
Redes neuronales en el trading: Generalización de series temporales sin vinculación a datos (Final)

Introducción
Los mercados financieros son un organismo vivo. Su pulso está determinado por millones de transacciones, cientos de informes económicos y un flujo continuo de noticias. En semejante entorno, los beneficios los obtienen aquellos que no solo pueden reaccionar rápidamente, sino también anticipar los puntos de cambio de tendencia. Este es precisamente el motivo por el que se desarrolló Mamba4Cast: un framework de pronóstico de series temporales inspirado en los últimos avances en arquitectura de redes neuronales y adaptado a las particularidades de las secuencias de alta frecuencia.
Así, hemos llegado a la fase final de nuestra introducción a este framework. En primer lugar, analizamos el framework teórico y el esquema general para el procesamiento de características. En la segunda parte profundizamos en la mecánica. Ahora pondremos todo junto para demostrar que el modelo no solo existe en el papel, sino que también funciona en un entorno de mercado real.
El framework en sí está estructurado como una cadena de módulos, cada uno de los cuales realiza su propia función especializada. El primer bloque es responsable de la extracción de características. Aquí el modelo toma datos sin procesar: precio de apertura, precio de cierre, high/low, volúmenes. Todos ellos pasan a través de una capa compacta que resalta los patrones locales. Podríamos decir que es como el ojo entrenado de un tráder detectando patrones en el caos de un gráfico.
Luego llega el turno de las capas convolucionales. Estos bloques actúan como filtros de mercado, extrayendo señales estables y cancelando el ruido. Asimismo, capturan y procesan picos de volatilidad, tendencias que se desvanecen y fases de consolidación emergentes. En este caso se usa una arquitectura multiventana, donde cada convolución está orientada hacia diferentes horizontes. De esta forma, el framework aprende a ver simultáneamente tanto las fluctuaciones inmediatas como los ciclos oscilatorios más largos.
El módulo clave, el SSM (State Space Model), contiene la capacidad de almacenar memoria a largo plazo. Y esto resulta especialmente importante en los datos financieros, donde los patrones a menudo no surgen de inmediato, sino en el transcurso de docenas de velas. Por ejemplo, una serie de rupturas falsas puede terminar con un impulso poderoso, y el modelo deberá estar preparado para ese escenario. Precisamente el SSM nos permite recordar el contexto y efectuar pronósticos informados incluso en condiciones de incertidumbre del mercado.
Lo que hace que Mamba4Cast sea particularmente valioso es su mecanismo de pronóstico para el horizonte de planificación completo. Y esto se corresponde con las tareas reales de los tráderes. Este enfoque se puede comparar con el trabajo de un conductor: mira delante del coche, pero también mantiene la vista en la distancia, leyendo la dinámica del tráfico. Este modo híbrido posibilita una política de conducta más estable y completa.
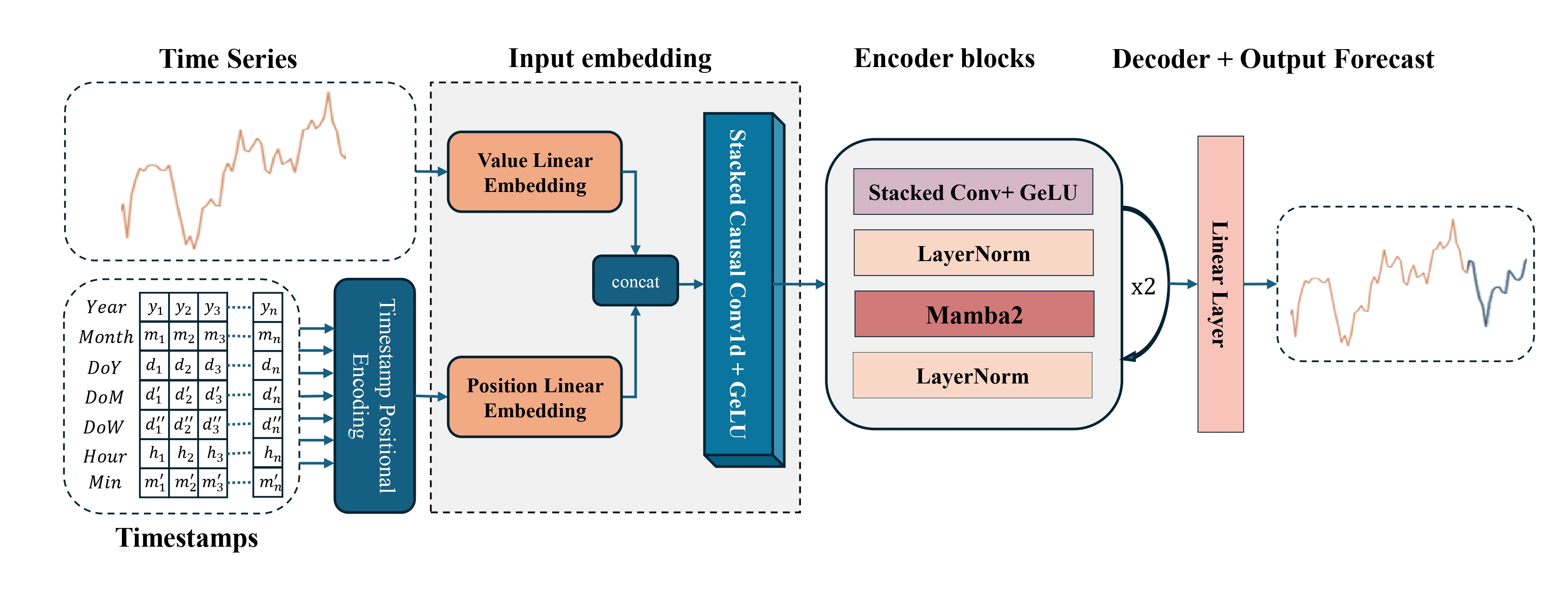
En este artículo, veremos la forma final del modelo: su arquitectura, los procesos de entrenamiento y los resultados del mundo real. Además, mostraremos cómo se combinan la teoría y la práctica, y cómo un modelo abstracto se transforma en una herramienta de trabajo para el análisis de mercados.
Arquitectura de los modelos
Hoy comenzaremos construyendo la arquitectura de un modelo entrenable: un agente de negociación completamente desarrollado capaz de tomar decisiones comerciales y realizar transacciones en tiempo real. Así como un tráder analiza cuidadosamente la situación actual del mercado, evalúa el comportamiento del precio, los volúmenes y el sentimiento del mercado, y solo entonces decide entrar en una posición, nuestro Agente también tendrá que ver y comprender el mercado, en lugar de seguir ciegamente las señales. Por ello, no nos limitaremos a predecir el próximo precio, nuestro objetivo es mucho más profundo: crear un modelo que pueda reconocer patrones de comportamiento del mercado, responder a condiciones en cambio constante y rápido y adaptarse a diferentes fases del ciclo del mercado.
En este contexto, el framework Mamba4Cast se implementa como uno de los elementos clave del sistema general: el Codificador del estado del entorno. Aquí es donde comienza a formarse la percepción del mercado sobre el modelo, convirtiendo un conjunto de números en una imagen significativa de lo que está ocurriendo. El Codificador actuará como el ojo comercial del Agente, entrenado para reconocer movimientos significativos, patrones ocultos y posibles puntos de entrada mucho antes de que se confirmen en el gráfico.
En este artículo seguimos adhiriéndonos a la lógica del framework de aprendizaje Actor-Director-Crítico. El sistema entrenado incluye cuatro modelos clave, cada uno responsable de su propio aspecto de la toma de decisiones comerciales:
- El Codificador del entorno representa los ojos del agente, generando incorporaciones del estado del mercado;
- El Actor (Actor) es un modelo que sugiere acciones comerciales específicas según la incorporación recibida;
- El Director (Director) es un modelo que clasifica las acciones propuestas por el Actor como buenas y malas, guiando el proceso de aprendizaje y previniendo decisiones erróneas;
- El Crítico (Critic) evalúa el valor de las acciones del Actor en el contexto del estado del mercado y genera una señal de retroalimentación para la optimización de la estrategia.
La arquitectura de todos los modelos está definida por el método CreateDescriptions, cuyos parámetros se transmiten como cuatro punteros a arrays dinámicos. Precisamente en estos arrays se escriben secuencialmente las descripciones de las capas y parámetros de cada uno de los modelos listados, desde el Codificador hasta el Crítico, lo que permite una gestión flexible de la estructura y una fácil adaptación del framework a nuevas exigencias.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&actor, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método CreateDescriptions, primero se verifica la validez de los punteros obtenidos a los cuatro arrays dinámicos. Si es necesario, se crearán nuevos objetos: esto garantiza que la descripción de la arquitectura se grabe posteriormente con exactitud sin el riesgo de conflictos de memoria.
A continuación procederemos a describir la arquitectura del Codificador de estado del entorno. Ahí se utiliza una capa completamente conectada de tamaño suficiente como objeto para obtener los datos de origen. Luego transmitimos los datos de origen (sin preprocesamiento) directamente desde el terminal: precios de apertura/cierre, high/low, volúmenes, así como las lecturas de los indicadores técnicos.
Como estos datos tienen diferentes características estadísticas y escalas, para estabilizar el proceso de entrenamiento del modelo, se requiere la alineación de la distribución. Y aquí es donde la capa de normalización de lotes viene al rescate. Esta transforma los vectores de entrada para que cada característica tenga una media cercana a cero y una varianza cercana a "1", lo cual promueve la convergencia acelerada y mejora la estabilidad del entrenamiento. En lugar de la implementación clásica, usamos una versión modificada: una capa de normalización con ruido añadido. Esta solución ayuda a mejorar la capacidad de generalización del modelo aumentando artificialmente la diversidad de los datos de entrenamiento.
A la salida de dicha conexión, el Codificador recibe características unificadas listas para su posterior procesamiento.//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, generamos las incorporaciones de pasos temporales utilizando el módulo CMamba4CastEmbedding. Precisamente aquí los vectores de características se enriquecen con armónicos de dos intervalos temporales clave: H1 (horario) y D1 (diario). Al agregar componentes de seno y coseno, el modelo obtiene información sobre las fluctuaciones horarias típicas y los ritmos diarios recurrentes. Esto permite al agente considerar los ciclos típicos del mercado: calentamientos matinales, tendencias diurnas y fases de calma vespertinas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = BarDescr; int prev_out = descr.window_out = NSkills; { int temp[] = {PeriodSeconds(PERIOD_H1), PeriodSeconds(PERIOD_D1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
El uso de un bloque de convolución de ventana múltiple con tres ventanas de convolución hará que las incorporaciones sean más ricas. Debemos señalar que la convolución no se realiza a lo largo del eje del tiempo, sino horizontalmente, dentro de una barra donde se analizan las relaciones entre las características.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.window_out * descr.windows.Size());
En la etapa final de codificación de la señal original, añadimos una capa de normalización. Su propósito es eliminar sesgos en la distribución de características, haciendo que los datos analizados sean más homogéneos y garantizando el funcionamiento estable del modelo durante el proceso de entrenamiento. Este paso ayuda a evitar cambios de gradiente y acelera la convergencia sin pérdida de calidad.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Luego procederemos directamente a la construcción de la arquitectura del codificador. Y aquí planeamos trabajar en el framework de secuencias temporales unitarias de características individuales. Por consiguiente, primero realizaremos una transposición de nuestro tensor de características.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; prev_out = descr.count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Aquí vale la pena señalar que nos encontramos con señales muy diferentes a las que recibíamos anteriormente desde el terminal. En esta etapa, hemos formado características enriquecidas completamente diferentes, cada una de las cuales representa una sección específica de la descripción de la barra recibida previamente desde el terminal.
El bloque del Codificador Mamba4Cast consta de una pila convolucional y un módulo SSM. Entre los módulos se proporciona una capa de normalización para alinear las características. En la pila de convolución, utilizamos módulos convolucionales de ventana múltiple. Aquí, cada filtro se centra en su propia ventana temporal y resalta los patrones de mercado correspondientes. Para conservar la dimensionalidad de los datos, se utiliza una capa de max pooling después de cada módulo convolucional de ventana múltiple que selecciona el valor de filtro máximo en cada ventana, reduciendo así las dimensiones espaciales sin cambiar la profundidad de las características.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; int filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
En SSM, hemos abandonado el Mamba2 original propuesto por los autores del framework Mamba4Cast y hemos elegido el módulo Chimera, que posibilita el análisis de datos en un plano bidimensional y nos permite considerar las dependencias cruzadas entre los componentes temporales y espaciales.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronChimera; //--- Window { int temp[] = {prev_out, prev_out/2}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units { int temp[] = {prev_count, prev_count*2}; //In, Out if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.windows[1]; prev_count=descr.units[1]; //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
El módulo se completará con una capa de normalización por lotes. Ya hemos discutido antes las ventajas de este enfoque.
Nuestra arquitectura de codificador presenta dos bloques secuenciales, cada uno de los cuales consta de una pila convolucional de ventana múltiple, una capa de max pooling y un módulo Chimera SSM, que posibilita enriquecimiento de características paso a paso y preservación del contexto.
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronChimera; //--- Window { int temp[] = {prev_out, prev_out/2}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units { int temp[] = {prev_count, prev_count*2}; //In, Out if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.windows[1]; prev_count=descr.units[1]; //--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Como decodificador utilizaremos dos capas convolucionales consecutivas para la predicción independiente de secuencias temporales unitarias a lo largo de todo el horizonte de planificación. Entre ellas instalaremos SoftPlus, que ofrece la no linealidad necesaria. En la salida del decodificador se usa la tangente hiperbólica (tanh), porque su rango de valores coincide con la escala de los datos normalizados, lo que ayuda a mantener la consistencia entre la entrada y la salida del modelo.
//--- layer 20 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = 4 * NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 21 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Sin embargo, aquí merece la pena recordar que para pasar a trabajar al modo de secuencia temporal unitaria, primero debemos realizar una transposición del tensor de las características analizadas. Por consiguiente, antes de pasar los resultados al decodificador, deberemos restaurarlos a su forma original mediante transposición inversa.
//--- layer 22 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; prev_out = descr.count; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
El siguiente paso para restaurar la estructura de datos consiste en reducir la dimensionalidad incrementada durante la formación de incorporaciones. Esto es necesario para llevar el tensor de resultados a una forma compatible con los datos de origen.
//--- layer 23 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = BarDescr; descr.layers = 1; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
La etapa final de la operación del codificador del estado de la cuenta será la operación de normalización inversa. En este paso, los valores obtenidos tras todas las transformaciones se devuelven a la escala de los datos de origen, lo que permite interpretar correctamente los resultados del modelo.
//--- layer 24 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación pasaremos a la descripción de la arquitectura del Actor. Su tarea principal consiste en evaluar el estado actual de la cuenta y las posiciones abiertas en el contexto del estado analizado del entorno del mercado. Usando como base la información recibida, el Actor toma una decisión comercial: una operación que tiene el potencial de brindar máxima rentabilidad con un riesgo mínimo.
En este contexto, al Actor se le proporciona como entrada un tensor que representa el estado actual de la cuenta. Este tensor contiene información agregada sobre el saldo, los volúmenes de las posiciones abiertas, la dirección de la negociación y otros parámetros clave que reflejan la condición financiera del agente comercial.
CLayerDescription *latent = encoder.At(LatentLayer-1); //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los datos obtenidos se procesan usando una capa de normalización por lotes que estabiliza la distribución de características y acelera el proceso de entrenamiento del modelo.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Luego se aplica una capa de atención cruzada para comparar el estado de la cuenta actual con la situación del mercado. En este caso se usa como contexto la representación latente del entorno previamente formada por el Codificador.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {AccountDescr, // Inputs window latent.windows[1] // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {1, // Inputs units latent.units[1] // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.layers = 2; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
En este experimento, usaremos una pila de dos módulos de atención cruzada dispuestos secuencialmente. Esta configuración permite realizar una comparación más profunda del estado interno de la cuenta con la dinámica del entorno del mercado, mejorando la capacidad del modelo para identificar relaciones de causa y efecto entre la posición actual y las condiciones externas.
Debemos entender que para la capa de atención cruzada, tomamos como contexto no la representación general del estado actual del entorno, sino la representación latente del codificador que se ha formado después de procesar la señal original como incorporaciones de secuencias unitarias individuales de características. En pocas palabras, el codificador (un bloque dentro del modelo del Codificador del estado del entorno) traduce cada característica en su propio vector de sentido compacto, y son estos vectores los que se introducen en el módulo de atención cruzada como contexto.
Piense en el módulo de atención cruzada como si fuera un director. Tiene las melodías de cada instrumento (incorporaciones de funciones) y una partitura del saldo actual de la cuenta. El director determina qué instrumentos deben sonar más fuerte ahora, es decir, qué características son más importantes para tomar una decisión, y enfatiza precisamente estas.
Gracias a ello, el mecanismo de atención cruzada compara patrones ocultos del mercado con la posición actual y selecciona las señales que ayudarán a tomar una decisión comercial efectiva.
Los resultados del análisis de contexto pasan por tres capas completamente conectadas (MLP), cada una de las cuales refina sucesivamente la representación de la acción objetivo. En la salida de la última capa, se forma la decisión comercial: una propuesta específica para abrir, mantener o cerrar una posición, considerando el estado actual de la cuenta y las condiciones del mercado.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los modelos del Director y el Crítico tienen una arquitectura similar: analizan el tensor de acciones propuestas por el Actor en el contexto de la situación actual del mercado. El resultado de estos modelos es la evaluación correspondiente: la aprobación o el rechazo de la acción propuesta desde el punto de vista de la estrategia y el riesgo.
Le proponemos dejar la implementación detallada de las arquitecturas de estos componentes para el estudio por parte del lector. El código fuente completo para la descripción de la arquitectura de todos los modelos entrenados, incluidos el Director y el Crítico, se proporciona en el archivo adjunto.
Entrenamiento de modelos
Tras familiarizarnos con la arquitectura del modelo, pasaremos directamente a la etapa de entrenamiento. Aquí debemos señalar que los autores del framework Mamba4Cast utilizaron series temporales sintéticas para probar y entrenar sus modelos. Esta solución posee una serie de ventajas, especialmente en el contexto del desarrollo y la depuración de arquitecturas de aprendizaje profundo.
En primer lugar, los sintéticos ofrecen control total sobre los parámetros de los datos: podemos preestablecer la amplitud, la frecuencia, las tendencias, la estacionalidad, el nivel de ruido e incluso incluir eventos raros o anómalos. Esto nos permite probar con precisión cómo responde el modelo a diversas características de series temporales e identificar sus debilidades en un entorno estrictamente controlado.
En segundo lugar, las series generadas artificialmente eliminan la influencia de datos sucios o incompletos, lo que resulta especialmente importante en las primeras etapas del entrenamiento. A diferencia de los datos reales del mercado, los sintéticos no contienen omisiones, artefactos de recopilación ni distorsiones que puedan enmascarar errores reales del modelo.
La tercera ventaja es la escalabilidad. La generación de datos sintéticos elimina el costo de recopilar y almacenar datos históricos y permite la creación rápida de muestras de entrenamiento del tamaño necesario para resolver problemas de cualquier complejidad. Esto resulta especialmente relevante al utilizar modelos que requieren muchos recursos y donde se necesita un entorno de aprendizaje rico y equilibrado.
Por último, los sintéticos son una herramienta fiable para las pruebas de estrés. Podemos simular situaciones extremas de mercado sin esperar a que sucedan en la vida real. Estos escenarios nos permiten probar la fiabilidad del modelo ante fluctuaciones inesperadas.
Por otra parte, el mercado real no es un laboratorio estéril, sino un mar tempestuoso donde las reglas a menudo se inventan sobre la marcha. Es por esto que, a pesar de todas las ventajas de los datos sintéticos, entrenar y validar un modelo únicamente con datos sintéticos supone un camino potencialmente peligroso.
En primer lugar, los datos reales del mercado siempre contienen ruido, lagunas, correlaciones sutiles y puntos sucios que no existen en un entorno creado artificialmente. Un modelo que no esté entrenado en dichas características puede perderse en el primer contacto con la realidad, especialmente en activos de baja liquidez o durante periodos de alta volatilidad.
En segundo lugar, el mercado está sujeto al efecto de la sorpresa: noticias, sanciones, fusiones, geopolítica, comportamiento de los principales actores: todo esto influye en los precios, pero es casi imposible modelarlo de forma sintética y fiable. Y aquí resulta especialmente importante que el modelo sea capaz de adaptarse y funcionar en condiciones de información incompleta.
En tercer lugar, los patrones de comportamiento de los participantes del mercado (desde el miedo hasta la codicia) crean dinámicas únicas que son difíciles de recrear usando generadores. Un modelo que no haya detectado dichos patrones corre el riesgo de sobreadaptarse a un entorno limpio y no reconocer señales importantes en el comercio real.
Precisamente por ello el enfoque híbrido se considera el más efectivo: los sintéticos se utilizan en las primeras etapas (para la calibración de la arquitectura, la selección de hiperparámetros y la depuración del entrenamiento), y luego se conectan datos reales para entrenar al modelo a vivir en condiciones de campo, enseñarle a cometer errores, adaptarse y tomar decisiones en un entorno inestable.
Hoy en día no disponemos de un generador completo de secuencias financieras sintéticas. Pero como dice el refrán, si la montaña no viene a Mahoma...
Para la primera etapa del entrenamiento, intentaremos aproximar las propiedades de los sintéticos usando el preprocesamiento de datos históricos reales. Como ya mencionamos antes, las series sintéticas suelen estar libres de artefactos, lagunas y otros ruidos del mercado. Para lograr una pureza similar en datos reales, aplicaremos una media móvil simple con una ventana corta para cada una de las características analizadas. Esto permitirá:
- suavizar anomalías locales y picos bruscos,
- neutralizar el impacto de valores atípicos aislados,
- aumentar la estabilidad del modelo durante la etapa de entrenamiento.
Debemos considerar que hemos elegido deliberadamente una ventana de promedio pequeña para preservar la dinámica y la forma de la señal. Nuestro objetivo no es enderezar todo hasta convertirlo en una línea plana, sino reducir el ruido que podría confundir al modelo. Así, implementamos una lógica similar en el asesor "…\MQL5\Experts\Mamba4Cast\StudyMA.mq5". En este artículo, solo analizaremos el método Train, que implementa el proceso de entrenamiento del modelo.
El algoritmo del método comienza con la creación de un vector de distribución de probabilidades para la selección de trayectorias individuales del búfer de reproducción de experiencias.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
En la etapa inicial, a todas las trayectorias se les asignan probabilidades iguales, lo cual permite un estudio más completo de toda la historia.
A continuación, inicializamos las variables locales que usaremos para almacenar datos temporalmente durante el proceso de entrenamiento del modelo.
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); matrix<float> hstate = matrix<float>::Zeros(1, HistoryBars * BarDescr); bool Stop = false; int average = 5; //--- uint ticks = GetTickCount();
Una vez completado el trabajo preparatorio, pasaremos a la creación de un sistema de ciclos de entrenamiento de modelos. El ciclo externo es responsable de controlar el número total de iteraciones de entrenamiento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if( !cEncoder.Clear() || !cActor.Clear() || !cDirector.Clear() || !cCritic.Clear() ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } result = vector<float>::Zeros(NActions);
Aquí tomaremos una muestra de una trayectoria del búfer de reproducción de experiencias y el estado del inicio del lote de entrenamiento. Luego reiniciaremos inmediatamente el estado interno de todos los modelos, eliminando la influencia de la memoria irrelevante en los datos de la nueva trayectoria. Después de eso, inicializaremos el ciclo de entrenamiento del modelo anidado dentro del paquete.
for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!hstate.Assign(Buffer[tr].States[i].state) || MathAbs(hstate).Sum() == 0 || !hstate.Reshape(HistoryBars, BarDescr)) { iter -= Batch + start - i; break; }
En el cuerpo del ciclo anidado, cargaremos los datos históricos que describen el estado analizado del entorno desde el búfer de reproducción de experiencias y organizaremos un ciclo para suavizarlos utilizando medias móviles.
for(int h = HistoryBars - 1; h > 0; h--) { state = vector<float>::Zeros(BarDescr); for(int a = MathMax(h - average + 1, 0); a <= h; a++) state += hstate.Row(a); if(!hstate.Row(state / MathMin(average, h + 1), h)) { iter -= Batch + start - i; break; } }
Los valores suavizados se transfieren al búfer de datos que describe el estado analizado del entorno.
if(!hstate.Reshape(1, HistoryBars * BarDescr) || !bState.AssignArray(hstate.Row(0))) { iter -= Batch + start - i; break; }
A continuación, debemos recordar que para que el framework Mamba4Cast funcione correctamente, necesitamos marcas temporales para cada barra. Sin embargo, en la estructura del búfer de reproducción de experiencias que creamos anteriormente, solo se almacena una marca temporal para cada estado del entorno, que corresponde a la última barra. Para crear el búfer de marca temporal requerido, realizaremos una pasada inversa a través de los estados del entorno desde el búfer de reproducción de experiencias desde el estado actual hasta una profundidad de análisis determinada y recopilaremos las marcas temporales.
bTime.Clear(); bTime.Reserve(HistoryBars); double time = (double)Buffer[tr].States[i].account[7]; for(int t = i; t >= MathMax(0, i - HistoryBars + 1); t--) if(!bTime.Add((float)(double)Buffer[tr].States[t].account[7])) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(bTime.Total() < HistoryBars) { float period = MathMin(Buffer[tr].States[i + 1].account[7] - Buffer[tr].States[i].account[7], Buffer[tr].States[i + 2].account[7] - Buffer[tr].States[i + 1].account[7]); do { if(!bTime.Add(bTime[-1] - period)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } } while(bTime.Total() < HistoryBars); } if(bTime.GetIndex() >= 0) if(!bTime.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Después transferiremos el algoritmo para llenar el búfer de descripción del estado de la cuenta de programas similares sin cambios.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; float profit = float(bState[0] / _Point * (result[0] - result[3])); bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tras preparar los datos de origen necesarios, realizaremos una pasada directa de todos los modelos. El primero en realizar una pasada directa será el Codificador del estado del entorno. En su trabajo, utiliza datos de descripción del estado del mercado suavizados y un búfer de marca temporal.
//--- Feed Forward if(!cEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación viene el Actor. Este analiza el búfer de estado de la cuenta y el contexto del entorno desde el estado latente del Codificador.
if(!cActor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
El Codificador de estado del entorno se entrena para predecir estados posteriores. Resulta fundamental comprender que no generamos el objetivo manualmente ni aplicamos medias móviles como se hace durante la etapa inicial de preparación de datos. En lugar de ello, simplemente cargamos el estado final del entorno, que ya está en el búfer de reproducción, con un desplazamiento determinado hacia el horizonte de planificación.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; } for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Y tras generar los valores objetivo, podemos ajustar los parámetros del Codificador llamando al método de pasada inversa.
//--- State Encoder Result.AssignArray(fstate); if(!cEncoder.backProp(Result, (CBufferFloat*)NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación, según los datos reales disponibles sobre el movimiento de precios futuro, podemos tomar una decisión comercial "casi perfecta".
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(pos > 0 && tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } } else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(pos > 0 && tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } else { ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); float max_sl = float(MaxSL * Point()); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] / 2 > MathAbs(target[argmin]) && MathAbs(target[argmin]) < max_sl) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin] / 2) && target[argmax] < max_sl) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); } if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(pos > 0 && tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } } else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(pos > 0 && tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } } } }
Cabe señalar que dicha decisión comercial se forma considerando la operación comercial realizada en el paso anterior. El Agente no trabaja con señales de vacío dispares, sino que construye una cadena de acciones. Y cada decisión posterior se basa en la transacción ya cerrada. Gracias a este enfoque no obtenemos un conjunto de órdenes dispares, sino una estrategia completa en la que cada decisión se desprende lógicamente de la anterior. Y son precisamente estas transacciones comerciales casi perfectas las que utilizamos para entrenar al Actor.
//--- Actor Policy bActions.GetData(result); if(!cActor.backProp(GetPointer(bActions), (CNet*)GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Usaremos las mismas operaciones comerciales para entrenar al Crítico. El objetivo es hacer que la función de evaluación de acciones se acerque a la política real del Actor. Después transmitiremos la misma secuencia casi perfecta de operaciones al Crítico y determinaremos la recompensa en función del cambio de precio en la siguiente barra.
//--- Critic if(!cCritic.feedForward(GetPointer(bActions), 1, false, (CNet*)GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } float reward = float((bActions[0] - bActions[3]) * fstate[0, 0] / Point()); Result.Clear(); if(!Result.Add(reward) || !cCritic.backProp(Result, (CNet*)GetPointer(cEncoder), LatentLayer) || !cEncoder.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer, true) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
De esta forma, el Crítico aprenderá a dar una valoración adecuada de las acciones del Actor según el cambio real de los precios, y ayudará a construir una estrategia más precisa y sostenible.
Las cosas resultan un poco diferentes con el entrenamiento del Director. No podemos suministrarle solo casos positivos; de lo contrario, nunca aprenderá a distinguir las malas acciones de las buenas. Por consiguiente, en cada paso seleccionaremos aleatoriamente cómo se verá el ejemplo de entrenamiento:
- Positivo. Introducimos la acción casi perfecta que acabamos de calcular a partir de los datos reales y le asignamos una etiqueta de "1" (éxito).
- Negativo. Formamos un vector de valores aleatorios de la misma dimensionalidad que el espacio de acciones y le asignamos la etiqueta "0" (fallo).
Después de esto, llamamos a los métodos de pasada directa e inversa del Director.
//--- Director Result.Clear(); if((MathRand() / 32767.0) > 0.5) Result.Add(1); else { target = vector<float>::Zeros(NActions); for(int i = 0; i < NActions; i++) target[i] = float(MathRand() / 32767.0); bActions.AssignArray(target); Result.Add(0); } if(!cDirector.feedForward(GetPointer(bActions), 1, false, (CNet*)GetPointer(cEncoder), LatentLayer) || !cDirector.backProp(Result, (CNet*)GetPointer(cEncoder), LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Este enfoque garantiza que el Director aprenda no solo a recompensar las buenas decisiones, sino también a reconocer los defectos de las malas, ayudando al Actor a evitar acciones ineficaces.
Ahora todo lo que queda es informar al usuario sobre el progreso del entrenamiento y pasar a la siguiente iteración del sistema de ciclos.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Encoder", percent, cEncoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, cActor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Director", percent, cDirector.getRecentAverageError()); str += StringFormat("%-16s %6.2f%% -> Error %15.8f\n", "Critic", percent, cCritic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Tras completar el proceso de entrenamiento del modelo, enviamos los resultados obtenidos al registro e inicializamos la finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", cEncoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", cActor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Director", cDirector.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", cCritic.getRecentAverageError()); ExpertRemove(); //--- }
Solo se han realizado cambios menores en los programas de entrenamiento online y offline para modelos en datos históricos reales en el contexto de la creación del búfer de marca temporal, así que no nos detendremos ahora en su estudio detallado. Su código completo se ofrece en el archivo adjunto y podrá examinarlos usted mismo. Allí también se presentan programas de interacción del entorno.
El entrenamiento de nuestro sistema está estructurado en tres etapas, cada una de las cuales prepara gradualmente el modelo para las condiciones reales del mercado.
En primer lugar, realizamos un entrenamiento primario online con datos históricos reales utilizando el método de suavizado descrito anteriormente. Esta etapa se realiza sin actualizar la muestra de entrenamiento. La capa de normalización por lotes con ruido agregado que utilizamos en el Сodificador de estado del entorno nos permitirá crear un aumento suficiente de los datos de origen y expandir significativamente el conjunto de entrenamiento en la representación del modelo.
Imaginemos que cada vela y cada indicador pasa por un filtro de ligera deformación: esto crea muchas variaciones de la misma situación y no permite que el modelo aprenda solo los mismos patrones. Como resultado, el Codificador aprende a ver la esencia del movimiento, a pesar de las más mínimas distorsiones.
La segunda etapa offline utiliza datos históricos sin suavizar: el modelo conoce la verdadera cara del mercado: picos pronunciados, caídas y fluctuaciones ruidosas. Esta transición de un mercado idealizado a datos sin procesar ayuda al Agente a adaptarse a las fluctuaciones reales del mercado, a aprender a mantener la estabilidad del pronóstico y a no alarmarse por anomalías repentinas. Nosotros seguiremos de cerca la dinámica del error de pronóstico y detendremos el entrenamiento tan pronto como la métrica permanezca dentro de un rango estrecho durante varias ejecuciones seguidas: esto será una señal de que el modelo ha interiorizado los datos.
Finalmente, en la tercera etapa, el agente pasa al simulador de estrategias para el aprendizaje online. Aquí observamos el comportamiento de la curva de saldo. Si después de varias pasadas consecutivas el saldo se congela y no muestra el crecimiento esperado, volveremos delicadamente al entrenamiento offline: ajustaremos la política del Actor a una trayectoria casi perfecta y ejecutaremos nuevamente el reentrenamiento.
Este enfoque paso a paso garantizará tanto una alta precisión de los pronósticos como la estabilidad de las decisiones comerciales en cualquier condición del mercado.
Simulación
Hemos realizado un gran trabajo para adaptar e implementar los enfoques propuestos por los autores del framework Mamba4Cast. Ahora ha llegado el momento de la verdad: probar la eficacia de las soluciones implementadas con datos reales.
Para ello, utilizaremos como muestra de entrenamiento cotizaciones de minutos de EURUSD durante todo el año 2024. Para garantizar la integridad del experimento, las pruebas finales se han realizado con datos históricos de enero a marzo de 2025, un periodo no incluido en el entrenamiento. Todos los demás parámetros se han mantenido sin cambios para garantizar que la evaluación de la estrategia sea objetiva y justa.
Ahora le presentamos los resultados de las pruebas.


Debemos reconocer que aquí observamos una frecuencia bastante alta de transacciones comerciales. El tiempo promedio de mantenimiento de la posición es de poco más de 3 minutos. En total, durante el periodo de prueba, el modelo ha completado 2.677 transacciones, 1.240 de las cuales se han cerrado con ganancias. A pesar de que el número de posiciones perdedoras ha sido ligeramente mayor, el modelo ha obtenido beneficios durante el periodo de prueba y observamos un aumento bastante seguro en la línea de saldo. Esto se puede explicar en parte abriendo posiciones con un stop bastante corto y luego manteniéndolo. Esta suposición se confirma por la pequeña diferencia entre la posición promedio y la posición máxima con pérdidas. Al mismo tiempo, la transacción comercial rentable máxima es casi 7 veces mayor que el beneficio promedio de una sola transacción.
Conclusión
Hemos recorrido un largo camino: desde la idea y la arquitectura del framework Mamba4Cast hasta su implementación práctica, su entrenamiento y las pruebas rigurosas con datos históricos reales. Asimismo, hemos enseñado al Codificador a percibir el mercado y al Actor a tomar decisiones considerando los riesgos. Hemos enseñado al Director a filtrar las mejores y peores señales, y al Crítico a evaluar las acciones en función de los resultados reales.
Las pruebas con EURUSD M1 durante enero-marzo de 2025 han mostrado que Mamba4Cast no solo es capaz de pronosticar, sino también de proteger contra el ruido, adaptarse a las sorpresas y mantener la rentabilidad a largo plazo.
Sin embargo, todos los programas presentados en el artículo son de naturaleza demostrativa y sirven como ilustración de las capacidades del framework Mamba4Cast. Antes de aplicar las soluciones propuestas en el trading real, será necesario entrenar los modelos con una muestra de datos verdaderamente representativa y realizar pruebas exhaustivas: esta es la única manera de garantizar la fiabilidad y seguridad de su estrategia comercial.
Enlaces
- Mamba4Cast: Efficient Zero-Shot Time Series Forecasting with State Space Models
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 4 | StudyMA.mq5 | Asesor | Asesor offline para entrenar modelos con datos promediados |
| 5 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 6 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 7 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 8 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 9 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18219
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.


- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso