Discussão do artigo "Trading por algoritmo: IA e seu caminho para os topos dourados"
Depois de ler o artigo, tive a ideia de brincar com o próprio processo de agrupamento.
Escrevi uma variante que executa o agrupamento em uma janela deslizante em vez de em todo o conjunto de dados. Isso pode melhorar o particionamento dos clusters, levando em conta a estrutura temporal do BP.
def sliding_window_clustering(dataset, n_clusters: int, window_size=200) -> pd.DataFrame: import numpy as np data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] # Primeiro, criamos centroides de referência global global_kmeans = KMeans(n_clusters=n_clusters).fit(meta_X) global_centroids = global_kmeans.cluster_centers_ clusters = np.zeros(len(data)) # Aplique o agrupamento em uma janela deslizante for i in range(0, len(data) - window_size + 1, window_size): window_data = meta_X.iloc[i:i+window_size] # Ensine o KMeans na janela atual local_kmeans = KMeans(n_clusters=n_clusters).fit(window_data) local_centroids = local_kmeans.cluster_centers_ # Combine os centroides locais com os centroides globais # para garantir a consistência dos rótulos de cluster centroid_mapping = {} for local_idx in range(n_clusters): # Encontre o centroide global mais próximo desse centroide local distances = np.linalg.norm(local_centroids[local_idx] - global_centroids, axis=1) global_idx = np.argmin(distances) centroid_mapping[local_idx] = global_idx + 1 # +1 para iniciar a numeração a partir de 1 # Obter os rótulos da janela atual local_labels = local_kmeans.predict(window_data) # Converter rótulos locais em rótulos globais consistentes for j in range(window_size): if i+j < len(clusters): # Verificando se está fora dos limites clusters[i+j] = centroid_mapping[local_labels[j]] data['clusters'] = clusters return data
Insira essa função no código e substitua o agrupamento por sliding_window_clustering.
Isso parece melhorar os resultados.
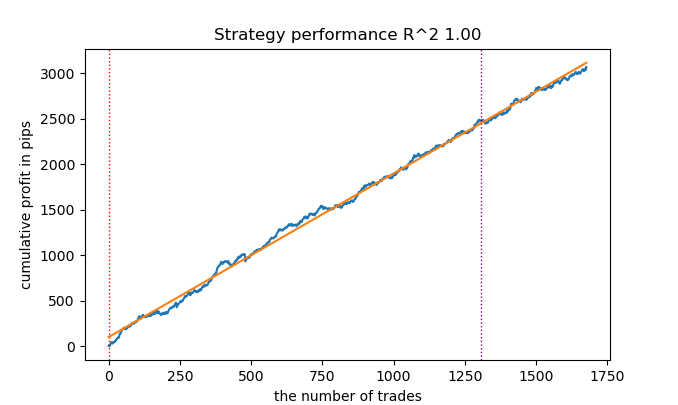
Ainda assim, às vezes é útil escrever artigos.
Obrigado pelo artigo, Dmitrievsky. Parece que o EA carregado e seu arquivo de inclusão são incompatíveis entre si. Ele faz referência ao arquivo mpq na pasta "Trend following", mas os arquivos de amostra estavam em "Mean reversion".
E a função get_features no "causal one direction.py" não é a mesma que aparece no artigo. Além disso, o arquivo mqh gerado por "causal one direction.py" ao exportar .onnx não é o mesmo que o oferecido em MQL5_files.zip.
Agradeço muito se você puder fazer os esclarecimentos necessários.
Paulo

Obrigado pelo artigo, Dmitrievsky. Parece que o EA carregado e seu arquivo de inclusão são incompatíveis entre si. Ele faz referência ao arquivo mpq na pasta "Trend following", mas os arquivos de amostra estavam em "Mean reversion".
E a função get_features no "causal one direction.py" não é a mesma que aparece no artigo. Além disso, o arquivo mqh gerado por "causal one direction.py" ao exportar .onnx não é o mesmo que o oferecido em MQL5_files.zip.
Agradeço muito se você puder fazer os esclarecimentos necessários.
Paulo
Atualizei os arquivos e adicionei um novo método de agrupamento.
Agora todos os caminhos e funções correspondem.
Portanto, você tem o R2, um índice modificado, cuja eficiência é baseada no lucro em pips. E quanto ao drawdown e outros indicadores de desempenho? Se obtivermos um modelo que dê mais de 90% no treinamento e pelo menos 85% no teste, então seu índice apresentará números impressionantes. Não importa quantas vezes eu tenha executado o testador no MT5, nunca recebi um lucro no histórico. O depósito é drenado. Isso ocorre apesar do fato de seu testador em Python fornecer 0,97-0,98
Não entendo o que isso tem a ver com o CV.
Todas essas estratégias têm baixo poder de comprovação, porque se baseiam apenas no histórico de cotações não estacionárias. Mas você pode detectar tendências.- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Trading por algoritmo: IA e seu caminho para os topos dourados foi publicado:
A evolução do entendimento das capacidades dos métodos de aprendizado de máquina no trading levou à criação de diferentes algoritmos que resolvem igualmente bem a mesma tarefa, mas que são essencialmente distintos. Nesta artigo será novamente analisado um sistema de trading de tendência unidirecional, usando o ouro como exemplo, mas aplicando um algoritmo de clusterização.
Ao observarmos esse importante método de análise e previsão de séries temporais sob diferentes ângulos, é possível identificar suas vantagens e desvantagens em comparação com outras formas de criação de sistemas de trading baseadas exclusivamente na análise e previsão de séries temporais financeiras. Em alguns casos, esses algoritmos se mostram bastante eficientes, superando os métodos clássicos tanto na velocidade de criação quanto na qualidade dos sistemas de negociação resultantes.
Neste artigo, vamos nos concentrar no trading unidirecional, quando o algoritmo abre apenas operações de compra ou de venda. Como algoritmos básicos, serão usados o CatBoost e o K-Means. O CatBoost é o modelo base, atuando como um classificador binário para classificar operações. Já o K-Means é utilizado para identificar regimes de mercado na etapa de preprocessamento.
Autor: Maxim Dmitrievsky