
取引におけるニューラルネットワーク:カオス理論を時系列予測に統合する(最終回)

はじめに
引き続き、Attraosフレームワークの提唱者たちが提案するアプローチに関して、独自の視点から発展させていきます。前回の記事では、このフレームワークの理論的な側面について考察しました。このフレームワークは、カオス理論の原理を応用して時系列予測問題の解決を試みます。
Attraosフレームワークのアーキテクチャは、非線形解析、機械学習、計算最適化の手法を組み合わせた、複雑な多成分システムです。位相空間再構成(PSR)法を用いることで、Attraosは隠れた動的プロセスをモデル化し、市場変数間に存在する非線形関係を取り込みます。この仕組みにより、市場データ内の安定構造の抽出が可能となり、それを将来の価格変動予測の精度向上に利用できます。
Attraosの主要な特徴のひとつが、Multi-Resolution Dynamic Memory Unit (MDMU)です。このモジュールは過去の価格変動パターンの保持と市場環境への適応を同時に実現します。特に金融市場では、異なる時間スケールで類似パターンが繰り返し現れ、その振幅や強度が変化する傾向があります。この性質により、モデルは市場構造の変化に応じた動的な調整をおこない、複数の時間軸にわたって安定した予測性能を維持します。
周波数領域における局所進化戦略の導入により、変化する市場環境への適応性が向上し、アトラクター間の差異が強調されます。この仕組みは予測誤差の抑制とアトラクター偏差の制御を支え、安定性と予測精度の両立につながります。
Attraosフレームワークの元の可視化を以下に示します。

前回の記事の実装パートではOpenCL側の基本コンポーネントを構築しました。今回は、メインプログラム側におけるオブジェクト生成および構成処理へと進みます。
Attraosオブジェクトの構築
Attraosアルゴリズムは、 PSRモジュールから始まります。このモジュールは、設定された時間遅延に従って対象となる時系列を位相空間へと変換します。この処理は前処理の中核を担い、時系列に潜在する依存関係、構造的特徴、および動的パターンの抽出を可能にします。
多次元時系列は通常、各時刻tにおけるシステム状態パラメータを行として持つ行列として表現されます。一方で本実装では、データは一次元バッファとして保持されており、行列表現はあくまで概念的なものです。データは各時刻のシステム状態ベクトルが順序通りに格納される構造になっています。ベクトルのサイズはウィンドウパラメータによって決定されます。そのため、特定の時間遅延を持つ部分系列を生成するには、ウィンドウ値を相対的に拡張し、同時に系列長を調整することで対応できます。この変換は追加の計算負荷を必要とせず、モデル構造の設計のみで実現されます。
フレームワークの以降の処理はすべて CNeuronAttraosオブジェクト内に構造化されており、その構成は以下に示されます。
class CNeuronAttraos : public CNeuronBaseOCL { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cX_norm; CNeuronConvOCL cA; CNeuronConvOCL cX_proj; CNeuronBaseOCL cDelta; CNeuronBaseOCL cB; CNeuronBaseOCL cC; CNeuronConvOCL cD; CNeuronBaseOCL cH; CNeuronConvOCL cDelta_proj; CNeuronBaseOCL cDeltaA; CNeuronBaseOCL cDeltaB; CNeuronBaseOCL cDeltaBX; CNeuronBaseOCL cDeltaH; CNeuronBaseOCL cHS; //--- virtual bool PScan(void); virtual bool PScanCalcGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronAttraos(void) {}; ~CNeuronAttraos(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronAttraos; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
この新しいクラス構造では、標準的なオーバーライド可能な仮想メソッド群に加えて、多数の内部オブジェクトが含まれています。これらはそれぞれ異なる機能を担い、クラス内要素間の連携を支援します。内部オブジェクトを用いることでコード構造が整理され、各オブジェクトが特定の処理を担当する形となるため、モジュール性が高く、変更にも対応しやすい設計となります。実装の過程では、各内部コンポーネントの機能を個別に確認し、その役割と全体構造における位置付けを明確にしていきます。
すべての内部オブジェクトはstaticとして宣言されており、動的な生成および破棄はおこなわれません。そのため、コンストラクタおよびデストラクタは空のままとなります。これらのオブジェクトに対するメモリ管理は自動的に処理されます。これらの宣言済みおよび継承されたオブジェクトの初期化は、Initメソッド内でおこなわれます。このメソッドには、生成されるオブジェクトのアーキテクチャを一意に定義するための定数がパラメータとして渡されます。これらのパラメータは直感的に理解できる構造になっています。
bool CNeuronAttraos::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; SetActivationFunction(None);
メソッド本体では、まず親クラスに同名で定義されたメソッドを呼び出します。この処理により、最小限の制御ポイントの設定と、継承されたインターフェースの初期化がおこなわれます。
この段階では、本オブジェクトに対する活性化関数は明示的に無効化されます。すべての処理は内部オブジェクトによって実行されるため、継承インターフェースはグローバルレベルのデータ交換のみに使用されます。
親クラスのメソッドが正常に実行された後、宣言済みオブジェクトの初期化に進みます。まず、学習可能パラメータを保持する2つの行列オブジェクトを初期化します。
- A:状態遷移行列
- D:元データとの残差接続行列
これらの行列は、解析対象シーケンス全体を含むフルマトリクスとの乗算に使用されるため、各要素はシーケンス長に応じて事前に複製された状態で保持されます。この設計により、追加のコピー操作を回避し、バックプロパゲーション処理の効率を確保します。
従来と同様に、学習可能パラメータは小規模な2層構造で管理されます。第1層は固定値を保持し、第2層では内部の学習パラメータと第1層の固定値を乗算することで所望のテンソルを生成します。この構造により、既存のニューラルネットワーク層の仕組みを流用しつつ、追加の機能実装を必要とせずにパラメータ学習をおこなうことが可能になります。第2層の学習パラメータ数を抑えるため、第1層は通常1要素のみで構成されます。
ただし本ケースでは、第2層の出力は繰り返し構造を持つテンソルである必要があります。そのため、第1層の固定値は指定回数だけ複製されます。第2層は畳み込み層として実装され、フィルタ数は学習パラメータ数と一致します。カーネルサイズおよびストライドは1に設定され、各出力テンソル要素が単一の入力値に依存する構造となります。
int index = 0; if(!cOne.Init(0, index, OpenCL, units_count, optimization, iBatch)) return false; if(!cOne.getOutput().Fill(1)) return false; cOne.SetActivationFunction(None); //--- index++; if(!cA.Init(0, index, OpenCL, 1, 1, window * window_key, units_count, 1, optimization, iBatch)) return false; cA.SetActivationFunction(MinusSoftPlus); CBufferFloat *w = cA.GetWeightsConv(); if(!w || !w.Fill(0)) return false;
第1層には学習可能なパラメータが存在しないため、この層は第2の学習パラメータ行列の生成にも利用できます。そのため、学習可能パラメータの生成に関しては、第2オブジェクトのみを初期化します。
index++; if(!cD.Init(0, index, OpenCL, 1, 1, window, units_count, 1, optimization, iBatch)) return false; cD.SetActivationFunction(None); w = cD.GetWeightsConv(); if(!w || !w.Fill(1)) return false;
なお、オブジェクト初期化の段階では、学習可能パラメータ行列は固定値で埋められます。これは一般的にランダム値で初期化する手法とは異なります。固定初期化は、学習初期段階で特定の性質を維持する必要がある場合や、初期条件が最終的なパラメータ分布に強く影響する場合に有効です。本ケースでは、初期段階での急激な変動を抑え、データへの適応をより滑らかにする役割を持ちます。
残りの状態空間モデルパラメータは入力データに依存して生成され、解析対象シーケンスの特徴に応じた適応が可能になります。畳み込み層はこれらのモデル要素を並列に生成します。この設計により、シーケンス全体に対して同時に畳み込み処理が実行されるため、計算効率が向上し、処理速度も大きく改善されます。
状態空間モデルのパラメータ生成に先立ち、入力データを正規化します。正規化によって元データのスケール差が除去され、最適化プロセスの安定性が向上し、学習挙動もより予測可能になります。
//--- index++; if(!cX_norm.Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false; cX_norm.SetActivationFunction(None); index++; if(!cX_proj.Init(0, index, OpenCL, window, window, 4 * window_key, units_count, 1, optimization, iBatch)) return false; cX_proj.SetActivationFunction(None);
次に、生成されたモデルパラメータを個別のエンティティに分割します。それに伴い、格納用の追加オブジェクトを生成し、保持するデータの内容が分かるように名称を付与します。
index++; if(!cDelta.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cDelta.SetActivationFunction(None); index++; if(!cB.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cB.SetActivationFunction(None); index++; if(!cC.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cC.SetActivationFunction(None); index++; if(!cH.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cH.SetActivationFunction(None);
続いて、隠れ状態の指数減衰パラメータを生成するオブジェクトを初期化します。このコンポーネントはシーケンス全体における情報ダイナミクスの制御を担い、過去状態の保持量と減衰の度合いを調整する上で重要な役割を持ちます。
index++; if(!cDelta_proj.Init(0, index, OpenCL, window_key, window_key, window, units_count, 1, optimization, iBatch)) return false; cDelta_proj.SetActivationFunction(SoftPlus);
活性化関数としてSoftPlusを使用することで、出力値が常に正の値となるよう制約されます。
また、計算過程における中間結果を保持するため、同一サイズの補助オブジェクトを複数初期化します。
index++; if(!cDeltaA.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaA.SetActivationFunction(None); index++; if(!cDeltaB.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaB.SetActivationFunction(None); index++; if(!cDeltaBX.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaBX.SetActivationFunction(None); index++; if(!cDeltaH.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaH.SetActivationFunction(None); index++; if(!cHS.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cHS.SetActivationFunction(None); //--- return true; }
初期化メソッドは、呼び出し元プログラムに対して論理値を返すことで終了します。
このオブジェクトでは、アーキテクチャパラメータを個別のローカル変数として保持しません。これは、内部オブジェクトに既に格納されている値の冗長な複製を避けるための実装です。必要なローカル変数は、順伝播および逆伝播メソッドの開始時に都度初期化されます。
オブジェクトの初期化完了後、順伝播アルゴリズムへ進みます。これは feedForwardメソッドとして実装されており、入力データオブジェクトへのポインタを引数として受け取ります。
bool CNeuronAttraos::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- uint window = cX_proj.GetWindow(); uint window_key = cX_proj.GetFilters() / 4; uint units = cD.GetUnits();
メソッド本体では、まず初期化時にローカルへ保持されなかった内部オブジェクトからパラメータを読み込みます。その後、モデルの学習可能パラメータに対応するテンソルを生成します。
if(!cA.FeedForward(cOne.AsObject())) // (Units, Window, WindowKey) return false; if(!cD.FeedForward(cOne.AsObject())) // (Units, Window)) return false;
続いて入力データを正規化し、その後、コンテキストに依存するモデルパラメータを生成します。
if(!NeuronOCL || !SumAndNormilize(NeuronOCL.getOutput(), NeuronOCL.getOutput(), cX_norm.getOutput(), window, true, 0, 0, 0, 0.5f)) return false; if(!cX_proj.FeedForward(cX_norm.AsObject())) // (Units, 4*WindowKey) return false;
生成されたパラメータは、その後個別のエンティティに分割されます。
if(!DeConcat(cDelta.getOutput(), cB.getOutput(), cC.getOutput(), cH.getOutput(), cX_proj.getOutput(), window_key, window_key, window_key, window_key, units)) // 4*(Units, WindowKey) return false;
適応的なタイムステップパラメータも生成します。
if(!cDelta_proj.FeedForward(cDelta.AsObject())) // (Units, Window) return false;
この段階で準備は完了し、時系列ダイナミクスをモデル化するMDMUアルゴリズムの構築に移ります。モデルの状態は以下の再帰方程式に従って更新されます。
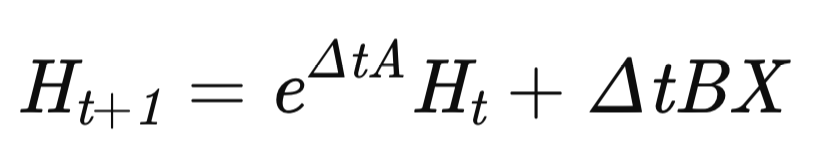
ここでΔtは適応的な時間ステップを表します。
まず最初に、第1項に含まれる指数成分を計算します。この際、標準的な指数関数の代わりにSoftPlusを適用します。SoftPlusにはいくつかの利点があります。
if(!DiagMatMul(cDelta_proj.getOutput(), cA.getOutput(), cDeltaA.getOutput(), window, window_key, units, SoftPlus)) // (Units, Window, WindowKey) return false;
SoftPlusは指数関数よりも緩やかに増加するため、遷移行列における急激な値の増大リスクを抑制します。これにより、勾配変化が滑らかになり、学習の安定性が向上します。
指数関数はΔtの微小な変化にも強く反応しますが、SoftPlusは変動を平滑化し、隠れ状態の急激な変化を防ぎます。
またノイズを含むデータにおいては、SoftPlusの増加が対数的に制約されるため外れ値の影響が抑えられ、モデル全体の安定性向上に寄与します。
次に、第2項の値を逐次的な行列積によって計算します。
if(!MatMul(cDelta_proj.getOutput(), cB.getOutput(), cDeltaB.getOutput(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false; if(!DiagMatMul(cX_norm.getOutput(), cDeltaB.getOutput(), cDeltaBX.getOutput(), window, window_key, units, None)) // (Units, Window, WindowKey) return false;
次に、隠れ状態の変化率に基づいて、ダイナミックレギュレータ行列を更新します。
if(!MatMul(cDelta_proj.getOutput(), cH.getOutput(), cDeltaH.getOutput(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false;
必要なデータの準備が完了した後、OpenCL側で前回の記事に実装した並行スキャンアルゴリズムを用いて、システムの隠れ状態を補正します。この処理はPScanカーネルのラッパーを呼び出すことで実行できます。
if(!PScan()) return false;
カーネル呼び出しは標準的な手順に従っているため、ここでは詳細な説明は省略します。このメソッドの完全なコードは添付ファイル(NeuroNet.cl)に含まれています。
次に、更新後の隠れ状態行列と隠れ状態射影行列を乗算することで、解析対象システムの予測状態を生成します。
if(!MatMul(cHS.getOutput(), cC.getOutput(), Output, window, window_key, 1, units)) // (Units, Window, 1) return false;
正規化された入力データは、直接接続係数と要素ごとの乗算をおこないます。
if(!ElementMult(cD.getOutput(), cX_norm.getOutput(), PrevOutput)) // (Units, Window)) return false;
これら2つの結果は加算されます。
if(!SumAndNormilize(Output, PrevOutput, Output, window, false, 0, 0, 0, 1)) // (Units, Window)) return false;
さらに、元の入力データを用いた残差接続を追加します。
if(!SumAndNormilize(Output, NeuronOCL.getOutput(), Output, window, false, 0, 0, 0, 1)) // (Units, Window)) return false; //--- return true; }
この手法は、隠れ状態の情報と入力データにおける短期的依存関係を統合します。
これにより、Attraosフレームワーク実装における順伝播アルゴリズムは完了となります。次に、処理結果(論理値)を呼び出し元に返して、メソッドの実行を完了します。
次のステップでは、本オブジェクトの逆伝播アルゴリズムを構築します。本記事ではcalcInputGradientsメソッドを扱い、誤差勾配の分配処理について説明します。以前と同様に、このメソッドは入力データオブジェクトへのポインタを受け取りますが、今回はそれに加えて、最終出力に対する入力データの寄与度に基づいた誤差スケールも引数として受け取ります。
bool CNeuronAttraos::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
まずメソッド内でポインタの有効性を確認します。ポインタが無効または期限切れである場合、それ以降の処理は意味を持ちません。
その後、順伝播と同様に入力データのパラメータをローカル変数へ保存します。
uint window = cX_proj.GetWindow(); uint window_key = cX_proj.GetFilters() / 4; uint units = cD.GetUnits();
次に、出力レベルの誤差勾配を3つのデータストリームに分配します。なお、順伝播では以下の3つの情報フローを用いていました。
- 状態空間モデル
- 係数付きの直接接続
- 残差接続
まず、誤差勾配は直接接続係数と正規化入力データとの間で分配されます。
if(!ElementMultGrad(cD.getOutput(), cD.getGradient(), cX_norm.getOutput(), cX_norm.getPrevOutput(), Gradient, cD.Activation(), None)) // (Units, Window)) return false;
次に、第2のデータストリームに沿って勾配を伝播し、隠れ状態と射影係数の間で誤差を分配します。
if(!MatMulGrad(cHS.getOutput(), cHS.getGradient(), cC.getOutput(), cC.getGradient(), Gradient, window, window_key, 1, units)) // (Units, Window, 1) return false;
必要に応じて、対応する活性化関数の導関数を用いて結果を補正します。
if(cHS.Activation() != None) { if(!DeActivation(cHS.getOutput(), cHS.getGradient(), cHS.getGradient(), cHS.Activation())) return false; } if(cC.Activation() != None) { if(!DeActivation(cC.getOutput(), cC.getGradient(), cC.getGradient(), cC.Activation())) return false; }
その後、対応するカーネルラッパーを用いて、並行スキャンモジュールへ勾配を伝播させます。
if(!PScanCalcGradient()) return false;
得られた値は各エンティティに割り当てられます。まず、隠れ状態および適応的タイムステップパラメータへ勾配を伝播します。
if(!MatMulGrad(cDelta_proj.getOutput(), cDelta_proj.getGradient(), cH.getOutput(), cH.getGradient(), cDeltaH.getGradient(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false;
次に、正規化入力データへ誤差勾配を伝播します。
if(!DiagMatMulGrad(cX_norm.getOutput(), cX_norm.getGradient(), cDeltaB.getOutput(), cDeltaB.getGradient(), cDeltaBX.getGradient(), window, window_key, units)) // (Units, Window, WindowKey) return false; if(!SumAndNormilize(cX_norm.getGradient(), cX_norm.getPrevOutput(), cX_norm.getPrevOutput(), window, false, 0, 0, 0, 1)) return false;
ここでは、正規化入力オブジェクトに対して既に一度勾配が伝播されているため、この段階では2つの情報ストリームの結果を統合します。
同様に、隠れ状態への影響係数および適応的タイムステップパラメータを制御する係数へ勾配を分配します。
if(!MatMulGrad(cDelta_proj.getOutput(), cDelta_proj.getPrevOutput(), cB.getOutput(), cB.getGradient(), cDeltaB.getGradient(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false; if(!SumAndNormilize(cDelta_proj.getGradient(), cDelta_proj.getPrevOutput(), cDelta_proj.getGradient(), window, false, 0, 0, 0, 1)) return false;
この時点で、適応的タイムステップパラメータに関する勾配は既存の値と統合されます。
次に、隠れ状態遷移行列へ誤差勾配を伝播し、対応する活性化関数の導関数を用いて補正します。
if(!DeActivation(cDeltaA.getOutput(), cDeltaA.getGradient(), cDeltaA.getGradient(), SoftPlus)) return false;
その後、各エンティティへ勾配を分配します。
if(!DiagMatMulGrad(cDelta_proj.getOutput(), cDelta_proj.getPrevOutput(), cA.getOutput(), cA.getGradient(), cDeltaA.getGradient(), window, window_key, units)) // (Units, Window, WindowKey) return false; if(!SumAndNormilize(cDelta_proj.getGradient(), cDelta_proj.getPrevOutput(), cDelta_proj.getGradient(), window, false, 0, 0, 0, 1)) return false;
この段階でも、適応的タイムステップに対応する誤差勾配は再度加算されます。ただし、この方向においてはこれが最後の情報ストリームとなります。その後、対応する活性化関数の導関数によって累積値を補正します。
if(cDelta_proj.Activation() != None) { if(!DeActivation(cDelta_proj.getOutput(), cDelta_proj.getGradient(), cDelta_proj.getGradient(), cDelta_proj.Activation())) return false; }
その後、適応的タイムステップレベルへ誤差勾配を伝播します。
if(!cDelta.calcHiddenGradients(cDelta_proj.AsObject())) return false;
この時点で、すべてのコンテキスト依存エンティティに対する勾配が得られます。これらの値は単一のテンソルとして統合されます。
if(!Concat(cDelta.getGradient(), cB.getGradient(), cC.getGradient(), cH.getGradient(), cX_proj.getGradient(), window_key, window_key, window_key, window_key, units)) // 4*(Units, WindowKey) return false;
その後、正規化入力レベルへ誤差勾配を伝播します。
if(!cX_norm.calcHiddenGradients(cX_proj.AsObject())) return false; if(!SumAndNormilize(cX_norm.getGradient(), cX_norm.getPrevOutput(), cX_norm.getGradient(), window, false, 0, 0, 0, 1)) return false;
正規化された入力オブジェクトには既に2回勾配が伝播されているため、この段階の値は既存の累積勾配に加算されます。
さらに残差接続経路の値を統合した後、入力データレベルへ勾配を伝播します。その際、対応する活性化関数の導関数によって補正します。
if(!SumAndNormilize(cX_norm.getGradient(), Gradient, cX_norm.getGradient(), window, false, 0, 0, 0, 1)) return false; if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), cX_norm.getGradient(), NeuronOCL.Activation())) return false; //--- return true; }
以上で calcInputGradients メソッドは終了し、論理値を呼び出し元へ返します。
パラメータ更新を担当するupdateInputWeightsメソッドについては、個別に確認することを推奨します。このメソッドは、学習可能パラメータを保持する4つの内部オブジェクトの更新処理を順に呼び出すだけの構造になっています。
また、オブジェクト状態の保存および復元に関するアルゴリズムについて補足します。新しいクラスには多数の内部オブジェクトがありますが、学習可能パラメータを保持しているのは4つのみです。そのため、保存時にはこれら4つのオブジェクトのみをディスクへ記録すれば十分です。
bool CNeuronAttraos::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(!cA.Save(file_handle)) return false; if(!cD.Save(file_handle)) return false; if(!cX_proj.Save(file_handle)) return false; if(!cDelta_proj.Save(file_handle)) return false; //--- return true; }
しかし、オブジェクトの機能をどのように復元するかという問題が生じます。Loadメソッドでは、まずディスクから保存済みデータを読み込みます。
bool CNeuronAttraos::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; //--- if(!LoadInsideLayer(file_handle, cA.AsObject())) return false; if(!LoadInsideLayer(file_handle, cD.AsObject())) return false; if(!LoadInsideLayer(file_handle, cX_proj.AsObject())) return false; if(!LoadInsideLayer(file_handle, cDelta_proj.AsObject())) return false;
アーキテクチャパラメータはローカル変数に保存されます。
uint window = cX_proj.GetWindow(); uint window_key = cX_proj.GetFilters() / 4; uint units_count = cD.GetUnits();
残りの処理は、一時ストレージオブジェクトの初期化手順と同様の構造になっています。
if(!cOne.Init(0, 0, OpenCL, units_count, optimization, iBatch)) return false; if(!cOne.getOutput().Fill(1)) return false; cOne.SetActivationFunction(None); int index = 3; if(!cX_norm.Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false; cX_norm.SetActivationFunction(None); index += 2; if(!cDelta.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cDelta.SetActivationFunction(None); index++; if(!cB.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cB.SetActivationFunction(None); index++; if(!cC.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cC.SetActivationFunction(None); index++; if(!cH.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cH.SetActivationFunction(None); index += 2; if(!cDeltaA.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaA.SetActivationFunction(None); index++; if(!cDeltaB.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaB.SetActivationFunction(None); index++; if(!cDeltaBX.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaBX.SetActivationFunction(None); index++; if(!cDeltaH.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaH.SetActivationFunction(None); index++; if(!cHS.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cHS.SetActivationFunction(None); //--- return true; }
この手法は、データ保存処理、オブジェクト復元処理、およびディスク使用量の最適化に寄与します。
これにより、MQL5におけるAttraosフレームワークの構築に関する説明を終了します。CNeuronAttraosクラスおよび全メソッドの完全なコードは添付ファイルに含まれています。
モデルアーキテクチャ
Attraosフレームワークのアルゴリズム実装に続いて、学習モデルのアーキテクチャについて説明します。この実験では、マルチタスク学習の枠組みにおいて2つのモデルを同時に学習させます。モデル構造はCreateDescriptionsメソッド内で定義され、このメソッドはモデルアーキテクチャの記述を格納する2つの動的配列へのポインタを受け取ります。
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
メソッド内ではまずポインタの有効性を確認し、必要に応じて新しいオブジェクトインスタンスを生成します。
最初に定義されるモデルはActorであり、先に実装したAttraosの手法を基盤として構築されます。通常と同様に、モデルは全結合入力層から開始し、その後にバッチ正規化層が続きます。これにより、取引ターミナルから取得した生データをそのままモデルへ入力することが可能になります。この場合、初期的な正規化処理はモデル内部で実行されます。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次にAttraosアーキテクチャの第1層を使用します。Attraosこの層は入力データを位相空間へ変換し、5ステップの時間遅延を適用します。この設定は1分足データにおいて5分間に相当します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAttraos; descr.window = BarDescr*5; // 5 min descr.count = HistoryBars/5; // 24 descr.window_out = 256; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
2層目では遅延が15ステップに増加します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAttraos; descr.window = BarDescr*15; // 15 min descr.count = HistoryBars/15; // 8 descr.window_out = 256; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
そして3層目では、それが30ステップになります。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAttraos; descr.window = BarDescr*30; // 30 min descr.count = HistoryBars/30; // 4 descr.window_out = 256; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
各CNeuronAttraosオブジェクトの出力は入力データと同じ次元構造を持つ点に注意が必要です。そのため、次に続く畳み込み層ではテンソルの次元が3分の1に圧縮されます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = HistoryBars/3; descr.window = BarDescr*3; descr.step = descr.window; int prev_window=descr.window_out = BarDescr; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
の後に意思決定ヘッドが続き、これは3層の全結合層を連続して配置した構造で構成されます。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 512; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = TANH; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
最終的な出力は正規化されます。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
その後、リスク管理ブロックが追加されます。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
方向性確率モデルによる将来の価格変動予測部分は、既存研究からそのまま継承されており、変更は加えられていません。そのため本記事ではその詳細な説明は省略します。学習対象モデルの完全なアーキテクチャについては添付資料に記載されており、環境とのインタラクションを扱うプログラムも含まれます。これらも従来研究から変更なく引き継がれています。
テスト
2本の記事にわたり、Attraosフレームワークのアイデアを拡張および適用するための実装作業をおこないました。ここで重要な段階として、実装した手法の機能性および有効性を実際のヒストリカルデータ上で評価します。この検証は、モデルの実用性や、異なる市場環境下でも安定したパターン抽出が可能かどうかを確認する上で重要です。
モデルは2024年のEURUSD M1の履歴データ全体を用いて学習されています。インジケータのパラメータはすべてデフォルト設定のままであり、追加の最適化はおこなっていません。この方針により、特定の過去データに対するチューニングといった外的要因を排除し、モデル本来の性能評価に焦点を当てています。また、インジケーター設定を変更しないことで、継続的な介入や再調整なしに市場ダイナミクスへ適応できるかどうかも検証しています。
学習は2段階で実施されます。第1段階ではバッチサイズを1とし、学習ごとに完全にランダムな状態をサンプリングすることで、モデルが多様な状態に触れる機会を最大化します。ただし、この段階のみではリスク管理ブロックの適切な学習には不十分です。そのため第2段階ではバッチサイズを60に拡張し、連続する60状態(1分足換算で約1時間)に基づいてモデルおよびリスク管理ブロックが調整されるようにしています。
テストには2025年1月から2月のデータを使用しました。この期間は未学習データによる厳密な評価をおこなう目的で選定されています。他の実験条件はすべて固定し、再現性と公平な比較が保たれるようにしています。この手法によりランダム要因を排除し、アルゴリズム性能を客観的に評価できます。
テスト結果を以下に示します。



テスト期間中、モデルは287回の取引を実行し、そのうち約39%が利益確定となりました。勝率自体は高くありませんが、損益比によって全体としてはプラスの結果となっています。具体的には、平均利益は平均損失のおよそ2倍であり、勝率の低さを補う形で最終的に1.15のプロフィットファクターを記録しました。
平均保有時間は2時間を超えており、短期から中期にかけての意思決定傾向が確認されます。特筆すべき点として、最も長く保有されたポジションは約2日間に達しており、この挙動については追加分析が必要です。
結論
本記事では、カオス理論の概念を時系列予測に応用する Attraosフレームワークについて検討しました。本フレームワークは、非線形解析、位相空間再構成、マルチ解像度動的メモリ、および適応的アルゴリズムを統合した構造を持ちます。これらの技術により、より高精度な予測と適応的な取引モデルの構築が可能になります。
実装パートでは、これらの手法に対する独自の解釈をMQL5上で実装し、ヒストリカルデータを用いてモデルの構築および学習をおこないました。アウトオブサンプルデータによるテストでは、未学習データに対しても利益を生成できることが確認されました。一方で、いくつかの課題も明らかになっています。特にポジション保有時間の長期化が見られ、また残高曲線の滑らかさにも改善の余地があります。これらの結果は潜在的な有効性を示す一方で、さらなる最適化の必要性を示唆しています。
なお、ここで述べた結論は本実装に固有のものであり、Attraosのオリジナル実装そのものについては本記事では検証対象としていません。
参考文献リスト
記事で使用されたプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17371
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索