença do contêiner e não precisa verificar se ele continua válido em vários pontos.
Em seguida, passamos à montagem do Codificador, o elemento central do nosso modelo. Limpamos o contêiner e adicionamos sequencialmente as descrições das camadas; cada etapa é acompanhada por uma verificação rigorosa de sucesso: se a criação do objeto ou sua adição ao array falhar por algum motivo, o método libera cuidadosamente os recursos e retorna um erro. Essa disciplina no gerenciamento de memória e de estados é útil tanto na depuração quanto em produção: ela impede que os problemas se espalhem pela pilha.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A primeira camada do Codificador é a camada de neurônio básico CNeuronBaseOCL, cujo número de neurônios é definido como o produto HistoryBars * BarDescr. A ideia aqui é clara: alimentamos a rede com uma janela histórica dividida por características descritivas. Essa camada não contém ativação; ela serve como porta de entrada, um buffer ao qual simplesmente fornecemos os dados de entrada.
O bloco seguinte, CNeuronBatchNormWithNoise, preserva a dimensionalidade da camada anterior, mas adiciona normalização e regularização com ruído. Isso não é um detalhe decorativo: as séries financeiras estão sujeitas a deriva da distribuição e a valores atípicos. BatchNorm com ruído aumenta a robustez diante dessas anomalias, normaliza as entradas para as camadas seguintes e, ao mesmo tempo, estimula o modelo a não se ajustar em excesso a pequenas variações aleatórias.
Depois da normalização, passamos à transformação da estrutura temporal por meio de CNeuronConcatDiff. Essa camada reúne o histórico por barras, mas faz isso com foco nas diferenças com passo (step = 1), fornecendo uma representação explícita da dinâmica: não apenas dos níveis, mas também de suas variações. Essa técnica muitas vezes oferece ao modelo uma percepção melhor dos sinais da tendência, da inércia e das reversões locais.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatDiff; prev_count = descr.count = HistoryBars; descr.layers = BarDescr; descr.step = 1; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, vem a camada CMamba4CastEmbeding, que implementa uma lógica de múltiplas janelas de incorporação de marcas de tempo sinusoidais. Isso dá ao modelo a capacidade de observar simultaneamente padrões de curto e longo prazo, formando uma representação rica do contexto de mercado.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = 2 * BarDescr; uint prev_out = descr.window_out = NSkills; { uint temp[] = {PeriodSeconds(PERIOD_D1), PeriodSeconds(PERIOD_MN1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui vale observar que as operações anteriores eram executadas na representação de uma série temporal multimodal. Já para que o framework TQNet opere corretamente, precisamos de uma sequência de séries temporais unitárias. Por isso, no passo seguinte, transpomos o tensor, reorganizando as dimensões para a aplicação posterior da atenção.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count;
Agora nos aproximamos do núcleo: a camada CNeuronTQMHA. Aqui, definimos o tamanho do período como o produto 24*7, o que corresponde a uma semana do calendário no timeframe H1. O tamanho do passo corresponde à quantidade de segundos em uma barra do timeframe indicado. Queremos que o carrossel TQ armazene padrões semanais e os recupere com o passo do timeframe H1.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTQMHA; { uint temp[] = {prev_out, 64, 24*7, PeriodSeconds(PERIOD_H1)}; // window, window_key, period, timeframe if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.step=NHeads; descr.count=prev_count; descr.batch = BatchSize; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } uint count = prev_count; uint window = prev_out;
Observe que usamos a semana do calendário (7 dias), mesmo que o instrumento analisado não seja negociado nos fins de semana. Essa é uma medida necessária, pois calculamos o elemento do carrossel a partir do horário de abertura da barra.
Em seguida, vem uma camada convolucional com ativação TANH, que serve para compactar e projetar as representações obtidas para o horizonte de planejamento definido. Esta é a etapa em que a representação rica é convertida em sinais preditivos concretos.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.count;
Depois, ocorre uma nova transposição, para devolver os dados à representação de sequência multimodal, semelhante à dos dados de entrada.
Outra convolução tem a função de compactar a dimensionalidade das características até o nível dos dados de entrada.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Essas operações convolucionais atuam como agregadores locais: acumulam informações entre os componentes da previsão e geram uma representação pronta para a desnormalização.
O Codificador é concluído pela camada CNeuronRevInDenormOCL. Esse módulo devolve as previsões à escala original, restaurando a média e a dispersão dos dados analisados, que haviam sido removidas na etapa de pré-processamento.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
Para aplicações financeiras, isso é fundamental: as previsões precisam ter uma escala interpretável, adequada para trading e cálculo de riscos.
Em toda a arquitetura, observa-se uma ideia central: primeiro, preparar e normalizar cuidadosamente a entrada; depois, extrair características dinâmicas e incorporações em diferentes escalas; em seguida, aplicar a atenção reforçada por TQ; e, por fim, agregar e projetar os valores previstos no espaço dos dados de entrada, com restauração da escala.
As arquiteturas dos modelos do Ator e do Crítico foram transferidas dos trabalhos anteriores sem alterações, por isso não vamos nos deter agora em sua análise detalhada. A solução arquitetural completa de todos os modelos treináveis é apresentada no arquivo anexo.
Teste
O treinamento foi estruturado em duas etapas sequenciais e complementares, o que proporciona uma base robusta e flexibilidade para operar em condições reais de mercado.
Na primeira etapa, offline, realizamos um treinamento sólido com dados históricos do par EURUSD no timeframe H1 durante todo o ano de 2024. Esse ano incluiu um conjunto completo de regimes de mercado: lateralizações tranquilas, tendências sustentadas, saltos repentinos de volatilidade e períodos de aumento do ruído. Por isso, ele funciona muito bem como um ambiente de aprendizado para o modelo.
A segunda etapa foi o ajuste fino online. O treinamento foi implementado em um ambiente o mais próximo possível do trading real: no testador de estratégias do MetaTrader 5, o modelo processava o fluxo de barras sequencialmente, como aconteceria em tempo real. O modo online revela propriedades completamente diferentes das observadas no treinamento em lote: a capacidade de lidar com ruído, reagir a mudanças de liquidez, considerar corretamente atrasos e o efeito do slippage acumulado na execução. Durante o ajuste, simulamos condições reais de execução para que o comportamento do modelo fosse previsível ao ser transferido para condições reais de trading.
A etapa final e, talvez, a mais rigorosa foi a verificação em um conjunto totalmente externo: cotações de janeiro a março de 2025. Todos os parâmetros do modelo e todos os hiperparâmetros permaneceram congelados; não houve ajuste adicional para esses dados. Esse tipo de verificação oferece uma visão objetiva da eficiência prática, pois reflete a capacidade do algoritmo de manter previsibilidade e robustez em novas condições.
Os resultados dos testes são apresentados abaixo.


Os resultados do teste mostraram uma vantagem estatística positiva bastante pequena. Com um depósito inicial de 100 dólares, o lucro líquido foi de 21,07 dólares. A proporção de operações lucrativas ficou próxima de 49%. Além disso, as posições vendidas encerraram com lucro com um pouco mais de frequência do que as longas. A operação lucrativa média gerou 1,13 dólar, enquanto a operação perdedora média foi de 0,92 dólar. O fator de lucro de 1,18, com uma expectativa de retorno de 0,09 dólar por operação, indica que a margem de segurança é mínima.
A regressão linear sobre a curva de rentabilidade mostra correlação de 0,86, mas o erro continua perceptível. Isso confirma o caráter ruidoso dos resultados.
O perfil de risco ainda está longe do ideal. Drawdowns elevados, combinados com uma pequena expectativa de retorno por operação, não permitem aumentar o capital com segurança. Ao mesmo tempo, a carga sobre a margem é baixa, o que significa que o problema não está no tamanho das posições, mas na qualidade dos pontos de entrada e na disciplina de fechamento.
Conclusão
Neste trabalho, analisamos em detalhes os fundamentos teóricos do framework TQNet, bem como as particularidades de sua integração à arquitetura de modelos de trading treináveis. Foram examinados os princípios centrais de desenvolvimento dos módulos, incluindo mecanismos modificados de atenção cruzada, o que permitiu alcançar um funcionamento mais flexível e robusto do algoritmo nas condições dos mercados financeiros.
Na parte prática do projeto, implementamos em MQL5 as abordagens propostas no TQNet, complementando-as com melhorias próprias na geração de características e no pré-processamento dos dados. O modelo foi treinado em duas etapas: com dados históricos (treinamento offline) e em condições próximas às de mercado real (ajuste online no testador de estratégias do MetaTrader 5).
Os testes finais em cotações novas, não utilizadas anteriormente, mostraram uma dinâmica positiva. O saldo da conta demonstrou crescimento consistente após um período inicial de drawdown, o que indica a capacidade do algoritmo de se adaptar às condições de mercado em mudança.
Os resultados obtidos confirmam que o TQNet, em combinação com soluções arquiteturais aprimoradas e um treinamento em duas etapas, é capaz de proporcionar uma expectativa matemática positiva.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA para treinamento offline de modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA para treinamento online de modelos |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrever o estado do sistema e a arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19181
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso