
Redes neurais em trading: decomposição em vez de escalonamento (Conclusão)

Introdução
Hoje, os mercados financeiros não são apenas um espaço de encontro entre vendedores e compradores, mas um ecossistema dinâmico complexo, no qual cada tick de preço é resultado da interação instantânea de centenas de fatores. Aqui, não há lugar para o acaso no sentido habitual da palavra: por trás do caos aparente escondem-se regularidades, ainda que revestidas de formas complexas e multicamadas. É justamente a capacidade de reconhecer essas estruturas ocultas e antecipar sua evolução que determina o sucesso de um trader ou de um sistema algorítmico. Nos artigos anteriores, fomos apresentados ao framework SSCNN (Spatial-Sequential Convolutional Neural Network). Por trás desse nome, à primeira vista pesado, há uma concepção bastante coerente e elegante, que combina dependências espaciais e temporais em um único algoritmo computacional.
A SSCNN se baseia na ideia de que uma série temporal é um registro de processos multidimensionais desdobrado ao longo do tempo. Cada instante está ligado não apenas ao passado e ao futuro, mas também a estruturas paralelas: espaços internos de atributos que variam de forma síncrona ou defasada.
Para capturar essas relações, o modelo usa uma cascata de blocos capazes de extrair padrões locais e módulos de processamento sequencial que preservam e acumulam o contexto. O elo central aqui é o módulo Attention-based Normalization, uma combinação de atenção e normalização que permite ao sistema concentrar-se nos trechos realmente significativos dos dados e, ao mesmo tempo, estabilizar o treinamento. Graças a essa arquitetura, a SSCNN não só é capaz de analisar sinais em diferentes níveis de detalhe, como também se adapta à estrutura variável dos dados, algo especialmente importante para instrumentos financeiros, com sua volatilidade variável e suas mudanças nos regimes de mercado.

Outra vantagem importante é a modularidade. A arquitetura SSCNN pode ser expandida e adaptada com facilidade a uma tarefa específica, seja a previsão de curto prazo do movimento impulsivo do preço, seja a busca por ciclos de longo prazo. A ideia de perceber os dados em camadas, em que cada nível do modelo extrai seu próprio subconjunto de atributos e o transmite ao nível seguinte, oferece flexibilidade e robustez.
Nas publicações anteriores, analisamos em detalhes como essas ideias foram incorporadas ao código e integradas ao ambiente MQL5, criando a base para um sistema de trading completo.
Agora chegamos à etapa final, em que a teoria deve se encontrar com a prática em sua forma mais exigente. Precisamos reunir os blocos separados em uma arquitetura coesa do framework e avaliar como a SSCNN processa e interpreta os dados de mercado. Verificaremos a eficiência das soluções implementadas em condições tão próximas quanto possível do trading real. Esta etapa é importante não apenas para medir a precisão das previsões ou a robustez do modelo, mas também para entender até que ponto seus algoritmos captam a dinâmica do mercado, distinguem estruturas ocultas e conseguem reconhecer mudanças de contexto. Afinal, no fim das contas, o sucesso de qualquer sistema de trading não é determinado pelo brilho da arquitetura, mas por como ele lida com o ruído, com picos inesperados e com as reviravoltas traiçoeiras dos gráficos.
Codificador
Nos trabalhos anteriores, construímos blocos separados da arquitetura SSCNN e hoje começamos a conectá-los em um único Codificador: o nó em que múltiplos fluxos de informação (tendências de longo prazo, padrões sazonais, flutuações de curto prazo e inter-relações espaciais) são cuidadosamente decompostos, ordenados, projetados para um horizonte definido e, em seguida, combinados em uma única representação de previsão.
A classe CNeuronSSCNNEncoder materializa essa ideia em código. Sua tarefa não é simplesmente chamar um conjunto de módulos em sequência, mas sincronizar sua operação: isolar cada componente de acordo com sua própria lógica, extrapolá-lo para o horizonte necessário, prever as estatísticas correspondentes e só então reunir tudo isso em uma representação rica e estruturada para a regressão polinomial final. O Codificador gerencia os fluxos de dados, coordena as transposições quando elas são necessárias para o funcionamento correto por fases e garante que cada resultado gerado por um subsistema individual seja inserido no ponto correto da concatenação no formato correto. A estrutura da classe é apresentada abaixo.
class CNeuronSSCNNEncoder : public CNeuronTransposeOCL { protected: CNeuronPeriodNorm cLongNorm; CNeuronConvOCL cLongExtrapolate; CNeuronTransposeOCL cLongMeanSTDevTransp; CNeuronBaseOCL cLongMeanExtrapolate; CNeuronTransposeVRCOCL cSeasonTransp; CNeuronAttentNorm cSeasonNorm; CNeuronTransposeVRCOCL cUnSeasonTransp; CNeuronConvOCL cSeasonExtrapolate; CNeuronConvOCL cSeasonMeanExtrapolate; CNeuronAttentNorm cShortNorm; CNeuronConvOCL cShortExtrapolate; CNeuronConvOCL cShortMeanExtrapolate; CNeuronSAttentNorm cSpatialNorm; CNeuronConvOCL cSpatialExtrapolate; CNeuronConvOCL cSpatialMeanExtrapolate; CNeuronBaseOCL cConcatenated; CNeuronTransposeOCL cTranspose; CNeuronPolynomialRegression cFusion; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSSCNNEncoder(void) {}; ~CNeuronSSCNNEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint variables, uint forecast, uint season_period, uint short_period, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronSSCNNEncoder; } virtual void TrainMode(bool flag) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { } };
A sequência de processamento dentro do Codificador foi cuidadosamente construída. Todos os objetos internos são declarados como estáticos, por isso o construtor e o destrutor da classe permanecem vazios, enquanto a montagem efetiva do grafo computacional é centralizada no método Init.
bool CNeuronSSCNNEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint variables, uint forecast, uint season_period, uint short_period, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, units_count + forecast, variables, optimization_type, batch)) return false; activation = None;
O método começa inicializando a classe pai CNeuronTransposeOCL, para a qual são passados os parâmetros básicos da arquitetura em construção. Essa chamada prepara a infraestrutura geral: alocação dos buffers globais, definição das dimensões dos tensores e vinculação ao contexto OpenCL.
Observe que o tamanho do tensor de resultados é indicado como a soma do comprimento da sequência analisada e do horizonte de planejamento. Aqui fica claro que, na saída do módulo, esperamos obter os dados originais depurados e a previsão necessária em uma representação unificada e comparável.
Logo após a inicialização básica, desativamos explicitamente a função de ativação da camada atual (activation = None), pois o Codificador trabalha com representações numéricas e estatísticas.
Em seguida, passamos à inicialização dos objetos internos. Primeiro, inicializamos a ramificação de longo prazo, cLongNorm. Aqui é criado um módulo de normalização por períodos, que prepara a componente estável da série (a tendência).
int index = 0; if(!cLongNorm.Init(0, index, OpenCL, 1, units_count, iWindow, optimization, iBatch)) return false;
Depois inicializamos cLongExtrapolate, o bloco de extrapolação da tendência, que estenderá a componente de longo prazo até o horizonte de previsão.
index++; if(!cLongExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cLongExtrapolate.SetActivationFunction(None);
Aqui é importante observar que, na implementação do autor, para extrapolar os dados, é usada a matriz de parâmetros treináveis E.
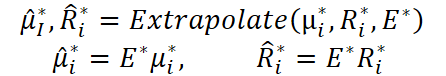
Nós, porém, em nossa implementação, decidimos usar uma camada convolucional sem função de ativação para isso. Uma camada convolucional sem ativação também é um operador linear, mas com vantagens adicionais do ponto de vista de engenharia. As convoluções oferecem esparsidade paramétrica (pesos compartilhados), são otimizadas para hardware e descrevem de forma natural transformações locais e quase locais, frequentemente encontradas em séries temporais.
Depois de extrapolarmos os resíduos da componente de longo prazo, chega a vez de extrapolar as próprias médias. O detalhe prático é que CNeuronPeriodNorm retorna um tensor em que os valores são gravados em pares: média e variância. Em vez de desfazer explicitamente a concatenação e copiar os dados, usamos um recurso simples e elegante: a transposição do tensor.
A transposição reorganiza os dados de modo que o pipeline forme, em sequência, séries separadas com todas as médias e todas as variâncias, sendo que a sequência das médias fica em primeiro lugar. Isso permite passar o tensor transposto diretamente para o módulo de extrapolação das médias. Em essência, usamos a ordem dos elementos na memória para obter fluxos de dados logicamente separados com esforço mínimo.
index++; if(!cLongMeanSTDevTransp.Init(0, index, OpenCL, iWindow, 2, optimization, iBatch)) return false; if(!cLongMeanSTDevTransp.getGradient().Fill(0)) return false; index++; if(!cLongMeanExtrapolate.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cLongExtrapolate.SetActivationFunction(None); if(!cLongMeanExtrapolate.getPrevOutput().Fill(1)) return false;
Mas aqui há ainda dois pontos específicos e importantes, que convém tratar de antemão. O primeiro é a proteção contra a contaminação dos gradientes das variâncias. Como nosso módulo de extrapolação trabalha apenas com as médias, precisamos garantir que valores aleatórios, capazes de distorcer a propagação reversa posterior, não sejam gravados na memória de gradientes das variâncias. Na implementação, isso é resolvido de forma simples e confiável já na inicialização: o buffer de gradientes do objeto de transposição é preenchido com zeros. Assim, eliminamos explicitamente qualquer estado residual acumulado na memória e eliminamos a influência de valores espúrios sobre σ².
O segundo ponto é a própria extrapolação das médias. Na formulação original, os autores simplesmente preenchem o tensor com os valores obtidos. Adotamos uma solução mais econômica em termos de engenharia: para obter o tensor preenchido necessário, usamos o produto externo (outer product) em sua forma simples. Pegamos o vetor-coluna das médias µ de tamanho N•1 e o multiplicamos por um vetor-linha composto por uns de tamanho 1•M. O resultado é uma matriz N•M, em que cada linha é uma cópia da média µi correspondente. Isso copia os valores para um tensor do tamanho necessário sem laços explícitos. As vantagens práticas dessa solução são evidentes: é uma operação linear, facilmente paralelizável na GPU, econômica em memória e claramente mapeável para OpenCL.
Como resultado, com código mínimo e baixa sobrecarga, obtemos um mecanismo limpo, compreensível e eficiente para extrapolar as médias. Ele preserva a semântica da ideia dos autores (projeção linear no tempo), mas a torna mais econômica e bem adaptada a cálculos paralelos em OpenCL.
Em seguida vem a ramificação de sazonalidade. Primeiro, o objeto cSeasonTransp configura a transposição por ciclos: agrupamos os dados por fases de um mesmo ciclo usando o parâmetro season_period. Isso facilita a seleção posterior de fases iguais e permite usar o módulo universal de normalização com coeficientes de atenção CNeuronAttentNorm.
index++; if(!cSeasonTransp.Init(0, index, OpenCL, iWindow, units_count / season_period, season_period, optimization, iBatch)) return false; index++; if(!cSeasonNorm.Init(0, index, OpenCL, season_period, cSeasonTransp.GetCount(), iWindow, optimization, iBatch)) return false; index++; if(!cUnSeasonTransp.Init(0, index, OpenCL, iWindow, season_period, cSeasonTransp.GetCount(), optimization, iBatch)) return false;
O objeto cSeasonNorm extrai a componente sazonal e normaliza os valores residuais, enquanto cUnSeasonTransp devolve os dados à orientação original antes da extrapolação. A extrapolação propriamente dita das componentes sazonais fica a cargo dos objetos cSeasonExtrapolate e cSeasonMeanExtrapolate.
index++; if(!cSeasonExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cSeasonExtrapolate.SetActivationFunction(None); index++; if(!cSeasonMeanExtrapolate.Init(0, index, OpenCL, season_period, season_period, iCount, iWindow, 1, optimization, iBatch)) return false; cSeasonMeanExtrapolate.SetActivationFunction(None);
A ramificação de curto prazo é definida por um conjunto semelhante de módulos, mas sem transposição dos dados. O objeto cShortNorm isola efeitos locais e rápidos dentro da janela short_period, cShortExtrapolate prevê esses efeitos, e cShortMeanExtrapolate prevê as estatísticas da camada de curto prazo. Observe que, nos parâmetros de inicialização do objeto de extrapolação das médias, usamos cShortNorm.GetUnits() para alinhar os formatos. Isso garante que os blocos seguintes recebam corretamente as saídas do normalizador como entradas.
index++; if(!cShortNorm.Init(0, index, OpenCL, units_count / short_period, short_period, iWindow, optimization, iBatch)) return false; index++; if(!cShortExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cShortExtrapolate.SetActivationFunction(None); index++; if(!cShortMeanExtrapolate.Init(0, index, OpenCL, cShortNorm.GetUnits(), cShortNorm.GetUnits(), iCount, iWindow, 1, optimization, iBatch)) return false; cShortMeanExtrapolate.SetActivationFunction(None); index++;
Em seguida, é inicializada a ramificação espacial: cSpatialNorm é o módulo S-AttnNorm, que extrai padrões espacialmente coerentes entre sequências individuais de cada atributo.
if(!cSpatialNorm.Init(0, index, OpenCL, units_count, variables, optimization, iBatch)) return false; index++; if(!cSpatialExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cSpatialExtrapolate.SetActivationFunction(None); index++; if(!cSpatialMeanExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, 1, iWindow, optimization, iBatch)) return false; cSpatialMeanExtrapolate.SetActivationFunction(None); index++;
Depois dele vêm cSpatialExtrapolate e cSpatialMeanExtrapolate, que preveem a componente espacial e suas estatísticas para o horizonte definido.
Todas as componentes previstas e suas estatísticas são então reunidas em um único tensor, cConcatenated. Aqui multiplicamos explicitamente a dimensionalidade do tensor por oito, porque na saída de cada ramificação é formado um par estrutura + resíduo (Rlt, μlt, Rse, μse, Rst, μst, Rsi, μsi), ou seja, oito fluxos de informação por unidade.
if(!cConcatenated.Init(0, index, OpenCL, 8 * Neurons(), optimization, iBatch)) return false; index++; if(!cTranspose.Init(0, index, OpenCL, 8 * iWindow, iCount, optimization, iBatch)) return false;
O tensor largo resultante é então transposto pelo módulo cTranspose, para reorganizar os dados no formato esperado pela camada final de fusão.
Na última etapa da inicialização, criamos cFusion, nosso módulo de regressão polinomial (fusão), que recebe como entrada o conjunto combinado de atributos com tamanho 8*iWindow e produz uma representação compacta, mas informativa, de comprimento iWindow para cada passo de tempo. É aqui que se implementa o esquema de combinação de efeitos multiplicativos e aditivos entre as componentes.
index++; if(!cFusion.Init(0, index, OpenCL, iCount, 8 * iWindow, iWindow, optimization, iBatch)) return false; //--- return true; }
Em cada etapa, verificamos a inicialização dos objetos e, se ocorrer algum erro, o método retorna false. Essa programação defensiva permite interromper imediatamente a montagem do Codificador diante de qualquer problema. Se todos os módulos forem criados e configurados com sucesso, o método termina retornando true, sinalizando que o Codificador está pronto para funcionar.
Depois de inicializar a estrutura do objeto, passamos à implementação da propagação para frente do Codificador no método feedForward, em que cada módulo é acionado no momento certo e passa o resultado ao módulo seguinte. O método é implementado passo a passo e reflete a lógica de processamento das quatro componentes: de longo prazo, sazonal, de curto prazo e espacial. Em seguida, reúne tudo em um único vetor de atributos e o passa para a fusão polinomial. No código, isso fica claro: em cada etapa chamamos FeedForward para o bloco correspondente, verificamos se a chamada foi bem-sucedida e seguimos adiante. Se algo sair errado em algum ponto, a função retorna false e a cadeia é interrompida.
bool CNeuronSSCNNEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Long if(!cLongNorm.FeedForward(NeuronOCL)) return false; if(!cLongExtrapolate.FeedForward(cLongNorm.AsObject())) return false; if(!cLongMeanSTDevTransp.FeedForward(cLongNorm.GetMeanSTDevs())) return false; if(!MatMul(cLongMeanSTDevTransp.getOutput(), cLongMeanExtrapolate.getPrevOutput(), cLongMeanExtrapolate.getOutput(), 1, 1, iCount, iWindow, true)) return false;
Primeiro é iniciada a ramificação de longo prazo. A chamada cLongNorm.FeedForward calcula a componente de longo prazo normalizada dos dados analisados. Trata-se de uma etapa preparatória, que separa a tendência dos efeitos locais. Em seguida, cLongExtrapolate.FeedForward recebe o resultado da normalização e constrói a previsão dos resíduos da componente de longo prazo para o horizonte necessário. Aqui é importante observar que o módulo recebe dados já estruturados de cLongNorm.
Depois é necessário extrapolar as estatísticas: médias e desvios-padrão. Para isso, primeiro o tensor de estatísticas cLongMeanSTDevTransp é transposto, a fim de reunir as sequências de médias separadamente dos desvios-padrão (já falamos antes sobre esse recurso de transposição). Em seguida, é executada a multiplicação matricial. Aqui, na prática, projetamos as estatísticas transpostas para o formato de que precisamos, usando um vetor-linha. A implementação produz o comportamento desejado de replicação das médias ao longo do horizonte, sem cópias desnecessárias.
Em seguida, é iniciada a ramificação sazonal. Primeiro, cSeasonTransp transpõe os dados analisados por fases do ciclo. Essa etapa prepara os dados para a normalização orientada por fase.
//--- Season if(!cSeasonTransp.FeedForward(cLongNorm.AsObject())) return false; if(!cSeasonNorm.FeedForward(cSeasonTransp.AsObject())) return false; if(!cUnSeasonTransp.FeedForward(cSeasonNorm.AsObject())) return false; if(!cSeasonExtrapolate.FeedForward(cUnSeasonTransp.AsObject())) return false; if(!cSeasonMeanExtrapolate.FeedForward(cSeasonNorm.GetMeans())) return false;
Depois, cSeasonNorm aplica a Attention-based Normalization por ciclos, destacando as posições relevantes das fases. A transposição inversa cUnSeasonTransp devolve os dados à forma original, pronta para a extrapolação. Em seguida, cSeasonExtrapolate recebe os resíduos sazonais recompostos e gera sua previsão, enquanto cSeasonMeanExtrapolate extrapola as médias das componentes sazonais obtidas do normalizador.
A ramificação de curto prazo segue um roteiro semelhante:
- cShortNorm recebe os dados já com a sazonalidade removida e isola efeitos locais e rápidos;
- cShortExtrapolate prevê esses resíduos de curto prazo;
- cShortMeanExtrapolate gera as previsões de suas estatísticas.
//--- Short if(!cShortNorm.FeedForward(cUnSeasonTransp.AsObject())) return false; if(!cShortExtrapolate.FeedForward(cShortNorm.AsObject())) return false; if(!cShortMeanExtrapolate.FeedForward(cShortNorm.GetMeans())) return false;
Observe que a passagem de dados da ramificação sazonal para a ramificação de curto prazo é uma decisão deliberada: primeiro removemos os ciclos maiores e só então capturamos os sobressaltos locais.
Em seguida vem a ramificação espacial. O módulo cSpatialNorm analisa conjuntos de séries em uma fatia temporal e extrai estruturas espacialmente coerentes. Depois, cSpatialExtrapolate prevê os resíduos espaciais, e cSpatialMeanExtrapolate prevê suas estatísticas.
//--- Spatial if(!cSpatialNorm.FeedForward(cShortNorm.AsObject())) return false; if(!cSpatialExtrapolate.FeedForward(cSpatialNorm.AsObject())) return false; if(!cSpatialMeanExtrapolate.FeedForward(cSpatialNorm.GetMeans())) return false;
Essa sequência garante que a normalização espacial trabalhe com efeitos locais já depurados da tendência e da sazonalidade.
Depois que todas as ramificações geram suas previsões, começa a montagem estruturada dos atributos. A primeira chamada ao método Concat combina os resíduos extrapolados e as médias das ramificações de longo prazo e sazonal em um buffer largo.
//--- Concat if(!Concat(cLongExtrapolate.getOutput(), cLongMeanExtrapolate.getOutput(), cSeasonExtrapolate.getOutput(), cSeasonMeanExtrapolate.getOutput(), cConcatenated.getOutput(), iCount, iCount, iCount, iCount, iWindow)) return false; if(!Concat(cConcatenated.getOutput(), cShortExtrapolate.getOutput(), cShortMeanExtrapolate.getOutput(), cConcatenated.getPrevOutput(), 4 * iCount, iCount, iCount, iWindow)) return false; if(!Concat(cConcatenated.getPrevOutput(), cSpatialExtrapolate.getOutput(), cSpatialMeanExtrapolate.getOutput(), cConcatenated.getOutput(), 6 * iCount, iCount, iCount, iWindow)) return false;
Em seguida, a segunda chamada de Concat adiciona os dados de curto prazo, expandindo o tensor acumulado. A terceira chamada ao método de concatenação complementa o resultado com as componentes espaciais.
Por fim, vem a etapa de fusão. Primeiro, cTranspose reorganiza o tensor largo já concatenado de modo a torná-lo adequado para o regressor polinomial. Trata-se de uma permutação das dimensões de atributos e passos de tempo, que torna a estrutura dos dados adequada para a agregação posterior. Em seguida, o módulo cFusion executa a fusão polinomial em si: uma combinação de caminhos aditivos e multiplicativos que produz uma representação compacta, mas informativa, da previsão.
//--- Fusion if(!cTranspose.FeedForward(cConcatenated.AsObject())) return false; if(!cFusion.FeedForward(cTranspose.AsObject())) return false; //--- return CNeuronTransposeOCL::feedForward(cFusion.AsObject()); }
O algoritmo da propagação para frente termina com a chamada ao método homônimo da classe pai CNeuronTransposeOCL, que converte o tensor de resultados em um conjunto de sequências individuais de cada atributo, adequado para análise pelas camadas neurais seguintes do modelo.
Em cada etapa, o código verifica rigorosamente o resultado das operações. E isso não é formalismo, mas uma proteção deliberada: qualquer exceção, erro de alocação de buffer ou formato incorreto interrompe imediatamente a execução, o que facilita a depuração e torna o comportamento do modelo seguro em produção.
Do ponto de vista arquitetural, a ordem das chamadas reflete o princípio de baixo para cima: primeiro extraímos e extrapolamos as componentes mais grosseiras e estáveis; depois passamos às componentes de maior resolução; em seguida, analisamos as relações espaciais; por fim, combinamos tudo cuidadosamente no módulo de fusão. Esse estilo simplifica o rastreamento de erros, deixa clara a semântica de cada bloco e permite validar a qualidade por etapas, da tendência às oscilações locais.
Se pensarmos no método de propagação para frente como um roteiro em que os atores entram em cena um após o outro, então, calcInputGradients é o instante após o espetáculo, quando é preciso desmontar cuidadosamente os objetos de cena, recolher as observações do diretor e devolver a energia do erro a cada módulo, permitindo que ele ajuste seu comportamento.
bool CNeuronSSCNNEncoder::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
No corpo do método, validamos logo de início o ponteiro para o objeto de dados de origem NeuronOCL. É uma proteção simples e necessária: sem um ponteiro correto, não há como saber para onde propagar os gradientes, portanto saímos de forma segura em caso de erro.
Em seguida começa a fase de fusão. Como a etapa final da propagação para frente foi a fusão polinomial seguida da transposição, no caminho inverso primeiro propagamos os gradientes de volta por esses módulos.
//--- Fusion if(!CNeuronTransposeOCL::calcInputGradients(cFusion.AsObject())) return false; if(!cTranspose.CalcHiddenGradients(cFusion.AsObject())) return false; if(!cConcatenated.CalcHiddenGradients(cTranspose.AsObject())) return false;
Chamamos o método homônimo da classe pai CNeuronTransposeOCL, que propaga o sinal de erro do contexto externo para o módulo de regressão polinomial. Depois propagamos os gradientes até o objeto de transposição cTranspose. Por fim, passamos os valores obtidos para o objeto cConcatenated, que armazena o tensor largo com a concatenação dos resultados de todas as componentes.
Em seguida, precisamos desempacotar, uma a uma, as contribuições de cada componente, executando uma sequência de chamadas DeConcat para desfazer a concatenação e dividir o gradiente comum em partes.
//--- DeConcat if(!DeConcat(cConcatenated.getPrevOutput(), cSpatialExtrapolate.getGradient(), cSpatialMeanExtrapolate.getGradient(), cConcatenated.getGradient(), 6 * iCount, iCount, iCount, iWindow)) return false; if(!DeConcat(cConcatenated.getGradient(), cShortExtrapolate.getGradient(), cShortMeanExtrapolate.getGradient(), cConcatenated.getPrevOutput(), 4 * iCount, iCount, iCount, iWindow)) return false; if(!DeConcat(cLongExtrapolate.getGradient(), cLongMeanExtrapolate.getGradient(), cSeasonExtrapolate.getGradient(), cSeasonMeanExtrapolate.getGradient(), cConcatenated.getGradient(), iCount, iCount, iCount, iCount, iWindow)) return false;
Primeiro extraímos de cConcatenated os gradientes para a ramificação espacial (cSpatialExtrapolate e cSpatialMeanExtrapolate). As duas chamadas seguintes do método DeConcat separam os gradientes das componentes de curto prazo, sazonal e de longo prazo. Em essência, o buffer largo único é distribuído entre os módulos de destino: cada módulo recebe exatamente a parte do gradiente que gerou durante a propagação para frente.
Agora começa a extração sequencial dos gradientes por ramificação, em ordem lógica inversa à sua montagem. Na ramificação espacial, primeiro passamos os gradientes das estatísticas: é a transferência do erro do bloco de previsão das médias da componente espacial para o módulo de normalização responsável por essas médias.
//--- Spatial if(!cSpatialNorm.GetMeans().CalcHiddenGradients(cSpatialMeanExtrapolate.AsObject())) return false; if(!cSpatialNorm.CalcHiddenGradients(cSpatialExtrapolate.AsObject())) return false;
Em seguida, o método cSpatialNorm.CalcHiddenGradients extrai o gradiente da ramificação espacial principal e o prepara para ser propagado para baixo.
A ramificação de curto prazo exige cuidado: primeiro, cShortNorm.CalcHiddenGradients passa o gradiente da normalização espacial para o normalizador dos efeitos de curto prazo.
//--- Short if(!cShortNorm.CalcHiddenGradients(cSpatialNorm.AsObject())) return false; CBufferFloat* temp = cShortNorm.getGradient(); if(!cShortNorm.SetGradient(cShortNorm.getPrevOutput(), false) || !cShortNorm.CalcHiddenGradients(cShortExtrapolate.AsObject()) || !SumAndNormilize(temp, cShortNorm.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cShortNorm.SetGradient(temp, false)) return false; if(!cShortNorm.GetMeans().CalcHiddenGradients(cShortMeanExtrapolate.AsObject())) return false;
Depois precisamos obter o gradiente de erro a partir do objeto de extrapolação dos dados. E, para não perder os valores já obtidos, salvamos o ponteiro atual do buffer de gradientes do erro na variável local temp. Em seguida vem um recurso mais sutil: trocamos temporariamente o ponteiro atual do buffer de gradientes do normalizador por um buffer livre do mesmo tamanho. Depois calculamos os gradientes em relação ao módulo de extrapolação. Em seguida somamos os valores dos dois fluxos de informação e devolvemos os ponteiros dos buffers de dados ao estado original. Ao concluir a distribuição dos gradientes do erro da componente de curto prazo, propagamos o sinal de erro do bloco de previsão das médias da ramificação de curto prazo de volta pelo caminho que gerou essas médias.
A ramificação sazonal é processada de forma semelhante, mas com uma transposição adicional.
//--- Season if(!cUnSeasonTransp.CalcHiddenGradients(cShortNorm.AsObject())) return false; temp = cUnSeasonTransp.getGradient(); if(!cUnSeasonTransp.SetGradient(cUnSeasonTransp.getPrevOutput(), false) || !cUnSeasonTransp.CalcHiddenGradients(cSeasonExtrapolate.AsObject()) || !SumAndNormilize(temp, cUnSeasonTransp.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cUnSeasonTransp.SetGradient(temp, false)) return false; if(!cSeasonNorm.GetMeans().CalcHiddenGradients(cSeasonMeanExtrapolate.AsObject())) return false; if(!cSeasonNorm.CalcHiddenGradients(cUnSeasonTransp.AsObject())) return false; if(!cSeasonTransp.CalcHiddenGradients(cSeasonNorm.AsObject())) return false;
Primeiro, cUnSeasonTransp.CalcHiddenGradients devolve os gradientes da normalização de curto prazo ao bloco de transposição inversa. Mais uma vez, aplicamos a técnica do buffer temporário: salvamos em temp, redirecionamos o buffer de gradientes para um buffer livre, chamamos CalcHiddenGradients, acumulamos os valores e devolvemos o resultado a cUnSeasonTransp. Isso garante a soma correta das contribuições e o alinhamento das escalas.
Depois disso, propagamos os erros para baixo, em direção ao Seasonal-Normalizer, e revertemos a transposição, ou seja, retornamos ao formato em que os dados vinham do normalizador de longo prazo.
A ramificação de longo prazo contém o trecho mais delicado: o cálculo reverso da multiplicação matricial para as estatísticas. No método MatMulGrad, executamos a operação inversa da multiplicação de vetores usada na propagação para frente: com isso, calculamos a contribuição do erro vinda de cLongMeanExtrapolate no buffer transposto cLongMeanSTDevTransp. Na prática, distribuímos os gradientes pelas médias, levando em conta a estrutura de replicação que usamos na extrapolação das médias. Em seguida, direcionamos os gradientes obtidos para o módulo de normalização.
//--- Long if(!MatMulGrad(cLongMeanSTDevTransp.getOutput(), cLongMeanSTDevTransp.getGradient(), cLongMeanExtrapolate.getPrevOutput(), cLongMeanExtrapolate.getGradient(), cLongMeanExtrapolate.getGradient(), 1, 1, iCount, iWindow, true)) return false; if(!cLongNorm.GetMeanSTDevs().CalcHiddenGradients(cLongMeanSTDevTransp.AsObject())) return false; if(!cLongNorm.CalcHiddenGradients(cSeasonTransp.AsObject())) return false; temp = cLongNorm.getGradient(); if(!cLongNorm.SetGradient(cLongNorm.getPrevOutput(), false) || !cLongNorm.CalcHiddenGradients(cLongExtrapolate.AsObject()) || !SumAndNormilize(temp, cLongNorm.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cLongNorm.SetGradient(temp, false)) return false;
Depois disso, cLongNorm.CalcHiddenGradients passa os gradientes acumulados da transposição sazonal de volta para o normalizador de longo prazo, e novamente aplicamos o recurso do buffer temporário. Isso garante o acúmulo das contribuições vindas da extrapolação do resíduo da componente de longo prazo e de outros módulos dependentes, sem perder resultados intermediários.
Por fim, a cadeia concluída de propagação reversa envia os gradientes de volta para a camada anterior (NeuronOCL). Esse é o ponto natural de saída do erro: depois de todos os recálculos internos, o Codificador entrega ao nó anterior do grafo computacional uma contribuição devidamente formada.
//--- if(!NeuronOCL.CalcHiddenGradients(cLongNorm.AsObject())) return false; //--- return true; }
Ao longo do método, todas as chamadas são acompanhadas por verificações dos resultados. Isso não é apenas confiabilidade, mas uma política fail-fast: detectamos o problema logo no início para evitar inconsistências sutis nos buffers, que depois seriam difíceis de rastrear. Algumas técnicas importantes se repetem ao longo de todo o método e merecem atenção à parte:
- uso de buffers temporários para acumular gradientes parciais,
- troca do buffer de gradientes ativo para não perder dados,
- chamada de SumAndNormilize para combinar corretamente as contribuições de acordo com o tamanho da janela.
Em resumo, o método percorre cuidadosamente a ordem inversa da propagação para frente, desempacota os buffers concatenados, distribui os gradientes pelas ramificações, acumula múltiplas fontes de contribuição por meio de buffers temporários e normalização e, no final, propaga o sinal de erro para a camada anterior. Essa ordem garante que cada módulo receba exatamente o gradiente correspondente à saída que ele produziu na propagação para frente e que o ajuste agregado seja coerente e convirja de forma estável durante o treinamento.
Depois que os gradientes são coletados e cuidadosamente distribuídos por todas as ramificações do Codificador, começa a fase final: a atualização propriamente dita dos parâmetros treináveis. Em nosso código, isso se resume a chamadas sequenciais dos métodos homônimos dos componentes internos: cada módulo é responsável por aplicar o gradiente acumulado aos seus próprios pesos.
bool CNeuronSSCNNEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { //--- Long if(!cLongNorm.UpdateInputWeights(NeuronOCL)) return false; if(!cLongExtrapolate.UpdateInputWeights(cLongNorm.AsObject())) return false; //--- Season if(!cSeasonNorm.UpdateInputWeights(cSeasonTransp.AsObject())) return false; if(!cSeasonExtrapolate.UpdateInputWeights(cUnSeasonTransp.AsObject())) return false; if(!cSeasonMeanExtrapolate.UpdateInputWeights(cSeasonNorm.GetMeans())) return false; //--- Short if(!cShortNorm.UpdateInputWeights(cUnSeasonTransp.AsObject())) return false; if(!cShortExtrapolate.UpdateInputWeights(cShortNorm.AsObject())) return false; if(!cShortMeanExtrapolate.UpdateInputWeights(cShortNorm.GetMeans())) return false; //--- Spatial if(!cSpatialNorm.UpdateInputWeights(cShortNorm.AsObject())) return false; if(!cSpatialExtrapolate.UpdateInputWeights(cSpatialNorm.AsObject())) return false; if(!cSpatialMeanExtrapolate.UpdateInputWeights(cSpatialNorm.GetMeans())) return false; //--- Fusion if(!cFusion.UpdateInputWeights(cTranspose.AsObject())) return false; //--- return true; }
Assim, o método updateInputWeights é um orquestrador conciso, mas poderoso: ele percorre a lista de componentes, delega a cada um a responsabilidade por seus pesos e coleta cuidadosamente os status de execução. Essa abordagem preserva a modularidade, facilita os testes e simplifica a expansão da arquitetura: ao adicionar novos componentes treináveis, basta inserir sua atualização no ponto correto dessa cadeia.
Com isso, concluímos a análise detalhada da lógica de montagem do Codificador. O código-fonte completo da classe CNeuronSSCNNEncoder e de todos os seus métodos é apresentado no anexo e pode servir de referência para integração ou modificação.
Objeto de nível superior
O framework SSCNN foi concebido desde o início como uma composição de uma sequência de Codificadores, em que cada um aprofunda a análise e eleva o grau de abstração dos atributos. Na prática, isso permite primeiro alinhar e extrair as componentes evidentes (tendência, sazonalidade, oscilações locais) e depois trabalhar, etapa por etapa, com uma representação cada vez mais rica e compacta, identificando inter-relações sutis. É justamente para coordenar essa sequência que introduzimos o objeto de nível superior CNeuronSSCNN, herdado de CNeuronSCNN.
A classe funciona como um orquestrador: ela encapsula a sequência de Codificadores, coordena o fluxo de tensores entre eles, trata o alinhamento de dimensões e formatos e garante que a propagação para frente e a reversa ocorram corretamente ao longo de toda a cadeia.
class CNeuronSSCNN : public CNeuronSCNN { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSSCNN(void) {}; ~CNeuronSSCNN(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint variables, uint forecast, uint season_period, uint short_period, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronSSCNN; } };
Vale observar que o comportamento de CNeuronSSCNN corresponde integralmente à lógica herdada da classe pai: não inventamos um novo algoritmo, apenas indicamos explicitamente quais Codificadores são usados na nova configuração. O motivo para sobrescrever a classe é puramente pragmático: precisamos definir um tipo específico de Codificador e seus parâmetros para construir vários níveis em sequência. Nos novos métodos, fazemos apenas alterações pontuais: substituímos os tipos e formatos dos Codificadores usados, sem alterar a lógica computacional em si. Portanto, agora não faz sentido examinar em detalhes algoritmos que já foram analisados anteriormente, pois sua implementação permanece a mesma. O código-fonte completo da classe e de todos os seus métodos está disponível no anexo.
Treinamento do modelo
Falemos brevemente sobre o treinamento do modelo. Mantemos a estratégia em duas etapas: primeiro, um treinamento offline intensivo; depois, um ajuste fino online em operação. Para acelerar a etapa offline, simplificamos deliberadamente a representação do estado do ambiente no Codificador de estado do ambiente e excluímos o treinamento dos módulos auxiliares de previsão. Isso traz um ganho claro na velocidade de preparação, mas reduz a representatividade da representação inicial. O treinamento é implementado no método Train.
void Train(void) { int start = iBarShift(Symb.Name(), TimeFrame, Start); int end = iBarShift(Symb.Name(), TimeFrame, End); int bars = CopyRates(Symb.Name(), TimeFrame, 0, start, Rates);
Primeiro, o método calcula os índices de início e fim da janela de treinamento e, em seguida, carrega os dados históricos do terminal. Essa é a preparação padrão dos dados: precisamos dos preços brutos e das marcas de tempo, a partir dos quais serão construídos todos os atributos e amostras subsequentes.
if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
O bloco seguinte verifica se foi possível redimensionar os buffers dos indicadores. Se pelo menos um buffer não puder ser alocado, exibimos uma mensagem de depuração e encerramos corretamente a execução do EA com ExpertRemove, para não continuar em um estado inconsistente.
Em seguida vem o laço que aguarda o cálculo dos indicadores. Verificamos se os indicadores são calculados em até um número limitado de iterações. Isso protege contra situações em que os dados ainda não estão prontos: em vez de iniciar com dados incompletos, damos algum tempo ao sistema, mas não indefinidamente. Se o limite for excedido, exibimos uma mensagem e encerramos a execução do EA.
//--- int count = -1; bool calculated = false; do { count++; calculated = (RSI.BarsCalculated() >= bars && CCI.BarsCalculated() >= bars && ATR.BarsCalculated() >= bars && MACD.BarsCalculated() >= bars ); Sleep(100); count++; } while(!calculated && count < 100); if(!calculated) { PrintFormat("%s -> %d The training data has not been loaded", __FUNCTION__, __LINE__); ExpertRemove(); return; } RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } bars -= end + HistoryBars + NForecast; if(bars < 0) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Depois disso, atualizamos os indicadores pelo método Refresh e colocamos o array Rates em modo Series, para que os acessos por índice funcionem na ordem habitual dos dados históricos. Em seguida, ajustamos o número de barras disponíveis. Isso leva em conta que, para cada exemplo de treinamento, precisamos dos valores HistoryBars anteriores e de uma margem para a previsão NForecast. Se o resultado for menor que zero, é sinal de que há poucos dados, e interrompemos a execução.
Preparamos os vetores de trabalho e o sinalizador de interrupção antecipada. Também registramos a hora atual, que será necessário para a atualização periódica da UI e para o controle de tempo.
vector<float> result, target, neg_target; bool Stop = false; //--- uint ticks = GetTickCount();
O laço principal de treinamento percorre as épocas. Ele continua até que o limite Epochs seja atingido, IsStopped sinalize uma parada externa ou o sinalizador Stop seja ativado por erro interno. No início de cada época, limpamos o estado interno do Codificador.
for(int epoch = 0; (epoch < Epochs && !IsStopped() && !Stop); epoch ++) { if(!cEncoder.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Dentro da época, há um laço que percorre as posições posit, que avança do início ao fim da janela histórica. Para cada posição, primeiro preparamos os dados de origem chamando CreateBuffers. Isso forma os buffers State e Time, que em seguida são passados para a rede. Depois formamos o vetor de estado da conta e geramos a ação de referência.
for(int posit = start - HistoryBars - NForecast - 1; posit >= end; posit--) { if(!CreateBuffers(posit, GetPointer(bState), GetPointer(bTime), Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } const vector<float> account = SampleAccount(GetPointer(bState), datetime(bTime[0])); const vector<float> target_action = OraculAction(account, Result); if(!bAccount.AssignArray(account)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Usamos um treinamento híbrido, baseado em sinais de recompensa e em uma trajetória de referência com lookahead sobre dados futuros.
Em seguida começa a propagação para frente. Primeiro, o Codificador de estado do ambiente gera a representação do estado atual do mercado.
//--- Feed Forward if(!cEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois, o Ator produz a ação do agente. Já o Crítico avalia a qualidade da ação no estado atual.
if(!cActor.feedForward(GetPointer(bAccount), 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.feedForward(GetPointer(cActor), -1, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Todas as chamadas são protegidas por verificações: em caso de erro, interrompemos imediatamente a execução e ativamos o sinalizador Stop.
O bloco Study é a etapa principal de atualização com base na recompensa. Obtemos a ação do Agente e calculamos a recompensa. Um detalhe interessante: se reward for negativo, multiplicamos seu valor por 2, ou seja, aumentamos as penalidades por decisões ruins. Esse reforço acelera o aprendizado a partir dos erros, mas exige cautela: uma penalidade agressiva demais pode desestabilizar o treinamento.
//--- Study cActor.getResults(Action); double equity = bAccount[2] * bAccount[0] * EtalonBalance / (1 + bAccount[1]); double reward = CheckAction(Action, equity, posit - NForecast + 1) / EtalonBalance; if(reward < 0) reward *= 2; Result.Clear(); if(!Result.Add(float(reward))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.backProp(Result, GetPointer(cEncoder), LatentLayer) || !cEncoder.backPropGradient((CBufferFloat*)NULL, NULL, LatentLayer, true) || !cActor.backPropGradient(GetPointer(cEncoder), LatentLayer, -1, true) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois executamos a propagação reversa em sequência: primeiro o Crítico, depois o Codificador e o Ator. Esse é o esquema clássico Ator-Crítico: o Crítico é atualizado pelo erro de avaliação do valor, e então o sinal segue para o Ator e o Codificador. Aqui, é importante respeitar a ordem: Crítico -> Codificador -> Ator, para que os gradientes percorram corretamente a estrutura comum do grafo computacional.
Em seguida vem a etapa do Oracul, o treinamento pela trajetória de referência. Executamos novamente a propagação para frente pelo Codificador e pelo Ator, pois seus parâmetros foram atualizados pouco antes. Como esperado, o resultado da análise do mesmo estado do ambiente tende a ser diferente.
//--- Oracul if(!cEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cActor.feedForward(GetPointer(bAccount), 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Action.AssignArray(target_action)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } reward = CheckAction(Action, equity, posit - NForecast + 1) / EtalonBalance;
Depois, substituímos a ação do agente pela ação de referência e calculamos a recompensa correspondente. Em seguida, executamos a propagação reversa pelo Actor, isto é, treinamos o Actor para imitar a ação de referência.
if(!cActor.backProp(Action, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.feedForward(Action, 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Result.Update(0, float(reward))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.backProp(Result, GetPointer(cEncoder), LatentLayer) || !cEncoder.backPropGradient((CBufferFloat*)NULL, NULL, LatentLayer, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- if(GetTickCount() - ticks > 500) { double percent = (epoch + 1.0 - double(posit - end) / (start - end - HistoryBars - NForecast)) / Epochs * 100.0; string str = ""; str += StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Actor", percent, cActor.getRecentAverageError()); str += StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Critic", percent, cCritic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Executamos o Crítico com a ação de referência, realizando as propagações para frente e reversa. Em seguida, chamamos novamente a otimização dos parâmetros do Codificador. Assim, em cada etapa, primeiro aprendemos com a própria experiência (aprendizado por reforço) e depois ajustamos a política na direção do alvo (aprendizado supervisionado). Isso muitas vezes produz uma convergência mais estável e mais rápida.
Durante o laço, aproximadamente a cada 500 ms geramos uma string de status com o percentual de progresso e os erros atuais do Ator e do Crítico. Esse é um mecanismo importante para informar o usuário sobre o andamento do treinamento.
Ao final de todas as épocas, limpamos o comentário, registramos as métricas finais no log do terminal e depois encerramos a execução do programa com segurança.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", cActor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", cCritic.getRecentAverageError()); ExpertRemove(); //--- }
O código-fonte completo do treinamento offline é apresentado no anexo. Ali você também encontrará o código de todos os programas usados na preparação do artigo e a arquitetura dos modelos treinados, que foram reaproveitados do trabalho anterior praticamente sem alterações. Na arquitetura do Codificador, alteramos apenas o tipo de sua camada principal.
Testes
Como já mencionado, o treinamento consiste em duas etapas consecutivas. Na primeira, a etapa offline, o modelo foi treinado com dados históricos do par EURUSD no timeframe H1 ao longo de todo o ano de 2024. Esse período incluiu uma ampla variedade de cenários de mercado, de fases calmas a oscilações bruscas, e permitiu treinar o modelo tanto com situações típicas quanto com eventos raros.
Na segunda etapa, realizamos um ajuste fino online em condições o mais próximas possível do mercado real. O treinamento foi conduzido no testador de estratégias do MetaTrader 5, onde o modelo processava sequencialmente um fluxo contínuo de candles. Esse modo revela a robustez diante de ruídos e distorções e permite adaptar o comportamento a mudanças no contexto de mercado.
Ao final, testamos o modelo com dados totalmente novos: cotações do período de janeiro a março de 2025. Todos os parâmetros e configurações permaneceram inalterados. Os resultados obtidos fornecem uma avaliação objetiva da precisão e da confiabilidade prática da abordagem proposta. Os resultados dos testes são apresentados abaixo.


Os resultados dos testes mostram um desempenho moderadamente positivo. Partindo de um depósito de $100, o EA obteve lucro de $62.25, com uma pequena diferença positiva entre o lucro bruto e o prejuízo bruto. Ainda assim, o fator de lucro mal supera 1, o que indica baixa eficiência da estratégia.
Durante o período de teste, foram realizadas 898 operações, distribuídas quase igualmente entre compras e vendas. Em ambos os casos, o percentual de operações lucrativas ficou em torno de 50%, com leve vantagem para as posições curtas. A operação lucrativa média gerou $1.97, enquanto a operação perdedora média foi de $1.82. O lucro máximo chegou a $13.56, e o prejuízo máximo, a $12.42.
De modo geral, o EA apresenta funcionamento estável, com execução precisa dos trades, mas a rentabilidade e a robustez da estratégia ainda precisam ser confirmadas.
Conclusão
Este artigo encerra a implementação das abordagens em MQL5 propostas pelos autores do framework SSCNN. O leitor foi apresentado à ideia de integração espaço-temporal dos atributos, em que cada instante reflete relações complexas entre as estruturas internas dos dados e os impulsos de mercado externos.
Esse modelo não apenas amplia os limites da compreensão do comportamento do mercado, mas também oferece uma ferramenta de adaptação a mudanças nos regimes de mercado, das fases calmas às oscilações acentuadas da volatilidade. A incorporação da Attention-based Normalization concentra a atenção nos trechos significativos e estabiliza o treinamento, transformando a SSCNN em um mecanismo analítico flexível, capaz de desemaranhar a complexidade estrutural das séries financeiras.
Links
- Parsimony or Capability? Decomposition Delivers Both in Long-term Time Series Forecasting
- Outros artigos da série
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA para treinamento offline dos modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA para treinamento online dos modelos |
| 3 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19134
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso