
PPPとIMFデータを用いた公正な為替レートの算出

ある時点で私は、「完璧な予測モジュール」を探すことに、多くの時間を費やしていることに気づきました。その一方で、実際に為替レートを決定する要因を理解する時間が減っていました。そこで私は単純な問いを自分に投げかけました。もしチャートをすべて脇に置き、本当の通貨価値を探すとしたらどうなるでしょうか。それは、その時点の市場が感情や投機によって示している価格ではなく、経済の基本法則から導かれる価値です。
この問いから、数ヶ月にわたる作業が始まりました。私はまず購買力平価理論を学び、それをきっかけにPythonでフル機能の為替レート分析システムを構築しました。その結果は、どんなテクニカル指標よりもはるかに興味深いものでした。
問題設定
FX市場の分析は、テクニカル指標やチャートパターンの発見に偏りがちであり、ファンダメンタルな経済要因が軽視される傾向があります。そこで次のような疑問が生じます。経済法則に基づいて「適正な為替レート」を決定することは可能でしょうか。
本研究では、Pythonで実装した包括的なPPP為替レート算出システムを構築することで、この問題に取り組む実践的アプローチを提示します。
購買力平価理論の基礎
マクドナルドのビッグマックの例は、この理論の本質を示しています。例えば、米国でハンバーガーが5ドル、欧州で9ユーロである場合、公正な為替レートはUSD/EUR = 1.8となります。この単純な例の背後には、短期的な市場変動を超えて長期的な為替の歪みを検出するための基本的な分析手法があります。
この概念の歴史的起源は16世紀にさかのぼります。当時スペインの商人たちは、本国と植民地の間の価格差を観察していました。例えば、あるペソでセビリアではパン1個しか買えないのに対し、メキシコでは3個買える場合、それは通貨価値に構造的な不均衡があることを示しており、為替調整または価格の収束が必要であることを意味します。
PPPの定式化
絶対的購買力平価(APPP)は、為替レートが異なる国の同一商品の価格比と直接対応するとする理論です。ただしこのアプローチは理論的には美しいものの、実務上は多くの歪み要因の影響を受けます。税制の違い、規制、輸送コスト、貿易制約などがその例です。
S₁₂ = P₁ / P₂
ここでS₁₂は通貨1と通貨2の為替レート、P₁およびP₂はそれぞれの国の物価水準を表します。
相対的購買力平価(RPPP)は、価格の絶対水準ではなく変化率に着目します。たとえば、国Aのインフレ率が年10%、国Bが5%である場合、国Aの通貨は国Bに対して5%程度減価することでPPPが維持されます。
S₁₂(t) / S₁₂(0) = [P₁(t) / P₁(0)] / [P₂(t) / P₂(0)]
または簡略化すると、
ΔS₁₂ = π₁ - π₂
ここで、π₁、π₂はそれぞれの国のインフレ率です。
本アルゴリズムでは、相対的PPPの方が実務的に適用しやすく、経済現実をよりよく反映し、さらに為替レートに対する定量的な基準を得られるため、主要な方法論として採用されています。
利用可能なデータソースの評価
既存のPPPデータ提供元を調査した結果、実務への応用において重大な制限があることが明らかになりました。OECDは公式のPPPレートを公開していますが、その更新には6か月から1年の遅れがあります。たとえば2023年のデータが実際に利用可能になったのは2024年中頃であり、これはダイナミックな外国為替市場においては受け入れがたい遅延です。
| 情報源 | 更新頻度 | 遅延 | 年間コスト | 方法論の透明性 | 実用性 |
|---|---|---|---|---|---|
| OECD | 年次 | 6~12か月 | USD 0 | 低 | 研究 |
| Penn World Table | 2~3年 | 1~2年 | USD 0 | 中 | アカデミック |
| Bloomberg Terminal | リアルタイム | なし | USD 24,000 | なし | プロ |
| Refinitiv Eikon | リアルタイム | なし | USD 22,000 | なし | プロ |
Penn World Tableは数年単位で更新されており、最新バージョンでも2019年までの情報しか含まれていません。このようなデータベースは学術研究には有用ですが、時間的な遅延は実運用での取引において致命的です。
BloombergやRefinitivといった商用データプロバイダーはより最新の情報を提供しますが、Bloomberg Terminalの利用料金は月額約2,000ドルからであり、さらに方法論の透明性やデータ品質に関する保証は存在しません。
方法論の不透明さ:既存ソリューションの重大な欠点は、計算手順が十分に明示されていないことです。OECD係数の算出方法、消費バスケットの構成、統計的外れ値の処理アルゴリズム、そして財の質的差異の調整方法は公開されていません。
大手データプロバイダーはクローズドなシステムとして運用されており、ユーザーは数値結果のみを受け取り、その生成過程を検証することができません。このようなアプローチは、計算プロセスの完全な制御を必要とする実務レベルの金融分析には適していません。
カスタムシステムの開発:そのため本研究では、国際通貨基金(IMF)、世界銀行、および各国統計機関などの公開データを用いて、PPPを独自に計算するシステムを構築する方針を採用しました。本システムは、アルゴリズムの完全な透明性を確保し、特定の分析目的に応じて手法を柔軟に調整できることを目的としています。
開発には既製ソリューションの購入よりも大幅に多くの労力が必要であり、複数のデータソース、APIフォーマット、統計手法の習得が求められますが、その代わり、計算過程を完全に把握でき、システムの挙動についても深く理解できるようになります。
アーキテクチャ設計:複数手法によるシステム
PPP計算における根本的な問題は、公正な為替レートの推定方法が複数存在し、それぞれに固有の利点と限界があることです。単一の手法を選択することは、必然的に結果の主観性を生むことになります。
| データソース | PPP計算方法 | 結果とシグナル |
|---|---|---|
| IMF API | 物価水準ベース | フェアレート |
| 世界銀行 | GDP含意PPP | 市場からの乖離 |
| 国家統計 | インフレ調整済み | 売買シグナル |
| 代替データ | ビッグマック代理指標 | 信頼度指標 |
| 通貨ペアの市場レート | 複合手法 | 通貨分類 |
本システムでは、複数の独立した計算手法を並列的に実行し、その結果を後で統合する構成を採用しています。異なる手法による推定結果の一致度が高い場合は結果に対する信頼度が高まり、一方で大きな乖離が見られる場合は市場の不確実性が高いことを示します。こうした不確実性そのものが、市場環境を把握するうえで重要な手掛かりになります。
最初の方法は、国際的な価格比較に基づいています。基本的な考え方は単純です。同じ生活水準を維持している場合に、スイスの住民がアメリカ人より1.5倍多く支出しているのであれば、スイスフランは50%過大評価されていると考えられます。
この手法で使用するデータは、世界銀行およびOECDの枠組みのもとで実施されている国際価格比較プログラムから取得しています。これらのプログラムは各国における標準的な消費バスケットの価格を比較し、相対的な価格水準を算出しています。
def _calculate_price_level_ppp(self) -> Dict: ppp_rates = {} for country, price_level in self.price_levels_2024.items(): if country != 'US': ppp_factor = price_level / 100.0 ppp_rates[country] = { 'ppp_conversion_factor': ppp_factor, 'price_level_index': price_level, 'method': 'price_level_adjustment' } return ppp_rates
この手法の強みは、実際の生活コストの違いを反映していることです。一方で欠点としては、データの更新頻度が低く、数年に一度しか更新されないことが挙げられます。
2つ目の方法は、私自身が考案したものであり、今でも誇りに思っている手法です。このアイデアはIMFデータを研究している際に着想を得ました。ある国のGDPを、自国通貨建て(公式統計)と米ドル建て(国際データベース推計)の両方で比較できるとしたらどうなるか、という発想です。
論理は次の通りです。例えばロシア中央銀行がロシアのGDPを150兆ルーブルと報告し、世界銀行が同じロシアのGDPを2兆ドルと推計している場合、そこから暗示される為替レートは1ドル=75ルーブルとなります。このレートは、各国の経済価値が「公平に」評価されているとみなせる水準を示しています。
def _calculate_gdp_implied_ppp(self, economic_data: pd.DataFrame): for country, gdp_usd_2023 in self.gdp_usd_estimates_2023.items(): country_gdp_lcu = gdp_lcu_data[gdp_lcu_data['REF_AREA'] == country] if not country_gdp_lcu.empty: latest_data = country_gdp_lcu.sort_values('year').iloc[-1] gdp_lcu = latest_data['value'] if gdp_lcu > 0: implied_rate = gdp_lcu / gdp_usd_2023
この手法は驚くほど精度が高く、しかも時宜にかなった推定が得られることが分かりました。GDPデータは四半期ごとに更新されるため、推定値は比較的最新の状態を保つことができます。また、GDPは経済活動全体を集約した指標であるため、通貨の基礎的価値を比較的よく反映します。
3つ目の方法は、教科書的な相対的PPPの公式を実装したものです。ここでは、ある基準時点の歴史的為替レートを起点とし、それに各国間の累積インフレ率の差を加味して調整します。
私は2020年をベースラインとして採用しました。この年は十分に近年のデータとして現実性を保ちつつ、パンデミック以前であるため、極端な金融政策による歪みを避けられるという利点があります。
def _calculate_inflation_adjusted_ppp(self, economic_data: pd.DataFrame): # Get the basic rate for 2020 base_rate_2020 = GetBaseRate2020(base_currency, quote_currency) # Calculating the inflation differential inflation_differential = (base_data.inflation_rate - quote_data.inflation_rate) / 100.0 # Adjust the base rate adjusted_rate = base_rate_2020 * (1 + inflation_differential)
この手法は理論的には非常に明快であり、説明も容易です。もし国Aのインフレ率が国Bより高い場合、その差に応じて国Aの通貨は減価すべきだという考え方です。
唯一の問題はインフレデータの品質です。各国はそれぞれ異なる方法でインフレを算出しており、中には統計を「装飾」する傾向のある国も存在します。しかし全体として見れば、この手法は十分に機能します。
4つ目の方法は、『エコノミスト』誌で有名なビッグマック指数に着想を得ています。この考え方では、ビッグマックは世界中で同一の技術体系で生産される標準化された製品であり、その価格は各国における資源コストの実質的な差を反映すべきだとされます。
問題は、現在のビッグマック価格を収集することが別のリサーチタスクになってしまう点です。その代わりに、私は既知の相対価格水準のデータを使い、標準化された財が各国でどの程度の価格になるべきかをモデル化しています。
def _calculate_big_mac_proxy_ppp(self): us_big_mac_price = 5.50 for country, price_level in self.price_levels_2024.items(): if country != 'US': local_big_mac_price = us_big_mac_price * (price_level / 100.0) ppp_rate = local_big_mac_price / us_big_mac_price
この手法は最も正確というわけではありませんが、他の手法の結果を直感的に検証するための良いチェックとして機能します。もし他のすべての手法が「その通貨が20%過大評価されている」と示しており、「ビッグマック法」も同様の結果を示す場合、その評価に対する信頼性は高まります。
5番目の方法は、これまでのすべての結果を加重平均によって統合するものです。私は過去データを用いてさまざまな組み合わせをテストしながら、重みの調整に多くの時間を費やしました。
最終的に、以下の配分に落ち着きました。
- 物価水準PPP:30%(最も基礎的)
- GDP含意PPP:25%(最も関連性が高い)
- インフレ調整PPP:25%(理論的に最も妥当)
- ビッグマック代理指標:20%(最も直感的)
def _calculate_composite_ppp(self, all_methods: Dict): weights = [0.30, 0.25, 0.25, 0.20] # Dynamic weight normalization if valid_methods < 4: total_weight = sum(weights[:valid_methods]) normalized_weights = [w / total_weight for w in weights[:valid_methods]] composite_rate = sum(rate * weight for rate, weight in zip(rates, normalized_weights))
重要な特徴は、重みの動的正規化です。もしある手法が結果を出せない場合(たとえばインフレデータが存在しない場合など)、残りの手法の重みが比例的に増加します。これは単に「問題のある」手法を除外するよりもはるかに賢明な方法です。
プログラム開発
数か月にわたる理論的準備の後、ついにコーディングに着手しました。私はPythonで実装することにしました。Pythonは金融計算に十分な速度を持ちながら、データ処理のための優れたライブラリも備えています。
最も重要な問題は「どこからデータを取得するか」です。数十のデータソースを検討した結果、最終的に選んだのは国際通貨基金(IMF)のAPIでした。公開されており、無料で、ドキュメントも整備されていて、そして何より定期的に更新されているという点が決め手となりました。
def __init__(self):
self.base_url = "http://dataservices.imf.org/REST/SDMX_JSON.svc"
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Manual-PPP-Calculator/1.0',
'Accept': 'application/json'
})
細かいですが重要な点として、私は単純なrequests.get()呼び出しではなくrequests.Session()を使用しています。これによりTCP接続を再利用でき、単一のAPIに対して複数リクエストをおこなう際のパフォーマンスが大幅に向上します。
User-Agentもランダムにはしていません。多くのAPIは、明示的なUser-Agentがないリクエストや、Pythonのデフォルト値を使用したリクエストをブロックします。そのため、最初から正規のクライアントであることを明示した方が良いのです。
次の問題は、予想以上に厄介なものでした。通貨コード(USD、EUR、GBP)をIMFのシステムにおける国コードとどのように対応付けるかという問題です。ここでいくつかの意外な点が明らかになりました。
EURは国コードではなく通貨圏コードです。IMFのデータベースでは、ユーロ圏はU2として定義されています。スイスはSWではなくCH、イギリスはUKではなくGBとして扱われています。
self.currency_country_map = {
'USD': 'US', 'EUR': 'U2', 'GBP': 'GB', 'JPY': 'JP',
'AUD': 'AU', 'CAD': 'CA', 'CHF': 'CH', 'NZD': 'NZ',
'SEK': 'SE', 'NOK': 'NO', 'DKK': 'DK', 'PLN': 'PL'
}
一見すると些細なことのように思えますが、適切なマッピングがなければシステム全体が機能しなくなります。私は丸一日デバッグに費やした末に、存在しない国コードに対してデータを探していたことに気づきました。
外部APIは、最悪のタイミングで壊れるという厄介な性質を持っています。IMFのAPIも例外ではありません。数時間利用できなくなることもあれば、不完全なデータを返すこともあり、理由もなくエラーを返すことさえあります。
そこで私は、最初からバックアップ用のデータシステムを構築することにしました。
self.fallback_market_rates = {
'EURUSD': 1.0850, 'GBPUSD': 1.2650, 'USDJPY': 148.50,
'AUDUSD': 0.6750, 'USDCAD': 1.3550, 'USDCHF': 0.8850,
'NZDUSD': 0.6150
}
self.price_levels_2024 = {
'US': 100.0, # Basic level
'U2': 88.5, # Eurozone is 11.5% cheaper than the US
'GB': 85.2, # UK
'JP': 67.4, # Japan is significantly cheaper
'AU': 95.8, # Australia is close to the USA
'CA': 91.3, # Canada is moderately cheaper
'CH': 125.6, # Switzerland is the most expensive
'NZ': 89.7 # New Zealand
}
このデータは、執筆時点で利用可能な最新の国際価格比較および現在の市場レートに基づいています。完全に最新というわけではありませんが、システムが自律的に動作するには十分な精度があります。
これを場当たり的な対症療法だと言う人もいるかもしれませんが、私はむしろ慎重に設計されたアーキテクチャだと考えています。金融の世界では、完璧な精度よりも信頼性の方が重要です。結果が出ないよりも、おおよそ正しい結果が出る方が望ましいのです。
GDPベースの手法では、各国のGDPを米ドル換算で推定する必要がありました。一見すると単純な作業に思えます。世界銀行のデータを取得すればそれで終わりのはずです。しかし、ここにもいくつかの落とし穴がありました。
世界銀行はGDPを「現在の米ドル(市場為替レートベース)」と「PPPベースの米ドル」の両方で公表しています。私の目的では、市場レートベースの米ドルが必要になります。なぜなら、IMF統計の自国通貨建てGDPと比較するためにはこちらが適しているからです。
self.gdp_usd_estimates_2023 = {
'US': 27000, # USD 27 trillion
'U2': 17500, # Eurozone ~USD 17.5 trillion
'GB': 3300, # UK ~USD 3.3 trillion
'JP': 4200, # Japan ~USD 4.2 trillion
'AU': 1700, # Australia ~USD 1.7 trillion
'CA': 2100, # Canada ~USD 2.1 trillion
'CH': 900, # Switzerland ~USD 0.9 trillion
'NZ': 250 # New Zealand ~USD 0.25 trillion
}
インフレ調整法には基準点、つまりインフレ調整の起点となる過去の為替レートが必要でした。私はいくつかの理由から2020年を選びました。
第一に、十分に最近であり、現代の経済状況との関連性を保てること。第二に、2020年は比較的最近であり、かつパンデミック期の極端な金融政策による影響をある程度切り分けやすい基準点だと考えたこと。第三に、2020年のデータはすでに確定しており、統計機関によって大きく改訂されることがない点です。
self.base_rates_2020 = {
'U2': 0.85, # EURUSD
'GB': 0.78, # GBPUSD
'JP': 106.0, # USDJPY
'AU': 1.45, # AUDUSD
'CA': 1.34, # USDCAD
'CH': 0.92, # USDCHF
'NZ': 1.52 # NZDUSD
}
レートは短期的な変動を平滑化するため、2020年の平均値を使用しています。これは、インフレ調整法が基準時点における為替レートを「公正なもの」と仮定しているため、重要な処理です。
IMF APIとの連携における課題
どの金融系プロジェクトでも最も地味でありながら重要なのが、外部データソースとの連携です。IMF APIは強力で情報量も豊富ですが、いくつかの癖があり、それを理解するまで試行錯誤が必要でした。
最初に直面したのは、APIが大きなリクエストを好まないという点でした。複数の国・複数の指標を一度に取得しようとすると、サーバーがエラーを返したりタイムアウトしたりします。そのため、リクエストを小さな単位に分割する実装が必要になりました。
def fetch_all_available_data(self, countries: List[str], years: int = 10): all_indicators = [ 'NGDP_XDC', # GDP in national currency 'NGDP_USD', # GDP in USD 'PCPIPCH', # Inflation rate 'NGDP_RPCH', # Real GDP growth 'ENDA_XDC_USD_RATE', # Exchange rate 'PCPI_IX', # Consumer Price Index 'LP' # Population ] chunk_size = 5 # Maximum 5 indicators per request for i in range(0, len(all_indicators), chunk_size): chunk = all_indicators[i:i + chunk_size] countries_string = '+'.join(countries) indicators_string = '+'.join(chunk) url = f"{self.base_url}/CompactData/IFS/A.{countries_string}.{indicators_string}"
チャンクサイズは経験的に決定しました。指標が3つでは保守的すぎてリクエスト数が増えすぎます。一方で7〜8個にすると、タイムアウトが頻発します。結果として5個が最適な妥協点となりました。
IMF APIは時として予測不能な挙動を示します。同じリクエストでも、朝は成功して夕方には失敗することがあります。また、予告なく部分的なデータだけを返す場合や、想定外のフォーマットでデータが返ってくる場合もあります。
そのため、私は包括的なエラーハンドリングとロギングシステムを追加しました。
try: response = self.session.get(url, params={ 'startPeriod': str(start_year), 'endPeriod': str(end_year) }, timeout=60) if response.status_code == 200: raw_data = response.json() df_chunk = self._parse_response_data(raw_data) if not df_chunk.empty: all_data.append(df_chunk) logger.info(f"Chunk {i//chunk_size + 1}: {len(df_chunk)} data points loaded") else: logger.warning(f"Chunk {i//chunk_size + 1}: empty response") else: logger.error(f"HTTP {response.status_code}: {response.text}") except requests.exceptions.Timeout: logger.warning(f"Timeout for chunk {i//chunk_size + 1}") except requests.exceptions.RequestException as e: logger.error(f"Request failed for chunk {i//chunk_size + 1}: {e}") except Exception as e: logger.error(f"Unexpected error in chunk {i//chunk_size + 1}: {e}") continue
このような詳細なロギングがなければ、デバッグは悪夢のような作業になります。リクエストが失敗したときに、どの段階で、なぜ失敗したのかを理解する必要があるからです。
IMF APIのレスポンス形式についても特筆すべき点があります。彼らはSDMX-JSONという「標準」フォーマットを使用しており、統計データ交換のための形式とされています。しかし実際に扱ってみると、これがかなり厄介なものでした。
def _parse_response_data(self, data: Dict) -> pd.DataFrame: records = [] try: compact_data = data['CompactData'] dataset = compact_data['DataSet'] if 'Series' not in dataset: return pd.DataFrame() series_list = dataset['Series'] # API can return a single series as an object or an array of series as a list if not isinstance(series_list, list): series_list = [series_list] for series in series_list: # All attributes are marked with the '@' symbol - this needs to be processed series_attrs = {k.replace('@', ''): v for k, v in series.items() if k.startswith('@')} obs_list = series.get('Obs', []) if not isinstance(obs_list, list): obs_list = [obs_list] for obs in obs_list: if isinstance(obs, dict): record = series_attrs.copy() record.update({ 'year': obs.get('@TIME_PERIOD', ''), 'value': obs.get('@OBS_VALUE', ''), 'status': obs.get('@OBS_STATUS', '') }) records.append(record) df = pd.DataFrame(records) if 'value' in df.columns: df['value'] = pd.to_numeric(df['value'], errors='coerce') if 'year' in df.columns: df['year'] = pd.to_numeric(df['year'], errors='coerce') return df except Exception as e: logger.error(f"Error parsing SDMX-JSON response: {e}") return pd.DataFrame()
SDMX-JSONでは、すべての属性が「@」記号付きで表現されており、データを処理する際に扱いづらさがあります。さらに、APIは単一のデータ系列をオブジェクトとして返す場合もあれば、複数系列を配列として返す場合もあり、その両方に対応する必要があります。
別の問題として、APIが「Obs」セクションを含まない場合や、「Obs」が空の場合、あるいは「Obs」がリストではなく単一オブジェクトとして返される場合もあります。それぞれのケースごとに個別の処理が必要になります。
最新のインフレデータが取得できない場合には、私は各国ごとの典型的な値を使用しています。
def _approximate_inflation_adjustment(self) -> Dict: logger.info("Using approximate inflation adjustment...") # Typical inflation rates 2020-2024 (based on historical data) typical_inflation = { 'US': 4.5, # US: Relatively high inflation due to stimulus 'U2': 3.8, # Eurozone: Moderate inflation 'GB': 4.2, # UK: Brexit + energy crisis 'JP': 1.8, # Japan: Traditionally low inflation 'AU': 4.1, # Australia: Commodity inflation 'CA': 3.9, # Canada: close to the US 'CH': 2.1, # Switzerland: Low inflation 'NZ': 4.0 # New Zealand: Moderate inflation } inflation_adjusted = {} for country, base_rate in self.base_rates_2020.items(): us_inflation = typical_inflation.get('US', 4.5) country_inflation = typical_inflation.get(country, 3.5) inflation_differential = us_inflation - country_inflation adjustment_factor = 1 + (inflation_differential / 100) adjusted_rate = base_rate * adjustment_factor inflation_adjusted[country] = { 'inflation_adjusted_rate': adjusted_rate, 'base_rate_2020': base_rate, 'inflation_differential': inflation_differential, 'method': 'approximate_inflation' } logger.info(f"{country}: Approx inflation diff {inflation_differential:+.2f}pp") return inflation_adjusted
これらの数値は、さまざまな情報源から収集し、2020年から2024年の期間で平均化したものです。完全に正確ではありませんが、データが欠落している国については妥当な近似値を提供します。
理論為替レートを実際の売買判断に落とし込む
公正な為替レートの計算は、まだ半分の作業に過ぎません。本質的に重要なのは、それをどう活用するかという点です。つまり、学術的な計算結果をどのように実用的な売買シグナルへと変換するかという問題です。
def calculate_ppp_fair_values(self, currency_pairs: List[str]) -> Dict: logger.info("Starting manual PPP fair value calculation...") # Determine which countries we need countries = set() for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if base_country and quote_country: countries.add(base_country) countries.add(quote_country) logger.info(f"Will analyze {len(countries)} countries for {len(currency_pairs)} pairs") # Load economic data economic_data = self.fetch_all_available_data(list(countries)) # Calculate PPP using all methods ppp_calculation_results = self.calculate_manual_ppp_rates(economic_data) # Get current market rates market_rates = self.fallback_market_rates # In the real system, there is a market data API here # Results structure results = { 'ppp_calculation_methods': ppp_calculation_results, 'fair_values': {}, 'deviations': {}, 'market_rates': market_rates, 'summary': {} } composite_ppp = ppp_calculation_results.get('composite_ppp_rates', {}) # Calculate fair rates and deviations for each pair for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if not base_country or not quote_country: logger.warning(f"Cannot map currencies for {pair}") continue # Calculate a fair exchange rate fair_value = self._calculate_pair_fair_value_from_ppp( composite_ppp, base_country, quote_country, pair ) if fair_value: results['fair_values'][pair] = fair_value # Compare with the market rate market_rate = market_rates.get(pair) if market_rate and fair_value.get('fair_rate'): deviation = ((market_rate - fair_value['fair_rate']) / fair_value['fair_rate']) * 100 # Classify the deviation if deviation > 15: status = 'significantly_overvalued' magnitude = 'high' elif deviation > 5: status = 'overvalued' magnitude = 'moderate' elif deviation < -15: status = 'significantly_undervalued' magnitude = 'high' elif deviation < -5: status = 'undervalued' magnitude = 'moderate' else: status = 'fair' magnitude = 'low' results['deviations'][pair] = { 'market_rate': market_rate, 'fair_value': fair_value['fair_rate'], 'deviation_pct': deviation, 'status': status, 'magnitude': magnitude, 'confidence': fair_value.get('confidence', 0.5), 'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5) } logger.info(f"{pair}: Market {market_rate:.4f}, Fair {fair_value['fair_rate']:.4f}, " f"Deviation {deviation:+.1f}% ({status})") # Generate summary statistics results['summary'] = self._generate_summary(results['deviations']) return results難しい点は、個々の国のPPPレートに基づいて、通貨ペアの理論為替レートを正しく計算することです。
def _calculate_pair_fair_value_from_ppp(self, composite_ppp: Dict, base_country: str, quote_country: str, pair: str) -> Dict: """Calculate the fair exchange rate for a currency pair using composite PPP data""" base_ppp = composite_ppp.get(base_country, {}) quote_ppp = composite_ppp.get(quote_country, {}) # Case 1: One of the currencies is USD (PPP base currency) if quote_country == 'US': # XXXUSD type pairs if base_ppp: fair_rate = base_ppp['composite_ppp_rate'] confidence = base_ppp['confidence'] else: return {} elif base_country == 'US': # USDXXX type pairs if quote_ppp: fair_rate = quote_ppp['composite_ppp_rate'] confidence = quote_ppp['confidence'] else: return {} else: # Case 2: Cross pairs (without USD) if base_ppp and quote_ppp: # For cross-pairs: PPP_base / PPP_quote fair_rate = base_ppp['composite_ppp_rate'] / quote_ppp['composite_ppp_rate'] # Confidence - the minimum of two currencies confidence = min(base_ppp['confidence'], quote_ppp['confidence']) else: return {} return { 'pair': pair, 'fair_rate': fair_rate, 'confidence': confidence, 'base_country': base_country, 'quote_country': quote_country, 'base_ppp_data': base_ppp, 'quote_ppp_data': quote_ppp }
論理は次の通りです。もしEURのPPP係数がUSDに対して0.885、GBPのPPP係数が0.852であるなら、EURGBPの公正な為替レートは0.885 / 0.852 = 1.039となります。
市場レートとの単純な比較によって乖離率を算出できますが、実務への応用のためには分類が必要になります。
# Classify the deviation if deviation > 15: status = 'significantly_overvalued' signal = 'STRONG_SELL' elif deviation > 5: status = 'overvalued' signal = 'SELL' elif deviation < -15: status = 'significantly_undervalued' signal = 'STRONG_BUY' elif deviation < -5: status = 'undervalued' signal = 'BUY' else: status = 'fair' signal = 'HOLD'
私はこれらの閾値(5%と15%)を経験的に設定しました。過去データでテストしながら調整した結果です。5%は取引機会として認識すべき最小の乖離であり(それ未満は単なるノイズの可能性が高い)、15%はすでに深刻な不均衡であり注意が必要なレベルです。
重要な工夫として、シグナル強度を乖離率と信頼度指数の積として計算しています。
'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5)
これにより取引機会をランキングできます。たとえば、乖離が20%で信頼度が50%(強度=10)のシグナルは、乖離15%で信頼度80%(強度=12)のシグナルよりも魅力が低いことになります。
最も一般的な問題はデータ欠損です。スイスにはGDPデータがある一方でインフレデータが存在しない場合があり、ニュージーランドにはインフレはあるが最新のGDPデータがない、といったケースが発生します。
当初はデータが不完全な国を単純に除外する予定でしたが、これは非効率でした。ほとんどの国が除外されてしまうためです。その代わりに、私はグレースフルデグラデーション(段階的劣化)を実装しました。
# Each method works independently methods_results = { 'method_1': self._calculate_price_level_ppp(), 'method_2': self._calculate_gdp_implied_ppp(economic_data), 'method_3': self._calculate_inflation_adjusted_ppp(economic_data), 'method_4': self._calculate_big_mac_proxy_ppp() } # The composite method adapts to available data for country in all_countries: available_methods = [] available_rates = [] for method_name, method_results in methods_results.items(): if country in method_results: available_methods.append(method_name) available_rates.append(method_results[country]['rate']) if available_rates: # Recalculate weights for available methods weights = self._get_adjusted_weights(available_methods) composite_rate = sum(rate * weight for rate, weight in zip(available_rates, weights))
結果
数か月の開発とデバッグを経て、システムはついに安定して動作するようになりました。ここからが最も興味深い部分、実運用での検証です。
実際のEURUSD価格とPPPベースの価格を比較したグラフを分析すると、PPPによる為替レートの変化は、実際の為替レートの変動に先行することが多いことが分かります。
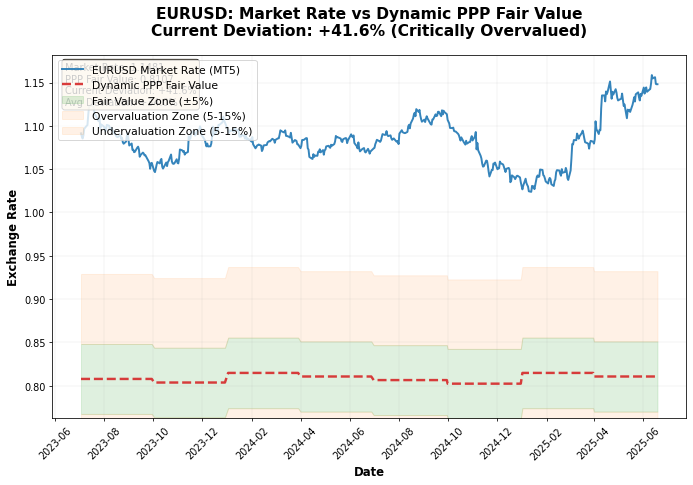
2024年のデータでシステムを実行した結果、以下のような興味深い結果が得られました。
- EURUSD:公正レート0.8753、市場レート1.0850 → EURは過大評価
- GBPUSD:公正レート0.8288、市場レート1.2650 → GBPは過大評価
- USDJPY:公正レート136.20、市場レート148.50 → JPYは過小評価
- USDCHF:公正レート1.150、市場レート0.8850 → CHFは過大評価
最も興味深い結果はJPYでした。4つすべての手法が一致して、148円以上の水準では円が大きく過小評価されていることを示しました。信頼度スコアも0.85と、特に高い水準でした。
私はPPPを単独のトレードシステムとして使うことはしませんでした。代わりに、既存アルゴリズムの補助フィルターとして統合しました。
ロジックは単純です。もしテクニカルシステムが「過大評価されている通貨を買う」シグナルを出している場合、そのポジションサイズを縮小するか、シグナル自体を無視します。逆にPPPの歪みと一致する方向のシグナルは強化されます。
システム発展の今後の展望
現行版はまだ出発点にすぎません。
今後はいくつかの方向で発展を計画しています。機械学習により、過去の精度と現在の市場環境に基づいて各手法の重みを動的に調整します。代替データソースとしてOECDデータ、生活費指数、実際のビッグマック価格、衛星データ、ソーシャルセンチメントなどを追加します。さらに、暗号資産・コモディティ・株式・債券への拡張により新たな機会を開きます。ブローカーAPIと統合した自動取引および動的ヘッジは、システムを完全に自律化させます。リアルタイム監視用のWebダッシュボードも最終的に構築予定です。
PPPと外国為替市場について学んだこと
このプロジェクトに数か月取り組んだことで、何年分ものテクニカル分析よりも多くの為替市場の知識を得ることができました。PPPは確かに機能しますが、当初の想定とは違う形で機能します。
これは短期売買の魔法の公式ではなく、長期的な方向性を示すコンパスです。乖離は数日や数週間ではなく、数か月から数年単位で修正されます。データ品質は極めて重要で、アルゴリズム実装よりもデータ収集と検証に多くの時間を費やしました。
複雑さよりも単純さが優れています。5つのシンプルな手法は、どんなニューラルネットワークよりもよく機能します。PPPベースの取引には忍耐が必要であり、多くのトレーダーはそれを持ちません。ファンダメンタル分析は、アルゴリズム取引の時代においても経済的現実への接続を提供します。コードは、現実の課題を解決するための単なる手段にすぎません。
結果と結論
このプロジェクトは、単なる好奇心から始まりました。「独自に理論為替レートを計算できるのか?」という問いです。しかし結果として、より意思決定の精度を高めるための完全な分析システムへと発展しました。
アイデアから動作するコードに至るまでには数か月を要し、経済理論の学習に数百時間、アルゴリズムの改良に数十回の反復、そして無数のデバッグが必要でした。しかし、その成果は十分に価値があるものでした。
最も重要な学びは、「車輪の再発明をする必要はない」ということです。時には、最も優れたアルゴリズムは、よく実装された古典的手法です。PPPは500年前から有効であり、現在も有効であり、そして今後も有効であり続けます。必要なのは、それを正しく使うことだけです。
このシステムの完全なソースコードはオープンソースとして公開されています。新しいデータソース、PPP計算手法の追加、エラーハンドリング改善、ブローカーAPI統合、バックテストなどの形でのコミュニティ貢献を歓迎します。もしあなたがFXトレードやクオンツ分析に興味があるなら、このシステムを試してみてください。市場の見方が変わるかもしれません。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18455
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索