
Vom Neuling zum Experten: Animierte Nachrichten-Schlagzeile mit MQL5 (IV) – Markteinsichten durch lokal verfügbare KI-Modelle

Inhalt:
- Einführung
- Übersicht
- Einrichten und Hosten eines AI-Modells vor Ort
- Integration von KI-Insights in MQL5: Verbesserung des News Headline EA
- Testen der Integration
- Schlussfolgerung
- Wichtige Lektionen
- Anhänge
Einführung
In dieser Diskussion gehen wir der Frage nach, wie wir Open-Source-KI-Modelle nutzen können, um unsere algorithmischen Handelswerkzeuge zu verbessern - insbesondere, wie wir den News Headline EA mit einem AI Info-Streifen erweitern können. Ziel ist es, Neueinsteigern eine solide Ausgangsbasis zu bieten. Wer weiß? Heute integrieren Sie vielleicht ein Modell, morgen bauen Sie vielleicht eines. Aber alles beginnt damit, dass wir die Grundlagen verstehen, die von denen gelegt wurden, die vor uns kamen.
Wir können kein Gespräch über moderne Fortschritte führen, ohne künstliche Intelligenz und ihren schnell wachsenden Einfluss auf menschliche Aufgaben zu erwähnen. Wenn es um den algorithmischen Handel geht, wird die Diskussion sogar noch relevanter - der Handel wird bereits von Zahlen und Automatisierung angetrieben, sodass KI im Vergleich zu anderen Bereichen, die noch eine Abkehr von manuellen Prozessen erfordern, eine natürliche Ergänzung darstellt.
KI-Modelle haben sich in verschiedenen Bereichen zu leistungsfähigen Werkzeugen entwickelt, doch nicht jeder hat die Ressourcen oder das Fachwissen, um eigene Modelle zu entwickeln, da die Entwicklung voll funktionsfähiger Systeme sehr komplex ist. Glücklicherweise hat das Aufkommen von Open-Source-Initiativen es möglich gemacht, kostenlos auf bereits trainierte Modelle zuzugreifen und von ihnen zu profitieren. Diese von der Gemeinschaft getragenen Bemühungen bieten einen praktischen Einstieg für viele Entwickler und Enthusiasten.
Allerdings bieten Premium-Modelle aufgrund des hohen Arbeitsaufwands, der in sie investiert wird, oft einen größeren Funktionsumfang. Dennoch sind Open-Source-Modelle ein wertvoller Ausgangspunkt, insbesondere für diejenigen, die KI integrieren möchten, ohne das Rad neu zu erfinden.
In der vorangegangenen Diskussion haben wir uns auf Indicator Insights konzentriert. Heute werden wir untersuchen, wie man Open-Source-KI für den algorithmischen Handel nutzen kann, indem wir ein quantisiertes Sprachmodell selbst hosten und es direkt in einen MQL5 Expert Advisor integrieren. Im nächsten Abschnitt beginnen wir mit einer kurzen Einführung in die Rolle von llama.cpp (der leichtgewichtigen Inferenz-Engine) und einem 4-Bit-GGUF-Modell (dem komprimierten „Gehirn“), gehen dann durch das Herunterladen und Vorbereiten des Modells, das Einrichten eines lokalen Python-basierten Inferenz-Servers mit FastAPI und schließlich das Einbinden in den News Headline EA, um einen dynamischen AI Info-Streifen zu erstellen.
Auf dem Weg dorthin werden wir wichtige Entscheidungen hervorheben, häufige Hindernisse aus dem Weg räumen und einen einfachen Smoke-Test demonstrieren - alles mit dem Ziel, Ihnen einen klaren, durchgängigen Plan für das Hinzufügen von Echtzeit-KI-Kommentaren zu Ihrem Handelsworkflow zu geben.
Übersicht
Für dieses Projekt verwenden wir eine 64-Bit Intel Core i7-8550U CPU (1,80-1,99 GHz) mit 8 GB RAM. In Anbetracht dieser Hardware-Einschränkungen haben wir uns für ein leichtgewichtiges 4-Bit-GGUF-Modell entschieden, insbesondere für stablelm-zephyr-3b.Q5_K_M.gguf, um eine effiziente Lade- und Inferenzleistung auf unserem System zu gewährleisten. Später werde ich die empfohlenen Hardware-Spezifikationen, die für Projekte dieser Art geeignet sind, zusammen mit den Upgrade-Plänen zur Unterstützung größerer und anspruchsvollerer KI-Modelle in der Zukunft vorstellen.
Bevor wir fortfahren, ist es wichtig, sich mit den wichtigsten Komponenten und Hardwareanforderungen vertraut zu machen, die für einen reibungslosen Ablauf dieses Projekts erforderlich sind. Zu Ausbildungszwecken arbeiten wir mit bescheidenen Spezifikationen, aber wenn Sie Zugang zu leistungsfähigerer Hardware haben, können Sie diese gerne nutzen. Ich werde auch Hinweise auf geeignete Modelle und empfohlene Spezifikationen für leistungsstärkere Systeme geben.
Verstehen von „Hugging Face“
„Hugging Face“ ist eine Plattform, auf der Tausende von vortrainierten Machine-Learning-Modellen (NLP, Vision, Sprache usw.) zusammen mit Datensätzen, Evaluierungsmetriken und Entwickler-Tools gehostet werden, die über das Internet oder die Python-Bibliothek huggingface_hub zugänglich sind. Es vereinfacht die Modellsuche, die Versionierung und die Verwaltung großer Dateien (Git LFS) und bietet sowohl kostenlose Optionen für das Selberhosten als auch eine verwaltete Inferenz-API für skalierbare Implementierungen. Mit umfassender Dokumentation, Community-Support und nahtloser Integration mit Frameworks wie PyTorch und TensorFlow ermöglicht Hugging Face jedem, schnell modernste KI-Modelle zu finden, herunterzuladen und in seinen Anwendungen auszuführen.
Hardware-Anforderungen
Für ein 4-Bit-GGUF-Modell mit 3 B-Parametern, das auf llama-cpp-python läuft, benötigen Sie mindestens:
- CPU: 4-Core/8-Thread (z. B. Intel i5/i7 oder AMD Ryzen 5/7) für Inferenzen im Sekundenbereich pro Token.
- RAM: ~6-8 GB frei, um das ~1,9 GB große quantisierte Modell zu laden, plus Arbeitsspeicher.
- Speicher: SSD mit ≥3 GB frei für den Modell-Cache (~1,9 GB) und OS-Overhead.
- Netzwerk: Localhost-Anrufe - keine externe Bandbreite erforderlich.
Aufrüstung der Spezifikationen
- Größere Modelle: Gehen Sie zu Modellen mit 7 B-Parametern oder 13 B-Parametern (quantisiert) über, aber planen Sie 12 GB+ und stärkere CPUs oder GPUs ein.
- GPU-Beschleunigung: Verwenden Sie NVIDIA-GPUs mit CUDA/cuBLAS und dem llama-cpp GPU-Backend oder Frameworks wie Triton/ONNX für 10-fache Beschleunigung.
- Horizontale Skalierung: Containerisierung (Docker) oder Bereitstellung in Kubernetes-Clustern zum Lastausgleich mehrerer Inferenz-Pods - ideal für hohe Durchsatzraten oder Konfigurationen für mehrere Nutzer.
- Cloud-GPUs/TPUs: Umstellung auf AWS/GCP/Azure-Instanzen (z. B. A10G, A100) für Modelle >13 B-Parameter oder Echtzeit-SLAs.
Software-Anforderungen:
Unser Arbeitsablauf verwendet mehrere sich ergänzende Shells und Umgebungen, um die Entwicklung und das Testen zu optimieren:
- Git Bash ist unsere erste Wahl, wenn es um das Abrufen und die Versionskontrolle von Code geht - verwenden Sie es, um das Hugging Face Repo mit git zu klonen, python download_model.py auszuführen (sobald Ihr bevorzugtes Python auf dem PATH steht) und sogar schnelle Smoke-Tests zu starten, wenn Sie die Bash-Syntax bevorzugen. Wir können die Windows-Eingabeaufforderung oder andere Shells für den gleichen Vorgang verwenden.
- MSYS2 gibt uns eine vollständige POSIX-Schicht unter Windows – sobald das Modell steht, können wir in MSYS2 bleiben und curl (oder httpie) gegen http://localhost:8000/insights laufen lassen, um zu überprüfen, ob unser FastAPI-Endpunkt funktioniert und JSON zurückgibt.
- Anaconda Prompt erstellen und aktivieren wir unsere ai-server Conda-Umgebung (python=3.12), installieren die Pakete llama-cpp-python, FastAPI und Uvicorn, und starten schließlich uvicorn server:app --reload --port 8000.
Im Folgenden finden Sie ein BlockChart, das als Vorlage für die Prozesse dient, die wir in dieser Diskussion behandeln werden.
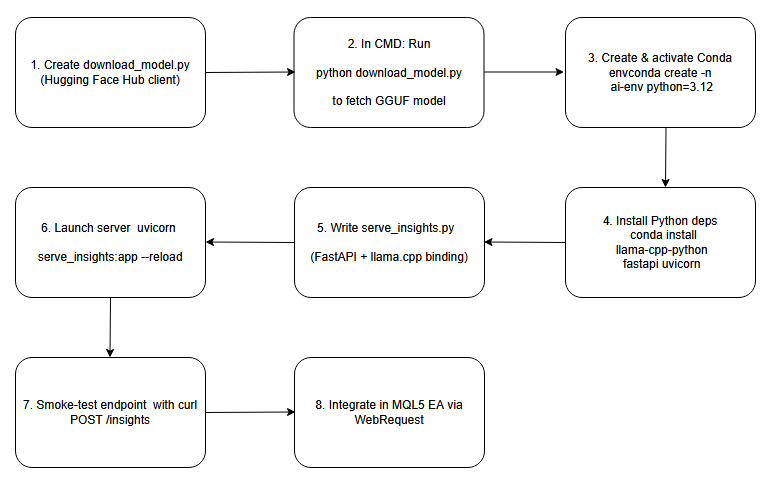
Das Flussdiagramm.
Einrichten und Hosten eines AI-Modells vor Ort
Schritt 1: Erstellen des Download-Skripts
Zu Beginn schreiben wir ein kleines Python-Skript, das den Client von Hugging Face Hub nutzt. In diesem Skript geben wir den Namen des Repository an (z. B. „TheBloke/stablelm-zephyr-3b.Q5_K_M.gguf“) und rufen hf_hub_download() auf, um die quantisierte GGUF-Datei in unseren lokalen Cache zu ziehen. Indem wir den zurückgegebenen Dateipfad ausdrucken, erhalten wir einen zuverlässigen, maschinenlesbaren Verweis darauf, wo sich das Modell jetzt auf der Festplatte befindet. Dieser Ansatz automatisiert den Download und stellt sicher, dass Sie den genauen Cache-Speicherort kennen – eine wichtige Voraussetzung für die Konfiguration von nachgelagertem Inferenzcode, ohne unvorhersehbare Verzeichnisse fest zu codieren.
# download_model.py from huggingface_hub import hf_hub_download # Download the public 4-bit GGUF model; no Hugging Face account required model_path = hf_hub_download( repo_id = "TheBloke/stablelm-zephyr-3b-GGUF", filename = "stablelm-zephyr-3b.Q5_K_M.gguf", repo_type = "model" ) print("Downloaded to:", model_path)
Schritt 2: Ausführen des Download-Skripts
Öffnen Sie dann eine einfache Windows-Eingabeaufforderung und wechseln Sie in das Verzeichnis, das Ihr Download-Skript enthält (z. B. download_model.py). Wenn Sie python download_model.py ausführen, verbindet sich der Client von Hugging Face über HTTPS, lädt die GGUF-Gewichte in seinen Cache und gibt den vollständigen Pfad aus (etwa C:\Users\You\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b.Q5_K_M\...\stablelm-zephyr-3b.Q5_K_M.gguf). Wenn Sie diesen Pfad sehen, wird bestätigt, dass die Datei vorhanden ist, und Sie können sie direkt in Ihre Inferenzkonfiguration kopieren.
Cmd in Windows:
python download_model.py
Pfad zum heruntergeladenen Modell:
Downloaded to: C:\Users\BTA24\.cache\huggingface\hub\…\stablelm-zephyr-3b.Q5_K_M.gguf
Schritt 3: Erstellen & Aktivieren einer Conda-Umgebung
conda create -n ai-env python=3.12 -y conda activate ai-env
Schritt 4: Installieren der Python-Abhängigkeiten
Wenn die Umgebung ai-server aktiv ist, verwenden Sie pip install llama-cpp-python fastapi uvicorn (oder conda install -c conda-forge llama-cpp-python, wenn Sie dies bevorzugen), um die Kernbibliotheken zu installieren. Die Llama-cpp-Python-Bindung umhüllt die leistungsstarke C++-Inferenzmaschine, die zum Laden und Ausführen Ihres GGUF-Modells benötigt wird, während FastAPI und Uvicorn ein asynchrones Web-Framework bzw. einen Server bereitstellen, um Endpunkte für die Generierung von Erkenntnissen bereitzustellen. Zusammen bilden diese Pakete das Rückgrat Ihres lokalen KI-Inferenzdienstes.
conda install -c conda-forge llama-cpp-python fastapi uvicorn -y
Schritt 5: Schreiben des FastAPI-Server-Skripts
Erstellen Sie in Ihrem Projektordner eine neue Datei (z.B. server.py) und importieren Sie FastAPI und Llama aus llama_cpp. Im globalen Bereich instanziieren Sie die Llama-Klasse mit dem Pfad zu Ihrer heruntergeladenen GGUF-Datei. Definieren Sie dann einen POST-Endpunkt unter /insights, der einen JSON-Textkörper (mit einer „Prompt“-Zeichenfolge) akzeptiert, llm.create() oder ein Äquivalent aufruft, um Text zu erzeugen, und eine JSON-Antwort mit einem „insight“-Feld zurückgibt. Mit nur wenigen Zeilen haben Sie nun einen RESTful-KI-Dienst, der bereit ist, Eingabeaufforderungen zu empfangen und Modellausgaben zurückzusenden.
# serve_insights.py from fastapi import FastAPI, Request from llama_cpp import Llama MODEL_PATH = r"C:\Users\BTA24\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b-GGUF\snapshots\<snapshot-id>\stablelm-zephyr-3b.Q5_K_M.gguf" llm = Llama(model_path=MODEL_PATH, n_threads=4, n_ctx=512) app = FastAPI() @app.post("/insights") async def insights(req: Request): data = await req.json() prompt = data.get("prompt", "") out = llm(prompt, max_tokens=64) text = out["choices"][0]["text"].strip() return {"insight": text}
Schritt 6: Starten des Inferenzservers
Wechseln Sie in der Anaconda-Eingabeaufforderung in Ihr Projektverzeichnis und starten Sie Uvicorn, wobei Sie auf die FastAPI-App zeigen. Aktivieren Sie die automatische Neuladung, um Skriptänderungen sofort zu übernehmen und auf Port 8000 auf eingehende Anfragen zu warten.
Wechseln Sie in den Ordner, in dem sich server.py befindet, und führen Sie es aus:
cd "C:\Users\YOUR_COMPUTER_NAME\PATH_TO_YOUR python serve insights file"
Wenn das der Fall ist, starten Sie den Server:
uvicorn serve_insights:app --host 0.0.0.0 --port 8000 --reload
Schritt 7: Smoke-Test des Endpunkts
Senden Sie von einem beliebigen Terminal eine einfache POST-Anfrage an http://localhost:8000/insights mit einer Testaufforderung in JSON-Form. Überprüfen Sie, ob der Server mit einem gültigen JSON antwortet, das das Feld „insight“ enthält.
curl -X POST http://localhost:8000/insights \ -H "Content-Type: application/json" \ -d '{"prompt":"One-sentence FX signal for EUR/USD."}'
Eine erfolgreiche Antwort sieht so aus:
{"insight":"Be mindful of daily open volatility…"}
Schritt 8: Integration in Ihren MQL5 EA
Nachdem der KI-Server eingerichtet und überprüft wurde, ist es an der Zeit, zu unserem MQL5 Expert Advisor zurückzukehren und dort weiterzumachen, wo wir aufgehört haben. Wir werden den AI-Insights-Endpunkt in unseren EA integrieren, indem wir einen dedizierten Streifen „AI Info“ in den Chart einfügen. Nach der Integration ruft Ihr EA den lokalen /insights-Endpunkt im konfigurierten Intervall auf, parst das zurückgegebene JSON und speist den resultierenden Text in denselben Smooth-Scroll-Mechanismus ein, den Sie bereits für Nachrichten und Indikatoren verwenden. Im nächsten Abschnitt werden wir die vollständige Code-Integration Schritt für Schritt durchgehen, um ein vollständiges, durchgängiges KI-gestütztes Handelswerkzeug zu erstellen.
Integration von KI-Insights in MQL5: Verbesserung des News Headline EA
Wir gehen davon aus, dass Sie unseren vorherigen Artikel gelesen haben, und konzentrieren uns nun auf die Integration der neuen AI-Insights-Funktion in den EA. In den folgenden Schritten werde ich jede erforderliche Code-Ergänzung hervorheben und erläutern – während ich den Rest des EA unberührt lasse – und dann den vollständigen, aktualisierten EA-Code am Ende unserer Diskussion bereitstellen.
1. Ausweitung unserer Eingaben
Zunächst fügen wir drei neue Eingabeparameter zu den bestehenden hinzu. Wir fügen einen booleschen Wert ein, damit wir den AI Info-Streifen nach Belieben ein- oder ausschalten können, eine Zeichenkette, in die wir die URL für unsere FastAPI (oder eine andere AI) eingeben, und eine ganze Zahl, die festlegt, wie viele Sekunden zwischen aufeinanderfolgenden POST-Aufrufen vergehen müssen. Damit können wir interaktiv experimentieren – den Streifen umschalten, auf verschiedene Server zeigen oder die Aktualisierungsrate erhöhen oder verringern, ohne den Kerncode zu berühren.
//--- 1) USER INPUTS ------------------------------------------------ input bool ShowAIInsights = true; input string InpAIInsightsURL = "http://127.0.0.1:8000/insights"; input int InpAIInsightsReloadSec = 60; // seconds between requests
2. Deklarieren gemeinsamer globaler Variablen
Als Nächstes führen wir globale Variablen ein, um unsere KI-Daten zu speichern und zu verwalten. Der aktuelle Text wird in einer Zeichenkette gespeichert und sein horizontaler Versatz in einem Integer-Wert festgehalten, sodass wir ihn bei jedem Ticken verschieben können. Um sich überschneidende Anfragen zu vermeiden, fügen wir eine Markierung hinzu, die angibt, wann eine Webanfrage im Gange ist, und wir speichern den Zeitstempel des letzten erfolgreichen Abrufs. Diese globalen Variablen sorgen dafür, dass wir immer etwas zum Zeichnen haben, genau wissen, wann wir den nächsten Aufruf senden müssen, und verhindern, dass HTTP-Aufrufe in die falsche Richtung laufen.
//--- 3) GLOBALS ----------------------------------------------------- string latestAIInsight = "AI insights coming soon…"; int offAI; // scroll offset bool aiRequestInProgress = false; // prevent concurrent POSTs datetime lastAIInsightTime = 0; // last successful fetch time
3. Aufbau von FetchAIInsights()
Wir kapseln unsere gesamte HTTP-Logik in einer einzigen Funktion. Darin überprüfen wir zunächst unseren Toggle und das Ausklingen: Wenn der KI-Streifen deaktiviert ist oder wenn wir ihn zu früh abgerufen haben (oder eine frühere Anfrage noch anhängig ist), kehren wir einfach zurück. Andernfalls erstellen wir eine minimale JSON-Nutzlast – vielleicht einschließlich des aktuellen Symbols – und feuern ein WebRequest("POST") ab. Bei Erfolg wird das Feld „insight“ aus der JSON-Antwort ausgelesen und unser globaler Text und Zeitstempel aktualisiert. Wenn etwas schief geht, lassen wir die vorherige Einsicht intakt, sodass unsere Bildlaufstreifen nie leer wird.
void FetchAIInsights() { if(!ShowAIInsights || aiRequestInProgress) return; datetime now = TimeTradeServer(); if(now < lastAIInsightTime + InpAIInsightsReloadSec) return; aiRequestInProgress = true; string hdrs = "Content-Type: application/json\r\n"; string body = "{\"prompt\":\"Concise trading insight for " + Symbol() + "\"}"; uchar req[], resp[]; string hdr; StringToCharArray(body, req); int res = WebRequest("POST", InpAIInsightsURL, hdrs, 5000, req, resp, hdr); if(res > 0) { string js = CharArrayToString(resp,0,WHOLE_ARRAY); int p = StringFind(js, "\"insight\":"); if(p >= 0) { int start = StringFind(js, "\"", p+10) + 1; int end = StringFind(js, "\"", start); if(start>0 && end>start) latestAIInsight = StringSubstr(js, start, end-start); } lastAIInsightTime = now; } aiRequestInProgress = false; }
4. Seeding des Canvas in OnInit()
In unserer Initialisierungsroutine erstellen wir, nachdem wir alle anderen Canvas eingerichtet haben, auch die AI-Canvas. Wir geben ihm die gleichen Abmessungen und einen halbtransparenten Hintergrund und positionieren es direkt unter den vorhandenen Streifen. Bevor die Daten zurückgegeben werden, zeichnen wir einen freundlichen Platzhalter („AI insights coming soon...“), damit das Chart gut aussieht. Schließlich rufen wir FetchAIInsights() einmal sofort auf - so ist gewährleistet, dass, selbst wenn wir mitten in der Sitzung beginnen, echte Inhalte erscheinen, sobald der erste Netzwerkaufruf abgeschlossen ist.
int OnInit() { // … existing init … // AI Insights lane if(ShowAIInsights) { aiCanvas.CreateBitmapLabel("AiC", 0, 0, canvW, lineH, COLOR_FORMAT_ARGB_RAW); aiCanvas.TransparentLevelSet(120); offAI = canvW; SetCanvas("AiC", InpPositionTop, InpTopOffset + (InpSeparateLanes ? 8 : 5) * lineH); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); aiCanvas.Update(true); // initial fetch FetchAIInsights(); } EventSetMillisecondTimer(InpTimerMs); return INIT_SUCCEEDED; }
5. Aktualisieren und Blättern in OnTimer()
Bei jedem Timer-Tick werden Ereignisse, Nachrichten und Indikatoren bereits neu gezeichnet. Direkt danach fügen wir unsere KI-Schritte ein: FetchAIInsights() aufrufen (was stillschweigend nicht funktioniert, wenn die Abklingzeit noch nicht verstrichen ist), die KI-Leinwand löschen, die letzte Einsicht an ihrem aktuellen Offset zeichnen, diesen Offset für einen reibungslosen Bildlauf nach links dekrementieren, sie umdrehen, wenn sie den Bildschirm verlässt, und schließlich Update(true) aufrufen, um sie sofort zu löschen. Das Ergebnis ist eine wunderschön scrollende KI-Nachricht, die nur dann aktualisiert wird, wenn wir es erlaubt haben - eine Mischung aus sanfter Animation und kontrollierter Netznutzung.
void OnTimer() { // … existing redraw for events/news/indicators … // fetch & draw AI lane FetchAIInsights(); if(ShowAIInsights) { aiCanvas.Erase(ARGB(120,0,0,0)); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); offAI -= InpAIInsightsSpeed; if(offAI + aiCanvas.TextWidth(latestAIInsight) < -20) offAI = canvW; aiCanvas.Update(true); } }
6. Aufräumen in OnDeinit()
Wenn unser EA entladen ist, räumen wir alles auf. Wir beenden den Timer, zerstören und löschen die KI-Canvas (nur, wenn sie existiert) und führen dann unsere bestehenden Bereinigungen für die anderen Leinwände, Ereignis-Arrays und dynamischen Objekte durch. Auf diese Weise wird sichergestellt, dass wir keine Spuren hinterlassen, sodass ein erneutes Laden oder eine erneute Bereitstellung des EA immer mit einer sauberen Weste beginnt.
void OnDeinit(const int reason) { EventKillTimer(); // … existing cleanup … if(ShowAIInsights) { aiCanvas.Destroy(); ObjectDelete(0, "AiC"); } }
Testen der Integration
Nachdem wir nun die Integration abgeschlossen haben, können wir unseren aktualisierten Expert Advisor in MetaTrader 5 laden und seine Leistung in Echtzeit beobachten. Achten Sie darauf, dass der KI-Server im Hintergrund läuft – ich untersuche noch, ob wir ihn programmatisch vom EA selbst aus starten können. Auf dem Screenshot unten sehen Sie die neue AI Info-Streifen, die am unteren Rand der anderen Streifen verankert ist und Live-Info-Text anzeigt.
Sie können das Farbschema im Code leicht anpassen; für diese Demo haben wir es bei der Standardeinstellung belassen. Sie werden auch die gelegentliche, kurze Pause beim Scrollen bemerken – ein Artefakt unseres aktuellen Fetch-Timings, das wir in den nächsten Überarbeitungen noch verfeinern werden. Da die End-to-End-KI-Funktion nun einsatzbereit ist, werden wir uns als Nächstes der serverseitigen Implementierung zuwenden, um genau zu verstehen, wie das Backend diese Erkenntnisse ermöglicht.

Der News Headline EA mit KI-gesteuerten Markteinblicken durch ein lokal verfügbares Modell
Der folgende Ausschnitt stammt direkt aus der Anaconda-Eingabeaufforderung, in der Uvicorn unseren /insights-Endpunkt bedient. Aus diesen Protokollen lassen sich drei Dinge ablesen
- Das Modell wurde erfolgreich geladen, die Inferenzmaschine ist also bereit.
- Uvicorn läuft und lauscht, also ist der HTTP-Server in Betrieb.
- Der WebRequest unseres EA hat den Server erfolgreich erreicht und einen neuen Inferenzzyklus ausgelöst.
Nachfolgend habe ich fünf dieser Schlussfolgerungszyklen während des Tests aufgezeichnet – jeder entspricht einem einzelnen POST aus dem EA. Nach diesem Ausschnitt werde ich Ihnen einen dieser Zyklen im Detail erläutern, damit Sie genau sehen können, was hinter den Kulissen geschieht.
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 83.42 ms / 64 runs ( 1.30 ms per token, 767.19 tokens per second) llama_print_timings: prompt eval time = 1890.97 ms / 6 tokens ( 315.16 ms per token, 3.17 tokens per second) llama_print_timings: eval time = 32868.44 ms / 63 runs ( 521.72 ms per token, 1.92 tokens per second) llama_print_timings: total time = 35799.69 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 51.40 ms / 64 runs ( 0.80 ms per token, 1245.21 tokens per second) llama_print_timings: prompt eval time = 1546.64 ms / 4 tokens ( 386.66 ms per token, 2.59 tokens per second) llama_print_timings: eval time = 29878.89 ms / 63 runs ( 474.27 ms per token, 2.11 tokens per second) llama_print_timings: total time = 32815.26 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 65.92 ms / 64 runs ( 1.03 ms per token, 970.80 tokens per second) llama_print_timings: prompt eval time = 1841.83 ms / 6 tokens ( 306.97 ms per token, 3.26 tokens per second) llama_print_timings: eval time = 31295.30 ms / 63 runs ( 496.75 ms per token, 2.01 tokens per second) llama_print_timings: total time = 34146.43 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 55.34 ms / 64 runs ( 0.86 ms per token, 1156.42 tokens per second) llama_print_timings: prompt eval time = 1663.61 ms / 4 tokens ( 415.90 ms per token, 2.40 tokens per second) llama_print_timings: eval time = 29311.62 ms / 63 runs ( 465.26 ms per token, 2.15 tokens per second) llama_print_timings: total time = 31952.19 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Verstehen der Funktionsweise von Model und WebRequest in Anaconda Prompt:
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Wenn Ihr FastAPI-Uvicorn-Server das GGUF-Modell lädt, meldet llama-cpp eine „Ladezeit“ von etwa 206 Sekunden – das sind die einmaligen Kosten für das Lesen und Initialisieren des gesamten quantisierten Netzwerks im Speicher. Danach folgt jeder eingehende HTTP-POST an /insights ungefähr dieser Reihenfolge:
Prompt-Bewertung (Prompt-Bewertungszeit)
Hier lässt llama-cpp die ersten paar Token Ihrer Eingabeaufforderung durch den Transformatorstapel des Modells laufen, um die Generierung „vorzubereiten“. In diesem Protokoll dauerte es insgesamt 1,49 s für 4 Token, was etwa 372 ms pro Token entspricht.
Token-Generierung (Eval-Zeit + Sample-Zeit)
- Für jedes weitere Token, das sie erzeugt, tut die Bibliothek zwei Dinge:
- Eval: Sie berechnet den Vorwärtsdurchlauf des Transformators (≈ 469 ms pro Token, also ~2,13 Token /s).
- Sample: Sie wendet nucleus/top-k/etc-Sampling zur Auswahl des nächsten Tokens (≈ 0,91 ms pro Token) an.
- Der Lauf für die Generierung von 63 Token dauerte etwa 29,6 s für die Überprüfungen plus 58 ms für das Sampling aller Token.
Gesamte Latenzzeit (Gesamtzeit)
Die Summe aus Prompt-Evaluierung, allen Token-Evaluierungen und Sampling ergibt 31,98 s von dem Moment an, in dem das Modell mit der Berechnung beginnt, bis es den endgültigen Text zurückgibt.
Sobald die Generierung abgeschlossen ist, protokolliert Uvicorn etwas wie:
INFO: 127.0.0.1:52770 - "POST /insights HTTP/1.1" 200 OK
was bedeutet, dass der Server die WebRequest(“POST“, „http://127.0.0.1:8000/insights“, ...) Ihres EA empfangen, verarbeitet und eine JSON-Payload mit Status 200 zurückgegeben hat, die Ihren „Einblick“ enthält.
Schließlich zeigt die Zeile an, dass llama-cpp eine sich wiederholende Token-Sequenz (ein Präfix) in seinem Cache erkannt und die Neuberechnung dieser Ebenen übersprungen hat, wodurch die Generierung leicht beschleunigt wurde.
Llama.generate: prefix-match hit
Während des Tests bemerkte ich gelegentliche Pausen beim Scrollen der EA-Streifen. Es stellte sich heraus, dass der direkte Aufruf von FetchAIInsights() in der Timer-Schleife bedeutete, dass die WebRequest-Anfrage des EA blockiert und bis zum Timeout gewartet wurde, während Uvicorn die gesamte Modellbewertung, die Token-Generierung und den Sampling-Prozess (etwa 32 Sekunden) durchführte, bevor JSON zurückgegeben wurde.
Durch die vollständige Entkopplung der Bildlauflogik von unseren HTTP-Aufrufen – der Text wird alle 20 ms gezeichnet und verschoben, bevor FetchAIInsights() aufgerufen wird – kann die UI-Lane ohne Unterbrechung weiter animiert werden. In der Zwischenzeit läuft die schwergewichtige Inferenz auf dem Server, und erst wenn sie abgeschlossen ist, aktualisieren wir latestAIInsight mit der neuen Antwort.
Schlussfolgerung
Abschließend hat diese Übung gezeigt, wie erweiterbar MQL5 sein kann, wenn es mit externen Diensten gekoppelt wird – ob nun Live-Wirtschaftskalenderereignisse und Schlagzeilen von Alpha Vantage abgerufen werden oder Ihre Charts mit KI-generierten „Notizen“ aus einem selbst gehosteten 4-Bit-Modell angereichert werden. Diese KI-Einsichten sind zwar kein Ersatz für Echtzeitdaten oder ein professionell geschultes Handelssystem, aber sie fügen eine bedarfsgerechte Ebene qualitativer Kommentare oder Brainstorming-Anregungen hinzu, die neue Ideen auslösen können.
Auf dem Weg dorthin haben wir uns mit Hugging Face vertraut gemacht und gelernt, MSYS2, Git Bash und Miniconda zu verwenden, um Modelle abzurufen, Server zu konfigurieren und isolierte Umgebungen zu verwalten. Wir haben zwei Sprachen miteinander verbunden – Python für die Modellinferenz und FastAPI und MQL5 für die On-Chart-Integration – und damit unsere Programmiertoolbox erweitert und gezeigt, wie verschiedene Ökosysteme zusammenarbeiten können. Wir laden Sie ein, zu experimentieren und uns Ihr Feedback im Kommentarbereich mitzuteilen.
Versuchen Sie in Zukunft, MetaTrader 5-Kursreihen oder Indikatorwerte in Echtzeit in Ihre KI-Eingabeaufforderungen zu integrieren, um den Kontext und die Relevanz zu verbessern. Sie können mit verschiedenen quantisierten Formaten experimentieren, Zero-Downtime-Bereitstellungen automatisieren oder Inferenzen auf mehrere Knoten verteilen. Die Aufrüstung auf ein größeres Modell und die Verbesserung der Hardware ermöglichen umfangreichere und differenziertere Einblicke, aber auch bescheidene Systeme können leistungsstarke, interaktive Handelshilfen liefern. Die Schnittstelle zwischen algorithmischem Handel und selbst gehosteter KI ist noch weit offen; Ihr nächster Durchbruch könnte die Art und Weise, wie Händler mit den Märkten interagieren, neu definieren.
Nachstehend finden Sie die angehängten Support-Dateien. Ich habe auch eine Tabelle mit einer kurzen Beschreibung für jede Datei vorbereitet, damit Sie ihren Zweck besser verstehen.
Wichtige Lektionen
| Lektion | Beschreibung |
|---|---|
| Umgebungs Isolierung | Verwenden Sie Conda oder virtualenv, um isolierte Python-Umgebungen zu erstellen und Abhängigkeiten wie FastAPI und llama-cpp-python getrennt und reproduzierbar zu halten. |
| Lokale Zwischenspeicherung | Laden Sie einmalig die große GGUF-Modelldateien über den Hugging Face Hub-Client herunter und speichern Sie sie im Cache, um wiederholte Netzwerkübertragungen zu vermeiden und den Serverstart zu beschleunigen. |
| Abfragebegrenzung | Implementieren Sie eine Mindestintervalldrosselung (z. B. 300 s) für KI-Anfragen, damit der EA den Server nicht überlastet oder eine übermäßige Inferenzlast verursacht. |
| Fehlerresistentes Parsing | JSON-Dekodierung in die Fehlerbehandlung einbeziehen und nur das erste gültige Objekt extrahieren, um den EA vor fehlerhaften oder mit zusätzlichen Daten versehenen Antworten zu schützen. |
| Doppelte Canvas-Pufferung | Verwenden Sie Canvas.Update(true), nachdem Sie jeden Zyklus gezeichnet haben, um Änderungen zu bestätigen, um ein Flackern zu verhindern und reibungslose Chart-Animationen zu gewährleisten. |
| Timer-gesteuerte Schleifen | Steuern Sie alle Bildläufe und Datenaktualisierungen mit einem einzigen Millisekunden-Timer (z. B. 20 ms), um ein Gleichgewicht zwischen flüssiger Animation und CPU-Last herzustellen. |
| Die Integration von WebRequest | Verwenden Sie WebRequest von MQL5, um JSON an den lokalen AI-Server zu POSTen und Erkenntnisse zu gewinnen. Denken Sie daran, die URL in den Terminaloptionen auf eine Whitelist zu setzen. |
| Randomisierung für Diversität | Variieren Sie die Aufforderungen oder wählen Sie Währungspaare für jede KI-Anfrage nach dem Zufallsprinzip aus, um vielfältige, sich nicht wiederholende Handelserkenntnisse zu gewinnen. |
| Ressourcenbereinigung | Zerstören Sie in OnDeinit alle Canvas-Objekte, löschen Sie dynamische Arrays und beenden Sie Timer, um Speicherlecks und verwaiste Chart-Objekte zu vermeiden. |
| Modularer Aufbau | Organisieren Sie den Code in übersichtlichen Funktionen – ReloadEvents, FetchAlphaVantageNews, FetchAIInsights, DrawLane – um die Lesbarkeit und Wartbarkeit zu verbessern. |
| Flexibilität der Shell | Nutzen Sie Git Bash für Git und Skripterstellung, MSYS2 für POSIX-Tools und Builds, Conda Prompt für Python-Umgebungen und CMD für schnelle, einmalige Aufgaben. |
| Quantisiertes lokal verfügbares Modell | Halten Sie ein quantisiertes GGUF-Modell lokal verfügbar, um den Speicherbedarf und die Inferenzlatenz im Vergleich zu Gewichten mit voller Genauigkeit zu reduzieren. |
| Trennung von Server und Client | Belassen Sie schwere Inferenzen auf dem FastAPI/Uvicorn-Server, damit der EA leichtgewichtig bleibt, indem er nur UI-Aktualisierungen und HTTP-Anfragen verarbeitet. |
| Entkoppeltes Rendering | Führen Sie Bildlauf- und Zeichenoperationen immer vor dem Aufruf von Netzwerkfunktionen aus, um die Reaktionsfähigkeit der Nutzeroberfläche auch bei langen Anfragen zu gewährleisten. |
| Schnelles Engineering | Entwerfen Sie prägnante, zielgerichtete JSON-Prompts, wie z. B. „Insight for EURUSD today“, um die Prompt-Auswertungszeit zu minimieren und die Modellausgabe zu fokussieren. |
| Strategien für die Probenahme | Passen Sie die Stichprobenparameter (top-k, top-p, Temperatur) in Ihrer FastAPI-Anwendung an, um ein Gleichgewicht zwischen Kreativität und Konsistenz bei den generierten Erkenntnissen herzustellen. |
| Asynchrone Endpunkte | Verwenden Sie die asynchronen Def-Handler von FastAPI, damit Uvicorn gleichzeitige EA-Anfragen bearbeiten kann, ohne bei langwierigen Inferenzen zu blockieren. |
| Protokollierung und Beobachtbarkeit | Instrumentieren Sie sowohl den EA als auch den Server mit Zeitstempeln und Level der Protokollierung – z. B. llama_print_timings und EA-Konsolenausdrucke – um Leistungsprobleme zu diagnostizieren. |
| Leistungskennzahlen | Zeigen Sie Metriken (z. B. über Prometheus) wie Anfragelatenz, Token pro Sekunde und Modellladezeit an, um die Systemleistung zu überwachen und zu optimieren. |
| Rückgriff-Strategien | Anzeige einer Standardmeldung „Einsicht nicht verfügbar“ in EA, wenn WebRequest fehlschlägt oder der Server nicht erreichbar ist, um die Stabilität der Nutzeroberfläche unter Fehlerbedingungen zu gewährleisten. |
Anlagen
| Dateiname | Beschreibung |
|---|---|
| News Headline EA.mq5 | MetaTrader 5 Expert Advisor Skript, das Scrolling Lanes für wirtschaftliche Kalenderereignisse, Alpha Vantage Nachrichten, On-Chart-Indikatoren Einblicke (RSI, Stochastics, MACD, CCI), und eine gedrosselte AI-gesteuerte Marktsignal Lane rendert. |
| download_model.py | Eigenständiges Python-Skript, das den Hugging Face Hub-Client verwendet, um das 4-Bit-GGUF-quantisierte StableLM-Zephyr-Modell abzurufen und zwischenzuspeichern und seinen lokalen Pfad für eine spätere Bezugnahme im Server-Setup zu drucken. |
| serve_insights.py | FastAPI-Anwendung, die das zwischengespeicherte GGUF-Modell über llama-cpp-python lädt, einen POST /insights-Endpunkt zur Annahme von JSON-Eingaben bereitstellt, Inferenzen durchführt und generierte Markteinblicke zurückgibt. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18685
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.