
从新手到专家:使用 MQL5 制作动画新闻标题(四) — 本地托管 AI 模型市场洞察

目录:
概述
在本次讨论中,我们将探讨如何利用开源 AI 模型来增强我们的算法交易工具 —— 具体来说,是如何通过 AI 洞察通道来扩展 News Headline EA。目标是帮助新人找到一个坚实的起点。谁知道呢?今天,您可能正在集成一个模型;明天,你可能会建造一个。但这一切都始于理解前人奠定的基础。
在谈论现代进步时,我们不能不提到人工智能及其对人类任务的快速增长的影响。当谈到算法交易时,讨论变得更加相关 —— 交易已经由数字和自动化驱动,与仍需要从手动流程转变的其他领域相比,AI 是一个自然的选择。
虽然 AI 模型已成为各个领域的强大工具,但由于开发功能齐全的系统非常复杂,并非每个人都有资源或专业知识来构建自己的模型。幸运的是,开源项目的兴起使得人们可以免费访问预先训练的模型并从中受益。这些社区驱动的努力为许多开发人员和爱好者提供了一个实用的切入点。
也就是说,由于投入了大量的工作,高端型号通常会提供更广泛的功能。尽管如此,开源模型仍然是一个有价值的起点,特别是对于那些希望在不重新发明轮子的情况下集成 AI 的人来说。
在前面的讨论中,我们重点讨论了指标洞察。今天,我们将探索如何通过自托管量化语言模型并将其直接集成到 MQL5 EA 交易中,利用开源 AI 进行算法交易。 在下一节中,我们将首先简要介绍 llama.cpp(轻量级推理引擎)和 4 位 GGUF 模型(压缩的“大脑”)的作用,然后逐步讲解如何下载和准备模型,如何使用 FastAPI 设置本地基于 Python 的推理服务器,最后将其连接到 News Headline EA 以创建一个动态 AI Insights 通道。
在此过程中,我们将重点介绍关键决策、解决常见障碍,并演示简单的冒烟测试 —— 所有这些都是为了向您提供一个清晰的、端到端的蓝图,以便将实时 AI 评论添加到您的交易工作流程中。
概览
在这个项目中,我们使用 64 位 Intel Core i7-8550U CPU(1.80–1.99 GHz)和 8 GB 内存。鉴于这些硬件限制,我们选择了一个轻量级的 4 位 GGUF 模型 —— 具体来说是 stablelm-zephyr-3b.Q5_K_M.gguf —— 以确保在我们的系统上实现高效的加载和推理性能。稍后,我将分享适用于此类项目的推荐硬件规格,以及未来支持更大、要求更高的 AI 模型所需的升级计划。
在我们继续之前,熟悉顺利运行此项目所需的关键组件和硬件要求非常重要。出于教育目的,我们正在使用适度的规格,但如果你有更强大的硬件,我们鼓励你利用它。我还将为更高性能的设置提供合适的型号和推荐规格的指导。
了解 Hugging Face
Hugging Face 是一个平台,托管着数千个预训练的机器学习模型(NLP、视觉、语音等),以及数据集、评估指标和开发者工具——可通过网页或 huggingface_hub Python 库访问。它简化了模型发现、版本控制和大文件管理(Git LFS),并提供免费自托管选项和托管推理 API,以实现可扩展的部署。Hugging Face 拥有全面的文档、社区支持,并能与 PyTorch 和 TensorFlow 等框架无缝集成,使任何人都能快速找到、下载并在自己的应用程序中运行尖端的 AI 模型。
硬件要求
对于在 llama-cpp-python 上运行的 4 位、3 B 参数 GGUF 模型,您至少需要:
- CPU:4 核/8 线程(例如 Intel i5/i7 或 AMD Ryzen 5/7),用于亚秒级逐词推理。
- RAM:约 6 至 8 GB 可用空间用于加载约 1.9 GB 的量化模型,加上工作内存。
- 存储:SSD 至少有 3 GB 的可用空间,用于模型缓存(约 1.9 GB)和操作系统开销。
- 网络:本地主机调用 —— 无需外部带宽。
升级规格
- 较大模型:升级到 7 B 参数或 13 B 参数模型(量化),但需要 12 GB 以上的内存和更强大的 CPU 或 GPU。
- GPU 加速:使用支持 CUDA/cuBLAS 的 NVIDIA GPU 和 llama-cpp GPU 后端或 Triton/ONNX 等框架,可实现 10 倍速度提升。
- 水平缩放:将容器化(Docker)或部署到 Kubernetes 集群上,以实现多个推理 pod 的负载均衡 —— 非常适合高吞吐量或多用户设置。
- 云端 GPU/TPU:对于参数大于 13 B 的模型或实时 SLA,请迁移到 AWS/GCP/Azure 实例(例如 A10G、A100)。
软件要求:
我们的工作流程使用多个互补的 shell 和环境来简化开发和测试:
- Git Bash 是我们获取和版本控制代码的首选工具 —— 使用它来克隆 Hugging Face 仓库,运行 python download_model.py(前提是您首选的 Python 已添加到 PATH),如果您喜欢 Bash 语法,甚至可以启动快速的冒烟测试。我们可以使用 Windows 命令提示符或其他 shell 来完成此过程。
- MSYS2 为我们在 Windows 上提供了一个完整的 POSIX 层 —— 模型就位后,我们就可以留在 MSYS2 中,对 http://localhost:8000/insights 运行 curl(或 httpie)来验证我们的 FastAPI 端点是否存活并返回 JSON。
- Anaconda Prompt 是我们创建和激活 ai-server Conda 环境(python=3.12)的地方,conda install llama-cpp-python、FastAPI 和 Uvicorn 包,最后启动 uvicorn server:app --reload --port 8000。
下面是一个框图,作为我们将在本次讨论中介绍的流程的蓝图。
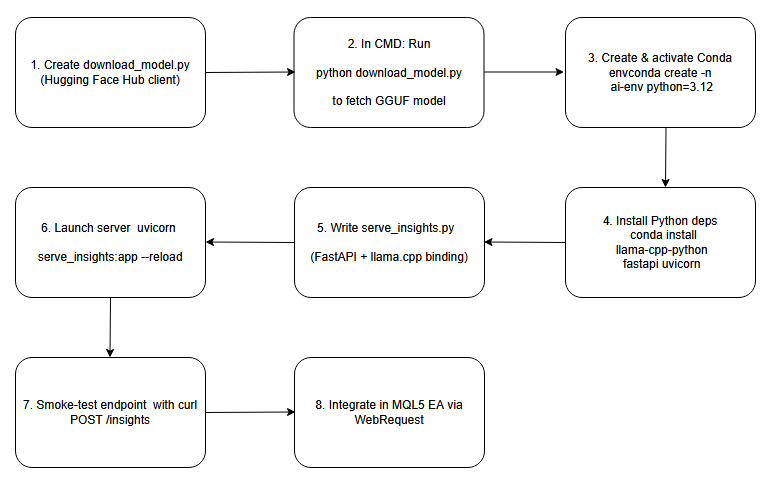
流程图。
在本地设置和托管 AI 模型
第一步:创建下载脚本
首先,我们编写一个利用 Hugging Face Hub 客户端的小型 Python 脚本。在此脚本中,我们指定存储库名称(例如,“ TheBloke/stablelm‑zephyr‑3b.Q5_K_M.gguf”),并调用 hf_hub_download() 将量化的 GGUF 文件拉取到我们的本地缓存中。通过打印出返回的文件路径,我们可以获得一个可靠的、机器可读的参考,以确定模型现在在磁盘上的位置。这种方法可以自动下载,并确保你知道确切的缓存位置 —— 这对于配置下游推理代码至关重要,而无需硬编码不可预测的目录。
# download_model.py from huggingface_hub import hf_hub_download # Download the public 4-bit GGUF model; no Hugging Face account required model_path = hf_hub_download( repo_id = "TheBloke/stablelm-zephyr-3b-GGUF", filename = "stablelm-zephyr-3b.Q5_K_M.gguf", repo_type = "model" ) print("Downloaded to:", model_path)
第二步:运行下载脚本
接下来,打开一个普通的 Windows 命令提示符,然后 cd 进入包含下载脚本的目录(例如 download_model.py)。当你执行 python download_model.py 时,Hugging Face 客户端将通过 HTTPS 连接,将 GGUF 权重下载到其缓存中,并打印完整路径(类似 C:\Users\You\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b.Q5_K_M\…\stablelm-zephyr-3b.Q5_K_M.gguf)。看到该路径可以确认文件已就位,并允许您将其直接复制到推理配置中。
Windows 系统中的命令提示符:
python download_model.py
下载模型的路径:
Downloaded to: C:\Users\BTA24\.cache\huggingface\hub\…\stablelm-zephyr-3b.Q5_K_M.gguf
第三步:创建并激活 Conda 环境
conda create -n ai-env python=3.12 -y conda activate ai-env
第四步:安装 Python 依赖项
在 ai-server 环境激活的情况下,使用 pip install llama-cpp-python fastapi uvicorn (或者如果喜欢,可以使用 conda install -c conda-forge llama-cpp-python)来引入核心库。llama-cpp-python 绑定封装了加载和运行 GGUF 模型所需的高性能 C++ 推理引擎,而 FastAPI 和 Uvicorn 分别提供了一个异步 Web 框架和服务器,用于公开生成见解的端点。这些软件包共同构成了您本地 AI 推理服务的骨干。
conda install -c conda-forge llama-cpp-python fastapi uvicorn -y
第五步:编写 FastAPI 服务器脚本
在你的项目文件夹中,创建一个新文件(例如 server.py),并从 llama_cpp 导入 FastAPI 和 Llama。在全局范围内,使用下载的 GGUF 文件的路径实例化 Llama 类。然后定义一个 POST 端点 /insights,该端点接受一个 JSON 正文(包含一个 “prompt” 字符串),调用 llm.create() 或等效方法来生成文本,并返回一个包含 “insight” 字段的 JSON 响应。只需几行代码,您现在就拥有了一个 RESTful AI 服务,可以接收提示并回传模型输出。
# serve_insights.py from fastapi import FastAPI, Request from llama_cpp import Llama MODEL_PATH = r"C:\Users\BTA24\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b-GGUF\snapshots\<snapshot-id>\stablelm-zephyr-3b.Q5_K_M.gguf" llm = Llama(model_path=MODEL_PATH, n_threads=4, n_ctx=512) app = FastAPI() @app.post("/insights") async def insights(req: Request): data = await req.json() prompt = data.get("prompt", "") out = llm(prompt, max_tokens=64) text = out["choices"][0]["text"].strip() return {"insight": text}
第六步:启动推理服务器
仍然在 Anaconda Prompt 中,切换到你的项目目录并启动 Uvicorn,指向 FastAPI 应用程序。启用自动重新加载以动态获取脚本更改,并监听端口 8000 以接收传入请求。
cd server.py 所在的文件夹并运行:
cd "C:\Users\YOUR_COMPUTER_NAME\PATH_TO_YOUR python serve insights file"
进入后,我们运行服务器:
uvicorn serve_insights:app --host 0.0.0.0 --port 8000 --reload
第七步:对端点进行冒烟测试
从任何终端向 http://localhost:8000/insights 发送一个简单的 POST 请求,其中包含 JSON 格式的测试提示。验证服务器是否返回包含 “insight” 字段的有效 JSON 数据。
curl -X POST http://localhost:8000/insights \ -H "Content-Type: application/json" \ -d '{"prompt":"One-sentence FX signal for EUR/USD."}'
成功的回复应如下所示:
{"insight":"Be mindful of daily open volatility…"}
第八步:集成到您的 MQL5 EA 中
AI 服务器已启动并验证,现在是时候回到我们的 MQL5 EA 交易,继续我们中断的工作了。我们将通过在图表上添加专门的“AI Insights”通道,把 AI-Insights 端点集成到我们的 EA 中。集成后,您的 EA 将按配置的间隔调用本地 /insights 端点,解析返回的 JSON,并将生成的文本输入到您已用于新闻和指标的相同平滑滚动机制中。在下一节中,我们将逐步完成完整的代码集成,以交付一个完整的端到端 AI 增强型交易工具。
将 AI 洞察集成到 MQL5 中:提升 News Headline EA
假设您已经阅读过我们之前的文章,现在我们将重点介绍如何将新的 AI-Insights 功能集成到 EA 中。接下来,我将重点介绍并解释每个需要添加的代码 —— 同时保持 EA 的其余部分不变 —— 然后在讨论结束时提供完整的、更新后的 EA 代码。
1.拓展我们的输入参数
首先,我们在现有输入参数的基础上增加了三个新的输入参数。我们包含一个布尔值,以便我们可以随时打开或关闭 AI Insights 通道;一个字符串,用于输入 FastAPI(或其他 AI)端点的 URL;以及一个整数,用于设置连续 POST 调用之间必须经过多少秒。有了这些,我们就可以进行交互式实验 —— 切换通道、指向不同的服务器,或者提高或降低刷新率,而无需触及核心代码。
//--- 1) USER INPUTS ------------------------------------------------ input bool ShowAIInsights = true; input string InpAIInsightsURL = "http://127.0.0.1:8000/insights"; input int InpAIInsightsReloadSec = 60; // seconds between requests
2.声明共享全局变量
接下来,我们引入全局变量来保存和管理我们的 AI 数据。我们将当前洞察文本保存在一个字符串中,并用整数跟踪其水平偏移量,以便我们可以在每个计时滚动它。为了避免请求重叠,我们添加了一个标志来标记何时进行 Web 请求,并且我们存储了上次成功获取的时间戳。这些全局变量确保我们总是有东西可以绘制,确切地知道何时发送下一个调用,并防止争用 HTTP 调用。
//--- 3) GLOBALS ----------------------------------------------------- string latestAIInsight = "AI insights coming soon…"; int offAI; // scroll offset bool aiRequestInProgress = false; // prevent concurrent POSTs datetime lastAIInsightTime = 0; // last successful fetch time
3.构建 FetchAIInsights()
我们将所有 HTTP 逻辑封装在一个函数中。在内部,我们首先检查切换和冷却时间:如果 AI 通道已禁用,或者我们最近才获取数据(或者之前的请求仍在等待处理),我们就直接返回。否则,我们将构造一个最小的 JSON 有效负载(可能包括当前交易品种),并发出 WebRequest("POST")。成功后,我们从 JSON 响应中解析出 “insight” 字段,并更新我们的全局文本和时间戳。如果出现任何错误,我们会保留之前的洞察,因此我们的滚动通道永远不会空白。
void FetchAIInsights() { if(!ShowAIInsights || aiRequestInProgress) return; datetime now = TimeTradeServer(); if(now < lastAIInsightTime + InpAIInsightsReloadSec) return; aiRequestInProgress = true; string hdrs = "Content-Type: application/json\r\n"; string body = "{\"prompt\":\"Concise trading insight for " + Symbol() + "\"}"; uchar req[], resp[]; string hdr; StringToCharArray(body, req); int res = WebRequest("POST", InpAIInsightsURL, hdrs, 5000, req, resp, hdr); if(res > 0) { string js = CharArrayToString(resp,0,WHOLE_ARRAY); int p = StringFind(js, "\"insight\":"); if(p >= 0) { int start = StringFind(js, "\"", p+10) + 1; int end = StringFind(js, "\"", start); if(start>0 && end>start) latestAIInsight = StringSubstr(js, start, end-start); } lastAIInsightTime = now; } aiRequestInProgress = false; }
4.在 OnInit() 中初始化 Canvas
在我们的初始化例程中,设置完所有其他画布后,我们还会创建 AI 画布。我们赋予它相同的尺寸和半透明背景,然后将其放置在现有通道的正下方。在任何数据返回之前,我们会绘制一个友好的占位符(“AI 洞察即将到来……”),使图表看起来更美观。最后,我们立即调用一次 FetchAIInsights() —— 这保证了即使我们从会话中间开始,真正的内容也会在第一次网络调用完成后立即出现。
int OnInit() { // … existing init … // AI Insights lane if(ShowAIInsights) { aiCanvas.CreateBitmapLabel("AiC", 0, 0, canvW, lineH, COLOR_FORMAT_ARGB_RAW); aiCanvas.TransparentLevelSet(120); offAI = canvW; SetCanvas("AiC", InpPositionTop, InpTopOffset + (InpSeparateLanes ? 8 : 5) * lineH); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); aiCanvas.Update(true); // initial fetch FetchAIInsights(); } EventSetMillisecondTimer(InpTimerMs); return INIT_SUCCEEDED; }
5.OnTimer() 中的刷新和滚动
每次计时器滴答到达,我们都会重新绘制事件、新闻和指标。紧接着,我们插入 AI 步骤:调用 FetchAIInsights()(如果冷却时间未过,则静默执行空操作),清除 AI 画布,在当前偏移量处绘制最新见解,递减该偏移量以实现平滑的向左滚动,在离开屏幕时将其循环,最后调用 Update(true) 立即刷新它。最终呈现的是一个精美的滚动式 AI 信息,只有在我们允许的情况下才会刷新 —— 将流畅的动画与可控的网络使用相结合。
void OnTimer() { // … existing redraw for events/news/indicators … // fetch & draw AI lane FetchAIInsights(); if(ShowAIInsights) { aiCanvas.Erase(ARGB(120,0,0,0)); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); offAI -= InpAIInsightsSpeed; if(offAI + aiCanvas.TextWidth(latestAIInsight) < -20) offAI = canvW; aiCanvas.Update(true); } }
6.在 OnDeinit() 中进行清理
当我们的 EA 交易卸载时,我们会把所有东西都清理干净。我们终止计时器,销毁并删除 AI 画布(仅当它存在时),然后对其他画布、事件数组和动态对象执行我们现有的清理操作。这样可以确保我们不留下任何痕迹 —— 因此重新加载或重新部署 EA 总是从零开始。
void OnDeinit(const int reason) { EventKillTimer(); // … existing cleanup … if(ShowAIInsights) { aiCanvas.Destroy(); ObjectDelete(0, "AiC"); } }
测试集成
现在我们已经完成了集成,让我们将更新后的 EA 交易加载到 MetaTrader 5 中,并观察其实时性能。务必保持 AI 服务器在后台运行 —— 我仍在探索是否可以通过 EA 本身以编程方式启动它。在下面的截图中,你会看到新的 AI Insights 通道位于其他通道的底部,显示实时洞察文本。
您可以在代码中轻松调整其配色方案;在本演示中,我们保留了默认设置。您还会注意到滚动时偶尔会出现短暂的停顿 —— 这是我们当前获取时间的一个问题,我们将在即将到来的版本中进行微调。随着端到端 AI 功能的上线和运行,接下来我们将转向服务器端实现,以了解后端是如何提供这些洞察的。

News Headline EA 凭借本地托管模型提供 AI 驱动的市场洞察
以下代码片段直接取自 Anaconda Prompt,Uvicorn 在其中提供我们的 /insights 端点。查看这些日志可以告诉我们三件事。
- 模型加载成功,推理引擎已准备就绪。
- Uvicorn 正在运行和监听,所以 HTTP 服务器已启动。
- 我们的 EA 的 Web 请求已成功到达服务器,触发了新的推理周期。
下面,我记录了测试期间的五个推理周期 —— 每个周期都对应于 EA 的一个 POST。 接下来,我将详细带你了解其中一个循环,以便你能够清楚地看到幕后发生了什么。
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 83.42 ms / 64 runs ( 1.30 ms per token, 767.19 tokens per second) llama_print_timings: prompt eval time = 1890.97 ms / 6 tokens ( 315.16 ms per token, 3.17 tokens per second) llama_print_timings: eval time = 32868.44 ms / 63 runs ( 521.72 ms per token, 1.92 tokens per second) llama_print_timings: total time = 35799.69 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 51.40 ms / 64 runs ( 0.80 ms per token, 1245.21 tokens per second) llama_print_timings: prompt eval time = 1546.64 ms / 4 tokens ( 386.66 ms per token, 2.59 tokens per second) llama_print_timings: eval time = 29878.89 ms / 63 runs ( 474.27 ms per token, 2.11 tokens per second) llama_print_timings: total time = 32815.26 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 65.92 ms / 64 runs ( 1.03 ms per token, 970.80 tokens per second) llama_print_timings: prompt eval time = 1841.83 ms / 6 tokens ( 306.97 ms per token, 3.26 tokens per second) llama_print_timings: eval time = 31295.30 ms / 63 runs ( 496.75 ms per token, 2.01 tokens per second) llama_print_timings: total time = 34146.43 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 55.34 ms / 64 runs ( 0.86 ms per token, 1156.42 tokens per second) llama_print_timings: prompt eval time = 1663.61 ms / 4 tokens ( 415.90 ms per token, 2.40 tokens per second) llama_print_timings: eval time = 29311.62 ms / 63 runs ( 465.26 ms per token, 2.15 tokens per second) llama_print_timings: total time = 31952.19 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
了解 Anaconda Prompt 中 Model 和 WebRequest 的工作原理:
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
当您的 FastAPI‐Uvicorn 服务器加载 GGUF 模型时,llama‐cpp 报告“加载时间”约为 206 秒 —— 这是将整个量化网络读取并初始化到内存中的一次性成本。之后,每个发送到 /insights 的 HTTP POST 请求大致遵循以下顺序:
及时评估(及时评估时间)
在这里,llama-cpp 将提示的前几个标记通过模型的转换器堆栈运行,以“启动”生成过程。日志显示,处理 4 个标记总共耗时 1.49 秒,平均每个标记耗时约 372 毫秒。
标记生成(评估时间 + 采样时间)
- 对于生成的每个后续标记,该库会执行以下两项操作:
- 评估:计算 transformer 前向传播(每个 token ≈ 469 毫秒,即 ~2.13 个 token /s)。
- 示例:应用 nucleus/top‑k/etc 采样来选择下一个标记(每个令牌 ≈ 0.91 毫秒)。
- 在你的运行中,生成 63 个标记大约需要 29.6 秒进行评估,加上对所有标记进行采样需要 58 毫秒。
总延迟(总时间)
将提示评估、所有标记评估和采样加起来,从模型开始计算到返回最终文本,共耗时 31.98 秒。
该代完成后,Uvicorn 会记录类似以下内容:
INFO: 127.0.0.1:52770 - "POST /insights HTTP/1.1" 200 OK
这意味着服务器已收到您的 EA 的 WebRequest(“POST”,“http://127.0.0.1:8000/insights”,…),对其进行了处理,并返回了包含您的“insight”的 200 状态 JSON 有效负载。
最后,该行表示 llama-cpp 在其缓存中识别出重复的标记序列(前缀),并跳过了重新计算这些层,从而略微加快了生成速度。
Llama.generate: prefix-match hit
在测试过程中,我注意到 EA 的通道滚动偶尔会出现停顿。结果表明,在定时器循环中直接调用 FetchAIInsights() 会导致 EA 的 WebRequest 阻塞 —— 等待超时 —— 而 Uvicorn 则需要运行整个模型评估、令牌生成和采样过程(大约 32 秒)才能返回 JSON。
通过将滚动逻辑与我们的 HTTP 调用完全解耦 —— 在调用 FetchAIInsights() 之前每 20 毫秒绘制和移动文本 —— UI 通道可以继续动画而不会中断。与此同时,繁重的推理在服务器上运行,只有当推理完成后,我们才会用新的响应更新 latestAIInsight 。
结论
总之,这项练习表明,MQL5 与外部服务结合使用时具有多么大的可扩展性 —— 无论是从 Alpha Vantage 获取实时经济日历事件和头条新闻,还是使用来自自托管 4 位模型的 AI 生成的“注释”来丰富您的图表。虽然这些 AI 见解不能替代实时数据或专业训练的交易系统,但它们可以按需提供定性评论或头脑风暴提示,从而激发新的想法。
在此过程中,我们熟悉了 Hugging Face,并学会了使用 MSYS2、Git Bash 和 Miniconda 来获取模型、配置服务器和管理隔离环境。我们融合了两种语言 —— Python 用于模型推理和 FastAPI,MQL5 用于图表上集成 —— 扩展了我们的编程工具箱,并展示了不同的生态系统如何协同工作。欢迎大家尝试,并在评论区分享您的反馈。
展望未来,尝试将实时 MetaTrader 5 价格系列或指标值输入到您的 AI 提示中,以改善上下文和相关性。您可以尝试不同的量化格式,自动化零停机部署,或在多个节点之间分发推理。升级到更大的模型并增强硬件,将解锁更丰富、更细致的见解 —— 但即使是适中的配置也能产生强大的交互式交易辅助工具。算法交易与自托管 AI 的交集仍有很大的发展空间;你的下一个突破可能会重新定义交易者与市场的互动方式。
请查看下方附件中的支持文件。我还为每个文件准备了一个简短的描述表,以帮助您理解它们的目的。
关键经验
| 经验 | 描述 |
|---|---|
| 环境隔离 | 使用 Conda 或 virtualenv 创建隔离的 Python 环境,使 FastAPI 和 llama-cpp-python 等依赖项保持分离和可重现性。 |
| 本地缓存 | 通过 Hugging Face Hub 客户端一次性下载并缓存大型 GGUF 模型文件,以避免重复的网络传输并加快服务器启动速度。 |
| 限速 | 对 AI 请求实施最小间隔节流(例如 300 秒),以免 EA 使服务器过载或产生过大的推理负载。 |
| 容错解析 | 将 JSON 解码封装在错误处理中,并且只提取第一个有效对象,从而保护 EA 免受格式错误或额外数据响应的影响。 |
| Canvas 双缓冲 | 在每个循环绘制完成后使用 Canvas.Update(true) 来提交更改,防止闪烁并确保图表动画流畅。 |
| 定时器驱动的循环 | 使用单个毫秒计时器(例如 20 毫秒)驱动所有滚动和数据刷新,以平衡动画流畅性和 CPU 负载。 |
| WebRequest 集成 | 使用 MQL5 的 WebRequest 将 JSON POST 到本地 AI 服务器并检索见解,请记住在终端选项中将 URL 列入白名单。 |
| 多样性随机化 | 针对每个 AI 请求,改变提示或随机选择货币对,以生成多样化、不重复的交易见解。 |
| 资源清理 | 在 OnDeinit 中,销毁所有 Canvas 对象,删除动态数组,并终止计时器,以避免内存泄漏和孤立的图表对象。 |
| 模块化设计 | 将代码组织成清晰的函数 —— ReloadEvents、FetchAlphaVantageNews、FetchAIInsights、DrawLane —— 以提高可读性和可维护性。 |
| Shell 灵活性 | 利用 Git Bash 进行 Git 和脚本编写,利用 MSYS2 进行 POSIX 工具和构建,利用 Conda Prompt 进行 Python 环境,利用 CMD 进行快速的一次性操作。 |
| 量化模型托管 | 在本地托管量化的 GGUF 模型,与全精度权重相比,可以减少内存占用和推理延迟。 |
| 服务器-客户端分离 | 将大量推理工作放在 FastAPI/Uvicorn 服务器上,让 EA 保持轻量级,仅处理 UI 更新和 HTTP 请求。 |
| 解耦渲染 | 在调用网络功能之前,始终执行滚动和绘制操作,即使在长时间请求期间也能确保 UI 的响应性。 |
| 提示工程 | 编写简洁、有针对性的 JSON 提示(例如“今日 EURUSD 走势分析”),以最大限度地减少提示评估时间并专注于模型输出。 |
| 样本策略 | 在 FastAPI 应用中调整采样参数(top-k、top-p、temperature),以在生成的见解中平衡创造性和一致性。 |
| 异步端点 | 使用 FastAPI 的异步定义处理程序,以便 Uvicorn 可以处理并发的 EA 请求,而不会阻塞长时间运行的推理。 |
| 日志记录与可观测性 | 使用日志时间戳和级别(例如 llama_print_timings 和 EA 控制台打印)来检测 EA 和服务器,以便诊断性能问题。 |
| 性能指标 | 公开请求延迟、每秒标记数和模型加载时间等指标(例如通过 Prometheus),以监控和优化系统性能。 |
| 备用策略 | 如果 WebRequest 失败或服务器宕机,则在 EA 中显示默认的“洞察不可用”消息,以在错误情况下保持 UI 稳定性。 |
附件
| 文件名 | 描述 |
|---|---|
| News Headline EA.mq5 | MetaTrader 5 EA 交易脚本,可渲染经济日历事件、Alpha Vantage 新闻、图表指标分析(RSI、随机振荡指标、MACD、CCI)的滚动通道,以及受限制的 AI 驱动的市场信号通道。 |
| download_model.py | 一个独立的 Python 脚本,使用 Hugging Face Hub 客户端获取并缓存 4 位 GGUF 量化的 StableLM-Zephyr 模型,并打印其本地路径,以便在服务器设置中稍后参考。 |
| serve_insights.py | FastAPI 应用程序通过 llama‑cpp‑python 加载缓存的 GGUF 模型,公开 POST /insights 端点以接受 JSON 提示,运行推理,并返回生成的市场洞察。 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18685
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
