
Treinamento de um U-Transformer não linear nos resíduos de um modelo autorregressivo linear

No trading algorítmico moderno, os desenvolvedores se deparam com um dilema fundamental: os modelos lineares são simples e interpretáveis, mas não conseguem capturar dependências não lineares complexas em séries temporais financeiras. As redes neurais profundas, por outro lado, em teoria, são capazes de modelar qualquer tipo de não linearidade, mas sofrem com sobreajuste e instabilidade em ambientes marcados por alto ruído de mercado e quantidades limitadas de dados.
Este artigo apresenta uma abordagem híbrida inovadora que resolve esse dilema por meio de uma modelagem em duas etapas: primeiro, um modelo autorregressivo linear com 25 atributos extrai dos dados de preço os principais padrões estatísticos; em seguida, uma arquitetura U-Transformer especializada é treinada nos resíduos do modelo linear, identificando padrões não lineares ocultos que a primeira etapa não conseguiu capturar.
A principal inovação está na adaptação da arquitetura U-Net, originalmente criada para segmentação de imagens, com a integração de blocos Transformer para análise de séries temporais. O sistema foi implementado em MQL5 e inclui uma lógica de negociação completa, com gerenciamento dinâmico de posições, reotimização automática de parâmetros e aprendizado online da rede neural.
A validação experimental demonstra a superioridade da abordagem híbrida em relação aos métodos puramente lineares, preservando ao mesmo tempo a eficiência computacional e a interpretabilidade dos resultados. O sistema apresentado é capaz de operar em tempo real, adaptando-se automaticamente às mudanças nas condições de mercado.
Introdução
Os mercados financeiros são sistemas adaptativos complexos, nos quais os métodos tradicionais de previsão enfrentam uma série de desafios fundamentais. O primeiro e mais evidente é o problema da não linearidade. Os dados de mercado exibem padrões complexos que não podem ser descritos por simples relações lineares: mudanças de regime na volatilidade, reações assimétricas a notícias e efeitos em cascata de liquidez. No entanto, as tentativas de aplicar modelos não lineares poderosos de machine learning a dados financeiros muitas vezes levam ao segundo problema: o sobreajuste e a instabilidade das previsões.
Esse problema é especialmente crítico no trading algorítmico, em que o modelo deve não apenas prever com precisão a direção do movimento do preço, mas também fazê-lo de forma estável em diferentes regimes de mercado, permanecendo ao mesmo tempo computacionalmente eficiente para operar em tempo real. Modelos econométricos clássicos do tipo ARIMA ou VAR oferecem estabilidade e interpretabilidade, mas sua natureza linear impõe restrições rígidas à capacidade de modelar a dinâmica complexa do mercado.
Por outro lado, arquiteturas modernas de deep learning, como LSTM, GRU e Transformer, em teoria, são capazes de aproximar quaisquer dependências não lineares, mas sua aplicação a dados financeiros é dificultada por vários fatores. Em primeiro lugar, o alto nível de ruído nos dados de mercado faz com que as redes neurais comecem a "memorizar" flutuações aleatórias em vez de aprender padrões reais. Em segundo lugar, a não estacionariedade das séries financeiras significa que os padrões aprendidos em dados históricos podem perder relevância rapidamente.
O terceiro problema é de ordem prática: as limitações computacionais das plataformas de trading, especialmente na linguagem MQL5, não permitem usar frameworks modernos de deep learning plenamente. O desenvolvedor é obrigado a implementar algoritmos de redes neurais "do zero", o que limita significativamente a complexidade das arquiteturas aplicáveis.
A solução proposta neste trabalho baseia-se na ideia de decompor a tarefa de previsão em duas etapas de naturezas distintas: uma etapa linear para capturar os principais padrões estatísticos e uma etapa não linear para modelar dependências residuais complexas. Essa abordagem permite aproveitar os pontos fortes das duas classes de métodos, minimizando suas limitações.
O modelo autorregressivo linear da primeira etapa é construído a partir de um espaço de atributos cuidadosamente projetado, composto por 25 atributos, composto não apenas por lags clássicos de preço, mas também por suas transformações não lineares, indicadores técnicos e componentes cíclicos. Esse modelo é otimizado por descida de gradiente e fornece um nível-base de desempenho preditivo com alta interpretabilidade.
A componente neural da segunda etapa usa uma arquitetura U-Transformer adaptada, que combina os princípios da U-Net, uma estrutura codificador-decodificador com skip connections, e mecanismos de atenção da arquitetura Transformer. A principal característica dessa abordagem está no fato de a rede neural ser treinada não com os dados de preço originais, mas com os resíduos do modelo linear, o que simplifica significativamente a tarefa e reduz o risco de sobreajuste.
Essa decomposição proporciona uma regularização natural: se as condições de mercado mudarem e o componente neural passar a gerar previsões instáveis, o sistema alterna automaticamente para as previsões mais conservadoras do modelo linear. Esse comportamento resulta de um esquema adaptativo de ponderação, no qual o peso do componente neural depende da qualidade atual de ambos os modelos.
Fundamentos teóricos da arquitetura U-Transformer
A arquitetura U-Transformer é uma síntese de dois conceitos poderosos da visão computacional e do processamento de linguagem natural: U-Net e mecanismos de atenção (attention). Originalmente, a U-Net foi desenvolvida para tarefas de segmentação de imagens médicas, nas quais é necessária uma localização precisa dos objetos sem perder o contexto global. A ideia central da U-Net consiste em uma arquitetura codificador-decodificador simétrica com skip connections horizontais, que permitem encaminhar informações detalhadas das camadas iniciais diretamente para as camadas posteriores do decodificador.
No contexto da análise de séries temporais, essa arquitetura ganha um novo significado. O codificador comprime progressivamente a informação temporal, extraindo padrões cada vez mais abstratos, enquanto o decodificador recupera a resolução temporal usando tanto representações abstratas quanto atributos detalhados por meio das skip connections. Isso é especialmente importante para dados financeiros, nos quais flutuações locais podem ser tão relevantes quanto tendências globais.
struct UTransformerNet { NeuralLayer encoder_layers[3]; // Энкодер: сжатие информации NeuralLayer decoder_layers[3]; // Декодер: восстановление разрешения AttentionBlock attention_heads[4]; // Multi-head attention double skip_connections[3][32]; // Горизонтальные связи U-Net double residuals[6000]; // Остатки для обучения double neural_predictions[6000]; // Предсказания нейросети };
O mecanismo de self-attention, herdado da arquitetura Transformer, acrescenta ao modelo a capacidade de concentrar-se dinamicamente nas partes mais relevantes da sequência de entrada. Diferentemente das camadas convolucionais ou recorrentes, a atenção permite que o modelo relacione diretamente eventos distantes no tempo, o que é crítico para os mercados financeiros, onde o impacto dos eventos pode se manifestar com defasagem.
void SelfAttention(double &inputs[], AttentionBlock &attention, double &outputs[]) { double queries[32], keys[32], values[32]; // Вычисление Q, K, V трансформаций for (int i = 0; i < NeuralNodes; i++) { queries[i] = 0; keys[i] = 0; values[i] = 0; for (int j = 0; j < NeuralNodes; j++) { queries[i] += inputs[j] * attention.query_weights[j][i]; keys[i] += inputs[j] * attention.key_weights[j][i]; values[i] += inputs[j] * attention.value_weights[j][i]; } } // Вычисление attention scores: Q × K^T for (int i = 0; i < NeuralNodes; i++) { attention.attention_scores[i] = 0; for (int j = 0; j < NeuralNodes; j++) { attention.attention_scores[i] += queries[i] * keys[j]; } attention.attention_scores[i] /= MathSqrt(NeuralNodes); // Масштабирование } }
A principal diferença entre a arquitetura proposta e os Transformers clássicos está na adaptação para séries temporais unidimensionais, em vez de representações tokenizadas bidimensionais. Em vez de codificação posicional, são usados atributos temporais, como hora do dia e componentes cíclicos, o que permite ao modelo considerar a sazonalidade intradiária das sessões de trading.
Modelo híbrido: regressão linear mais rede neural
A ideia central da abordagem híbrida está na decomposição aditiva da previsão em duas componentes de naturezas distintas:
Финальное_предсказание = Линейная_модель(X) + α × U_Transformer(Остатки)
em que α é um coeficiente de ponderação adaptativo, dependente da qualidade atual de ambos os modelos.
A componente linear é formulado como um modelo autorregressivo clássico com um espaço de atributos ampliado:
// Вычисление линейного предсказания double linear_pred = 0; for (int i = 0; i < 25; i++) linear_pred += g_pair.coeffs[i] * features[i];O componente neural é treinado não com os dados de preço originais, mas com os resíduos do modelo linear:
void TrainUTransformer() { // Вычисление остатков линейной модели for (int i = 0; i < g_pair.data_size; i++) { double linear_pred = 0; for (int j = 0; j < 25; j++) linear_pred += g_pair.coeffs[j] * g_pair.features[i][0][j]; g_pair.neural_net.residuals[i] = g_pair.prices[i] - linear_pred; } // Обучение нейросети на остатках for (int epoch = 0; epoch < NeuralEpochs; epoch++) { double total_loss = 0; for (int i = 0; i < g_pair.data_size; i++) { double prediction = UTransformerForward(g_pair.coeffs, g_pair.neural_net.residuals[i]); double error = prediction - g_pair.neural_net.residuals[i]; total_loss += error * error; } } }
Essa decomposição traz várias vantagens críticas. Em primeiro lugar, a rede neural resolve uma tarefa significativamente mais simples: a modelagem dos resíduos em vez da série original. Em geral, os resíduos apresentam menor variância e propriedades estatísticas mais estacionárias, o que facilita o treinamento e reduz o risco de sobreajuste.
Em segundo lugar, o sistema implementa naturalmente o princípio "fail-safe": se o componente neural começar a gerar previsões instáveis, com loss elevado, o sistema aumenta automaticamente o peso do componente linear:
double GetHybridPrediction(double price_t1, double price_t2, double price_t3) { // Линейное предсказание double linear_pred = 0; for (int i = 0; i < 25; i++) linear_pred += g_pair.coeffs[i] * features[i]; // Нейросетевая коррекция double neural_correction = 0; if (g_pair.neural_net.is_trained) { neural_correction = UTransformerForward(g_pair.coeffs, 0); } // Адаптивное взвешивание double confidence = MathMin(g_pair.current_r2, 0.8); double neural_weight = g_pair.neural_net.is_trained ? (1.0 - confidence) : 0.0; return linear_pred + neural_weight * neural_correction; }
O coeficiente neural_weight se adapta automaticamente à qualidade do modelo: quando o R² da componente linear é alto, indicando bom desempenho preditivo, a parcela neural recebe um peso menor; quando o R² é baixo, recebe um peso maior. Isso garante a robustez do sistema em diferentes regimes de mercado e evita situações em que uma rede neural mal treinada prejudica previsões lineares com bom desempenho preditivo.
Espaço multidimensional de atributos e engenharia de atributos
A qualidade de qualquer modelo de machine learning depende criticamente do quão informativos são os atributos de entrada. Em previsão financeira, essa dependência se manifesta de forma especialmente intensa, pois os dados de mercado se caracterizam por alto nível de ruído e não estacionariedade. O sistema proposto utiliza um espaço de atributos cuidadosamente projetado, com 25 dimensões, que inclui tanto lags clássicos de preço quanto suas transformações não lineares, indicadores técnicos e componentes cíclicos.
O conjunto básico de atributos inclui termos lineares e quadráticos dos lags de preço:
void CalculateFeatures(double price_t1, double price_t2, double price_t3, int bar_index, string symbol, double &features[]) { // Линейные ценовые компоненты features[0] = price_t1; // X(t-1) features[1] = MathPow(price_t1, 2); // X(t-1)² features[2] = price_t2; // X(t-2) features[3] = MathPow(price_t2, 2); // X(t-2)² features[4] = price_t3; // X(t-3) // Разностные операторы (momentum) features[5] = (price_t1 - price_t2); // Краткосрочный momentum features[9] = (price_t1 - price_t3); // Среднесрочный momentum features[18] = MathPow(price_t1 - price_t2, 2); // Квадратичный momentum }Os componentes cíclicos modelam padrões periódicos em diferentes escalas temporais:
// Низкочастотные циклы (дневная сезонность) features[6] = MathSin(price_t1); features[7] = MathCos(price_t1); // Высокочастотные циклы (внутридневные паттерны) features[13] = MathSin(price_t1 * 1000); features[14] = MathCos(price_t1 * 1000); // Временная компонента (час торговой сессии) datetime bar_time = iTime(symbol, PERIOD_H1, bar_index); MqlDateTime dt; TimeToStruct(bar_time, dt); features[17] = (dt.hour / 24.0);
As transformações não lineares ajudam o modelo a se adaptar a diferentes regimes de volatilidade:
// Корневые и экспоненциальные трансформации features[15] = MathSqrt(MathAbs(price_t1)); features[16] = MathExp(-MathAbs(price_t1 - price_t2)); // Гиперболический тангенс для ограничения выбросов features[23] = MathTanh(price_t1 - ma);
Os indicadores técnicos acrescentam informações sobre a microestrutura de mercado:
// RSI и его нелинейные версии double rsi = 50.0; // Упрощенный расчет для демонстрации features[10] = (rsi / 100.0); features[21] = MathPow(rsi / 100.0, 2); // Отклонение от скользящей средней double ma = price_t1; // Упрощенный расчет features[11] = (price_t1 - ma); // Волатильность (ATR) double atr = MathAbs(price_t1 - price_t2); features[12] = atr; features[20] = (atr * (price_t1 - price_t2)); // Взаимодействие волатильности и momentum
Uma categoria especial é formada pelos atributos de interação, que modelam efeitos não lineares entre diferentes componentes:
// Парные взаимодействия features[8] = (price_t1 * price_t2); features[19] = (price_t1 / price_t2); // Тройные взаимодействия features[22] = (price_t1 * price_t2 * price_t3); // Константный терм features[24] = 1.0;
Essa diversidade de atributos permite que o modelo linear represente um amplo espectro de padrões de mercado, desde movimentos tendenciais simples até padrões não lineares complexos. Ao mesmo tempo, a componente neural é treinada nos resíduos desse modelo linear rico em atributos, o que simplifica significativamente sua tarefa.
Estruturas de dados e gestão da memória em MQL5
A implementação de algoritmos complexos de machine learning no ambiente MQL5 exige atenção especial à gestão da memória e às estruturas de dados. Diferentemente dos frameworks modernos de deep learning, que gerenciam automaticamente a memória e os grafos computacionais, em MQL5 o desenvolvedor precisa projetar manualmente estruturas de dados eficientes.
A estrutura central do sistema, PairData, reúne todos os dados necessários para um par de moedas:
struct PairData { string analyst_symbol; // Символ для анализа (EURUSD) string trade_symbol; // Символ для торговли (USDJPY) // Коэффициенты линейной модели double coeffs[25]; // Текущие коэффициенты double best_coeffs[25]; // Лучшие найденные коэффициенты // Метрики качества double current_r2; // Текущий R² double best_r2; // Лучший достигнутый R² double learning_rate; // Адаптивная скорость обучения // Временные ряды и признаки double prices[6000]; // Целевые цены double features[6000][50][25]; // Последовательности признаков int data_size; // Актуальный размер данных // Состояние позиций для averaging/pyramiding double last_buy_price; // Цена последней BUY позиции double last_sell_price; // Цена последней SELL позиции int buy_levels; // Количество уровней BUY int sell_levels; // Количество уровней SELL // Нейросетевая компонента UTransformerNet neural_net; };
A estrutura da camada neural é otimizada para multiplicação matricial eficiente:
struct NeuralLayer { double weights[64][64]; // Матрица весов слоя double biases[64]; // Вектор смещений double outputs[64]; // Выходы нейронов double gradients[64]; // Градиенты для backpropagation int size; // Фактический размер слоя };
O bloco de atenção implementa uma versão simplificada de multi-head attention:
struct AttentionBlock { double query_weights[32][32]; // Матрица трансформации запросов double key_weights[32][32]; // Матрица трансформации ключей double value_weights[32][32]; // Матрица трансформации значений double attention_scores[32]; // Веса внимания double context[32]; // Контекстный вектор };
Uma característica central da gestão da memória é o uso de arrays estáticos de tamanho fixo em vez de estruturas dinâmicas. Isso se deve à necessidade de garantir um consumo de memória previsível:
// Максимальные размеры массивов заданы как константы double prices[6000]; // Максимум 6000 исторических точек double features[6000][50][25]; // Последовательности из 50 баров double residuals[6000]; // Остатки для обучения нейросети
O array tridimensional features[6000][50][25] merece atenção especial. A primeira dimensão corresponde aos pontos históricos de dados; a segunda, às sequências temporais de comprimento 50, para uso potencial em mecanismos recorrentes ou de attention; e a terceira, aos 25 atributos. Essa estrutura permite acesso eficiente aos dados durante o treinamento e a previsão.
A inicialização dos pesos da rede neural utiliza a inicialização Xavier/Glorot para garantir um treinamento estável:
void InitializeNeuralNetwork() { MathSrand(GetTickCount()); for (int layer = 0; layer < NeuralLayers; layer++) { int input_size = (layer == 0) ? 25 : NeuralNodes; double scale = MathSqrt(2.0 / (input_size + NeuralNodes)); for (int i = 0; i < input_size; i++) { for (int j = 0; j < NeuralNodes; j++) { g_pair.neural_net.encoder_layers[layer].weights[i][j] = (MathRand() / 32767.0 - 0.5) * 2.0 * scale; } } } }
Essa estruturação da memória garante a operação eficiente do sistema mesmo com os recursos limitados da plataforma de trading, sem perder a possibilidade de implementar algoritmos complexos de machine learning.
Algoritmo de treinamento do sistema bicomponente
O treinamento do sistema híbrido é um ciclo iterativo no qual as componentes linear e neural são otimizadas alternadamente, mas de forma coordenada. Essa abordagem garante convergência estável e permite que cada componente se especialize na parte da tarefa de previsão que lhe cabe.
A primeira etapa é a otimização do modelo linear com descida de gradiente com taxa de aprendizado adaptativa:
void OptimizeCoefficients() { double best_coeffs[25]; ArrayCopy(best_coeffs, g_pair.coeffs); double best_r2 = CalculateR2(); g_pair.learning_rate = InitialLearningRate; for (int iter = 0; iter < MaxIterations; iter++) { double gradients[25]; ArrayInitialize(gradients, 0.0); // Вычисление градиентов по всем обучающим примерам for (int i = 0; i < g_pair.data_size; i++) { double actual = g_pair.prices[i]; double predicted = 0.0; // Forward pass линейной модели for (int j = 0; j < 25; j++) predicted += g_pair.coeffs[j] * g_pair.features[i][0][j]; double error = predicted - actual; // Накопление градиентов: ∂L/∂w_j = 2 * error * x_j for (int j = 0; j < 25; j++) gradients[j] += 2.0 * error * g_pair.features[i][0][j]; } // Нормализация градиентов for (int j = 0; j < 25; j++) gradients[j] /= g_pair.data_size;
Um elemento crítico para a estabilidade do treinamento é o gradient clipping, usado para evitar gradientes explosivos:
// Gradient clipping для стабильности double gradient_norm = 0.0; for (int j = 0; j < 25; j++) gradient_norm += gradients[j] * gradients[j]; gradient_norm = MathSqrt(gradient_norm); if (gradient_norm > 1.0) { for (int j = 0; j < 25; j++) gradients[j] /= gradient_norm; } // Обновление коэффициентов for (int j = 0; j < 25; j++) g_pair.coeffs[j] -= g_pair.learning_rate * gradients[j];
A taxa de aprendizado adaptativa se ajusta automaticamente à dinâmica da otimização:
double new_r2 = CalculateR2(); if (new_r2 > best_r2) { // Улучшение найдено - увеличиваем скорость обучения best_r2 = new_r2; ArrayCopy(best_coeffs, g_pair.coeffs); g_pair.learning_rate *= 1.01; } else { // Ухудшение - откатываемся и уменьшаем скорость ArrayCopy(g_pair.coeffs, best_coeffs); g_pair.learning_rate *= 0.8; if (g_pair.learning_rate < InitialLearningRate * 0.01) break; // Слишком малая скорость - останавливаемся } } }
A segunda etapa é o treinamento da rede neural nos resíduos do modelo linear otimizado:
void TrainUTransformer() { // Вычисление остатков после оптимизации линейной модели for (int i = 0; i < g_pair.data_size; i++) { double linear_pred = 0; for (int j = 0; j < 25; j++) linear_pred += g_pair.coeffs[j] * g_pair.features[i][0][j]; g_pair.neural_net.residuals[i] = g_pair.prices[i] - linear_pred; } double best_loss = 1e6; int no_improve_count = 0; for (int epoch = 0; epoch < NeuralEpochs; epoch++) { double total_loss = 0; for (int i = 0; i < g_pair.data_size; i++) { // Forward pass нейросети double prediction = UTransformerForward(g_pair.coeffs, g_pair.neural_net.residuals[i]); // Вычисление MSE loss double error = prediction - g_pair.neural_net.residuals[i]; total_loss += error * error; // Упрощенная backpropagation (градиент по последнему слою) double gradient = 2.0 * error / g_pair.data_size; for (int layer = NeuralLayers - 1; layer >= 0; layer--) { for (int j = 0; j < NeuralNodes; j++) { for (int k = 0; k < NeuralNodes; k++) { g_pair.neural_net.encoder_layers[layer].weights[k][j] -= g_pair.neural_net.learning_rate * gradient * 0.01; } } } } total_loss /= g_pair.data_size; // Early stopping для предотвращения переобучения if (total_loss < best_loss) { best_loss = total_loss; no_improve_count = 0; } else { no_improve_count++; if (no_improve_count > 5) break; } } }
A coordenação do treinamento das duas componentes ocorre por meio de reotimização periódica:
if (g_pair.bars_since_optimization >= OptimizationInterval) { PrepareOptimizationData(); OptimizeCoefficients(); // Сначала линейная модель // Переобучение нейросети каждые 5 циклов оптимизации if (g_pair.neural_net.training_steps % 5 == 0) { TrainUTransformer(); // Затем нейросеть на новых остатках } g_pair.bars_since_optimization = 0; }
Procedimento de propagação para frente no U-Transformer
A propagação para frente no U-Transformer consiste em processar sequencialmente os dados de entrada em uma arquitetura codificador-decodificador com mecanismos de atenção integrados. O procedimento começa com a preparação do vetor de entrada, que inclui os atributos agregados por média ao longo da sequência temporal:
double UTransformerForward(double &coefficients[], double residual) { double layer_input[32]; double layer_output[32]; double attention_output[32]; // Подготовка входных данных: усреднение признаков по последовательности double avg_features[25]; for (int i = 0; i < 25; i++) { avg_features[i] = 0; for (int j = 0; j < 50; j++) { avg_features[i] += g_pair.features[0][j][i]; } avg_features[i] /= 50; } // Инициализация входного слоя for (int i = 0; i < 25; i++) layer_input[i] = avg_features[i];
O bloco codificador da arquitetura processa a informação sequencialmente ao longo de várias camadas, cada uma especializada na extração de atributos em diferentes níveis de abstração:
// Проход через энкодерные слои с сохранением skip connections for (int layer = 0; layer < NeuralLayers; layer++) { int input_size = (layer == 0) ? 25 : NeuralNodes; // Forward pass через полносвязный слой ForwardLayer(layer_input, input_size, g_pair.neural_net.encoder_layers[layer], layer_output); // Применение self-attention (для первых слоев) if (layer < TransformerHeads) { SelfAttention(layer_output, g_pair.neural_net.attention_heads[layer], attention_output); // Residual connection: выход = слой + attention for (int i = 0; i < NeuralNodes; i++) layer_output[i] = layer_output[i] + attention_output[i]; } // Сохранение skip connection для декодера for (int i = 0; i < NeuralNodes; i++) g_pair.neural_net.skip_connections[layer][i] = layer_output[i]; // Подготовка входа для следующего слоя for (int i = 0; i < NeuralNodes; i++) layer_input[i] = layer_output[i]; }
A camada totalmente conectada implementa a operação padrão de transformação linear com ativação não linear:
void ForwardLayer(double &inputs[], int input_size, NeuralLayer &layer, double &outputs[]) { for (int j = 0; j < layer.size; j++) { double sum = layer.biases[j]; // Матричное умножение: W * x + b for (int i = 0; i < input_size; i++) sum += inputs[i] * layer.weights[i][j]; // GELU активация для лучшей сходимости outputs[j] = GELU(sum); } }
GELU (Gaussian Error Linear Unit) é usada como uma alternativa moderna à ReLU:
double GELU(double x) { return 0.5 * x * (1.0 + Tanh(MathSqrt(2.0 / M_PI) * (x + 0.044715 * x * x * x))); }
O mecanismo de self-attention calcula os pesos de atenção para diferentes partes da sequência de entrada:
void SelfAttention(double &inputs[], AttentionBlock &attention, double &outputs[]) { double queries[32], keys[32], values[32]; // Вычисление Query, Key, Value векторов for (int i = 0; i < NeuralNodes; i++) { queries[i] = 0; keys[i] = 0; values[i] = 0; for (int j = 0; j < NeuralNodes; j++) { queries[i] += inputs[j] * attention.query_weights[j][i]; keys[i] += inputs[j] * attention.key_weights[j][i]; values[i] += inputs[j] * attention.value_weights[j][i]; } } // Softmax normalization весов внимания double max_score = attention.attention_scores[0]; for (int i = 1; i < NeuralNodes; i++) if (attention.attention_scores[i] > max_score) max_score = attention.attention_scores[i]; double sum_exp = 0; for (int i = 0; i < NeuralNodes; i++) { attention.attention_scores[i] = MathExp(attention.attention_scores[i] - max_score); sum_exp += attention.attention_scores[i]; } for (int i = 0; i < NeuralNodes; i++) attention.attention_scores[i] /= sum_exp; // Применение весов внимания к values for (int i = 0; i < NeuralNodes; i++) { outputs[i] = 0; for (int j = 0; j < NeuralNodes; j++) outputs[i] += attention.attention_scores[j] * values[j]; } }
A agregação final usa average pooling para obter uma saída escalar:
// Декодерная часть (упрощенная - использует только последний энкодерный выход) double final_sum = 0; for (int i = 0; i < NeuralNodes; i++) final_sum += layer_output[i]; return final_sum / NeuralNodes; // Average pooling }
Essa arquitetura permite o processamento multinível da informação: as camadas de baixo nível extraem padrões locais, os mecanismos de atenção modelam dependências de longo prazo e as skip connections preservam informações detalhadas para a previsão final.
Sistema de geração de sinais de trading
A geração de sinais de trading no sistema híbrido implementa uma arquitetura em dois níveis, com alternância automática entre as fontes de sinais conforme a qualidade de cada componente do modelo. Essa arquitetura garante a robustez do sistema em diferentes regimes de mercado e evita a degradação do desempenho quando o desempenho de um dos modelos se deteriora.
A fonte primária de sinais é o U-Transformer, ativado quando o desempenho do treinamento atinge um nível suficiente:
void ProcessPair() { // Получение данных для анализа с символа-аналитика double price_t1 = iClose(g_pair.analyst_symbol, PERIOD_H1, 1); double price_t2 = iClose(g_pair.analyst_symbol, PERIOD_H1, 2); double price_t3 = iClose(g_pair.analyst_symbol, PERIOD_H1, 3); // Текущая цена торгового символа double current_ask = SymbolInfoDouble(g_pair.trade_symbol, SYMBOL_ASK); double current_bid = SymbolInfoDouble(g_pair.trade_symbol, SYMBOL_BID); double current_price = (current_ask + current_bid) / 2.0; int signal = 0; // ОСНОВНОЙ СИГНАЛ: U-Transformer (при высоком качестве) if (g_pair.neural_net.is_trained && g_pair.neural_net.loss < 0.01) { double features[25]; CalculateFeatures(price_t1, price_t2, price_t3, 1, g_pair.analyst_symbol, features); double neural_prediction = UTransformerForward(g_pair.coeffs, 0); double neural_threshold = 0.0001; if (neural_prediction > neural_threshold) signal = 1; // BUY сигнал else if (neural_prediction < -neural_threshold) signal = -1; // SELL сигнал } }
A fonte de sinais de reserva é ativada quando a rede neural ainda não foi treinada ou apresenta resultados insatisfatórios:
// РЕЗЕРВНЫЙ СИГНАЛ: Линейная модель if (signal == 0 && g_pair.current_r2 > 0.1) { double predicted_price = GetHybridPrediction(price_t1, price_t2, price_t3); double base_threshold = g_pair.current_r2 * 0.001; if (predicted_price > current_ask + base_threshold) signal = 1; if (predicted_price < current_bid - base_threshold) signal = -1; }
Um elemento crítico é o limiar adaptativo de disparo, escalonado conforme a qualidade do modelo. Para os sinais da rede neural, usa-se um limiar fixo, pois o modelo é treinado em resíduos normalizados. Para os sinais lineares, o limiar é proporcional ao R² do modelo: quanto melhor o ajuste, mais agressivos podem ser os sinais gerados pelo sistema.
O log da fonte do sinal garante transparência às decisões de trading:
if (OpenPosition(true, lot)) { Print(g_pair.trade_symbol, ": BUY opened by ", g_pair.neural_net.is_trained ? "U-TRANSFORMER" : "LINEAR", " R2=", DoubleToString(g_pair.current_r2, 3), " UT_Loss=", DoubleToString(g_pair.neural_net.loss, 6)); }
A separação entre os símbolos usados para análise e para trading permite empregar a prática de negociação em símbolos sintéticos, por exemplo, em barras Renko. Por exemplo, a análise do EURUSD Renko pode gerar sinais para operar EURUSD, o que amplia as capacidades do sistema e pode melhorar a qualidade dos sinais por incorporar informações adicionais.
Estratégias de gerenciamento de posições e gestão de risco
O sistema de gerenciamento de posições implementa duas estratégias complementares: averaging, ou preço médio em posições perdedoras, e pyramiding, ou incremento de posições vencedoras. Essas estratégias se adaptam automaticamente às condições de mercado e são integradas ao sistema de geração de sinais.
A estrutura de acompanhamento das posições inclui todos os parâmetros necessários para implementar estratégias complexas:
struct PairData { // Отслеживание состояния позиций double last_buy_price; // Цена последней BUY позиции double last_sell_price; // Цена последней SELL позиции int buy_levels; // Количество уровней BUY позиций int sell_levels; // Количество уровней SELL позиций bool last_was_averaging; // Флаг последней операции усреднения };
A estratégia de averaging é ativada quando o preço se move contra a posição aberta por uma distância definida enquanto o sistema continua gerando sinais na mesma direção:
// УСРЕДНЕНИЕ BUY позиций if (g_pair.last_buy_price > 0) { double distance_points = (g_pair.last_buy_price - current_price) / SymbolInfoDouble(g_pair.trade_symbol, SYMBOL_POINT); if (EnableAveraging && distance_points >= DistancePoints && signal == 1 && g_pair.buy_levels < MaxAveragingLevels) { double lot = NormalizeLot(g_pair.trade_symbol, LotSize * AveragingLotMultiplier); if (OpenPosition(true, lot)) { g_pair.last_buy_price = current_price; g_pair.buy_levels++; g_pair.last_was_averaging = true; Print(g_pair.trade_symbol, ": BUY AVERAGING level ", g_pair.buy_levels, " at distance ", DoubleToString(distance_points, 1), " points"); } } }
A estratégia de pyramiding opera de forma oposta: aumenta a exposição em posições lucrativas:
// ПИРАМИДИНГ BUY позиций distance_points = (current_price - g_pair.last_buy_price) / SymbolInfoDouble(g_pair.trade_symbol, SYMBOL_POINT); if (EnablePyramiding && distance_points >= DistancePoints && signal == 1 && g_pair.buy_levels < MaxPyramidingLevels && !g_pair.last_was_averaging) { double lot = NormalizeLot(g_pair.trade_symbol, LotSize * PyramidingLotMultiplier); if (OpenPosition(true, lot)) { g_pair.last_buy_price = current_price; g_pair.buy_levels++; Print(g_pair.trade_symbol, ": BUY PYRAMIDING level ", g_pair.buy_levels, " at distance ", DoubleToString(distance_points, 1), " points"); } }
A principal característica da implementação é a proibição do uso simultâneo de averaging e pyramiding, controlada pela flag last_was_averaging, o que evita que a estratégia se degrade em uma adição caótica de posições.
O gerenciamento do tamanho dos lotes usa multiplicadores para diferentes tipos de operação:
double NormalizeLot(string symbol, double lot) { double min_lot = SymbolInfoDouble(symbol, SYMBOL_VOLUME_MIN); double max_lot = SymbolInfoDouble(symbol, SYMBOL_VOLUME_MAX); double lot_step = SymbolInfoDouble(symbol, SYMBOL_VOLUME_STEP); lot = MathRound(lot / lot_step) * lot_step; lot = MathMax(min_lot, MathMin(max_lot, lot)); return lot; }
Essa arquitetura de gerenciamento de posições oferece flexibilidade no gerenciamento das posições sem abrir mão do controle do risco máximo. O sistema consegue se adaptar a diferentes condições de mercado usando averaging em mercados tendenciais e pyramiding em movimentos impulsivos, mantendo sempre uma regra clara de saída com lucro.
Reotimização automática dos coeficientes do modelo
A capacidade de adaptação às mudanças nas condições de mercado é um requisito crítico para qualquer sistema de trading. Os mercados financeiros apresentam comportamento não estacionário, no qual os padrões estatísticos podem mudar sob influência de eventos macroeconômicos, alterações na microestrutura de mercado ou mudanças no comportamento dos participantes. O sistema implementa uma reotimização automática que atualiza periodicamente os parâmetros do modelo com base em uma janela móvel de dados históricos.
A reotimização é disparada quando se acumula uma quantidade definida de novas barras de trading:
void OnTick() { if (!g_initialized) return; ProcessPair(); // Проверка необходимости реоптимизации if (isNewBar()) { if (g_pair.bars_since_optimization >= OptimizationInterval) { PrepareOptimizationData(); // Подготовка данных OptimizeCoefficients(); // Реоптимизация линейной модели // Переобучение нейросети каждые 5 циклов if (g_pair.neural_net.training_steps % 5 == 0) { TrainUTransformer(); } g_pair.bars_since_optimization = 0; } } }
A preparação dos dados para otimização usa uma janela móvel de tamanho fixo, o que ajuda a manter o equilíbrio entre a estabilidade do modelo e sua capacidade de adaptação às mudanças:
void PrepareOptimizationData() { g_pair.data_size = 0; int available_bars = iBars(g_pair.analyst_symbol, PERIOD_H1); if (available_bars < 50) { Print("WARNING: Insufficient bars for ", g_pair.analyst_symbol); return; } int max_data_points = MathMin(OptimizationBars, 6000); for (int i = 50; i < MathMin(max_data_points + 50, available_bars - 1); i++) { if (g_pair.data_size >= 6000) break; double price_t0 = iClose(g_pair.analyst_symbol, PERIOD_H1, i - 1); if (price_t0 <= 0) continue; g_pair.prices[g_pair.data_size] = price_t0; // Сбор временных последовательностей признаков for (int j = 0; j < 50; j++) { double price_t1 = iClose(g_pair.analyst_symbol, PERIOD_H1, i - j); double price_t2 = iClose(g_pair.analyst_symbol, PERIOD_H1, i - j - 1); double price_t3 = iClose(g_pair.analyst_symbol, PERIOD_H1, i - j - 2); if (price_t1 <= 0 || price_t2 <= 0 || price_t3 <= 0) continue; double features[25]; CalculateFeatures(price_t1, price_t2, price_t3, i - j, g_pair.analyst_symbol, features); for (int k = 0; k < 25; k++) { g_pair.features[g_pair.data_size][j][k] = features[k]; } } g_pair.data_size++; } Print(g_pair.analyst_symbol, ": Prepared ", g_pair.data_size, " data points"); }
O procedimento de otimização inclui um mecanismo para preservar os melhores coeficientes encontrados:
void OptimizeCoefficients() { if (g_pair.data_size < 10) { Print(g_pair.analyst_symbol, ": Insufficient data (", g_pair.data_size, ")"); return; } double best_coeffs[25]; ArrayCopy(best_coeffs, g_pair.coeffs); double best_r2 = CalculateR2(); // Критерий улучшения для продолжения оптимизации double initial_r2 = g_pair.current_r2; for (int iter = 0; iter < MaxIterations; iter++) { // ... код градиентного спуска ... double new_r2 = CalculateR2(); if (new_r2 > best_r2) { best_r2 = new_r2; ArrayCopy(best_coeffs, g_pair.coeffs); g_pair.learning_rate *= 1.01; // Ускорение при улучшении } else { ArrayCopy(g_pair.coeffs, best_coeffs); g_pair.learning_rate *= 0.8; // Замедление при ухудшении if (g_pair.learning_rate < InitialLearningRate * 0.01) break; } // Критерий останова по минимальному улучшению if (iter > 10 && (best_r2 - initial_r2) < MinR2Improvement) break; } // Обновление лучших коэффициентов ArrayCopy(g_pair.coeffs, best_coeffs); g_pair.current_r2 = best_r2; if (best_r2 > g_pair.best_r2) { g_pair.best_r2 = best_r2; ArrayCopy(g_pair.best_coeffs, best_coeffs); } Print(g_pair.analyst_symbol, ": R2=", DoubleToString(g_pair.current_r2, 4), " Best=", DoubleToString(g_pair.best_r2, 4)); }
O sistema acompanha o desempenho do modelo por meio da métrica R-quadrado, que mostra a parcela da variância explicada:
double CalculateR2() { if (g_pair.data_size < 10) return 0.0; double sum_actual = 0.0; double sum_squared_total = 0.0; double sum_squared_residual = 0.0; // Вычисление среднего значения for (int i = 0; i < g_pair.data_size; i++) sum_actual += g_pair.prices[i]; double mean_actual = sum_actual / g_pair.data_size; // Вычисление компонент R² for (int i = 0; i < g_pair.data_size; i++) { double actual = g_pair.prices[i]; double predicted = 0.0; for (int j = 0; j < 25; j++) predicted += g_pair.coeffs[j] * g_pair.features[i][0][j]; double residual = actual - predicted; double total_variance = actual - mean_actual; sum_squared_residual += residual * residual; sum_squared_total += total_variance * total_variance; } if (sum_squared_total <= 0.0) return 0.0; return 1.0 - (sum_squared_residual / sum_squared_total); }
Treinamento online da rede neural nos resíduos
O treinamento online da componente neural representa uma tarefa mais complexa em comparação com a otimização linear. A rede neural não é atualizada a cada ciclo de otimização, mas periodicamente, a cada 5 ciclos, o que evita o sobreajuste e reduz a carga computacional.
void TrainUTransformer() { if (g_pair.data_size < 10) { Print("Insufficient data for U-Transformer training: ", g_pair.data_size); return; } // Расчет остатков от оптимизированной линейной модели for (int i = 0; i < g_pair.data_size; i++) { double linear_pred = 0; for (int j = 0; j < 25; j++) linear_pred += g_pair.coeffs[j] * g_pair.features[i][0][j]; g_pair.neural_net.residuals[i] = g_pair.prices[i] - linear_pred; } Print("Training U-Transformer on ", g_pair.data_size, " residuals..."); double best_loss = 1e6; int no_improve_count = 0;
O procedimento de treinamento usa uma versão simplificada de backpropagation, adaptada às limitações do MQL5:
for (int epoch = 0; epoch < NeuralEpochs; epoch++) { double total_loss = 0; for (int i = 0; i < g_pair.data_size; i++) { // Forward pass double prediction = UTransformerForward(g_pair.coeffs, g_pair.neural_net.residuals[i]); g_pair.neural_net.neural_predictions[i] = prediction; // Вычисление MSE loss double error = prediction - g_pair.neural_net.residuals[i]; total_loss += error * error; // Упрощенная backpropagation double gradient = 2.0 * error / g_pair.data_size; // Обновление весов (упрощенная схема) for (int layer = NeuralLayers - 1; layer >= 0; layer--) { for (int j = 0; j < NeuralNodes; j++) { for (int k = 0; k < NeuralNodes; k++) { g_pair.neural_net.encoder_layers[layer].weights[k][j] -= g_pair.neural_net.learning_rate * gradient * 0.01; } } } } total_loss /= g_pair.data_size; // Early stopping механизм if (total_loss < best_loss) { best_loss = total_loss; no_improve_count = 0; } else { no_improve_count++; if (no_improve_count > 5) break; // Останов при отсутствии улучшений } if (epoch % 5 == 0) Print("U-Transformer epoch ", epoch, " loss: ", DoubleToString(total_loss, 6)); }
A finalização do treinamento inclui a atualização das métricas e do estado da rede neural:
g_pair.neural_net.loss = best_loss; g_pair.neural_net.is_trained = true; g_pair.neural_net.training_steps++; Print("U-Transformer training completed. Loss: ", DoubleToString(best_loss, 6)); }
O critério de desempenho da rede neural (loss < 0.01) determina quando o sistema pode usar os sinais neurais como base:
// В функции генерации сигналов if (g_pair.neural_net.is_trained && g_pair.neural_net.loss < 0.01) { // Используем U-Transformer для генерации сигналов double neural_prediction = UTransformerForward(g_pair.coeffs, 0); // ... }
Essa arquitetura de treinamento online permite a adaptação da componente neural às mudanças nas condições de mercado, preservando a eficiência computacional e evitando o sobreajuste.
Tomamos como base o EA do artigo sobre modelos de regressão e incorporamos a ele nosso modelo híbrido.
Vejamos o teste do modelo no símbolo EURUSD, no timeframe M15, no período a partir de 1º de julho de 2025:
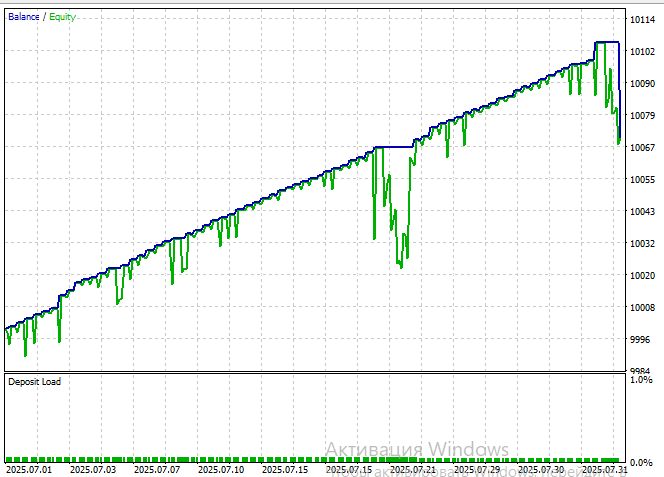
O coeficiente de Sharpe ficou bastante bom:
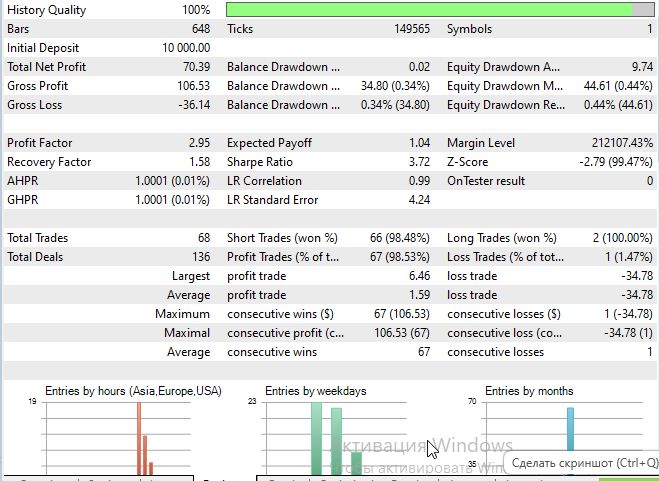
Conclusão
O sistema híbrido apresentado demonstra a possibilidade prática de integrar arquiteturas modernas de deep learning com métodos econométricos clássicos dentro das limitações da plataforma de trading MQL5. A decomposição da tarefa de previsão em duas etapas, uma linear e outra não linear, permite aproveitar os pontos fortes de ambas as abordagens, minimizando suas deficiências.
As principais contribuições deste trabalho incluem a adaptação bem-sucedida da arquitetura U-Net para a análise de séries temporais financeiras, a integração de mecanismos de atenção para modelar dependências de longo prazo e a implementação de um sistema automático de alternância entre fontes de sinais. O sistema opera de forma estável em diferentes regimes de mercado, por meio da ponderação adaptativa das componentes e à reotimização periódica dos parâmetros.
O valor prático da solução está em sua prontidão para uso em trading real. O sistema inclui uma lógica de trading completa, com gerenciamento de posições, gestão de risco e logging detalhado das operações. A separação entre os símbolos usados para análise e para trading amplia as possibilidades de uso de correlações entre mercados.
No entanto, é preciso reconhecer com transparência as limitações da implementação atual. A backpropagation simplificada, a ausência de técnicas modernas de regularização e a arquitetura fixa da rede limitam o potencial da componente neural. O uso de arrays estáticos em vez de estruturas de dados dinâmicas impõe restrições rígidas à escalabilidade do sistema.
Ainda assim, a abordagem proposta abre uma direção promissora para o desenvolvimento de sistemas de trading. O conceito de treinar uma rede neural nos resíduos de um modelo linear pode ser aplicado a uma classe mais ampla de tarefas de previsão, sem se limitar aos mercados financeiros. A arquitetura modular do sistema permite experimentar facilmente diferentes tipos de redes neurais e estratégias de gerenciamento de posições.
A demonstração de que métodos avançados de machine learning podem ser implementados mesmo em ambientes de desenvolvimento restritos, como MQL5, é especialmente valiosa. Isso abre caminho para um amplo grupo de traders e desenvolvedores que não têm acesso a frameworks modernos de deep learning.
Literatura
- Attention Is All You Need (Vaswani et al., 2017)
- U-Net: Convolutional Networks for Biomedical Image Segmentation (Ronneberger et al., 2015)
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18916
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso