
中央銀行のバランスシートデータからグローバル流動性を読み解く

21世紀の金融危機、すなわち2008年の住宅ローン危機から2020年代のパンデミックによる混乱に至るまでの出来事は、ゲームのルールを根本的に変化させました。中央銀行はもはや金利調整という限定的な役割にとどまりません。その手段は大きく拡張され、社債購入、銀行への直接融資、通貨スワップ、さらには政府支出の資金調達支援といった非伝統的な手法を含むようになりました。これらの措置は強力なポンプのように、世界経済へ流動性を注入したり、逆に吸収したりします。そしてその影響は、金融政策を映し出す中央銀行のバランスシートに反映されます。
本記事は単なる中央銀行バランスシート分析の解説ではありません。むしろ、生の流動性データを価値ある為替予測へと変換する「錬金術の坩堝(るつぼ)」のようなシステム構築を探求するものです。米連邦準備制度(Fed)、欧州中央銀行(ECB)、日銀(BOJ)、および中国人民銀行(PBoC)の情報を統合し、グローバル流動性の複合インデックスを作成します。そして機械学習とテクニカル分析を組み合わせ、従来の手法では見逃されがちな隠れたパターンを発見する方法を検討します。さらに、このシステムを実取引に統合し、抽象的なデータを具体的な売買判断へと変換する方法も示します。
従来のテクニカル分析は、チャートやインジケーターを用いるものの、雲だけで天気を予測するのに近いと言えます。一方でファンダメンタル分析はマクロ経済への深い理解を必要とし、短期売買には必ずしも適していません。本アプローチはこの二つの世界を結び付け、流動性データを短期的な値動きと長期トレンドの両方を理解する鍵へと変えます。
理論的基礎:世界経済の鼓動としての流動性
グローバル流動性は単に流通している資金量ではありません。それは世界経済の「血流」とも言える複雑なシステムであり、通貨供給量、金融商品、そして資本の自由な移動を支える仕組みを包含しています。狭義には、流動性とは資産が価値を損なうことなく迅速に現金へ換金できる能力を指します。しかしグローバルな観点では、資本が国境、市場、セクター間をどれだけ容易に移動できるかを反映しています。こうした資本移動そのものが、強力な長期トレンドを生み出す可能性を持っています。
Fed、ECB、BOJ、PBoCといった中央銀行は、このオーケストラを指揮する存在です。彼らのバランスシートは単なる会計報告ではなく、資産購入や融資などを通じて経済にどれだけ資金を供給したかを示す指標です。たとえばFedが国債を購入すれば、そのバランスシートは拡大し、新たな流動性が創出されます。一方でECBが準備預金要件を引き上げれば、流動性は吸収され、資金の流れは縮小します。
量的緩和や資産購入による中央銀行バランスシートの拡大は、通常その国の通貨を弱める傾向があります。これは主に二つの理由によります。第一に、マネーサプライの増加は需給の法則により通貨価値を低下させます。第二に、そのような政策は金利低下を伴うことが多く、利回りを求める投資家にとって通貨の魅力を低下させるためです。
しかし、この関係は単純ではありません。もし主要中央銀行が同時にバランスシートを拡大すれば、為替への影響は相殺される可能性があります。すべての通貨が同時に「インフレ」するような状態になるためです。この場合の重要な要素は相対的な勢いです。例えば日銀がFedよりも速いペースでバランスシートを拡大すれば、円はドルに対して弱くなる可能性が高くなります。
流動性が金融システムにどのように伝播するかを理解することは、予測において極めて重要です。主な伝達チャネルには以下があります。
- 金利チャネル:中央銀行の利下げはマネーサプライを増加させ、通貨建て資産の利回りを低下させ、通貨を弱めます。
- ポートフォリオチャネル:中央銀行の大量資産購入は投資家の資産構成を変化させ、代替投資先への移動を促します。
- 信用チャネル:信用条件の改善は経済活動を刺激し、通貨フローに影響を与えます。
- 期待形成チャネル :中央銀行のコミュニケーションや先行シグナルは実際の行動前から市場期待を形成します。
将来の政策期待が、将来のトレンドを生み出します。では次に、この点をさらに詳しく見ていきます。
情報透明性の時代において、中央銀行はコミュニケーションの達人となっています。声明、記者会見、経済見通しは単なる言葉ではなく、市場期待を形成する強力なツールです。Fed議長が金融引き締めを示唆すると、市場は正式決定前からドル相場に反応し始めることがあります。流動性分析では、バランスシートの数値だけでなく当局者の発言姿勢も考慮する必要があります。これは実際の政策と同様に重要となり得ます。
システムアーキテクチャ:金融の未来を設計する
本システムは単一の巨大な構造ではなく、明確に定義された機能をそれぞれが担う、注意深く組み上げられたモザイクのような構成です。GlobalLiquidityMinerは中央銀行のバランスシートデータを収集・処理し、雑多なデータを整合性のある時系列データへと変換します。ForexLiquidityForecasterはこのデータを利用し、テクニカル指標で拡張した上で機械学習アルゴリズムに投入し、精度の高い予測を生成します。このアプローチにより、システム全体を停止することなく個別コンポーネントを更新でき、新しいデータソースや市場環境への適応も可能になります。
金融市場は、短期的なトレーダー心理と長期的なマクロ経済トレンドが絡み合う複雑適応系です。本アーキテクチャはこの二重性を反映し、高速なテクニカルシグナルと深いファンダメンタル要因を組み合わせています。
GlobalLiquidityMinerモジュールはデータ収集システムの中核を担います。このモジュールは、FedのFRED APIからBOJの複雑なデータ形式、そして限定的なPBoCデータまで、さまざまなソースを扱います。その主な目的は単なるデータ取得ではなく、分析可能な形へ標準化することです。各中央銀行は異なる頻度(Fedは週次レポート、PBoCは四半期データなど)および異なる通貨単位でデータを公開しています。そのため本モジュールは欠損値を補間し、指標を正規化し、時系列データを同期させます。
import pandas as pd import logging from typing import Dict from fredapi import Fred import yfinance as yf import requests from io import StringIO logger = logging.getLogger(__name__) class GlobalLiquidityMiner: def __init__(self, fred_api_key: str, start_date: str, end_date: str): self.fred = Fred(api_key=fred_api_key) if fred_api_key else None self.start_date = start_date self.end_date = end_date self.data_cache = {} def fetch_central_bank_balance_sheets(self) -> Dict[str, pd.DataFrame]: """Obtaining central bank balance sheet data.""" balance_sheets = {} if self.fred: logger.info("Loading Federal Reserve data...") try: fed_total_assets = self.fred.get_series('WALCL', start=self.start_date, end=self.end_date) fed_securities = self.fred.get_series('WSHOSHO', start=self.start_date, end=self.end_date) fed_loans = self.fred.get_series('WLRRAL', start=self.start_date, end=self.end_date) balance_sheets['FED'] = pd.DataFrame({ 'date': fed_total_assets.index, 'total_assets': fed_total_assets.values, 'securities_held': fed_securities.reindex(fed_total_assets.index, method='ffill').values, 'loans_and_repos': fed_loans.reindex(fed_total_assets.index, method='ffill').values, 'currency': 'USD' }) balance_sheets['FED']['assets_growth_rate'] = balance_sheets['FED']['total_assets'].pct_change(periods=52) balance_sheets['FED']['securities_share'] = balance_sheets['FED']['securities_held'] / balance_sheets['FED']['total_assets'] logger.info(f"Loaded {len(fed_total_assets)} Federal Reserve data entries") except Exception as e: logger.error(f"Error loading Fed data: {e}") self.data_cache['balance_sheets'] = balance_sheets return balance_sheets
このモジュールは、流動性データとテクニカル指標を組み合わせ、機械学習モデル用の特徴量を生成します。スライディングウィンドウを使用することで、流動性の変化がもたらす短期、長期双方への影響を考慮することができます。
from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score, mean_squared_error import numpy as np class ForexLiquidityForecaster: def __init__(self, liquidity_miner: GlobalLiquidityMiner): self.liquidity_miner = liquidity_miner self.models = {} self.scalers = {} def build_prediction_model(self, symbol: str, feature_df: pd.DataFrame): """ Training a forecasting model.""" targets = { f'return_{h}d': feature_df['close'].shift(-h) / feature_df['close'] - 1 for h in [1, 5] } feature_columns = [col for col in feature_df.columns if not col.startswith(('return_', 'volatility_', 'direction_'))] X = feature_df[feature_columns].dropna() train_size = int(len(X) * 0.8) X_train, X_test = X.iloc[:train_size], X.iloc[train_size:] models = {} for target_name, target_series in targets.items(): y = target_series.dropna() common_idx = X.index.intersection(y.index) X_aligned, y_aligned = X.loc[common_idx], y.loc[common_idx] scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_aligned.iloc[:train_size]) X_test_scaled = scaler.transform(X_aligned.iloc[train_size:]) model = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42) model.fit(X_train_scaled, y_aligned.iloc[:train_size]) test_pred = model.predict(X_test_scaled) test_r2 = r2_score(y_aligned.iloc[train_size:], test_pred) models[target_name] = {'model': model, 'scaler': scaler, 'r2': test_r2} self.models[symbol] = models self.scalers[symbol] = scaler
ForexLiquidityForecasterモジュールはシステムの頭脳であり、流動性データと市場指標が交わる部分です。このモジュールは Random Forest アルゴリズムを使用し、中央銀行のバランスシート、テクニカル指標(RSI、MACD、移動平均線)、および通貨ペアの値動きの間に存在する非線形な関係を特定します。特徴量は時間的なラグ(遅延)を考慮して生成されるため、流動性の変化による即時的な影響だけでなく、時間差を伴って現れる影響も捉えることができます。
from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score import numpy as np import pandas as pd class ForexLiquidityForecaster: def __init__(self, liquidity_miner: GlobalLiquidityMiner): self.liquidity_miner = liquidity_miner self.models = {} self.scalers = {} self.forecasts = {} def prepare_features(self, symbol: str, historical_data: pd.DataFrame) -> pd.DataFrame: """Create features for forecasting.""" df = historical_data.copy() # Technical indicators df['rsi_14'] = self.calculate_rsi(df['close'], 14) df['ema_50'] = df['close'].ewm(span=50).mean() df['volatility_20d'] = df['close'].pct_change().rolling(20).std() # Attaching liquidity data if 'balance_sheets' in self.liquidity_miner.data_cache: for bank, bs_data in self.liquidity_miner.data_cache['balance_sheets'].items(): df = df.join(bs_data[['total_assets']].rename(columns={'total_assets': f'{bank}_balance'}), how='left') df[f'{bank}_balance'].fillna(method='ffill', inplace=True) return df.dropna() def calculate_rsi(self, series: pd.Series, period: int = 14) -> pd.Series: """RSI calculation.""" delta = series.diff() gain = delta.where(delta > 0, 0).rolling(window=period).mean() loss = -delta.where(delta < 0, 0).rolling(window=period).mean() rs = gain / loss return 100 - (100 / (1 + rs)) def build_prediction_model(self, symbol: str, feature_df: pd.DataFrame): """ Training a forecasting model.""" targets = { f'return_{h}d': feature_df['close'].shift(-h) / feature_df['close'] - 1 for h in [1, 3, 5, 8] } feature_columns = [col for col in feature_df.columns if not col.startswith('return_')] X = feature_df[feature_columns].dropna() train_size = int(len(X) * 0.8) X_train, X_test = X.iloc[:train_size], X.iloc[train_size:] models = {} for target_name, target_series in targets.items(): y = target_series.dropna() common_idx = X.index.intersection(y.index) X_aligned, y_aligned = X.loc[common_idx], y.loc[common_idx] scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_aligned.iloc[:train_size]) X_test_scaled = scaler.transform(X_aligned.iloc[train_size:]) model = RandomForestRegressor(n_estimators=200, max_depth=15, random_state=42) model.fit(X_train_scaled, y_aligned.iloc[:train_size]) test_pred = model.predict(X_test_scaled) test_r2 = r2_score(y_aligned.iloc[train_size:], test_pred) models[target_name] = {'model': model, 'scaler': scaler, 'r2': test_r2} self.models[symbol] = models self.scalers[symbol] = scaler
実装編:データから行動へ
FRED APIは、Fedのバランスシートに関するデータの宝庫であり、総資産、保有証券、融資残高などの情報を提供しています。本コードは、リクエスト回数の制限などのAPI固有の制約に対応するとともに、異なる更新頻度で提供されるデータを同期する処理も実装しています。
def fetch_fed_data(self): """Obtaining Federal Reserve data via API FRED.""" try: fed_data = self.fred.get_series('WALCL', start=self.start_date, end=self.end_date) return pd.DataFrame({ 'date': fed_data.index, 'total_assets': fed_data.values, 'currency': 'USD' }).set_index('date') except Exception as e: logger.error(f"Error loading Fed data: {e}") return pd.DataFrame()
ECB(欧州中央銀行)のデータはStatistical Data Warehouseを通じて取得されます。また、データ取得サービスが停止した場合や利用できない場合には、EURUSDやEuro Stoxx 50といった代替指標(プロキシ指標)が使用されます。一方、データへのアクセスが制限されているBOJおよびPBoC については、流動性状況を間接的に反映する市場指標が利用されます。具体的には、日経225指数、USDJPY、および 中国国債市場の指標 などが用いられます。
def fetch_boj_proxy_data(self): """Obtaining BOJ proxy data.""" try: usdjpy = yf.download('USDJPY=X', start=self.start_date, end=self.end_date, progress=False) nikkei = yf.download('^N225', start=self.start_date, end=self.end_date, progress=False) proxy_balance = pd.DataFrame(index=usdjpy.index) proxy_balance['jpy_strength'] = 1 / usdjpy['Close'] proxy_balance['equity_liquidity'] = nikkei['Close'] / nikkei['Close'].rolling(252).mean() proxy_balance['synthetic_balance'] = proxy_balance['jpy_strength'].rolling(30).mean() * proxy_balance['equity_liquidity'] * 1000000 return proxy_balance except Exception as e: logger.error(f"Error loading BOJ data: {e}") return pd.DataFrame()
流動性インデックス:市場を導く羅針盤
複合流動性インデックス(Composite Liquidity Index)は、中央銀行のバランスシートから得られた正規化データを、それぞれの影響力を反映した重み付けで組み合わせます。内訳は、Fed (35%)、ECB (25%)、BOJ (15%)、PBoC (20%)、その他(5%)です。動的な調整により、データのボラティリティと信頼性が考慮されます。
def calculate_liquidity_index(self) -> pd.DataFrame: """Calculation of the composite liquidity index.""" all_series = {} weights = {'FED_balance': 0.35, 'ECB_balance': 0.25, 'BOJ_balance': 0.15, 'PBOC_balance': 0.20} for bank, df in self.data_cache.get('balance_sheets', {}).items(): series_name = f'{bank}_balance' normalized = (df['total_assets'] - df['total_assets'].rolling(252).mean()) / df['total_assets'].rolling(252).std() all_series[series_name] = normalized combined_df = pd.DataFrame(all_series).fillna(method='ffill') liquidity_index = combined_df.dot(pd.Series(weights)) return pd.DataFrame({'liquidity_index': liquidity_index}, index=combined_df.index)
メインのインデックスに加えて、本システムは短期インデックス(30日)、長期インデックス(252日)、加速度インデックス、および流動性ボラティリティインデックスといったサブインデックスを作成します。これらの指標は、さまざまな市場環境に予測を適応させるのに役立ちます。
def enhance_liquidity_index(self, base_index: pd.Series) -> pd.DataFrame: """Creating advanced liquidity indicators.""" enhanced_df = pd.DataFrame(index=base_index.index) enhanced_df['base_liquidity_index'] = base_index enhanced_df['short_term_liquidity'] = base_index.rolling(window=30).mean() enhanced_df['long_term_trend'] = base_index.rolling(window=252).mean() enhanced_df['liquidity_acceleration'] = base_index.diff().diff() enhanced_df['liquidity_volatility'] = base_index.rolling(window=60).std() return enhanced_df
MetaTrader 5との統合:実取引への架け橋
本システムは、市場データの取得および取引シグナルの生成のために、MetaTrader 5と統合されています。特徴量にはテクニカル指標と流動性指標の両方が含まれており、予測のための独自のデータセットを構築します。
import MetaTrader5 as mt5 from datetime import datetime, timedelta class TradingIntegration: def __init__(self, forecaster: ForexLiquidityForecaster): self.forecaster = forecaster mt5.initialize() def fetch_forex_data(self, symbol: str, days: int = 1460) -> pd.DataFrame: """Fetching data from MetaTrader 5.""" utc_from = datetime.now() - timedelta(days=days) rates = mt5.copy_rates_from(symbol, mt5.TIMEFRAME_D1, utc_from, days) if rates is None: return pd.DataFrame() df = pd.DataFrame(rates) df['date'] = pd.to_datetime(df['time'], unit='s') df.set_index('date', inplace=True) return df def generate_trading_signals(self, symbol: str, forecasts: dict) -> dict: """Generating trading signals.""" signals = {} short_term_returns = [f['return'] for h, f in forecasts['forecasts'].items() if h in ['1d', '2d', '3d']] avg_return = np.mean(short_term_returns) if short_term_returns else 0 signals['short_term'] = { 'signal': 'BUY' if avg_return > 0.005 else 'SELL' if avg_return < -0.005 else 'HOLD', 'strength': min(abs(avg_return) * 100, 100) } return signals
可視化:グラフで見る全体像
本システムは、トレーダーが流動性と価格の関係を視覚的に把握できるよう、インタラクティブな可視化機能を提供します。チャートには、価格予測、流動性インデックスの推移、および特徴量の重要度が含まれます。
import matplotlib.pyplot as plt import numpy as np def create_comprehensive_visualization(self, symbol: str): """Building a set of visualizations.""" forecasts = self.forecaster.forecasts.get(symbol, {}) historical_data = self.fetch_forex_data(symbol, days=180) plt.figure(figsize=(15, 8)) plt.plot(historical_data.index[-60:], historical_data['close'].iloc[-60:], label='Historical prices', linewidth=2) forecast_dates = [datetime.strptime(f['date'], '%Y-%m-%d') for f in forecasts.get('forecasts', {}).values()] forecast_prices = [f['price'] for f in forecasts.get('forecasts', {}).values()] if forecast_dates: plt.plot(forecast_dates, forecast_prices, 'r--', label='Forecast', linewidth=2) plt.title(f'{symbol}: Price forecast considering liquidity', fontsize=14, fontweight='bold') plt.xlabel('Date', fontsize=12) plt.ylabel('Price', fontsize=12) plt.legend() plt.grid(True, alpha=0.3) plt.savefig(f'forecast_{symbol}.png', dpi=300) plt.close()
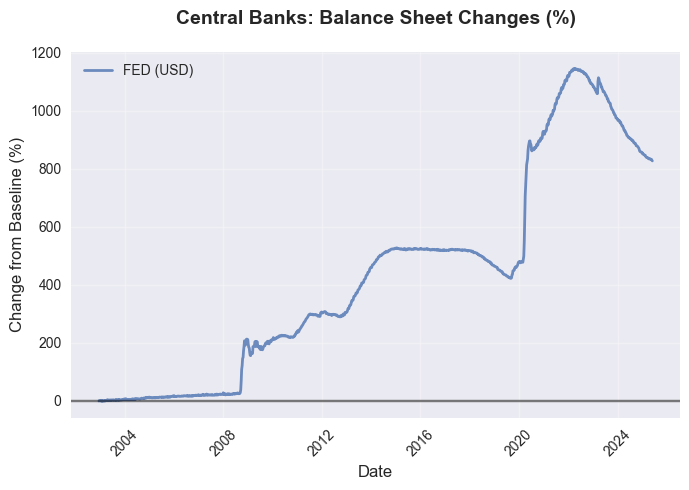
その結果、私たちはグローバル流動性の全体像を把握することができます。
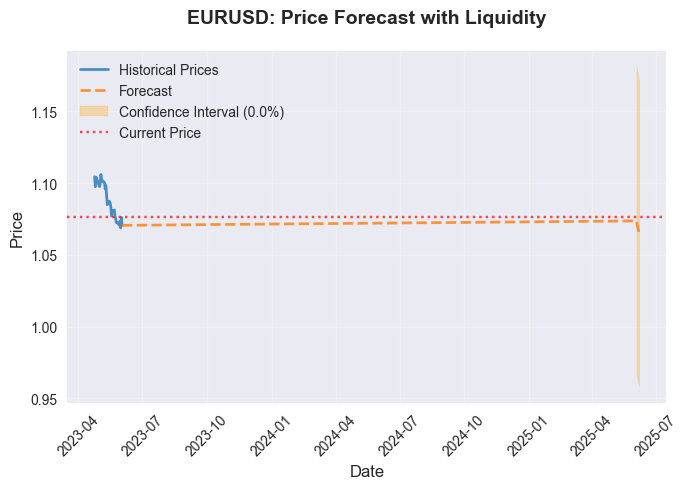
流動性データから導き出される予測は次のとおりです。
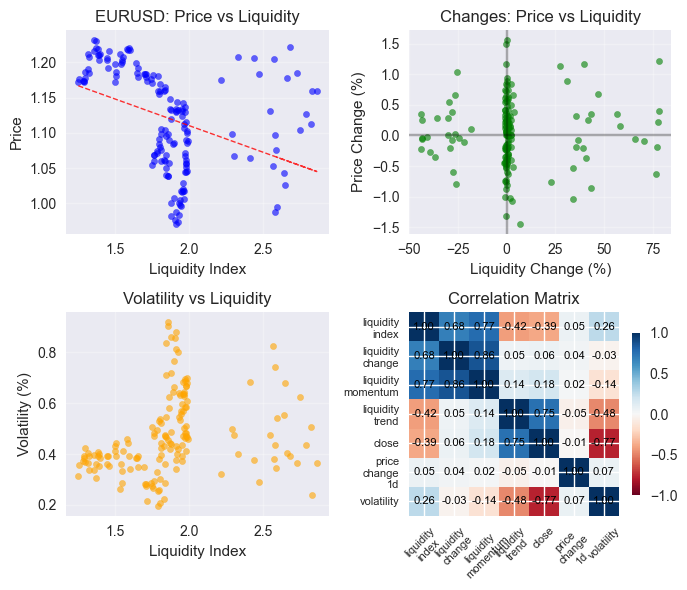
そして相関行列は以下のとおりです。
結論
開発したシステムは、中央銀行のバランスシート分析と高度な機械学習およびテクニカル分析手法を組み合わせた強力なツールであり、通貨の値動きを予測するための包括的なアプローチを提供します。GlobalLiquidityMinerおよびForexLiquidityForecasterを含むモジュール型アーキテクチャにより、柔軟性、拡張性、および変化する市場環境への適応能力が確保されています。
MetaTrader 5との統合により、トレーダーは予測結果を実際の取引に活用することができ、複雑なデータを具体的な売買判断へと変換できます。インタラクティブな可視化機能やバックテスト結果は、システムの透明性と堅牢性を高め、トレーダーが高い確信を持って意思決定をおこなうことを支援します。
本システムは従来の分析手法を超え、ファンダメンタル要因とテクニカル要因の両方を考慮した包括的なアプローチを提供します。これによりトレーダーは市場変化に反応するだけでなく、グローバル流動性を外国為替市場という荒波の中の羅針盤として活用し、変化を先取りすることが可能になります。世界経済におけるボラティリティと不確実性が高まる中、このアプローチは単なる優位性ではなく、取引が成功するための必須要件になりつつあります。
もちろん、このシステムにも限界があります。PBoCのように一部の中央銀行ではデータへのアクセスが制限されているため、代替指標を利用する必要があり、そのことが精度を低下させる可能性があります。また、機械学習は強力な手法であるものの、予期せぬ地政学的ショックや経済的ショックが発生した場合には、絶対的な予測精度を保証するものではありません。しかし、アルゴリズムの継続的な改良、データソースの拡充、新たな市場要因の導入によって、本システムは今後も有効性と実用性を維持できるでしょう。
将来的な発展としては、ニュースやソーシャルメディアといった大量の非構造化データを処理するために、ニューラルネットワークモデルを統合することが考えられます。これにより予測能力はさらに向上するでしょう。また、現在の経済状況に応じて流動性インデックスの重みを自動的に調整する適応型メカニズムの実装も可能です。こうした展開は、不確実性に対してさらに強靭で、あらゆる市場環境において安定した成果を生み出せる次世代取引システムへの道を開きます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18355
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
この画像、最高だね。ネットミームにはぴったりだ。