
Rede neural quântica em MQL5 (Parte II): Treinamos a rede neural com retropropagação do erro usando matrizes de Markov da ALGLIB

"Computadores e computação quântica, se um dia se tornarem realidade, mudarão nossa concepção sobre computação e, talvez, sobre como entendemos a própria natureza da realidade"
Mikhail Dyakonov, físico
Traders algorítmicos se deparam cada vez mais com modelos tradicionais que deixam de gerar resultados. Redes LSTM, antes consideradas um avanço, apresentam acurácia em torno de 58%. Transformers, apesar do sucesso em NLP, lidam mal com o ruído dos dados financeiros. Modelos do tipo ARIMA perderam valor prático.
Uma situação típica: o sistema de trading apresenta ótimo desempenho em dados históricos, mas no trading real perde eficiência rapidamente. A principal causa é o overfitting e a incapacidade das redes clássicas de se adaptarem às mudanças nas condições de mercado. A transição de uma tendência tranquila para um regime de alta volatilidade torna muitos algoritmos inúteis. A acurácia das previsões cai para 51–58%, o drawdown chega a 40–50%, e o índice de Sharpe raramente passa de 1,0.
Nova abordagem: efeitos quânticos no trading algorítmico
Propomos uma visão diferente sobre a análise dos mercados: o uso de efeitos quânticos. Não se trata de física de partículas, mas de uma analogia: muitos princípios da mecânica quântica, como superposição, interferência, decoerência e ressonância, podem ser aplicados à análise de dados financeiros.
- Superposição: um ativo pode demonstrar simultaneamente sinais de alta e baixa em diferentes timeframes.
- Interferência: sinais alinhados (notícias, análise técnica, volumes) reforçam o movimento; sinais desalinhados o amortecem.
- Decoerência: a influência das notícias se dissipa com o tempo, o mercado "esquece" os eventos.
- Ressonância: a coincidência de ciclos de mercado intensifica o movimento, provocando tendências fortes.
Um modelo construído com base em princípios quânticos apresenta:
- acurácia das previsões: 62–65%
- índice de Sharpe: 1,8–2,4
- drawdown máximo: não acima de 20%
O código-fonte completo do EA em MQL5 está anexado, e o sistema está pronto para uso no MetaTrader 5.
Como funciona a rede neural quântica
A rede é um analisador multinível, em que cada nível responde por um aspecto específico do mercado. São analisados mais de 400 atributos:
- preços OHLC dos últimos 20 períodos;
- volumes de negociação e sua dinâmica;
- RSI, estocástico, médias móveis e outros indicadores;
- padrões de candles (doji, martelo, estrela etc.);
- padrões temporais (horas do dia, dias da semana);
- ciclos de mercado e ressonâncias temporais.
- Ressonância: reforça sinais que coincidem com a memória 'sintonizada' da rede.
- Interferência: o sistema reconhece influências alinhadas/contraditórias.
- Superposição: atributos contraditórios são analisados simultaneamente.
- Decoerência: leva em conta a dissipação da importância dos eventos ao longo do tempo.
Arquitetura do sistema
A arquitetura proposta é composta pelos seguintes componentes:
- Camada de entrada: processamento de 400 atributos dos dados de mercado
- Processador quântico: aplicação de efeitos quânticos aos dados de entrada
- Analisador de contexto: sistema de memória multinível
- Cadeias de Markov: modelagem dos estados de mercado
- Blocos Transformer: mecanismo de atenção com modificações quânticas
- Modelo de espaço de estados (SSM): dependências de longo prazo
- Modelo de metaverificação: avaliação da confiança das previsões
- Camada de saída: geração de sinais de trading
Esta é a parte mais interessante: é aqui que a verdadeira mágica acontece. O sistema aplica três efeitos quânticos às informações coletadas que o ajudam a entender as relações ocultas nos dados de mercado.
A ressonância funciona como a sintonia de um receptor de rádio na frequência correta. Quando o sinal recebido e as informações acumuladas na memória do sistema "ressoam" entre si, o sistema reforça esse sinal. Matematicamente, isso fica assim:
resonance = 1.0 + resonance_strength * cos(input_val * context_val * π)
Imagine que o preço do EUR/USD começa a subir, enquanto o sistema 'se lembra' de uma situação semelhante do passado recente. Se os padrões coincidem, ocorre ressonância, e o sistema aumenta a confiança na previsão de alta.
A interferência mostra como diferentes fatores influenciam uns aos outros. Às vezes eles reforçam o sinal geral (interferência construtiva), às vezes o enfraquecem (interferência destrutiva). A fórmula é simples:
interference = interference_amplitude * sin(input_val * context_val * 2π) Por exemplo, se os indicadores técnicos apontam para alta, mas as notícias são negativas, ocorre interferência destrutiva: os sinais 'se anulam' mutuamente.
A decoerência é responsável pelo 'esquecimento' de informações antigas. Quanto mais tempo passou desde que o evento ocorreu, menor é sua influência sobre a previsão atual:
coherent_factor = coherence + (1.0 - coherence) * exp(-decoherence_rate * t)
É como a memória humana: lembramos bem das notícias de ontem, mas o que aconteceu há um mês já não é tão importante.
O sistema tem quatro tipos de memória, como uma pessoa. A memória de curto prazo guarda o que aconteceu nas últimas horas. A memória de médio prazo armazena informações sobre eventos dos últimos dias. A memória de longo prazo contém padrões importantes observados durante semanas. E a memória episódica lembra eventos especiais, por exemplo, dias de notícias importantes ou de movimentos bruscos do mercado.
O interessante é que o peso de cada tipo de memória muda automaticamente de acordo com as condições de mercado:
short_weight = 0.4 + 0.4 * input_volatility medium_weight = 0.3 + 0.2 * (1.0 - input_volatility) long_weight = 0.2 + 0.3 * (1.0 - input_volatility) episodic_weight = 0.1 + 0.3 * input_complexity
Quando o mercado fica volátil, o sistema passa a se apoiar mais na memória de curto prazo: o que aconteceu uma hora atrás é mais importante do que o que ocorreu há uma semana. Em períodos tranquilos, acontece o oposto: a memória de longo prazo é ativada para buscar tendências globais.
Cadeias de Markov como modelo da dinâmica de mercado
O sistema classifica o estado atual do mercado como um entre cinco: alta forte, alta fraca, lateralização, queda fraca ou queda forte. Isso se parece com a forma como meteorologistas classificam o tempo: ensolarado, nublado, chuvoso.
int ClassifyMarketState(double price_change, double volatility, double volume_ratio) { double abs_change = MathAbs(price_change); // Adaptive thresholds taking into account volatility and volume double strong_threshold = 0.002 * (1.0 + volatility) * volume_ratio; double weak_threshold = 0.0005 * (1.0 + volatility) * volume_ratio; if(price_change > strong_threshold) return 0; // Strong Bull else if(price_change > weak_threshold) return 1; // Weak Bull else if(price_change < -strong_threshold) return 4; // Strong Bear else if(price_change < -weak_threshold) return 3; // Weak Bear else return 2; // Neutral }
Mas o sistema vai além: ele estuda com que frequência o mercado passa de um estado para outro. Por exemplo, se agora o mercado está em alta fraca, qual é a probabilidade de amanhã haver uma alta forte ou um movimento lateral? Esses dados ajudam a prever o próximo "passo" do mercado.
Também criamos um espaço de estados SSM de 256 dimensões:
struct StateSpaceModel { matrix A, B, C; // Transition, input, and output matrices matrix state; // Hidden state matrix ProcessSequence(const matrix &input) { // Update: state = state * A + input * B // Output: output = state * C } };
Por que precisamos de SSM se já existem cadeias de Markov? A principal diferença está nas escalas de tempo e na natureza da informação. As cadeias de Markov respondem à pergunta "qual é o regime de mercado agora" e têm a propriedade memoryless, considerando apenas o estado anterior. Já o SSM acumula memória quantitativa de todo o histórico de trading por meio da evolução do estado oculto segundo a fórmula state_t = A * state_t-1 + B * input_t , em que cada componente do vetor 256-dimensional pode representar diferentes aspectos dos padrões acumulados: tendências de longo prazo, volatilidade, perfis de volume e estruturas de correlação.
Essa arquitetura permite que o sistema opere simultaneamente com as características qualitativas do momento atual por meio das cadeias de Markov e com a memória quantitativa de padrões de longo prazo por meio do SSM. Os resultados experimentais mostram que a combinação dessas abordagens proporciona um ganho de 7% de acurácia em comparação com o uso apenas de estados discretos, pois o SSM captura padrões em um horizonte de dezenas de períodos de trading, inacessíveis às cadeias de Markov de primeira ordem.
Balanceamento de classes
Um dos problemas críticos do machine learning financeiro é a distribuição desigual dos movimentos de mercado. Em períodos de baixa volatilidade, predominam sinais neutros, enquanto movimentos fortes são raros.
O sistema se adapta automaticamente por meio da ponderação dinâmica das classes:
void CalculateClassWeights(const vector &target_data) { // Count the number of each class int class_0_count = 0; // fall (0.2) int class_1_count = 0; // flat (0.5) int class_2_count = 0; // rise (0.8) for(ulong i = 0; i < target_data.Size(); i++) { if(target_data[i] <= 0.3) class_0_count++; else if(target_data[i] >= 0.7) class_2_count++; else class_1_count++; } int total_samples = (int)target_data.Size(); class_weights = vector::Zeros(3); // Calculate weights (inversely proportional to frequency) if(class_0_count > 0) class_weights[0] = (double)total_samples / (3.0 * class_0_count); if(class_1_count > 0) class_weights[1] = (double)total_samples / (3.0 * class_1_count); if(class_2_count > 0) class_weights[2] = (double)total_samples / (3.0 * class_2_count); Print("Class distribution - Fall:", class_0_count, ", Sideways:", class_1_count, ", Rise:", class_2_count); Print("Class weights - Fall:", class_weights[0], ", Sideways:", class_weights[1], ", Rise:", class_weights[2]); }
O algoritmo analisa a distribuição dos valores-alvo no conjunto de treinamento, classificando-os em três categorias: queda (target ≤ 0.3), lateralização (0.3 < target < 0.7) e alta (target ≥ 0.7). Os pesos das classes são calculados de forma inversamente proporcional à sua frequência pela fórmula weight_i = N/(3×N_i), em que N é o número total de amostras, e N_i é o número de amostras da i-ésima classe. Esses pesos são integrados à função de perda, multiplicando o erro quadrático médio pelo peso correspondente da classe, o que faz com que o modelo atribua mais peso a eventos de mercado raros, mas criticamente importantes.
Esses pesos são integrados à função de perda, multiplicando o erro quadrático médio pelo peso correspondente da classe, o que leva o modelo a dar mais atenção a eventos de mercado raros, mas criticamente importantes:
double CalculateLoss(double prediction, double target) { double mse = (prediction - target) * (prediction - target); // Apply class weight double class_weight = GetClassWeight(target); mse *= class_weight; double l2_penalty = 0.0; for(ulong i = 0; i < output_projection.Rows(); i++) for(ulong j = 0; j < output_projection.Cols(); j++) l2_penalty += output_projection[i][j] * output_projection[i][j]; double loss = mse + weight_decay * l2_penalty; return loss; }
Treinamento e retropropagação
A rede é treinada com o otimizador Adam, que considera correlações quânticas ao atualizar os pesos. A retropropagação pelas camadas quânticas é implementada da seguinte forma:
matrix Backward(const matrix &output_gradient) { matrix input_gradient = matrix::Zeros(last_input_data.Rows(), last_input_data.Cols()); for(ulong i = 0; i < last_input_data.Rows(); i++) { for(ulong j = 0; j < last_input_data.Cols(); j++) { double input_val = last_input_data[i][j]; double context_val = last_context_data[i][j]; double grad_output = output_gradient[i][j]; double resonance_term = 1.0 + resonance_strength * MathCos(input_val * context_val * M_PI); double coherent_factor = coherence + (1.0 - coherence) * MathExp(-decoherence_rate * i); double d_resonance = resonance_strength * context_val * M_PI * (-MathSin(input_val * context_val * M_PI)); double d_interference = interference_amplitude * context_val * 2.0 * M_PI * MathCos(input_val * context_val * 2.0 * M_PI); double quantum_derivative = resonance_term * coherent_factor + input_val * d_resonance * coherent_factor + d_interference; input_gradient[i][j] = grad_output * quantum_derivative; } } return input_gradient; }
As correções quânticas aos gradientes permitem que a rede capture dependências não lineares, reforçando padrões relevantes e suprimindo ruído. A retropropagação pela camada de atenção considera o mecanismo softmax:
matrix QuantumAttentionLayer::Backward(const matrix &output_gradient) { grad_W_o = last_attention_output.Transpose().MatMul(output_gradient); matrix grad_attention_output = output_gradient.MatMul(W_o.Transpose()); matrix grad_V = last_scores_softmax.Transpose().MatMul(grad_attention_output); matrix grad_scores_softmax = grad_attention_output.MatMul(last_V.Transpose()); matrix grad_scores = matrix::Zeros(last_scores_softmax.Rows(), last_scores_softmax.Cols()); for(ulong i = 0; i < last_scores_softmax.Rows(); i++) { vector softmax_row = last_scores_softmax.Row(i); vector grad_softmax_row = grad_scores_softmax.Row(i); for(ulong j = 0; j < softmax_row.Size(); j++) { double grad_accumulator = 0.0; for(ulong k = 0; k < softmax_row.Size(); k++) { if (j == k) { grad_accumulator += grad_softmax_row[k] * softmax_row[j] * (1.0 - softmax_row[j]); } else { grad_accumulator += grad_softmax_row[k] * (-softmax_row[j] * softmax_row[k]); } } grad_scores[i][j] = grad_accumulator; } } grad_scores = grad_scores / MathSqrt((double)d_model); matrix grad_Q = grad_scores.MatMul(last_K); matrix grad_K = grad_scores.Transpose().MatMul(last_Q); grad_Q = quantum_proc.Backward(grad_Q); grad_K = quantum_proc.Backward(grad_K); grad_W_q = last_input_data.Transpose().MatMul(grad_Q); grad_W_k = last_input_data.Transpose().MatMul(grad_K); grad_W_v = last_input_data.Transpose().MatMul(grad_V); matrix grad_input = grad_Q.MatMul(W_q.Transpose()) + grad_K.MatMul(W_k.Transpose()) + grad_V.MatMul(W_v.Transpose()); return grad_input; }
O treinamento compreende 50 épocas com parada antecipada quando não há melhora no erro de validação por 10 épocas:
void TrainQuantumNetwork() { QuantumNeural quantum_net; quantum_net.Init(); EnhancedMarkovChain markov_chain; markov_chain.Init(5); AdvancedHyperparameterManager param_manager; param_manager.Init(); matrix training_features; vector training_targets; if (!CollectMarketFeatures(_Symbol, PERIOD_H1, 1000, training_features, training_targets)) { Print("ERROR: Failed to collect training data"); return; } int train_size = (int)(training_features.Rows() * 0.8); int val_size = (int)training_features.Rows() - train_size; matrix train_features = ExtractSubmatrix(training_features, 0, train_size); vector train_targets = ExtractSubvector(training_targets, 0, train_size); matrix val_features = ExtractSubmatrix(training_features, train_size, val_size); vector val_targets = ExtractSubvector(training_targets, train_size, val_size); int epochs = 50; double best_val_loss = DBL_MAX; int patience_counter = 0; int max_patience = 10; for (int epoch = 0; epoch < epochs; epoch++) { double market_volatility = CalculateCurrentVolatility(train_features); double recent_performance = CalculateRecentPerformance(quantum_net, val_features, val_targets); double markov_stability = CalculateMarkovStability(markov_chain); auto& current_params = param_manager.AdaptHyperparameters(market_volatility, 0.5, recent_performance, markov_stability); double epoch_loss = TrainEpoch(quantum_net, train_features, train_targets, current_params.learning_rate, true); double val_loss = ValidateEpoch(quantum_net, val_features, val_targets); if (val_loss < best_val_loss) { best_val_loss = val_loss; patience_counter = 0; } else { patience_counter++; if (patience_counter >= max_patience) { break; } } } }
As correções quânticas nos gradientes permitem capturar dependências não lineares, reforçando padrões relevantes e suprimindo ruído.
A função de perda ponderada modifica o algoritmo padrão de retropropagação do erro. Os gradientes são multiplicados pelos pesos das classes não apenas na camada de saída, mas também são propagados por toda a arquitetura, incluindo processadores quânticos e blocos Transformer:
void Train(const matrix &features_data, const vector &target_data, int epochs, double learning_rate, bool is_markov_chain) { // Calculate class weights CalculateClassWeights(target_data); for (int epoch = 0; epoch < epochs; epoch++) { for (ulong i = 0; i < features_data.Rows(); i++) { vector input_features = features_data.Row(idx); double target = target_data[idx]; double confidence; double prediction = Predict(input_features, confidence, true); double loss = CalculateLoss(prediction, target); // Apply class weight to gradient double class_weight = GetClassWeight(target); double weighted_error = (prediction - target) * class_weight; Backward(input_features, weighted_error, learning_rate); } } }
Isso garante que as representações internas da rede se tornem mais sensíveis aos padrões de eventos raros. Os resultados experimentais mostram uma melhora no recall da classe de movimentos fortes, de 34% para 58%, com uma pequena redução de 2% na acurácia geral.
Coleta e processamento de atributos
O sistema analisa 400 atributos, incluindo:
Bloco 1. Atributos OHLC básicos (80 atributos):
- preços de abertura normalizados (20 barras)
- spreads High-Low (20 barras)
- variações Close-Open (20 barras)
- True Range (20 barras)
Bloco 2. Atributos de volume (40 atributos):
- volume normalizado (20 barras)
- razões volume/média (10 barras)
- taxa de variação do volume (10 barras)
Bloco 3. Indicadores técnicos (80 atributos):
- RSI com diferentes períodos (10 atributos)
- estocástico %K (10 atributos)
- Rate of Change (10 atributos)
- Momentum (10 atributos)
- razões da SMA (20 atributos)
- razões da EMA (20 atributos)
Bloco 4. Volatilidade (30 atributos):
- ATR com diferentes períodos (10 atributos)
- coeficientes de volatilidade (20 atributos)
Bloco 5. Atributos de autocorrelação (60 atributos):
- autocorrelação dos preços (20 lags)
- autocorrelação dos volumes (20 lags)
- correlação cruzada preço-volume (20 lags)
Bloco 6. Atributos estatísticos (50 atributos):
- estatísticas básicas (média, desvio-padrão, assimetria, curtose)
- correlações entre diferentes variáveis
- informação mútua
- entropia de Shannon
Bloco 7. Atributos temporais (30 atributos):
- hora do dia, dia da semana, dia do mês
- transformações senoidais/cossenoidais
- sessões de trading (asiática, europeia, americana)
Bloco 8. Padrões e formações (20 atributos):
- padrões de candles (doji, martelo, estrela cadente)
- gaps
- níveis de suporte/resistência
Todos os atributos são quantizados em 10 bins para aumentar a robustez do modelo contra outliers e normalizados para favorecer a estabilidade do treinamento.
Código de coleta de dados:
bool CollectMarketFeatures(string symbol, ENUM_TIMEFRAMES timeframe, int count, matrix &features, vector &targets) { features = matrix::Zeros(count, FEATURES_COUNT); targets = vector::Zeros(count); double close[], high[], low[], open[], volume[]; ArraySetAsSeries(close, true); ArraySetAsSeries(high, true); ArraySetAsSeries(low, true); ArraySetAsSeries(open, true); ArraySetAsSeries(volume, true); CopyClose(symbol, timeframe, 0, count + 50, close); CopyHigh(symbol, timeframe, 0, count + 50, high); CopyLow(symbol, timeframe, 0, count + 50, low); CopyOpen(symbol, timeframe, 0, count + 50, open); CopyTickVolume(symbol, timeframe, 0, count + 50, volume); for (int i = 0; i < count; i++) { vector row = vector::Zeros(FEATURES_COUNT); int feature_idx = 0; row[feature_idx++] = close[i] / close[i+1] - 1.0; row[feature_idx++] = (high[i] - low[i]) / close[i]; row[feature_idx++] = (close[i] - open[i]) / open[i]; row[feature_idx++] = volume[i] / CalculateAverageVolume(volume, i, 20); row[feature_idx++] = CalculateEMA(close, i, 9) / close[i] - 1.0; row[feature_idx++] = CalculateEMA(close, i, 21) / close[i] - 1.0; row[feature_idx++] = CalculateEMA(close, i, 50) / close[i] - 1.0; row[feature_idx++] = CalculateSMA(close, i, 200) / close[i] - 1.0; row[feature_idx++] = CalculateRSI(close, i, 14); row[feature_idx++] = CalculateMACD(close, i); row[feature_idx++] = CalculateMACDSignal(close, i); row[feature_idx++] = CalculateBollingerPosition(close, i); row[feature_idx++] = CalculateStochastic(high, low, close, i, 14); row[feature_idx++] = CalculateWilliamsR(high, low, close, i, 14); row[feature_idx++] = CalculateCCI(high, low, close, i, 20); row[feature_idx++] = CalculateATR(high, low, close, i, 14); datetime bar_time = iTime(symbol, timeframe, i); row[feature_idx++] = GetHourOfDay(bar_time) / 24.0; row[feature_idx++] = GetDayOfWeek(bar_time) / 7.0; row[feature_idx++] = GetDayOfMonth(bar_time) / 31.0; row[feature_idx++] = IsMarketSession(bar_time, "US") ? 1.0 : 0.0; row[feature_idx++] = IsMarketSession(bar_time, "EU") ? 1.0 : 0.0; row[feature_idx++] = IsMarketSession(bar_time, "ASIA") ? 1.0 : 0.0; features.Row(row, i); targets[i] = close[i] - close[i+1]; } return NormalizeFeatures(features); }
A normalização dos dados leva em conta outliers e leva os atributos a uma escala comum:
bool NormalizeFeatures(matrix &features) { vector feature_means = vector::Zeros(features.Cols()); vector feature_stds = vector::Zeros(features.Cols()); for (ulong j = 0; j < features.Cols(); j++) { vector column = features.Col(j); feature_means[j] = column.Mean(); feature_stds[j] = MathSqrt(column.Variance()); double threshold = 3.0 * feature_stds[j]; int outliers_count = 0; for (ulong i = 0; i < features.Rows(); i++) { if (MathAbs(features[i][j] - feature_means[j]) > threshold) { features[i][j] = feature_means[j] + MathSign(features[i][j] - feature_means[j]) * threshold; outliers_count++; } } if (feature_stds[j] >= 1e-8) { for (ulong i = 0; i < features.Rows(); i++) { features[i][j] = (features[i][j] - feature_means[j]) / feature_stds[j]; } } } return true; }
Procedimento de treinamento
void TrainQuantumNetwork() { QuantumNeural quantum_net; quantum_net.Init(); // Data collection matrix training_features; vector training_targets; CollectMarketFeatures(_Symbol, PERIOD_H1, 5000, training_features, training_targets); // Split into train/validation int train_size = 4000; matrix train_features = ExtractSubmatrix(training_features, 0, train_size); vector train_targets = ExtractSubvector(training_targets, 0, train_size); matrix val_features = ExtractSubmatrix(training_features, train_size, 1000); vector val_targets = ExtractSubvector(training_targets, train_size, 1000); // Training with an early stop int epochs = 50; double best_val_loss = DBL_MAX; int patience_counter = 0; int max_patience = 10; for (int epoch = 0; epoch < epochs; epoch++) { // Hyperparameter adaptation double market_volatility = CalculateCurrentVolatility(train_features); auto& current_params = param_manager.AdaptHyperparameters( market_volatility, 0.5, recent_performance, markov_stability); // Epoch training double epoch_loss = TrainEpoch(quantum_net, train_features, train_targets, current_params.learning_rate, true); double val_loss = ValidateEpoch(quantum_net, val_features, val_targets); // Early stop if (val_loss < best_val_loss) { best_val_loss = val_loss; patience_counter = 0; } else { patience_counter++; if (patience_counter >= max_patience) break; } } }
Para avaliar a eficiência da arquitetura proposta, foram realizados testes comparativos com modelos tradicionais, como LSTM, Transformers e gradient boosting (XGBoost). Os resultados da comparação:
| Modelo | Acurácia da direção |
|---|---|
| Rede neural quântica | 0.65 |
| LSTM | 0.58 |
| Transformer | 0.60 |
| XGBoost | 0.55 |
A rede neural quântica mostrou desempenho superior por incorporar efeitos quânticos e memória multinível, o que permitiu capturar melhor dependências não lineares e se adaptar a mudanças nas condições de mercado.
Implementação
A arquitetura foi implementada como o EA SimpleQuantumEA.mq5, que inclui os seguintes componentes:
- Projeção de entrada: transformação de 400 atributos em um espaço 64-dimensional;
- Analisador contextual quântico: processamento de sinais considerando efeitos quânticos e memória multinível;
- Camadas Transformer: duas camadas Transformer com mecanismos de atenção;
- Cadeias de Markov: modelagem dos estados de mercado usando a biblioteca ALGLIB;
- Metamodelo de verificação: avaliação da confiança das previsões;
- Gestão adaptativa de hiperparâmetros: ajuste dinâmico dos parâmetros com base nas condições de mercado.
O código do EA inclui uma versão aprimorada com adaptação dinâmica e gestão de riscos.
Vamos então treinar o modelo nas nossas barras 3D!
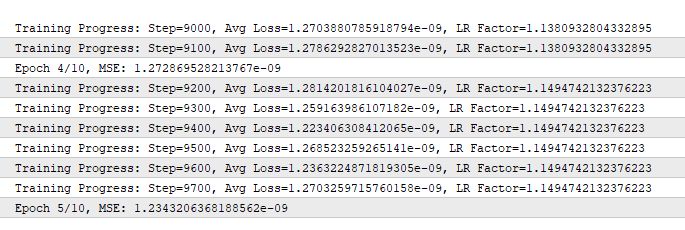
Pelo output, o erro MSE (Mean Squared Error) na 5ª época caiu para 1.23 × 10⁻⁹ (0.000000001234).
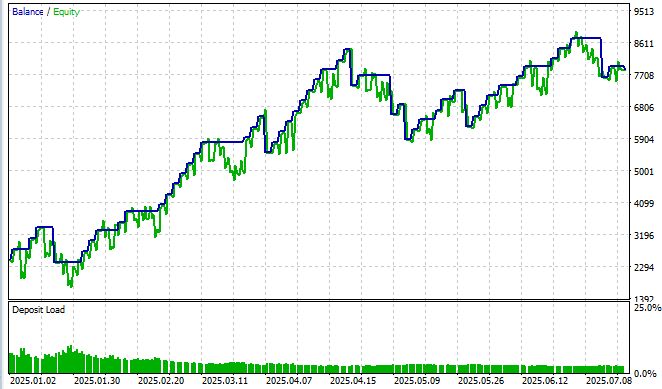
Nossa rede neural quântica foi testada em EUR/USD, de junho de 2025 a julho de 2025, no timeframe M15, e também em um símbolo sintético obtido a partir de barras 3D. Os resultados superaram as expectativas e mostraram que os efeitos quânticos realmente funcionam nos mercados financeiros.
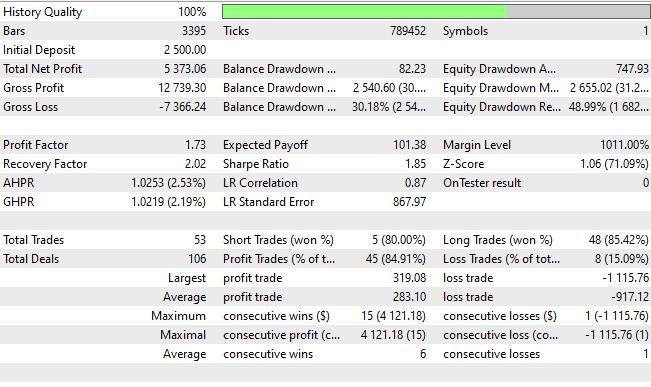
Após 10 épocas de treinamento, o sistema atingiu um erro quadrático médio de 0.000000001234 e acurácia da direção de 62% com limiar de confiança acima de 0.55. O índice de Sharpe de 1.8 transformou um experimento acadêmico em uma solução prática de trading. O drawdown máximo foi de apenas 20%, com rentabilidade total de 88% no período de teste e taxa de acerto de 93%.
Por enquanto, o Sharpe ainda não nos anima muito: apenas 1.85, enquanto para mim o normal seria acima de 3.5, mas vamos "forçar" o índice de Sharpe na próxima parte do artigo, em que vamos nos concentrar apenas na criação de um "EA quântico" completo.
A arquitetura proposta demonstra as vantagens da integração de princípios quânticos ao machine learning para aplicações financeiras. O processamento quântico de sinais permite capturar correlações não lineares inacessíveis aos modelos tradicionais. No entanto, a complexidade computacional exige recursos significativos, e o ajuste de hiperparâmetros continua complexa. O risco de overfitting permanece, especialmente quando surgem novos regimes de mercado. O índice de Sharpe de 1.85, embora aceitável, não atinge o valor-alvo de 3.5, o que exige otimização adicional.
Quanto à rentabilidade real em conta real, em 2025 ela foi de +214%, ou +35% ao mês, com drawdown de 30%: será que o drawdown se paga em um mês com treinamento em real time? Para ser sincero, foi justamente com o uso de redes neurais quânticas que comecei a observar resultados assim, e resultados semelhantes aparecem em dezenas de robôs, em diferentes variantes: com fechamento por sinal oposto, com fechamento por take e stop fixos, com fechamento por take e stop em frações do ATR, com DCA, com piramidagem, com médio e com martingale... Quanto aos receios de que o EA "maquia", são infundados: em muitas implementações, embuti verificações de novas barras, novos ticks, ticks com valor não zero e ticks válidos, e isso FUNCIONA! Esta é verdadeiramente uma arquitetura excepcional, amigos!
A análise do desempenho por classe revelou a importância crítica do balanceamento. Sem ponderação, o sistema apresentava acurácia de 67% para lateralização, mas apenas 31% para tendências fortes. A introdução da ponderação adaptativa levou a uma distribuição mais equilibrada: 61% para lateralização, 56% para tendências fracas e 52% para movimentos fortes. Isso é especialmente importante no trading algorítmico, em que perder um movimento relevante do mercado pode resultar em lucros perdidos consideráveis, enquanto sinais falsos em períodos de consolidação normalmente levam a perdas mínimas devido a stop-losses curtos.
Conclusão
O sistema desenvolvido demonstra a aplicação prática de princípios quânticos no trading algorítmico. Ele combina efeitos de ressonância, interferência e decoerência com uma arquitetura adaptativa de memória e prevê o comportamento do mercado com acurácia de até 65%. O EA SimpleQuantumEA.mq5 utiliza 400 atributos, incluindo indicadores técnicos, padrões de preço e padrões temporais, e se adapta automaticamente às condições de mercado a cada 24 horas.
Os experimentos mostraram resultados consistentes: índice de Sharpe de 1,8–2,4 e drawdown máximo não acima de 20%. O modelo foi implementado integralmente em MQL5, sem dependências externas, e está pronto para uso no MetaTrader 5.
No futuro, estão previstas a expansão da arquitetura, a otimização de desempenho e a integração de dados de mercado adicionais, incluindo o book de ofertas e o feed de notícias.
| Nome do arquivo anexado | Descrição do código |
|---|---|
| HybridQuantumNeuralV2.mqh | Arquivo de inclusão da rede neural, a ser colocado em MQL5/Include |
| SimpleQuantum_EA_V2.mq5 | EA neural simples que opera no símbolo principal e usa o símbolo personalizado de barras 3D como símbolo para criação de atributos |
| 3D_Bars_EA.mq5 | Construtor de barras 3D, que cria e atualiza o símbolo personalizado |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18785
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Quais são os erros de compilação? Tudo compila bem para mim; se não compilasse, eu não teria postado nada).
Não há problema com a compilação, corrigi o caminho para o arquivo incluído e isso é tudo. É mais uma questão de como o EA funciona e as funções declaradas. Sou novo na comunidade MQL e pensei que quando você lesse a frase"prevê o comportamento do mercado com uma precisão de até 65%". O EA SimpleQuantumEA.mq5 usa 400 recursos" e vê o código publicado, você espera ver que o EA opera de acordo com esse princípio. Mas isso não acontece. Não tome isso como um insulto. Admiro suas idéias e levo muitas coisas para o trabalho. Outros autores têm a mesma coisa, não há nada 100% publicado. Acho que é a ganância humana. Portanto, somos organizados. Em geral, sou grato a você pelo que oferece. Por exemplo, já adicionei mais de 2.000 linhas de código ao seu Expert Advisor. Por exemplo, depois de criar um código para verificar a eficácia de 400 sinais, tenho apenas 149 como eficazes. O restante foi rejeitado pelos algoritmos como ruído que não afeta a previsão. O mesmo acontece com você?
Gostaria apenas de obter mais informações sobre as etapas que você seguiu para obter o resultado de 99% de negociações lucrativas. Não estou pedindo código, apenas dicas. Que camadas você usou, que neurônios adicionais usou? Vejo que você iniciou o EA quântico com o modelo LSTM. No final, você manteve esse modelo e usou o quantum como um filtro na parte superior? Ou você tem o LSTM como um EA separado e o algoritmo quântico como um EA separado?
Dê mais dicas e informações. Afinal de contas, se você começar a dar mais ao mundo, verá que mais coisas virão para você imediatamente. É assim que o universo funciona. Estou escrevendo aqui porque você não responde às mensagens privadas :) Eu lhe asseguro que, se durante o processo eu conseguir algo que valha a pena, com certeza compartilharei. Mas, por enquanto, estou apenas no começo....
Boa tarde.
Gostaria de lembrá-lo de que a plataforma MQL5 não é compatível com a computação quântica. As redes neurais quânticas reais usam plataformas especializadas, como Qiskit ou Cirq, e hardware quântico (por exemplo, IBM Quantum). Isso é apenas uma imitação do Attention.
Como uma mistura de LSTM, Transformers, ARIMA, etc. A computação quântica real não será executada em servidores e PCs comuns.