
Técnicas do MQL5 Wizard que você deve conhecer (Parte 58): Aprendizado por Reforço (DDPG) com Padrões de Média Móvel e Oscilador Estocástico
Introdução
A partir do nosso último artigo, testamos 10 padrões de sinal dos nossos 2 indicadores (MM e Oscilador Estocástico). Sete conseguiram passar pelo teste forward com base em uma janela de teste de 1 ano. No entanto, desses, apenas 2 conseguiram isso realizando tanto operações compradas quanto vendidas. Isso ocorreu devido à nossa pequena janela de testes, motivo pelo qual os leitores são incentivados a testar isso em um histórico maior antes de levar a ideia adiante.
Estamos seguindo uma tese na qual os três principais modos de aprendizado de máquina podem ser utilizados em conjunto, cada um em sua própria “fase”. Esses modos, recapitulando, são aprendizado supervisionado (SL), aprendizado por reforço (RL) e inferência/aprendizado por inferência (IL). Nos aprofundamos em SL no último artigo, onde padrões combinados da média móvel e do oscilador estocástico foram normalizados em um vetor binário de características. Esse vetor foi então alimentado em uma rede neural simples que treinamos no par EUR USD para o ano de 2023 e posteriormente submetemos a testes forward para o ano de 2024.
Como nossa abordagem se baseia na tese de que o RL pode ser utilizado para treinar modelos enquanto estão em uso, queremos demonstrar isso neste artigo utilizando nossos resultados e rede anteriores provenientes do SL. O RL, estamos propondo, é uma forma de retropropagação em tempo de execução que ajusta cuidadosamente nossas decisões de compra e venda para que elas não sejam baseadas apenas em mudanças projetadas de preço, como ocorria no modelo de SL.
Esse “ajuste fino”, como vimos em artigos anteriores sobre RL, combina exploração e aproveitamento. Assim, nossa rede de política, por meio do treinamento em um ambiente de mercado ao vivo, determinaria quais estados deveriam resultar em ações de compra ou venda. Pode haver casos em que um estado de alta não signifique necessariamente uma oportunidade de compra, e vice-versa. Isso significa que nosso modelo de RL atua como um filtro adicional para as decisões tomadas pelo modelo de SL. Os estados do nosso modelo de SL utilizavam valores contínuos unidimensionais, e isso será muito semelhante ao espaço de ações que utilizaremos.
DDPG
Já analisamos diversos algoritmos diferentes de RL e, para este artigo, estamos examinando o Deep Deterministic Policy Gradient (DDPG). Esse algoritmo específico, de forma semelhante ao DQN que analisamos em um artigo anterior, serve para realizar previsões em espaços de ação contínuos. Lembre-se de que, para a maioria dos algoritmos que analisamos recentemente, eles eram classificadores, buscando gerar distribuições de probabilidade sobre qual deveria ser o próximo curso de ação, como comprar, vender ou manter (por exemplo).
Este não é um classificador, mas sim um regressor. Definimos o espaço de ações como um valor de ponto flutuante no intervalo de 0,0 a 1,0. Essa abordagem pode ser utilizada para calibrar muito mais opções do que simplesmente:
- comprar (qualquer valor acima de 0.5);
- vender (qualquer valor abaixo de 0.5);
- ou manter (qualquer valor próximo de 0.5)
Isso poderia ser alcançado pela introdução de tipos de ordens pendentes ou até mesmo pelo dimensionamento de posições. Essas possibilidades são deixadas para o leitor explorar, pois permaneceremos com a implementação básica, na qual 0.5 serve como limite principal.
Em princípio, o DDPG utiliza redes neurais para aproximar os valores Q (recompensas provenientes das ações) e otimiza diretamente a política (a rede que escolhe a próxima melhor ação quando recebe estados do ambiente), em vez de apenas estimar os valores Q. Ao contrário do DQN, que também pode ser utilizado para ações discretas/de classificação, como esquerda ou direita, o DDPG é destinado exclusivamente a espaços de ação contínuos. (Pense em ângulos de direção ou torques de motores ao treinar sistemas robóticos, por exemplo). Como ele funciona?
Principalmente, duas redes neurais são utilizadas.
- Uma delas é a rede Ator (Actor), cuja função é decidir a melhor ação para um determinado estado do ambiente.
- A outra é a rede Crítica (Critic), cujo propósito é avaliar quão boa é a ação selecionada pelo ator, estimando as recompensas potenciais que podem ser obtidas ao executar essa ação.
Essa estimativa também é conhecida como Valor Q (Q-Value). Além disso, um elemento importante dentro do DDPG é o buffer de repetição de experiência. Ele armazena experiências passadas (um termo coletivo que representa estados, ações, recompensas e próximos estados) em um buffer. Amostras aleatórias desse buffer são utilizadas para treinar as redes e reduzir a correlação entre as atualizações.
Além das 2 redes mencionadas acima, também são utilizadas suas cópias equivalentes, chamadas de “alvos” (targets). Essas cópias separadas das redes ator e crítica têm seus pesos atualizados em um ritmo mais lento e argumenta-se que isso ajuda a estabilizar o processo de treinamento ao fornecer alvos consistentes. Por fim, a exploração, uma característica fundamental do aprendizado por reforço, é levada um passo adiante no DDPG por meio da introdução de um componente de ruído nas ações através de algoritmos, sendo o mais comum o ruído de Ornstein-Uhlenbeck.
O treinamento do DDPG abrange essencialmente 3 aspectos. Primeiramente, envolve o aprimoramento da rede ator, onde a rede crítica orienta a rede ator na definição de quais ações são boas ou ruins, para que a rede ator ajuste melhor seus pesos ao selecionar ações que maximizem as recompensas. Em segundo lugar, envolve o aprimoramento da rede crítica, que aprende a estimar melhor as recompensas/Valores Q utilizando atualizações de Bellman, conforme apresentado na equação abaixo:

Onde:
-
Q(s,a): O valor Q previsto (estimativa do crítico) para executar a ação a no estado s.
-
r: Recompensa imediata recebida após executar a ação a no estado s.
-
γ: Fator de desconto (0≤γ<1), que determina o quanto as recompensas futuras são valorizadas (mais próximo de 0 = foco no curto prazo, mais próximo de 1 = foco no longo prazo).
-
s′: Próximo estado observado após executar a ação a no estado s.
-
Qtarget(s′,⋅): Estimativa da rede Q-alvo para o valor Q do próximo estado s′ (utilizada para estabilizar o treinamento).
-
Actortarget(s′): Ação recomendada pelo ator-alvo para o próximo estado s′ (política determinística).
Por fim, existem atualizações suaves (soft updates) para o ator-alvo e o crítico-alvo, nas quais as atualizações são realizadas lentamente para acompanhar as redes principais de acordo com a seguinte equação:
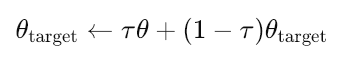
Onde:
- θtarget: Parâmetros (pesos) da rede-alvo (ator ou crítico).
- θ: Parâmetros da rede principal (online) (ator ou crítico).
- τ: Taxa de atualização suave (0≪τ≪1, por exemplo, 0.001). Controla quão lentamente as redes-alvo são atualizadas.
- τ pequeno = as redes-alvo mudam muito lentamente (treinamento mais estável).
- τ grande = as redes-alvo são atualizadas mais rapidamente (menos estabilidade, mas adaptação potencialmente mais rápida).
Por que DDPG? Ele é popular porque funciona bem em espaços de ação contínuos e de alta dimensionalidade, além de combinar a estabilidade do Q-Learning com a flexibilidade dos gradientes de política. Conforme mostrado no exemplo acima de espaço de ação contínuo em robótica, ele é muito popular em robótica, controle baseado em física e outras tarefas complexas semelhantes. Isso não significa que não possamos utilizá-lo em séries temporais financeiras, e é isso que exploraremos.
Estamos implementando a maior parte do nosso código em Python 3.10 devido às eficiências oferecidas no treinamento de redes muito profundas. Mas, neste campo, aprende-se algo novo de tempos em tempos. No meu caso, foi descobrir que o Python é realmente capaz de realizar cálculos tão rápidos no treinamento de redes (PyTorch e TensorFlow) graças a códigos-base e classes em C/C++, além do CUDA. Ora, o MQL5 é muito semelhante ao C e a implementação do OpenCL é suportada há algum tempo. Acredito que esteja faltando apenas uma biblioteca com multiplicação básica de matrizes (parcialmente em OpenCL) para obter desempenho semelhante no MQL5. Isso pode ser algo que vale a pena explorar.
Buffer de Replay
O buffer de replay é um componente muito importante no DDPG e em outros algoritmos de aprendizado por reforço off-policy. Ele é utilizado principalmente para quebrar correlações temporais entre amostras consecutivas, permitir a reutilização de experiências para tornar o aprendizado mais eficiente, fornecer um conjunto diversificado de transições para um treinamento estável e armazenar experiências passadas (tuplas de estado, ação, recompensa, próximo estado e concluído) para utilização no processo de treinamento/atualização dos pesos da rede.
Sua implementação principal começa pela função de inicialização:
def __init__(self, capacity): self.buffer = deque(maxlen=capacity)
Estamos utilizando collections.deque com uma capacidade máxima fixa e descartando automaticamente experiências antigas quando o buffer está cheio, por meio de um comportamento FIFO (First-In-First-Out). É uma solução muito simples e eficiente em termos de memória. Em seguida, temos a operação de inserção (push), na qual o buffer armazena tuplas completas de transição e lida tanto com transições bem-sucedidas quanto terminais (utilizando o indicador done). Ela oferece uma sobrecarga mínima ao adicionar novas experiências.
def push(self, state, action, reward, next_state, done): self.buffer.append((state, action, reward, next_state, done))
O mecanismo de amostragem utilizado é uma amostragem aleatória uniforme, muito importante para quebrar correlações. Ele é eficiente porque utiliza processamento em lote por meio de zip(*batch), o que permite separar os componentes das transições. Retorna todos os componentes necessários para a atualização do Q-learning.
def sample(self, batch_size): batch = random.sample(self.buffer, batch_size) states, actions, rewards, next_states, dones = zip(*batch)
O próximo elemento da classe do buffer de replay é a conversão para tensor e o tratamento de dispositivos para cada um dos componentes do ambiente. Como já mostrado acima, eles são estados, ações, recompensas, próximos estados e dones. A conversão é bastante robusta. Ela lida tanto com arrays NumPy quanto com tensores PyTorch como entrada. Isso garante que os tensores (que podem ser entendidos como arrays com informações de gradiente anexadas) sejam desvinculados dos grafos computacionais.
Movemos os dados para a CPU para evitar conflitos de dispositivos. Realizamos uma conversão explícita para Float Tensor (float-32), que é um requisito comum para redes neurais. Esse tipo de dado, menor que o double frequentemente utilizado no MQL5, é significativamente mais eficiente em termos computacionais. Por fim, graças ao PyTorch (ao contrário do TensorFlow), podemos optar por mover os dados para um dispositivo específico de processamento, como uma GPU, caso esteja disponível.
states = torch.FloatTensor( np.array([s.detach().cpu().numpy() if torch.is_tensor(s) else s for s in states]) ).to(device)
Nossa classe de buffer de replay funciona bem com o DDPG porque, em primeiro lugar, facilita o aprendizado off-policy, dado que o DDPG requer um buffer de replay para aprender a partir de dados históricos. Os espaços de ação contínuos do DDPG são tratados adequadamente pela conversão para Float Tensor. Ela fornece estabilidade ao DDPG por meio da amostragem aleatória, que ajuda a evitar atualizações correlacionadas que poderiam desestabilizar o treinamento. Também acrescenta flexibilidade ao ser capaz de trabalhar tanto com entradas NumPy quanto torch, comuns em pipelines de Aprendizado por Reforço.
Possíveis melhorias incluem a mudança para buffers de replay por experiência priorizada para lidar com transições importantes; utilização de retornos em múltiplas etapas ou aprendizado n-step; separação/classificação de diferentes tipos de experiências; e conversões para tensor mais eficientes que evitem o intermediário NumPy.
De modo geral, porém, nossa classe de buffer de replay é robusta devido ao uso de verificação de tipo com torch.is_tensor(), ao tratamento de dispositivos para garantir compatibilidade CPU/GPU e à separação limpa dos componentes do ambiente. O desempenho também não é comprometido, já que deque oferece operações append e pop com complexidade O(1); utiliza processamento em lote para minimizar sobrecarga; e implementa amostragem aleatória, que é eficiente para buffers de tamanho moderado. Ela também é de fácil manutenção, dado que o código possui uma implementação clara e concisa; é simples de estender ou modificar; e fornece boa consistência de tipos na saída.
As principais limitações e considerações podem estar relacionadas ao uso de memória. Armazenar transições completas pode consumir muito espaço para estados de transição de alta dimensionalidade. Além disso, a capacidade fixa pode precisar de ajustes para diferentes ambientes. Outra limitação está relacionada à eficiência da amostragem. A amostragem uniforme não prioriza experiências importantes, pois todas recebem o mesmo peso. Também não há tratamento dos limites dos episódios durante a amostragem.
Possíveis alternativas que abordam alguns desses problemas incluem o uso de armazenamento baseado em disco para buffers muito grandes; estados baseados em imagens para armazenar representações compactadas; e a adição de suporte para armazenar informações adicionais, como probabilidades logarítmicas. Essas alterações podem fornecer uma base sólida para o DDPG, permitindo sua extensão conforme necessidades específicas de aplicação, mantendo ao mesmo tempo sua funcionalidade principal.
Redes Crítica e Ator
Ambas as redes seguem uma estrutura semelhante de Perceptron Multicamadas (Multi-Layer Perceptron). Contudo, como seria de se esperar em Aprendizado por Reforço, elas desempenham funções distintas no DDPG. A rede crítica, também chamada de função Q, estima o valor dos pares estado-ação (Valores Q ou Recompensas), enquanto a rede ator, também chamada de rede de política, determina a ação ideal para um determinado estado.
A inicialização e a estrutura de camadas da rede crítica assumem o seguinte formato:
def __init__(self, state_dim, action_dim, hidden_dim): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1)
Os pontos principais aqui são os seguintes: ela recebe tanto estados quanto ações como entrada (como vimos em algoritmos anteriores de RL), diferentemente das funções de valor em outros métodos; estamos implementando essa rede com três camadas totalmente conectadas, contendo hidden dim neurônios nas duas primeiras camadas; a camada final gera apenas um único valor escalar Q; e a arquitetura foi concebida para estimar Q(s,a) em espaços de ação contínuos.
A mecânica da passagem direta (forward pass) é a seguinte:
def forward(self, state, action): x = torch.cat([state, action], dim=1) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) q_value = self.fc3(x)
Os componentes “críticos” dentro desta implementação incluem torch.cat, que é essencial para a estimativa do valor de ação no DDPG. Ele combina os vetores de entrada de estado e ação antes do processamento. O dimensionamento dim=1 garante a concatenação adequada para processamento em lote. Outra parte digna de nota do nosso código são as funções de ativação. A ReLU é utilizada nas camadas ocultas, pois ajuda a mitigar o problema do gradiente desaparecente. Nenhuma ativação é aplicada na camada final, já que os valores Q podem assumir qualquer número real.
O fluxo de informações ocorre do par estado-ação para as camadas ocultas e então para a estimativa do valor Q. Ele representa o núcleo da função de Q-Learning. A rede ator também possui a seguinte inicialização e estrutura:
def __init__(self, state_dim, action_dim, hidden_dim): super(Actor, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, action_dim) self.tanh = nn.Tanh()
Os aspectos principais que merecem destaque aqui são: ela recebe apenas state-dim como entrada, uma vez que a política depende do estado. Para nossos propósitos, ela segue uma estrutura semelhante de três camadas à da rede crítica acima, porém com um tratamento de saída diferente. O tamanho da camada final corresponde à dimensionalidade do espaço de ações. A ativação Tanh utilizada na camada de saída é importante para ações limitadas. A mecânica da passagem direta (forward pass) é definida pela seguinte listagem:
def forward(self, state):
x = self.relu(self.fc1(state))
x = self.relu(self.fc2(x))
action = self.tanh(self.fc3(x)) Muito mais simples e direta do que a rede crítica, onde o processamento do estado recebe apenas o estado como entrada (ao contrário da crítica) e então constrói a representação do estado através das camadas ocultas. A geração da ação é possibilitada pela ativação Tanh, que restringe as saídas ao intervalo [-1, 1]. Isso é fundamental para os espaços de ação contínuos do DDPG. Esse intervalo fixo pode ser redimensionado para o intervalo de ações do ambiente, como [0, 1], entre outros. Também merece destaque o fato de que a política é inerentemente determinística. Uma ação específica é produzida, em vez de uma distribuição de probabilidades sobre um conjunto discreto de ações, como frequentemente ocorre nos métodos de política estocástica.
As escolhas de projeto específicas do DDPG feitas para a rede crítica possuem algumas semelhanças com outros algoritmos de Aprendizado por Reforço, sendo elas: o tratamento conjunto das entradas, já que estado e ação são concatenados; a utilização de uma saída escalar, que funciona bem em espaços de ação contínuos; e a ausência de ativação na saída, preservando toda a faixa de estimativas dos valores Q. Para a rede ator, as escolhas de projeto do DDPG incluem saídas limitadas através do uso da Tanh, garantindo que as ações permaneçam dentro de uma faixa aprendível; natureza determinística, uma vez que se busca uma ação mais precisamente determinada em vez de uma política estocástica; e correspondência com o espaço de ações, onde o tamanho da camada final se alinha diretamente às dimensões de ação do ambiente.
Nosso exemplo de DDPG utiliza um espaço de ação unidimensional. O espaço de estados também é unidimensional, pois esse era o resultado da rede de aprendizado supervisionado utilizada no artigo anterior. As características arquiteturais compartilhadas incluem ativações ReLU, que são uma escolha bastante comum para camadas ocultas em Aprendizado por Reforço Profundo. Mantivemos tamanhos ocultos consistentes através de dimensionalidade uniforme em toda a rede e também adotamos uma estrutura MLP adequada para espaços de estados de baixa dimensionalidade.
Os pontos fortes da implementação não são particularmente excepcionais para redes PyTorch, mas incluem: robustez no tratamento de dimensões e especificação clara das dimensões de entrada e saída; gerenciamento de ativações com separação adequada entre ativações ocultas e de saída; e suporte para processamento em lote, já que todas as operações (em seus tensores) mantêm uma dimensão de lote. Além disso, algumas considerações que aumentam o desempenho dessas redes são a eficiência da ReLU, já que essa ativação é mais rápida em comparação com outros tipos; a simplicidade das camadas lineares (sem convoluções ou recorrências); e o número mínimo de operações graças às passagens diretas simplificadas.
Possíveis melhorias para a rede crítica incluem: normalização de camadas (layer normalization), que pode estabilizar o aprendizado; arquitetura dueling com valores de estado; e múltiplas saídas Q, como no TD3, para clipped double Q-learning. Para a rede ator, melhorias possíveis incluem injeção de ruído para exploração (embora o DDPG utilize ruído externo); normalização em lote (batch normalization) para auxiliar com diferentes escalas de estados; e normalização espectral para um treinamento mais estável.
No contexto da integração dessas duas redes dentro do DDPG: o papel da rede crítica durante o treinamento é fornecer estimativas de valores Q para as atualizações da política, que são então utilizadas para calcular os alvos de diferença temporal para ela própria. Ela precisa avaliar com precisão suas entradas, os valores estado-ação, para quantificar o quanto a política (pesos e vieses da rede ator) precisa ser ajustada. O papel do ator durante o treinamento é fornecer ações tanto para o funcionamento do ambiente quanto para o cálculo dos valores Q, atualizar a ascensão de gradiente sobre os valores Q da crítica e aprender políticas determinísticas suaves para controle contínuo.
Conclusão
Deveríamos analisar a classe Agente DDPG e a classe de dados Ambiente antes de revisar os relatórios do testador de estratégias para os nossos 7 padrões que conseguiram avançar nos testes forward do artigo anterior. No entanto, abordaremos esses tópicos no próximo artigo, já que este já está bastante extenso. Grande parte do material apresentado aqui está em Python, com a intenção de exportar redes ONNX para integração no MQL5 como recurso.
O Python é importante neste momento porque é mais eficiente para treinamento do que o MQL5 puro. Contudo, podem existir soluções alternativas utilizando OpenCL que também poderemos explorar em artigos futuros. O código típico anexado que utilizamos na montagem pelo Wizard a partir das classes de sinal também será analisado no próximo artigo e, por esse motivo, não temos anexos para este artigo.
| Nome | Descrição |
|---|---|
| wz_58_ddpg.py | Arquivo de script da implementação de Aprendizado por Reforço DDPG em Python |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/17668
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso