
Simulação de mercado (Parte 23): Iniciando o SQL (VI)

Introdução
No artigo anterior Simulação de mercado (Parte 22): Iniciando o SQL (V), abordei a questão de como fazer uso, ou melhor, como uma chave primária se liga a uma chave estrangeira. Se você não sabe do que estou falando, sugiro que você, pare a leitura, e leia primeiro os artigos anteriores. Isto para que você consiga de fato entender o que estaremos fazendo aqui.
Entendendo o resultado da pesquisa
Pois bem, no artigo anterior, montamos um pequeno banco de dados, cujo objetivo era permitir a exemplificar o uso das chaves primárias, junto com chaves estrangeiras. Porém, ao fazer uma pesquisa em que esta configuração foi utilizada. Você muito provavelmente acabará se deparando com um resultado bem diferente do esperado. Para ficar um pouco, mais claro vamos usar o seguinte código para pesquisar no banco de dados.
SELECT * FROM tb_Quotes;
Código 01
O resultado é visto logo abaixo.
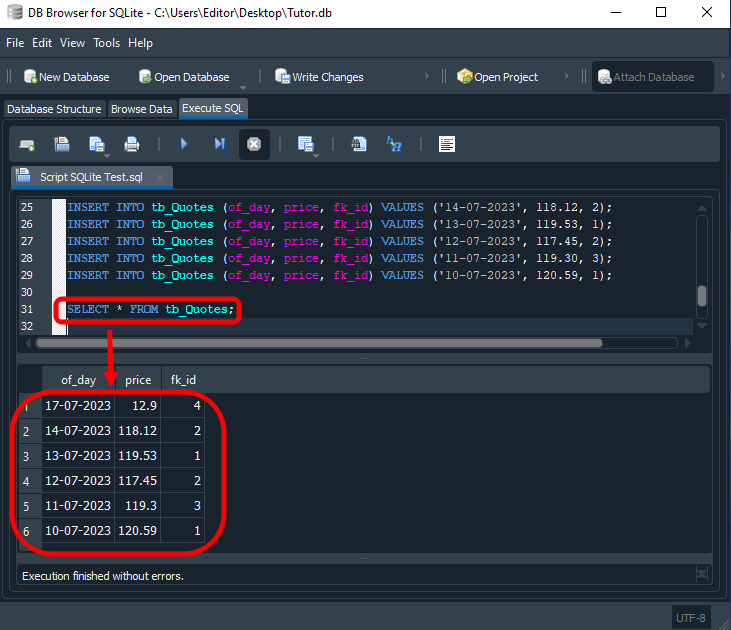
Imagem 01
Assim você acaba se perguntando: O que fiz de errado? A resposta é: NADA. Muita gente não faz uso de chaves estrangeiras em seus bancos de dados, justamente por não entender o conceito por detrás de tais chaves. E por conta disto acabam por criar bancos de dados não relacionais. Tornando assim a manutenção e a própria estrutura do banco de dados, muito mais complicada do que realmente poderia ser criada. Isto torna o processamento e o trabalho do SQL muito maior do que realmente ocorreria normalmente.
Um dos maiores trunfos do SQL está no fato de que você pode criar tabelas aparentemente isoladas. Porém, toda via e, entretanto, consegue fazer com que estas tabelas, ou melhor dizendo, os valores presentes nestas tabelas venham a se ligar de alguma forma. E isto evita justamente um dos maiores problemas que existia antes do SQL, que são dados em duplicada. Talvez você não entenda o quando isto é prejudicial ao banco de dados. Mas isto de fato, acaba destruindo completamente a grande vantagem que existe em se utilizar SQL, quando bancos de dados precisam ser criados por sua aplicação.
Visualizando um diagrama do Banco de dados
Para fazer a visualização de um diagrama, existem diversas alternativas. Algumas com mais ou menos recursos. No caso do DB Browser, que está sendo usado, aqui para explicar algumas coisas. Você não conseguirá de fato obter o tal diagrama. Bem, pelo menos até o momento que escrevo este artigo. Já que por se tratar de um programa de código aberto, e que recebe atualizações via GITHub. Pode ser que no momento que você esteja lendo este artigo, tal recurso já esteja presente no DB Browser. Assim uma alternativa seria usar o DBeaver. Este é um programa, que tem uma versão gratuita que pode ser baixada e utilizada sem grandes problemas. Bem uma vez com o DBeaver em mãos. Você deverá seguir os seguintes passos para poder visualizar um diagrama.
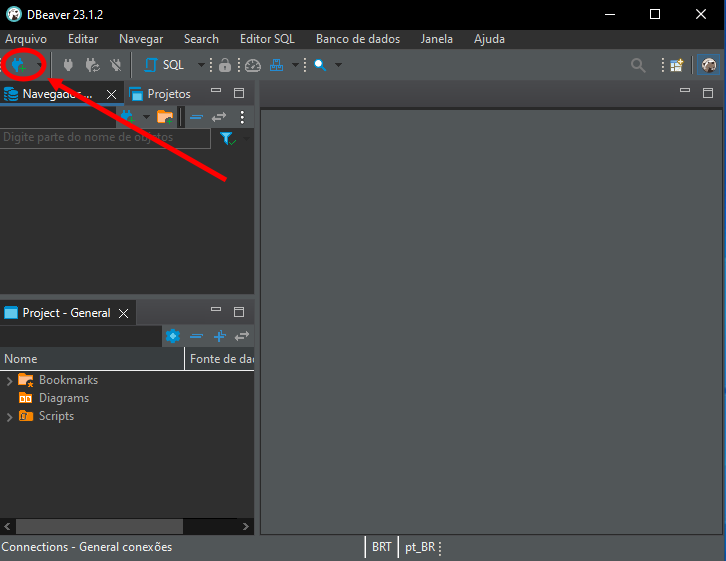
Imagem 02
Assim você será direcionado a uma nova janela vista logo abaixo.
Imagem 03
Aqui você deverá selecionar o tipo de banco de dados a ser visualizado. Lembre-se de que o nosso banco de dados é do tipo SQLite. Então procure ele e o selecione como mostrado logo abaixo.

Imagem 04
Ok, agora você será apresentado a seguinte janela.
Imagem 05
Aqui você deverá colocar o caminho e o nome do banco de dados a ser aberto, como você pode ver logo a seguir.
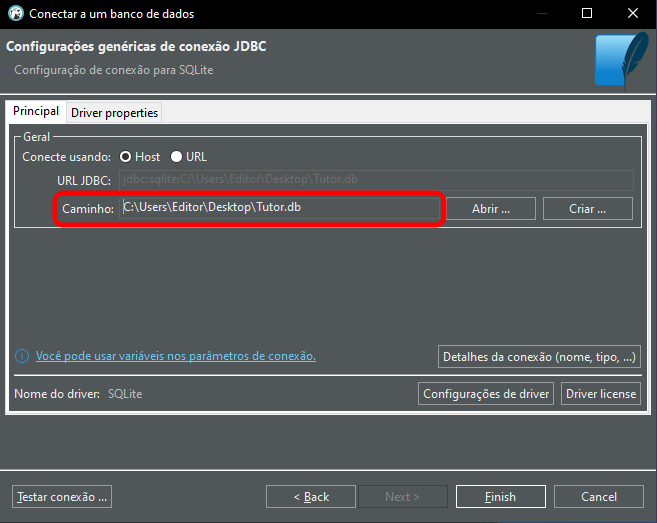
Imagem 06
Feito isto, clique em Finish e uma última tela lhe será apresentada.
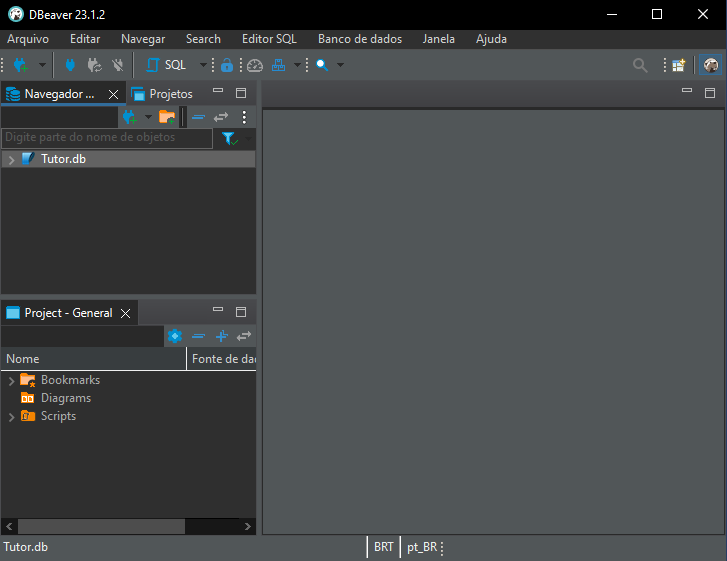
Imagem 07
Se você fez tudo certo, você irá ver isto que podemos observar na imagem 07. Onde nosso banco de dados está pronto para ser trabalhado. Assim, finalmente podemos abrir o diagrama, clicando nos pontos destacados logo abaixo.
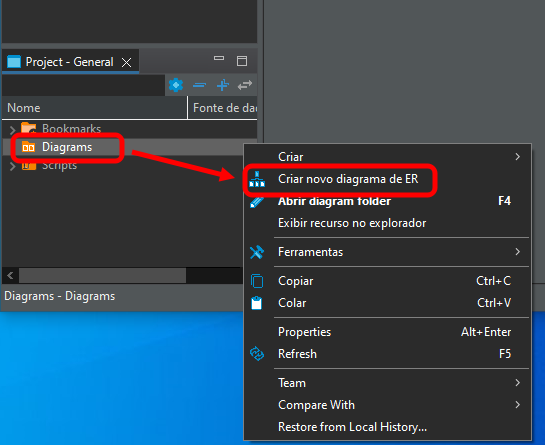
Imagem 08
Isto abrirá uma janela que você pode ver a seguir.
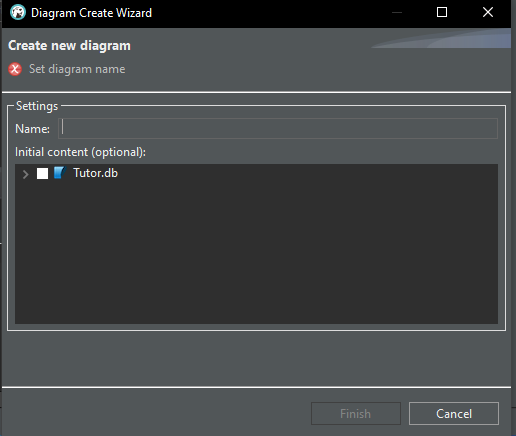
Imagem 09
Agora dê um nome ao diagrama que será criado, como pode ser visto na imagem abaixo. Você pode dar qualquer nome que desejar.
Imagem 10
E finalmente clicando em Finish, o resultado será o que é visto logo abaixo.
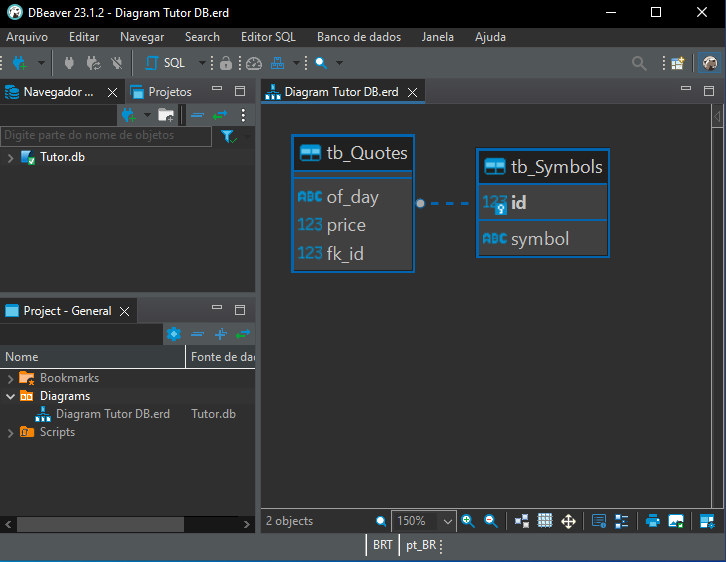
Imagem 11
Entendendo o que o diagrama representa
Na imagem 11, podemos ver claramente que existe uma relação entre a tabela tb_Quotes e a tabela tb_Symbols. Mas talvez você ache que esta relação é de um para um. Ou seja, para cada registro na tabela tb_Symbols, existirá um registro correspondente na tabela tb_Quotes. Bem, isto pode até acontecer, em alguns cenários. Mas observe uma coisa neste diagrama. É algo bastante sutil, porém importante. Na imagem abaixo temos exatamente o ponto, a ser observado, sendo destacado.
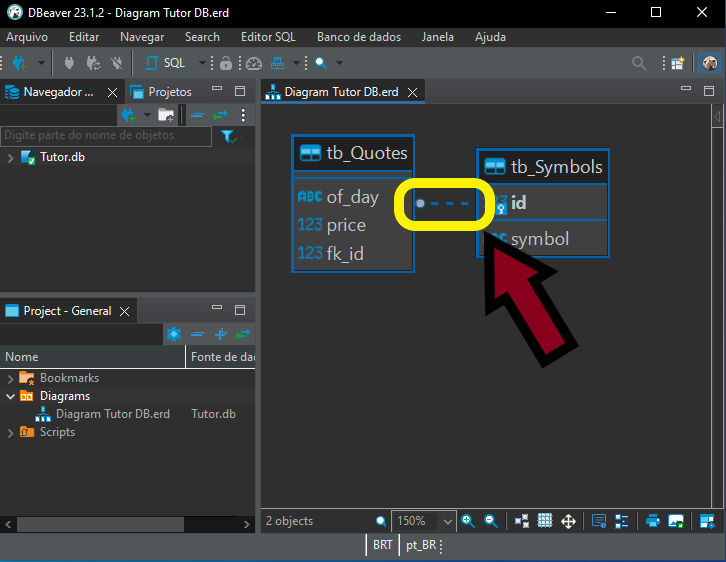
Imagem 12
Observe que de um lado temos uma bolinha e o outro não temos nada. Preste muita atenção a isto. Mas o que isto significa? Bem isto indica uma relação de um para muitos. Ou seja, no lado, ou tabela em que a bolinha se encontra, podemos ter muitos registros para cada um dos registros da tabela em que este traço esteja sendo ligado. Saber interpretar corretamente este tipo de coisa, irá lhe permitir fazer uma pesquisa de maneira mais adequada. Assim como também, permitirá que você faça modificações ou mudanças no banco de dados de uma forma bem mais simples e sem erros.
Isto por que, o fato de termos em uma tabela algum registro, que poderá se repetir muitas vezes em uma, ou diversas outras tabelas. Nos ajudará a entender e a projetar adequadamente o funcionamento de gatilhos, seja para adicionar novos dados, remover algum registro, ou mesmo atualizar alguma informação no banco de dados. Mas isto é tema para um outro momento. O que precisamos neste momento, é entender como este tipo de ligação pode nos ajudar a visualizar adequadamente o que está no banco de dados.
Traduzindo as coisas para o SQL
Muito bem, até o momento, tudo que fizemos foi ver como produzir o diagrama do banco de dados. Agora vamos voltar ao DB Browser, lembrando que você também poderá usar o MetaEditor ver o mesmo tipo de resultado que será visto aqui. E utilizar um código ligeiramente diferente para fazer a pesquisa no banco de dados. O código em questão é visto logo abaixo.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes, tb_Symbols;
Código 02
Assim ao executar este script, o SQL estará nos retornando 24 registros. Mas por que? Bem, vamos olhar o que aconteceu aqui. Observe na imagem abaixo o resultado da execução do código.
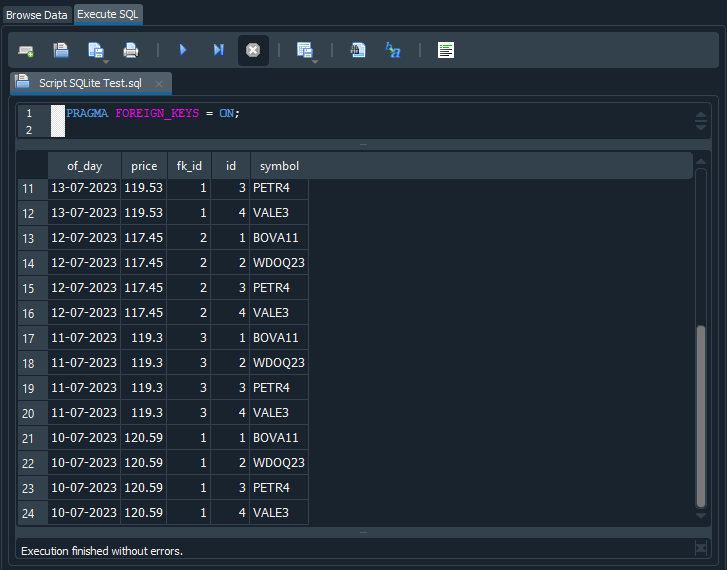
Imagem 13
Você pode notar que entre os registros das linhas 17 e 20, o mesmo valor tanto de cotação como data, estão se repetindo. Ou seja, o SQL, interpretou, que era para executar o comando select e que o conteúdo das tabelas tb_Quotes e tb_Symbols, deveria ser combinado de alguma forma. Por conta disto, temos valores sendo repetidos vindos da tabela tb_Quotes, quando o valor da tabela tb_Symbols está mudando. Já que temos seis registros na tabela tb_Quotes e quatro registros na tabela tb_Symbols. Assim ao combinar ambas tabelas, o SQL gera os 24 registros que nos são apresentados. Agora entenderam o motivo, do SQL nos apresentar 24 registros?
Mas observe uma coisa na imagem 13. Existem pontos em que o valor de fk_id é igual ao valor de id. Hum, isto é curioso, não é mesmo? Mas por que isto acontece? O motivo é que o valor do registro em fk_id, está nos dizendo qual é o valor que devemos procurar. Agora vamos voltar ao nosso diagrama visto na imagem 12. Lá vemos que o valor de id, está na tabela tb_Symbols e o valor de fk_id está na tabela tb_Quotes.
Bem, agora precisamos usar o que é conhecido como alias. Ou seja, precisamos criar um apelido para que possamos relacionar uma tabela com a outra. Isto para que o SQL, saiba como montar os dados, a fim de que eles sejam corretamente apresentados a nós. Para usar um aliás, ou apelido, temos que tomar o cuidado de não usarmos palavras reservadas. Algumas implementações, conseguem lidar com isto. Mas em geral, e até mesmo para evitar confusão por parte de outros programadores SQL. Evite usar palavras reservadas, como apelidos em código SQL. Assim o novo código a ser executado é visto logo abaixo.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * 32. FROM tb_Quotes AS tq, tb_Symbols AS ts 33. WHERE tq.fk_id = ts.id;
Código 03
Ao executarmos este código temos o resultado visto na imagem logo a seguir.
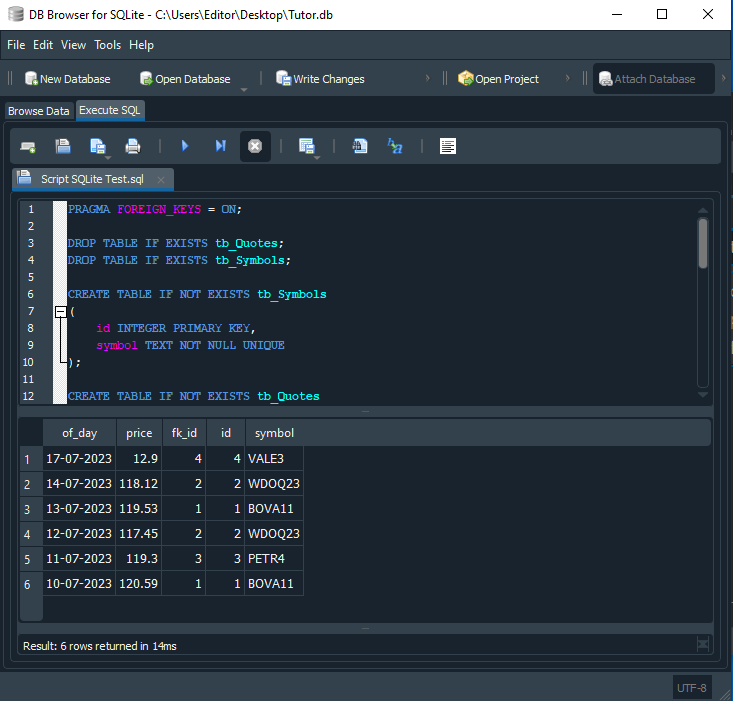
Imagem 14
Como por milagre, agora temos exatamente o que era esperado. Ou seja, podemos ver os seis registros de cotação indicando qual foi o ativo, a data e o preço do lançado. Agora vamos entender o porquê, de isto acontecer. Observe na linha 32 do script. Depois do nome de cada uma das tabelas, estamos adicionando um alias, para trabalhar com as tabelas.
Para que o SQL, saiba como ligar cada uma destas tabelas, e isto a fim de nos fornecer o resultado adequado. Usamos a linha 33. Nesta linha, temos a instrução WHERE, que diz qual o critério usado na filtragem ou montagem do resultado. No caso, queremos que quando o registro fk_id da tabela tb_Quotes, seja igual ao registro id da tabela tb_Symbol, o SQL anote o resultado para nos apresentar depois. Então o comando SELECT, irá varrer todas as possibilidades de combinações. Como foi visto anteriormente. Porém, devido ao filtro, o SQL irá nos retornar apenas o que realmente foi pedido.
Um detalhe nesta explicação dada acima. Na verdade, o SQL não irá varrer todas as possibilidades, ou combinações entre as tabelas. Este tipo de coisa iria fazer com que o mecanismo de pesquisa viesse a degradar muito rapidamente a performance geral do sistema. No bem da verdade, o que acontece é que o SQL usará uma das tabelas para começar a criar os resultados, daí ele buscará na outra tabela os campos necessários para fazer as devidas comparações e ajustes. Desta maneira, a pesquisa é efetivada de forma muito mais eficiente.
Podemos melhorar ainda mais o que o SQL está nos retornando. Não é raro, termos colunas, com nomes bastante estranhos, e outras vezes, como você viu na imagem 14, o SQL retornar colunas que não queremos. Como fazer para filtrar este tipo de coisa? Simples. Bastará dizer ao SQL quais colunas queremos e também qual o nome que elas deverão ter. Assim chegamos ao script visto abaixo.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Data da cotação', 32. tq.price AS 'Preço Atual', 33. ts.symbol AS 'Nome do Ativo' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id;
Código 04
Agora o resultado é o que podemos ver logo abaixo.
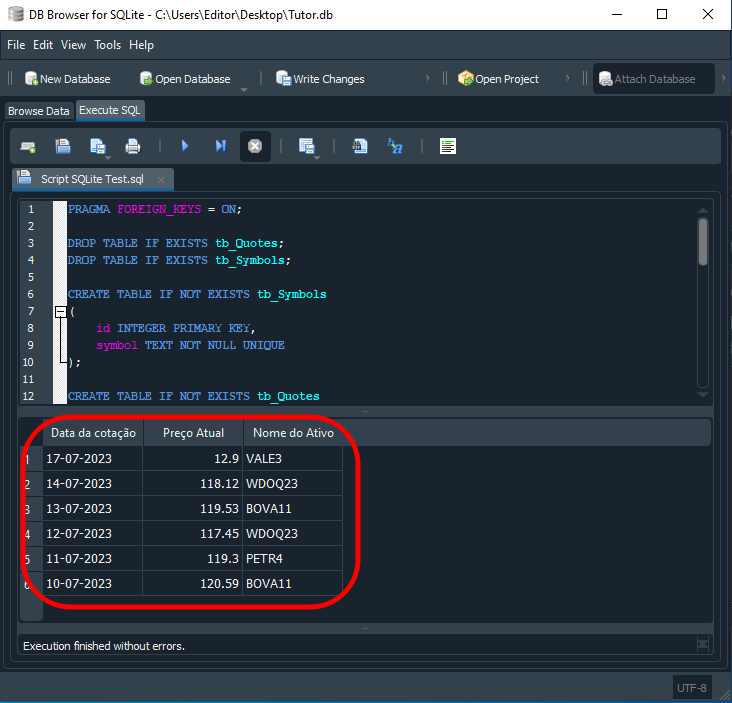
Imagem 15
Caramba. Então o SQL não é bem o que eu imaginava? Sempre achei que ele era um monte de instruções sem muito sentido. Mas agora vejo que de fato ele pode ser bem interessante. Mas isto daqui é apenas um aperitivo. Muitos acham que precisamos de uma programação externa para tratar ainda mais as informações a nos serem reportadas. Mas, você pode fazer isto diretamente no SQL. Como por exemplo: Vamos supor que você queira os dados em uma certa ordem. Onde os preços maiores ficam no início e os menores mais no final. Para fazer isto usamos um código como o visto logo abaixo.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Data da cotação', 32. tq.price AS 'Preço Atual', 33. ts.symbol AS 'Nome do Ativo' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id 36. ORDER BY price DESC;
Código 05
E o resultado deste código 05 ao ser executado pelo SQL será o que podemos ver logo abaixo.
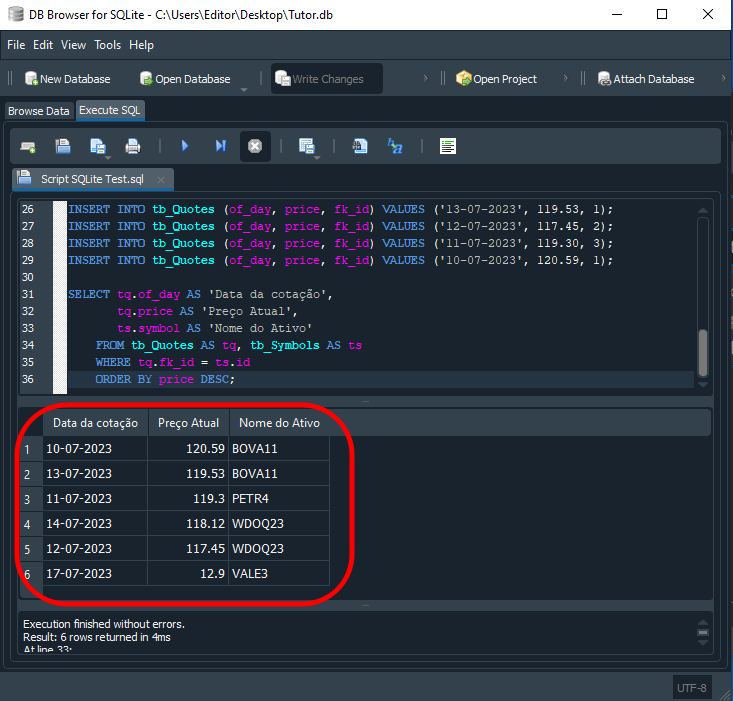
Imagem 16
Cuidado com os registros
No artigo, Simulação de mercado (Parte 19): Iniciando o SQL (II), expliquei como você poderia modificar ou atualizar registros, usando o comando UPDATE e o comando DELETE. Apesar de aquilo funcionar, não é o melhor modo de trabalhar com banco relacional. Já que aquela forma é muito sujeita a erros. Quando temos diversas tabelas se relacionando entre si. Para entender o problema, vamos voltar ao código 05. O que iremos fazer é algo bem simples. Note que até a linha 29, criamos o banco e adicionamos coisas a ele. Não importa se os dados estão corretos. Apenas queríamos criar o banco. Assim ao executar o SELECT na linha 31 temos o resultado visto a seguir.
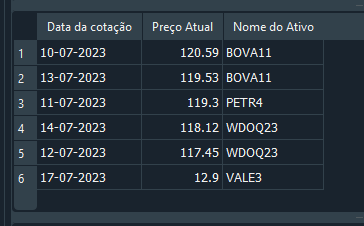
Imagem 17
E neste momento você nota que existe um registro errado. Mas em vez de recriar todo o banco, ou apagar o registro, você decide usar o comando UPDATE, para atualizar o valor para o correto. Isto é feito como mostrado logo abaixo.
1. UPDATE tb_Quotes SET price = 29.58 WHERE fk_id = 3; 2. 3. SELECT tq.of_day AS 'Data da cotação', 4. tq.price AS 'Preço Atual', 5. ts.symbol AS 'Nome do Ativo' 6. FROM tb_Quotes AS tq, tb_Symbols AS ts 7. WHERE tq.fk_id = ts.id 8. ORDER BY price DESC;
Código 06
Obtendo assim o resultado visto logo abaixo.
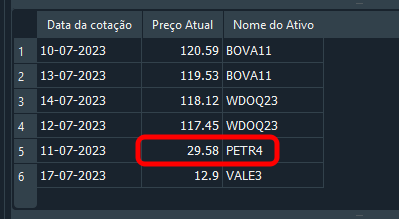
Imagem 18
Ok. O registro foi atualizado, e você se sente feliz, imaginando já saber trabalhar com o SQL. Porém, observe o código 05, onde incluímos de dados no banco. Você pode notar que existe apenas um único registro de PETR4. Então a informação seria facilmente modificada, ou mesmo removida. Mas vamos pensar um pouco. E se no lugar de PETR4, você precisa-se modificar o registro do WDOQ23. Como você faria esta modificação? Você pode logo dizer: Simples, eu usaria o seguinte comando:
01. UPDATE tb_Quotes 02. SET price = 119 03. WHERE fk_id = 2 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Data da cotação', 07. tq.price AS 'Preço Atual', 08. ts.symbol AS 'Nome do Ativo' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Código 07
Novamente, você está correto, já que o resultado é o que podemos ver logo abaixo. Isto por conta que você, de forma inteligente, filtrou a resultado baseando-se no fk_id e no of_day.
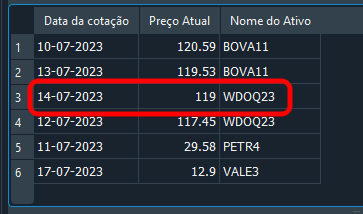
Imagem 19
Atualizando um registro em um banco relacional
Uma boa forma, se bem que não a única, de fazer uma edição em um banco relacional. É você entender o que cada comando em SQL faz. Ou melhor dizendo: Se você não compreender, os comandos em SQL, achará que SQL é uma linguagem extremamente limitada. Mas se você entender, conseguirá fazer muita coisa. E quando digo muita. É de fato, muita coisa mesmo. Já vi gente, usando programação externa para resolver coisas que poderiam ser resolvidas diretamente usando SQL. O motivo de a pessoa fazer isto, é pelo fato de ela não entender adequadamente como o SQL funciona. Sendo assim, vamos entender como fazer a mesma mudança feita no tópico acima, mas desta vez, não iremos precisar digitar o valor para o fk_id.
Neste ponto você deve estar pensando: Vamos então usar um sistema de tabelas não relacional? Não, meu amigo leitor. Iremos manter o banco relacional. Assim, para atingir o mesmo objetivo alcançando no tópico anterior, vamos atualizar o código 07 para o que é visto logo abaixo.
01. UPDATE tb_Quotes 02. SET price = 4985.5 03. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Data da cotação', 07. tq.price AS 'Preço Atual', 08. ts.symbol AS 'Nome do Ativo' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Código 08
Cara, que doideira é esta? Você tem certeza que isto funciona? Pois eu nunca vi, alguém fazer algo tão maluco. De fato, seu ceticismo é adequado, meu caro leitor. Mas veja o resultado logo abaixo.
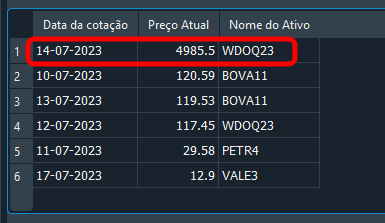
Imagem 20
Note que coloquei um valor bastante diferente, justamente para mostrar que dá certo. Então a questão é: Como o código acima funciona? Observe que não estou em ponto algum, dizendo qual é a fk_id ou qual o id a ser procurado. Mas mesmo assim, o registro correto está sendo modificado. O que estou fazendo é informar o nome do ativo, assim como da data em questão. Já que estou informando o nome do ativo, assim como a data em questão. Um detalhe importante aqui: Apesar de cada registro conter uma data diferente. Você deve pensar, as coisas de uma forma mais realista. Ou seja, mesmo em uma data parecida, podemos ter no banco de dados, ativos com contações diferentes. Assim sendo, usar uma filtragem dupla, onde informamos a data e o ativo. Torna a pesquisa consideravelmente mais precisa. Retornando exatamente a informação procurada.
Não sei se você conseguiu perceber. Mas acabo de explicar como o código visto acima funciona. Se você não conseguiu entender, ou captar a mensagem. Não se sinta mal. De fato, é difícil pegar as coisas assim logo de cara. Mas vamos entender calma o que está ocorrendo neste código 18. Observe que o comando UPDATE, foi colocado em diversas linhas. Fiz isto de forma proposital, para conseguir explicar o que está acontecendo.
Muito bem, na linha 01 dizemos que queremos atualizar um registro na tabela tb_Quotes. Se no lugar do UPDATE, tivéssemos informando DELETE. O registro seria deletado da tabela. Então tudo que irei explicar, também serve para remover registros. Já na linha dois, estou dizendo exatamente, qual a coluna que será atualizada. Assim como também o valor que deverá constar na coluna, depois da atualização. Até neste ponto, acredito que todos estão conseguindo acompanhar. Agora na linha três, usando a palavra reservada WHERE, para podemos informar qual é o critério de filtragem, a fim de que o SQL, saiba como encontrar o registro correto. Pois bem, agora preste muita atenção. Pois é aqui que mora a parte que muitos iniciantes não conseguem entender.
Cada um destes comandos, são na verdade funções. Ou seja, eles retornam valores. Pode ser um valor único, ou pode ser um valor composto. Contendo neste caso, diversos outros valores ou campos. Então quando usamos o comando SELECT, podemos ter como retorno um valor único, como é o caso aqui. Mas também podemos ter um retorno com múltiplos valores, contidos dentro de algo que seria uma tabela. Justamente como acontece, quando o comando SELECT é executado na linha seis.
Quando a filtragem é feita de uma forma bem específica, e em uma tabela igualmente específica. O comando SELECT retorna algo que será único. Podendo assim este retorno ser entendido como sendo uma variável. Mas espera um pouco. O SQLite não nos permite implementar variáveis. Certo? Bem, mais ou menos. Porém, se você souber como manipular o SQL, e não somente o SQLite, você poderá virtualmente ter variáveis dentro do código SQL. Esta questão será melhor compreendida depois. Já que precisaremos fazer uma outra coisa, quando usamos tabelas relacionadas. Isto para manter o banco de dados consistente.
Mas voltando a explicação, veja que nesta linha três, estamos dizendo qual o nome do ativo. No caso o WDOQ23. Isto faz com que o SQL, pesquise na tabela tb_Symbols, que estamos indicando no comando SELECT, a procura de algo. O que é este algo? Este algo é o valor ts.id. Ou seja, quando a pesquisa for concluída o SELECT irá retornar o valor de registro, da coluna id, onde o nome do ativo é WDOQ23. Hum, interessante. Então, o SQL irá procurar em uma tabela, o valor que nos diz qual é o que deveremos procurar na outra tabela? Isto a fim de conseguir encontrar o registro correto, no qual queremos fazer a modificação. É isto? Sim. É justamente isto que estamos fazendo, aqui meu caro leitor. Note que a probabilidade de erro aqui é consideravelmente muito menor.
Porém nem tudo é perfeito. Pois pode acontecer, de você informar um nome de ativo, cujo id não será encontrado. Apesar de parecer algo raro, este tipo de situação é bastante comum no dia a dia. Assim sendo, este código 08 não saberá tratar adequadamente este tipo de situação. Ou para que fique mais claro. Você pode tentar fazer algo e o SQL não lhe diz que está errado. Ou que não foi devidamente compreendido pelo SQL. E você fica imaginando que tudo ocorreu perfeitamente bem. Já que teremos como resultado a apresentação do resultado da execução do comando SELECT da linha seis.
Neste momento, você talvez não entenda como isto é problemático. Já que se a implementação, não indicar algo errado, você ficará na ilusão de que tudo está perfeito. Mas quando vai, em um momento futuro, pesquisar, ou mesmo usar aqueles dados, que você imaginava estar ali. Terá uma desagradável surpresa ao ver que as informações não constam, como era esperado. E muitas das vezes é impossível reaver a informação correta, a fim de solucionar adequadamente este tipo de falha.
Verificando se o registro foi atualizado
Para verificar se um registro, no qual você deseja atualizar. Foi ou não atualizado com sucesso. Existe uma forma, relativamente simples de se fazer isto no SQLite. Para isto, precisaremos usar um pequeno código. Mas antes de ver o código, precisamos pensar sobre algo. Não é raro, muitos dizerem que depois de fazer uma atualização, ou mesmo inserir algum registro no banco de dados. Deveríamos fazer um SELECT para analisar se tudo ocorreu bem. Existe um pequeno problema nesta abordagem. Se você estiver tratando com um banco pequeno. Ou que, por qualquer motivo, foram feitas poucas alterações. Usar um SELECT a fim de verificar se tudo ocorreu como esperado. É sim uma forma adequada de analisar se o banco foi ou não atualizado com sucesso. Porém, e principalmente em bancos compartilhados, se você tiver que fazer uma atualização de diversos registros a coisa não será muito simples de verificar com o uso de um SELECT.
Felizmente tais bancos compartilhados, fazem uso de servidores. Sendo assim o SQLite não se enquadraria nesta situação. Mas mesmo em um banco que usa o SQLite, pode ocorrer, em algum momento que você tenha que atualizar centena ou mesmo milhares de registros. Pense só em todo o trabalho para analisar um a um, usando o SELECT para verificar se o banco foi ou não corretamente atualizado. É justamente esta questão que nos faz tomar algum tipo de medida diferente. Verificar um a um os registros atualizados, é algo perfeitamente aceitável, quando fazemos poucas mudanças no banco de dados.
Porém, conforme a carga de trabalho, vai se intensificando e a quantidade de operações vai aumentando, precisamos adotar outra forma de fazer as coisas. Além da maneira que irei mostrar daqui a pouco, existe uma outra forma quase equivalente. Mas iremos ver isto depois. Neste momento, vamos focar no primeiro objetivo. Ou seja, como podemos de alguma forma, usando o SQLite, saber se todos os pedidos de atualização de registros, foram ou não executados.
Para fazer isto, a solução é bastante simples. Porém, você deve tomar algum cuidado. Isto para evitar gerar algum tipo de falha pelo mal-uso do que irei mostrar. O código de demonstração pode ser visto logo abaixo.
1. UPDATE tb_Quotes 2. SET price = 4987.5 3. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 4. AND of_day = '14-07-2023'; 5. 6. SELECT changes() 'Updated Records';
Código 09
Ao executar este código você verá o seguinte resultado.
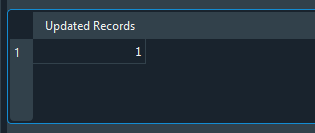
Imagem 21
Repare no fato de que estamos tendo como resultado, o valor de um. Por que? O motivo é que a instrução UPDATE, está realizando uma única atualização ou modificação no banco de dados. Se você executasse centenas ou mesmo milhares de atualizações. O valor mostrado, seria exatamente a quantidade de vezes que a instrução UPDATE obteve sucesso. Porém observe o seguinte fato. Se neste mesmo código mostrado acima, fosse modificado para o que é mostrado na figura abaixo, o resultado seria outro. Como você pode ver na mesma imagem.
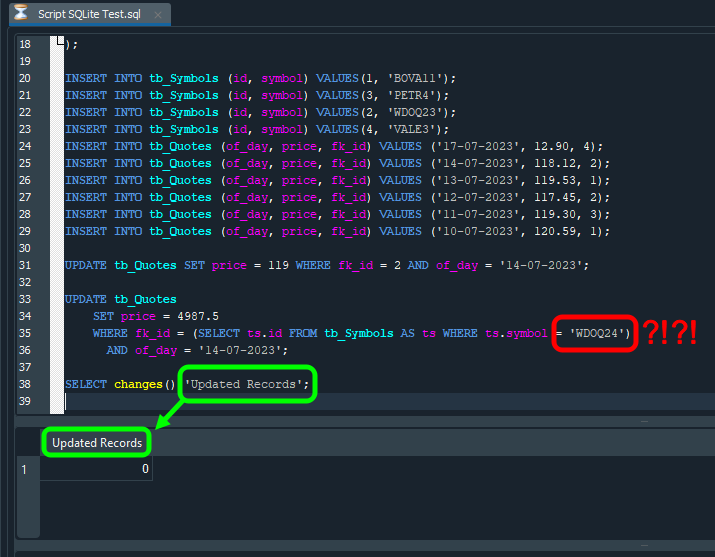
Imagem 22
Nesta imagem, destaquei em vermelho o que foi modificado, frente ao que você pode ver sendo feito antes. Note que a única mudança foi o nome do ativo. E como ele não existe, o comando SELECT, não conseguirá dizer qual o id a ser utilizado. Assim, o comando UPDATE, não conseguirá ser executado pelo SQL. Por fim, quando formos usar o comando SELECT que tem como objetivo verificar a quantidade de UPDATES que foram corretamente executados. Este retornará uma quantidade diferente da que esperávamos. No caso zero, já que esperávamos que um UPDATE fosse executado. No entanto, por conta do fato de termos indicado um nome de um ativo inexistente na tabela. Nenhum UPDATE foi executado.
Existe um outro detalhe na imagem acima. Este está sendo destacado em verde. O que estou querendo dizer neste ponto, é que, o cabeçalho do que, estará sendo reportado pelo SQL, é justamente a informação que se encontra no comando SELECT. Sem saber disto, você poderia ficar tentado a fazer as coisas de uma maneira diferente. Mas como você pode notar, podemos controlar diversas coisas, com uma certa facilidade.
No entanto, como informei, este comando que estamos fazendo uso aqui, tem como objetivo, apenas verificar a quantidade de vezes que um comando foi ou não executado corretamente. Já que o SQLite, nos permite desenvolver um tipo de banco de dados local e personalizado. Podemos fazer as coisas e uma forma totalmente diferente.
E sim, para quem não sabe, o SQLite pode ser baixado diretamente do reportório do GITHub e ter seu código fonte modificado, para que possamos fazer com que ele trabalhe de uma maneira ligeiramente diferente do que seria o usual. Como o propósito desta série, não é de fato mostrar como fazer isto, estou apenas mencionando neste fato. Já que dependendo da implementação que você estiver utilizando. No caso específico do SQLite. Pode ser que a sua implementação trate as falhas de atualização, ou acréscimo de novos registros de uma maneira completamente diferente da que irei mostrar. Ou seja, para encontrar a melhor forma se fazer as coisas, sugiro você estudar a documentação da implementação que você estiver tentando utilizar.
Mas antes de passarmos para o próximo assunto, vamos ver um detalhe, sobre esta forma que apresentei de testar se ocorreu ou não as atualizações no banco de dados. Esta combinação SELECT change(), somente nos mostrará o resultado, da última execução do comando UPDATE, no caso. Então vamos supor o seguinte: Você utiliza o seguinte fragmento mostrado abaixo.
1. UPDATE tb_Quotes SET price = 119 WHERE fk_id = 2 AND of_day = '14-07-2023'; 2. 3. UPDATE tb_Quotes SET price = 4987.5 WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ24') AND of_day = '14-07-2023'; 4. 5. SELECT changes() 'Updated Records';
Código 10
Note que agora temos dois comandos UPDATES sendo executados. Obviamente você espera que venha um resultado acumulativo, ou que seja representativo de alguma forma. Já que teoricamente estamos usando um mesmo script. Pois bem, as coisas não funcionam desta maneira. Preste muita atenção ao código da linha três, e você notará que é exatamente o mesmo visto na imagem 22. Então tudo que foi adicionado neste código 10, é a linha um. Ok. Então mesmo pelo fato de que a linha três, venha a falhar, e falhará. Teríamos na execução da linha cinco, o retorno de um valor diferente de zero. Mas ao executar o código, você nota que o valor informado pelo SQL foi zero. O que aconteceu de errado? Será que ambas linhas, tanto a linha um quanto a linha três falharam na sua execução? Não, elas não falharam. Apenas a linha três que realmente falhou.
Mas como, antes de analisar o resultado da execução da linha um, fizemos um novo requerimento ao SQL, na linha três. Quando formos pedir ao SQL para nos dizer o que aconteceu, ele reportará apenas o resultado da última operação. Ou seja, justamente a falha na linha três. Algumas pessoas costumam ficar completamente loucas e ensandecidas ao tentar entender por que um script está ou não funcionando como o esperado. Mas tudo tem haver, com o fato, de você muito provavelmente esteja fazendo suposições. Quando, começamos a fazer suposições em programação, as coisas não costumam dar muito certo. Já que suposições indicam que você simplesmente espera que as coisas aconteçam e não que você garante que elas acontecerão. Assim, nunca faça suposições. Garanta que as coisas funcionam, antes de começar a lançar ofensas de DEUS até o DIABO.
Considerações finais
Mas de qualquer maneira, existe um outro fato, ou fardo que precisamos ainda resolver. Isto quando fazemos uso de bancos, ou tabelas relacionadas. Como a que estamos usando neste sistema. Onde em uma tabela colocamos os nomes dos ativos, e em outra tabela colocamos os dados referentes a cotações. Tal esquema poderia ser muito mais elaborado e com diversas ligações. Fazendo uso de diversas tabelas que estariam e manteriam uma relação íntima entre elas. Tudo isto, fazendo uso das chaves primárias e chaves estrangeiras.
Para entender o nível do problema, ou o tamanho do caroço que temos de enfrentar. Quero que você pense e imagine o seguinte cenário: Em um dado momento no futuro, é decidido que um determinado ativo não será mais mantido. Isto por conta que ele já não é mais interessante de ser mantido ou observado. Ok. Este tipo de decisão pode acontecer, mais hora ou menos hora. O grande problema, e é aqui que nos deparamos com o caroço no mingau, é: Como remover os registros do ativo do banco de dados? Bem, muitos pode dizer, que a solução é simples. Você simplesmente faz algum tipo de loop, ou algum requerimento para que o SQL remova os registros para você. Sim, de fato seria mais ou menos isto. Se você estiver trabalhando com um banco de dados, onde temos apenas uma única e imensa tabela de registros. O que ao meu ver é uma tremenda de uma insanidade. Mas tudo bem, cada um sabe, ou deveria saber o que está fazendo.
Requerer junto ao SQL que todos registros de um dado ativo, sejam apagados seria uma tarefa super simples. Tudo que você precisaria fazer seria um DELETE. O comando em sim, iria se parecer bastante com o comando UPDATE. Algo trivial que não irei entrar em detalhes aqui. Mas e se, o banco de dados não fizer uso de uma tabela. Mas sim de diversas tabelas que estão de alguma forma relacionadas entre si. Como você poderia remover todos os registros de um determinado ativo? Hum. Agora a coisa começou a ficar um pouco mais complicada, não é mesmo?
Isto por que, e agora quero que você pense no esquema que estamos usando. Se você removesse o nome do ativo, da tabela tb_Symbols, com certeza no momento que fosse pesquisar no banco de dados, você teria um certo resultado. Isto usando o comando logo abaixo.
SELECT tq.of_day AS 'Data da cotação', tq.price AS 'Preço Atual', ts.symbol AS 'Nome do Ativo' FROM tb_Quotes AS tq, tb_Symbols AS ts WHERE tq.fk_id = ts.id ORDER BY price DESC;
Código 11
| Arquivo | Descrição |
|---|---|
| Experts\Expert Advisor.mq5 | Demonstra a interação entre o Chart Trade e o Expert Advisor (É necessário o Mouse Study para interação) |
| Indicators\Chart Trade.mq5 | Cria a janela para configuração da ordem a ser enviada (É necessário o Mouse Study para interação) |
| Indicators\Market Replay.mq5 | Cria os controles para interação com o serviço de replay/simulador (É necessário o Mouse Study para interação) |
| Indicators\Mouse Study.mq5 | Permite interação entre os controles gráficos e o usuário (Necessário tanto para operar o replay simulador, quanto no mercado real) |
| Services\Market Replay.mq5 | Cria e mantém o serviço de replay e simulação de mercado (Arquivo principal de todo o sistema) |
| Code VS C++\Servidor.cpp | Cria e mantém um soquete servidor criado em C++ (Versão Mini Chat) |
| Code in Python\Server.py | Cria e mantém um soquete em python para comunicação entre o MetaTrader 5 e o Excel |
| Indicators\Mini Chat.mq5 | Permite implementar um mini chat via indicador (Necessário uso de um servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar um mini chat via Expert Advisor (Necessário uso de um servidor para funcionar) |
| Scripts\SQLite.mq5 | Demonstra uso de script SQL por meio do MQL5 |
| Files\Script 01.sql | Demonstra a criação de uma tabela simples, com chave estrangeira |
| Files\Script 02.sql | Demonstra a adição de valores em uma tabela |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso