
取引におけるニューラルネットワーク:多変量時系列のデュアルクラスタリング(最終回)

はじめに
本記事では、金融市場予測における強力な手法である、多変量時系列のデュアルクラスタリングを実現するDUETフレームワークの実装作業を継続します。DUETは、時間的クラスタリングとチャネルクラスタリングを統合することで、複雑かつ変化し続ける市場ダイナミクスへの適応を可能にし、従来手法が抱える過学習の問題や柔軟性の制約を克服します。
DUETは複数の主要モジュールから構成されており、それぞれが重要な役割を担っています。まずデータ処理の初期段階では、正規化および外れ値除去がおこなわれ、モデルの頑健性が向上します。
次に、時間クラスタリングが適用され、時系列データを類似した動的特性を持つグループに分割します。これにより、市場プロセスにおける位相シフトをモデルが考慮できるようになり、特に高いボラティリティを持つ資産の分析において重要となります。
チャネルクラスタリングは、多数の市場要因の中から重要な変数を特定するために用いられます。金融データにはノイズや冗長な情報が大量に含まれており、精度の高い予測を妨げる要因となります。DUETはパラメータ間の相関関係を解析し、重要性の低い要素を除去することで、重要な特徴量の処理に計算資源を集中させます。さらに、周波数領域での信号解析および潜在特徴の抽出機構により、モデルはランダムな市場変動の影響を受けにくくなります。
データ融合モジュールでは、時間クラスタリングとチャネルクラスタリングの両モジュールから得られた情報を統合し、環境状態の統一的な表現を構築します。この処理はマスク付きアテンション機構に基づいており、モデルがより重要な特徴に集中しつつ、代表性の低いデータの影響を最小化することを可能にします。その結果、DUETは動的な環境変化に対して高い頑健性を示し、長期予測性能を向上させます。
最終的な予測モジュールでは、統合された特徴量を用いて時系列の将来値を算出します。この段階では、市場指標間の非線形関係を捉えることが可能な高度なニューラルネットワーク手法が用いられます。DUETアーキテクチャは柔軟性に優れており、さまざまな条件に動的に適応できるため、手動によるパラメータ調整を軽減します。
DUETフレームワークのオリジナルの可視化を以下に示します。

前回の記事の実装パートでは、時間クラスタリングモジュールの実装を紹介しました。今回はその続きとして、チャネルクラスタリングモジュールの構築に取り組みます。
チャネルクラスタリングモジュール
チャネルクラスタリングモジュールは、多変量時系列の予測においてチャネル間の関係性を適切に考慮するという課題に対応するものです。ここではDUETフレームワークの著者らは、周波数領域におけるチャネルのクラスタリングを目的とした距離関数の学習を採用しています。
CCMの重要な特徴の1つは、データを周波数領域で表現することです。これを実現するために、時系列データは高速フーリエ変換(FFT)を用いて周波数成分へ分解されます。その結果、信号はスペクトル領域で解析され、チャネル間の関係性がより明確になります。従来の解析では見えなかった多くの潜在的な依存関係が、周波数領域への変換後にのみ現れるため、このアプローチは複雑な時系列データにおいて特に有用です。
チャネル間の関係性は、学習可能な距離メトリックによって評価されます。周波数スペクトルの振幅表現を基本尺度として用い、距離は修正されたマハラノビス距離により計算されます。この手法は、チャネル間の距離だけでなく、スペクトル空間における相関関係も考慮します。
チャネル間の距離を計算した後、関係行列が構築され、要素は[0, 1]の範囲に正規化されます。この正規化により、弱いノイズ的な変動を排除しつつ、最も重要な接続を識別することが可能になります。
最終的な情報フィルタリングのために、二値チャネルマスク行列が構築されます。この処理は確率的サンプリングに基づいており、各チャネルには予測における有用性の確率が割り当てられます。この仕組みにより、データに含まれる不確実性を考慮でき、固定的な閾値処理を回避できます。その結果、モデルは自動的に重要性の低いチャネルを除外し、解釈性を大幅に向上させるとともに情報の冗長性を削減します。
本研究の範囲では、チャネルクラスタリングモジュールのやや簡略化されたバージョンを実装します。離散フーリエ変換アルゴリズムは、既にFITSフレームワークの一部として実装されており、ライブラリ内で利用可能です。マハラノビス距離の代わりに、周波数振幅成分間のベクトル距離に基づくより単純な方法を使用します。これにより周波数解析の利点を維持しつつ、計算コストを削減しアルゴリズムを簡素化しています。
時系列データを周波数領域へ変換した後、各チャネルについて振幅スペクトルのノルムを計算します。その後、チャネル間の距離を算出し、関係行列を構築します。弱い依存関係を以降の解析から除去するために正規化を行い、ノイズを抑制しつつ距離をスケーリングします。これにより重要なチャネル間相関のみが保持されます。この行列に基づいて、関係性の確率モデルが構築されます。各チャネルには他の系列への影響度を反映した重要度重みが割り当てられます。
記述されたアルゴリズムは、OpenCL側のMaskByDistanceカーネルとして実装されます。カーネルのパラメータは3つのデータバッファへのポインタを含みます。最初の2つは解析対象信号の実部と虚部を格納し、3つ目は結果の保存に使用されます。この場合、それはチャネルマスキング行列を格納します。
__kernel void MaskByDistance(__global const float *buf_real, __global const float *buf_imag, __global float *mask, const int dimension ) { const size_t main = get_global_id(0); const size_t slave = get_local_id(1); const int total = (int)get_local_size(1);
カーネル本体では、まず2次元実行空間における現在のスレッドが特定されます。第1次元は解析対象チャネル、第2次元は比較対象チャネルに対応します。ワークグループは第2次元に沿って構成されます。
次に、同一ワークグループ内のスレッド間でデータを交換するためのローカルメモリ配列が作成されます。
__local float Temp[LOCAL_ARRAY_SIZE]; int ls = min((int)total, (int)LOCAL_ARRAY_SIZE);
続いて、グローバルデータバッファにおけるオフセットが決定されます。
const int shift_main = main * dimension; const int shift_slave = slave * dimension; const int shift_mask = main * total + slave;
準備ステップの後、計算は開始され、2つの周波数振幅ベクトル間の距離を計算するループが実行されます。
//--- calc distance float dist = 0; if(main != slave) { #pragma unroll for(int d = 0; d < dimension; d++) dist += pow(ComplexAbs((float2)(buf_real[shift_main + d], buf_imag[shift_main + d])) - ComplexAbs((float2)(buf_real[shift_slave + d], buf_imag[shift_slave + d])), 2.0f); dist = sqrt(dist); }
スレッド行列の対角要素については注意が必要です。期待通り、この場合アルゴリズムは同一ベクトル間の距離を計算することになり、それは明らかに0です。そのため距離計算ループはスキップされ、直接0が代入されます。
次に値を正規化する必要があります。そのために、ワークグループ内の最大距離を求めるアルゴリズムを実装します。まずループによって各スレッドサブグループの最大値がローカル配列に収集されます。
//--- Look Max #pragma unroll for(int i = 0; i < total; i += ls) { if(i <= slave && (i + ls) > slave) Temp[slave % ls] = fmax((i == 0 ? 0 : Temp[slave % ls]), IsNaNOrInf(dist, 0)); barrier(CLK_LOCAL_MEM_FENCE); }
次に、ローカル配列要素の中から最大値を求めます。
int count = ls; do { count = (count + 1) / 2; if(slave < count && (slave + count) < ls) { if(Temp[slave] < Temp[slave + count]) Temp[slave] = Temp[slave + count]; Temp[slave + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
その後、ワークグループ内で距離を最大値で割ることで正規化をおこないます。
//--- Normalize if(Temp[0] > 0) dist /= Temp[0];
結果として、正規化されたすべての距離は[0, 1]の範囲に収まります。値1は最も離れたチャネルに対応します。しかし、そのようなチャネルは影響が最も小さいため、正規化距離の逆数が出力バッファに格納されます。
//--- result mask[shift_mask] = 1 - IsNaNOrInf(dist, 1); }
これでカーネルの実装は完了です。
この実装の重要な特徴として、学習可能なパラメータを一切含まない点が挙げられます。周波数振幅ベクトル間の距離は他の要因に依存しない固定量であるためです。これによりバックプロパゲーションを不要とし、最適化のオーバーヘッドを削減できます。
次に、メインプログラム側でチャネルクラスタリングモジュールの機能を構築します。そのために新しいクラスCNeuronChanelMaskを作成します。その構造は以下の通りです。
class CNeuronChanelMask : public CNeuronBaseOCL { //--- protected: uint iUnits; uint iFFTdimension; CBufferFloat cbFFTReal; CBufferFloat cbFFTImag; //--- virtual bool FFT(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im, bool reverse = false); virtual bool Mask(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronChanelMask(void) {}; ~CNeuronChanelMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronChanelMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
この構造では、少数の内部数値オブジェクトの中に、解析信号の周波数成分の実部と虚部を格納する2つのバッファのみが存在します。これらの使用方法については、仮想メソッドの実装時に詳しく説明されます。
これらのオブジェクトは静的として宣言されており、コンストラクタおよびデストラクタは空のままとなります。これらの宣言済みおよび継承されたオブジェクトの初期化は、Initメソッド内でおこなわれます。
bool CNeuronChanelMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(window <= 0) return false; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, units_count * units_count, optimization_type, batch)) return false;
メソッドのパラメータには、オブジェクトのアーキテクチャを定義するいくつかの定数が含まれています。
- window:解析対象シーケンスの長さ
- units_count:チャネル数
なお、このオブジェクトの出力はチャネルマスキング行列(正方行列)であることが想定されています。その次元はチャネル数に依存し、シーケンス長には依存しません。ただし、入力データの正しい前処理のためにはシーケンス長が必要となるため、まずそのパラメータを検証し、その後で親クラスのメソッドを呼び出します。ここでは継承されたインターフェースの初期化が既に実装されています。
親メソッドの正常終了後、定数を保存します。
//--- Save constants
iUnits = units_count;
activation = None;
ここで重要なのは、以前実装したFFTアルゴリズムが、2の冪乗長のシーケンスのみをサポートしている点です。これは一般的には問題ではなく、ゼロパディングによって長さを調整することができます。しかしまずは、最も近い上側の2の冪を求める必要があります。
//--- Calculate FFT dimension int power = int(MathLog(window) / M_LN2); if(MathPow(2, power) != window) power++; iFFTdimension = uint(MathPow(2, power));
その後、周波数成分の実部と虚部を一時保存するバッファを十分なサイズで初期化します。
if(!cbFFTReal.BufferInit(iFFTdimension * iUnits, 0) || !cbFFTReal.BufferCreate(OpenCL)) return false; if(!cbFFTImag.BufferInit(iFFTdimension * iUnits, 0) || !cbFFTImag.BufferCreate(OpenCL)) return false; //--- return true; }
初期化が完了したため、CNeuronChanelMask::feedForwardメソッドでフォワードパス処理を実装します。この段階は比較的単純です。
bool CNeuronChanelMask::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!FFT(NeuronOCL.getOutput(), NULL, GetPointer(cbFFTReal), GetPointer(cbFFTImag), false)) return false; //--- return Mask(); }
このメソッドは入力データオブジェクトへのポインタを受け取り、まず有効性を検証します。その後、入力データを周波数成分へ変換し、先に説明したカーネルをラップするメソッドを呼び出します。実行結果は呼び出し元へ返されます。
カーネルのエンキュー処理は既に説明したパターンに従うため、ここでは省略します。
前述の通り、このモジュールではバックプロパゲーションは使用しません。そのため該当メソッドはスタブとしてオーバーライドされ、常にtrueを返す実装になっています。この設計により、新しいオブジェクトを既存のモデルアーキテクチャへシームレスに統合することが可能になります。
これで、チャネルクラスタリングモジュールのアルゴリズムの実装が完了しました。クラスとそのメソッドの完全なソースコードは、記事の添付ファイルで入手できます。
DUETブロック
この段階では、すでに時間クラスタリングモジュールとチャネルクラスタリングモジュールを構築しています。これら2つのモジュールは並列に動作し、多変量時系列を時間領域および周波数領域という2つの表現で解析します。得られたすべての結果はFusionモジュールで統合され、マスク付きアテンション機構を用いてチャネル依存性に関する情報を統合します。この処理により、検出された相関を考慮しながら個々のチャネル予測のアライメントが可能になります。Fusionはチャネル間依存重みに基づいて各チャネルの影響を調整します。その結果、最終的な予測はより頑健になり、過学習およびランダムノイズの影響を受けにくくなります。
実際には、修正された自己アテンション機構を使用しており、時間クラスタリングモジュールから得られる依存係数にチャネルクラスタリングモジュールが生成するマスクを乗算します。その後で初めて、Softmax関数によって重みを正規化します。
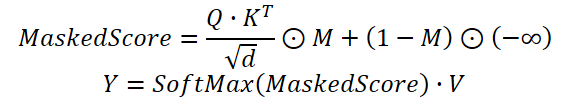
提案アルゴリズムはCNeuronDUETオブジェクト内に実装されており、これは上記3つのモジュールの機能を統合したものです。新しいクラスの構造を以下に示します。
class CNeuronDUET : public CNeuronTransposeOCL { protected: uint iWindowKey; uint iHeads; //--- CNeuronTransposeOCL cTranspose; CNeuronMoE cExperts; CNeuronConvOCL cQKV; CNeuronBaseOCL cQ; CNeuronBaseOCL cKV; CNeuronChanelMask cMask; CBufferFloat cbScores; CNeuronBaseOCL cMHAttentionOut; CNeuronConvOCL cPooling; CNeuronBaseOCL cResidual; CNeuronMHFeedForward cFeedForward; //--- virtual bool AttentionOut(void); virtual bool AttentionInsideGradients(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CNeuronDUET(void) {}; ~CNeuronDUET(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint units_out, uint experts, uint top_k, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronDUET; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual void TrainMode(bool flag) { bTrain = flag; cExperts.TrainMode(bTrain); } };
重要な点として、この場合の親クラスはデータ転置レイヤーです。これは入力データの構造に起因します。
モデルへの入力は多変量時系列を表す行列であり、各行が解析対象システムの各時点に対応します。しかし、ここで説明したすべてのモジュールは単変量時系列として動作します。これはデータフュージョンモジュールにも同様に適用されます。そのため、正しく処理するために入力データは解析に適した形式へ転置されます。すべての処理完了後、結果は元の表現へ変換されます。この最終ステップは親クラスによって処理され、データ構造の一貫性を保証しモジュール統合を容易にします。
上記のクラス構造から分かる通り、多数の内部オブジェクトがアルゴリズム構築において重要な役割を果たしています。これらの機能の詳細はクラスの仮想メソッド実装時に説明します。ここでは、すべてのオブジェクトがクラス内に直接宣言されているため、コンストラクタおよびデストラクタは空でよい点が重要です。すべてのオブジェクト(継承されたものを含む)の初期化はInitメソッドでおこなわれます。
bool CNeuronDUET::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint units_out, uint experts, uint top_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, window, units_out, optimization_type, batch)) return false;
初期化メソッドはオブジェクトのアーキテクチャを定義する一連の定数を受け取ります。このパラメータ構造は既知のものです。一部は時間クラスタリングおよびチャネルクラスタリングモジュールで使用され、その他はアテンションブロックに関連します。特に重要なのはunits_outパラメータであり、出力シーケンス長を定義します。
メソッド内ではまず親クラスの対応メソッドを呼び出し、パラメータ検証および継承インターフェースの初期化を行います。
次に必要なパラメータを内部変数へ保存します。
iWindowKey = MathMax(window_key, 1); iHeads = MathMax(heads, 1);
次に内部オブジェクトを初期化します。前述の通り入力データは解析前に転置される必要があるため、専用オブジェクトがその処理を担当します。
int index = 0; if(!cTranspose.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
その後、時間クラスタリングモジュールおよびチャネルクラスタリングモジュールを初期化します。
index++; if(!cExperts.Init(0, index, OpenCL, units_count, units_out, window, experts, top_k, optimization, iBatch)) return false; index++; if(!cMask.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
次にデータフュージョンモジュールの構成要素を初期化します。これは修正されたアテンションモジュールです。まずQuery、Key、Value生成用のオブジェクトを初期化します。この場合、単一の畳み込み層で並列生成します。
index++; if(!cQKV.Init(0, index, OpenCL, units_out, units_out, iHeads * iWindowKey * 3, window, 1, optimization, iBatch)) return false;
次にそれらを分割するオブジェクトを2つ追加します。
index++; if(!cQ.Init(0, index, OpenCL, cQKV.Neurons() / 3, optimization, iBatch)) return false; index++; if(!cKV.Init(0, index, OpenCL, cQ.Neurons() * 2, optimization, iBatch)) return false;
アテンション係数はデータバッファに格納されます。
if(!cbScores.BufferInit(cMask.Neurons()*iHeads, 0) || !cbScores.BufferCreate(OpenCL)) return false;
すべての場合において、オブジェクトの次元は転置後の入力行列を考慮して設定されます。
次にマルチヘッドアテンション出力を初期化します。
index++; if(!cMHAttentionOut.Init(0, index, OpenCL, cQ.Neurons(), optimization, iBatch)) return false;
続いて異なるヘッドの出力を統合し次元削減をおこなう畳み込み層を初期化します。
index++; if(!cPooling.Init(0, index, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, units_out, window, 1, optimization, iBatch)) return false; cPooling.SetActivationFunction(None);
次に残差接続用のオブジェクトを追加します。
index++; if(!cResidual.Init(0, index, OpenCL, cPooling.Neurons(), optimization, iBatch)) return false; cResidual.SetActivationFunction(None);
元のアーキテクチャに従い通常のFeedForwardブロックが想定されますが、本実装ではStockFormer由来のマルチヘッド版に置き換えています。
index++; if(!cFeedForward.Init(0, index, OpenCL, units_out, 4 * units_out, window, 1, heads, optimization, iBatch)) return false; //--- return true; }
メソッドは、操作の論理結果を呼び出し元に返すことで終了します。
次に、CNeuronDUET::feedForwardメソッドにおけるフォワードパスの実装に進みます。
bool CNeuronDUET::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false;
このメソッドは入力データオブジェクトへのポインタを受け取り、まずそれをデータ転置モジュールへ渡します。以降のすべての処理は転置後のデータ上で実行されます。
まず、単変量時系列の予測を得るために、時間クラスタリングモジュールへデータを渡します。
if(!cExperts.FeedForward(cTranspose.AsObject())) return false;
次に、同じく転置された入力をチャネルクラスタリングモジュールへ渡します。
if(!cMask.FeedForward(cTranspose.AsObject())) return false;
続いてデータ融合モジュールの処理をおこないます。Query、Key、Valueの各要素は時間クラスタリングモジュールの出力から生成されます。
if(!cQKV.FeedForward(cExperts.AsObject())) return false;
その後、出力を2つのテンソルへ分割します。
if(!DeConcat(cQ.getOutput(), cKV.getOutput(), cQKV.getOutput(), iWindowKey, 2 * iWindowKey, cQKV.GetUnits())) return false;
次に、マスク付きマルチヘッド自己アテンションのラッパーメソッドを呼び出します。
if(!AttentionOut()) return false;
マルチヘッドアテンションの出力は、時間クラスタリングモジュールの次元に一致するよう射影されます。
if(!cPooling.FeedForward(cMHAttentionOut.AsObject())) return false;
その後、残差接続が加算されます。
if(!SumAndNormilize(cExperts.getOutput(), cPooling.getOutput(), cResidual.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
マルチヘッドFeedForwardブロックは内部に残差接続を含む独立モジュールとして実装されています。そのため、前段の結果を入力として呼び出すだけで十分です。
if(!cFeedForward.FeedForward(cResidual.AsObject())) return false;
最後に、親クラスの機能を用いて結果を元のデータ表現へ戻します。
return CNeuronTransposeOCL::feedForward(cFeedForward.AsObject());
}
実行された処理の論理結果を呼び出し元プログラムに返し、メソッドの実行を完了します。
フィードフォワードプロセスの実装が完了した後、バックプロパゲーションアルゴリズムに進みます。これは通常、以下の2つのメソッドに分かれます。
- 最終結果への寄与度に基づいて内部オブジェクトおよび入力データへ誤差勾配を分配する処理(calcInputGradients)
- モデル全体の誤差を最小化するためのパラメータ更新処理(updateInputWeights)
実装におけるDUETブロックの学習可能パラメータはすべて内部オブジェクトに含まれているため、それぞれの対応メソッドを呼び出すだけで十分です。一方で重要なのは、誤差勾配を内部オブジェクトおよび入力データへ正しく分配することです。
calcInputGradientsメソッドは入力データオブジェクトへのポインタを受け取ります。これはフォワードパスで使用された同一オブジェクトです。ただし今回は、そのオブジェクトに対応する勾配値が格納される必要があります。
bool CNeuronDUET::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
当然ながら、有効なオブジェクトにのみデータを渡すことが可能です。そのため、まずポインタの妥当性を確認します。無効であれば以降の処理は意味を持ちません。
ご存知の通り、勾配の伝播はフォワードパスの情報フローに厳密に従い、その逆順で行われます。フォワードパスの最後が親クラス呼び出しで終了しているため、バックプロパゲーションも親クラスから開始します。ここでは誤差勾配の分配処理を呼び出します。
if(!CNeuronTransposeOCL::calcInputGradients(cFeedForward.AsObject())) return false;
次に、マルチヘッドFeedForwardモジュールへ勾配を伝播します。
if(!cPooling.calcHiddenGradients(cFeedForward.AsObject())) return false;
続いて、マルチヘッドアテンション出力へ勾配を分配します。
if(!cMHAttentionOut.calcHiddenGradients(cPooling.AsObject())) return false;
次に、マスク付き自己アテンション内部でQuery、Key、Valueへ誤差を分配するラッパーメソッドを呼び出します。
if(!AttentionInsideGradients()) return false;
その後、テンソルを結合します。
if(!Concat(cQ.getGradient(), cKV.getGradient(), cQKV.getGradient(), iWindowKey, 2 * iWindowKey, iCount)) return false;
必要に応じて活性化関数の微分で値を補正します。
if(cQKV.Activation() != None) if(!DeActivation(cQKV.getOutput(), cQKV.getGradient(), cQKV.getGradient(), cQKV.Activation())) return false;
次に時間クラスタリングモジュールへ勾配を伝播します。
if(!cExperts.calcHiddenGradients(cQKV.AsObject()) || !DeActivation(cExperts.getOutput(), cExperts.getPrevOutput(), cPooling.getGradient(), cExperts.Activation()) || !SumAndNormilize(cExperts.getGradient(), cExperts.getPrevOutput(), cExperts.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
重要な点として、時間クラスタリングモジュールの出力は残差接続にも使用されています。そのため、勾配はその経路にも伝播される必要があります。このため、まずアテンション出力側の勾配を活性化関数の微分で補正し、その後両経路の勾配を加算します。
次に、時間クラスタリングモジュールへ勾配を伝播します。
if(!cTranspose.calcHiddenGradients(cExperts.AsObject())) return false;
最後に、入力データレベルへ戻します。
return prevLayer.calcHiddenGradients(cTranspose.AsObject());
}
実行された処理の論理結果を呼び出し元プログラムに返し、メソッドの実行を完了します。
なお、勾配伝播においてチャネルクラスタリングモジュールは情報フローに含まれません。前述の通り、このモジュールはバックプロパゲーションを持たないため、この段階では不要な処理を明示的に除外しています。
これで、DUETフレームワークの著者らが提案したアプローチに対する解釈を実装するアルゴリズムについての説明は完了です。記載されているすべてのオブジェクトとそのメソッドの完全なソースコードは、記事の添付ファイルで入手できます。
モデルアーキテクチャ
次の段階では、開発したコンポーネントを学習可能なモデルのアーキテクチャに統合します。そのため、ここではモデルのアーキテクチャ設計について説明します。
これまでの研究と同様に、マルチタスク学習アプローチを採用し、2つのモデルを同時に学習します。すなわち、Actorモデルと、将来の価格変動方向の確率を予測するモデルです。後者のアーキテクチャは既存研究から完全に踏襲しているため、本稿ではActorのアーキテクチャに焦点を当てます。両モデルの構造はCreateDescriptionsメソッド内で定義されています。
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
メソッドの引数では、モデルアーキテクチャの記述を格納する2つの動的オブジェクトへのポインタを受け取ります。メソッド内部では、まずこれらのポインタを検証し、必要に応じて新しいインスタンスを生成します。
Actorモデルは、入力データのインターフェースとして機能する全結合層から開始されます。この層は、分析対象となる全ての情報量を収容できる十分なサイズである必要があります。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
DUETフレームワークの提案に従い、次にバッチ正規化層を配置します。この層は入力データを標準化し、外れ値の影響を最小化することを目的としています。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
続いて、先に構築したDUETブロックを2層連続で使用します。ただし、データ分割の方法は従来とは異なり、本実験では多次元位相空間でのデータ表現を採用しています。この手法はAttraosフレームワークに着想を得ており、時系列の複雑な依存関係をより正確にモデリングし、解釈性を向上させます。最初のDUETブロックでは、5分ステップが使用されます。
時間クラスタリングモジュールでは、16個の並列エンコーダが初期化され、その中から最も適した4つが選択されます。各クラスタについて、最も適切な4つが選ばれます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDUET; descr.window = BarDescr * 5; // 5 min { int temp[] = {HistoryBars / 5, HistoryBars / 5, 16, 4}; // {Units in (24), Units out (24), Experts, Top K} if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = 256; descr.step = 4; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
2つ目のDUETブロックでは、位相表現のステップが15に増加しますが、それ以外のパラメータは同一です。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDUET; descr.window = BarDescr * 15; // 15 min { int temp[] = {HistoryBars / 15, HistoryBars / 15, 16, 4}; // {Units in (8), Units out (8), Experts, Top K} if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = 256; descr.step = 4; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
データ処理中、テンソルサイズ自体は変化しませんが、続く畳み込み層によって系列長は3分の1に削減されます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars / 3; descr.window = BarDescr * 3; descr.step = descr.window; int prev_window = descr.window_out = BarDescr; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、3層の全結合層からなる意思決定ブロックが続きます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = TANH; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
その後、再びバッチ正規化層が適用されます。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Actorの出力には、リスク管理ブロックが追加されます。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 64; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
両モデルの完全なアーキテクチャは添付ファイルに記載されています。また、環境とのインタラクションおよびモデル学習プログラムについては、以前の研究から変更なく再利用されています。
テスト
DUETフレームワークで提案されたアプローチの解釈をMQL5で実装し、それを学習可能なモデルへ統合するために、多くの作業を行いました。これにより、次の重要な段階である、実際の履歴データを用いた検証へ進むことができます。ここから、実装したソリューションを実際の履歴データで検証する重要な段階に進みます。
モデルの学習には、EURUSDの2024年通年におけるM1(1分足)時間軸の履歴データセットを使用します。データ収集時には、インジケーターのパラメータはすべてデフォルト値のまま維持されています。
モデルの学習は2段階で実施されます。最初の段階では、バッチサイズを1に設定します。これにより、反復ごとに学習データセットからランダムな状態が選択されます。これにより、モデルは様々な状況に適応しやすくなります。しかし、この設定だけではリスク管理ブロックの適切な動作には不十分です。そのため、第2段階ではバッチサイズを60に増加させます。これにより、60個の環境状態の系列と、それに対応するActorの行動を同時に考慮できるようになります。これにより、学習の安定性が向上し、学習効率が改善します。
学習済みモデルは、2025年1月〜2月の履歴データで検証されます。評価の客観性を確保するため、すべての設定は学習時と同一に維持されています。テスト結果を以下に示します。


テスト期間中、モデルは合計53回の取引を実行し、そのうち56%以上が利益確定となりました。また、勝ちトレードにおける平均利益は、負けトレードの平均損失のおよそ2倍となっています。これらの結果により、プロフィットファクターは2.44となりました。
結論
本研究では、周波数領域解析、距離関数の学習、および確率的フィルタリングを組み合わせて多変量時系列解析をおこなうDUETフレームワークを検討しました。これらの要素は、予測精度の向上と、ノイズに対するモデルのロバスト性の強化に寄与します。
実装パートでは、提案手法に対する独自の解釈MQL5で実装し、モデルへ統合しました。モデルは実際の履歴データで学習させ、アウトオブサンプルデータでテストしました。得られた結果は、本モデルの有効性を示唆するものです。ただし、実運用環境へ導入する前に、より代表性の高いデータセットでの再学習および包括的な検証をおこなう必要があります。
参照文献
記事で使用されたプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17487
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索