
Del básico al intermedio: Acceso aleatorio (II)

Introducción
En el artículo anterior, Del básico al intermedio: Acceso aleatorio (I), se dio una breve introducción sobre qué sería un modelo de acceso aleatorio, tanto para la escritura como para la lectura de datos en un archivo. Sin embargo, en aquel artículo, como no queríamos volver el contenido demasiado denso ni presentar demasiada información de una sola vez, no se explicó una cuestión que, si no es la que más confusión y dolores de cabeza genera, es una de las que más afecta a quien está implementando algo que necesita usar archivos en general.
Ahora, presta atención a lo que voy a decir, porque entender esto correctamente es más importante que entender lo que se explicará a lo largo de este artículo. No siempre necesitamos realmente implementar o saber qué tipo de dato se almacenará en un archivo. La mayoría de las veces, los archivos están estructurados de una determinada manera, sea cual sea. Esta forma en que cada archivo está estructurado nos obliga, o mejor dicho, nos permite usar ciertos tipos de datos, sin que tengamos que preocuparnos por cómo se leen o se escriben los datos.
Puede parecer un tanto extraño decir esto. Pero en la práctica, normalmente las cosas ocurren así. Rara vez, salvo en momentos muy específicos, necesitaremos saber realmente qué tipo de dato se almacena en una determinada posición del archivo. Pero, cuando ocurre este tipo de situación, saber y entender lo que debe hacerse es mucho más importante de lo que pueda parecer. Esto se debe a que, dependiendo de cómo imagines que funcionan las cosas, tú, como programador, puedes acabar teniendo muchas dificultades para resolver ciertos problemas relacionados con archivos. Por esta razón, te pido, mi querido lector, que prestes mucha atención a cada punto que se explicará en este artículo, porque entender lo que se verá aquí puede ser la diferencia entre leer un archivo de la manera adecuada y simplemente no conseguir entender absolutamente nada de lo que contiene ese mismo archivo.
Acceso aleatorio a archivos (Parte 2)
Cuando hablamos de uniones, en artículos anteriores de esta misma serie mostré que necesitas prestar mucha atención al tipo de dato y a la cantidad de bytes que contiene cada tipo. Sin saber esto, resulta muy complejo comprender realmente qué se representa en cualquier tipo de dato.
Las uniones en sí son un tema que mucha gente, a veces, ignora o ni siquiera llega a usar en sus códigos. Sin embargo, con respecto a estructuras y arrays, el asunto es completamente diferente. En este caso, muchas veces es muy difícil, por no decir casi imposible, crear ciertos modelos de datos sin entender realmente tales conceptos de programación, ya que las estructuras y los arrays son elementos mucho más comunes en el código que las uniones propiamente dichas.
Bien, pero existe un problema al que muchos acaban teniendo que enfrentarse. En este caso, las cosas pueden complicarse mucho, ya que existe un tipo de modelado en el que estructuras, arrays y uniones están todos presentes al mismo tiempo. Cuando esto ocurre, o entiendes realmente cómo se trabaja con tales conceptos, o te quedarás completamente desorientado. Este modelado implica, precisamente, trabajar con archivos de acceso aleatorio.
Tal vez quieras asustarme. No creo que los archivos puedan ser tan complicados como estás diciendo. No es exactamente así, mi querido lector. Tal vez todavía no entiendas el nivel de lo que estamos manejando. Los archivos son, con diferencia, la forma de datos más compleja que puede crear y concebir un programador. Esto es tan cierto que, cuando surge un nuevo estándar de archivo, junto con él surge una serie de documentos destinados únicamente a explicar cómo se trabaja con ese nuevo estándar.
Sin acceso a tales documentos, que explican cómo es el estándar interno de un archivo, si lo abres, no conseguirás entender absolutamente nada de lo que contiene, salvo que el archivo sea un documento de texto puro. Esta tal vez sea la única excepción en la que no se necesita ningún documento que explique cómo utilizar el estándar interno de un archivo. Para ejemplificar lo dicho, tomemos el ejemplo más simple de todos, que sería el formato bitmap. Este formato está descrito en diversos documentos repartidos por la WEB, y es un formato muy simple y bastante práctico, orientado precisamente a almacenar imágenes sin ningún tipo de compresión compleja.
Aunque existe una ligera compresión en algunos casos, esto es un mero detalle que podemos ignorar en este momento. La cuestión aquí es exactamente otra. En este caso, la cuestión aquí implica entender, o no, qué se almacena en cualquier archivo. Por ejemplo, si abres una imagen en un editor hexadecimal, verás algo parecido a lo que se ve en la siguiente imagen.
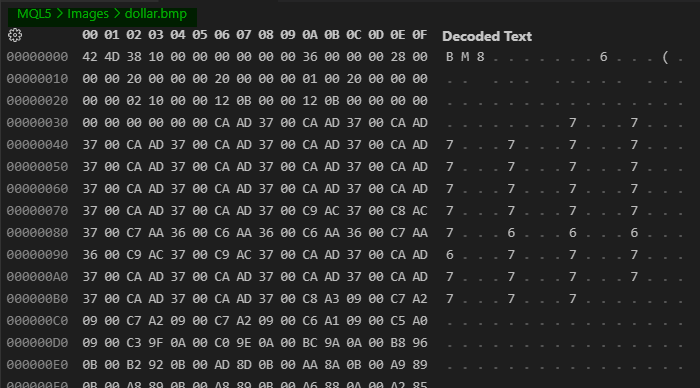
Imagen 01
Observa, en esta imagen 01, algo bastante curioso, mi querido lector. Observa que, en verde, se destaca cuál es el archivo que se muestra aquí. Sin embargo, al mirar estos datos, con toda seguridad no sabrías decir qué tipo de contenido existe en este archivo. Salvo por el hecho de que existen algunos marcadores que nos ayudan a identificarlo. Como, por ejemplo, los tres primeros valores presentes en este archivo. Obviamente, otro programador, o incluso otro programa, podrían utilizar estos mismos tres valores para indicar otro tipo de archivo completamente diferente. Aunque esto no es común, nada impide que alguien lo haga.
Sin embargo, si consideramos que esto no ocurre, enseguida puedes imaginar que se trata de un archivo bitmap. Y, como tal, deberá leerse como un bitmap. Ahora te pregunto: ¿Sabrías cómo obtener la información de este archivo sin tener la documentación que explica cómo está estructurado? Probablemente no. Esto se debe a que, salvo por el hecho de que tenemos los tres primeros valores remitiéndonos a lo que sería un formato bitmap, no existe ninguna otra información que nos diga cómo está estructurado internamente el archivo. Por lo tanto, si no sabes qué tipo de programa debe utilizarse para visualizar el contenido real del archivo, no podrás saber qué tipo de información existe en ese archivo.
Y es más o menos así como funcionan los programas. Parece magia, pero el sistema operativo comprueba el encabezado del archivo. Dependiendo del encabezado, este puede estar vinculado o no a alguna aplicación específica. Si lo está, cuando pidas visualizar el contenido del archivo, el sistema operativo utilizará el programa más adecuado para ese tipo de encabezado. Aunque muchos crean que esto está relacionado con otras cuestiones. A veces, incluso puede estarlo. Pero no viene al caso en este momento.
Bien, pero ¿adónde quiero llegar con esta cuestión? Pues bien, en el artículo anterior vimos cómo podíamos leer y escribir en un archivo de forma completamente aleatoria, usando llamadas como FileSeek y otras auxiliares. Pero allí hicimos un trabajo con el objetivo de leer un byte y, por cada byte leído o escrito, el índice de posición del archivo avanzaba automáticamente una posición. Pero ¿siempre es así? Para responder a esta cuestión, necesitamos abordar otro punto que se abordó en otros artículos, como cuando hablamos de uniones, estructuras y arrays. Aunque vimos estos temas por separado y poco a poco, aquí vamos a utilizar todos estos temas al mismo tiempo. Esto, para entender cómo avanza el índice de posición del archivo en cada lectura o escritura que hagamos.
Bien, ahora vamos a olvidar lo que se vio en la imagen 01, porque no nos ayudará en este momento. Tenemos que empezar con algo que sea más simple, pero adecuado a lo que se explicará. Para ello, vamos a utilizar el siguiente código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. const datetime dt = D'31.10.2024 15:30:10'; 08. const int i32 = 356248; 09. 10. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 11. { 12. Print("Error..."); 13. return; 14. }; 15. 16. FileWrite(handle, i32, "Info", dt); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileTell(handle), " >> ", FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Código 01
Bien, este código 01, cuando se ejecute, generará un archivo cuyo contenido se muestra a continuación.

Imagen 02
Pero este mismo código 01 también hará que, en el terminal, tengamos la siguiente salida.
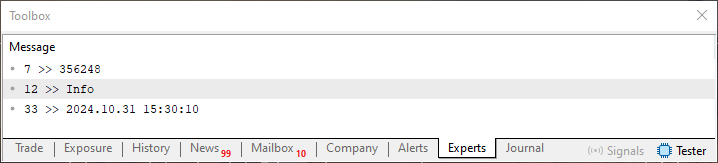
Imagen 03
Ahora viene la parte que nos interesa. Observa que, en esta imagen 03, tenemos un valor numérico antes de un dato que se leerá del archivo. Pues bien, este valor numérico que podemos ver antes de la información es la posición donde termina la información actual y empieza una nueva información. Así, si conocemos el valor anterior de la posición de lectura o escritura del archivo, podemos saber cuántas unidades de información se escribieron o leyeron. Pero espera, ¿no sería correcto decir bytes leídos o escritos? No, mi querido lector, y pronto entenderás el motivo.
Bien, entonces vamos a cambiar el código para saber cuántas unidades de información se escribieron o leyeron. En este caso, solo estamos leyendo. Pero debes considerar lo que se explica para ambos casos. Entonces, tenemos el siguiente código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. 18. FileWrite(handle, i32, "Info", dt); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. old = FileTell(handle); 26. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+
Código 02
Cuando se ejecute, este código 02 producirá el siguiente resultado.
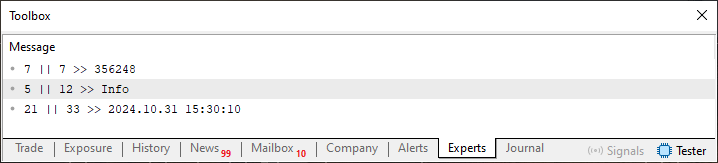
Imagen 04
Como este código 02, así como el resultado de la ejecución, es muy fácil de entender, podemos pasar al siguiente nivel. Pero quiero que entiendas lo siguiente, mi querido lector. En este momento, la lectura que estamos haciendo está forzando al sistema a leer un valor a la vez, basándonos en lo que sería un delimitador presente en el archivo. Este delimitador se obtiene mediante un carácter de tabulación, como puede verse en la siguiente imagen.

Imagen 05
Observa que, en esta imagen, destaco precisamente este carácter de tabulación. Pero ¿qué ocurriría si cambiamos un poco el código? Bien, para ver esto, vamos a usar el siguiente código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI | FILE_TXT)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. 18. FileWrite(handle, i32, "Info", dt); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. old = FileTell(handle); 26. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+
Código 03
Cuando ejecutes este código 03, verás lo que se ve en la siguiente imagen.
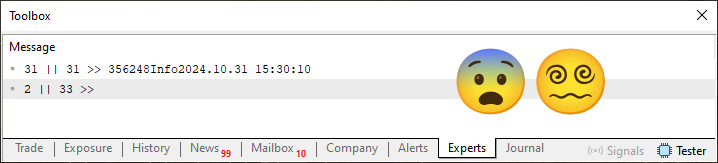
Imagen 06
¿Qué locura es esta? No entendí qué cambió en el código para que el resultado fuera así. Bien, no lo diré, tendrás que observar el código para encontrar lo que se modificó. Sin embargo, si miras el contenido binario del archivo, verás lo que se muestra a continuación.

Imagen 07
Hombre, hiciste algo. Dime dónde cambiaste algo. Nuevamente, mi amigo lector, tendrás que mirar el código para entender qué modifiqué. De cualquier forma, puedes notar que el resultado ya no es el que existía antes. Esto se debe a que, ahora, cambiamos el formato del propio archivo. Como la aplicación ya no sabe cómo leer el archivo para recuperar los datos, el resultado es este desorden total.
Ahora, presta atención: para resolver este desorden, necesitamos decirle al código, de alguna manera, dónde termina un valor y dónde empieza otro. Esto puede hacerse de diversas formas. Aquí veremos solo una de tantas formas de hacerlo. Como cada caso es distinto, no existe una forma única de resolver la cuestión. Pero vayamos con calma, porque quiero que entiendas cómo se hará esto de la manera adecuada.
Primero, vamos a modificar el código para algo parecido a lo que se ve a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. FileWriteString(handle, (string)i32); 18. FileWriteString(handle, "info"); 19. FileWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 20. 21. FileFlush(handle); 22. 23. FileSeek(handle, 0, SEEK_SET); 24. while (!FileIsEnding(handle)) 25. { 26. old = FileTell(handle); 27. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 28. } 29. 30. FileClose(handle); 31. } 32. //+------------------------------------------------------------------+
Código 04
Muy bien, aunque el resultado que se verá en el terminal sea el mismo que se ve al ejecutar el código 03, este código 04 genera un archivo un poco diferente. Este código puede verse a continuación.

Imagen 08
Ahora, presta atención, mi querido lector. Como se dijo, existen distintas formas de hacer lo mismo. Pero aquí usaremos un método muy parecido al que existía en el antiguo y extinto lenguaje de programación BASIC. Así, el siguiente paso se ve en el siguiente código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. FileWriteInteger(handle, 0, CHAR_VALUE); 18. FileWriteString(handle, (string)i32); 19. FileWriteInteger(handle, 0, CHAR_VALUE); 20. FileWriteString(handle, "info"); 21. FileWriteInteger(handle, 0, CHAR_VALUE); 22. FileWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 23. 24. FileFlush(handle); 25. 26. FileSeek(handle, 0, SEEK_SET); 27. while (!FileIsEnding(handle)) 28. { 29. old = FileTell(handle); 30. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 31. } 32. 33. FileClose(handle); 34. } 35. //+------------------------------------------------------------------+
Código 05
Ahora, mucha, pero mucha atención. Este código 05 creará un archivo como el que se ve en la siguiente imagen.

Imagen 09
Al observar esta imagen 09, puedes notar que marco algunos puntos donde el valor en hexadecimal es igual a cero. ¿Por qué? El motivo es que usaremos precisamente la posición donde están estos valores para indicar cómo deberá reconstruir el texto la aplicación. Esto, para poder mostrar el texto correcto directamente en el terminal. Si miras el terminal cuando ejecutes este código 05, notarás algo extraño, aunque perfectamente comprensible para quienes han seguido lo que se explica y se muestra en los artículos. Esto ocurre porque, cuando intentamos imprimir algo en el terminal, tendremos como primer carácter del archivo un valor igual a cero. Por esta razón, tendremos un resultado que, en principio, puede parecer bastante inusual.
Sin embargo, incluso en este código 05, si cambias el valor usado en la función FileSeek, en la línea 26, para saltar este primer valor cero que aparece justo al inicio del archivo, notarás que algún tipo de dato se mostrará en el terminal. Prueba esto después, para ver y entender cómo se comportará el programa. Así que queda como sugerencia para algo que puedes experimentar después. Sin embargo, aquí, en el artículo, no haremos esto, ya que quiero que veas, por ti mismo, cómo puedes controlar los resultados a medida que se modifica el código. Pero volvamos a nuestra cuestión principal.
Como el archivo que estamos generando ahora debe entenderse como un archivo binario, FileReadString necesita saber cuántos bytes deberán leerse. Esto, para tener el texto correcto y completo que se mostrará en el terminal. Para hacer esto, vamos a modificar nuevamente el código, como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. const datetime dt = D'31.10.2024 15:30:10'; 09. const int i32 = 356248; 10. 11. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 12. { 13. Print("Error..."); 14. return; 15. }; 16. FWriteString(handle, (string)i32); 17. FWriteString(handle, "info"); 18. FWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. uchar old = (uchar) FileReadInteger(handle, CHAR_VALUE); 26. Print(old, " || ", FileTell(handle), " >> ", FileReadString(handle, old)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+ 32. void FWriteString(int &handle, const string szArg) 33. { 34. long offs = (long) FileWriteInteger(handle, 0, CHAR_VALUE); 35. long size = (long) FileWriteString(handle, szArg); 36. ulong ftell = FileTell(handle); 37. FileSeek(handle, (size + offs) * -1, SEEK_CUR); 38. FileWriteInteger(handle, (uchar)size, CHAR_VALUE); 39. FileSeek(handle, ftell, SEEK_SET); 40. } 41. //+------------------------------------------------------------------+
Código 06
Muy bien, ahora sí tenemos un código que generará un resultado interesante en el terminal. Al ejecutar este código, veremos como resultado lo que se ve en la siguiente imagen.
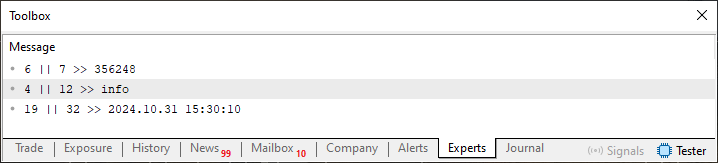
Imagen 10
Ahora, con respecto al archivo. Si lo abres en un editor hexadecimal, verás algo parecido a lo que se muestra a continuación.

Imagen 11
Observa que, en este caso, como se ve en esta imagen 11, se destacan algunos valores. Estos valores son la parte importante para nosotros. Esto ocurre porque indican la cantidad de caracteres que deberá leer la función FileReadString. O, dicho de otra manera: estos mismos valores destacados en la imagen 11 indican cuántos caracteres deberán leerse a continuación. Básicamente y de forma muy clara, puedes ver que estos mismos valores también se muestran en la imagen 10. Pero entonces, ¿por qué este código 06 funcionó, mientras que los demás solo generaron un archivo que no presentaba ningún resultado plausible en el terminal?
Para entender esto, necesitamos observar con calma precisamente el procedimiento que se creó en la línea 32 de este código 06. Este procedimiento, en cierto modo, es el corazón de nuestra aplicación, ya que accederá aleatoriamente al archivo para componer la parte del contenido que se grabará en el archivo. Sin embargo, este mismo procedimiento centra la operación en un tipo o, mejor dicho, en un ancho de bytes, por lo que todo depende bastante del tipo de dato que almacenaremos en el archivo.
Ahora, presta atención a algunos detalles aquí, porque son importantes. En la línea 34, pedimos que se almacene un byte. Este mismo byte servirá para ajustar el offset después. Este offset es un punto crucial. Pero llegaremos a ese punto con calma. Primero, entendamos cómo funciona esta rutina de la línea 32. Bien, ahora que tenemos un offset, grabamos el contenido de la string en el archivo. Esto ocurre en la línea 35. Detalle: la string NO DEBE CONTENER MÁS DE 255 símbolos, ya que este es el límite definido por el byte escrito antes. Ahora, en la línea 36, guardamos temporalmente la posición actual del archivo. Esto ocurre porque volveremos a la posición del byte que contiene la longitud del mensaje y cambiaremos el contenido de ese byte. Esto ocurre en la línea 37. La grabación en sí ocurre en la línea 38. Observa que todos estos accesos podrían sustituirse por un único acceso si usáramos un array. Pero, por ahora, vamos a dejarlo así, solo para que sea sencillo entender lo que se está haciendo.
Muy bien, una vez que los datos se hayan grabado, la línea 20 fuerza la escritura inmediata del archivo, en caso de que todavía quede algún dato en el buffer. Después, la línea 22 apunta al inicio del archivo y, en ese momento, entramos en el bucle de la línea 23, que fuerza la lectura: primero leeremos el carácter que nos indica la cantidad de símbolos que deben leerse. Luego, usamos la línea 26 para leer y mostrar estos mismos símbolos.
Observa que necesitamos una coincidencia entre la línea 25 y la línea 34. Esto sirve para que la aplicación sepa cuántos bytes representan realmente el número de símbolos que deben leerse. Es en este punto donde entra la cuestión del offset. Muy bien, pero este mismo tipo de construcción también podría modelarse de otra manera que, a mi modo de ver, simplifica mucho el desarrollo del código, así como su mantenimiento y su mejora.
Ahora, detente y piensa un momento, mi querido lector. Lo que estamos haciendo aquí, en este archivo que estamos creando, es justamente algo que ya se vio en otro artículo de esta misma secuencia. Sin embargo, en aquel momento aún no teníamos elementos suficientes para poder explicar ciertos detalles que aquí sí podemos poner en práctica. Lo que quiero decir es que, al observar la forma en que se implementa todo, en realidad estamos trabajando con una estructura de datos. Por esta razón, es importante que no te aferres al código, sino que procures entender los conceptos adoptados y pienses en las posibilidades que tenemos para obtener el mismo tipo de resultado. Algunas son más simples, mientras que otras son más eficientes. De cualquier forma, entender el concepto es más importante que intentar memorizar y escribir código al azar.
Bien, para mostrar que podemos trabajar de distintas maneras y aun así obtener siempre el mismo tipo de resultado, vamos a experimentar un poco con lo que se vio hasta aquí. Para ello, trabajaremos con un código algo diferente en ciertos aspectos. Este código puede verse a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle, 07. start = 1; 08. uchar arr[]; 09. 10. const datetime dt = D'31.10.2024 15:30:10'; 11. const int i32 = 356248; 12. 13. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_BIN)) == INVALID_HANDLE) 14. { 15. Print("Error..."); 16. return; 17. }; 18. 19. start += arr[start - 1] = (uchar) StringToCharArray((string)i32, arr, start); 20. start += arr[start - 1] = (uchar) StringToCharArray("info", arr, start); 21. start += arr[start - 1] = (uchar) StringToCharArray(StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS)), arr, start); 22. 23. FileWriteArray(handle, arr, 0, start - 1); 24. FileFlush(handle); 25. 26. ArrayFree(arr); 27. 28. FileSeek(handle, 0, SEEK_SET); 29. FileReadArray(handle, arr); 30. 31. FileClose(handle); 32. 33. for (uint i = 0; i < arr.Size(); i+= arr[i]) 34. Print(i, " >> ", CharArrayToString(arr, i + 1, arr[i])); 35. } 36. //+------------------------------------------------------------------+
Código 07
Cuando se ejecute este código 07, tendremos como resultado en el terminal lo que se muestra en la siguiente imagen.
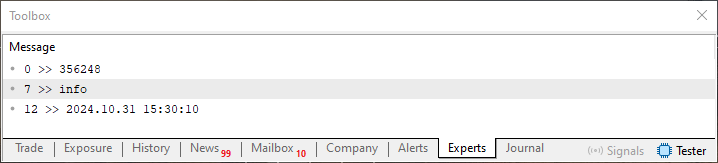
Imagen 12
Ahora, entendamos algo aquí, mi amigo lector. A diferencia de los demás códigos vistos hasta este momento, aquí hacemos algunas operaciones de una manera algo diferente. Esto se debe a que estamos sustituyendo aquella cantidad de accesos a la unidad de disco por una operación directamente en memoria. Esto puede verse claramente aquí, en el código 07. Pero ¿qué tipo de impacto tiene esto en el código y también en el uso de la aplicación? Después de todo, tanto el objetivo como el resultado, aparentemente, se mantuvieron intactos.
Bien, mi querido lector, el hecho de eliminar todos aquellos accesos al disco y trasladar gran parte de ellos a manipulaciones realizadas en memoria hace que la aplicación sea más ágil y también evita un retraso, o una caída en el rendimiento de MetaTrader 5, debido a las incesantes solicitudes de escritura en disco. Técnicamente, estamos forzando la escritura solo en las líneas 25 y 26. Sin embargo, en este código 07 tenemos algunas cosas que quizá no tengan mucho sentido para quien esté empezando en programación. Aun teniendo los artículos anteriores para ayudar a entender gran parte del código, creo que necesito dar una breve explicación sobre por qué este código 07 funciona y genera el mismo tipo de resultado visto en los códigos anteriores.
Para empezar, observa que, en la línea siete, se inicializa una variable que nos será muy útil. Asimismo, en la línea ocho, declaramos un array dinámico. Este array será nuestro archivo en memoria. Ahora, presta mucha atención a lo que se hace en las líneas 19, 20 y 21. En estas líneas del código 07, estamos haciendo lo mismo que se hizo en las líneas 16, 17 y 18 del código 06. Sin embargo, aquí, en este código 07, estas mismas tres líneas mencionadas también realizan la operación equivalente al procedimiento FWriteString, que también aparece en el código 06.
Pero espera un momento. Ahora me quedé un tanto confundido con respecto a este código 07. ¿Me estás diciendo que estas líneas 19, 20 y 21 sustituyen todo lo que se hacía en el código 06 para escribir los datos en el archivo? Sí, mi querido lector. Pero estas líneas, en el código 07, a mi modo de ver, no parecen hacer esto. Al menos, no logro verlo en este momento. ¿Podrías explicarlo mejor? Claro que puedo explicarlo. Entonces, entendamos qué hace una de las líneas, ya que las demás funcionan de la misma manera.
Tal vez lo que vuelve esto un tanto confuso es que estas líneas están compactadas. Entonces, veamos cómo funciona la línea 19. En primer lugar, debes recordar que la variable start ya tendrá un valor cuando se ejecute la función StringToCharArray. Así, el valor que contenga start nos indicará en qué posición del array comienza la inserción, de los caracteres presentes en la string. Consulta la documentación para obtener más detalles sobre esta función StringToCharArray. Una vez que todos los caracteres se hayan transferido al array, la función devolverá la cantidad de caracteres añadidos. Así, usamos el valor start para colocar, al inicio del array, la cantidad de caracteres. Esto nos da, de esta manera, el mismo tipo de modelado realizado por el código 06.
Sin embargo, existe una diferencia aquí. StringToCharArray contará todos los caracteres, incluido el carácter NULL. Es decir, el valor de conteo será diferente del que se obtenía en el código 06. Presta mucha atención a este detalle. Con todo, el último paso de esta línea, en este caso la línea 19, será actualizar la posición apuntada por la variable start.
Ahora viene la parte interesante del código, que es precisamente la línea 23. Si entendiste lo que ocurrió en las líneas 19, 20 y 21, habrás notado que la variable start siempre apunta a un carácter NULL dentro del array. Este carácter es el último del array. Sin embargo, como ese carácter no nos interesa, usamos la función FileWriteArray para almacenar todos los caracteres en disco, excepto uno, que es el último carácter dentro del array. Con esto, tendremos un archivo binario muy similar al que crearía el código 06. No obstante, será incompatible con el archivo generado por el código 06, precisamente por el carácter de conteo al inicio de la string. Por este motivo, también cambiamos la rutina de lectura por la que aparece en la línea 29. Allí, leemos todo el archivo de una sola vez. Pero, para poder mostrarlo de manera adecuada y obtener así el resultado esperado, usamos el bucle de la línea 33.
Consideraciones finales
En este artículo, vimos cómo podríamos implementar un sistema de acceso aleatorio para escribir datos en un archivo. Esto, con el fin de definir algún tipo de formato protocolario. Sin embargo, hacerlo directamente en un archivo no siempre es una buena idea.
Muchas veces, el mejor camino sería crear un archivo en memoria, dentro de cualquier array. Solo después de que el array tenga todos los valores debidamente cargados, pasamos a la fase de escritura de los datos en un archivo de disco. Esto hace que el proceso sea más eficiente, ya que la memoria es mucho más rápida que los discos físicos. Incluso las unidades SSD son más lentas que una memoria RAM. Además, no tiene mucho sentido leer byte por byte en un archivo. Lo mejor es leer un bloque grande directamente a la memoria y trabajar con él allí, donde podemos buscar byte a byte en busca de algún dato específico.
Aunque aquí hemos trabajado solo con tipos de un único byte, puedes extender lo que se vio aquí para trabajar con tipos más largos o complejos. Esto, sin ninguna dificultad, ya que, para hacerlo, puedes reducirlo todo a unidades como estructuras o uniones. Ambas ya se vieron y explicaron aquí en esta secuencia.
| Archivo MQ5 | Descripción |
|---|---|
| Code 01 | Demostración de acceso a archivo |
| Code 02 | Demostración de acceso a archivo |
| Code 03 | Demostración de acceso a archivo |
| Code 04 | Demostración de acceso a archivo |
| Code 05 | Demostración de acceso a archivo |
| Code 06 | Demostración de acceso a archivo |
| Code 07 | Demostración de acceso a archivo |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/16271
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso