
Optimización móvil continua (Parte 8): Mejorando el programa y corrigiendo los errores encontrados

Introducción
A petición de los usuarios y lectores del presente ciclo de artículos, el programa ha sido modificado, y ahora podemos decir que el este artículo contiene la nueva versión del autooptimizador. Asimismo, hemos introducido en el autooptimizador tanto las mejoras solicitadas, como algunas nuevas cuya idea surgió durante la corrección del programa. Las optimizaciones ahora se realizan muchas veces más rápido que en la versión anterior, lo cual hemos conseguido trabajando sin mutex y evitando algunas otras acciones que ralentizaron el proceso de generación de informes. Ahora, la optimización se puede usar para un conjunto de activos. Además, hemos resuelto el problema de la memoria ocupada en el momento de la optimización.
Los artículos anteriores pueden leerse clicando en los enlaces mostrados abajo:
- Optimización móvil continua (Parte 1): Mecanismo de trabajo con los informes de optimización
- Optimización móvil continua (Parte 2): Mecanismo de creación de informes de optimización para cualquier robot
- Optimización móvil continua (Parte 3): Método de adaptación del robot al optimizador automático
- Optimización móvil continua (Parte 4): Programa de control de la optimización (optimizador automático)
- Optimización móvil continua (Parte 5): Panorámica del proyecto del optimizador automático, creación de la interfaz gráfica
- Optimización móvil continua (Parte 6): La lógica del optimizador automático y su estructura
- Optimización móvil continua (Parte 7): Encajando la parte lógica del optimizador automático con la parte gráfica y el control de la misma desde el programa
Añadiendo el rellenado automático de fechas
En la anterior versión del programa solo se podían introducir las fechas por fases para las optimizaciones históricas y futuras, lo cual resultaba inconveniente, y ante solicitudes repetidas, implementamos la funcionalidad para la automatización de la introducción de los intervalos de tiempo necesarios. Podemos describir los detalles de esta idea de la forma siguiente. Necesitamos dividir automáticamente el intervalo temporal seleccionado en las fechas para las optimizaciones históricas y futuras. El salto de ambos tipos de optimización es fijo y se establece antes de comenzar la división en intervalos. Cada nuevo intervalo de fechas hacia el futuro debe comenzar al día siguiente, en relación con el intervalo anterior. El desplazamiento de los intervalos históricos (que se superponen) es igual al salto de las ventanas hacia el futuro. Las optimizaciones en tiempo real, a diferencia de las históricas, no se superponen, sino que forman una historia comercial continua.
Para llevar la tarea a cabo, hemos decidido mover esta funcionalidad a una ventana gráfica aparte, haciéndola lo más independiente posible y no directamente compatible con la interfaz principal. Como resultado, hemos obtenido la siguiente jerarquía de objetos.
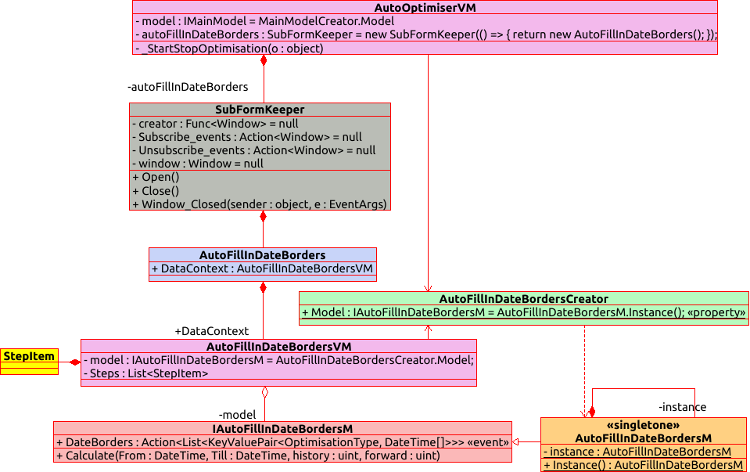
Vamos a analizar la conexión obtenida, mostrando paralelamente ejemplos de implementación. Comenzaremos por la interfaz gráfica de la extensión creada, es decir, todo lo que se encuentra en el gráfico del objeto AutoFillInDateBorders, que representa la ventana gráfica, y más abajo. En la ventana, comparamos los elementos de la interfaz gráfica, su marcado XAML y los campos de la parte ViewModel representada por la clase AutoFillInDateBordersVM.
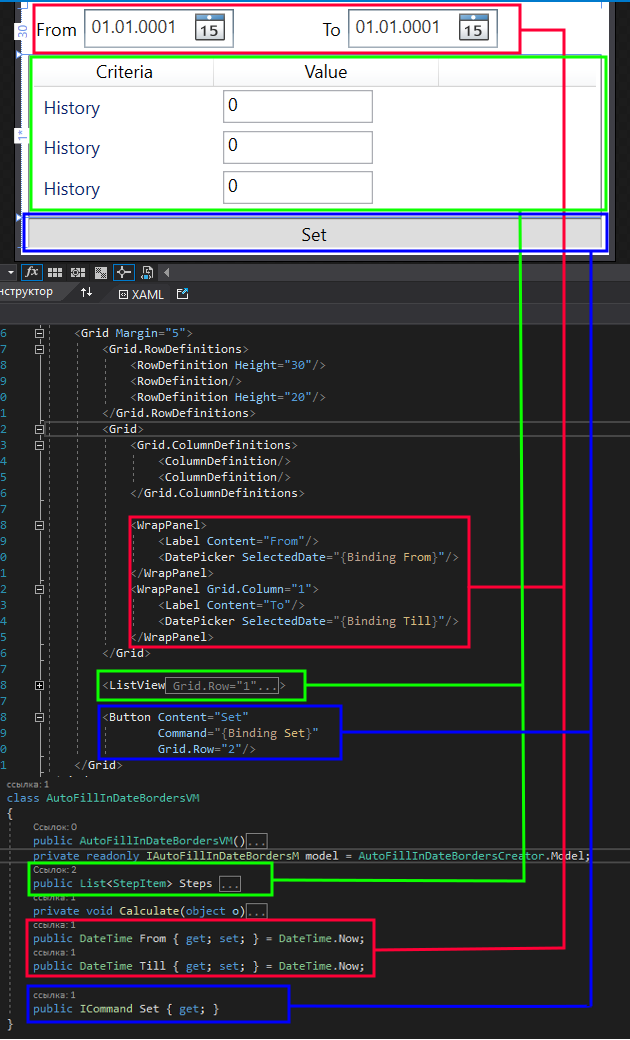
Como podemos ver, la interfaz gráfica tiene tres secciones principales. Estas incluyen dos calendarios para introducir las fechas de inicio y finalización del periodo de optimización, recuadros para especificar los límites de los intervalos futuro e histórico, y también el botón "Set", que sirve para dividir el intervalo especificado en las ventanas históricas y futuras correspondientes. El recuadro en la captura de pantalla tiene tres líneas duplicadas, no obstante, en realidad solo hay dos líneas: la primera se encarga del rango de fechas históricas y la segunda establece el rango futuro.
El valor del recuadro en cuestión es el salto del tipo de optimización correspondiente en días. Por ejemplo, si el valor del intervalo histórico es de 360 días y el valor futuro es 90, esto indicará que el intervalo temporal que hemos elegido en los calendarios se dividirá en una serie de intervalos de optimización históricos de 360 días e intervalos futuros de 90 días. El inicio de cada ventana siguiente de la pasada de optimización histórica será desplazado por el salto del intervalo futuro.
class AutoFillInDateBordersM : IAutoFillInDateBordersM { private AutoFillInDateBordersM() { } private static AutoFillInDateBordersM instance; public static AutoFillInDateBordersM Instance() { if (instance == null) instance = new AutoFillInDateBordersM(); return instance; } public event Action<List<KeyValuePair<OptimisationType, DateTime[]>>> DateBorders; public void Calculate(DateTime From, DateTime Till, uint history, uint forward) { if (From >= Till) throw new ArgumentException("Date From must be less then date Till"); List<KeyValuePair<OptimisationType, DateTime[]>> data = new List<KeyValuePair<OptimisationType, DateTime[]>>(); OptimisationType type = OptimisationType.History; DateTime _history = From; DateTime _forward = From.AddDays(history + 1); DateTime CalcEndDate() { return type == OptimisationType.History ? _history.AddDays(history) : _forward.AddDays(forward); } while (CalcEndDate() <= Till) { DateTime from = type == OptimisationType.History ? _history : _forward; data.Add(new KeyValuePair<OptimisationType, DateTime[]>(type, new DateTime[2] { from, CalcEndDate() })); if (type == OptimisationType.History) _history = _history.AddDays(forward + 1); else _forward = _forward.AddDays(forward + 1); type = type == OptimisationType.History ? OptimisationType.Forward : OptimisationType.History; } if (data.Count == 0) throw new ArgumentException("Can`t create any date borders with setted In sample (History) step"); DateBorders?.Invoke(data); } }
La clase de modelo de datos de la ventana en cuestión constituye un objeto escrito con el uso del patrón de Singletone. Esto es necesario para que parte de ViewModel de la ventana principal pueda interactuar con el modelo de datos sin tener que pasar por la ventana gráfica del ajuste analizado. De los métodos interesantes, este objeto contiene solo el método "Calculate", cuya misión consiste en calcular los propios intervalos de fechas, y el evento llamado después de la finalización del procedimiento mencionado. El evento adopta como parámetro una colección de valores emparejados, donde la clave es el tipo de intervalo analizado (optimización futura o histórica), y el valor es una matriz de dos valores del tipo DateTime. La primera fecha indica el inicio del intervalo seleccionado, mietras que la segunda indica la fecha de finalización.
El método de cálculo de los intervalos de fechas calcula estos en un ciclo, cambiando alternativamente el tipo de ventana calculada (futura o histórica). En primer lugar, establecemos el tipo de ventana histórica como punto de partida de todos los cálculos. También establecemos antes del inicio del ciclo los valores de la fecha inicial para cada uno de los tipos de ventana. En un ciclo en cada iteración, primero calculamos el borde extremo del tipo de ventana elegido utilizando la función anidada, y después comparamos este valor con la fecha del intervalo extremo. Si se supera dicha fecha, entonces esta será la condición de salida del ciclo. En un ciclo, formamos el rango de la ventana de optimización. Luego, actualizamos la fecha de inicio de la siguiente ventana y el conmutador del tipo de ventana.
Después de realizar todas las operaciones, si no han sucedido errores, se llamará a un evento con el rango de fechas pasado. De todas las demás acciones se encargará la clase. La ejecución del método anterior se inicia con la llamada de retorno a la pulsación del botón "Set".
La fábrica de modelos de datos para nuestra extensión se implementa de la manera más simple:
class AutoFillInDateBordersCreator { public static IAutoFillInDateBordersM Model => AutoFillInDateBordersM.Instance(); }
En esencia, cuando llamamos a la propiedad estática Model, estamos recurriendo constantemente a la misma instancia del objeto del modelo de datos, que luego convertimos en un tipo de interfaz. Precisamente esto vamos a usar en la parte ViewModel de nuestra ventana principal.
public AutoOptimiserVM() { ... AutoFillInDateBordersCreator.Model.DateBorders += Model_DateBorders; .... } ~AutoOptimiserVM() { ... AutoFillInDateBordersCreator.Model.DateBorders -= Model_DateBorders; .... }
Tanto en el constructor como en el destructor del objeto ViewModel de la ventana principal del programa, tenemos la oportunidad de no guardar un puntero a la instancia de esta clase, sino de llamarlo a través de la fábrica de modelos de datos estáticos. En este caso, además, merece la pena señalar que la propia parte de ViewModel de la ventana principal funciona con la clase analizada, sin sospechar siquiera que está trabajando con ella. Después de todo, en ninguna parte, salvo en el constructor y destructor de esta clase, se mencionan referencias a este objeto. La llamada de retorno que se suscribe al evento mencionado borra en primer lugar todos los intervalos de fechas ingresados anteriormente, y después añade uno a uno en un ciclo los nuevos intervalos de fechas obtenidos a través del evento. En sí, el método que añade los intervalos de fechas a la colección, también se implementa en el lado de ViewModel de la interfaz gráfica principal, y tiene el aspecto que sigue:
void _AddDateBorder(DateTime From, DateTime Till, OptimisationType DateBorderType) { try { DateBorders border = new DateBorders(From, Till); if (!DateBorders.Where(x => x.BorderType == DateBorderType).Any(y => y.DateBorders == border)) { DateBorders.Add(new DateBordersItem(border, _DeleteDateBorder, DateBorderType)); } } catch (Exception e) { System.Windows.MessageBox.Show(e.Message); } }
La creación del objeto DateBorder está envuelta en una construcción 'try - catch'. Esto se implementa así porque podría darse una excepción en el constructor del objeto, y debe gestionarse de alguna forma. También hemos añadido el método ClearDateBorders, implementado así:
ClearDateBorders = new RelayCommand((object o) => { DateBorders.Clear(); });
Lo necesitamos para eliminar rápidamente todos los intervalos de fechas introducidos. En la versión anterior, teníamos que eliminar cada fecha por separado, lo cual resultaba inconveniente para una gran cantidad de fechas. En la misma línea con los controles de rango de las fechas existentes anteriormente, hemos añadido los botones de la ventana de la interfaz gráfica principal que llaman a las novedades mecionadas.
![]()
Al clicar en el botón Autoset, se activa una llamada de retorno que llama al método Open en una instancia de la clase SubFormKeeper. Esta clase ha sido implementada como un contenedor que encapsula el proceso de creación de las ventanas anidadas en nuestra aplicación. Esto resulta necesario para aligerar de propiedades y campos sobrantes el ViewModel de la ventana principal, y también para evitarnos la tentación innecesaria de acceder directamente a la ventana auxiliar creada, ya que no tenemos que interactuar directamente con ella.
class SubFormKeeper { public SubFormKeeper(Func<Window> createWindow, Action<Window> subscribe_events = null, Action<Window> unSubscribe_events = null); public void Open(); public void Close(); }
Si analizamos la firma de esta clase, veremos que ofrece exactamente el mismo conjunto de posibilidades enumeradas a partir de los métodos públicos. En el futuro, todas las ventanas auxiliares del optimizador automático serán incluidas en esta clase en particular.
Novedades y corrección de errores en la biblioteca para trabajar con los resultados de optimización
Esta parte del artículo describe los cambios en la biblioteca para trabajar con informes de optimización "ReportManager.dll". Aparte de la introducción de un coeficiente de usuario, la nueva función posibilita una descarga más rápida de los informes de optimización desde el terminal. Asimismo, hemos encontrado y corregido un error en la clasificación de datos que no habíamos detectado anteriormente.
- Introduciendo un coeficiente de optimización personalizado
Una de las sugerencias de mejora en los comentarios de los artículos anteriores se refería a la capacidad de usar un coeficiente personalizado para filtrar los resultados de optimización. Para implementar esta opción, hemos tenido que introducir algunas modificaciones en los objetos existentes. No obstante, para ofrecer soporte a informes antiguos, la clase encargada de leer los datos de las optimizaciones puede operar tanto con los informes que tienen un coeficiente personalizado como con los que se han generado en versiones anteriores del programa. Por consiguiente, el formato del informe se ha mantenido sin cambios. Asimismo, dispone de un parámetro adicional: un campo para especificar el coeficiente personalizado.
En primer lugar, hemos añadido a la enumeración "SortBy" el nuevo parámetro "Custom", y también hemos agregado el campo correspondiente a la estructura "Coefficients". Tras hacer esto, hemos añadido el coeficiente personalizado a los objetos encargados de guardar los datos, pero no lo hemos agregado a los objetos que se ocupan de descargarlos y leerlos. De la escritura de datos se encargan dos métodos y una clase con métodos estáticos que se usa desde MQL5 para guardar informes.
public static void AppendMainCoef(double customCoef, double payoff, double profitFactor, double averageProfitFactor, double recoveryFactor, double averageRecoveryFactor, int totalTrades, double pl, double dd, double altmanZScore) { ReportItem.OptimisationCoefficients.Custom = customCoef; ... }
Lo primero que hemos hecho ha sido añadir al método AppendMainCoef un nuevo parámetro para identificar el coeficiente personalizado. Luego, al igual que se hizo con otros coeficientes pasados, lo hemos añadido a la estructura ReportWriter.ReportItem. Ahora, cuando intentemos compilar el proyecto antiguo con la nueva biblioteca "ReportManager.dll", obtendremos una excepción, porque hemos cambiado la firma del método AppendMainCoef. No obstante, tras editar ligeramente el objeto que está descargando los datos, hemos solucionado este error. Pasaremos al código MQL5 un poco más tarde.
Debemos decir de inmediato que, para realizar correctamente la compilación con la versión actual de la biblioteca dll, debemos reemplazar la carpeta "History Manager" situada en el directorio Include por la nueva del archivo del artículo actual: esto bastará para compilar los robots con las formas antiguas y nuevas de descargar datos.
Lo siguiente que hemos cambiado es la firma del método Write, que ahora no genera excepciones, pero retorna una línea con un mensaje de error. Esto resultaba necesario para poder deshacerse del mutex con nombre, que ralentizaba significativamente el proceso de descarga de datos, pero era imprescindible para generar informes en la versión anterior de la clase de descarga. No obstante, hemos dejado el método que escribe los datos usando un mutex para mantener la compatibilidad con el formato de exportación de datos implementado previamente.
Para que aparezca un nuevo registro en el archivo con el informe, necesitaremos crear una nueva etiqueta <Item/> con el atributo Name igual al valor "Custom".
WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.Custom.ToString(), new Dictionary<string, string> { { "Name", "Custom" } });
También hemos modificado el método OptimizationResultsExtentions.ReportWriter, donde hemos agregado una línea de código que, al igual que en el método ReportWriter.Write, añade una etiqueta <Item/> con un parámetro de coeficiente personalizado.
Ahora, merece la pena plantearse si debemos añadir coeficientes personalizados a la descarga y el código del lado del robot escrito en MQL5. En primer lugar, vamos a analizar la anterior versión de la descarga de datos; en esta, la parte del código encargada de operar con la clase ReportWriter se encuentra en la clase CXmlHistoryWriter, en el archivo XmlHistoryWriter.mqh. Para ofrecer soporte a coeficientes personalizados, hemos creado un enlace de función con la siguiente firma:
typedef double(*TCustomFilter)();
Y también un campo private en la clase mencionada, que debería guardar esta función.
class CXmlHistoryWriter { private: const string _path_to_file,_mutex_name; CReportCreator _report_manager; TCustomFilter custom_filter; void append_bot_params(const BotParams ¶ms[]);// void append_main_coef(PL_detales &pl_detales, TotalResult &totalResult);// //double get_average_coef(CoefChartType type); void insert_day(PLDrawdown &day,ENUM_DAY_OF_WEEK day);// void append_days_pl();// public: CXmlHistoryWriter(string file_name,string mutex_name, CCCM *_comission_manager, TCustomFilter filter);// CXmlHistoryWriter(string mutex_name,CCCM *_comission_manager, TCustomFilter filter); ~CXmlHistoryWriter(void) {_report_manager.Clear();} // void Write(const BotParams ¶ms[],datetime start_test,datetime end_test);// };
El valor de este campo private se rellena desde los constructores de la clase. Además, en el método append_main_coef, cuando llamemos al método estático "ReportWriter::AppendMainCoef" desde la biblioteca dll, llamaremos a la función transmitida por su puntero, y así recibiremos el valor del coeficiente personalizado.
La clase no se utiliza directamente, ya que tenemos un contenedor descrito anteriormente, en el tercer artículo: la clase CAutoUploader.
class CAutoUploader { private: datetime From,Till; // Testing start and end dates CCCM *comission_manager; // Commission manager BotParams params[]; // List of parameters string mutexName; // Mutex name TCustomFilter custom_filter; public: CAutoUploader(CCCM *comission_manager, string mutexName, BotParams ¶ms[], TCustomFilter filter); CAutoUploader(CCCM *comission_manager, string mutexName, BotParams ¶ms[]); virtual ~CAutoUploader(void); virtual void OnTick(); // Calculating testing start and end dates };
double EmptyCustomCoefCallback() {return 0;} //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CAutoUploader::CAutoUploader(CCCM *_comission_manager,string _mutexName,BotParams &_params[], TCustomFilter filter) : comission_manager(_comission_manager), mutexName(_mutexName), From(0), Till(0), custom_filter(filter) { CopyBotParams(params,_params); } //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CAutoUploader::CAutoUploader(CCCM *_comission_manager,string _mutexName,BotParams &_params[]) : comission_manager(_comission_manager), mutexName(_mutexName), From(0), Till(0), custom_filter(EmptyCustomCoefCallback) { CopyBotParams(params,_params); }
Para guardar la anterior versión del constructor, hemos creado la función "EmptyCustomCoefCallback". Esta función retorna cero como coeficiente personalizado. Si llamamos al constructor anterior de esta clase, transmitiremos a la clase CXmlHistoryWriter exactamente esta función. Si tomamos el ejemplo usado en el artículo №4, podremos añadir un coeficiente personalizado al robot de la forma siguiente:
//+------------------------------------------------------------------+ //| SimpleMA.mq5 | //| Copyright 2019, MetaQuotes Software Corp. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2019, MetaQuotes Software Corp." #property link "https://www.mql5.com" #property version "1.00" #include <Trade/Trade.mqh> #include <History manager/AutoLoader.mqh> // Include CAutoUploader #define TESTER_ONLY input int ma_fast = 10; // MA fast input int ma_slow = 50; // MA slow input int _sl_ = 20; // SL input int _tp_ = 60; // TP input double _lot_ = 1; // Lot size // Comission and price shift (Article 2) input double _comission_ = 0; // Comission input int _shift_ = 0; // Shift int ma_fast_handle,ma_slow_handle; const double tick_size = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_SIZE); CTrade trade; CAutoUploader * auto_optimiser;// Pointer to CAutoUploader class (Article 3) CCCM _comission_manager_;// Comission manager (Article 2) double CulculateMyCustomCoef() { return 0; } //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ... // Add Instance CAutoUploader class (Article3) auto_optimiser = new CAutoUploader(&_comission_manager_,"SimpleMAMutex",params,CulculateMyCustomCoef); //--- return(INIT_SUCCEEDED); } double OnTester() { return(CulculateMyCustomCoef()); } //+------------------------------------------------------------------+
Para evitar el código sobrante distraiga a la vista, hemos eliminado toda la implementación, salvo la parte asociada con la introducción de un coeficiente personalizado, pero el lector podrá estudiarla en el archivo adjunto. Lo primero que debemos hacer es crear una función que calculará el coeficiente personalizado. En el ejemplo, este retorna cero y no tiene implementación como tal, pero es en ella donde debemos describir el cálculo del coeficiente personalizado. A continuación, en la llamada de retorno OnTester, ya no realizaremos cálculos, sino que llamaremos a la función que hemos descrito. En el momento en que se cree la clase CAutoUploader, todo lo que necesitaremos es llamar al nuevo constructor sobrecargado con un factor personalizado. Esto completará la introducción del coeficiente personalizado en la anterior versión de la carga de datos.
- Acelerando la carga de datos de las pasadas de optimización utilizada en el nuevo formato de carga de datos
La renuncia al mutex sin duda ha aumentado la velocidad de descarga de los datos, pero no tan significativamente como necesitábamos. En la anterior versión de la clase de descarga, para añadir datos al archivo, teníamos que realizar una serie de operaciones con cada nuevo registro:
- Leer un archivo.
- Guardar los datos leídos en la RAM de la computadora.
- Añadir una nueva pasada de optimización a los datos leídos en la memoria.
- Eliminar el archivo antiguo.
- Crear un archivo nuevo y limpio en lugar del anterior.
- Guardar la matriz de datos completa en el archivo creado.
Así es como funciona la clase XmlDocument que utilzamos desde la biblioteca C# estándar, lo cual requiere mucho tiempo. Además, el tiempo dedicado a estas operaciones aumenta a medida que crece el tamaño del archivo. Hemos tenido que aceptar esta función en la versión anterior, porque no podíamos acumular todos los datos en un solo lugar. En cambio, almacenamos los datos después de completar cada optimización. En la implementación actual, los datos se acumulan usando frames y, por consiguiente, podemos convertir todos los datos a la vez al formato requerido. Esto se implementa usando el método "OptimisationResultsExtentions.ReportWriter", escrito anteriormente. Se trata de un método de extensión para la matriz de pasadas de optimización. A diferencia de ReportWriter.Write, este método no añade datos a un archivo, sino que crea un archivo y escribe todas las pasadas de optimización línea por línea. Por consiguiente, unaa matriz de datos que haya necesitado varios minutos al ser escrita por ReportWriter.Write, ahora se podrá escribir en un par de segundos.
Para permitir el uso del método OptimisationResultsExtentions.ReportWriter de MQL5, hemos creado un contenedor en la clase ReportWriter.
public class ReportWriter { private static ReportItem ReportItem; private static List<OptimisationResult> ReportData = new List<OptimisationResult>(); public static void AppendToReportData(string symbol, int tf, ulong StartDT, ulong FinishDT) { ReportItem.Symbol = symbol; ReportItem.TF = tf; ReportItem.DateBorders = new DateBorders(StartDT.UnixDTToDT(), FinishDT.UnixDTToDT()); ReportData.Add(ReportItem); ClearReportItem(); } public static void ClearReportItem() { ReportItem = new ReportItem(); } public static void ClearReportData() { ReportData.Clear(); } public static string WriteReportData(string pathToBot, string currency, double balance, int laverage, string pathToFile) { try { ReportData.ReportWriter(pathToBot, currency, balance, laverage, pathToFile); ClearReportData(); } catch (Exception e) { return e.Message; } ClearReportData(); return ""; } }
En la clase ReportWriter, hemos creado el campo ReportData, donde se guardará una colección de ReportItems, es decir, será la colección de pasadas de optimización del robot. La idea consiste en escribir todos los datos necesarios en la estructura ReportItem usando los métodos descritos en el primer artículo de MQL5. Luego, llamando al método AppendToReportData, los añadiremos a la colección de pasadas de optimización. De esta manera, formamos la recopilación de datos necesaria en el lado de C#. Después de añadir todas las pasadas de optimización a la colección, llamamos al método WriteReportData, que, usando el método OptimizationResultsExtentions.ReportWriter, generará rápidamente el informe de optimización.
- Arreglando el bug
Por desgracia, en la anterior versión del programa, cometimos un error que detectamos bastante tarde. El error en cuestión se relaciona con el mecanismo de clasificación de las optimizaciones que describimos en el primer artículo de esta serie. Como la clasificación de los datos resulta posible según una serie de criterios, es necesario determinar cuál de estos criterios maximizaremos y cuál minimizaremos. Por ejemplo, sería una tontería maximizar el número de transacciones con pérdidas.
Para evitar confusiones, debemos decir que en este método de clasificación de optimizaciones, las direcciones de las clasificaciones no tienen valores muy familiares para nosotros:
- Descendente: debe entenderse como "los mejores parámetros arriba, los peores, abajo"
- Ascendente: debe entenderse como "los peores parámetros arriba, y los mejores, abajo".
Para que el método encargado de ordenar los datos pueda determinar qué criterios se deben maximizar y cuáles se deben minimizar, hemos creado un método que retorna los indicadores correspondientes. Antes, este método se implementaba de la siguiente manera:
private static SortMethod GetSortMethod(SortBy sortBy) { switch (sortBy) { case SortBy.Payoff: return SortMethod.Increasing; case SortBy.ProfitFactor: return SortMethod.Increasing; case SortBy.AverageProfitFactor: return SortMethod.Increasing; case SortBy.RecoveryFactor: return SortMethod.Increasing; case SortBy.AverageRecoveryFactor: return SortMethod.Increasing; case SortBy.PL: return SortMethod.Increasing; case SortBy.DD: return SortMethod.Decreasing; case SortBy.AltmanZScore: return SortMethod.Decreasing; case SortBy.TotalTrades: return SortMethod.Increasing; case SortBy.Q_90: return SortMethod.Decreasing; case SortBy.Q_95: return SortMethod.Decreasing; case SortBy.Q_99: return SortMethod.Decreasing; case SortBy.Mx: return SortMethod.Increasing; case SortBy.Std: return SortMethod.Decreasing; case SortBy.MaxProfit: return SortMethod.Increasing; case SortBy.MaxDD: return SortMethod.Decreasing; case SortBy.MaxProfitTotalTrades: return SortMethod.Increasing; case SortBy.MaxDDTotalTrades: return SortMethod.Decreasing; case SortBy.MaxProfitConsecutivesTrades: return SortMethod.Increasing; case SortBy.MaxDDConsecutivesTrades: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Mn: return SortMethod.Increasing; case SortBy.AverageDailyDD_Mn: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Mn: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Mn: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Tu: return SortMethod.Increasing; case SortBy.AverageDailyDD_Tu: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Tu: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Tu: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_We: return SortMethod.Increasing; case SortBy.AverageDailyDD_We: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_We: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_We: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Th: return SortMethod.Increasing; case SortBy.AverageDailyDD_Th: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Th: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Th: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Fr: return SortMethod.Increasing; case SortBy.AverageDailyDD_Fr: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Fr: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Fr: return SortMethod.Decreasing; default: throw new ArgumentException($"Unaxpected Sortby variable {sortBy}"); } }
La implementación actual es la siguiente:
private static OrderBy GetSortingDirection(SortBy sortBy) { switch (sortBy) { case SortBy.Custom: return OrderBy.Ascending; case SortBy.Payoff: return OrderBy.Ascending; case SortBy.ProfitFactor: return OrderBy.Ascending; case SortBy.AverageProfitFactor: return OrderBy.Ascending; case SortBy.RecoveryFactor: return OrderBy.Ascending; case SortBy.AverageRecoveryFactor: return Or-derBy.Ascending; case SortBy.PL: return OrderBy.Ascending; case SortBy.DD: return OrderBy.Ascending; case SortBy.AltmanZScore: return OrderBy.Descending; case SortBy.TotalTrades: return OrderBy.Ascending; case SortBy.Q_90: return OrderBy.Ascending; case SortBy.Q_95: return OrderBy.Ascending; case SortBy.Q_99: return OrderBy.Ascending; case SortBy.Mx: return OrderBy.Ascending; case SortBy.Std: return OrderBy.Descending; case SortBy.MaxProfit: return OrderBy.Ascending; case SortBy.MaxDD: return OrderBy.Ascending; case SortBy.MaxProfitTotalTrades: return OrderBy.Ascending; case SortBy.MaxDDTotalTrades: return OrderBy.Descending; case SortBy.MaxProfitConsecutivesTrades: return OrderBy.Ascending; case SortBy.MaxDDConsecutivesTrades: return OrderBy.Descending; case SortBy.AverageDailyProfit_Mn: return OrderBy.Ascending; case SortBy.AverageDailyDD_Mn: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Mn: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Mn: return OrderBy.Descending; case SortBy.AverageDailyProfit_Tu: return OrderBy.Ascending; case SortBy.AverageDailyDD_Tu: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Tu: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Tu: return OrderBy.Descending; case SortBy.AverageDailyProfit_We: return OrderBy.Ascending; case SortBy.AverageDailyDD_We: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_We: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_We: return OrderBy.Descending; case SortBy.AverageDailyProfit_Th: return OrderBy.Ascending; case SortBy.AverageDailyDD_Th: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Th: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Th: return OrderBy.Descending; case SortBy.AverageDailyProfit_Fr: return OrderBy.Ascending; case SortBy.AverageDailyDD_Fr: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Fr: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Fr: return OrderBy.Descending; default: throw new ArgumentException($"Unaxpected Sortby variable {sortBy}"); } }
Como podemos ver en el código, la dirección de clasificación de los coeficientes seleccionados ha variado. En la implementación anterior, marcábamos como ordenados en orden descendente. No obstante, no tomábamos en cuenta que estos datos tienen un valor negativo y que deben ser ordenados en orden ascendente, no descendente. Para comprender la lógica que hemos empleado al establecer esta dirección, deberemos consultar el siguiente fragmento de código que implementa la clasificación para cada uno de los valores transmitidos:
// Si el mínimo es inferior a cero, desplazamos todos los datos a la magnitud del mínimo negativoif (mm.Min < 0) { value += Math.Abs(mm.Min); mm.Max += Math.Abs(mm.Min); } // If the maximum is greater than zero, calculate if (mm.Max > 0) { // Calculate the coefficient according to the sorting method if (GetSortingDirection(item.Key) == OrderBy.Descending) { // Calculate the coefficient to sort in descending order data.SortBy += (1 - value / mm.Max) * coef; } else { // Calculate the coefficient to sort in ascending order data.SortBy += value / mm.Max * coef; } }
El valor value es el valor numérico de un coeficiente determinado. Antes de clasificar los datos, deberemos comprobar si el valor mínimo de la matriz del coeficiente seleccionado para la clasificación es negativo. Si lo es, convertiremos estos valores en un plano positivo, desplazándolos hacia arriba en el valor del coeficiente mínimo. Por consiguiente, tendremos una matriz de valores que oscilará en el rango [0 ; (Max + |Min|)]. Al calcular el coeficiente resultante que servirá para realizar la clasificación final, convertiremos la matriz de datos al rango [0 ; 1], dividiendo cada i-ésimo valor por el valor máximo de la matriz de datos de clasificación. Si el método de clasificación es descendente, restaremos el valor resultante de uno, invirtiendo así la matriz de pesos resultantes. Por eso mismo, la anterior versión de clasificación de datos es incorrecta: debido a la lógica de clasificación multifactor implementada, simplemente hemos invertido la matriz de pesos, que no era necesaria para los coeficientes marcados en el código anterior. En el primer artículo, describimos con más detalle el método de clasificación. Igualmente por conveniencia, el nombre del método y el tipo del valor retornado han sido cambiados a otros más adecuados, pero esto no influye de ninguna manera en la lógica de la aplicación.
El segundo error se encuentra en la parte del código que ordenaba la matriz de resultados de optimización en el caso de que solo se eligiera un criterio de clasificación. La anterior implementación era la siguiente:
if (order == OrderBy.Ascending) return results.OrderBy(x => x.GetResult(sortingFlags.ElementAt(0))); else return results.OrderByDescending(x => x.GetResult(sortingFlags.ElementAt(0)));
La actual tiene el aspecto que vemos:
if (order == GetSortingDirection(sortingFlags.ElementAt(0))) return results.OrderBy(x => x.GetResult(sortingFlags.ElementAt(0))); else return results.OrderByDescending(x => x.GetResult(sortingFlags.ElementAt(0)));
La versión anterior de las clases no consideraba las instrucciones establecidas por el método GetSortingDirection. La nueva realiza la clasificación según este criterio. Y, por ejemplo, si seleccionamos la clasificación descendente (los mejores resultados en la parte superior), entonces para SortBy.PL, se realizará una clasificación descendente, según lo solicitado, y el valor más alto estará en la parte superior; sin embargo, para el parámetro SortBy.MaxDDTotalTrades (número total de transacciones con pérdidas), arriba se encontrará el valor más pequeño, y la matriz se ordenará en consecuencia, no en orden descendente, sino ascendente. Esto es necesario para mantener la estructura lógica. Por ejemplo, si seleccionamos solo SortBy.MaxDDTotalTrades como criterio, entonces, con el método de clasificación anterior, no habríamos obtenido los parámetros óptimos (que esperábamos), sino, por el contrario, los peores encontrados.
Automatización de la descarga de parámetros del robot y nuevas reglas para la escritura de asesores
La nueva lógica para descargar los parámetros se encuentra en el archivo "AutoUploader2.mqh". Después de describir este mecanismo, ofreceremos un ejemplo sobre su implementación basado en el asesor experto del cuarto artículo que ya conocemos.
class CAutoUploader2 { private: CAutoUploader2() {} static CCCM comission_manager; static datetime From,Till; static TCustomFilter on_tester; static TCallback on_tick, on_tester_deinit; static TOnTesterInit on_tester_init; static string frame_name; static long frame_id; static string file_name; static bool FillInData(Data &data); static void UploadData(const Data &data, double custom_coef, const BotParams ¶ms[]); public: static void OnTick(); static double OnTester(); static int OnTesterInit(); static void OnTesterDeinit(); static void SetUploadingFileName(string name); static void SetCallback(TCallback callback, ENUM_CALLBACK_TYPE type); static void SetCustomCoefCallback(TCustomFilter custom_filter_callback); static void SetOnTesterInit(TOnTesterInit on_tester_init_callback); static void AddComission(string symbol,double comission,double shift); static double GetComission(string symbol,double price,double volume); static void RemoveComission(string symbol); }; datetime CAutoUploader2::From = 0; datetime CAutoUploader2::Till = 0; TCustomFilter CAutoUploader2:: EmptyCustomCoefCallback; TCallback CAutoUploader2:: EmptyCallback; TOnTesterInit CAutoUploader2:: EmptyOnTesterInit; TCallback CAutoUploader2:: EmptyCallback; CCCM CAutoUploader2::comission_manager; string CAutoUploader2::frame_name = "AutoOptomiserFrame"; long CAutoUploader2::frame_id = 1; string CAutoUploader2::file_name = MQLInfoString(MQL_PROGRAM_NAME)+"_Report.xml";
La nueva clase para descargar informes solo contiene métodos estáticos. Esto es necesario para que no tengamos que instanciarlo, y así facilitar la escritura del asesor experto eliminando el código innecesario de su implementación. Esta clase contiene varios campos estáticos, incluidos los límites de fecha (por analogía con la clase usada anteriormente; podrá ver los detalles en el artículo #3), los enlaces de función para las llamadas de retorno para el final de la simulación, y los frames de optimización, así como una llamada de retorno para la llegada de un nuevo tick, la clase del gestor de comisiones (consulte el artículo 2 para obtener más detalles), el nombre e la identificación de los frames y, finalmente, el nombre del archivo con la exportación de los resultados de optimización.
Al escribir un asesor experto para incluir el optimizador automático, añadimos un enlace al archivo en el asesor experto, donde ya se han definido una serie de llamadas de retorno. Si el asesor utiliza cualquiera de las llamadas de retorno definidas en este archivo, la solución más simple sería crear una función con la firma de la llamada de retorno utilizada y su implementación; luego añadiríamos esta a los enlaces a las funciones para las llamadas de retorno a través de funciones estáticas especiales.
#ifndef CUSTOM_ON_TESTER double OnTester() { return CAutoUploader2::OnTester(); } #endif #ifndef CUSTOM_ON_TESTER_INIT int OnTesterInit() { return CAutoUploader2::OnTesterInit(); } #endif #ifndef CUSTOM_ON_TESTER_DEINIT void OnTesterDeinit() { CAutoUploader2::OnTesterDeinit(); } #endif #ifndef CUSTOM_ON_TICK void OnTick() { CAutoUploader2::OnTick(); } #endif
Cada una de las llamadas de retorno específicas está envuelta en una condición de preprocesador, lo cual permite evitar su definición en este archivo definiendo la condición de preprocesador conveniente. Ofreceremos los detalles de la implementación en un ejemplo adicional.
Si decidimos describir estas llamadas de retorno por nuestra cuenta, no debemos olvidar llamar a los métodos estáticos de la clase CAutoUploader2 (como se hace en este fragmento de código) al inicio de la llamada de retorno definida. Esto es necesario para que el mecanismo de generación de informes funcione correctamente.
Para activar una llamada de retorno personalizada y descargar los datos (si no hemos implementado nuestra propia llamada de retorno), transmitiremos el puntero a la función con la descripción de la implementación al método estático "CAutoUploader2::SetCustomCoefCallback". Para gestionar las comisiones, usaremos uno de los métodos siguientes.
static void AddComission(string symbol,double comission,double shift); static double GetComission(string symbol,double price,double volume); static void RemoveComission(string symbol);
Ahora que hemos terminado de analizar la funcionalidad, vamos a ver cómo opera todo esto.
int CAutoUploader2::OnTesterInit(void) { return on_tester_init(); }
En primer lugar, el asesor experto en la llamada de retorno OnTesterInit llama al método CAutoUploader2::OnTesterInit (si hemos iniciado la optimización), donde llama al puntero de función transmitido o a una función vacía, si ha sido sustituida por defecto.
void CAutoUploader2::OnTick(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)==1 || MQLInfoInteger(MQL_TESTER)==1) { if(From == 0) From = iTime(_Symbol,PERIOD_M1,0); Till=iTime(_Symbol,PERIOD_M1,0); } on_tick(); }
Luego, en cada tick, guardamos en las variables correspondientes la hora real del inicio de la optimización. Luego, el asesor llama al método on_tick, para que sea enviado como una llamada de retorno sobre la llegada de un nuevo tick, o una llamada de retorno vacía predeterminada. El guardado de la hora de optimización se realiza solo si el asesor se está ejecutando en el simulador.
double CAutoUploader2::OnTester(void) { double ret = on_tester(); Data data[1]; if(!FillInData(data[0])) return ret; if(MQLInfoInteger(MQL_OPTIMIZATION)==1) { if(!FrameAdd(frame_name, frame_id, ret, data)) Print(GetLastError()); } else if(MQLInfoInteger(MQL_TESTER)==1) { BotParams params[]; UploadData(data[0], ret, params, false); } return ret; }
Cuando el funcionamiento del simulador finaliza, llamamos al método estático CAutoUploader2::OnTester en la llamada de retorno de OnTester, donde se guardan los frames (si es una optimización), o estos son escritos en un archivo (si es una simulación). Si se trata de una simulación, el proceso finalizará en el salto actual, y el terminal se cerrará mediante el comando transmitido en el archivo de configuración. No obstante, si se trata de un proceso de optimización, tendrá la siguiente etapa final:
input bool close_terminal_after_finishing_optimisation = false; // MetaTrader Auto Optimiser param (must be false if you run it from terminal) void CAutoUploader2::OnTesterDeinit(void) { ResetLastError(); if(FrameFilter(frame_name,frame_id)) { ulong pass; string name; long id; double coef_value; Data data[]; while(FrameNext(pass,name,id,coef_value,data)) { string parameters_list[]; uint params_count; BotParams params[]; if(FrameInputs(pass,parameters_list,params_count)) { for(uint i=0; i<params_count; i++) { string arr[]; StringSplit(parameters_list[i],'=',arr); BotParams item; item.name = arr[0]; item.value = arr[1]; ADD_TO_ARR(params,item); } } else Print("Can`t get params"); UploadData(data[0], coef_value, params, true); } CheckRetMessage(ReportWriter::WriteReportData(get_path_to_expert(), CharArrayToString(data[0].currency), data[0].balance, data[0].laverage, TerminalInfoString(TERMINAL_COMMONDATA_PATH)+"\\"+file_name)); } else { Print("Can`t select apropriate frames. Error code = " + IntegerToString(GetLastError())); ResetLastError(); } on_tester_deinit(); if(close_terminal_after_finishing_optimisation) { if(!TerminalClose(0)) { Print("==================================="); Print("Can`t close terminal from OnTesterDeinit error number: " + IntegerToString(GetLastError()) + " Close it by hands"); Print("==================================="); } } ExpertRemove(); }
La etapa final de la optimización es la llamada del método estático CAutoUploader2::OnTesterDeinit(). En este método, podemos leer todos los frames guardados y, usando estos como base, formar el archivo que nos interese con el informe de optimización descargado. Lo primero que debemos hacer es resetear el error anterior e intentar filtrar los frames según el nombre y el identificador. A continuación, leemos cada frame en un ciclo y obtenemos los datos guardados en él, que escribiremos en el archivo.
Después de leer los datos, leemos los parámetros de entrada del robot para la pasada de optimización dada y añadimos la información obtenida a la colección de la clase estática en el lado de C#. Tras salir del ciclo, registramos la colección generada en un archivo, llamando para ello al método ReportWriter::WriteReportData. Luego, llamamos a la llamada de retorno personalizada transmitida, o al enlace vacío predeterminado. No obstante, hay un problema con este enfoque: para que el autooptimizador funcione, este debe poder reiniciar el terminal, y para ello, el terminal primero debe estar apagado.
Antes, este problema se resolvía estableciendo el indicador correspondiente del archivo de configuración igual a true, sin embargo, al trabajar con frames, esto no se puede hacer, porque su procesamiento final comienza después de detenerse la optimización, y si establecemos el indicador necesario del archivo de configuración en true, no podremos procesarlos, ya que la terminal se apagará antes de que se complete el método OnTerderDeinit. Para solucionar el problema, hemos añadido una variable de entrada que, junto con el archivo incluido, se añadirá al asesor experto. Esta variable se modifica desde el autooptimizador, y no debe cambiarse manualmente o en el código. Si es igual a true, llamaremos al método de cierre del terminal desde MQL5; de lo contrario, el terminal no se cerrará. Al finalizar todas las situaciones descritas, el asesor que procesa los frames es eliminado del gráfico.
El método UploadData actúa simultáneamente como método que añade datos a una colección y como método que carga un salto de prueba específico en un archivo, siempre que sea una simulación, no una optimización.
void CAutoUploader2::UploadData(const Data &data, double custom_coef, const BotParams ¶ms[], bool is_appent_to_collection) { int total = ArraySize(params); for(int i=0; i<total; i++) ReportWriter::AppendBotParam(params[i].name,params[i].value); ReportWriter::AppendMainCoef(custom_coef,data.payoff,data.profitFactor,data.averageProfitFactor, data.recoveryFactor,data.averageRecoveryFactor,data.totalTrades, data.pl,data.dd,data.altmanZScore); ReportWriter::AppendVaR(data.var_90,data.var_95,data.var_99,data.mx,data.std); ReportWriter::AppendMaxPLDD(data.max_profit,data.max_dd, data.totalProfitTrades,data.totalLooseTrades, data.consecutiveWins,data.consequtiveLoose); ReportWriter::AppendDay(MONDAY,data.averagePl_mn,data.averageDd_mn, data.numberProfitTrades_mn,data.numberLooseTrades_mn); ReportWriter::AppendDay(TUESDAY,data.averagePl_tu,data.averageDd_tu, data.numberProfitTrades_tu,data.numberLooseTrades_tu); ReportWriter::AppendDay(WEDNESDAY,data.averagePl_we,data.averageDd_we, data.numberProfitTrades_we,data.numberLooseTrades_we); ReportWriter::AppendDay(THURSDAY,data.averagePl_th,data.averageDd_th, data.numberProfitTrades_th,data.numberLooseTrades_th); ReportWriter::AppendDay(FRIDAY,data.averagePl_fr,data.averageDd_fr, data.numberProfitTrades_fr,data.numberLooseTrades_fr); if(is_appent_to_collection) { ReportWriter::AppendToReportData(_Symbol, data.tf, data.startDT, data.finishDT); return; } CheckRetMessage(ReportWriter::Write(get_path_to_expert(), CharArrayToString(data.currency), data.balance, data.laverage, TerminalInfoString(TERMINAL_COMMONDATA_PATH)+"\\"+file_name, _Symbol, data.tf, data.startDT, data.finishDT)); }
Si la bandera is_appent_to_collection es igual a true, la pasada simplemente se añade a la colección. Si es igual a false, descargaremos la pasada actual en un archivo. Podemos ver en el código anterior que la bandera solo es igual a true cuando leemos los frames y los añadimos a una colección para descargar informes rápidamente. Si ejecutamos el asesor experto en el modo de prueba, este método será llamado con el parámetro false, lo cual indica que el informe debe guardarse en un archivo.
Ahora, vamos a ver cómo añadir un enlace para descargar informes de optimización usando la nueva lógica, para ello, analizaremos el archivo creado previamente con el asesor experto de prueba del cuarto artículo. Si no tenemos en cuenta el enlace al archivo de inclusión, la conexión del nuevo método implicará solo 3 líneas de código, en lugar de las 16 líneas del ejemplo usado en el artículo №4. En cuanto a las llamadas de retorno usadas para descargar los datos, ahora el asesor tiene la implementación de llamada de retorno "OnTick", mientras que todas las demás llamadas de retorno ("OnTester", "OnTesterInit", "OnTesterDeinit") se implementan en el archivo de inclusión.
//+------------------------------------------------------------------+ //| SimpleMA.mq5 | //| Copyright 2019, MetaQuotes Software Corp. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2019, MetaQuotes Software Corp." #property link "https://www.mql5.com" #property version "1.00" #include <Trade/Trade.mqh> #define CUSTOM_ON_TICK // Tell to uploading system that we implement OnTick callback ourself #include <History manager/AutoUpLoader2.mqh> // Include CAutoUploader #define TESTER_ONLY input int ma_fast = 10; // MA fast input int ma_slow = 50; // MA slow input int _sl_ = 20; // SL input int _tp_ = 60; // TP input double _lot_ = 1; // Lot size // Comission and price shift (Article 2) input double _comission_ = 0; // Comission input int _shift_ = 0; // Shift int ma_fast_handle,ma_slow_handle; const double tick_size = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_SIZE); CTrade trade; //+------------------------------------------------------------------+ //| Custom coeffifient`s creator | //+------------------------------------------------------------------+ double CulculateMyCustomCoef() { return 0; } //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ... CAutoUploader2::SetCustomCoefCallback(CulculateMyCustomCoef); CAutoUploader2::AddComission(_Symbol,_comission_,_shift_); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { CAutoUploader2::OnTick(); // If CUSTOM_ON_TICK was defined ... } //+------------------------------------------------------------------+
En color rojo, marcamos la adición de una interfaz para descargar los datos del asesor experto en un archivo utilizando el nuevo tipo de descarga. Como podemos ver en el ejemplo, la llamada de retorno de OnTester permanecía implementada en el archivo que descarga los datos, y para que se calcule nuestro coeficiente personalizado, se le transmitió el método "CulculateMyCustomCoef", que debería contener lógica personalizada para implementar esta llamada de retorno. La llamada de retorno de OnTick se dejó implementada en el robot para el ejemplo. Para ello, antes del enlace al archivo donde se describe el procedimiento de carga de datos, se define la variable CUSTOM_ON_TICK. Para estudiar la implementación de este robot con más detalle, y también para compararlo con la implementación por defecto (donde la descarga para el autooptimizador no está conectada) y con la opción de implementación con el método anterior de descarga de datos, el lector podrá analizar los archivos correspondientes del archivo adjunto al artículo.
Cambiando el modo de inicio de las optimizaciones y otras mejoras
La nueva versión del programa también contiene una serie de mejoras, la principal de las cuales se analizará en el capítulo actual. Querríamos comenzar con la adición de la posibilidad de planificar las optimizaciones en una serie de activos.
- Planificación de la optimización en la lista de activos transmitida
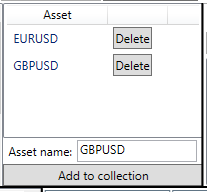
Esta mejora nos permitirá ahorrar tiempo al realizar optimizaciones en una serie de activos, porque las tareas programadas se ejecutarán día y noche hasta que finalice la lista indicada. No obstante, para crearla, hemos tenido que modificar ligeramente la forma en que se inicia el proceso de optimización descrito en los artículos anteriores. Antes, después de presionar el botón "Start/Stop", ViewModel reasignaba inmediatamente el trabajo al método del modelo de datos, que llamaba a un ciclo completo desde el inicio de la optimización hasta el almacenamiento de los resultados. Ahora, primero llamamos al método que itera la lista de parámetros transmitida, y ya luego inicia las optimizaciones y su posterior guardado en el directorio adecuado.
public async void StartOptimisation(OptimiserInputData optimiserInputData, bool isAppend, string dirPrefix, List<string> assets) { if (assets.Count == 0) { ThrowException("Fill in asset name"); OnPropertyChanged("ResumeEnablingTogle"); return; } await Task.Run(() => { try { if (optimiserInputData.OptimisationMode == ENUM_OptimisationMode.Disabled && assets.Count > 1) { throw new Exception("For test there mast be selected only one asset"); } StopOptimisationTougle = false; bool doWhile() { if (assets.Count == 0 || StopOptimisationTougle) return false; optimiserInputData.Symb = assets.First(); LoadingOptimisationTougle = assets.Count == 1; assets.Remove(assets.First()); return true; } while (doWhile()) { var data = optimiserInputData; // Copy input data StartOptimisation(data, isAppend, dirPrefix); } } catch (Exception e) { LoadingOptimisationTougle = true; OnPropertyChanged("ResumeEnablingTogle");м ThrowException?.Invoke(e.Message); } }); }
Después de transmitir la lista de activos y verificar que esté completa, pasamos a la parte asincrónica de este método. En un ciclo, llamamos al método de inicio de las optimizaciones previamente analizado, que ahora es sincrónico y, por consiguiente, espera a que se complete el proceso de optimización. Como en la clase del optimizador la estructura transmitida para los parámetros de optimización puede modificar, la copiamos antes de iniciar cada nueva optimización, suministrando con ello a la entrada los datos iniciales de cada nueva optimización.
La condición de continuación, así como la sustitución del activo sobre el que se realizará la optimización, se ejecuta utilizando la función anidada doWhile(). En el cuerpo de la función, comprobamos la condición de salida del ciclo, asignamos el valor del siguiente activo y eliminamos el último activo asignado de la lista. Por consiguiente, en cada nueva iteración de ciclo, primero indicaremos el activo en el que se realizará la optimización, y luego ejecutaremos la optimización, y así sucesivamente hasta que la lista esté vacía o hasta que se envíe una señal sobre la finalización de optimización. En implementaciones anteriores, el proceso de optimización podría finalizarse de manera urgente con solo terminar el proceso en ejecución. No obstante, en la implementación actual, el proceso pasaría a la siguiente iteración en lugar de interrumpirse. Por eso, hemos realizado los ajustes adecuados en el método de finalización de la optimización.
/// <summary> /// Complete optimization from outside the optimizer /// </summary> public void StopOptimisation() { StopOptimisationTougle = true; LoadingOptimisationTougle = true; Optimiser.Stop(); var processes = System.Diagnostics.Process.GetProcesses().Where(x => x.ProcessName == "metatester64"); foreach (var item in processes) item.Kill(); } bool StopOptimisationTougle = false;
Ahora, cuando se detiene la optimización, simplemente establecemos este indicador en true ; el ciclo de iteración de activos, al ver esto, sale de las iteraciones en ejecución. A continuación, después de reasignar a la clase optimizador el proceso de detención de la optimización, debemos terminar los procesos de prueba que también se encontraban en ejecución , porque cuando el terminal se cierra con urgencia, estos procesos con frecuencia se congelan y permanecen en un estado de ejecución hasta que se reinicia la computadora.
Como podemos ver en el fragmento de código anterior, se ha introducido otra bandera: "LoadingOptimisationTougle". Esta indica si es necesario cargar la optimización realizada actualmente en la interfaz gráfica, como se implementó anteriormente. Para acelerar el proceso, esta bandera siempre es igual a false, hasta que el proceso se detenga a la fuerza, o hasta que se alcance el último elemento de la lista de activos transmitida. Y solo después de esto, al salir del proceso de optimización, los datos se cargarán en la interfaz gráfica.
- Guardando un archivo de configuración con los parámetros de inicio de la optimización y borrando la memoria de las optimizaciones cargadas
Incluso en la primera versión del programa, ya introdujimos la posibilidad de añadir nuevas pasadas a las antiguas durante la reoptimización, y no volver así a realizar toda la optimización móvil. No obstante, para que la imagen no cambien al iniciar una nueva optimización, los parámetros de su inicio deberán ser los mismos que en la optimización anterior. Para ello, hemos introducido la opción de almacenar los parámetros de las optimizaciones realizadas anteriormente en el mismo directorio donde se guardan los resultados de las pasadas de optimización. También hemos añadido a la interfaz gráfica un botón que nos permitirá cargarlos para una nueva optimización.
![]()
Después de clicar en este botón, se activará el siguiente método de la clase AutoOptimiserVM:
private void SetBotParams() { if (string.IsNullOrEmpty(SelectedOptimisation)) return; try { Status = "Filling bot params"; OnPropertyChanged("Status"); Progress = 100; OnPropertyChanged("Progress"); var botParams = model.GetBotParamsFromOptimisationPass(OptimiserSettings.First(x => x.Name == "Available experts").SelectedParam, SelectedOptimisation); for (int i = 0; i < BotParams.Count; i++) { if (!botParams.Any(x => x.Variable == BotParams[i].Vriable)) continue; BotParams[i] = new BotParamsData(botParams.First(x => x.Variable == BotParams[i].Vriable)); } } catch (Exception e) { MessageBox.Show(e.Message); } Status = null; OnPropertyChanged("Status"); Progress = 0; OnPropertyChanged("Progress") }
Primero, solicitamos al modelo de datos la lista de parámetros del asesor. Luego, iteramos en un ciclo por todos los parámetros cargados en la interfaz gráfica y comprobamos si el parámetro está disponible en la lista de parámetros recibidos. Si encontramos el parámetro, lo reemplazamos por un nuevo valor en la lista de parámetros actuales. El método del modelo de datos que retorna los parámetros correctos del archivo de configuración es leído por el directorio seleccionado en el cuadro combinado donde se guarda el archivo con el nombre de "OptimisationSettings.set". Este archivo es generado por el método que inicia la optimización, una vez finalizado este proceso.
- Eliminando las pasadas de optimización cargadas previamente de la memoria
También hemos añadido una opción para borrar las pasadas de optimización después de cargarlas. El caso es que ocupan mucho espacio en la memoria RAM y, si el equipo tiene poca RAM, en ocasiones, con una gran cantidad de pruebas históricas y futuras, podría desbordarse de tal forma que el equipo se bloquee. Para minimizar la utilización de recursos, hemos eliminado la duplicación de datos en las pasadas de optimización histórica y futura. Ahora se almacenan solo en el modelo de datos. Asimismo, hemos añadido a la interfaz gráfica el botón especial "Clear loaded results", que recurre al método "ClearResults" del modelo de datos.
void ClearOptimisationFields() { if (HistoryOptimisations.Count > 0) dispatcher.Invoke(() => HistoryOptimisations.Clear()); if (ForwardOptimisations.Count > 0) dispatcher.Invoke(() => ForwardOptimisations.Clear()); if (AllOptimisationResults.AllOptimisationResults.Count > 0) { AllOptimisationResults.AllOptimisationResults.Clear(); AllOptimisationResults = new ReportData { AllOptimisationResults = new Dictionary<DateBorders, List<OptimisationResult>>() }; } GC.Collect(); } public void ClearResults() { ClearOptimisationFields(); OnPropertyChanged("AllOptimisationResults"); OnPropertyChanged("ClearResults"); }
El método mencionado recurre al método private "ClearOptimisationFields", encargado de limpiar en la clase AutoOptimiserM las colecciones que contengan los informes de optimización cargados. No obstante, como estamos tratando con C#, donde la gestión de la memoria no se realiza manualmente, sino de forma automática, para aplicar el borrado de la matriz y eliminar datos de la memoria inmediatamente después del borrado, necesitaremos eliminar la memoria de todos los objetos eliminados. Para ello, llamaremos al método estático Collect de la clase Garbige Collector (GC). Después de realizar dichas acciones, la RAM quedará limpia de los objetos que la ocupaban previamente.
- Formando un archivo (*.set) de la pasada de optimización necesaria.
Después de ver las pasadas de optimización generadas, para introducir más rápidamente los parámetros seleccionados en el robot, necesitaremos generar un archivo (*.set) con su configuración. Antes, debíamos escribir manualmente los parámetros encontrados, o bien generar el archivo desde el simulador, iniciándolo con un doble clic sobre la línea de la optimización seleccionada.
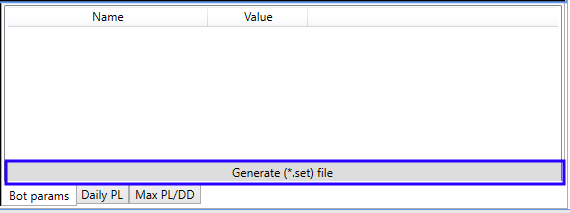
El recuadro sobre el botón contiene una lista con los valores clave donde se guardan los parámetros de optimización. Clicando en el botón, llamaremos a un método del modelo de datos, a donde transmitiremos la lista del recuadro de arriba.
public void SaveBotParams(IEnumerable<KeyValuePair<string, string>> data, string path) { SetFileManager setFileManager = new SetFileManager(path, true) { Params = data.Select(x => new ParamsItem { Variable = x.Key, Value = x.Value }).ToList() }; setFileManager.SaveParams(); }
Este método obtiene la ruta al archivo creado y convierte la matriz clave-valor en una estructura con los parámetros del experto, guardándolos luego en la ruta especificada. La ruta al archivo se indica a través de la interfaz estándar para guardar un archivo desde ViewModel.
Conclusión
Debido a la carga de trabajo, este artículo se ha publicado mucho más tarde de lo planeado, pero esperamos que resulte interesante y útil para todos los que han seguido este proyecto. Seguiremos desarrollándolo en la medida de lo posible, ya que aún quedan algunas ideas que mejorar. Concretamente, querríamos añadir el filtrado automático de optimizaciones, agregar la búsqueda de los mejores parámetros basados en los resultados retrospectivos de la optimización continua, y también la selección de un portafolio con las optimizaciones realizadas. Aunque no hemos implementado nada de esto, si el proyecto sigue siendo interesante para usted, querido lector, continuaremos desarrollándolo en la medida de lo posible. Por ahora, hemos logrado construir un proyecto plenamente funcional que permite cargar el procesador al 100% y optimizar a la vez una serie de activos usando optimizaciones históricas tanto móviles como convencionales.
En los anexos se encuentra el nuevo proyecto del optimizador automático, con el robot de prueba analizado en el artículo №4. Lo único que el lector deberá hacer para usarlo es compilar los archivos del proyecto del optimizador automático y el robot de prueba. A continuación, deberá compilar ReportManager.dll (la implementación descrita en el primer artículo) en el directorio MQL5/Libraries, con lo que ya podrá proceder a probar la combinación obtenida. En los artículos 3 y 4 de esta serie, ya hemos hablado sobre cómo incluir la optimización automática de sus expertos.
Para aquellos lectores que aún no han trabajado con Visual Studio, vamos a describir el proceso de compilación. Podrán compilar el proyecto después de abrirlo en Visual Studio con una amplia gama de métodos, aquí tienen 3 de ellos:
-
El más sencillo consiste en pulsar la combinación de teclas CTRL+SHIFT+B,
-
Otro más visual consiste en pulsar la flecha verde en el editor: se iniciará la aplicación en el modo de depuración del código, pero también tendrá lugar la compilación (funcionará sin problemas solo si está seleccionado el modo de compilación Debug),
-
Otra opción sería desde el punto Build del menú desplegable.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/7891
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Redes neuronales: así de sencillo (Parte 3): Redes convolucionales
Redes neuronales: así de sencillo (Parte 3): Redes convolucionales
 Redes neuronales: así de sencillo (Parte 4): Redes recurrentes
Redes neuronales: así de sencillo (Parte 4): Redes recurrentes
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
¿Qué debo hacer para resolver esto?
Saludos
Hola Andrei Decidí volver a la búsqueda del grial y me alegró encontrar tu optimizador funcionando y finalizado. Las soluciones construidas enteramente en Mql5 resultaron ser exigentes para el soporte del autor y se descarrilaron. Y tu optimizador funcionará mientras exista C# y la ventana del probador de estrategias en MT5 no cambiará. Es extraño que no haya una demanda masiva deoptimización back-forward. De todos modos, ¡muchas gracias por tu duro trabajo!
El probador ya está funcionando, pero voy a expresar algunos deseos. Puede que incluso alguien más siga perfeccionando el proyecto y lo ponga en la base de código.
1. Me gustaría tener tooltips con explicaciones en la cabecera de las tablas con resultados. Que son: var 90, var 95, mx....
2. Los valores de PL y DD en las ventanas 1 y 3 de la pestaña "resultados" no coinciden. Bueno, ¿y las unidades de medida?
3. La función OnTester() no se compila porque está definida en los archivos del optimizador, por lo que se anulan los criterios totalmente personalizados. A partir de los estándar el programa permite escribir cualquier conjunto.
4. ¿Cómo prescindir de los gráficos de balance? Usted puede pegar todos los delanteros juntos y ejecutarlos en un probador, por ejemplo. O mejor - un gráfico aproximado en la ventana del optimizador de una vez para evaluar la valía de la EA para seguir perdiendo el tiempo. Por lo menos, el optimizador debe mostrar el resultado final de todos los pases hacia adelante.
5. El cálculo de los beneficios en pips es necesario. Especialmente teniendo en cuenta cómo funciona el probador con cripto. Añadir una casilla de verificación.
6. Y por último, me gustaría soñar con la posibilidad de añadir múltiples TFs. Similar a la posibilidad de añadir varios activos.
Bueno, y mucho, mucho dinero....
El probador ya está funcionando, pero voy a expresar algunos deseos. Puede que incluso alguien más siga perfeccionando el proyecto y lo ponga en la base de código.
1. Me gustaría tener tooltips con explicaciones en la cabecera de las tablas con resultados. Que son: var 90, var 95, mx....
2. Los valores de PL y DD en las ventanas 1 y 3 de la pestaña "resultados" no coinciden. Bueno, ¿y las unidades de medida?
3. La función OnTester() no se compila porque está definida en los archivos del optimizador, por lo que se anulan los criterios totalmente personalizados. A partir de los estándar el programa permite escribir cualquier conjunto.
4. ¿Cómo prescindir de los gráficos de balance? Usted puede pegar todos los delanteros juntos y ejecutarlos en un probador, por ejemplo. O mejor - un gráfico aproximado en la ventana del optimizador de una vez para evaluar la valía de la EA para seguir perdiendo el tiempo. Por lo menos, el optimizador debe mostrar el resultado final de todos los pases hacia adelante.
5. El cálculo de los beneficios en pips es necesario. Especialmente teniendo en cuenta cómo funciona el probador con cripto. Añadir una casilla de verificación.
6. Y por último, me gustaría soñar con la posibilidad de añadir múltiples TFs. Similar a la posibilidad de añadir varios activos.
Bueno, y mucho, mucho dinero....
Gracias por sus comentarios, yo no apoyo este proyecto, pero sí que debería estar trabajando durante mucho tiempo.
Si alguien tiene un deseo de refinar, ajustar el proyecto - a continuación, hacerlo)
https://github.com/AndreyKrivcov/MetaTrader-Auto-Optimiser.
Si compilo los archivos .mq5 que enviaste desde tu expert advisor llamado "New uploading variant" muestra muchos errores como puedes ver en la imagen de abajo. Acabo de descargar la última versión publicada (8 º artículo).
¿Qué debo hacer para resolver esto?
Saludos
Pues eso. Descargar el archivo adjunto al artículo y ver dos carpetas en el mismo:
Así. Descargamos el archivo adjunto al artículo y vemos dos carpetas en él:
Mover la carpeta MetaTrader-Auto-Optimiser desde el archivo al directorio raíz donde se encuentra MetaTrader 5:
Mueva la carpeta MetaTrader-Auto-Optimiser del archivo al directorio raíz donde se encuentra MetaTrader 5:
En la carpeta MQL5 del archivo hay dos carpetas - cópielas en la carpeta MQL5 de su terminal. En consecuencia, la carpeta Test Expert se copiará en la carpeta MQL5, y dos carpetas: CustomGeneric y History manager se copiarán en la carpeta MQL5.
Compila el archivo SimpleMA.mq5 en la carpeta Experts\Test Expert\Nnueva variante de carga:
Hay dos carpetas en el archivo, en la carpeta MQL5 - cópialas en la carpeta MQL5 de tu terminal. En consecuencia, la carpeta Test Expert se copiará en la carpeta MQL5\Experts, y dos carpetas se copiarán en la carpeta MQL\Include: CustomGeneric y History manager.
Compila el archivo SimpleMA.mq5 que se encuentra en la carpeta Experts\Test Expert\NNNew uploading variant:
Obtenemos 100 errores y 60 advertencias:
Obtenemos 100 errores y 60 advertencias:
Pasemos al primer error y veamos que no es una importación cerrada:
Pasemos al primer error y veamos que no se trata de una importación cerrada:
Haga doble clic en la inscripción sobre el error y vaya al archivo UploadersEntities.mqh en la línea con el error:
Haga doble clic en la inscripción sobre el error y entre en el fichero UploadersEntities.mqh en la línea con el error:
¿Qué vemos? Vemos que realmente no se ha cerrado la importación. Vamos a arreglarlo:
¿Qué vemos? Y vemos realmente no cerrada la importación. Lo arreglamos:
Compila de nuevo. El error de importación ha desaparecido, pero ahora el compilador no ve las funciones y métodos del fichero importado:
Compilemos de nuevo. El error de importación ha desaparecido, pero ahora el compilador no ve las funciones y métodos del fichero importado:
Recuerda que estamos importando métodos y clases de una dll de terceros. Debe estar ubicado en la carpeta MQL5/Libraries.
Abrimos la carpeta MetaTrader-Auto-Optimiser, copiada del archivo al directorio raíz de MetaTrader 5. Vemos el archivo Metatrader Auto Optimiser.sln en ella:
Recordamos que estamos importando métodos y clases de una dll de terceros. Y debería estar en la carpeta MQL5\Libraries.
Abrimos la carpeta MetaTrader-Auto-Optimiser copiada del archivo al directorio raíz de MetaTrader 5. Vemos el archivo Metatrader Auto Optimiser.sln en ella:
Haga doble clic en este archivo para abrir el proyecto en MS Visual Studio.
Al abrir el proyecto, vemos que es para una plataforma obsoleta:
Haga doble clic en este archivo para abrir el proyecto en MS Visual Studio.
Al abrir el proyecto, vemos que es para una plataforma obsoleta:
Dejamos marcada la casilla "Upgrade target to .NET Framefork 4.8 platform" y pulsamos el botón "Continue".
A continuación, de nuevo para el segundo proyecto:
Deje marcada la casilla "Upgrade target to .NET Framefork 4.8 platform" y haga clic en el botón "Continue".
A continuación, de nuevo para el segundo proyecto:
Después de cargar los proyectos, seleccione "Release" y Cualquier CPU:
Después de cargar los proyectos, selecciona "Release" y Any CPU:
Y pulsa Ctrl+F5 para compilar y construir los proyectos.
Después de compilar el proyecto en MS Visual Studio vaya al directorio raíz de la terminal y en ella a la carpeta \MetaTrader-Auto-Optimiser\ReportManager\bin\Release. Copia el archivo de la biblioteca ReportManager.dll de esta carpeta al directorio MQL5/Libraries del terminal.
Ahora compila de nuevo el archivo SimpleMA.mq5 de la carpeta MQL5\Experts\Test Expert\Nnew uploading variant.
Hecho, sin errores:
Y pulse Ctrl+F5 para compilar y construir los proyectos.
Después de compilar el proyecto en MS Visual Studio, vaya al directorio raíz del terminal y en él a la carpeta \MetaTrader-Auto-Optimiser\ReportManager\bin\Release. Copiamos el archivo compilado ReportManager.dll de esta carpeta al directorio MQL5\Libraries del terminal.
Ahora vamos a compilar de nuevo el archivo SimpleMA.mq5 de la carpeta MQL5\Experts\Test Expert\NNew uploading variant.
Hecho, sin errores:
Disfruta
Entonces. Descargar el archivo adjunto al artículo y ver dos carpetas en el mismo:
Así. Descargamos el archivo adjunto al artículo y vemos dos carpetas en él:
Transferir la carpeta MetaTrader-Auto-Optimiser desde el archivo al directorio raíz donde se encuentra MetaTrader 5:
Trasladar la carpeta MetaTrader-Auto-Optimiser desde el archivo comprimido al directorio raíz donde se encuentra MetaTrader 5:
En la carpeta MQL5 del archivo hay dos carpetas - cópielas en la carpeta MQL5 de su terminal. En consecuencia, la carpeta Test Expert se copiará en la carpeta MQL5, y dos carpetas: CustomGeneric y History manager se copiarán en la carpeta MQL5.
Compila el archivo SimpleMA.mq5 que se encuentra en la carpeta Experts\Test Expert\Nnueva variante de carga:
Hay dos carpetas en el archivo, en la carpeta MQL5 - cópialas en la carpeta MQL5 de tu terminal. En consecuencia, la carpeta Test Expert se copiará en la carpeta MQL5\Experts, y dos carpetas se copiarán en la carpeta MQL\Include: CustomGeneric y History manager.
Compila el archivo SimpleMA.mq5 ubicado en la carpeta Experts\Test Expert\NNNueva variante de subida:
Obtenemos 100 errores y 60 advertencias:
Obtenemos 100 errores y 60 advertencias:
Ve al primer error y verás que no es una importación cerrada:
Vayamos al primer error y veamos que no es una importación cerrada:
Gracias, actualizadas las fuentes adjuntas al artículo