
初級から中級まで:配列(I)

はじめに
ここで提示されるコンテンツは、教育目的のみに使用されることを意図しています。いかなる状況においても、提示された概念を学習し習得する以外の目的でアプリケーションを利用することは避けてください。
前回の「初級から中級まで:配列と文字列(III)」では、これまでに習得してきた知識レベルに合ったコードを用いて、標準ライブラリがバイナリ(2進数)値を10進数、8進数、16進数に変換する方法を解説し、実演しました。また、2進数の文字列表現を生成することで、結果を視覚的に把握しやすくする方法についても取り上げました。
この基本的な概念に加えて、秘密のフレーズに基づいてパスワードの長さを定義する方法についても説明しました。偶然にも、生成されたパスワードには文字列の繰り返しが含まれており、意図した結果ではなかったにもかかわらず、興味深い現象が見られました。これは単なる幸運な偶然でしたが、配列や文字列に関する他のさまざまな概念やポイントを説明する絶好の機会でもあります。
中には、標準ライブラリに含まれる各関数や手続きの詳細な動作についての解説を期待している読者もいらっしゃるかもしれません。しかし、私の本来の目的は、それぞれの選択の背後にある考え方や概念を明らかにすることです。皆さん自身が、解決すべき問題の性質に応じて適切な選択をできるようになってほしいと考えています。まだ基本的な段階ではありますが、すでに実用的なプログラミングの可能性が見えてきています。これにより、少し高度な概念を取り入れることも可能になります。
こうしたアプローチは、コーディングをより簡単にするだけでなく、複雑なコードを読みやすくする手助けにもなります。これから紹介する内容について、不安に感じる必要はありません。変更は段階的に導入していくので、安心して読み進めてください。私は、表現を省略・圧縮する傾向があり、初心者には少しわかりにくいこともあるかもしれませんが、そのスタイルにも徐々に慣れていただければと思います。
それでは、前回取り上げた内容を振り返るところから始めましょう。つまり、秘密のフレーズからパスワードを生成する際に、因数分解のプロセスによって偶然生じた結果を避けるための、数ある方法の一つを学んでいきましょう。
数ある解決策の一つ
さて、今日は、まずコードをもう少しエレガントにすることから始めます。元のコードを以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
コード01
私の見解では、これはあまり洗練されたコードではありません。16行目と17行目で宣言された変数が、21行目のループ内でしか使用されていないからです。仮に将来、同じ名前の変数や異なる型の変数が必要になった場合、それに対応するためにコードの調整に余分な手間がかかることになります。前回の記事でも取り上げたように、FORループの中で直接変数を宣言することは可能です。
さて、親愛なる読者の皆さん、ここで注意していただきたいのは、FORループ内でのみ使用することを目的として複数の変数を宣言する場合、それらはすべて同じ型でなければならないという点です。FORループの最初の式で異なる型の変数を同時に宣言・初期化することはできません。ですので、ここで小さな決断を下す必要があります。16行目と17行目に宣言されている変数「pos」と「i」はuchar型ある一方、FORループ内で宣言されている変数「c」はint型です。「pos」と「i」をintに変更するか、「c」をucharに変更するという選択肢があります。私の意見としては、フレーズが255文字を超えることはまずないと考えられるため、妥協案として、インデックスとしてのみ使用されるこれら3つの変数をすべてushort型に統一するのが適切でしょう。このような考えに基づいて、コード01をコード02へと改良していきましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+
コード02
コード02は一見複雑に見えますが、コード01と同じ処理を実行します。しかし、20行目に注目してください。ここでは、ループ内でのみ使用されるすべての変数を、for文の最初の式で宣言しています。そして、for文の3番目の式にも注目してください。この書き方では、三項演算子を使わなければ変数「i」の値をこのように調整することはできません。ただし、ここでおこなっているのは、インデックスが配列の範囲を超えないように制御しているだけです。実際のインクリメント処理は、23行目でおこなわれています。
この変更があっても、出力結果はまったく変わりません。つまり、コードを実行すると、以下の画像のような表示が端末に現れます。
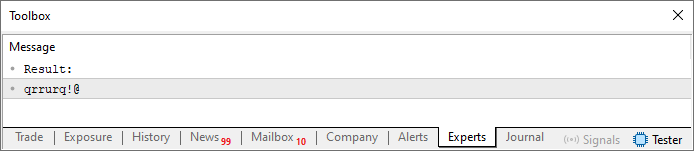
図01
さて、少し考えてみましょう。出力文字列内の記号の繰り返しは、27行目でszCodePhrase文字列の同じ位置を参照しているために発生しています。つまり、13行目で定義された文字列の長さ内に収まるように値を減らしているため、同じ場所を繰り返し参照してしまうのです。しかし(ここが重要なポイントですが)、現在の位置と前の位置を合計すれば、前とはまったく異なる新しいインデックスを生成できます。13行目の文字列には重複した文字が含まれていないため、出力文字列、つまりパスワードにも重複した文字は含まれません。
ここで覚えておくべき重要なことがあります。このテクニックは必ずしも常にうまく機能するわけではありません。なぜなら、13行目で定義された文字列の文字数が必ずしも理想的とは限らないからです。別のケースでは、値がちょうど完全なサイクルに陥ってしまう可能性があります。これは、基本的に13行目で宣言された文字や記号のループを扱っているためで、このループでは最初の文字(閉じ括弧)が最後の文字(数字の9)につながっているようなものです。まるで蛇が自分の尻尾を噛んでいるような状態です。
プログラマー以外の多くの人はこの概念を理解しにくいですが、コードを扱う際にはこうしたことが何らかの形で必ず起こります。
さて、これから何をするのか説明したところで、実際のコードを見てみましょう。すぐ下に掲載しています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 0) + psw[c]) % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+s
コード03
このアプローチは非常に興味深いものです。ご覧のとおり、コードにはほとんど変更を加えていません。新しく追加されたのは27行目だけです。20行目のforループの第3式で行った処理と非常によく似たことをしています。ただ、それについて詳しく説明する前に、まずは結果を見てみましょう。以下に表示されています。
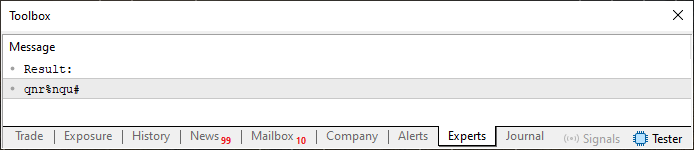
図02
先ほどまで繰り返し表示されていた文字が、もはや存在しないことが確認できます。しかし、コード03のたった1行を変更するだけで、さらに改善することが可能です。前回の記事で説明したように、27行目で使用されている三項演算子は、IF文のように機能します。そのため、最初に計算される値には調整が加えられません。一方で、それ以降のすべての値には、前回のループで使用されたインデックスに基づいて調整がおこなわれます。ここで重要なのは、この調整に使われている配列の値は、20行目のループ内で計算されたものではなく、13行目で定義された文字列から取得された値であるという点です。したがって、その正確な値を求めるには、ASCII表を参照し、その値を20行目で算出された値に加算する必要があります。少しややこしく感じられるかもしれませんが、落ち着いて考えてみれば、実はとてもシンプルです。
ここで、三項演算子に使われている「0」という値に注目してください。これが、最初のインデックスが変更されない理由です。では、この「0」を別の値に置き換えたらどうなるでしょうか。たとえば、27行目を次のように変更するとします。
psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 5) + psw[c]) % StringLen(szCodePhrase)]);
次の画像でわかるように、結果はまったく異なります。
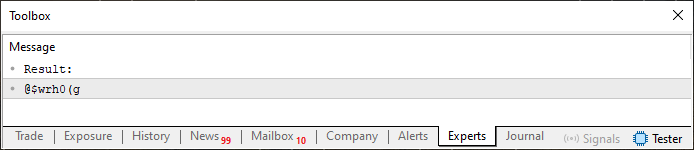
図03
面白いと思いませんか。ほんの少し変更を加えるだけで、多くの人が強力なパスワ ードだと考えるものを生成できるのです。そして、それを実現するのに使ったのは、基本的な計算と、覚えやすい2つのフレーズだけです。これらすべてを、私自身がまだ「初心者レベル」と考えているプログラミング知識だけで達成できたという点にも注目してください。プログラミングを始めたばかりの人にとっても、これは決して悪くない成果だと思います。読者の皆さんも、ぜひ新しい可能性を探求しながら、いろいろと試してみてください。今回紹介したのは、経験豊富なプログラマーであれば数分で実装できるような、シンプルで基本的な例にすぎません。
これが、配列を使ったデモンストレーションの中で最も簡単な部分でした。しかし、まだ終わりではありません。より高度で複雑なトピックに進む前に、配列についてもう少し詳しく見ておく必要があります。それでは、新しいトピックに進みましょう。
データ型と配列との関係
プログラミングにおいて最も複雑で、混乱しやすく、習得が難しいテーマのひとつが、まさにこのセクションで取り上げる内容です。もしかすると、読者の皆さんはまだ、このトピックが実際にどれほど複雑で奥深いものなのかを実感していないかもしれません。自分は優れたプログラマーだと思っている人でさえ、こうした概念同士の相互関係をまったく理解していない場合があり、その結果、本来は可能であったり、それほど難しくないタスクを、不可能あるいは非常に困難であると決めつけてしまうことがあります。
ですが、このテーマを少しずつ理解していくことで、最初は無関係に思える他の多くの概念についても、実は深いところで密接に結びついていることに気づくはずです。
まず、コンピュータのメモリについて考えてみましょう。プロセッサが8ビット、16ビット、32ビット、64ビット、あるいは48ビットといった珍しい構成であっても、それ自体は本質的な問題ではありません。同様に、2進数、8進数、16進数、あるいは他の数値表現を扱っているかどうかも、ここでは重要ではありません。本当に注目すべきは、データ構造がどのように設計・構築されているかという点です。たとえば、1バイトは8ビットだと定めたのは誰でしょうか。なぜ8なのでしょうか。10ビット、または12ビットではだめだったのでしょうか。
今のところは、この話があまりしっくりこないかもしれません。というのも、数十年にわたる実践的な知識や経験を、初心者にもわかる形に要約するのは非常に難しいからです。特定の概念をまだ紹介していない状態でこうしたテーマに踏み込むのは少し無理がありますが、これまでの記事で扱ってきた内容をベースにすれば、少し楽しく実験してみることもできます。今回は、あるデータ型の配列と、それとは異なるデータ型の変数を使ってみましょう。ただし、1つだけルールがあります。配列に使うデータ型は、変数のデータ型と同じであってはなりません。それでも、いくつかの簡単なルールを守れば、これらを相互に連携させたり、同じ種類の値を保持させたりすることが可能です。
複雑で、はるかに多くのプログラミング知識が必要なように思えますが、実際に試してみて確かめてみましょう。より楽しみながら進められるよう、今回は前回の記事で使った関数(2進数値を他の形式に変換する関数)をもう一度使ってみましょう。
いいアイデアですね。この関数は今後さまざまな概念を説明する際に頻繁に使うことになるので、今回はヘッダーファイルに分けておきましょう。それでは、次に示すコードをご覧ください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
コード04
さて、ここで重要なことをひとつお伝えします。コード04はヘッダーファイルであり、チュートリアル用スクリプトにのみ使用されることを意図しています。そのため、このファイルはscriptsディレクトリ内のサブフォルダに配置します。この点については、以前に詳しく説明したので、ここでは繰り返しません。それでは進みましょう。では、ここでひとつ覚えておいていただきたいことがあります。今回変換をおこなうすべての値は、符号なし(unsigned)として扱う必要があります。少なくとも、コード04にある関数の細かな修正が完了するまでは、このルールに従ってください。
この準備が整えば、すべてが正しく動作しているかどうかを簡単なスクリプトを使ってテストすることができます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation via standard library.\n" + 11. "Decimal: %I64u\n" + 12. "Octal : %I64o\n" + 13. "Hex : %I64X", 14. value, value, value 15. ); 16. PrintFormat("Translation personal.\n" + 17. "Decimal: %s\n" + 18. "Octal : %s\n" + 19. "Hex : %s\n" + 20. "Binary : %s", 21. ValueToString(value, 0), 22. ValueToString(value, 1), 23. ValueToString(value, 2), 24. ValueToString(value, 3) 25. ); 26. } 27. //+------------------------------------------------------------------+
コード05
このスクリプトを実行すると、出力は次の画像のようになります。
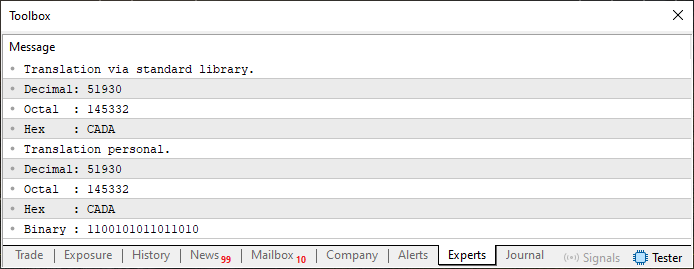
図04
ちゃんと動作しています。これで、異なるデータ型の配列と変数を使った実験を始める準備が整いました。ここから先では、特定のプログラミング言語でしか見られない、非常に興味深い挙動を少しずつ理解できるようになっていきます。まず、コード05に少しだけ変更を加えます。このバージョンが私たちの出発点となる「ゼロフレーム」です。その内容を以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA}; 09. ushort value = 0; 10. 11. value = (array[0] << 8) | (array[1]); 12. 13. PrintFormat("Translation personal.\n" + 14. "Decimal: %s\n" + 15. "Octal : %s\n" + 16. "Hex : %s\n" + 17. "Binary : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2), 21. ValueToString(value, 3) 22. ); 23. } 24. //+------------------------------------------------------------------+
コード06
さて、ここで読者の皆さんにお願いがあります。これから先の内容に全集中できるよう、気を散らすものは一旦脇に置いてください。これから扱うテーマは、多くの初心者プログラマーにとって非常に混乱しやすいものだからです。もちろん、すべてのプログラマーというわけではありませんが、特定の言語、たとえばMQL5のような言語を使っている人にとっては、特に戸惑いやすい部分です。
説明に入る前に、コード06を実行した結果を見てみましょう。以下に示します。
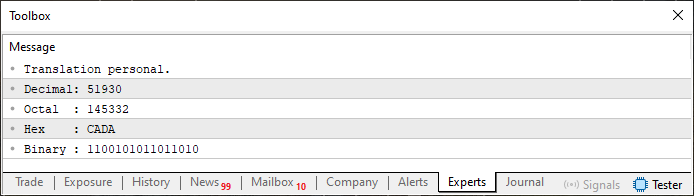
図05
ここで見ているコード06は、非常に幅広い概念の基礎となるものです。このコードを本質的に理解できれば、このあとに続く関連トピックも難なく理解できるようになるでしょう。というのも、それらの多くは、何らかの形でこのコードがおこなっている処理に基づいているからです。
最初のうちは、この一見シンプルなコードが実はどれほど複雑で、また、このような実装が可能だからこそ達成できることがどれほど多いか、なかなか実感できないかもしれません。だからこそ、少しずつ丁寧に進めていきましょう。ある程度経験がある方にとっては、この後に説明する内容はおそらく目新しいものではないと思います。しかし、まだ勉強を始めたばかりの方にとっては、ここでの説明は少し分かりにくいかもしれません。
正直に言うと、少し先走ってしまったかもしれません。では、少し話を戻しましょう。ここで質問です。これまでの説明だけをもとに、コード06のどの部分が理解できないと感じますか。おそらく、8行目と11行目ではないでしょうか。実際、プログラミングを始めたばかりの方にとっては、この2行の意味は直感的に理解しづらいと思います。この記事の前のセクションでも、似たような記述を見てきました。具体的には、コード03の15行目、20行目、23行目、27行目です。
ただし、コード06では少し動作が異なります。完全に違うわけではありませんが、混乱を招く程度には異なっているのです。もしかすると、私が配列についてきちんと説明する前に使ってしまったのがよくなかったのかもしれません。その点については、お詫びします。特に、図05に表示されたコード06の出力を見たときに、戸惑ってしまった方もいるのではないでしょうか。
ですので、ここで一度立ち止まって、順を追って正しく進めていきましょう。まずは、コード06の11行目から見ていきます。この行は、実は以下のコードとまったく同じ意味になります。
value = (0xCA << 8) | (0xDA);
最初は、少し複雑に見えるかもしれません。たとえ、ビットシフト演算子の動作についてはすでに説明していたとしてもです。そこで、視覚的な補助ツールを使ってみましょう。そうすれば、はるかに理解しやすくなるはずです。
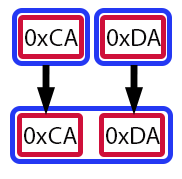
図06
この図では、赤い四角形がそれぞれ1バイト(より正確にはuchar型の値)を表しています。青い四角形は変数を示しており、矢印は処理の中で値がどのように移動・変化するかを示しています。つまり、図06は、11行目で変数valueの値がどのように構成されたのかを視覚的に表しています。「ちょっと確認させてください。つまり、valueがushort型であっても、そこにuchar型の値を挿入できるということですか。そうすることで、まったく新しい数値を作り出すことができるんですね。」その通りです、読者の皆さん。でも、話はそれだけでは終わりません。この概念をしっかり理解するためにも、ここは焦らず一歩ずつ丁寧に進めていきましょう。
すでにご存じのように、8行目で定義されたメモリ領域は定数領域です。しかし、そこにはもうひとつ注目すべき点があります。このメモリブロックの中では値が初期化されています。これをあえてたとえるなら、昔のゲーム機に使われていた「ROMカセット」のようなものだと考えてもいいかもしれません。

図07
RAM内にROMを作成するという表現は、一見すると奇妙に思えるかもしれません。しかし、実際のところ、8行目でおこなわれているのはまさにそのような処理です。
では、ここでまた質問です。8行目で定義された「ROM」のサイズは一体どれほどでしょうか。これは一概には言えません。これはごまかしではなく、事実に基づいた説明です。幸いなことに、標準ライブラリには、確保されたメモリ領域のサイズを取得するための関数が用意されています。ここであらためて確認しておきたいのは、配列は文字列として扱うことも可能ですが、文字列はあくまで特殊な形式の配列であるという点です。たとえば、これまでの例では、単純なフレーズからパスワードを生成する目的で配列を使用しました。しかし、コード06で使用されている配列は、文字列ではなく純粋なデータ配列であり、任意の値を表すために設計されたものです。もっとも、uchar型として定義されているため、格納できる値の範囲は制限されることになります。ここで着目すべき点は、このような小さな型の配列に対して、より大きなデータ型を用いてその内容を再解釈することが可能であるということです。
その際に必要となるのは、配列全体に含まれるビット数を保持可能なデータ型です。これこそが、図06が視覚的に示していた内容となります。図中の青色の領域は、配列内の複数のビットを1つの論理的な値としてまとめたものを表現しています。この概念をより明確に理解するために、8行目のコードにいくつかの情報を追加し、その結果がどのように変化するかを観察してみましょう。ただし、説明が複雑になりすぎないよう、以下のように簡潔にコードを修正することとします。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+
コード07
確かに、コード07でおこなっている処理は、一見すると常軌を逸しているように見えるかもしれません。しかし、その実行結果をご覧ください。以下です。
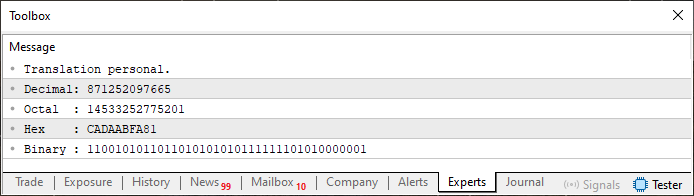
図08
これは完全に狂っていると言いたくなるかもしれません。しかしご覧のとおり、読者の皆さん、これは実際に動作します。つまり、2進数、16進数、そして10進数を1つの配列の中で組み合わせて使用したということです。そして最終的に、何らかの情報を保持する、ROMのような小さなメモリブロックを構築することができました。しかし最も驚くべき点は、ここで見ているのが、巨大な氷山のほんの一角にすぎないということです。
さらに深く掘り下げる前に、ここで実際に何が起こったのか、そしてこのような構成を扱う際に注意すべき制限や留意点について、少し立ち止まって確認しておきましょう。
8行目では、単にデータを追加しただけです。では、そこに配置できるデータの最大量はどれくらいでしょうか。答えは、無限に、あるいは少なくとも、システムが許容する限りにおいて、です。実際には、格納できるデータ量はマシンのメモリ容量に依存します。ただし、8行目の配列には事実上無制限に値を入れることが可能であっても、value変数に関してはそうではありません。ここに厳密な制限があります。この例では、読者の皆さんにできる限り自由に実験していただけるように、MQL5で現在サポートされている最大ビット幅、つまり64ビット(8バイト)を使用しました。では、value変数には8バイトまでしか保存できないのでしょうか。正確にはそうではありません。実際には、64ビットに達した時点で、新しいデータは既存の値を上書きしていくことになります。これにより、一種のデータフローモデルが形成されますが、これについては後ほど詳しく説明します。
重要なのは、この変数が最大64ビットを保持できるという点です。ただし、それが「8つの値」とは限りません。そしてまさにここが、これまでの内容を読まずに本記事から読み始めた方にとって、混乱の始まりとなる部分です。
さて、11行目のループと12行目の処理内容を見ていく前に、コード07のほんの小さな箇所を修正してみましょう。この変更によって、配列のサイズや含まれる情報量の概念がよりはっきりと見えるようになります。その変更は、以下のコードのようになります。
const ushort array[] = {0xCADA, B'1010101111111010', 0x81}; 上記の変更後の行を見てみると、配列の要素数はもはや5つではなく、3つになっていることがわかります。そして重要なのは、要素数が減ったにもかかわらず、使用するメモリ量はほとんど変わっていないという点です。違いは、8ビットのメモリが無駄になっていることです。というのも、コード07では各バイトが完全に利用されていたのに対して、この新しい構成では、配列の最後の値が16ビット中の8ビットしか使用していません。これくらいの無駄は許容範囲だと思えるかもしれません。後ほどこの点についてもさらに詳しく見ていきますが、今はまず、使用するデータ型がメモリ使用量に影響を与えること、そして場合によってはコードの挙動にも影響を与えることを押さえておいてください。
しかし、さらに悪いケースもあります。それは以下のような行を使う場合です。
const int array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 多くの開発者が、すべての変数に対して最適なデータ型を使うことをあまり気にしていないことは理解しています。しかし、このコードをコード07の中で使ったとしても、見た目上は何の問題もないように思えるかもしれません(実際に現時点では問題は起きません)。ですがこの場合、1要素あたり8ビットの無駄ではなく、16ビットずつの無駄が発生しています。5つの要素があるとすれば、合計で80ビット、つまり10バイトが無駄になる計算です。これは、この記事の冒頭で構築したパスワードの幅よりも大きいのです。
もちろん、今日のマシンでは32GB以上のRAMが搭載されていることも珍しくないため、この程度のメモリの無駄は問題にならないと思えるかもしれません。そして実際、この例においては、無駄があってもコードの動作自体に変化はありません。これは、11行目と12行目のロジックが正しく機能しているおかげです。
ここでおこなっているのは、配列内の各要素に対して、valueに格納されている値を8ビット左にシフトし、新しい要素のためのスペースを確保する、という処理です。それが12行目でおこなわれています。ただしこの行は、変数cによって示される配列の特定の要素だけを対象としています。では、配列にいくつの要素があるのかはどうやって知るのでしょうか。それが示されているのが11行目です。forループの条件式の2つ目の項目が、その情報を提供しています。ここでは、MQL5の標準ライブラリに含まれる関数を呼び出しているのです。
この関数はArraySize()を使うのと同等です。このようにして、各要素が実際に使うビット数に関係なく、配列にいくつの要素が存在しているのかを判断することができます。
この動作を試してみたい場合は、次のようにコードを修正するだけでかまいません。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. Print("Number of elements in the array: ", ArraySize(array)); 25. } 26. //+------------------------------------------------------------------+
コード08
コード08を実行すると、下の図の強調表示された領域に示すように、配列内に存在する要素の数を確認できます。
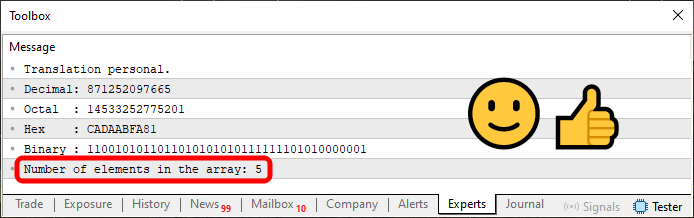
図09
最後に
さて、親愛なる読者の皆さん。この記事には、すでに皆さんが学び、吸収すべき豊富な内容が含まれています。ですので、ここで一旦立ち止まり、これまで取り上げたことを復習し、実際に手を動かして練習する時間を取っていただければと思います。この記事で扱った配列はROM型、つまり内容を変更できないものですが、それでもここで解説された基礎概念をしっかりと理解することは非常に重要です。これらは配列操作に関する基盤となる知識だからです。一度にすべてを理解するのは難しいかもしれませんが、粘り強く取り組み、より深い理解を目指していただきたいと思います。
この記事、そしてこれまでの連載で解説した概念をしっかりと習得することは、プログラマーとしての皆さんの成長にとって大きな支えになるはずです。そして、ここから先の内容はさらに複雑になっていきます。難易度も増していきますが、それに臆することなく、むしろ挑戦を楽しんでください。ぜひ実際に手を動かして練習し、記事の中で言及されたものの、紙面の都合などで完全には説明しきれなかったトピックについては、添付ファイルを活用してください。たとえば、文中で紹介されたコードの一部には、変更の結果を出力していない例もあります。そうした変更がメモリにどのような影響を与えるのかを理解することはとても重要です。どうぞ、添付ファイルを活用しながら、実際に試してみてください。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15462
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索