
Do iniciante ao especialista: criação de um EA animado para notícias em MQL5 (IV) - Análise de mercado com modelos hospedados localmente usando IA

Conteúdo:
- Introdução
- Considerações gerais
- Configuração e hospedagem local do modelo de inteligência artificial
- Integração da ferramenta "Análise de inteligência artificial" no MQL5: aperfeiçoamento do EA "Manchetes de Notícias"
- Testes e integração
- Conclusão
- Principais lições
- Conteúdo do anexo
Introdução
Nesta discussão, veremos como usar modelos de inteligência artificial de código aberto para aprimorar nossas ferramentas de trading algorítmico, em especial como complementar o EA "Manchetes de Notícias" com a seção "Análise de inteligência artificial". O objetivo é ajudar iniciantes a encontrar um ponto de partida confiável. Quem sabe? Hoje você pode integrar um modelo e amanhã, talvez, criar o seu próprio. Mas tudo começa pela compreensão dos fundamentos estabelecidos por quem veio antes de nós.
Não podemos falar sobre os avanços modernos sem mencionar a inteligência artificial e sua influência em rápida expansão na solução de desafios humanos. Quando o assunto é trading algorítmico, a discussão se torna ainda mais relevante, pois o trading já se baseia em números e automação, o que torna a inteligência artificial uma solução natural em comparação com outras áreas que ainda precisam abandonar rotinas manuais.
Embora os modelos de inteligência artificial tenham se tornado ferramentas poderosas em várias áreas, nem todos têm os recursos ou a experiência necessários para criar seus próprios modelos, devido à complexidade do desenvolvimento de sistemas plenamente funcionais. Felizmente, o crescimento das iniciativas de código aberto permitiu obter acesso gratuito a modelos pré-treinados e utilizá-los sem custo. Esses esforços conduzidos pela comunidade servem como um ponto de partida prático para muitos desenvolvedores e entusiastas.
Ao mesmo tempo, os modelos premium costumam ter recursos mais amplos graças ao enorme esforço investido neles. Ainda assim, os modelos de código aberto são um ponto de partida valioso, especialmente para quem deseja integrar inteligência artificial sem reinventar a roda.
Na discussão anterior, nos concentramos na seção "Análise de indicadores". Hoje veremos como usar inteligência artificial de código aberto no trading algorítmico, hospedando por conta própria um modelo de linguagem quantizado e integrando-o diretamente a um EA em MQL5. Na próxima seção, começaremos com uma breve introdução aos papéis do llama.cpp (um mecanismo de inferência leve) e do modelo de 4 bits em formato GGUF (o "cérebro" compactado). Em seguida, veremos o download e a preparação do modelo, a configuração de um servidor local de inferência baseado em Python com FastAPI e, por fim, sua conexão ao EA "Manchetes de Notícias" para criar uma seção dinâmica de "Análise de inteligência artificial".
Ao longo do caminho, comentaremos as principais decisões, como contornar problemas comuns e apresentaremos um teste de fumaça simples. Tudo isso foi pensado para oferecer a você um guia claro e completo para adicionar comentários gerados por inteligência artificial em tempo real ao seu fluxo de trading.
Considerações gerais
Para este projeto, usamos um processador Intel Core i7-8550U de 64 bits (1,80-1,99 GHz) com 8 GB de RAM. Considerando essas limitações de hardware, escolhemos um modelo GGUF leve de 4 bits, mais especificamente o stablelm-zephyr-3b.Q5_K_M.gguf, para garantir carregamento eficiente e bom desempenho de inferência no nosso sistema. Mais adiante, compartilharei as especificações técnicas de hardware recomendadas para projetos desse tipo, bem como planos de upgrade para dar suporte a modelos de inteligência artificial maiores e mais exigentes no futuro.
Antes de continuar, é importante conhecer os principais componentes e requisitos de hardware necessários para o funcionamento estável deste projeto. Para fins educacionais, estamos trabalhando com especificações modestas, mas, se você tiver acesso a um hardware mais potente, recomendamos aproveitá-lo. Também darei recomendações sobre modelos adequados e especificações técnicas indicadas para configurações mais robustas.
Conhecendo a plataforma Hugging Face
Hugging Face é uma plataforma que hospeda milhares de modelos de machine learning pré-treinados (NLP, vision, speech etc.), além de conjuntos de dados, métricas de avaliação e ferramentas para desenvolvedores, acessíveis pela internet ou pela biblioteca huggingface_hub em Python. Isso simplifica a busca de modelos, o controle de versões e a gestão de arquivos grandes (Git LFS), além de oferecer tanto opções gratuitas de hospedagem própria quanto uma API gerenciada de inferência para implantações escaláveis. Com documentação completa, suporte da comunidade e integração fluida com frameworks como PyTorch e TensorFlow, a Hugging Face permite que qualquer usuário encontre, baixe e execute rapidamente modelos avançados de inteligência artificial em suas próprias aplicações.
Requisitos de hardware
Para um modelo GGUF de 4 bits com 3B de parâmetros, executado em llama-cpp-python, você precisará no mínimo de:
- CPU: processador de 4 núcleos/8 threads (por exemplo, Intel i5/i7 ou AMD Ryzen 5/7) para gerar cada token em uma fração de segundo.
- RAM: ~6-8 GB livres para carregar o modelo quantizado de ~1,9 GB, além da memória operacional.
- Armazenamento: SSD com ≥3 GB de espaço livre para o cache do modelo (~1,9 GB) e uma reserva para o sistema operacional.
- Rede: chamadas locais; não é necessária largura de banda externa.
Upgrade das especificações
- Modelos maiores: migre para modelos de 7B ou 13B parâmetros (quantizados), mas planeje usar mais de 12 GB de memória e CPUs ou GPUs mais potentes.
- Aceleração por GPU: use GPUs NVIDIA com CUDA/cuBLAS e o backend GPU do llama-cpp, ou frameworks como Triton/ONNX, para obter aceleração de 10 vezes.
- Escala horizontal: conteinerização (Docker) ou implantação em clusters Kubernetes para balancear a carga entre várias instâncias de inferência, uma ótima opção para configurações de alta performance ou multiusuário.
- Recursos em nuvem para GPU/TPU: migre para instâncias AWS/GCP/Azure (por exemplo, A10G, A100) para modelos com >13B parâmetros ou SLAs em tempo real.
Requisitos de software:
Nosso fluxo de trabalho usa vários shells e ambientes complementares para otimizar o desenvolvimento e os testes:
- Git Bash é nossa ferramenta para obter o código e controlar versões. Use-o para fazer git clone do repositório Hugging Face, executar python download_model.py (assim que o Python estiver no PATH) e até rodar testes de fumaça rápidos, caso você prefira a sintaxe Bash. Também podemos usar o Prompt de Comando do Windows ou outros shells para esse mesmo processo.
- MSYS2 nos fornece uma camada POSIX completa no Windows. Assim que o modelo estiver pronto, poderemos permanecer no MSYS2 para executar curl (ou httpie) contra http://localhost:8000/insights e confirmar que nosso endpoint FastAPI está ativo e retornando JSON.
- No Anaconda Prompt, criamos e ativamos nosso ambiente Conda para o servidor de IA (python=3.12), instalamos os pacotes llama-cpp-python, FastAPI e Uvicorn e, por fim, executamos uvicorn server:app --reload --port 8000.
Abaixo está o fluxograma que serve de base para as etapas que veremos nesta discussão.
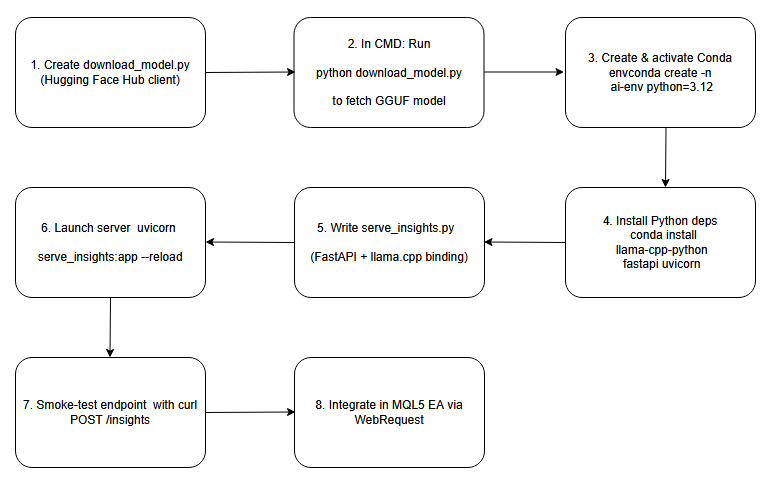
Fluxograma de sequência de operações.
Configuração e hospedagem local do modelo de inteligência artificial
Etapa 1: Criamos o script de download
Para começar, escreveremos um pequeno script em Python que usa o cliente Hugging Face Hub. Nesse script, indicamos o nome do repositório (por exemplo, "TheBloke/stablelm-zephyr-3b.Q5_K_M.gguf") e chamamos hf_hub_download() para baixar o arquivo GGUF quantizado para o nosso cache local. Em seguida, ao imprimir o caminho do arquivo retornado, obtemos uma referência confiável e legível por máquina para o local onde o modelo está agora no disco. Essa abordagem automatiza o download e garante que você conheça a localização exata do cache, o que é essencial para configurar o código de inferência subsequente sem hard-coding de diretórios imprevisíveis.
# download_model.py from huggingface_hub import hf_hub_download # Download the public 4-bit GGUF model; no Hugging Face account required model_path = hf_hub_download( repo_id = "TheBloke/stablelm-zephyr-3b-GGUF", filename = "stablelm-zephyr-3b.Q5_K_M.gguf", repo_type = "model" ) print("Downloaded to:", model_path)
Etapa 2: Executamos o script de download
Em seguida, abrimos o Prompt de Comando padrão do Windows e acessamos o diretório que contém o seu script de download (por exemplo, download_model.py). Quando python download_model.py for executado, o cliente Hugging Face se conectará via HTTPS, baixará o arquivo GGUF para o próprio cache e exibirá o caminho completo (algo como C:\Users\You.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b.Q5_K_M\…\stablelm-zephyr-3b.Q5_K_M.gguf). Visualizar esse caminho confirma que o arquivo está pronto e permite copiá-lo diretamente para a sua configuração de inferência.
Cmd no Windows:
python download_model.py
Caminho para o modelo baixado:
Адрес загрузки: C:\Users\BTA24\.cache\huggingface\hub\…\stablelm-zephyr-3b.Q5_K_M.gguf
Etapa 3: Criação e ativação do ambiente Conda
conda create -n ai-env python=3.12 -y conda activate ai-env
Etapa 4: Instalamos as dependências Python
Com o ambiente ai-server ativo, use pip install llama-cpp-python fastapi uvicorn (ou "conda install -c conda-forge llama-cpp-python", se preferir) para baixar as bibliotecas principais. O binding llama-cpp-python fornece o mecanismo de inferência C++ de alta performance necessário para carregar e executar o seu modelo GGUF, enquanto FastAPI e Uvicorn fornecem, respectivamente, o framework web assíncrono e o servidor para expor endpoints para fornecer insights. Juntos, esses pacotes formam a base do seu serviço local de inferência com inteligência artificial.
conda install -c conda-forge llama-cpp-python fastapi uvicorn -y
Etapa 5: Escrevemos o script de servidor FastAPI
Na pasta do seu projeto, crie um novo arquivo (por exemplo, server.py) e importe FastAPI e Llama de llama_cpp. No escopo global, crie uma instância da classe Llama, especificando o caminho para o arquivo GGUF que você baixou. Em seguida, defina um endpoint POST em /insights, que receba texto em formato JSON (contendo a string "prompt"), chame llm.create() ou um equivalente para gerar texto e retorne uma resposta em formato JSON contendo o campo "insight". Com apenas algumas linhas, você passa a ter um serviço RESTful de IA pronto para receber prompts e transmitir as saídas do modelo em streaming.
# serve_insights.py from fastapi import FastAPI, Request from llama_cpp import Llama MODEL_PATH = r"C:\Users\BTA24\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b-GGUF\snapshots\<snapshot-id>\stablelm-zephyr-3b.Q5_K_M.gguf" llm = Llama(model_path=MODEL_PATH, n_threads=4, n_ctx=512) app = FastAPI() @app.post("/insights") async def insights(req: Request): data = await req.json() prompt = data.get("prompt", "") out = llm(prompt, max_tokens=64) text = out["choices"][0]["text"].strip() return {"insight": text}
Etapa 6: Inicialização do servidor de inferência
Ainda no Anaconda Prompt, acesse o diretório do seu projeto e inicie o Uvicorn apontando para a aplicação FastAPI. Ative o recarregamento automático para acompanhar instantaneamente as alterações no script e receber requisições de entrada pela porta 8000.
Use cd para entrar na pasta onde server.py está localizado e execute:
cd "C:\Users\YOUR_COMPUTER_NAME\PATH_TO_YOUR python serve insights file"
Após entrar, iniciaremos o servidor:
uvicorn serve_insights:app --host 0.0.0.0 --port 8000 --reload
Etapa 7: Teste de fumaça do endpoint
Em qualquer terminal, envie uma requisição POST simples para http://localhost:8000/insights com um prompt de teste em formato JSON. Verifique se o servidor retorna um JSON válido contendo o campo "insight".
curl -X POST http://localhost:8000/insights \ -H "Content-Type: application/json" \ -d '{"prompt":"One-sentence FX signal for EUR/USD."}'
Uma resposta bem-sucedida terá a seguinte aparência:
{"insight":"Be mindful of daily open volatility…"}
Etapa 8: Integração ao seu EA em MQL5
Agora que o servidor de inteligência artificial está em execução e foi verificado, é hora de voltar ao nosso EA em MQL5 e continuar de onde paramos. Vamos integrar o endpoint AI Insights ao nosso EA adicionando ao gráfico uma barra especial "AI Insights" (ou seja, "Análise de inteligência artificial"). Após a integração, seu EA chamará o endpoint local /insights em um intervalo definido, analisará o JSON retornado e encaminhará o texto obtido no mesmo mecanismo de rolagem suave que você já usa para notícias e indicadores. Na próxima seção, veremos passo a passo a integração completa do código para criar uma ferramenta de trading completa, aprimorada com inteligência artificial.
Integração da ferramenta "Análise de inteligência artificial" no MQL5: aperfeiçoamento do EA "Manchetes de Notícias"
Partindo do pressuposto de que você leu nosso artigo anterior, agora vamos nos concentrar apenas na integração do novo recurso "Análise de inteligência artificial" ao EA. Nas próximas etapas, destacarei e explicarei cada adição de código necessária, mantendo intacto o restante do EA, e depois apresentarei o código completo atualizado do EA ao final da nossa discussão.
1. Expansão dos nossos parâmetros de entrada.
Primeiro, adicionamos três novos parâmetros de entrada aos já existentes. Incluímos um valor booleano para ativar ou desativar a barra "Análise de inteligência artificial" conforme necessário, uma string na qual informamos a URL do nosso endpoint FastAPI (ou de outra IA) e um número inteiro que define quantos segundos devem decorrer entre chamadas POST consecutivas. Com isso, podemos experimentar em modo interativo: ativar ou desativar a barra, apontar para servidores diferentes ou aumentar e reduzir a frequência, sem alterar o código principal.
//--- 1) USER INPUTS ------------------------------------------------ input bool ShowAIInsights = true; input string InpAIInsightsURL = "http://127.0.0.1:8000/insights"; input int InpAIInsightsReloadSec = 60; // seconds between requests
2. Declaração de variáveis globais compartilhadas
Em seguida, introduzimos variáveis globais para armazenar e gerenciar nossos dados de inteligência artificial. Salvamos o texto atual de insight como uma única string e acompanhamos seu deslocamento horizontal como um número inteiro para deslocá-lo a cada tick. Para evitar requisições duplicadas, adicionamos uma flag que indica quando uma requisição web está em execução e salvamos o timestamp da nossa última coleta bem-sucedida. Essas variáveis globais garantem que sempre haja algo para desenhar, que saibamos exatamente quando enviar a próxima chamada e que evitemos picos de chamadas HTTP.
//--- 3) GLOBALS ----------------------------------------------------- string latestAIInsight = "AI insights coming soon…"; int offAI; // scroll offset bool aiRequestInProgress = false; // prevent concurrent POSTs datetime lastAIInsightTime = 0; // last successful fetch time
3. Desenvolvimento de FetchAIInsights()
Encapsulamos toda a nossa lógica HTTP em uma única função. Dentro dela, primeiro verificamos nossa flag de ativação e o intervalo de espera: se a barra de inteligência artificial estiver desativada, se a última coleta foi recente demais ou se a requisição anterior ainda não foi concluída, simplesmente retornamos. Caso contrário, criamos uma carga útil JSON mínima, possivelmente incluindo o símbolo atual, e executamos WebRequest("POST"). Se a chamada for bem-sucedida, extraímos o campo "insight" da resposta JSON e atualizamos nosso texto global e o timestamp. Se algo der errado, mantemos a informação anterior sem alterações, para que a nossa barra rolante nunca fique vazia.
void FetchAIInsights() { if(!ShowAIInsights || aiRequestInProgress) return; datetime now = TimeTradeServer(); if(now < lastAIInsightTime + InpAIInsightsReloadSec) return; aiRequestInProgress = true; string hdrs = "Content-Type: application/json\r\n"; string body = "{\"prompt\":\"Concise trading insight for " + Symbol() + "\"}"; uchar req[], resp[]; string hdr; StringToCharArray(body, req); int res = WebRequest("POST", InpAIInsightsURL, hdrs, 5000, req, resp, hdr); if(res > 0) { string js = CharArrayToString(resp,0,WHOLE_ARRAY); int p = StringFind(js, "\"insight\":"); if(p >= 0) { int start = StringFind(js, "\"", p+10) + 1; int end = StringFind(js, "\"", start); if(start>0 && end>start) latestAIInsight = StringSubstr(js, start, end-start); } lastAIInsightTime = now; } aiRequestInProgress = false; }
4. Preenchimento do canvas em OnInit()
Na nossa rotina de inicialização, depois de configurar todos os demais canvas, também criamos o canvas de IA. Damos a ele as mesmas dimensões e o mesmo fundo semitransparente e, em seguida, o posicionamos logo abaixo das barras existentes. Antes de retornar qualquer dado, desenhamos um texto de preenchimento claro ("Os resultados da análise com inteligência artificial aparecerão em breve..."), para que o gráfico fique com uma aparência impecável. Por fim, chamamos imediatamente a função FetchAIInsights() uma única vez. Isso garante que, mesmo se o EA for iniciado no meio de uma sessão, o conteúdo real apareça assim que a primeira chamada de rede for concluída.
int OnInit() { // … existing init … // AI Insights lane if(ShowAIInsights) { aiCanvas.CreateBitmapLabel("AiC", 0, 0, canvW, lineH, COLOR_FORMAT_ARGB_RAW); aiCanvas.TransparentLevelSet(120); offAI = canvW; SetCanvas("AiC", InpPositionTop, InpTopOffset + (InpSeparateLanes ? 8 : 5) * lineH); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); aiCanvas.Update(true); // initial fetch FetchAIInsights(); } EventSetMillisecondTimer(InpTimerMs); return INIT_SUCCEEDED; }
5. Atualização e rolagem em OnTimer()
A cada tick do timer, já redesenhamos eventos, notícias e indicadores. Logo depois, executamos nossas ações com inteligência artificial: chamamos a função FetchAIInsights() (que é desativada automaticamente se o intervalo de espera ainda não tiver passado), limpamos o canvas de IA, desenhamos o insight mais recente com o deslocamento atual, reduzimos esse deslocamento para obter uma rolagem suave para a esquerda, fazemos o texto voltar ao início quando ele sai da tela e, por fim, chamamos Update(true) para aplicar a atualização imediatamente. O resultado é uma mensagem de IA com rolagem suave, atualizada apenas quando permitimos, combinando animação fluida com uso controlado da rede.
void OnTimer() { // … existing redraw for events/news/indicators … // fetch & draw AI lane FetchAIInsights(); if(ShowAIInsights) { aiCanvas.Erase(ARGB(120,0,0,0)); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); offAI -= InpAIInsightsSpeed; if(offAI + aiCanvas.TextWidth(latestAIInsight) < -20) offAI = canvW; aiCanvas.Update(true); } }
6. Limpeza em OnDeinit()
Quando nosso EA é descarregado, colocamos tudo em ordem. Desativamos o timer, destruímos e removemos o canvas de IA (somente se ele existir) e, em seguida, executamos a limpeza já existente dos outros canvas, arrays de eventos e objetos dinâmicos. Isso garante que não deixemos nenhum recurso pendente; por isso, recarregar ou reimplantar o EA sempre comece com uma base limpa.
void OnDeinit(const int reason) { EventKillTimer(); // … existing cleanup … if(ShowAIInsights) { aiCanvas.Destroy(); ObjectDelete(0, "AiC"); } }
Teste da integração
Agora que concluímos a integração, vamos carregar nosso EA atualizado no MetaTrader 5 e observar seu funcionamento em tempo real. Certifique-se de que o servidor de IA esteja em execução em segundo plano; ainda estou estudando se conseguiremos iniciá-lo programaticamente a partir do próprio EA. Na captura de tela abaixo, você verá a nova barra "Análise de inteligência artificial" fixada abaixo das demais barras, exibindo o texto analítico dos insights em tempo real.
Você pode ajustar facilmente o esquema de cores no código; para esta demonstração, deixamos a configuração padrão. Você também perceberá pausas breves e ocasionais na rolagem. Isso é consequência da nossa temporização atual da coleta, que ajustaremos nas próximas versões. Agora que o recurso de inteligência artificial integrada está em funcionamento, passaremos para a implementação do servidor para entender exatamente como o backend fornece esses recursos.

EA "Manchetes de Notícias" com dados analíticos baseados em IA de um modelo hospedado localmente
O trecho abaixo foi retirado diretamente do Anaconda Prompt, onde o Uvicorn atende nosso endpoint /insights. A análise desses logs nos mostra três coisas
- O modelo foi carregado com sucesso, portanto o mecanismo de inferência está pronto.
- O Uvicorn está em execução e ouvindo requisições, ou seja, o servidor HTTP está ativo.
- O WebRequest do nosso EA chegou com sucesso ao servidor, iniciando um novo ciclo de inferência.
Abaixo, registrei cinco desses ciclos de inferência durante os testes; cada um deles corresponde a um POST separado enviado pelo EA. Depois desse trecho, explicarei em detalhes um desses ciclos, para que você veja exatamente o que acontece nos bastidores.
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 83.42 ms / 64 runs ( 1.30 ms per token, 767.19 tokens per second) llama_print_timings: prompt eval time = 1890.97 ms / 6 tokens ( 315.16 ms per token, 3.17 tokens per second) llama_print_timings: eval time = 32868.44 ms / 63 runs ( 521.72 ms per token, 1.92 tokens per second) llama_print_timings: total time = 35799.69 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 51.40 ms / 64 runs ( 0.80 ms per token, 1245.21 tokens per second) llama_print_timings: prompt eval time = 1546.64 ms / 4 tokens ( 386.66 ms per token, 2.59 tokens per second) llama_print_timings: eval time = 29878.89 ms / 63 runs ( 474.27 ms per token, 2.11 tokens per second) llama_print_timings: total time = 32815.26 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 65.92 ms / 64 runs ( 1.03 ms per token, 970.80 tokens per second) llama_print_timings: prompt eval time = 1841.83 ms / 6 tokens ( 306.97 ms per token, 3.26 tokens per second) llama_print_timings: eval time = 31295.30 ms / 63 runs ( 496.75 ms per token, 2.01 tokens per second) llama_print_timings: total time = 34146.43 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 55.34 ms / 64 runs ( 0.86 ms per token, 1156.42 tokens per second) llama_print_timings: prompt eval time = 1663.61 ms / 4 tokens ( 415.90 ms per token, 2.40 tokens per second) llama_print_timings: eval time = 29311.62 ms / 63 runs ( 465.26 ms per token, 2.15 tokens per second) llama_print_timings: total time = 31952.19 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Entendendo o funcionamento do modelo e do WebRequest dentro do Anaconda Prompt:
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Quando seu servidor FastAPI-Uvicorn carrega o modelo GGUF, o llama-cpp informa que o "tempo de carregamento" é de cerca de 206 segundos. Esse é um custo único para ler e inicializar toda a rede quantizada na memória. Depois disso, cada HTTP POST recebido em /insights segue aproximadamente esta sequência:
Avaliação da requisição (tempo de avaliação da requisição)
Aqui, o llama-cpp passa os primeiros tokens da sua requisição pela pilha de transformers do modelo para "iniciar" a geração. Nesse log, 4 tokens levaram ao todo 1,49 segundo, o que equivale a cerca de 372 ms por token.
Geração de token (tempo de avaliação + tempo de amostragem)
- Para cada token subsequente gerado, a biblioteca executa duas operações:
- Avaliação: calcula a propagação para frente do transformer (≈ 469 ms por token, ou seja, ~2,13 tokens por segundo).
- Amostragem: aplica nucleus/top-k/etc para escolher o próximo token (≈ 0,91 ms por token).
- No seu experimento, a geração de 63 tokens levou cerca de 29,6 segundos de avaliação, mais 58 ms para amostrar todos eles.
Latência total (tempo total)
A soma do tempo de avaliação da requisição, de todas as avaliações de tokens e da amostragem resulta em 31,98 segundos desde o início dos cálculos pelo modelo até a obtenção do texto final.
Assim que a geração termina, o Uvicorn registra algo como:
INFO: 127.0.0.1:52770 - "POST /insights HTTP/1.1" 200 OK
isso significa que o servidor recebeu WebRequest("POST", "http://127.0.0.1:8000/insights", …) do seu EA, processou a requisição e retornou as informações em formato JSON com status 200, contendo sua informação analítica.
Por fim, a linha indica que o llama-cpp reconheceu em seu cache uma sequência repetida de tokens (prefixo) e pulou o recálculo dessas camadas, o que acelerou um pouco a geração.
Llama.generate: prefix-match hit
Durante os testes, notei pausas ocasionais na rolagem da barra do EA. Descobri que chamar a função FetchAIInsights() diretamente no loop do timer fazia com que o WebRequest do EA ficasse bloqueado aguardando a resposta, enquanto o Uvicorn executava toda a avaliação do modelo, a geração de tokens e a amostragem (cerca de 32 segundos) antes de retornar o JSON.
Com a lógica de rolagem completamente separada das nossas chamadas HTTP, desenhando e deslocando o texto a cada 20 ms antes de chamar a função FetchAIInsights(), a animação da barra da interface pode continuar sem interrupções. Enquanto isso, a inferência computacionalmente pesada é executada no servidor e, somente após sua conclusão, atualizamos latestAIInsight com a nova resposta.
Conclusão
Em resumo, este exercício mostrou o quanto o MQL5 pode ser extensível quando combinado com serviços externos, seja para carregar eventos atuais do calendário econômico e manchetes da Alpha Vantage, seja para complementar seus gráficos com "notas" geradas por inteligência artificial a partir de um modelo de 4 bits hospedado localmente. Embora esses conteúdo analítico gerado por IA não substituam dados em tempo real nem um sistema de trading desenvolvido profissionalmente, eles acrescentam uma camada qualitativa de comentários sob demanda ou sugestões para brainstorming, que podem gerar novas ideias.
Ao longo do caminho, conhecemos a plataforma Hugging Face e aprendemos a usar MSYS2, Git Bash e Miniconda para obter modelos, configurar servidores e gerenciar ambientes isolados. Combinamos duas linguagens: Python para a inferência dos modelos e FastAPI, e MQL5 para a integração com os gráficos, ampliando nosso conjunto de ferramentas de programação e demonstrando como diferentes ecossistemas podem trabalhar em conjunto. Convidamos você a experimentar e compartilhar seu feedback na seção de comentários.
Olhando adiante, para melhorar o contexto e a relevância, experimente inserir nas suas prompts de inteligência artificial a série de preços da plataforma MetaTrader 5 ou valores de indicadores em tempo real. Também é possível testar diferentes formatos quantizados, automatizar implantações sem tempo de inatividade ou distribuir a inferência entre vários nós. A migração para um modelo maior e a modernização do hardware permitirão obter insights mais ricos e detalhados, mas até mesmo configurações modestas podem se tornar poderosos assistentes interativos para trading. As possibilidades na interseção entre trading algorítmico e IA autônoma continuam em aberto; seu próximo avanço pode mudar a forma como os traders interagem com os mercados.
Confira abaixo os arquivos de suporte anexados. Também preparei uma tabela com uma breve descrição de cada arquivo para ajudar você a entender sua finalidade.
Principais lições
| Aprendizado | Descrição |
|---|---|
| Isolamento do ambiente | Use Conda ou virtualenv para criar ambientes Python isolados, mantendo dependências como FastAPI e llama-cpp-python separadas e reproduzíveis. |
| Cache local | Baixe e armazene em cache uma única vez arquivos grandes de modelos GGUF usando o cliente Hugging Face Hub, para evitar transferências repetidas pela rede e acelerar a inicialização do servidor. |
| Controle de taxa | Defina um limite com intervalo mínimo (por exemplo, 300 segundos) para as requisições de IA, para que o EA não sobrecarregue o servidor nem gere carga excessiva de inferência. |
| Análise sintática tolerante a falhas | Inclua a decodificação JSON no tratamento de erros e extraia apenas o primeiro objeto válido, protegendo o EA contra respostas incorretas ou respostas com dados adicionais. |
| Bufferização dupla do canvas | Usa Canvas.Update(true) após cada ciclo de desenho para aplicar as alterações, evitar cintilação e garantir uma animação suave no gráfico. |
| Ciclos controlados por timer | Controla a rolagem e a atualização dos dados por meio de um único timer em milissegundos (por exemplo, 20 ms), para equilibrar a fluidez da animação com a carga sobre a CPU. |
| Integração com WebRequest | Usa WebRequest do MQL5 para enviar JSON ao servidor local de IA e receber dados analíticos, lembrando de adicionar a URL à lista de permissões nas configurações do terminal. |
| Randomização para diversidade | Altera os prompts ou seleciona aleatoriamente pares de moedas para cada requisição de IA, a fim de gerar insights de trading variados e não repetitivos. |
| Limpeza de recursos | Em OnDeinit, destrói todos os objetos Canvas, remove arrays dinâmicos e desativa timers para evitar vazamentos de memória e objetos órfãos no gráfico. |
| Projeto modular | Estrutura o código em funções claras, como ReloadEvents, FetchAlphaVantageNews, FetchAIInsights e DrawLane, para melhorar a legibilidade e a manutenção. |
| Versatilidade de shells | Usa Git Bash para Git e scripts, MSYS2 para ferramentas e builds POSIX, Conda Prompt para ambientes Python e CMD para a execução rápida de tarefas pontuais. |
| Hospedagem de modelo quantizado | Hospeda localmente um modelo GGUF quantizado para reduzir o consumo de memória e a latência de inferência em comparação com pesos em precisão completa. |
| Separação entre servidor e cliente | Mantém a inferência pesada no servidor FastAPI/Uvicorn, permitindo que o EA permaneça leve e processe apenas atualizações da interface e requisições HTTP. |
| Renderização separada | Sempre executa as operações de rolagem e desenho antes de chamar funções de rede, garantindo a responsividade da interface do usuário mesmo durante requisições longas. |
| Elaboração de prompts | Cria prompts JSON curtos e direcionados, como "Informações sobre o par EURUSD para hoje", para minimizar o tempo de avaliação dos prompts e concentrar a saída do modelo. |
| Estratégias de amostragem | Configure parâmetros de amostragem (top-k, top-p, temperatura) na sua aplicação FastAPI para equilibrar criatividade e consistência dos dados analíticos gerados. |
| Endpoints assíncronos | Usa manipuladores assíncronos definidos no FastAPI para que o Uvicorn possa processar requisições simultâneas do EA sem bloquear a inferência prolongada. |
| Logging e observabilidade | Registre logs com timestamps e níveis tanto no EA quanto no servidor, por exemplo, llama_print_timings e mensagens no console do EA, para diagnosticar problemas de performance. |
| Métricas de performance | Disponibiliza métricas (por exemplo, via Prometheus), como latência da requisição, número de tokens por segundo e tempo de carregamento do modelo, para monitorar e otimizar a performance do sistema. |
| Estratégias de fallback | Exibe a mensagem "insight unavailable" (informação analítica indisponível) por padrão no EA em caso de falha do WebRequest ou do servidor, mantendo a estabilidade da interface do usuário em condições de erro. |
Conteúdo do anexo
| Nome do arquivo | Descrição |
|---|---|
| News Headline EA.mq5 | EA para MetaTrader 5 que exibe diretamente no gráfico barras de rolagem de eventos do calendário econômico, notícias da Alpha Vantage, informações de indicadores (RSI, Stochastics, MACD, CCI), além de uma barra de sinais de mercado com rolagem lenta controlada por IA. |
| download_model.py | Script Python autônomo que usa o cliente Hugging Face Hub para obter e armazenar em cache o modelo StableLM-Zephyr quantizado de 4 bits em formato GGUF e exibe seu caminho local para uso posterior na configuração do servidor. |
| serve_insights.py | Aplicação FastAPI que carrega o modelo GGUF em cache por meio do llama-cpp-python, disponibiliza o endpoint POST /insights para receber prompts em formato JSON, executa a inferência e retorna as informações de mercado geradas. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/18685
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso