
Von der Grundstufe bis zur Mittelstufe: Die Direktive Include

Einführung
Der hier dargestellte Inhalt ist ausschließlich für Bildungszwecke bestimmt. Die Anwendung sollte unter keinen Umständen zu einem anderen Zweck als zum Erlernen und Beherrschen der vorgestellten Konzepte verwendet werden.
Im vorherigen Artikel Von der Grundstufe zur Mittelstufe: Die Anweisungen BREAK und CONTINUE haben wir uns in erster Linie darauf konzentriert, zu verstehen, wie der Ausführungsabfolge innerhalb von Schleifen, die die WHILE- und DO WHILE-Anweisungen verwenden, gesteuert werden kann. Obwohl ich davon ausgehe, dass Sie, liebe Leserin, lieber Leser, wahrscheinlich gut vorbereitet sind, um Schleifen mit der FOR-Anweisung zu verstehen, werde ich eine kurze Pause bei der Erörterung von Schleifen einlegen. Diese Pause ist notwendig, da es von Vorteil ist, andere Konzepte zu überprüfen, bevor wir mit weiteren Operatoren für die Ausführungsabfolge fortfahren.
Daher werden wir in diesem Artikel ein Thema ansprechen, das für Sie sehr hilfreich sein kann. Sobald es erklärt ist, kann ich anfangen, anspruchsvollere Code-Beispiele zu präsentieren. Bis jetzt war es für mich eine ziemliche Herausforderung, Code zu schreiben, ohne bestimmte in MQL5 verfügbare Ressourcen zu nutzen. Auch wenn einige von Ihnen vielleicht denken, dass es mir leicht gefallen ist, ist das Schreiben von Code ohne diese Ressourcen in der Tat eine große Herausforderung. Aber jetzt werden wir der Liste der bereits vorhandenen Möglichkeiten einige neue hinzufügen.
Die Ressource, auf die ich mich beziehe, ist die Verwendung von Kompilierdirektiven. Ohne diese Direktiven wird vieles, was wir tun können, erheblich eingeschränkt, sodass wir gezwungen sind, viel mehr Code zu schreiben, als in einem realen Programmierszenario notwendig wäre.
Im Gegensatz zu dem, was viele denken, machen Kompilierdirektiven den Code nicht unübersichtlicher. Im Gegenteil, ihr Hauptzweck ist genau das Gegenteil: Sie sollen den Code einfacher, schneller und leichter zu handhaben und zu ändern machen. Das Problem ist, dass viele Anfänger diese Ressource entweder ignorieren oder nicht lernen, sie richtig zu nutzen. Dies kann daran liegen, dass einige Programmiersprachen solche Ressourcen nicht in ihrem Werkzeugkasten haben. Einige Beispiele für Sprachen, die keine Kompilierungsdirektiven enthalten, sind JavaScript und Python. Obwohl diese Sprachen bei Gelegenheitsprogrammierern recht beliebt sind, eignen sie sich nicht für die Erstellung bestimmter Arten von Anwendungen. Es geht hier jedoch nicht um diese Sprachen, sondern um MQL5. Lassen Sie uns also mit dem ersten Thema dieses Artikels beginnen.
Warum Kompilierdirektiven verwenden?
Obwohl die in MQL5 vorhandenen Kompilierdirektiven für die meisten Situationen gut geeignet sind, gibt es Momente, in denen ich das Fehlen anderer Anweisungen spüre. Das liegt daran, dass MQL5 im Wesentlichen aus einer hochgradig verfeinerten Modifikation von C/C++ hervorgegangen ist. In C/C++ gibt es jedoch bestimmte Direktiven, die in MQL5 nicht verfügbar sind. Eine dieser Direktiven ist #if, die, obwohl sie so unauffällig zu sein scheint, äußerst hilfreich sein kann, um bestimmte Teile der Version, an der wir arbeiten, zu kontrollieren.
Obwohl diese Direktive in MQL5 nicht vorhanden ist (zumindest nicht zu dem Zeitpunkt, an dem ich diesen Artikel schreibe), wird sie hier nicht vermisst werden. Ich erwähne diese Tatsache nur, damit Sie, lieber Leser, der vielleicht daran interessiert ist, in Zukunft C/C++ zu lernen, sich einiger Details bewusst sind, die C/C++ von MQL5 unterscheiden. Auch wenn alles, wenn nicht sogar das meiste, was hier vorgestellt wird, auch als Sprungbrett zum Erlernen von C/C++ dienen kann.
Im Wesentlichen dienen die Kompilierdirektiven zwei Hauptzwecken, um es kurz zusammenzufassen. Der erste Zweck besteht darin, die Implementierung in Richtung eines effizienteren Codemodells zu lenken. Der zweite Zweck besteht darin, dass Sie verschiedene Versionen desselben Codes erstellen können, ohne frühere Abschnitte zu löschen oder zu verlieren.
Ich verstehe, dass diese Ideen vielen von Ihnen seltsam erscheinen mögen. Anfänger in der Programmierung haben nämlich oft die Angewohnheit, einen Teil des Codes zu löschen, um eine neue Version zu erstellen. Damit versuchen sie, mögliche Probleme zu korrigieren oder die Durchführung bestimmter Berechnungen oder Vorgänge zu verbessern.
Dieser Ansatz muss jedoch nur in Sprachen verwendet werden, in denen es keine Kompilierungsdirektiven gibt. Sprachen, die solche Ressourcen zulassen und einbeziehen, können verschiedene Miniversionen desselben Codes gleichzeitig unterbringen. Die Auswahl zwischen den Versionen erfolgt auf intelligente und organisierte Weise durch die Verwendung von Direktiven.
Als Teil dieser Organisation wird vom Programmierer eine gewisse Erfahrung verlangt. Hier und jetzt werden wir mit den Grundlagen beginnen. Mit anderen Worten, ich gehe davon aus, dass Sie, mein lieber und geschätzter Leser, absolut keine Kenntnisse darüber haben, wie man mit Kompilierdirektiven arbeitet, sie handhabt und Code implementiert.
In den kommenden Artikeln werde ich Ihnen jedoch nach und nach zeigen, wie Sie Aktivitäten im Zusammenhang mit den Kompilierdirektiven integrieren können. Wahrscheinlich werde ich keinen Artikel verfassen, der sich ausschließlich mit diesem speziellen Thema befasst. Dies ist lediglich eine Einführung in das Thema, damit Sie verstehen können, was eine Kompilierdirektive ist.
Nachdem wir nun eine allgemeine Einführung in das Thema gegeben haben, wollen wir uns nun die häufigste Direktive in MQL5-Code ansehen. Aber dafür gehen wir zu einem neuen Thema über.
Die Direktive #INCLUDE
Höchstwahrscheinlich ist dies die Kompilierdirektive, der Sie, lieber Leser, am häufigsten im Code begegnen werden, insbesondere in MQL5 und C/C++-ähnlichem Code. Und warum ist das so? Der Grund dafür ist, dass ein großer Teil, wenn nicht alle erfahreneren Programmierer es NICHT MÖGEN, alles in eine einzige Codedatei zu packen. Wie Sie im Laufe der Zeit feststellen werden, unterteilen erfahrene Programmierer ihren Code normalerweise in kleinere Blöcke. Diese Blöcke entwickeln sich oft zu etwas, das man als eine Bibliothek von Funktionen, Prozeduren, Strukturen und Klassen bezeichnen könnte, die alle in einer sehr logischen Weise organisiert sind. Diese Organisation macht die Programmierung, selbst bei der Erstellung von neuem und einzigartigem Code, extrem schnell und mit minimalen Änderungen möglich. Das Ziel besteht darin, den ursprünglichen Code, den der Programmierer im Laufe der Zeit sorgfältig katalogisiert hat, in eine neue Version des Codes zu verwandeln.
In der Zwischenzeit kann es vorkommen, dass Sie wiederholt Code eintippen müssen, um dieselben Aufgaben zu erledigen.
Ich werde Ihnen jedoch nicht beibringen, wie Sie Ihren Code organisieren müssen, um diese Direktive zu nutzen. Tatsächlich wird Ihnen NIEMAND beibringen, wie man das macht, da es nur Sinn macht, wenn die Person, die den Code pflegt, sorgfältig und akribisch auswählt, wo jedes Element platziert werden soll. Ich werde Ihnen zwar nicht beibringen, wie Sie Ihren Code auf diese Weise organisieren, aber ich kann Ihnen erklären, wie Sie auf den Code zugreifen können, den Sie mit so viel Sorgfalt und Aufmerksamkeit erstellt haben. Das ist der Hauptzweck dieser Direktive: Ihnen den Zugang zu den Dingen auf eine sehr natürliche und praktische Weise zu ermöglichen.
In diesem Fall gibt es keinen Ausführungsablauf. Es gibt zwar einige Details zu beachten, aber wir werden diese nach und nach ansprechen, damit Sie sie auf natürliche Weise verstehen können.
Nehmen wir zunächst einen der in früheren Artikeln behandelten Codes. Dadurch wird das, was wir hier besprechen, vertrauter. Beginnen wir daher mit der Erstellung eines kleinen Anfangscodes. Sie können es unten sehen:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. ulong value; 07. 08. Print("Factorial of 5: ", Factorial(5)); 09. Print("Factorial of 3: ", Factorial(3)); 10. Print(One_Radian()); 11. do 12. { 13. value = Tic_Tac(); 14. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 15. }while (value < 3); 16. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 17. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 18. } 19. //+------------------------------------------------------------------+ 20. double One_Radian() 21. { 22. return 180. / M_PI; 23. } 24. //+------------------------------------------------------------------+ 25. ulong Tic_Tac(bool reset = false) 26. { 27. static ulong Tic_Tac = 0; 28. 29. if (reset) 30. Tic_Tac = 0; 31. else 32. Tic_Tac = Tic_Tac + 1; 33. 34. return Tic_Tac; 35. } 36. //+------------------------------------------------------------------+ 37. ulong Factorial(uchar who) 38. { 39. static uchar counter = 0; 40. static ulong value = 1; 41. 42. if (who) who = who - 1; 43. else 44. { 45. counter = 0; 46. value = 1; 47. } 48. while (counter < who) 49. { 50. counter = counter + 1; 51. value = value * counter; 52. }; 53. while (counter > who) 54. { 55. value = value / counter; 56. counter = counter - 1; 57. }; 58. counter = counter + 1; 59. return (value = value * counter); 60. } 61. //+------------------------------------------------------------------+
Code 01
Sie, lieber Leser, müssen diesen Code 01 unbedingt verstehen können. Dies ist eine Voraussetzung dafür, dass wir von hier an weitermachen können. Wenn Sie diesen Code nicht verstehen können, hören Sie bitte sofort auf und gehen Sie zu den vorherigen Artikeln zurück. Dieser Code ist sehr einfach und sollte unter keinen Umständen verwirrend oder schwer verständlich sein.
Wenn dieser Code ausgeführt wird, wird er im MetaTrader 5-Terminal die folgende Ausgabe erzeugen:
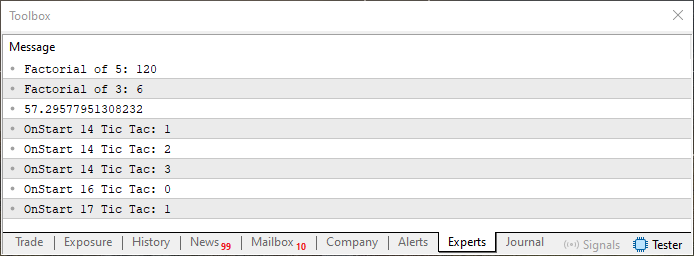
Abbildung 01
Wir tun dies nur, um zu überprüfen, ob es funktioniert. Da wir deutlich sehen können, dass sie wie erwartet funktioniert, können wir jetzt damit beginnen, die Verwendung der Kompilierdirektive zu diskutieren. Vielleicht hätte ich mit einer anderen Direktive beginnen sollen, aber das ist in Ordnung. Da die Direktive #include die am häufigsten verwendete ist, ist es sinnvoll, mit ihr zu beginnen. Also, weiter geht's.
Das erste, was Sie wissen müssen, bevor Sie etwas anderes tun, ist, wie Sie Ihren Code aufteilen. Dies mag trivial erscheinen, ist es aber nicht. Wenn Sie keine Methode finden, die für Sie geeignet und brauchbar ist, werden Sie mit der Zeit ernsthafte Probleme bekommen, wenn Sie versuchen, neuen Code zu erstellen. Wenn Sie jedoch eine Methode entwickeln, die für Sie funktioniert, werden Sie es weit bringen.
Da es sich hier um einen reinen Lehrgang handelt, werden wir die Dinge in drei separate Dateien aufteilen. Jeder enthält eine Funktion oder Prozedur, die ursprünglich in diesem Code 01 vorkommt.
In diesem Sinne könnten Sie denken: „Okay, ich werde die Dateien erstellen.“ Aber das ist nicht der zweite Schritt, den Sie tun sollten, lieber Leser. Es gibt sogar noch einen Schritt davor. Der zweite Schritt, den Sie tun sollten, ist zu antworten: „Wo soll ich die von mir erstellten Dateien ablegen?“ Warten Sie eine Minute. Sollte das Verzeichnis nicht das Include-Verzeichnis sein? Dies ist eine sehr viel persönlichere Frage als alles andere. Der Grund dafür ist, dass der beste Ort nicht immer das Aufnahmeverzeichnis ist. Wenn Sie sich nicht sicher sind, wovon ich spreche, navigieren Sie einfach über den MetaEditor zum MQL5-Ordner, wie in der Abbildung unten gezeigt:
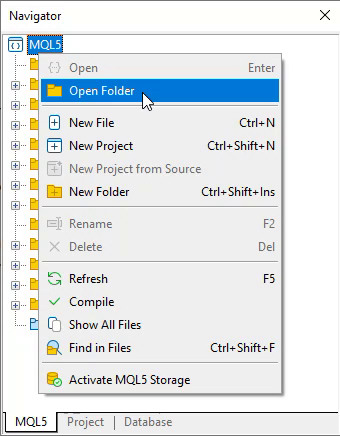
Abbildung 02
Wenn Sie dies tun, sehen Sie einen Ordner mit dem Namen „Include“ im MQL5-Verzeichnis. Dies ist das Standardverzeichnis für die Arten von Dateien, die wir erstellen werden und die üblicherweise als Header-Dateien bezeichnet werden. Wie ich bereits erwähnt habe, ist dies jedoch nicht immer die beste Wahl. Je nach Projekt oder Zielsetzung kann es zu Problemen führen, wenn Sie alle Header-Dateien im Include-Verzeichnis unterbringen. Der Grund dafür ist, dass leicht unterschiedliche Versionen derselben Prozedur oder Funktion mit einer anderen Version, die sich im Include-Ordner befinden könnte oder sollte, in Konflikt geraten könnten.
Viele werden dies jedoch in Frage stellen und fragen: Könnten wir nicht Unterverzeichnisse anlegen, um unsere Header-Dateien besser zu organisieren? Ja, das ist in der Tat eine der häufigsten Praktiken. Doch selbst wenn man diesen Ansatz mit Unterverzeichnissen innerhalb des Include-Ordners verfolgt, ist er in einigen Fällen nicht ideal.
Aber bevor jetzt jemand in Panik gerät, werde ich Ihnen zeigen, wie Sie damit umgehen können. Dies soll Ihnen helfen, Ihren eigenen Code bestmöglich zu organisieren. Wie ich bereits sagte, kann einem niemand beibringen, wie man das macht. Aber wenn Sie verstehen, wie es gemacht werden kann, können Sie Ihre eigene Organisationsstruktur schaffen.
Lassen Sie uns also in diesem ersten Fall etwas ganz anderes tun. Wir werden ein Unterverzeichnis innerhalb des Ordners Scripts erstellen. Dieses Unterverzeichnis enthält alle Funktionen, die in Code 01 beschrieben sind. Aber um die Dinge richtig zu trennen, werden wir dies in Abschnitten behandeln, beginnend mit Lösung 1.
Lösung 1
Die erste Lösung für die Trennung der Funktionen in Code 01 besteht darin, jede Funktion in einer Header-Datei unterzubringen. Diese Dateien befinden sich jedoch in einem Ordner innerhalb des Verzeichnisses Scripts. Ein wichtiges Detail: Verwenden Sie immer die Erweiterung .MQH für die von Ihnen erstellten Header-Dateien. Auf diese Weise ist es einfacher, die Dateien im Dateiexplorer Ihres Betriebssystems zu identifizieren. Damit sind wir in der Liga angekommen. Dadurch wird sichergestellt, dass jede der Dateien den folgenden Inhalt enthält.
1. //+------------------------------------------------------------------+ 2. #property copyright "Daniel Jose" 3. //+------------------------------------------------------------------+ 4. double One_Radian() 5. { 6. return 180. / M_PI; 7. } 8. //+------------------------------------------------------------------+
Datei 01
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. ulong Tic_Tac(bool reset = false) 05. { 06. static ulong Tic_Tac = 0; 07. 08. if (reset) 09. Tic_Tac = 0; 10. else 11. Tic_Tac = Tic_Tac + 1; 12. 13. return Tic_Tac; 14. } 15. //+------------------------------------------------------------------+
Datei 02
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. ulong Factorial(uchar who) 05. { 06. static uchar counter = 0; 07. static ulong value = 1; 08. 09. if (who) who = who - 1; 10. else 11. { 12. counter = 0; 13. value = 1; 14. } 15. while (counter < who) 16. { 17. counter = counter + 1; 18. value = value * counter; 19. }; 20. while (counter > who) 21. { 22. value = value / counter; 23. counter = counter - 1; 24. }; 25. counter = counter + 1; 26. return (value = value * counter); 27. } 28. //+------------------------------------------------------------------+
Datei 03
Ein weiterer wichtiger Punkt: Sobald die Aufteilung erfolgt ist, können Sie selbst entscheiden, wo die Elemente platziert werden und wie die einzelnen Dateien heißen. Hier gibt es keine feste Regel. Es steht Ihnen frei, Ihre eigene Wahl zu treffen.
Nachdem die Codes aus Code 01 extrahiert und in getrennten Dateien untergebracht wurden, sieht der Code nun wie folgt aus:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. ulong value; 07. 08. Print("Factorial of 5: ", Factorial(5)); 09. Print("Factorial of 3: ", Factorial(3)); 10. Print(One_Radian()); 11. do 12. { 13. value = Tic_Tac(); 14. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 15. }while (value < 3); 16. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 17. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 18. } 19. //+------------------------------------------------------------------+
Code 02
Großartig! Es scheint viel einfacher zu sein als das, was wir in Code 01 gesehen haben. Das ist wahr, liebe Leser. Wenn Sie jedoch versuchen, diesen Code 02 zu kompilieren, werden Sie auf eine große Anzahl von Fehlern stoßen, die vom Compiler gemeldet werden. Diese Fehler, wie in der Abbildung unten gezeigt, zeigen an, dass der Compiler den Code nicht interpretieren konnte.
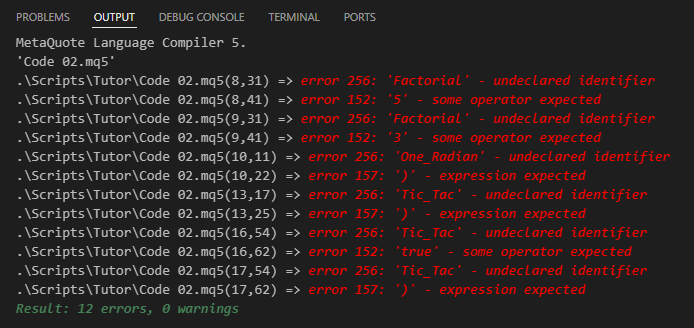
Abbildung 03
In Wirklichkeit liegt es nicht daran, dass der Compiler den Code nicht verstanden hat. Das Problem ist, dass der Compiler nicht weiß, wie er die im Code vorkommenden Prozedur- und Funktionsaufrufe auflösen soll. Aber was bedeutet das? Im Gegensatz zu dem, was viele über Programmiersprachen denken oder annehmen, besteht eine Programmiersprache tatsächlich aus zwei Komponenten. Die erste Komponente wird als Standardbibliothek bezeichnet. Diese Standardbibliothek definiert die Funktionen, Prozeduren, reservierten Wörter, Konstanten und andere Elemente, die wir zur Erstellung von so genanntem User-Level-Code verwenden.
Als Programmierer, der eine bestimmte Sprache verwendet, können Sie die Funktionsweise der Standardbibliothek nicht ändern. Sie können jedoch die darin definierten Elemente nutzen, um Ihre eigenen Lösungen zu entwickeln. Alles, was in der Standardbibliothek enthalten ist, kann verwendet werden, ohne dass spezielle Operationen erforderlich sind. Alles, was nicht in dieser Bibliothek enthalten ist, muss jedoch ausdrücklich in den Code eingefügt werden. Dadurch weiß der Compiler, wie er jeden Funktions- oder Prozeduraufruf auflösen muss, der auftreten kann. Wenn wir also versuchen, Code 02 zu kompilieren, wird er trotz seiner Ähnlichkeit mit Code 01 nicht kompiliert.
Um den Code erfolgreich zu kompilieren, müssen Sie dem Compiler ausdrücklich mitteilen, welche Dateien in den Kompilierungsprozess einbezogen werden sollen. Genau aus diesem Grund wird diese Direktive als Kompilierungsdirektive bezeichnet und trägt den sehr passenden Namen #include. Mit anderen Worten, sie teilt dem Compiler mit, dass er diese Datei bei der Kompilierung des Codes einschließen soll. Verstehen Sie jetzt, lieber Leser?
Wenn Sie dieses Konzept wirklich begreifen, werden Sie in der Lage sein, Dinge zu erreichen, die Sie vorher nicht erreichen konnten. Selbst wenn man versucht, das Programmieren zu erlernen, können einige Aspekte unklar oder ohne konkrete Bedeutung erscheinen. Aber darauf werden wir zu einem anderen Zeitpunkt noch genauer eingehen. Ich möchte Sie nicht mit zu vielen Informationen überhäufen. Ich möchte, dass Sie das, was in jedem dieser Artikel erklärt und demonstriert wird, vollständig verstehen und aufnehmen.
Wenn nun Code 02 nicht kompiliert werden kann, weil der Compiler nicht weiß, wie er auf die erforderlichen Informationen zugreifen soll, wie können wir das Problem lösen? Sollen wir die soeben erstellten Dateien manuell öffnen, jede Funktion oder Prozedur kopieren und direkt in Code 02 einfügen, damit er wieder wie Code 01 aussieht? Denn wenn Code 01 erfolgreich kompiliert wurde, bedeutet dies, dass er korrekt war. Aber dieser Ansatz scheint nicht ganz logisch zu sein. Ich habe gesehen, dass andere Programme funktionieren, ohne dass ganze Codeabschnitte kopiert und in das endgültige Skript eingefügt werden mussten. Jetzt bin ich neugierig. Wie lässt sich dieses Problem lösen? Das ist der einfache Teil. Sie müssen lediglich etwas Ähnliches tun wie im folgenden Code gezeigt:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. #include "Tutorial\File 02.mqh" 06. #include "Tutorial\File 03.mqh" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. ulong value; 11. 12. Print("Factorial of 5: ", Factorial(5)); 13. Print("Factorial of 3: ", Factorial(3)); 14. Print(One_Radian()); 15. do 16. { 17. value = Tic_Tac(); 18. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 19. }while (value < 3); 20. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 21. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 22. } 23. //+------------------------------------------------------------------+
Code 03
Jetzt kommt der interessante Teil. Wenn Sie versuchen, den Code 03 zu kompilieren, erhalten Sie eine Antwort ähnlich der unten abgebildeten:
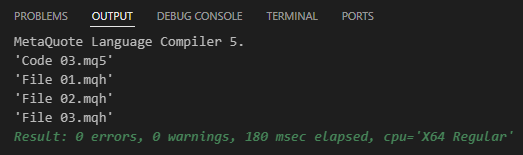
Abbildung 04
Mit anderen Worten: Erfolg. Aber wie? Der Grund liegt in den Zeilen vier, fünf und sechs von Code 03. Diese Zeilen können technisch gesehen an jeder beliebigen Stelle des Codes platziert werden. Aus organisatorischen Gründen werden sie jedoch in der Regel an den Anfang des Drehbuchs gestellt. Es gibt seltene Situationen, in denen sie an anderer Stelle erscheinen können, aber das sind Sonderfälle, die hier nicht zutreffen. Trotzdem ist es fantastisch, die Dinge auf eine viel besser organisierte und praktischere Weise strukturieren zu können.
Es gibt jedoch ein wichtiges Konzept, das Sie zumindest in den Grundzügen verstehen müssen. Wir werden dies in künftigen Artikeln noch genauer untersuchen. Entscheidend ist, wie die einzelnen #include-Direktiven in Code 03 deklariert werden.
Ich werde dies jetzt nicht im Detail erklären. Ich empfehle Ihnen stattdessen, die Dokumentation zu lesen. Wenn ich es jetzt erklären würde, würden Sie vielleicht nicht verstehen, warum es in Code 03 so gemacht wird. Schlimmer noch, Sie könnten am Ende eher verwirrt sein, als dass Sie sich Klarheit darüber verschaffen, warum die Erklärungen in einigen Fällen so und in anderen Fällen anders aussehen.
In der Dokumentation finden Sie weitere Einzelheiten unter Einbindung von Dateien (#include). Diejenigen, die mir schon eine Weile folgen, wissen jedoch, dass es einen bestimmten Grund für die Art und Weise gibt, wie die Zeilen vier, fünf und sechs im Code 03 geschrieben sind.
Unabhängig davon erhalten Sie bei der Ausführung von Code 03 die gleiche Ausgabe wie in Abbildung 01 dargestellt. Kommen wir nun zur zweiten Art der Lösung. Um sie von dieser klar zu trennen, führen wir einen neuen Abschnitt ein.
Lösung 2
Diese zweite Lösung folgt dem Prinzip der Nutzerfreundlichkeit. Mit anderen Worten, wir erstellen etwas, das die Fähigkeit von MQL5 erweitert, neuen Code zu erstellen oder Code schneller zu generieren. Es ist nicht ungewöhnlich, dass andere Programmierer modifizierte Header-Dateien verteilen, die ursprünglich in MetaTrader 5 enthalten sind. Ich persönlich finde diese Verteilungen recht nützlich, da einige Änderungen sehr interessant sein können. Es stellt sich jedoch die Frage, wo diese Dateien abgelegt werden sollen.
Dies ist deshalb so wichtig, weil MetaTrader 5 regelmäßig aktualisiert wird. Wenn Sie eine geänderte Header-Datei haben, egal ob sie von jemand anderem erstellt oder von Ihnen angepasst wurde, und Sie sie für Ihre Entwicklungsarbeit äußerst praktisch und nützlich finden, sollten Sie sie nicht einfach irgendwo speichern. Wenn sie sich im Include-Verzeichnis innerhalb des MQL5-Ordners befindet, könnte sie beim nächsten MetaTrader 5-Update überschrieben werden. In diesem Fall würden Sie Ihre wertvolle Datei verlieren.
Hierfür gibt es eine Lösung: Benennen Sie die geänderte Header-Datei um. Sie können aber auch den im vorigen Abschnitt beschriebenen Ansatz verwenden. Beide Methoden werden funktionieren. Beim ersten Ansatz stoßen Sie jedoch auf einige Einschränkungen. Zum Beispiel wird es schwieriger sein, auf Header-Dateien zuzugreifen, die außerhalb des aktuellen Verzeichnisses gespeichert sind. Dies ist zwar nicht unmöglich, erfordert aber zusätzliche Schritte zur Verwaltung.
Wenn wir dieselbe Header-Datei in mehreren, nicht miteinander verbundenen Anwendungen verwenden wollen, ist es daher am besten, sie an einem einzigen, zentralen Ort zu speichern. Hier tun wir dies innerhalb des Include-Verzeichnisses. Denken Sie jedoch immer daran, regelmäßig Backups zu erstellen. Idealerweise sollten Sie ein Versionskontrollsystem verwenden, um Ihre Dateien effizient zu verwalten.
Dafür empfehle ich die Verwendung von GIT. Mehr darüber können Sie in meinem anderen Artikel erfahren: „GIT: Was ist das?“. Der richtige Umgang mit GIT erspart Ihnen unzählige Kopfschmerzen und schlaflose Nächte. Aber natürlich müssen Sie lernen, das Werkzeug richtig einzusetzen.
Nun zurück zu unserem Thema. Wir können nun dieselben Dateien aus dem vorherigen Abschnitt wiederverwenden, sie aber im Verzeichnis „include“ speichern. Auf diese Weise können wir zwei verschiedene Versionen derselben Datei beibehalten: eine, auf die jede von Ihnen erstellte Anwendung leicht zugreifen kann, und eine andere, die speziell für das Projekt ist, an dem wir hier arbeiten. Um dies zu demonstrieren und zu beweisen, dass es möglich ist, ändern wir eine der Dateien aus dem vorherigen Abschnitt. Tatsächlich werden wir jetzt zwei Versionen davon pflegen: eine, die nur für das aktuelle Projekt zugänglich ist, und eine weitere, die für jedes von Ihnen entwickelte Skript zur Verfügung steht. Diese Datei ist unten abgebildet:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. double One_Radian() 05. { 06. return 180. / M_PI; 07. } 08. //+------------------------------------------------------------------+ 09. double ToRadians(double angle) 10. { 11. return angle / One_Radian(); 12. } 13. //+------------------------------------------------------------------+ 14. double ToDegrees(double angle) 15. { 16. return angle * One_Radian(); 17. } 18. //+------------------------------------------------------------------+
Datei 04
Da wir von den Grundlagen ausgehen, werde ich einige Dinge, die wir tun könnten, nicht zeigen. Ich werde mich darauf konzentrieren, wie Sie mit der Header-Datei arbeiten können. Jetzt haben wir zwei Dateien, die zwei identische Versionen derselben Funktion enthalten, in diesem Fall die Funktion One_Radians. Das mag Ihnen jetzt noch trivial und unwichtig erscheinen, aber wenn wir tiefer gehen und neue Funktionen enthüllen, werden wir sehen, dass diese Situation nützlich sein kann. Wir werden das zu gegebener Zeit in Ordnung bringen.
Jetzt wollen wir, dass Datei 04 anstelle von Datei 01 verwendet wird. Der Grund dafür ist, dass sie andere Funktionen enthält, die wir verwenden wollen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. #include "Tutorial\File 02.mqh" 06. #include "Tutorial\File 03.mqh" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. ulong value; 11. 12. Print("Factorial of 5: ", Factorial(5)); 13. Print("Factorial of 3: ", Factorial(3)); 14. Print(One_Radian()); 15. Print(ToRadians(90)); 16. do 17. { 18. value = Tic_Tac(); 19. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 20. }while (value < 3); 21. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 22. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 23. } 24. //+------------------------------------------------------------------+
Code 04
Wenn Sie versuchen, Code 04 zu kompilieren, erhalten Sie das in der folgenden Abbildung dargestellte Ergebnis.
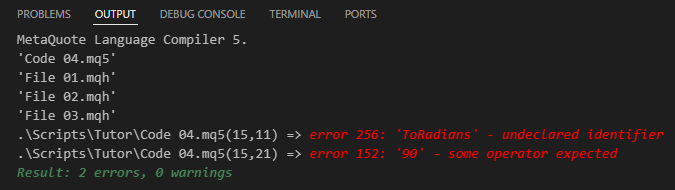
Abbildung 05
Dies beweist, dass ein Fehler im Code vorliegt. Dieses Problem lässt sich jedoch leicht beheben, auch wenn Sie als Programmierer sehr aufmerksam sein müssen. Die Herausforderung entsteht, wenn man mit Header-Dateien arbeitet, die verschiedene Versionen einer Funktion oder Prozedur mit demselben Namen enthalten. An dieser Stelle wird es knifflig. Sie müssen selbst lernen, wie Sie mit dieser Situation umgehen. Leider gibt es keine allgemeingültige Methode oder einfache Erklärung für diesen Fall. Der Grund dafür ist ganz einfach: Es hängt alles davon ab, wie Sie Ihren Code im Laufe der Zeit strukturiert haben. Abgesehen von dieser Komplexität ist die Lösung für die Zwecke dieses Lehrbeispiels recht einfach. Tatsächlich ist die Fehlermeldung auf eine fehlende Funktion zurückzuführen, die in Zeile 15 stehen sollte. Da diese Funktion in keiner der im 04-Code enthaltenen Header-Dateien enthalten ist, wird die Kompilierung immer fehlschlagen. Um dies zu beheben, müssen wir dem Compiler mitteilen, wo er die richtige Datei finden kann, die die notwendige Funktion enthält, damit Zeile 15 funktioniert. Die Lösung besteht darin, den Code in Code 05 zu ändern, der im Folgenden dargestellt wird:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include <Tutorial\File 01.mqh> 05. #include "Tutorial\File 02.mqh" 06. #include "Tutorial\File 03.mqh" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. ulong value; 11. 12. Print("Factorial of 5: ", Factorial(5)); 13. Print("Factorial of 3: ", Factorial(3)); 14. Print(One_Radian()); 15. Print(ToRadians(90)); 16. do 17. { 18. value = Tic_Tac(); 19. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 20. }while (value < 3); 21. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 22. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 23. } 24. //+------------------------------------------------------------------+
Code 05
Beachten Sie, dass die Änderung sehr geringfügig zu sein scheint. Diese kleine Anpassung ist jedoch beabsichtigt. Es dient dazu, zu zeigen, dass es wichtig ist, zu üben und wirklich zu verstehen, wie die Dinge in der realen Welt der Programmierung funktionieren. Wenn Sie versuchen, Code 05 zu kompilieren, wird das Ergebnis wie unten dargestellt sein:
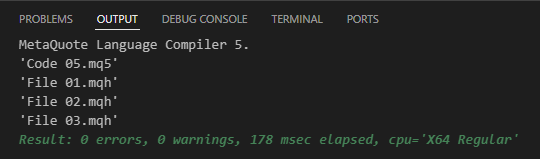
Abbildung 06
Dies bestätigt, dass sich die in Zeile 4 eingeschlossene Datei tatsächlich im Include-Verzeichnis befindet. Sie können dies in der beigefügten Datei sehen, die visuell veranschaulicht, wie alles in der Praxis organisiert werden sollte. Der letzte Punkt, der in diesem Artikel gezeigt wird, ist das Ergebnis der Ausführung von Code 05:
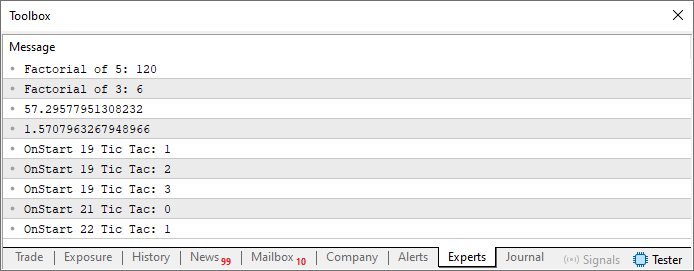
Abbildung 07
Abschließende Überlegungen
In diesem Artikel haben wir uns mit einer der am häufigsten verwendeten Kompilierdirektiven beschäftigt. Obwohl wir uns auf einen einzigen Aspekt konzentriert haben, ist es unmöglich, alles, was diese Direktive leisten kann, in nur einem Artikel zu behandeln. Selbst wenn wir mehrere Artikel allein zu dieser Direktive verfassen würden, wäre es schwierig, einige Aspekte vollständig zu erklären. Denn was jemanden wirklich zu einem großartigen Programmierer macht, ist nicht nur die Fähigkeit, ein Programm so zu strukturieren, dass es Ergebnisse liefert. Es geht darum, die eigene Identität als Entwickler zu organisieren. Das bedeutet, dass Sie nützliche und häufig verwendete Codeschnipsel in Header-Dateien erstellen und katalogisieren, um sie bei Ihren täglichen Programmieraufgaben leichter wiederverwenden zu können.
Und wie kann man das lernen? Das kann einem niemand beibringen. Das ist etwas, das man nur durch Übung und Zeit meistern kann. Sie müssen jedoch den ersten Schritt tun. Ziel dieses Artikels ist es, Sie bei diesem ersten Schritt zu unterstützen. Ich hoffe, Sie haben diesen Artikel als nützlich empfunden, lieber Leser. In der nächsten Folge werden wir eine weitere Kontrollflussdirektive untersuchen. Also, wir sehen uns dort!
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15383
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wieder der Unsinn des Autors. Zitat:" Aber es gibt einige Direktiven in C/C++, die in MQL5 nicht verfügbar sind. Eine davon ist #ifdef, die, obwohl sie uninteressant erscheinen mag, uns in manchen Momenten sehr hilft, bestimmte Teile der Version, an der wir arbeiten, zu kontrollieren. "
#ifdef gibt es in MQL4 und MQL5 schon sehr lange.
Warum lesen Sie das? 🤦♀️
Wieder der Unsinn des Autors. Zitat:" Aber es gibt einige Direktiven in C/C++, die in MQL5 nicht verfügbar sind. Eine davon ist #ifdef, die, obwohl sie uninteressant erscheinen mag, uns in manchen Momenten sehr hilft, bestimmte Teile der Version, an der wir arbeiten, zu kontrollieren. "
#ifdef gibt es in MQL4 und MQL5 schon sehr lange.
Warum lesen Sie das? 🤦♀️
Sein Spitzname in der Basis ist vDev - dies ist sein Thema!!!
Lekha - lass uns den Skalp testen!!!! )
O autor está falando bobagem de novo. Zitat: " Mas em C/C++ há algumas diretivas que não estão no MQL5. Um deles é o #ifdef, que, embora possa parecer desinteressante, em alguns pontos realmente nos ajuda a controlar certas partes da versão em que estamos trabalhando. "
#ifdef está no MQL4 e MQL5 há muito tempo.
Entschuldigung. Es war jedoch ein Fehler meinerseits, sich auf die Richtlinie im Text zu beziehen. Ich wollte mich auf die #if-Direktive beziehen, denn die #ifdef-Direktive ist das Äquivalent zur #if defined-Direktive in C und C++. Aber um es hier in MQL5 zu verallgemeinern, verwenden wir #ifdef, das auch in C und C++ vorhanden ist. Auch hier soll auf die #if-Direktive verwiesen werden, die einen ganz anderen Zweck hat und sogar zur Überprüfung der Werte von Definitionen verwendet werden kann. Aufgrund eines Schreibfehlers habe ich jedoch #ifdef eingefügt und dies nicht bemerkt. Ich entschuldige mich für dieses Versehen meinerseits. 👍
Entschuldigung. Es ist mir jedoch ein Fehler unterlaufen, als ich mich auf die Richtlinie im Text bezog. Ich wollte mich auf die #if-Direktive beziehen, denn die #ifdef-Direktive ist das Äquivalent der #if defined-Direktive, die es in C und C++ gibt. Aber um es hier in MQL5 zu verallgemeinern, verwenden wir #ifdef, das es auch in C und C++ gibt. Auch hier soll auf die #if-Direktive verwiesen werden, die einen ganz anderen Zweck hat und sogar zur Überprüfung der Werte von Definitionen verwendet werden kann. Aufgrund eines Schreibfehlers habe ich jedoch #ifdef eingefügt und dies nicht bemerkt. Ich entschuldige mich für dieses Versehen meinerseits. 👍
Das ist okay, jeder hat seine Momente )
Warum lesen Sie das? 🤦♀️
Ich bin durch Zufall auf diesen Artikel gestoßen, die Website hat ihn in den Links angegeben.