
初心者からエキスパートへ:MQL5を使用したアニメーションニュースヘッドライン(IV) - ローカルホストAIモデル市場インサイト

内容
はじめに
本ディスカッションでは、オープンソースのAIモデルを活用してアルゴリズム取引ツールを強化する方法、特に、News Headline EAにAI Insightsレーンを追加する手法について解説します。本稿の目的は、初心者の方が確かな出発点を見つける手助けをすることです。今日、モデルを統合することから始めても、明日には自分でモデルを構築する可能性があります。しかし、その第一歩は、先人たちが築いた基盤を理解することから始まります。
現代の進歩について議論する際、人工知能(AI)の急速な発展と人間の作業への影響に触れないわけにはいきません。アルゴリズム取引に関して言えば、この議論はさらに重要になります。なぜなら、取引はすでに数値と自動化によって動いており、手作業からの移行がまだ必要な他の分野と比べて、AIが自然に適合するからです。
AIモデルは様々な分野で強力なツールとなっていますが、完全なシステムを開発するには高い専門知識やリソースが必要なため、自身でモデルを構築することが難しい場合もあります。幸いなことに、オープンソースの取り組みにより、事前学習済みのモデルに無償でアクセスし、活用できる環境が整っています。これらのコミュニティ主導のプロジェクトは、多くの開発者や愛好者にとって実践的な入り口となります。
とはいえ、プレミアムモデルは、多大な開発労力が投入されているため、より広範な機能を提供することが多いです。それでも、オープンソースモデルは「車輪の再発明」を避けつつAIを統合する上で、非常に価値のある出発点となります。
前回の説明では、インジケーターインサイトに焦点を当てました。今回は、量子化された言語モデルをセルフホスティングし、それをMQL5のEAに直接統合する方法を探ります。 次のセクションでは、まずllama.cpp(軽量推論エンジン)と4ビットGGUFモデル(圧縮された「脳」)の役割を簡単に解説し、その後、モデルのダウンロードと準備、FastAPIを用いたPythonベースのローカル推論サーバーのセットアップ、そしてNews Headline EAへの接続方法までを順を追って説明します。
さらに、重要な意思決定のポイントや、よくあるトラブルシューティング、簡単なスモークテストの実演もおこない、リアルタイムでAIによる市場コメントを取引ワークフローに追加するための、明確なエンドツーエンドの設計図を提示します。
概要
本プロジェクトでは、64ビットIntel Core i7‑8550U CPU(1.80〜1.99 GHz)と8GBのRAMを使用しています。このハードウェア環境を考慮し、システム上で効率的にモデルを読み込み、推論できるよう、軽量な4ビットGGUFモデル、具体的にはstablelm‑zephyr‑3b.Q5_K_M.ggufを選択しました。後ほど、同様のプロジェクトに適した推奨ハードウェア仕様や、将来的により大規模で負荷の高いAIモデルに対応するためのアップグレード計画についても共有します。
本プロジェクトをスムーズに進めるためには、まず主要コンポーネントや必要なハードウェア要件に慣れておくことが重要です。教育目的として今回は控えめな仕様で進めますが、より高性能なハードウェアが利用できる場合は、それを活用することをお勧めします。また、高性能環境向けの適切なモデルや推奨仕様についてもガイドします。
Hugging Faceの理解
Hugging Faceは、数千の事前学習済み機械学習モデル(NLP、画像、音声など)に加え、データセット、評価指標、開発ツールをホスティングするプラットフォームです。Webまたはhuggingface_hub Pythonライブラリを通じてアクセス可能で、モデルの探索、バージョン管理、大容量ファイル管理(Git LFS)を簡単に行えます。また、無料のセルフホスティングオプションと、スケーラブルなデプロイ向けの管理型Inference APIも提供しています。包括的なドキュメント、コミュニティサポート、PyTorchやTensorFlowなどのフレームワークとのシームレスな統合により、誰でも最先端AIモデルを迅速に見つけ、ダウンロードし、アプリケーションに組み込んで実行することが可能です。
ハードウェア要件
4ビット、3BパラメータのGGUFモデルをllama‑cpp‑pythonで実行する場合、最低限必要な仕様は以下の通りです。
- CPU:4コア/8スレッド(例:Intel i5/i7またはAMD Ryzen 5/7)1トークンあたりの推論時間が1秒未満
- RAM:約6〜8GBの空き容量(量子化モデル約1.9GBの読み込み+作業メモリ)
- ストレージ:SSDで3GB以上の空き容量(モデルキャッシュ約1.9GB+OSオーバーヘッド)
- ネットワーク:ローカルホスト呼び出しのみで、外部帯域は不要
仕様のアップグレード
- より大きなモデル:7Bまたは13Bパラメータモデル(量子化済み)に移行する場合、RAMは12GB以上、CPUやGPUもより強力なものが必要です。
- GPUアクセラレーション:CUDA/cuBLAS対応のNVIDIA GPUを利用するか、llama‑cpp GPUバックエンドまたはTriton/ONNXフレームワークを活用することで、最大10倍の高速化が可能です。
- 水平スケーリング:Dockerでコンテナ化、またはKubernetesクラスター上で複数の推論ポッドをロードバランスすることで、ハイスループットやマルチユーザー環境に対応可能です。
- クラウドGPU/TPU:13Bパラメータ以上のモデルやリアルタイムSLA向けには、AWS/GCP/Azureのインスタンス(例:A10G、A100)に移行します。
ソフトウェア要件
本ワークフローでは、開発とテストを効率化するために複数のシェルや環境を併用しています。
- Git Bash:コードの取得やバージョン管理に使用します。Hugging Faceリポジトリをgit cloneしたり、python download_model.pyを実行したり、簡単なスモークテストをおこなう際にも便利です。Windowsコマンドプロンプトや他のシェルでも同様の操作が可能です。
- MSYS2:Windows上でPOSIX互換レイヤーを提供します。モデル配置後、curlやhttpieでhttp://localhost:8000/insightsにアクセスし、FastAPIエンドポイントが生きているか、JSONを返すかを確認できます。
- Anaconda Prompt: ai-server Conda環境(Python 3.12)を作成・アクティブ化し、llama‑cpp‑python、FastAPI、Uvicornをインストールします。その後、「uvicorn server:app --reload --port 8000」でサーバーを起動します。
下図は、本ディスカッションで扱うプロセスの設計図としてのフローチャートです。
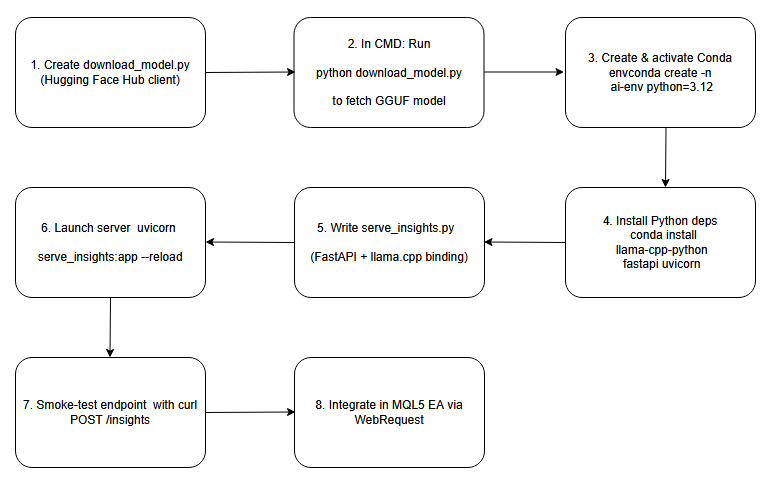
フローチャート
AIモデルのローカルでのセットアップとホスティング
手順1:ダウンロードスクリプトを作成する
まず、Hugging Face Hubクライアントを活用した小さなPythonスクリプトを作成します。このスクリプトでは、リポジトリ名(例:TheBloke/stablelm‑zephyr‑3b.Q5_K_M.gguf)を指定し、hf_hub_download()を呼び出して量子化されたGGUFファイルをローカルキャッシュにダウンロードします。その後、返却されたファイルパスを出力することで、モデルがディスク上のどこに保存されているかを機械的に参照できる信頼性の高い情報を得られます。この方法により、ダウンロードの自動化が可能になり、予測不可能なディレクトリをハードコーディングせずに、下流の推論コードを正しく設定することができます。
# download_model.py from huggingface_hub import hf_hub_download # Download the public 4-bit GGUF model; no Hugging Face account required model_path = hf_hub_download( repo_id = "TheBloke/stablelm-zephyr-3b-GGUF", filename = "stablelm-zephyr-3b.Q5_K_M.gguf", repo_type = "model" ) print("Downloaded to:", model_path)
手順2:ダウンロードスクリプトを実行する
次に、Windowsのコマンドプロンプトを開き、ダウンロードスクリプト(例:download_model.py)が置かれたディレクトリに cd で移動します。「python download_model.py」を実行すると、Hugging FaceクライアントはHTTPS経由で接続し、GGUFの重みをキャッシュにダウンロードして、完全なパス(例:C:\Users\You\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b.Q5_K_M\…\stablelm-zephyr-3b.Q5_K_M.gguf)を出力します。そのパスでファイルが配置されていることが確認され、推論構成に直接コピーできるようになります。
WindowsのCmd
python download_model.py
ダウンロードしたモデルへのパス
Downloaded to: C:\Users\BTA24\.cache\huggingface\hub\…\stablelm-zephyr-3b.Q5_K_M.gguf
手順3:Conda環境の作成と有効化
conda create -n ai-env python=3.12 -y conda activate ai-env
手順4:Pythonの依存関係をインストールする
AIサーバー環境が有効になっている状態で、コマンド「pip install llama-cpp-python fastapi uvicorn」(または「conda install -c conda-forge llama-cpp-python」)を実行してコアライブラリをインストールします。llama-cpp-pythonは、高性能なC++推論エンジンをラップするバインディングで、GGUFモデルの読み込みおよび実行に必要です。一方、FastAPIとUvicornはそれぞれ非同期Webフレームワークとサーバーを提供し、洞察生成用のエンドポイントを公開することができます。これらのパッケージを組み合わせることで、ローカルAI推論サービスの基盤を構築することが可能です。
conda install -c conda-forge llama-cpp-python fastapi uvicorn -y
手順5:FastAPIサーバースクリプトを書く
プロジェクトフォルダ内に新しいファイル(例:server.py)を作成し、FastAPIとllama_cppからLlamaをインポートします。グローバルスコープで、ダウンロード済みのGGUFモデルのパスを指定してLlamaクラスをインスタンス化します。次に、「/insights」というPOSTエンドポイントを定義します。このエンドポイントはJSON形式のリクエストボディ(「prompt」文字列を含む)を受け取り、llm.create()または同等のメソッドを呼び出してテキストを生成し、insightフィールドを含むJSON形式でレスポンスを返すように設定します。わずか数行のコードで、プロンプトを受け取りモデルの出力を返すRESTful AIサービスを構築できるようになります。
# serve_insights.py from fastapi import FastAPI, Request from llama_cpp import Llama MODEL_PATH = r"C:\Users\BTA24\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b-GGUF\snapshots\<snapshot-id>\stablelm-zephyr-3b.Q5_K_M.gguf" llm = Llama(model_path=MODEL_PATH, n_threads=4, n_ctx=512) app = FastAPI() @app.post("/insights") async def insights(req: Request): data = await req.json() prompt = data.get("prompt", "") out = llm(prompt, max_tokens=64) text = out["choices"][0]["text"].strip() return {"insight": text}
手順6:推論サーバーを起動する
引き続きAnaconda Prompt上で作業し、プロジェクトディレクトリに移動しUvicornを起動します。FastAPIアプリを指定し、auto-reloadを有効にすることで、スクリプトの変更を即座に反映できます。また、ポート8000で外部からのリクエストを受け付けるよう設定します。
server.pyがあるフォルダにcdして以下を実行します。
cd "C:\Users\YOUR_COMPUTER_NAME\PATH_TO_YOUR python serve insights file"
入ったら、サーバーを実行します。
uvicorn serve_insights:app --host 0.0.0.0 --port 8000 --reload
手順7:エンドポイントのスモークテスト
任意のターミナルから、簡単なPOSTリクエストをhttp://localhost:8000/insightsに送信します。リクエストボディはJSON形式で、テスト用のpromptを含めます。サーバーが正しく動作していれば、レスポンスとしてinsightフィールドを含む有効なJSONが返ってきます。
curl -X POST http://localhost:8000/insights \ -H "Content-Type: application/json" \ -d '{"prompt":"One-sentence FX signal for EUR/USD."}'
成功した応答は次のようになります。
{"insight":"Be mindful of daily open volatility…"}
手順8:MQL5 EAに統合する
AIサーバーの起動と動作確認が完了したら、再びMQL5のEAに戻り、前回の作業の続きを行います。今回、EAにAI‑Insightsエンドポイントを統合し、チャート上に専用の「AI Insights」レーンを追加します。統合後は、EAが設定された間隔でローカルの「/insights」エンドポイントを呼び出し、返却されるJSONを解析して、ニュースやインジケーターで使用しているスムーズスクロールの仕組みに組み込むことができます。次のセクションでは、完全なコード統合をステップごとに解説し、エンドツーエンドでAIを活用した取引ツールを完成させる手順をご紹介します。
AI InsightsをMQL5に統合する: News Headline EAの強化
前回の記事を読んだことを前提として、今回はEAに新しいAI‑Insights機能を統合する方法に焦点を当てます。以下の手順では、必要なコード追加箇所を一つずつ解説し、残りのEAコードには手を加えずに進めます。そして最後に、更新済みの完全なEAコードを提供します。
1. 入力パラメータの拡張
まず、既存の入力パラメータに加えて3つの新しい入力パラメータを追加します。ブール値でAI Insightsレーンのオン/オフを切り替えられるようにし、文字列でFastAPIまたは他のAIエンドポイントのURLを指定し、整数で連続するPOSTリクエストの間隔(秒)を設定します。これにより、EAのコアコードを触ることなく、AI Insightsレーンの切り替えやサーバーの指定、更新間隔の調整をインタラクティブに試すことができます。
//--- 1) USER INPUTS ------------------------------------------------ input bool ShowAIInsights = true; input string InpAIInsightsURL = "http://127.0.0.1:8000/insights"; input int InpAIInsightsReloadSec = 60; // seconds between requests
2. 共有グローバルの宣言
次に、AIデータを保持・管理するためのグローバル変数を導入します。現在のインサイトテキストを1つの文字列として保持し、その水平方向のオフセットを整数で追跡することで、各フレームごとにスクロールできるようにします。さらに、リクエストの重複送信を防ぐためのフラグを追加し、最後に正常に取得できた時刻のタイムスタンプも記録します。これらのグローバル変数によって、常に描画する内容を保持し、次の呼び出しをおこなう正確なタイミングを把握し、HTTPリクエストの競合を防ぐことができます。
//--- 3) GLOBALS ----------------------------------------------------- string latestAIInsight = "AI insights coming soon…"; int offAI; // scroll offset bool aiRequestInProgress = false; // prevent concurrent POSTs datetime lastAIInsightTime = 0; // last successful fetch time
3. FetchAIInsights()の構築
HTTP処理のすべてを1つの関数にカプセル化します。関数内ではまず、トグル状態とクールダウン時間を確認します。AIレーンが無効になっている場合、あるいは直前にデータを取得したばかり(または前回のリクエストがまだ処理中)の場合は、そのまま何もせずにリターンします。条件を満たしていれば、最小限のJSONペイロード(たとえば現在の銘柄などを含む)を作成し、WebRequest("POST")を送信します。リクエストが成功した場合は、JSONレスポンスからinsightフィールドを抽出し、それを使ってグローバルのテキストとタイムスタンプを更新します。万が一エラーが発生した場合は、以前のインサイトをそのまま保持するようにし、スクロール中のレーンが空白にならないようにします。
void FetchAIInsights() { if(!ShowAIInsights || aiRequestInProgress) return; datetime now = TimeTradeServer(); if(now < lastAIInsightTime + InpAIInsightsReloadSec) return; aiRequestInProgress = true; string hdrs = "Content-Type: application/json\r\n"; string body = "{\"prompt\":\"Concise trading insight for " + Symbol() + "\"}"; uchar req[], resp[]; string hdr; StringToCharArray(body, req); int res = WebRequest("POST", InpAIInsightsURL, hdrs, 5000, req, resp, hdr); if(res > 0) { string js = CharArrayToString(resp,0,WHOLE_ARRAY); int p = StringFind(js, "\"insight\":"); if(p >= 0) { int start = StringFind(js, "\"", p+10) + 1; int end = StringFind(js, "\"", start); if(start>0 && end>start) latestAIInsight = StringSubstr(js, start, end-start); } lastAIInsightTime = now; } aiRequestInProgress = false; }
4.OnInit()でキャンバスをシードする
初期化ルーチンでは、他のキャンバスをすべて設定した後に、AIキャンバスも作成します。 このキャンバスには、既存のレーンと同じサイズを与え、半透明の背景を設定します。そして、位置を既存のレーンのすぐ下に配置します。データがまだ返ってきていない段階では、「AI insights coming soon…」のようなフレンドリーなプレースホルダーを描画して、チャート全体が未完成に見えないようにします。最後に、FetchAIInsights()を一度即座に呼び出します。これにより、たとえ途中からセッションを開始した場合でも、最初のネットワーク呼び出しが完了した時点で実際のコンテンツが表示されることが保証されます。
int OnInit() { // … existing init … // AI Insights lane if(ShowAIInsights) { aiCanvas.CreateBitmapLabel("AiC", 0, 0, canvW, lineH, COLOR_FORMAT_ARGB_RAW); aiCanvas.TransparentLevelSet(120); offAI = canvW; SetCanvas("AiC", InpPositionTop, InpTopOffset + (InpSeparateLanes ? 8 : 5) * lineH); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); aiCanvas.Update(true); // initial fetch FetchAIInsights(); } EventSetMillisecondTimer(InpTimerMs); return INIT_SUCCEEDED; }
5. OnTimer()での更新とスクロール
タイマーの各ティックごとに、イベント、ニュース、インジケーターなどを再描画していますが、そのすぐ後にAI関連の処理ステップを挿入します。まずFetchAIInsights()を呼び出します(クールダウン中であれば静かにスキップします)。次に、AIキャンバスを消去し、最新のインサイトテキストを現在のオフセット位置に描画します。その後、オフセット値をデクリメントして、テキストが左方向にスムーズにスクロールするようにします。テキストが画面外に出たら、オフセットをループさせて再度右端に戻します。最後にUpdate(true)を呼び出して、描画内容を即座に反映させます。その結果、滑らかにスクロールするAIメッセージが表示され、許可されたタイミングでのみネットワーク更新がおこなわれるという、スムーズなアニメーションと効率的な通信制御を両立した仕上がりになります。
void OnTimer() { // … existing redraw for events/news/indicators … // fetch & draw AI lane FetchAIInsights(); if(ShowAIInsights) { aiCanvas.Erase(ARGB(120,0,0,0)); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); offAI -= InpAIInsightsSpeed; if(offAI + aiCanvas.TextWidth(latestAIInsight) < -20) offAI = canvW; aiCanvas.Update(true); } }
6. OnDeinit()でのクリーンアップ
EAをアンロードするときは、すべてをきれいに片付けます。まずタイマーを停止し、AIキャンバスを破棄・削除します(存在する場合のみ)。その後、既存のキャンバスやイベント配列、動的オブジェクトに対するクリーンアップ処理を順に実行します。これにより、EAを再ロードや再デプロイしても、常にクリーンな状態から開始できるようになります。
void OnDeinit(const int reason) { EventKillTimer(); // … existing cleanup … if(ShowAIInsights) { aiCanvas.Destroy(); ObjectDelete(0, "AiC"); } }
統合のテスト
統合が完了したので、更新済みのEAをMetaTrader 5に読み込み、リアルタイムでの動作を確認します。バックグラウンドでAIサーバーを起動しておくことを忘れないでください。現状では、EA自身からサーバーを自動起動できるかどうかはまだ検証中です。下のスクリーンショットでは、他のレーンの下に配置された新しい「AI Insights」レーンが表示され、ライブのインサイトテキストを確認できます。
色の設定はコード内で簡単に調整可能です。今回のデモではデフォルトのまま使用しています。スクロールに時折一瞬の停止が見られますが、これは現行のフェッチタイミングによるもので、今後の改良で最適化予定です。エンドツーエンドのAI機能が稼働したところで、次はサーバーサイドの実装を確認し、バックエンドがどのようにインサイトを生成しているかを理解します。

ローカルホストモデルからのAI主導の市場洞察を特集するNews Headline EA
下のスニペットは、Uvicornが「/insights」エンドポイントを提供している状態のものです。これらのログから以下のことが分かります。
- モデルが正常に読み込まれ、推論エンジンが準備完了している。
- Uvicornが起動しており、HTTPサーバーがリクエストを受け付けている。
- EAからのWebRequestがサーバーに届き、新しい推論サイクルがトリガーされた。
下記では、テスト中に記録した5回の推論サイクルを確認できます。各サイクルはEAからの1回のPOSTリクエストに対応しています。 この後、1つの推論サイクルを詳細に追い、裏側で何が起きているかをステップごとに説明します。
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 83.42 ms / 64 runs ( 1.30 ms per token, 767.19 tokens per second) llama_print_timings: prompt eval time = 1890.97 ms / 6 tokens ( 315.16 ms per token, 3.17 tokens per second) llama_print_timings: eval time = 32868.44 ms / 63 runs ( 521.72 ms per token, 1.92 tokens per second) llama_print_timings: total time = 35799.69 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 51.40 ms / 64 runs ( 0.80 ms per token, 1245.21 tokens per second) llama_print_timings: prompt eval time = 1546.64 ms / 4 tokens ( 386.66 ms per token, 2.59 tokens per second) llama_print_timings: eval time = 29878.89 ms / 63 runs ( 474.27 ms per token, 2.11 tokens per second) llama_print_timings: total time = 32815.26 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 65.92 ms / 64 runs ( 1.03 ms per token, 970.80 tokens per second) llama_print_timings: prompt eval time = 1841.83 ms / 6 tokens ( 306.97 ms per token, 3.26 tokens per second) llama_print_timings: eval time = 31295.30 ms / 63 runs ( 496.75 ms per token, 2.01 tokens per second) llama_print_timings: total time = 34146.43 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 55.34 ms / 64 runs ( 0.86 ms per token, 1156.42 tokens per second) llama_print_timings: prompt eval time = 1663.61 ms / 4 tokens ( 415.90 ms per token, 2.40 tokens per second) llama_print_timings: eval time = 29311.62 ms / 63 runs ( 465.26 ms per token, 2.15 tokens per second) llama_print_timings: total time = 31952.19 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Anacondaプロンプト内のモデルとWebRequestの動作を理解します。
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
FastAPI+UvicornサーバーがGGUFモデルをロードすると、llama-cppは約206秒のロード時間を報告します。これは、量子化されたモデル全体をメモリに読み込み初期化する際の一度きりのコストです。その後、/insightsへの各HTTP POSTは、おおよそ次の手順で処理されます。
プロンプト評価(プロンプト評価時間)
llama-cppは、モデルのtransformerスタックを通してプロンプトの最初の数トークンを処理し、生成の準備をおこないます。このログでは4トークンの処理に1.49秒かかっており、1トークンあたり約372msです。
トークン生成(評価時間 + サンプル時間)
- 以降の各トークン生成では、ライブラリは以下を実行します。
- 評価:Transformerの順伝播計算(1トークンあたり約469ms→約2.13トークン/秒)
- サンプリング:nucleus/top‑kなどの手法で次のトークンを選択(1トークンあたり約0.91ミリ秒)
- この実行例では63トークンの生成で、評価に約29.6秒、サンプリングに58ミリ秒かかっています。
合計レイテンシ(合計時間)
プロンプト評価+トークン評価+サンプリングを合計すると、モデルが計算を開始してから最終テキストが返るまで約31.98秒です。
生成が完了すると、Uvicornのログには以下のような情報が記録されます。
INFO: 127.0.0.1:52770 - "POST /insights HTTP/1.1" 200 OK
つまり、このログはサーバーがEAからの「WebRequest("POST","http://127.0.0.1:8000/insights",…)」を受信し、処理したうえで、200ステータスのJSONペイロード(「insight」を含む)を返したことを示しています。
最後の行は、llama-cppがキャッシュ内で繰り返し出現するトークン列(プレフィックス)を認識し、そのレイヤーの再計算をスキップしたため、生成がわずかに高速化されたことを意味します。
Llama.generate: prefix-match hit
テスト中、EAのレーンスクロールに時折の一時停止が発生することに気づきました。原因は、タイマーループ内で直接FetchAIInsights()を呼び出していたことです。 この場合、EAのWebRequestがブロックされ、Uvicornがモデルの評価、トークン生成、サンプリング(約32秒)を完了してJSONを返すまで待機してしまっていました。
スクロールロジックとHTTP呼び出しを完全に分離して、テキストの描画と移動は、FetchAIInsights()を呼び出す前に20ミリ秒ごとに更新すると、UIレーンは途切れずアニメーションを続行しました。重い推論処理はサーバーサイドで実行され、完了時にlatestAIInsightを更新します。
結論
今回の演習を通して、MQL5は外部サービスと組み合わせることで非常に拡張性が高いことが示されました。Alpha Vantageからライブ経済カレンダーやニュースを取得したり、自宅ホストの4ビットAIモデルでチャートにAIノートを追加したりと、多様な情報を統合することが可能です。これらのAIインサイトはリアルタイムデータや専門家による取引システムの代替にはなりませんが、オンデマンドでの定性的なコメントやブレインストーミングのきっかけを提供し、新しいアイデアを生み出す助けとなります。
その過程で、Hugging Faceの利用に慣れ、MSYS2、Git Bash、Minicondaを使ってモデルを取得したり、サーバーを設定したり、隔離環境を管理する方法を学びました。また、Python(モデル推論、FastAPI)とMQL5(チャート統合)という2つの言語を橋渡しすることで、プログラミングのツールボックスを広げ、多様なエコシステムが連携できることを実証しました。読者の皆さんも、ぜひ実験をおこない、コメント欄でフィードバックを共有してください。
今後の展望としては、MetaTrader 5のリアルタイムの価格データやインジケーター値をAIプロンプトに入力し、文脈や関連性を高めることが考えられます。異なる量子化フォーマットを試したり、ゼロダウンタイムでの自動デプロイを行ったり、複数ノードに推論を分散させることも可能です。より大きなモデルにアップグレードし、ハードウェアを強化すれば、より豊かで細やかなインサイトを得られますが、控えめなセットアップでも十分に強力でインタラクティブな取引支援を提供できます。アルゴリズム取引と自宅ホストAIの交差点はまだ広く開かれており、次のブレイクスルーはトレーダーと市場の関わり方を再定義するかもしれません。
以下にサポートファイルを添付しています。それぞれのファイルの目的がわかるよう、簡単な説明をまとめた表も用意しました。
重要な学び
| 学び | 説明 |
|---|---|
| 環境分離 | Condaやvirtualenvを使ってPython環境を隔離し、FastAPIやllama‑cpp‑pythonなどの依存関係を分離や再現可能に保ちます。 |
| ローカルキャッシュ | Hugging Face Hubクライアント経由で大きなGGUFモデルファイルを一度ダウンロードしてキャッシュし、ネットワーク転送の繰り返しを避け、サーバー起動を高速化します。 |
| レート制限 | AIリクエストに最小間隔(例:300秒)のスロットルを設け、EAがサーバーを圧迫したり過剰な推論負荷をかけたりしないようにします。 |
| エラー耐性のある解析 | JSONデコードをエラーハンドリングでラップし、最初の有効なオブジェクトのみを抽出して、EAが壊れたレスポンスや余分なデータで停止しないようにします。 |
| キャンバスのダブルバッファリング | 各描画サイクル後にCanvas.Update(true)を呼び出して変更を確定させ、ちらつきを防ぎ、チャートアニメーションを滑らかに保ちます。 |
| タイマー駆動ループ | すべてのスクロールやデータ更新を単一のミリ秒タイマー(例:20ミリ秒)で駆動し、アニメーションの滑らかさとCPU負荷のバランスを取ります。 |
| WebRequestとの統合 | MQL5のWebRequestでローカルAIサーバーにJSONをPOSTしインサイトを取得する際、ターミナルオプションでURLを許可リストに登録します。 |
| 多様性のためのランダム化 | プロンプトを変えたり通貨ペアをランダムに選んだりして、AIリクエストごとに多様で反復の少ない取引インサイトを生成します。 |
| リソースのクリーンアップ | OnDeinitで全Canvasオブジェクトを破棄し、動的配列を削除し、タイマーを停止してメモリリークや孤立したチャートオブジェクトを防ぎます。 |
| モジュラー設計 | コードを明確な関数(ReloadEvents、FetchAlphaVantageNews、FetchAIInsights、DrawLane)に整理して可読性と保守性を向上させます。 |
| シェルの柔軟性 | GitやスクリプトにはGit Bash、POSIXツールやビルドにはMSYS2、Python環境にはConda Prompt、簡易操作にはCMDを活用します。 |
| 量子化モデルホスティング | ローカルで量子化されたGGUFモデルをホスティングし、フル精度ウェイトよりもメモリ使用量と推論レイテンシを低減します。 |
| サーバーとクライアントの分離 | 重い推論処理はFastAPI/Uvicornサーバーでおこない、EAは軽量のままUI更新とHTTPリクエストのみを担当させます。 |
| 描画と処理の分離 | ネットワーク関数を呼ぶ前に必ずスクロールと描画をおこない、長時間のリクエスト中もUIの応答性を維持します。 |
| プロンプトエンジニアリング | 簡潔でターゲットを絞ったJSONプロンプト(例:「Insight for EURUSD today」)を作成し、プロンプト評価時間を最小化してモデル出力を集中させます。 |
| サンプリング戦略 | FastAPIアプリ内でtop‑k、top‑p、temperatureなどのサンプリングパラメータを調整し、生成インサイトの創造性と一貫性のバランスを取ります。 |
| 非同期エンドポイント | FastAPIのasync defハンドラを使用して、Uvicornが長時間実行の推論にブロックされずにEAリクエストを並列処理できるようにします。 |
| ロギングと可観測性 | EAとサーバーの両方でタイムスタンプやログレベルを記録(例:llama_print_timingsやEAコンソール出力)し、パフォーマンス問題を診断します。 |
| パフォーマンス指標 | リクエストレイテンシ、トークン毎秒、モデル読み込み時間などの指標(例:Prometheus経由)を公開し、システムパフォーマンスを監視し、最適化します。 |
| フォールバック戦略 | WebRequestが失敗したりサーバーがダウンした場合、EAに「insight unavailable」のデフォルトメッセージを表示し、UIの安定性を維持します。 |
添付ファイル
| ファイル名 | 説明 |
|---|---|
| News Headline EA.mq5 | MetaTrader 5用のEAスクリプト。経済カレンダーイベント、Alpha Vantageニュース、チャート上インジケーター(RSI、ストキャスティクス、MACD、CCI)のスクロールレーンを描画し、さらにレート制御されたAI駆動の市場シグナルレーンも表示します。 |
| download_model.py | Hugging Face Hubクライアントを使用して4ビットGGUF量子化StableLM-Zephyrモデルを取得しキャッシュするスタンドアロンPythonスクリプト。サーバー設定時に参照するため、ローカルパスを出力します。 |
| serve_insights.py | llama‑cpp‑python経由でキャッシュ済みGGUFモデルをロードするFastAPIアプリケーション。POST /insightsエンドポイントを公開し、JSONプロンプトを受け取り推論を実行し、生成された市場インサイトを返します。 |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/18685
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索