
Del básico al intermedio: Acceso aleatorio (I)

Introducción
En el artículo anterior, Del básico al intermedio: FileSave y FileLoad, hablamos sobre las funciones de biblioteca FileLoad y FileSave, y se ofreció una buena introducción y explicación. Aunque muchos las consideran poco prometedoras debido a algunas dificultades que nos imponen para realizar ciertas operaciones, son bastante útiles cuando se trata de generar archivos de log. Estos archivos, para quien no lo sepa, sirven para que sepamos cómo funciona realmente nuestro código en determinados escenarios, y son una herramienta de extrema utilidad para cualquier desarrollador.
A pesar de esto, las funciones FileSave y FileLoad están básicamente orientadas a una implementación en la que el acceso a los datos de los archivos será secuencial. Esto se debe a la propia forma en que operan estas funciones. Sin embargo, muchas veces, gran parte de los desarrolladores implementa acceso aleatorio al archivo, aunque FileLoad y FileSave puedan permitir ese acceso de forma indirecta, cargando y guardando el archivo completo en memoria.
Por lo tanto, aunque sea posible crear un acceso aleatorio, este no se realizará realmente de la forma habitual. En este caso, el objetivo es cargar solo las partes necesarias del archivo, en pequeños bloques. Este tipo de situación, aunque parezca no tener mucho sentido en tiempos en los que la memoria de la computadora es lo suficientemente barata como para poder mantener grandes archivos en ella, puede ser muy útil en muchos otros escenarios, donde el objetivo es fragmentar el archivo de una determinada manera.
Acceso aleatorio a archivos (Parte 1)
Si observas la documentación de varios lenguajes de programación para comprobar cuáles son los procedimientos y funciones que implementa un lenguaje u otro, al estudiar específicamente la parte relacionada con el manejo de archivos, notarás que, muchas veces, los lenguajes de programación ponen a disposición muchas más funciones y procedimientos de los que realmente necesitarás o usarás. Algunos lenguajes, como C++, por ejemplo, tienen una cantidad muy pequeña de funciones y procedimientos para trabajar con archivos.
Sin embargo, en el caso de C++, disponemos de métodos de entrada y salida extensibles a otros usos, lo que permite usar una sintaxis mucho más simbólica de lo natural. En el futuro, trataremos este tipo de recursos aquí en MQL5. Por ahora, quedémonos en lo básico, ya que no tiene sentido complicarlo antes de tiempo.
Entonces, si miras la documentación de MQL5, notarás que existen diversas funciones y procedimientos orientados tanto a la lectura como a la escritura de datos en archivos. Los métodos más simples son FileLoad y FileSave, que fueron presentados y explicados en el artículo anterior. Pero, como se dijo en la introducción de este artículo, estos métodos no están orientados al acceso aleatorio al contenido de un archivo. Precisamente por esta razón, aparecen varios otros métodos en la documentación de MQL5, ya que su objetivo es permitir precisamente el acceso aleatorio al contenido de cualquier archivo.
Bien, esto explica parcialmente la presencia de tantos métodos diferentes descritos en la documentación. Sin embargo, esto no explica cómo trabajar con esos métodos, ni tampoco explica cómo podemos manejar tipos de datos implementados por el programador. Sí, mi querido lector, tú, como programador, no estás limitado a trabajar solamente con los tipos definidos en el lenguaje de programación. Los buenos lenguajes de programación, como MQL5, nos permiten crear tipos únicos y orientados a situaciones específicas. Quizá no estés entendiendo de qué estoy hablando, ya que esto parece bastante inusual.
Sin embargo, en los artículos de esta misma secuencia, cuando hablamos de template y typename, hacíamos precisamente eso: creando tipos únicos y especialmente orientados a un problema determinado. También podemos utilizar uniones y estructuras para crear un tipo específico, cuyo propósito es crear una abstracción para datos especiales.
Bien, con esto, acabamos creando una restricción para simplificar lo que se verá aquí. Como el objetivo es mostrar, de la forma más didáctica posible, cómo realizar ciertos tipos de operaciones, explicar cada una de aquellas funciones y procedimientos que vimos en la documentación de MQL5 para trabajar con archivos pasa a ser bastante innecesario. Podemos centrarnos en un tipo de modelado, para mostrar cómo cubrir una amplia gama de posibilidades de implementación.
Así, el material que se mostrará aquí, en ningún caso, debe considerarse la única forma de hacerlo. Dependiendo del caso, usar una función o procedimiento de la biblioteca estándar de MQL5 será, con diferencia, la mejor manera de resolver ciertos tipos de problemas. Esto se debe a que el proceso se vuelve más directo, y no a un enfoque indirecto cuyo objetivo sea obtener otro tipo de solución.
Dicho esto, nos limitaremos a utilizar pocas funciones y procedimientos. Sin embargo, esto no te impedirá experimentar con otras funciones o procedimientos para entender el funcionamiento de operaciones algo más específicas de la biblioteca estándar de MQL5. Así que, mi querido lector, intenta ver e imaginar posibilidades más allá de lo que se mostrará aquí. Porque podemos obtener los mismos tipos de resultados utilizando métodos ligeramente diferentes. Aunque esos métodos pueden llegar a ser más simples de comprender para un programador u otro. Así que empecemos con el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileClose(handle); 19. 20. Print("Success"); 21. } 22. //+------------------------------------------------------------------+
Código 01
Ahora, cuando ejecutemos este código 01, veremos que se crea un archivo en una SandBox determinada. Creo que tú, mi querido lector, no deberías tener dificultades para entender de qué archivo se trata y dónde se creará. Sin embargo, existe cierto detalle respecto del contenido de este archivo. Esta es la parte interesante.
Observa lo siguiente: En este código 01, estamos indicando, en la línea 8, que se abra un archivo en modo escritura. Si tenemos éxito, la variable tendrá un valor que podrá utilizarse para manipular el archivo. Hasta ahí, todo muy bonito y simple. Tanto es así que, para indicar que las operaciones que se efectuarán en el archivo han terminado, usamos la línea 18, cuyo objetivo es cerrar el archivo, lo que permite liberarlo para usarlo con cualquier otro propósito. Sin embargo, la parte que realmente nos interesa se encuentra entre las líneas 13 y 16. Allí es donde escribimos en el archivo.
Antes de ver cómo puede hacerse la lectura, entendamos esta cuestión sobre la escritura. Porque esto es mucho más importante de lo que pueda parecer a primera vista.
Puedes ver claramente lo que queremos escribir en el archivo, ya que todo el contenido es muy simple y fácil de comprender. Sin embargo, aun así, ¿qué se escribe realmente en el archivo? Bueno, para responder a esto, podemos ver el contenido del archivo a continuación.

Imagen 01
En esta imagen 01, podemos ver el resultado de las operaciones de escritura en el archivo. Espera, este contenido parece algo extraño. Entonces, miremos este mismo archivo visto en la imagen 01, pero en formato binario. Puedes verlo a continuación.
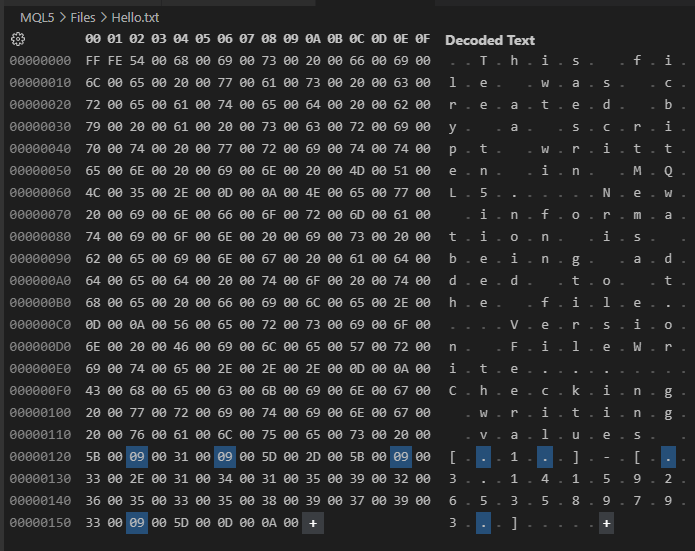
Imagen 02
Ahora, atención, mi querido lector: el contenido que se ve en esta imagen 02 es exactamente el mismo que se ve en la imagen 01. Sin embargo, aquí, en la imagen 02, vemos cada uno de los bytes del archivo escrito por el código 01. Observa algo interesante en esta imagen 02, que puede ser la diferencia entre leer un valor correcto y leer un valor completamente erróneo cuando hagamos una lectura aleatoria.
Aunque no hayamos indicado absolutamente nada al comienzo del archivo, y esto puede verse en la imagen 01 y en el código 01, al inicio del archivo que puede verse en la imagen 02 tenemos dos bytes extraños que no tienen mucho sentido. Estos bytes tienen como objetivo indicar el tipo de formato, y en ningún caso nos interesan. En el código 01, notas claramente que no existen. Sin embargo, aquí existen otros caracteres que tampoco aparecen en el código 01. Se trata de los caracteres de retorno de carro y nueva línea.
En esta misma imagen 02 hay algunos bytes destacados. ¿Por qué? El motivo es que estos se insertan para tabular la información de la línea 16 del código 01. Es extremadamente importante que entiendas la presencia de estos caracteres de tabulación. Porque, dependiendo del tipo de contenido que estés escribiendo, pero principalmente del propósito para el que se crea el archivo, estos caracteres extra pueden destruir por completo cualquier posibilidad de leer correctamente el archivo más adelante. Puede que no esperes la presencia de esos caracteres, y estos acaben destruyendo el sistema de indexación en el momento de la lectura de los datos.
Bien, entendí que no siempre lo que aparece en el código se representará realmente de la misma forma cuando escribimos en un archivo. ¿Pero siempre es así? Bueno, depende, querido lector. Mira lo siguiente: si cambiamos el código 01 por el código que aparece a continuación, el resultado podrá ser muy diferente.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_ANSI)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileClose(handle); 19. 20. Print("Success"); 21. } 22. //+------------------------------------------------------------------+
Código 02
Ahora, presta atención: la única diferencia entre el código 01 y este código 02 es justamente un valor extra que añadimos a la función FileOpen. Por este simple hecho, observa lo que ocurre cuando el código 02 crea el archivo. Puedes observarlo comparando la imagen 03, a continuación, con la imagen 02.
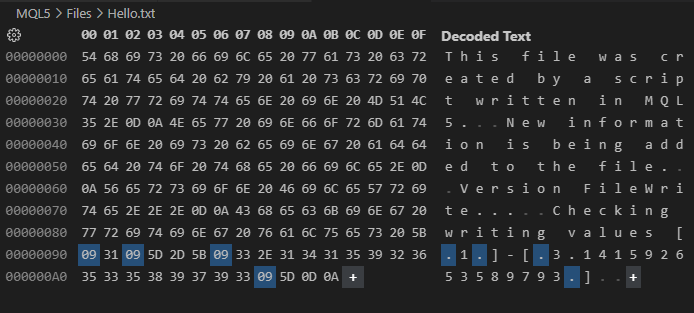
Imagen 03
¡Vaya! Y yo que pensaba que los resultados de pequeños cambios en el código no marcarían tanta diferencia. Mi querido lector, hay cuestiones que solo llegarás a comprender realmente experimentando y viéndolas ocurrir en la práctica. Una de ellas es justamente esta que acabas de observar ante tus ojos. Por eso te digo que procures practicar y estudiar el contenido de los artículos, intentando aplicar el contenido de una manera un poco diferente, pero, principalmente, probando qué ocurre cuando cambiamos ciertos elementos del código.
Siguiendo con esto, observa que este resultado, visto en la imagen 03, está mucho más cerca del contenido que cabría esperar al observar el código 02. Sin embargo, aun así, tenemos la cuestión de los caracteres de tabulación, retorno de carro y nueva línea, que aún siguen apareciendo. ¿Por qué? El motivo es que no estamos pidiendo que el archivo se escriba en modo binario.
Independientemente de esto, vamos a hacer un pequeño cambio en el código. Esto, con el fin de leer un punto determinado del archivo, solo para verificar un pequeño detalle que es importante que entiendas incluso antes de pasar a una escritura binaria del archivo.
Sin saber por qué escribir un archivo de manera binaria o no binaria, resulta algo confuso hacer la elección correcta en distintos momentos de una implementación real.
Para que podamos visualizar lo que quiero mostrar, necesitamos crear un nuevo código. Se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Código 03
Este código 03, además de permitirnos escribir el archivo, tal como lo hacía el código 02, también nos permite leer el contenido del archivo. Para que todo ocurra sin problemas y entiendas lo que veremos más adelante, primero necesitamos entender qué esperar como resultado de la ejecución de este código 03.
Básicamente, el archivo que se escribirá es el que podemos ver en la imagen 03. Para garantizar que el archivo contenga realmente información dentro de lo esperado, usamos la línea 18 para volcar el buffer al archivo en disco. Esta operación, vista en la línea 18, puede ser innecesaria en algunos momentos. Dependiendo de qué tan cargado esté el sistema operativo con operaciones de escritura o lectura en disco, la escritura realizada por las líneas 13 a 16 puede ocurrir en tiempo real. Sin embargo, puede que, en algún momento, esto no ocurra. Como no quiero cerrar el archivo para luego volver a abrirlo y leer los datos almacenados en él, usamos esta función de biblioteca de la línea 18 para "forzar" un volcado inmediato de los datos al archivo.
Bien, una vez hecho esto, tenemos cierta garantía de que el archivo contendrá realmente los datos que pueden verse en la imagen 03. Ahora viene la parte de la lectura. Como el puntero del archivo se modificó y se encuentra al final, necesitamos reposicionarlo en algún otro punto. En este caso, apuntaremos al inicio del archivo. Para ello, usamos la línea 20, donde literalmente movemos el punto de lectura y escritura al comienzo del archivo en disco. Presta atención a esto, mi querido lector. La lectura que haremos no será del contenido del buffer, sino del propio archivo.
Esto se aplica tanto a la escritura como a la lectura, podemos utilizar el método de lectura que se ve en la línea 21, donde leeremos hasta que se indique el final del archivo. Lo que realmente nos interesa aquí es lo que hace la línea 22. En esta línea, le indicamos a la aplicación que muestre, en el terminal de MetaTrader 5, el contenido leído del archivo. Esta es la parte que realmente nos importa aquí.
Ahora, presta atención: en nuestro caso, tenemos lo que serían cuatro líneas escritas. Estas pueden verse en la imagen 01. Entonces, obviamente, cuando se ejecute la línea 22 del código 03, en principio obtendremos en el terminal un resultado impreso parecido a lo que se ve en la imagen 01. Sin embargo, cuando miramos el terminal de MetaTrader 5, nos encontramos con algo parecido a la imagen 04, a continuación.
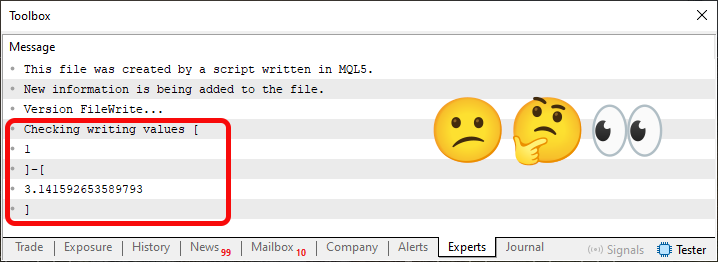
Imagen 04
Mmm, extraño. Aparentemente, las tres primeras líneas se muestran correctamente. Sin embargo, esta región marcada en rojo nos muestra un dato distinto del esperado. Muy extraño. Pues bien, mi querido lector, aunque parezca extraño, este resultado que se muestra, en principio, es muy bueno para nosotros. Sin embargo, quiero recordar a todos que aquí lo estamos haciendo de la forma más simple posible, precisamente para encontrar una respuesta a algo que todos, en principio, harían, pero que acabaría dando resultados diferentes de los esperados.
Sin embargo, aquí tenemos esta salida, algo extraña, precisamente por el carácter de tabulación. Pero espera un momento, ¿cómo es eso? Bueno, mi querido lector, como estamos leyendo el archivo en modo no binario, esta función FileReadString detendrá la lectura siempre que encuentre la combinación de retorno de carro y nueva línea, pero también cuando encuentre un carácter de tabulación. Basta con consultar la documentación para más detalles, aunque allí se menciona el uso de archivos CSV. Este no es, en principio, el caso aquí, ya que el contenido del archivo no está pensado para representar un formato CSV.
Bien, una vez más, hay algo que aprender aquí. Esto ocurre porque, entre los flags de lectura del archivo, el hecho de no haber informado qué tipo de dato debía analizar la operación de lectura de la línea 22 provoca una interpretación en la que las tabulaciones se consideran durante la lectura. Así, para resolver esta cuestión, necesitamos cambiar una vez más el código, usando el código que aparece a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_TXT)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Código 04
Observa que, una vez más, necesitamos modificar solo un punto del código. Se trata de la línea 8, que puede verse en este código 04. Sin embargo, aun así, el resultado es muy diferente de lo que se vio en la imagen 04. En este caso, cuando se ejecuta el código 04, podremos ver en el terminal lo que aparece a continuación.
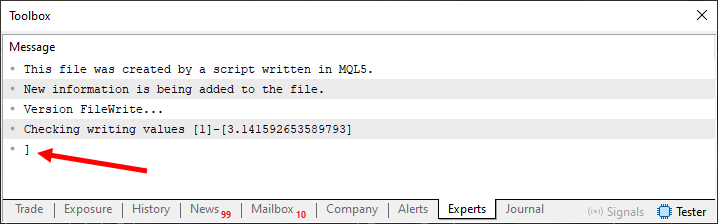
Imagen 05
Observa que, en este caso, el contenido se parece mucho a lo previsto al observar la parte de escritura que aparece en el código. Claro que tuvimos un pequeño inconveniente, precisamente el que señala la flecha en la imagen 05. Pero esto es un problema de menor importancia, ya que el objetivo, de cierto modo, puede considerarse alcanzado. El objetivo era precisamente leer el archivo de forma que obtuviéramos algo muy parecido al texto que aparece entre las líneas 13 y 16 del código 04.
Muy bien, ahora que esto quedó hecho y mostrado, podemos empezar a pensar en la cuestión de la lectura y escritura binaria. Esto nos permite buscar un acceso aleatorio al contenido del archivo. Sin embargo, este tipo de contenido, que estamos escribiendo y leyendo del archivo, por ser muy similar y parecido a lo que sería un texto cotidiano, no es realmente adecuado para demostrar de forma clara y simple cómo se dan en la práctica las operaciones binarias y de acceso aleatorio. Para ello, y como una forma de dar el primer paso y tener una visión inicial y básica, sobre el tema, necesitamos cambiar el contenido por algo un poco más simple. Esto se hace utilizando el código que aparece a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_BIN)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. for (uchar c = 0; c < 10; c++) 14. FileWriteInteger(handle, c, CHAR_VALUE); 15. 16. FileFlush(handle); 17. 18. FileSeek(handle, 0, SEEK_SET); 19. Print("The byte value of the ", FileTell(handle), " position in the file is ", FileReadInteger(handle, CHAR_VALUE)); 20. 21. FileClose(handle); 22. } 23. //+------------------------------------------------------------------+
Código 05
Al ejecutar este código 05, se creará un archivo con valores de cero a nueve, como se hace en la línea 14. Pero hay un pequeño detalle, y es extremadamente importante que lo entiendas muy bien, mi querido lector. Observa que, durante la escritura, indicamos que el valor que se va a escribir sea de tipo CHAR_VALUE. Entender esto es muy importante, porque, por defecto, esta función escribirá valores de tipo INT_VALUE. Pero espera, no sé por qué entender esto sería importante para nosotros. Bueno, para entender la importancia de esta información, hay que recordar, o mejor dicho, es necesario que hayas entendido cómo trabajar con uniones.
En esta serie, se publicaron dos artículos básicos sobre uniones, y uno de ellos es Del básico al intermedio: Unión (I). Además de este conocimiento, también tendrías que entender cómo trabajar con arrays. Esto también se explicó en otros artículos de esta misma serie. Considerando que tienes todo el conocimiento necesario explicado en los artículos anteriores, podemos tratar de entender por qué, al ejecutar este código 05, obtendremos el resultado que aparece a continuación.
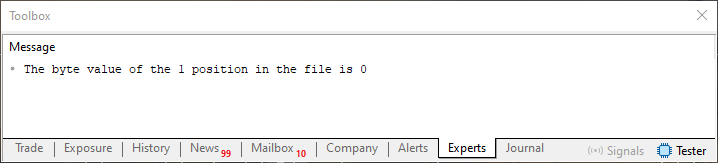
Imagen 06
Bien, cuando se ejecute la línea 19 del código 05, se mostrará algo parecido a lo que se ve en la imagen 06. Pero ¿qué quiere decirnos este mensaje impreso en el terminal? Bueno, puedes notar que, en este mensaje, se imprimen dos valores numéricos. El primer valor se refiere a la posición actual en el archivo. El segundo valor se refiere al contenido de esa posición específica. Ahora, presta atención, mi querido lector. Un archivo, cuando se lee de esta forma, debe pensarse como un array. Es decir, un array cuyo índice se incrementa automáticamente. También podemos indicar cuál es el índice dentro de este array, y esto se hace utilizando la línea 18.
De la misma manera que la cuenta en un array se inicia en el índice cero, cuando vamos a acceder a datos en un archivo, el índice también se inicia en cero. Sin embargo, a diferencia de lo que ocurría si indicábamos un índice fuera del array, aquí, cuando usamos archivos, el sistema siempre situará el índice en una posición válida. Prueba este código 05 para entenderlo, cambiando el valor cero que se usa en la función de la línea 18 por otros valores. Mira el resultado. Esto te ayudará a entender cómo se realiza el acceso a los datos.
Sin embargo, también es necesario entender otra cuestión aquí. Observa que FileReadInteger también usa CHAR_VALUE. Esto se debe a que queremos leer un solo byte. Normalmente, se leerían cuatro bytes, lo que haría avanzar el índice, o la posición del archivo, esos mismos cuatro bytes. Presta mucha atención a estos detalles que estoy mencionando. Precisamente por esta razón, entender las uniones ayudará bastante a comprender esta forma de acceso a los datos de un archivo.
Antes de pasar al siguiente paso, prueba bastante este código 05, hasta entender realmente cómo funciona, es decir, hasta que consigas entender que los archivos no son más que arrays guardados en disco. En cuanto logres entender esto y consolidar este concepto, será mucho más simple entender lo que haremos a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_BIN)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. for (uchar c = 0; c < 10; c++) 14. FileWriteInteger(handle, c, CHAR_VALUE); 15. 16. FileFlush(handle); 17. 18. FileSeek(handle, 4, SEEK_SET); 19. FileWriteInteger(handle, 45, CHAR_VALUE); 20. 21. FileFlush(handle); 22. 23. FileSeek(handle, 4, SEEK_SET); 24. Print("The byte value of the ", FileTell(handle), " position in the file is ", FileReadInteger(handle, CHAR_VALUE)); 25. 26. FileClose(handle); 27. } 28. //+------------------------------------------------------------------+
Código 06
Ahora, observa este código 06. Como verás, se parece bastante a código 05. Sin embargo, aquí hacemos algo que va un poco más allá del código 05, ya que escribimos en el archivo mediante acceso completamente aleatorio. Aquí aparece una broma algo poco graciosa, si no conseguiste consolidar el concepto de array con el concepto de archivo. Esto ocurre porque, en este código 06, podemos realizar una operación que sería imposible si realmente estuviéramos trabajando con arrays. Al menos, de la forma en que se trabaja con la mayoría de los arrays.
Antes de explicar este código 06, veamos el resultado de su ejecución. Se muestra a continuación.
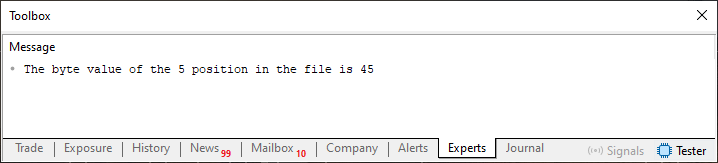
Imagen 07
Ahora viene la parte divertida: entender cómo se consiguió este mensaje de la imagen 07. Primero, observa que los únicos cambios en este código 06, respecto del código 05, son las líneas 18 y 19. Estas dos líneas sirven para cambiar el valor de una posición específica dentro del archivo. Sería como indicar cuál sería el nuevo valor en una posición dada dentro de un array. Hasta ahí, es muy simple de entender, ya que la posición indicada está dentro de lo que crea el bucle de la línea 13.
Puedes hacer lo mismo sin que necesariamente se haya creado alguna posición anterior. O, mejor dicho, no estás limitado a crear el array antes de asignar un valor a una posición dada. Recuerda que aquí estamos tratando con archivos. En este caso, podrías indicar una posición muy por encima del límite superior del array y, aun así, la operación funcionaría.
Tal vez esto haya quedado algo confuso. En la práctica es bastante simple. Cambia el valor de la función FileSeek de la línea 18 por un valor superior a los diez elementos creados por el bucle de la línea 13, como, por ejemplo, 14. No olvides cambiar también el valor de la línea 23 por el mismo valor usado en la línea 18. Esto hará que el código, al ejecutarse, genere el resultado que aparece a continuación.
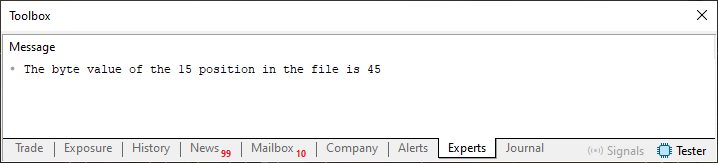
Imagen 08
¡Qué cosa tan extraña! Siempre imaginé que el archivo tendría que escribirse byte a byte, posición tras posición. Entonces, ¿podemos escribir en cualquier lugar, sin importar qué datos existan antes? Esto sí que es curioso. Mi querido lector, este tipo de situaciones es lo que hace que el trabajo de programación sea tan memorable y divertido, aunque, en algunos momentos, resulte algo confuso para quien empieza a verlo por primera vez.
Consideraciones finales
En este artículo, tuvimos lo que puede considerarse la primera experiencia con archivos de acceso aleatorio. Claro que, al decir esto, considero que tú, mi querido y estimado lector, no tenías idea de que existen tantos detalles relacionados con el trabajo con archivos.
Como, en este artículo, prácticamente nos concentramos en implementar la primera escritura en una posición arbitraria dentro de un archivo, no fue posible explicar algunos detalles relacionados con la indexación de datos dentro del archivo. Como esta cuestión es de extrema importancia, ya tenemos un tema para ver y tratar en el próximo artículo. Así que procura estudiar y practicar lo que se mostró aquí en este artículo y, para ello, aprovecha bien los códigos fuente incluidos en el anexo. Nos vemos en el próximo artículo.
| Archivo MQ5 | Descripción |
|---|---|
| Code 01 | Demostración de acceso a archivos |
| Code 02 | Demostración de acceso a archivos |
| Code 03 | Demostración de acceso a archivos |
| Code 04 | Demostración de acceso a archivos |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/16246
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso