
Otimização Walk Forward contínua (Parte 8): Melhorias e correções do programa

Introdução
O programa foi modificado com base nos comentários e solicitações dos usuários e leitores desta série de artigos. Este artigo contém uma nova versão do otimizador automático. Esta versão implementa os recursos solicitados e fornece outras melhorias, que eu descobri ao trabalhar com o programa. As otimizações agora são realizadas de maneira mais rápida do que na versão anterior, que é o resultado da decisão de trabalhar sem mutexes e para evitar algumas outras ações que retardavam o processo de geração de relatórios. Agora, a otimização pode ser usada para um conjunto de ativos. Além disso, o problema com a memória ocupada no momento da otimização foi resolvido.
Os artigos anteriores desta série:
- Otimização Walk Forward Contínua (Parte 1): Trabalhando com os Relatórios de Otimização
- Otimização Walk Forward Contínua (Parte 2): Mecanismo para a criação de um relatório de otimização para qualquer robô
- Otimização Walk Forward Contínua (Parte 3): Método de Adaptação de um Robô ao Otimizador Automático
- Otimização Walk Forward Contínua (Parte 4): Gerenciamento de Otimização (Otimizador Automático)
- Otimização Walk Forward Contínua (Parte 5): Panorama do Projeto Otimizador Automático e Criação da Interface Gráfica
- Otimização Walk Forward contínua (Parte 6): Lógica e estrutura do otimizador automático
- Otimização Walk Forward Contínua (Parte 7): Vinculação da parte lógica do Otimizador Automático com a parte gráfica e o controle do mesmo no programa
Adicionando o preenchimento automático de data
A versão anterior do programa tinha uma entrada em fase de datas para otimizações do histórico e forward, o que era inconveniente. Desta vez, eu implementei a entrada automatizada dos intervalos de tempo necessários. Os detalhes da funcionalidade podem ser descritos a seguir. O intervalo de tempo selecionado deve ser automaticamente dividido em otimização forward e histórico. A etapa para ambos os tipos de otimização é fixa e definida antes da divisão em intervalos. Cada novo intervalo de forward deve começar no dia seguinte após o intervalo anterior. O deslocamento dos intervalos do histórico (que se sobrepõem) é igual as janelas de forward. Ao contrário das otimizações do histórico, as de forward não se sobrepõem e implementam um histórico de negociação contínuo.
Para implementar esta tarefa, eu decidi transferir esta funcionalidade para uma janela gráfica separada e torná-la independente e não diretamente relacionada à interface principal. Como resultado, nós temos a seguinte hierarquia de objetos.
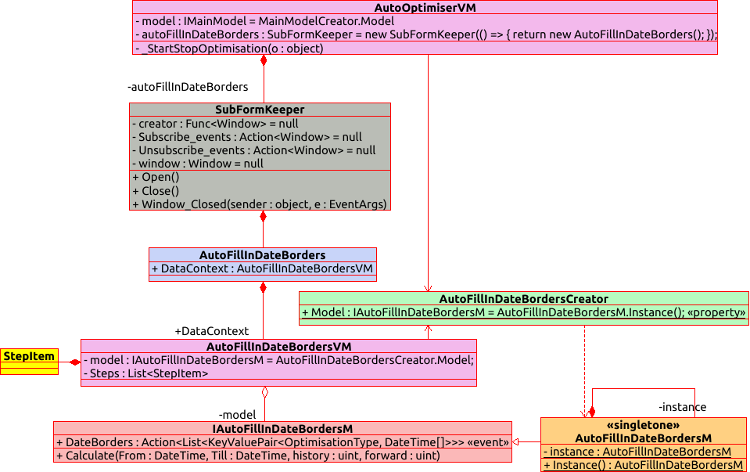
Vamos considerar como essa funcionalidade está conectada e ver seus exemplos de implementação. Comecemos com a interface gráfica da extensão criada, ou seja, tudo no gráfico a partir do objeto AutoFillInDateBorders, que representa a janela gráfica, e abaixo. A imagem mostra os elementos da GUI, a marcação XAML e os campos da parte ViewModel representada pela classe AutoFillInDateBordersVM.
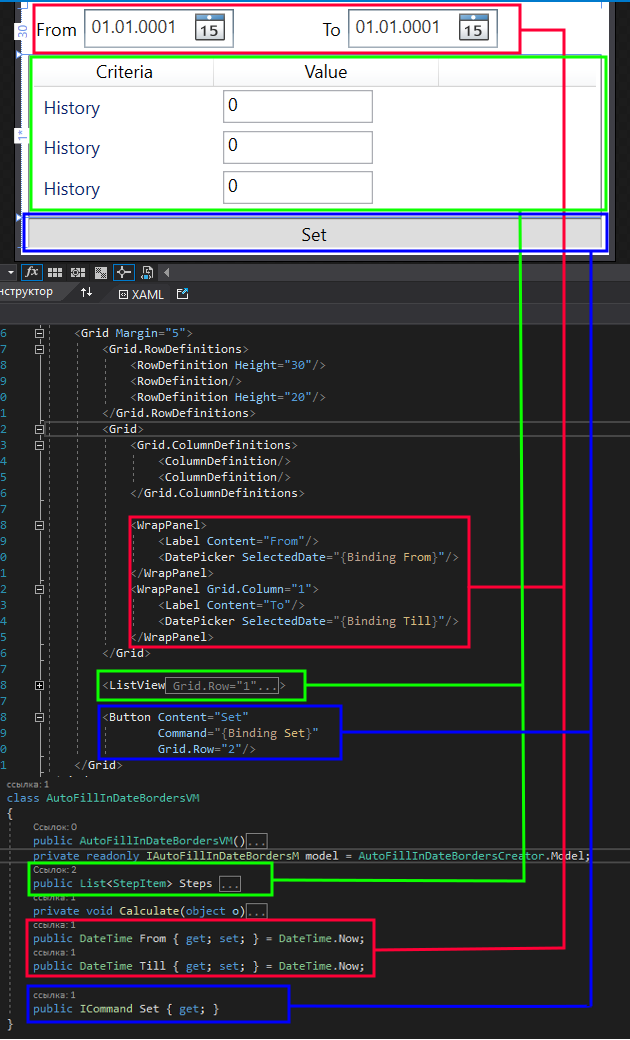
Como você pode ver, a GUI possui três seções principais. Isso inclui dois calendários para inserir as datas de início e término do período de otimização, tabelas para especificar os limites dos intervalos de forward e histórico, bem como o botão "Set", que divide o intervalo especificado nas janelas do histórico e forward apropriadas. A tabela na captura de tela contém três linhas duplicadas, no entanto, na verdade, existem apenas duas linhas: a primeira é responsável pelo intervalo de datas do histórico e a segunda define o intervalo de forward.
o valor 'Value' na tabela é o passo do tipo de otimização correspondente em dias. Por exemplo, se o 'Value' do intervalo do histórico for 360 dias e o de forward for 90, isso significa que o intervalo de tempo especificado nos calendários será dividido em intervalos de 360 dias para a otimização do histórico e de 90 dias para o de forward. O início de cada próxima janela de otimização do histórico será deslocado pelo passo do intervalo de forward.
class AutoFillInDateBordersM : IAutoFillInDateBordersM { private AutoFillInDateBordersM() { } private static AutoFillInDateBordersM instance; public static AutoFillInDateBordersM Instance() { if (instance == null) instance = new AutoFillInDateBordersM(); return instance; } public event Action<List<KeyValuePair<OptimisationType, DateTime[]>>> DateBorders; public void Calculate(DateTime From, DateTime Till, uint history, uint forward) { if (From >= Till) throw new ArgumentException("Date From must be less then date Till"); List<KeyValuePair<OptimisationType, DateTime[]>> data = new List<KeyValuePair<OptimisationType, DateTime[]>>(); OptimisationType type = OptimisationType.History; DateTime _history = From; DateTime _forward = From.AddDays(history + 1); DateTime CalcEndDate() { return type == OptimisationType.History ? _history.AddDays(history) : _forward.AddDays(forward); } while (CalcEndDate() <= Till) { DateTime from = type == OptimisationType.History ? _history : _forward; data.Add(new KeyValuePair<OptimisationType, DateTime[]>(type, new DateTime[2] { from, CalcEndDate() })); if (type == OptimisationType.History) _history = _history.AddDays(forward + 1); else _forward = _forward.AddDays(forward + 1); type = type == OptimisationType.History ? OptimisationType.Forward : OptimisationType.History; } if (data.Count == 0) throw new ArgumentException("Can`t create any date borders with set In sample (History) step"); DateBorders?.Invoke(data); } }
A classe do modelo para os dados da janela é um objeto escrito usando o padrão Singleton. Isso permite a interação da parte ViewModel da janela principal com o modelo de dados, enquanto ignora a janela de gráficos da extensão. Entre os métodos interessantes, o objeto contém apenas "Calculate", que calcula os intervalos de datas e um evento chamado após a conclusão do procedimento acima. O evento recebe a coleção de valores emparelhados como um parâmetro, em que a chave é o tipo do intervalo analisado (otimização direta ou histórica), e o valor é um array de dois valores DateTime. A primeira data indica o início do intervalo selecionado e a segunda indica o fim.
O método, que cálcula os intervalos de datas, realiza os cálculos em um loop, alternativamente alterando o tipo da janela calculada (forward ou histórico). Primeiramente, o tipo da janela do histórico é definido como o ponto de partida de todos os cálculos. Os valores das datas iniciais para cada um dos tipos de janela também são definidos antes do início do loop. A cada iteração de um loop, a borda extrema do tipo de janela selecionada é calculada usando a função aninhada, e então este valor é verificado com a data do intervalo extremo. Se essa data for excedida, então, é uma condição de saída do loop. O intervalo da janela de otimização é formado em um loop. Então, a próxima data de início da janela e o alternador do tipo da janela são atualizados.
Depois de todas as operações, se nenhum erro ocorreu, um evento é chamado com o intervalo de datas que foi passado. Todas as outras ações são realizadas pela classe. A execução do método acima é iniciada pelo retorno de chamada ao pressionar o botão "Set".
O modelo de dados factory da nossa extensão é implementado de maneira mais simples:
class AutoFillInDateBordersCreator { public static IAutoFillInDateBordersM Model => AutoFillInDateBordersM.Instance(); }
Basicamente, quando nós chamamos a propriedade estática 'Model', nos referimos de forma constante à mesma instância de objeto do modelo de dados e, em seguida, o convertemos em um tipo de interface. Vamos usar esse fato na parte ViewModel de nossa janela principal.
public AutoOptimiserVM() { ... AutoFillInDateBordersCreator.Model.DateBorders += Model_DateBorders; .... } ~AutoOptimiserVM() { ... AutoFillInDateBordersCreator.Model.DateBorders -= Model_DateBorders; .... }
Tanto no construtor quanto no destruidor do objeto ViewModel da janela principal, temos a oportunidade de não armazenar um ponteiro para uma instância dessa classe, mas de chamá-lo por meio de um modelo factory de dados estáticos. Preste atenção que a parte ViewModel da janela principal funciona com a classe considerada sem saber que ela trabalha com ela. Isto acontece porque as referências a este objeto não são mencionadas em nenhum lugar, exceto no construtor e destruidor da classe. O retorno da chamada que se inscreve no evento mencionado esvazia primeiro todos os intervalos de datas inseridos anteriormente e, em seguida, em um loop, ele adiciona os novos intervalos de datas obtidos por meio do evento, um de cada vez. O método de adição dos intervalos de datas à coleção também é implementado no lado ViewModel da interface gráfica principal. Ele se parece com isso:
void _AddDateBorder(DateTime From, DateTime Till, OptimisationType DateBorderType) { try { DateBorders border = new DateBorders(From, Till); if (!DateBorders.Where(x => x.BorderType == DateBorderType).Any(y => y.DateBorders == border)) { DateBorders.Add(new DateBordersItem(border, _DeleteDateBorder, DateBorderType)); } } catch (Exception e) { System.Windows.MessageBox.Show(e.Message); } }
A criação de um objeto DateBorder é envolvida em uma construção 'try - catch'. Isso é feito porque uma exceção pode ocorrer no construtor do objeto e ela deve ser tratada de alguma forma. Eu também adicionei o método ClearDateBorders:
ClearDateBorders = new RelayCommand((object o) => { DateBorders.Clear(); });
Ele permite a exclusão rápida de todos os intervalos de datas inseridos. Na versão anterior, cada data precisava ser excluída separadamente, o que era inconveniente para um grande número de datas. Os botões da janela da GUI principal que chamam as inovações descritas foram adicionados na mesma linha com os controles de intervalo de datas existentes anteriormente.
![]()
Um clique em Autoset dispara o retorno da chamada que chama o método Open na instância da classe SubFormKeeper. Esta classe foi escrita como um wrapper que encapsula o processo de criação da janela aninhada. Isso elimina as propriedades e campos desnecessários no ViewModel da janela principal, bem como nos impede de acessar diretamente a janela auxiliar criada, pois ela não deve ser interagida de maneira direta.
class SubFormKeeper { public SubFormKeeper(Func<Window> createWindow, Action<Window> subscribe_events = null, Action<Window> unSubscribe_events = null); public void Open(); public void Close(); }
Se você observar a assinatura da classe, você verá que, a partir dos métodos públicos, ela fornece exatamente o conjunto listado de possibilidades. Além disso, todas as janelas do otimizador automático auxiliar serão envolvidas nesta classe específica.
Novos recursos e correções de bugs na biblioteca para trabalhar com resultados de otimização
Esta parte do artigo descreve as alterações na biblioteca para trabalhar com os relatórios de otimização - "ReportManager.dll". Além da introdução de um coeficiente personalizado, o novo recurso oferece um descarregamento mais rápido de relatórios de otimização da plataforma. Ele também corrige um erro na ordenação de dados.
- Apresentando um coeficiente de otimização personalizado
Uma das sugestões de melhoria nos comentários dos artigos anteriores foi a capacidade de usar um coeficiente personalizado para filtrar os resultados de otimização. Para implementar esta opção, eu tive que fazer algumas alterações nos objetos existentes. No entanto, para suportar os relatórios antigos, a classe que lê os dados de otimizações pode trabalhar tanto com relatórios que possuem coeficientes customizados, quanto com aqueles que foram gerados em versões anteriores do programa. Portanto, o formato do relatório permaneceu inalterado. Ele tem um parâmetro adicional - um campo para especificar o coeficiente personalizado.
A enumeração "SortBy" agora apresenta o novo parâmetro "Custom", e o campo apropriado foi adicionado à estrutura "Coefficients". Isso adiciona o coeficiente aos objetos responsáveis pelo armazenamento de dados, mas não o adiciona aos objetos que descarregam e leem os dados. A gravação de dados é realizada por dois métodos e uma classe com métodos estáticos que são usados a partir da MQL5 para salvar os relatórios.
public static void AppendMainCoef(double customCoef, double payoff, double profitFactor, double averageProfitFactor, double recoveryFactor, double averageRecoveryFactor, int totalTrades, double pl, double dd, double altmanZScore) { ReportItem.OptimisationCoefficients.Custom = customCoef; ... }
Primeiramente, foi adicionado um novo parâmetro, que identifica o coeficiente personalizado, ao método AppendMainCoef. Então, ele é adicionado à estrutura ReportWriter.ReportItem, como outros coeficientes aprovados. Agora, se você tentar compilar o projeto antigo com a nova biblioteca "ReportManager.dll", obterá uma exceção, porque a assinatura do método AppendMainCoef foi alterada. Este erro pode ser corrigido editando ligeiramente o objeto que descarrega os dados - nós passaremos para o código em MQL5 mais tarde.
Para habilitar a compilação correta com a versão dll atual, substitua o "History Manager" no diretório Include por um novo que está anexado abaixo neste artigo - isso será o suficiente para compilar os robôs com os métodos antigos e novos.
Além disso, eu alterei a assinatura do método Write, que agora não lança exceções, mas retorna uma mensagem de erro. Isso foi adicionado porque o programa não usa mais o mutex nomeado, o que desacelerou significativamente o processo de descarregamento dos dados, mas era necessário para gerar os relatórios na versão antiga da classe de descarregamento. No entanto, eu não excluí o método que grava os dados usando um mutex, a fim de manter a compatibilidade com o formato de exportação de dados implementado anteriormente.
Para que um novo registro apareça no arquivo do relatório, nós precisamos criar uma nova tag <Item/> com o atributo Name igual a "Custom".
WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.Custom.ToString(), new Dictionary<string, string> { { "Name", "Custom" } });
Outro método modificado é o OptimisationResultsExtentions.ReportWriter: uma linha semelhante foi adicionada aqui, que adiciona a tag <Item/> com o parâmetro do coeficiente personalizado.
Agora, vamos considerar a adição de coeficientes personalizados aos dados e ao código do robô em MQL. Primeiro, vamos considerar a versão antiga da funcionalidade de download dos dados, na qual o código que trabalha com a classe ReportWriter está localizado na classe CXmlHistoryWriter no arquivo XmlHistoryWriter.mqh. Uma referência à assinatura a seguir foi criada para oferecer suporte aos coeficientes personalizados:
typedef double(*TCustomFilter)();
O campo 'private' na classe acima armazena esta função.
class CXmlHistoryWriter { private: const string _path_to_file,_mutex_name; CReportCreator _report_manager; TCustomFilter custom_filter; void append_bot_params(const BotParams ¶ms[]);// void append_main_coef(PL_detales &pl_detales, TotalResult &totalResult);// //double get_average_coef(CoefChartType type); void insert_day(PLDrawdown &day,ENUM_DAY_OF_WEEK day);// void append_days_pl();// public: CXmlHistoryWriter(string file_name,string mutex_name, CCCM *_comission_manager, TCustomFilter filter);// CXmlHistoryWriter(string mutex_name,CCCM *_comission_manager, TCustomFilter filter); ~CXmlHistoryWriter(void) {_report_manager.Clear();} // void Write(const BotParams ¶ms[],datetime start_test,datetime end_test);// };
O valor desse campo 'private' é preenchido a partir do construtor da classe. Além disso, no método append_main_coef, ao chamar o método estático "ReportWriter::AppendMainCoef" da biblioteca dll, ele chama a função passada pelo seu ponteiro e, assim, receber o valor do coeficiente personalizado.
A classe não é usada diretamente, pois há um wrapper que foi descrito anteriormente, no terceiro artigo - ela é a classe CAutoUploader.
class CAutoUploader { private: datetime From,Till; // Testing start and end dates CCCM *comission_manager; // Commission manager BotParams params[]; // List of parameters string mutexName; // Mutex name TCustomFilter custom_filter; public: CAutoUploader(CCCM *comission_manager, string mutexName, BotParams ¶ms[], TCustomFilter filter); CAutoUploader(CCCM *comission_manager, string mutexName, BotParams ¶ms[]); virtual ~CAutoUploader(void); virtual void OnTick(); // Calculating testing start and end dates };
double EmptyCustomCoefCallback() {return 0;} //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CAutoUploader::CAutoUploader(CCCM *_comission_manager,string _mutexName,BotParams &_params[], TCustomFilter filter) : comission_manager(_comission_manager), mutexName(_mutexName), From(0), Till(0), custom_filter(filter) { CopyBotParams(params,_params); } //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CAutoUploader::CAutoUploader(CCCM *_comission_manager,string _mutexName,BotParams &_params[]) : comission_manager(_comission_manager), mutexName(_mutexName), From(0), Till(0), custom_filter(EmptyCustomCoefCallback) { CopyBotParams(params,_params); }
A função "EmptyCustomCoefCallback" foi criada para salvar a versão antiga do construtor. Esta função retorna zero como um coeficiente personalizado. Se o construtor anterior desta classe é chamado, passamos esta função para a classe CXmlHistoryWriter. Se nós tomarmos um exemplo usado no artigo 4, nós podemos adicionar um coeficiente personalizado ao robô da seguinte maneira:
//+------------------------------------------------------------------+ //| SimpleMA.mq5 | //| Copyright 2019, MetaQuotes Software Corp. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2019, MetaQuotes Software Corp." #property link "https://www.mql5.com" #property version "1.00" #include <Trade/Trade.mqh> #include <History manager/AutoLoader.mqh> // Include CAutoUploader #define TESTER_ONLY input int ma_fast = 10; // MA fast input int ma_slow = 50; // MA slow input int _sl_ = 20; // SL input int _tp_ = 60; // TP input double _lot_ = 1; // Lot size // Comission and price shift (Article 2) input double _comission_ = 0; // Comission input int _shift_ = 0; // Shift int ma_fast_handle,ma_slow_handle; const double tick_size = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_SIZE); CTrade trade; CAutoUploader * auto_optimiser;// Pointer to CAutoUploader class (Article 3) CCCM _comission_manager_;// Comission manager (Article 2) double CulculateMyCustomCoef() { return 0; } //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ... // Add Instance CAutoUploader class (Article3) auto_optimiser = new CAutoUploader(&_comission_manager_,"SimpleMAMutex",params,CulculateMyCustomCoef); //--- return(INIT_SUCCEEDED); } double OnTester() { return(CulculateMyCustomCoef()); } //+------------------------------------------------------------------+
Aqui, eu removi a implementação, exceto a parte associada à introdução do coeficiente personalizado, para não fornecer muito código aqui. O código completo está disponível em anexo. Primeiro, é necessário criar uma função, que irá calcular o coeficiente personalizado. No exemplo acima, a função retorna zero e não tem implementação, mas o cálculo do coeficiente personalizado deve ser descrito nela. Portanto, os cálculos não serão feitos no retorno da OnTester - a função descrita será chamada em vez disso. Durante a criação da classe CAutoUploader, nós precisamos apenas chamar uma nova sobrecarga do construtor e especificar o coeficiente personalizado nela. Isso completa a adição de um coeficiente personalizado.
- O carregamento mais rápido dos dados de passagem da otimização no novo formato de upload dos dados
A decisão de excluir o mutex aumentou a velocidade de carregamento dos dados, mas essa melhoria não é suficiente. Na versão anterior, nós tínhamos que executar uma série de operações com cada novo registro para adicionar os dados a um arquivo:
- Ler um arquivo
- Salvar os dados lidos na RAM
- Adicionar uma nova passagem de otimização aos dados lidos na memória
- Remover o arquivo antigo
- Criar um arquivo novo e limpo no lugar do antigo
- Salvar todo o array de dados no arquivo criado
Este é o procedimento padrão da classe usada XmlDocument da biblioteca padrão C#. Este procedimento é demorado. Além disso, a quantidade de tempo para essas operações aumenta à medida que o arquivo cresce. Nós tivemos que aceitar esse recurso na versão anterior, pois nós não podíamos acumular todos os dados em um só lugar. Em vez disso, nós salvamos os dados após a conclusão de cada otimização. Na implementação atual, os dados são acumulados usando quadros e, portanto, nós podemos converter todos os dados para o formato necessário de uma vez. Isso é implementado usando o método "OptimisationResultsExtentions.ReportWriter" escrito anteriormente. Este é um método de extensão para o conjunto de passos da otimização. Ao contrário do ReportWriter.Write, este método não adiciona os dados para um arquivo, mas cria um arquivo e grava todos os passos de otimização linha por linha. Portanto, o array de dados que demorava vários minutos quando era escrito por ReportWriter.Write agora pode ser escrito em alguns segundos.
Um wrapper na classe ReportWriter foi criado para permitir o uso do método OptimisationResultsExtentions.ReportWriter da MQL5.
public class ReportWriter { private static ReportItem ReportItem; private static List<OptimisationResult> ReportData = new List<OptimisationResult>(); public static void AppendToReportData(string symbol, int tf, ulong StartDT, ulong FinishDT) { ReportItem.Symbol = symbol; ReportItem.TF = tf; ReportItem.DateBorders = new DateBorders(StartDT.UnixDTToDT(), FinishDT.UnixDTToDT()); ReportData.Add(ReportItem); ClearReportItem(); } public static void ClearReportItem() { ReportItem = new ReportItem(); } public static void ClearReportData() { ReportData.Clear(); } public static string WriteReportData(string pathToBot, string currency, double balance, int laverage, string pathToFile) { try { ReportData.ReportWriter(pathToBot, currency, balance, laverage, pathToFile); ClearReportData(); } catch (Exception e) { return e.Message; } ClearReportData(); return ""; } }
Na classe ReportWriter, nós criamos o ReportData, que armazenará uma coleção de elementos ReportItem, portanto, será uma coleção de passos de otimização. A ideia é gravar todos os dados necessários da MQL5 na estrutura ReportItem, usando os métodos descritos no primeiro artigo. Então, chamando o método AppendToReportData, adicionamos eles à coleção de passos de otimização. Desta forma, a coleta de dados necessária será formada no lado da C#. Assim que todos os passos da otimização forem adicionados à coleção, chamamos o método WriteReportData que forma rapidamente o relatório de otimização usando o método OptimisationResultsExtentions.ReportWriter.
- Correção de bug
Infelizmente, eu cometi um erro na versão anterior do programa, que for percebido tardiamente. Esse erro está relacionado ao mecanismo de ordenação das otimizações descrito no primeiro artigo. Como a ordenação dos dados pode ser realizada de acordo com vários critérios, é necessário determinar quais desses critérios serão maximizados e quais serão minimizados. Por exemplo, ninguém maximizaria o número de negociações perdedoras.
Para evitar confusão, a ordenação da otimização tem um significado de direção um pouco diferente:
- Descendente - do melhor para o pior parâmetro
- Ascendente - do pior para os melhores parâmetros
Para que o método de ordenação dos dados seja capaz de determinar quais critérios que devem ser maximizados e quais devem ser minimizados, foi criado um método separado retornando as variáveis apropriadas. A implementação do método anterior era a seguinte:
private static SortMethod GetSortMethod(SortBy sortBy) { switch (sortBy) { case SortBy.Payoff: return SortMethod.Increasing; case SortBy.ProfitFactor: return SortMethod.Increasing; case SortBy.AverageProfitFactor: return SortMethod.Increasing; case SortBy.RecoveryFactor: return SortMethod.Increasing; case SortBy.AverageRecoveryFactor: return SortMethod.Increasing; case SortBy.PL: return SortMethod.Increasing; case SortBy.DD: return SortMethod.Decreasing; case SortBy.AltmanZScore: return SortMethod.Decreasing; case SortBy.TotalTrades: return SortMethod.Increasing; case SortBy.Q_90: return SortMethod.Decreasing; case SortBy.Q_95: return SortMethod.Decreasing; case SortBy.Q_99: return SortMethod.Decreasing; case SortBy.Mx: return SortMethod.Increasing; case SortBy.Std: return SortMethod.Decreasing; case SortBy.MaxProfit: return SortMethod.Increasing; case SortBy.MaxDD: return SortMethod.Decreasing; case SortBy.MaxProfitTotalTrades: return SortMethod.Increasing; case SortBy.MaxDDTotalTrades: return SortMethod.Decreasing; case SortBy.MaxProfitConsecutivesTrades: return SortMethod.Increasing; case SortBy.MaxDDConsecutivesTrades: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Mn: return SortMethod.Increasing; case SortBy.AverageDailyDD_Mn: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Mn: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Mn: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Tu: return SortMethod.Increasing; case SortBy.AverageDailyDD_Tu: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Tu: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Tu: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_We: return SortMethod.Increasing; case SortBy.AverageDailyDD_We: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_We: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_We: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Th: return SortMethod.Increasing; case SortBy.AverageDailyDD_Th: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Th: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Th: return SortMethod.Decreasing; case SortBy.AverageDailyProfit_Fr: return SortMethod.Increasing; case SortBy.AverageDailyDD_Fr: return SortMethod.Decreasing; case SortBy.AverageDailyProfitTrades_Fr: return SortMethod.Increasing; case SortBy.AverageDailyDDTrades_Fr: return SortMethod.Decreasing; default: throw new ArgumentException($"Unaxpected Sortby variable {sortBy}"); } }
A implementação atual é a seguinte:
private static OrderBy GetSortingDirection(SortBy sortBy) { switch (sortBy) { case SortBy.Custom: return OrderBy.Ascending; case SortBy.Payoff: return OrderBy.Ascending; case SortBy.ProfitFactor: return OrderBy.Ascending; case SortBy.AverageProfitFactor: return OrderBy.Ascending; case SortBy.RecoveryFactor: return OrderBy.Ascending; case SortBy.AverageRecoveryFactor: return Or-derBy.Ascending; case SortBy.PL: return OrderBy.Ascending; case SortBy.DD: return OrderBy.Ascending; case SortBy.AltmanZScore: return OrderBy.Descending; case SortBy.TotalTrades: return OrderBy.Ascending; case SortBy.Q_90: return OrderBy.Ascending; case SortBy.Q_95: return OrderBy.Ascending; case SortBy.Q_99: return OrderBy.Ascending; case SortBy.Mx: return OrderBy.Ascending; case SortBy.Std: return OrderBy.Descending; case SortBy.MaxProfit: return OrderBy.Ascending; case SortBy.MaxDD: return OrderBy.Ascending; case SortBy.MaxProfitTotalTrades: return OrderBy.Ascending; case SortBy.MaxDDTotalTrades: return OrderBy.Descending; case SortBy.MaxProfitConsecutivesTrades: return OrderBy.Ascending; case SortBy.MaxDDConsecutivesTrades: return OrderBy.Descending; case SortBy.AverageDailyProfit_Mn: return OrderBy.Ascending; case SortBy.AverageDailyDD_Mn: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Mn: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Mn: return OrderBy.Descending; case SortBy.AverageDailyProfit_Tu: return OrderBy.Ascending; case SortBy.AverageDailyDD_Tu: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Tu: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Tu: return OrderBy.Descending; case SortBy.AverageDailyProfit_We: return OrderBy.Ascending; case SortBy.AverageDailyDD_We: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_We: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_We: return OrderBy.Descending; case SortBy.AverageDailyProfit_Th: return OrderBy.Ascending; case SortBy.AverageDailyDD_Th: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Th: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Th: return OrderBy.Descending; case SortBy.AverageDailyProfit_Fr: return OrderBy.Ascending; case SortBy.AverageDailyDD_Fr: return OrderBy.Descending; case SortBy.AverageDailyProfitTrades_Fr: return OrderBy.Ascending; case SortBy.AverageDailyDDTrades_Fr: return OrderBy.Descending; default: throw new ArgumentException($"Unaxpected Sortby variable {sortBy}"); } }
Como você pode ver no código, foi alterado a direção da ordenação dos coeficientes selecionados. Na implementação anterior, eles eram marcados como classificados em ordem decrescente. No entanto, eu não levei em consideração que esses dados têm um valor negativo e que devem ser classificados em ordem crescente e não decrescente. Para entender a lógica, observamos o código a seguir, que implementa a ordenação para cada um dos valores passados:
// If the minimum is below zero, shift all data by the negative minimum valueif (mm.Min < 0) { value += Math.Abs(mm.Min); mm.Max += Math.Abs(mm.Min); } // If the maximum is greater than zero, calculate if (mm.Max > 0) { // Calculate the coefficient according to the sorting method if (GetSortingDirection(item.Key) == OrderBy.Descending) { // Calculate the coefficient to sort in descending order data.SortBy += (1 - value / mm.Max) * coef; } else { // Calculate the coefficient to sort in ascending order data.SortBy += value / mm.Max * coef; } }
A variável 'value" é um valor numérico de um certo coeficiente. Antes de ordenar os dados, verificamos se o valor mínimo do array do coeficiente selecionado para ordenação é negativo. Se for, convertemos esses valores para o plano positivo deslocando-os para cima pelo valor do coeficiente mínimo. Assim, nós teremos um array de valores no intervalo [0 ; (Máx + |Mín|)]. Ao calcular o coeficiente resultante pelo qual a ordenação final será realizada, nós deslocamos o array de dados para o intervalo [0; 1] dividindo cada i-ésimo valor pelo valor máximo do array de dados para ordenação. Se o método de ordenação for decrescente, então subtraímos o valor resultante de um, invertendo assim o array dos pesos resultantes. É por isso que a versão anterior de ordenação dos dados está incorreta: devido à lógica de ordenação multifatorial implementada, simplesmente invertemos o array de pesos, que não era necessária para os coeficientes marcados no código acima. O método de ordenação é descrito com mais detalhes no primeiro artigo. Por conveniência, o nome do método e o tipo de retorno foram alterados para outros mais apropriados, mas isso não afeta a lógica do aplicativo de forma alguma.
O segundo erro foi a parte do código que ordenou o array de resultados da otimização no caso em que apenas um critério de ordenação foi selecionado. A implementação anterior foi a seguinte:
if (order == OrderBy.Ascending) return results.OrderBy(x => x.GetResult(sortingFlags.ElementAt(0))); else return results.OrderByDescending(x => x.GetResult(sortingFlags.ElementAt(0)));
O atual se parece com isto:
if (order == GetSortingDirection(sortingFlags.ElementAt(0))) return results.OrderBy(x => x.GetResult(sortingFlags.ElementAt(0))); else return results.OrderByDescending(x => x.GetResult(sortingFlags.ElementAt(0)));
A versão anterior não levava em consideração as direções especificadas pelo método GetSortingDirection. A versão nova ordena de acordo com este critério. Por exemplo, se nós selecionarmos a ordenação decrescente (os melhores resultados no topo), então para SortBy.PL, a ordenação decrescente solicitada será realizada, e o valor mais alto estará no topo. No entanto, para o parâmetro SortBy.MaxDDTotalTrades (o número total de negócios não lucrativos), o menor valor ficará no topo e o array será ordenado em ordem crescente. Isso preserva a estrutura lógica. Por exemplo, se nós selecionarmos SortBy.MaxDDTotalTrades como critério, nós teríamos recebido os piores passes de acordo com a lógica de ordenação anterior.
O carregamento automatizado dos parâmetros do robô e novas regras de escrita do Expert Advisor
A nova lógica de carregamento dos parâmetros é fornecida no arquivo "AutoUploader2.mqh". A descrição do mecanismo será seguida por um exemplo baseado no Expert Advisor apresentado no quarto artigo.
class CAutoUploader2 { private: CAutoUploader2() {} static CCCM comission_manager; static datetime From,Till; static TCustomFilter on_tester; static TCallback on_tick, on_tester_deinit; static TOnTesterInit on_tester_init; static string frame_name; static long frame_id; static string file_name; static bool FillInData(Data &data); static void UploadData(const Data &data, double custom_coef, const BotParams ¶ms[]); public: static void OnTick(); static double OnTester(); static int OnTesterInit(); static void OnTesterDeinit(); static void SetUploadingFileName(string name); static void SetCallback(TCallback callback, ENUM_CALLBACK_TYPE type); static void SetCustomCoefCallback(TCustomFilter custom_filter_callback); static void SetOnTesterInit(TOnTesterInit on_tester_init_callback); static void AddComission(string symbol,double comission,double shift); static double GetComission(string symbol,double price,double volume); static void RemoveComission(string symbol); }; datetime CAutoUploader2::From = 0; datetime CAutoUploader2::Till = 0; TCustomFilter CAutoUploader2:: EmptyCustomCoefCallback; TCallback CAutoUploader2:: EmptyCallback; TOnTesterInit CAutoUploader2:: EmptyOnTesterInit; TCallback CAutoUploader2:: EmptyCallback; CCCM CAutoUploader2::comission_manager; string CAutoUploader2::frame_name = "AutoOptomiserFrame"; long CAutoUploader2::frame_id = 1; string CAutoUploader2::file_name = MQLInfoString(MQL_PROGRAM_NAME)+"_Report.xml";
A nova classe possui apenas os métodos estáticos. Isso evita a necessidade de instanciá-lo, o que simplifica o processo de desenvolvimento do EA, removendo o código desnecessário. Esta classe possui vários campos estáticos, incluindo intervalos de datas semelhante à classe usada anteriormente, para mais detalhes, leia o terceiro artigo), referências de função para testar o seu retorno de conclusão, quadros de otimização e retorno da chegada do novo tick, uma classe de gestão da comissão (para mais detalhes, consulte o artigo 2), nome do quadro e id e o nome do arquivo para baixar os resultados de otimização.
Para conectar o otimizador automático, adicionamos ao EA um link para o arquivo no qual alguns dos retornos já estão definidos. Se o EA usar qualquer um dos retornos de chamada definido neste arquivo, a solução mais fácil será criar uma função com a assinatura do retorno de chamada usado e sua implementação, e então adicioná-la às referências de função para os retornos de chamada usando as funções estáticas especiais.
#ifndef CUSTOM_ON_TESTER double OnTester() { return CAutoUploader2::OnTester(); } #endif #ifndef CUSTOM_ON_TESTER_INIT int OnTesterInit() { return CAutoUploader2::OnTesterInit(); } #endif #ifndef CUSTOM_ON_TESTER_DEINIT void OnTesterDeinit() { CAutoUploader2::OnTesterDeinit(); } #endif #ifndef CUSTOM_ON_TICK void OnTick() { CAutoUploader2::OnTick(); } #endif
Cada um dos retornos de chamada específicos é envolvido em uma condição do pré-processamento, o que permite evitar sua definição neste arquivo, definindo a condição de pré-processamento apropriada. Os detalhes de implementação serão fornecidos em um exemplo adicional.
Se você decidir descrever esses retornos de chamada por conta própria, não se esqueça de chamar os métodos estáticos da classe CAutoUploader2 (como feito neste trecho de código) no início do retorno de chamada definido. Isso é necessário para uma operação correta do mecanismo de geração de relatórios.
Para habilitar um retorno de chamada personalizado para download dos dados (se você não implementou seu próprio retorno de chamada), passe um ponteiro da função que contém a descrição da implementação para o método estático CAutoUploader2::SetCustomCoefCallback. Para gerenciar as comissões, use um dos seguintes métodos.
static void AddComission(string symbol,double comission,double shift); static double GetComission(string symbol,double price,double volume); static void RemoveComission(string symbol);
Isso é tudo sobre a funcionalidade. Agora, vamos ver como funciona.
int CAutoUploader2::OnTesterInit(void) { return on_tester_init(); }
O Expert Advisor chama no retorno de chamada da OnTesterInit o método CAutoUploader2::OnTesterInit (se a otimização foi iniciada), onde ele chama o ponteiro da função passada ou uma função vazia se ela foi substituída por padrão.
void CAutoUploader2::OnTick(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)==1 || MQLInfoInteger(MQL_TESTER)==1) { if(From == 0) From = iTime(_Symbol,PERIOD_M1,0); Till=iTime(_Symbol,PERIOD_M1,0); } on_tick(); }
Então, a cada tick, o tempo real do início da otimização é salvo nas variáveis correspondentes. Então, o EA chama o método on_tick que foi enviado como um retorno de chamada da chegada do novo tick ou um retorno de chamada vazio padrão. O tempo de otimização é salvo apenas se o EA estiver em execução no testador.
double CAutoUploader2::OnTester(void) { double ret = on_tester(); Data data[1]; if(!FillInData(data[0])) return ret; if(MQLInfoInteger(MQL_OPTIMIZATION)==1) { if(!FrameAdd(frame_name, frame_id, ret, data)) Print(GetLastError()); } else if(MQLInfoInteger(MQL_TESTER)==1) { BotParams params[]; UploadData(data[0], ret, params, false); } return ret; }
Quando a operação do testador é concluída, o método estático CAutoUploader2::OnTester é chamado no retorno de chamada da OnTester, onde os quadros são salvos (se for uma otimização), ou os quadros são gravados em um arquivo (se for um teste). Se for um teste, o processo termina na etapa atual e plataforma é encerrada por meio do comando passado no arquivo de configuração. No entanto, se for um processo de otimização, a seguinte etapa final é realizada:
input bool close_terminal_after_finishing_optimisation = false; // MetaTrader Auto Optimiser param (must be false if you run it from terminal) void CAutoUploader2::OnTesterDeinit(void) { ResetLastError(); if(FrameFilter(frame_name,frame_id)) { ulong pass; string name; long id; double coef_value; Data data[]; while(FrameNext(pass,name,id,coef_value,data)) { string parameters_list[]; uint params_count; BotParams params[]; if(FrameInputs(pass,parameters_list,params_count)) { for(uint i=0; i<params_count; i++) { string arr[]; StringSplit(parameters_list[i],'=',arr); BotParams item; item.name = arr[0]; item.value = arr[1]; ADD_TO_ARR(params,item); } } else Print("Can`t get params"); UploadData(data[0], coef_value, params, true); } CheckRetMessage(ReportWriter::WriteReportData(get_path_to_expert(), CharArrayToString(data[0].currency), data[0].balance, data[0].laverage, TerminalInfoString(TERMINAL_COMMONDATA_PATH)+"\\"+file_name)); } else { Print("Can`t select apropriate frames. Error code = " + IntegerToString(GetLastError())); ResetLastError(); } on_tester_deinit(); if(close_terminal_after_finishing_optimisation) { if(!TerminalClose(0)) { Print("==================================="); Print("Can`t close terminal from OnTesterDeinit error number: " + IntegerToString(GetLastError()) + " Close it by hands"); Print("==================================="); } } ExpertRemove(); }
A etapa final de otimização é a chamada do método estático CAutoUploader2::OnTesterDeinit(). Todos os quadros salvos são lidos neste método e o arquivo final com o relatório de otimização é formado. Primeiro, redefinimos o erro anterior e filtramos os quadros por nomes e ids. Então, lemos cada quadro em um loop e obtemos os seus dados salvos que será gravado em um arquivo.
Depois de ler os dados, lemos os parâmetros de entrada do EA para este passo de otimização e adicionamos as informações recebidas à coleção da classe estática no lado C#. Depois de sair do loop, a coleção formada é escrita em um arquivo usando a chamada do método ReportWriter::WriteReportData. Então, é chamado o retorno de chamada personalizado passado ou uma referência vazia padrão. Essa abordagem tem um problema: para que o otimizador automático opere, ele deve ser capaz de reiniciar a plataforma, na qual ela deve primeiro ser encerrada primeiro.
Anteriormente, o a flag do arquivo de configuração era definida como true para resolver esse problema. No entanto, isso não pode ser feito ao trabalhar com quadros, uma vez que seu processamento final começa após a otimização ser interrompida e se a flag necessária do arquivo de configuração for definida como true, então não seremos capazes de processá-los, porque a plataforma será encerrada antes que o método OnTerderDeinit seja concluído. Para resolver o problema, eu adicionei uma variável de entrada que será adicionada ao Expert Advisor junto com o arquivo de inclusão. Esta variável é modificada no otimizador automático e não deve ser modificada manualmente ou no código. Se ela for definida como true, o método de fechamento da plataforma é chamado a partir da MQL5, caso contrário, a plataforma não fecha. Após todas as situações descritas, o EA que processa os quadros, é retirado do gráfico.
O método UploadData atua como um método de adição dos dados à coleção e como um método de download de uma determinada passagem do testador para um arquivo se ele for um teste e não uma otimização.
void CAutoUploader2::UploadData(const Data &data, double custom_coef, const BotParams ¶ms[], bool is_appent_to_collection) { int total = ArraySize(params); for(int i=0; i<total; i++) ReportWriter::AppendBotParam(params[i].name,params[i].value); ReportWriter::AppendMainCoef(custom_coef,data.payoff,data.profitFactor,data.averageProfitFactor, data.recoveryFactor,data.averageRecoveryFactor,data.totalTrades, data.pl,data.dd,data.altmanZScore); ReportWriter::AppendVaR(data.var_90,data.var_95,data.var_99,data.mx,data.std); ReportWriter::AppendMaxPLDD(data.max_profit,data.max_dd, data.totalProfitTrades,data.totalLooseTrades, data.consecutiveWins,data.consequtiveLoose); ReportWriter::AppendDay(MONDAY,data.averagePl_mn,data.averageDd_mn, data.numberProfitTrades_mn,data.numberLooseTrades_mn); ReportWriter::AppendDay(TUESDAY,data.averagePl_tu,data.averageDd_tu, data.numberProfitTrades_tu,data.numberLooseTrades_tu); ReportWriter::AppendDay(WEDNESDAY,data.averagePl_we,data.averageDd_we, data.numberProfitTrades_we,data.numberLooseTrades_we); ReportWriter::AppendDay(THURSDAY,data.averagePl_th,data.averageDd_th, data.numberProfitTrades_th,data.numberLooseTrades_th); ReportWriter::AppendDay(FRIDAY,data.averagePl_fr,data.averageDd_fr, data.numberProfitTrades_fr,data.numberLooseTrades_fr); if(is_appent_to_collection) { ReportWriter::AppendToReportData(_Symbol, data.tf, data.startDT, data.finishDT); return; } CheckRetMessage(ReportWriter::Write(get_path_to_expert(), CharArrayToString(data.currency), data.balance, data.laverage, TerminalInfoString(TERMINAL_COMMONDATA_PATH)+"\\"+file_name, _Symbol, data.tf, data.startDT, data.finishDT)); }
Se a flag is_appent_to_collection for true, o passe é simplesmente adicionado à coleção. Se for false, então carregamos o passe atual para um arquivo. Pode-se ver no código acima que a flag só é igual a true quando lemos os quadros e os adicionamos a uma coleção para o download rápido dos relatórios. Se nós executarmos o Expert Advisor no modo de teste, este método será chamado com o parâmetro 'false', o que significa que o relatório deve ser salvo em um arquivo.
Agora, vamos ver como adicionar um link para baixar os relatórios de otimização usando a nova lógica. Consideramos o arquivo criado anteriormente com um Expert Advisor de teste do quarto artigo. A conexão do novo método (além da referência ao arquivo de inclusão) leva apenas 3 linhas de código, em vez das 16 linhas do exemplo usado no artigo 4. Quanto aos retornos de chamada usados para download dos dados, agora o EA tem a implementação do retorno de chamada da "OnTick" enquanto todos os outros retornos ("OnTester", "OnTesterInit", "OnTesterDeinit") são implementados no arquivo de inclusão.
//+------------------------------------------------------------------+ //| SimpleMA.mq5 | //| Copyright 2019, MetaQuotes Software Corp. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2019, MetaQuotes Software Corp." #property link "https://www.mql5.com" #property version "1.00" #include <Trade/Trade.mqh> #define CUSTOM_ON_TICK // Tell to uploading system that we implement OnTick callback ourself #include <History manager/AutoUpLoader2.mqh> // Include CAutoUploader #define TESTER_ONLY input int ma_fast = 10; // MA fast input int ma_slow = 50; // MA slow input int _sl_ = 20; // SL input int _tp_ = 60; // TP input double _lot_ = 1; // Lot size // Comission and price shift (Article 2) input double _comission_ = 0; // Comission input int _shift_ = 0; // Shift int ma_fast_handle,ma_slow_handle; const double tick_size = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_SIZE); CTrade trade; //+------------------------------------------------------------------+ //| Custom coeffifient`s creator | //+------------------------------------------------------------------+ double CulculateMyCustomCoef() { return 0; } //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ... CAutoUploader2::SetCustomCoefCallback(CulculateMyCustomCoef); CAutoUploader2::AddComission(_Symbol,_comission_,_shift_); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { CAutoUploader2::OnTick(); // If CUSTOM_ON_TICK was defined ... } //+------------------------------------------------------------------+
Em vermelho é exibido a adição da interface de download dos dados usando o novo método. Como você pode ver no exemplo, o retorno de chamada da OnTester ainda está implementado no arquivo de download dos dados. Para permitir o cálculo do coeficiente personalizado, nós passamos para isso o método CulculateMyCustomCoef, que deve conter a lógica personalizada para a implementação deste retorno de chamada. A implementação do retorno de chamada da OnTick permanece no robô. Por isso, a variável CUSTOM_ON_TICK está definida antes da referência ao arquivo no qual o procedimento de download de dados é descrito. Você pode usar o arquivo anexado para estudar a implementação do EA em mais detalhes, bem como compará-la com a implementação padrão e com uma implementação do método de download dos dados anteriores.
Alterações no método de inicialização de otimização e outras melhorias
A nova versão possui uma série de outras melhorias. Um deles é a capacidade de agendar as otimizações em vários ativos.
- Agenda de otimização para a lista de ativos passada
Essa melhoria permite economizar tempo ao realizar as otimizações em vários ativos. As tarefas agendadas serão executadas dia e noite até que a lista especificada termine. Para habilitar esse recurso, eu tive que alterar o processo de inicialização da otimização descrita em artigos anteriores. Anteriormente, após pressionar o botão "Start / Stop", o ViewModel redirecionava instantaneamente a tarefa para o método do modelo de dados, que chamava um ciclo completo, desde o início da otimização até o salvamento dos resultados. Agora, nós chamamos primeiro o método, que percorre a lista de parâmetros passada e, em seguida, inicia as otimizações e as salva no diretório apropriado.
public async void StartOptimisation(OptimiserInputData optimiserInputData, bool isAppend, string dirPrefix, List<string> assets) { if (assets.Count == 0) { ThrowException("Fill in asset name"); OnPropertyChanged("ResumeEnablingTogle"); return; } await Task.Run(() => { try { if (optimiserInputData.OptimisationMode == ENUM_OptimisationMode.Disabled && assets.Count > 1) { throw new Exception("For test there must be selected only one asset"); } StopOptimisationTougle = false; bool doWhile() { if (assets.Count == 0 || StopOptimisationTougle) return false; optimiserInputData.Symb = assets.First(); LoadingOptimisationTougle = assets.Count == 1; assets.Remove(assets.First()); return true; } while (doWhile()) { var data = optimiserInputData; // Copy input data StartOptimisation(data, isAppend, dirPrefix); } } catch (Exception e) { LoadingOptimisationTougle = true; OnPropertyChanged("ResumeEnablingTogle");м ThrowException?.Invoke(e.Message); } }); }
Depois de passar a lista de ativos e verificar sua integridade, movemos para a parte assíncrona deste método. Em um loop, chamamos o método de lançamento das otimizações consideradas anteriormente, que agora é síncrono e, portanto, aguarda a conclusão do processo de otimização. Visto que a estrutura passada para os parâmetros de otimização pode mudar na classe do otimizador, copiamos antes de iniciar cada nova otimização e alimentamos os dados iniciais para cada nova otimização.
A condição de continuação, bem como a de substituição do ativo no qual a otimização será realizada, é executada pela função aninhada doWhile(). No corpo da função, verificamos a condição de saída do loop, atribuímos o valor do próximo ativo, e em seguida, excluímos o último ativo atribuído da lista. Assim, a cada nova iteração do loop, nós indicamos primeiro o ativo, no qual a otimização será realizada e, em seguida, executamos a otimização, e assim por diante até que a lista esteja vazia, ou até que um sinal de conclusão da otimização é enviado. Em implementações anteriores, o processo de otimização poderia ser encerrado urgentemente, simplesmente concluindo o processo em execução. No entanto, na implementação atual, o processo mudaria para a próxima iteração em vez de parar. É por isso que os ajustes apropriados foram feitos no método de término da otimização.
/// <summary> /// Complete optimization from outside the optimizer /// </summary> public void StopOptimisation() { StopOptimisationTougle = true; LoadingOptimisationTougle = true; Optimiser.Stop(); var processes = System.Diagnostics.Process.GetProcesses().Where(x => x.ProcessName == "metatester64"); foreach (var item in processes) item.Kill(); } bool StopOptimisationTougle = false;
Agora, ao parar a otimização, nós simplesmente alteramos esta flag para true. O loop de ativos vê a flag e sai das iterações em execução. Além disso, depois de redirecionar o processo de parada da otimização para a classe do otimizador, nós devemos encerrar os processos do testador em execução, porque quando a plataforma é fechada com urgência, esses processos geralmente congelam e permanecem em execução até que o computador seja reiniciado.
Para isso, é usado o sinalizador adicional LoadingOptimisationTougle. Esta flag indica se a otimização realizada atualmente deve ser carregada na interface gráfica, como foi implementada anteriormente. Para acelerar o processo, esta flag é sempre "false" até que o processo seja interrompido forçadamente ou até que o último item da lista de ativos passada seja alcançado. E só depois disso, ao sair do processo de otimização, os dados serão carregados na interface gráfica.
- Salvar um arquivo de configuração com os parâmetros de inicialização da otimização e limpar a memória das otimizações carregadas
A capacidade de anexar novos passes aos anteriores durante a otimização repetida, em vez de realizá-los de novo, está disponível desde a primeira versão do programa. No entanto, para garantir uma imagem uniforme, novas otimizações devem ser lançadas com os mesmos parâmetros. Para isso, eu introduzi a opção de salvar os parâmetros das otimizações realizadas anteriormente no mesmo diretório onde os resultados da otimização são armazenados. Um botão separado foi adicionado à GUI, permitindo carregar essas configurações para uma nova configuração.
![]()
O seguinte método da classe AutoOptimiserVM é acionado após um clique no botão:
private void SetBotParams() { if (string.IsNullOrEmpty(SelectedOptimisation)) return; try { Status = "Filling bot params"; OnPropertyChanged("Status"); Progress = 100; OnPropertyChanged("Progress"); var botParams = model.GetBotParamsFromOptimisationPass(OptimiserSettings.First(x => x.Name == "Available experts").SelectedParam, SelectedOptimisation); for (int i = 0; i < BotParams.Count; i++) { if (!botParams.Any(x => x.Variable == BotParams[i].Vriable)) continue; BotParams[i] = new BotParamsData(botParams.First(x => x.Variable == BotParams[i].Vriable)); } } catch (Exception e) { MessageBox.Show(e.Message); } Status = null; OnPropertyChanged("Status"); Progress = 0; OnPropertyChanged("Progress") }
Primeiro, nós solicitamos a lista de parâmetros do EA do modelo de dados. Então, iteramos através de todos os parâmetros carregados para a GUI e verificamos se o parâmetro está disponível na lista de parâmetros recebidos. Se o parâmetro foi encontrado, ele é substituído por um novo valor. O método do modelo de dados retorna os parâmetros corretos do arquivo de configurações, lê ele de um diretório selecionado na caixa de combinação onde o arquivo está armazenado com o nome de "OptimisationSettings.set". Este arquivo é gerado pelo método que inicia a otimização, após a conclusão deste processo.
- Removendo os passes de otimização carregadas anteriormente da memória
Uma opção também foi adicionada para limpar os passes de otimização após carregá-las. Eles ocupam muito espaço de RAM. Se o computador tiver pouca RAM, vários testes anteriores e históricos podem torná-lo mais lento. Para minimizar o uso de recursos, foi removido a duplicação dos dados nos passes de otimização do histórico e de forward. Agora eles são armazenados apenas no modelo de dados. Um botão especial "Clear loaded results" foi adicionado à GUI, que se refere ao método ClearResults do modelo de dados.
void ClearOptimisationFields() { if (HistoryOptimisations.Count > 0) dispatcher.Invoke(() => HistoryOptimisations.Clear()); if (ForwardOptimisations.Count > 0) dispatcher.Invoke(() => ForwardOptimisations.Clear()); if (AllOptimisationResults.AllOptimisationResults.Count > 0) { AllOptimisationResults.AllOptimisationResults.Clear(); AllOptimisationResults = new ReportData { AllOptimisationResults = new Dictionary<DateBorders, List<OptimisationResult>>() }; } GC.Collect(); } public void ClearResults() { ClearOptimisationFields(); OnPropertyChanged("AllOptimisationResults"); OnPropertyChanged("ClearResults"); }
O método mencionado refere-se ao método privado ClearOptimisationFields que esvazia coleções de relatórios de otimização na classe AutoOptimiserM. No entanto, como usamos a C#, em que a memória é gerenciada não manualmente, mas automaticamente, também é necessário limpar a memória de todos os objetos excluídos para aplicar a limpeza do array e a exclusão de dados da memória. Isso pode ser feito chamando o método estático Collect da classe Garbage Collector (GC). Após as ações realizadas, os objetos previamente existentes são apagados da RAM.
- Geração de um arquivo *.set do passe desejado.
Depois de visualizar os passes de otimização geradas, nós precisamos gerar um arquivo *set para inserir os parâmetros desejados em um Expert Advisor. Anteriormente, nós tínhamos que inserir os parâmetros encontrados manualmente ou formar um arquivo do testador, clicando duas vezes na linha de otimização selecionada para iniciar um teste.
A tabela acima do botão contém uma lista de valores-chave que armazena os parâmetros de otimização. Ao clicar no botão, chamamos um método do modelo de dados, para o qual a lista da tabela acima é passada.
public void SaveBotParams(IEnumerable<KeyValuePair<string, string>> data, string path) { SetFileManager setFileManager = new SetFileManager(path, true) { Params = data.Select(x => new ParamsItem { Variable = x.Key, Value = x.Value }).ToList() }; setFileManager.SaveParams(); }
Este método recebe o caminho para o arquivo criado, converte a o array de valor-chave em uma estrutura com os parâmetros do EA e armazena ele no caminho especificado. O caminho para o arquivo é definido por meio da interface de armazenamento do arquivo padrão do ViewModel.
Conclusão
O artigo saiu muito mais tarde do que eu planejei, mas espero que seja interessante e útil para todos que acompanharam este projeto. Eu vou continuar a desenvolvê-lo e implementar novas ideias de melhoria. Uma delas é adicionar a filtragem automática de otimizações, para implementar a busca dos melhores parâmetros com base nos resultados retrospectivos das otimizações walk forward, bem como permitir a coleta de um portfólio de otimizações realizadas. Caros leitores, se este projeto é do seu interesse, eu continuarei com o seu desenvolvimento. O projeto em seu estado atual está pronto para uso, permitindo carregar o processador em 100% e otimizar o uso de vários ativos ao mesmo tempo, usando otimizações do histórico regular e walk forward.
O anexo inclui o projeto do otimizador automático completo com um Expert Advisor de teste considerado no artigo 4. Se você quiser usar o EA, compile o projeto do otimizador automático e o robô de teste. Em seguida, copie o ReportManager.dll (descrito no primeiro artigo) para o diretório MQL5/Libraries, e você poderá começar a testar o EA. Consulte os artigos 3 e 4 desta série para obter os detalhes sobre como conectar o otimizador automático aos seus Expert Advisors.
Aqui está a descrição do processo de compilação para todos aqueles que não trabalham com o Visual Studio. O projeto pode ser compilado no VisualStudio de diferentes maneiras, eis três deles:
- O mais fácil é pressionar CTRL + SHIFT + B.
- Um método mais visual é clicar no array verde no editor — isso iniciará o aplicativo no modo de depuração de código e executará a compilação (se o modo de compilação de depuração estiver selecionado).
- Outra opção é usar o comando Build do menu.
O programa compilado dependerá da pasta MetaTrader Auto Optimizer/bin/Debug (ou MetaTrader Auto Optimizer/bin/Release — dependendo do método de compilação selecionado).
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/7891
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Abordagem de força bruta para encontrar padrões
Abordagem de força bruta para encontrar padrões
 Uma abordagem científica para o desenvolvimento de algoritmos de negociação
Uma abordagem científica para o desenvolvimento de algoritmos de negociação
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
O que devo fazer para resolver isso?
Atenciosamente
Olá, Andrei. Decidi voltar à busca do graal e fiquei feliz ao encontrar seu otimizador funcionando e finalizado. As soluções criadas inteiramente com base no Mql5 acabaram exigindo muito do suporte do autor e saíram dos trilhos. E seu otimizador funcionará enquanto houver C# e a janela do testador de estratégias no MT5 permanecerá inalterada. É estranho que não exista uma demanda em massa para aotimização back-forward. De qualquer forma, muito obrigado por seu trabalho árduo!
O testador já está funcionando, mas gostaria de expressar alguns desejos. Talvez até mesmo outra pessoa continue a refinar o projeto e a colocá-lo na base de código.
1. Gostaria de ter dicas de ferramentas com explicações no cabeçalho das tabelas com resultados. O que são: var 90, var 95, mx....
2. Os valores de PL e DD nas janelas 1 e 3 da guia "resultados" não correspondem. Bem, e as unidades de medida?
3. A função OnTester() não é compilada porque está definida nos arquivos do otimizador, portanto, os critérios totalmente personalizados são cancelados. Entre os critérios padrão, o programa permite que você digite qualquer conjunto.
4. Como podemos fazer sem gráficos de equilíbrio? Você pode colar todos os avançados e executá-los em um testador, por exemplo, ou melhor, um gráfico aproximado na janela do otimizador de uma só vez para avaliar se o EA vale a pena ser desperdiçado por mais tempo. No mínimo, o otimizador deve exibir o resultado final de todas as passagens avançadas.
5. O cálculo do lucro em pips é necessário. Especialmente considerando como o testador trabalha com criptografia. Adicione uma caixa de seleção.
6. E, por fim, gostaria de sonhar com a possibilidade de adicionar vários TFs. Semelhante à possibilidade de adicionar vários ativos.
Bem, e muito, muito dinheiro....
O testador já está funcionando, mas vou expressar alguns desejos. Talvez até mesmo outra pessoa continue a refinar o projeto e a colocá-lo na base de código.
1. Gostaria de ter dicas de ferramentas com explicações no cabeçalho das tabelas com resultados. O que são: var 90, var 95, mx....
2. Os valores de PL e DD nas janelas 1 e 3 da guia "resultados" não correspondem. Bem, e as unidades de medida?
3. A função OnTester() não é compilada porque está definida nos arquivos do otimizador, portanto, os critérios totalmente personalizados são cancelados. Entre os critérios padrão, o programa permite que você digite qualquer conjunto.
4. Como podemos fazer sem gráficos de equilíbrio? Você pode colar todos os encaminhamentos e executá-los em um testador, por exemplo, ou, melhor ainda, apresentar um gráfico aproximado na janela do otimizador de uma só vez para avaliar se o consultor vale a pena perder mais tempo. No mínimo, o otimizador deve exibir o resultado final de todas as passagens a termo.
5. O cálculo do lucro em pips é necessário. Especialmente considerando como o testador trabalha com criptografia. Adicione uma caixa de seleção.
6. E, por fim, gostaria de sonhar com a possibilidade de adicionar vários TFs. Semelhante à possibilidade de adicionar vários ativos.
Bem, e muito, muito dinheiro....
Obrigado por seu feedback. Não apoio este projeto, mas sim, ele deve funcionar por muito tempo.
Se alguém quiser refinar e ajustar o projeto, faça-o.
https://github.com/AndreyKrivcov/MetaTrader-Auto-Optimiser.
Se eu compilar os arquivos .mq5 que você enviou do seu consultor especialista chamado "New uploading variant" (Nova variante de carregamento), ele mostrará vários erros, como você pode ver na imagem abaixo. Acabei de baixar a última versão publicada (8º artigo).
O que devo fazer para resolver isso?
Atenciosamente
Então. Faça o download do arquivo anexado ao artigo e veja duas pastas nele:
Então. Baixamos o arquivo anexado ao artigo e vemos duas pastas nele:
Mova a pasta MetaTrader-Auto-Optimiser do arquivo para o diretório raiz onde o MetaTrader 5 está localizado:
Mova a pasta MetaTrader-Auto-Optimiser do arquivo para o diretório raiz onde o MetaTrader 5 está localizado:
Há duas pastas na pasta MQL5 no arquivo - copie-as para a pasta MQL5 de seu terminal. Assim, a pasta Test Expert será copiada para a pasta MQL5, e duas pastas: CustomGeneric e History manager serão copiadas para a pasta MQL5.
Compile o arquivo SimpleMA.mq5 na pasta Experts\Test Expert\New uploading variant:
Há duas pastas no arquivo, na pasta MQL5 - copie-as para a pasta MQL5 de seu terminal. Da mesma forma, a pasta Test Expert será copiada para a pasta MQL5\Experts, e duas pastas serão copiadas para a pasta MQL\Include: CustomGeneric e History manager.
Compile o arquivo SimpleMA.mq5 localizado na pasta Experts\Test Expert\New uploading variant:
Recebemos 100 erros e 60 avisos:
Recebemos 100 erros e 60 avisos:
Vamos passar para o primeiro erro e ver que não se trata de uma importação fechada:
Vamos passar para o primeiro erro e ver que não se trata de uma importação fechada:
Clique duas vezes na inscrição sobre o erro e acesse o arquivo UploadersEntities.mqh na linha com o erro:
Clique duas vezes na inscrição sobre o erro e acesse o arquivo UploadersEntities.mqh na linha com o erro:
O que estamos vendo? E vemos que a importação realmente não foi fechada. Vamos corrigir isso:
O que estamos vendo? E vemos que a importação realmente não foi fechada. Vamos consertar:
Compilar novamente. O erro de importação desapareceu, mas agora o compilador não vê as funções e os métodos do arquivo importado:
Vamos compilar novamente. O erro de importação desapareceu, mas agora o compilador não vê as funções e os métodos do arquivo importado:
Lembre-se de que estamos importando métodos e classes de uma dll de terceiros. Ela deve estar localizada na pasta MQL5/Libraries.
Abra a pasta MetaTrader-Auto-Optimiser, copiada do arquivo para o diretório raiz do MetaTrader 5. Nela, vemos o arquivo Metatrader Auto Optimiser.sln:
Lembramos que estamos importando métodos e classes de uma dll de terceiros. E ela deve estar na pasta MQL5\Libraries.
Abra a pasta MetaTrader-Auto-Optimiser copiada do arquivo para o diretório raiz do MetaTrader 5. Nela, vemos o arquivo Metatrader Auto Optimiser.sln:
Clique duas vezes nesse arquivo para abrir o projeto no MS Visual Studio.
Ao abrir o projeto, vemos que ele é para uma plataforma desatualizada:
Clique duas vezes nesse arquivo para abrir o projeto no MS Visual Studio.
Ao abrir o projeto, vemos que ele é para uma plataforma desatualizada:
Deixe a caixa de seleção marcada para "Upgrade target to .NET Framefork 4.8 platform" e clique no botão "Continue".
Depois, novamente para o segundo projeto:
Deixe marcada a caixa de seleção "Upgrade target to .NET Framefork 4.8 platform" (Atualizar destino para a plataforma .NET Framefork 4.8) e clique no botão "Continue" (Continuar).
Depois, novamente para o segundo projeto:
Depois de carregar os projetos, selecione "Release" (Liberar) e Any CPU:
Depois de carregar os projetos, selecione "Release" (Liberar) e Any CPU (Qualquer CPU):
E pressione Ctrl+F5 para compilar e construir os projetos.
Depois de compilar o projeto no MS Visual Studio, vá para o diretório raiz do terminal e, nele, para a pasta \MetaTrader-Auto-Optimiser\ReportManager\bin\Release. Copie o arquivo da biblioteca ReportManager.dll construída a partir dessa pasta para o diretório MQL5/Libraries do terminal.
Agora compile novamente o arquivo SimpleMA.mq5 da pasta MQL5\Experts\Test Expert\New uploading variant.
Pronto, não há erros:
E pressione Ctrl+F5 para compilar e construir projetos.
Depois de compilar o projeto no MS Visual Studio, vá para o diretório raiz do terminal e, nele, para a pasta \MetaTrader-Auto-Optimiser\ReportManager\bin\Release. Copie o arquivo de biblioteca compilado ReportManager.dll dessa pasta para o diretório MQL5\Libraries do terminal.
Agora vamos compilar o arquivo SimpleMA.mq5 da pasta MQL5\Experts\Test Expert\New uploading variant novamente.
Pronto, sem erros:
Aproveite
Portanto. Faça o download do arquivo anexado ao artigo e veja duas pastas nele:
Então. Baixamos o arquivo anexado ao artigo e vemos duas pastas nele:
Transfira a pasta MetaTrader-Auto-Optimiser do arquivo para o diretório raiz onde o MetaTrader 5 está localizado:
Mova a pasta MetaTrader-Auto-Optimiser do arquivo para o diretório raiz onde o MetaTrader 5 está localizado:
Há duas pastas na pasta MQL5 no arquivo - copie-as para a pasta MQL5 de seu terminal. Assim, a pasta Test Expert será copiada para a pasta MQL5, e duas pastas: CustomGeneric e History manager serão copiadas para a pasta MQL5.
Compile o arquivo SimpleMA.mq5 localizado na pasta Experts\Test Expert\New uploading variant:
Há duas pastas no arquivo, na pasta MQL5 - copie-as para a pasta MQL5 de seu terminal. Da mesma forma, a pasta Test Expert será copiada para a pasta MQL5\Experts, e duas pastas serão copiadas para a pasta MQL\Include: CustomGeneric e History manager.
Compile o arquivo SimpleMA.mq5 localizado na pasta Experts\Test Expert\New uploading variant:
Recebemos 100 erros e 60 avisos:
Recebemos 100 erros e 60 avisos:
Vá até o primeiro erro e veja que não se trata de uma importação fechada:
Vamos passar para o primeiro erro e ver que não se trata de uma importação fechada:
Obrigado, atualizei as fontes anexadas ao artigo