
Del básico al intermedio: Colas, listas y árboles (IV)

Introducción
En el artículo anterior, Del básico al intermedio: colas, listas y árboles (III), se explicó todo lo básico y esencial sobre qué es realmente una lista enlazada. Vimos que, con un simple cambio en el código, podríamos construir una lista doblemente enlazada o una lista simplemente enlazada. Algo que muchos consideran difícil y complicado. Sin embargo, lo visto en el artículo anterior no muestra todo lo que se puede hacer con una lista enlazada. Tampoco explica por qué, en muchos casos, es la mejor opción cuando necesitamos implementar algún tipo de sistema cuyo objetivo sea analizar una gran cantidad de datos.
Recordemos que, originalmente, estos datos se colocarían en arrays. Sin embargo, el uso de arrays puede hacer que todo nuestro código sea bastante costoso en términos de rendimiento durante su ejecución. Para resolver precisamente esta cuestión, académicos e investigadores de ciencia de datos desarrollaron el mecanismo explicado en estos artículos. Recuerda que aquí estoy intentando explicar las cosas de la forma más sencilla y didáctica posible.
Muy bien, el mecanismo presentado hasta ahora solo nos permite insertar y eliminar valores situados en los extremos de la lista enlazada. Sin embargo, a menudo necesitamos añadir y eliminar valores en alguna posición intermedia. Y es precisamente este mecanismo el que falta por explicar, ya que todavía no se ha implementado. Entonces, sigamos con nuestro ritual, que consiste en eliminar cualquier tipo de distracción que pueda impedirte concentrarte en lo que veremos en el artículo. Empecemos a implementar la última parte para que la lista enlazada sea totalmente funcional. Como de costumbre, pasaremos a un nuevo tema para comenzar nuestro recorrido por el divertido mundo de la programación.
Colas, listas y árboles (IV)
En el artículo anterior, terminamos con el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. 25. (*loc).info = arg; 26. (*loc).prev = NULL; 27. switch(pos) 28. { 29. case SEEK_SET: 30. (*loc).start = start; 31. (*start).prev = loc; 32. start = loc; 33. break; 34. case SEEK_END: 35. if (prev != NULL) (*prev).start = loc; 36. (*loc).prev = prev; 37. prev = loc; 38. start = (start == NULL ? loc : start); 39. break; 40. } 41. } 42. //+----------------+ 43. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 44. { 45. stList <T> *loc = NULL; 46. 47. if ((prev == NULL) || (start == NULL)) 48. return false; 49. 50. switch (pos) 51. { 52. case SEEK_SET: 53. loc = start; 54. start = (*loc).start; 55. break; 56. case SEEK_END: 57. loc = prev; 58. prev = (*loc).prev; 59. break; 60. } 61. arg = (*loc).info; 62. 63. delete loc; 64. 65. return true; 66. } 67. //+----------------+ 68. void Debug(void) 69. { 70. Print("===== DEBUG ====="); 71. for (stList <T> *loc = prev; loc != NULL; loc = (*loc).prev) 72. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]",(*loc).start, loc, (*loc).prev, (*loc).info); 73. Print("================="); 74. } 75. //+----------------+ 76. }; 77. //+------------------------------------------------------------------+ 78. void OnStart(void) 79. { 80. stList <char> list; 81. 82. list.Store(10); 83. list.Store(84); 84. list.Store(-6); 85. list.Store(47, SEEK_SET); 86. 87. list.Debug(); 88. 89. for (char info; list.Restore(info, SEEK_SET);) 90. Print(info); 91. }; 92. //+------------------------------------------------------------------+
Código 01
Este código nos permite crear una lista que se comporte como una pila, o una lista que trabaje con algo parecido al principio FIFO (el primero que entra es el primero que sale). Todo esto de una forma muy sencilla. Para más detalles, consulta el artículo anterior. Sin embargo, aunque esta capacidad ya convierte al código 01 en algo bastante útil para resolver diversos problemas, no contiene el mecanismo para insertar o eliminar elementos de una lista, que no se encuentren en los extremos. En otras palabras: este código 01 solo nos permite eliminar o añadir el primer o el último elemento de la lista. NUNCA un elemento intermedio.
A pesar de ello, en el artículo anterior te lancé un desafío para que lo resolvieras. La idea era que tú, mi querido lector, pudieras comprobar hasta qué punto habías entendido lo explicado y mostrado en el artículo. Si lo superaste, debes felicitarte, aunque di algunas pistas sobre cómo hacerlo, no es tan fácil para quien está empezando a aprender programación. Esto se debe a que es necesario pensar en cómo resolver ciertos detalles del código que se va a implementar.
De cualquier forma, hayas conseguido resolver el problema propuesto en el artículo anterior o no, aquí veremos mi propuesta de solución. Recuerda que el objetivo es didáctico. Así que, manos a la obra.
Para empezar, vamos a revisar el resultado de la ejecución de este código 01. El resultado se muestra a continuación.
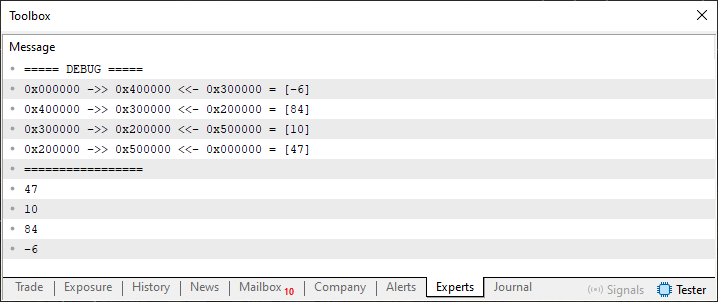
Imagen 01
La idea es eliminar primero uno de estos valores. En este caso, el valor 84 o el valor 10, sin modificar demasiado el código 01 ni copiar la lista que se muestra en la imagen 01 a otro lugar de la memoria. La manera más simple de hacerlo es modificar los valores prev y start de la propia lista para eliminar el elemento deseado. Bien, esta es la idea básica. Pero ¿cómo hacerlo? Si observas la imagen 01, notarás que en la sección donde depuramos la lista se muestra cómo se enlazan las direcciones. Supongamos que queremos eliminar el elemento cuyo valor es 84.
Si observas la imagen 01, verás que la dirección donde se encuentra este elemento es 0x300000; fíjate en la columna del medio. La dirección anterior es 0x200000 y la posterior, 0x400000. A partir de esta información, podemos definir una forma de eliminar el elemento cuyo valor es 84: para ello, necesitamos que el elemento anterior, el 10, apunte al siguiente, el -6, y que el elemento con valor -6 apunte al 10. Así, el elemento cuyo valor es 84 podrá eliminarse de la lista sin ningún problema.
Creo que ahora ya sabes lo que necesitamos hacer. Para que veas cómo se hace en la práctica, vamos a ver el código que elimina precisamente este elemento 84, que se muestra a continuación.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. //+----------------+ 012. public: 013. //+----------------+ 014. stList(void) 015. :prev(NULL), 016. start(NULL) 017. {} 018. //+----------------+ 019. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 020. { 021. stList <T> *loc; 022. 023. loc = new stList <T>; 024. 025. (*loc).info = arg; 026. (*loc).prev = NULL; 027. switch(pos) 028. { 029. case SEEK_SET: 030. (*loc).start = start; 031. (*start).prev = loc; 032. start = loc; 033. break; 034. case SEEK_END: 035. if (prev != NULL) (*prev).start = loc; 036. (*loc).prev = prev; 037. prev = loc; 038. start = (start == NULL ? loc : start); 039. break; 040. } 041. } 042. //+----------------+ 043. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 044. { 045. stList <T> *loc = NULL; 046. 047. if ((prev == NULL) || (start == NULL)) 048. return false; 049. 050. switch (pos) 051. { 052. case SEEK_SET: 053. loc = start; 054. start = (*loc).start; 055. break; 056. case SEEK_END: 057. loc = prev; 058. prev = (*loc).prev; 059. break; 060. } 061. arg = (*loc).info; 062. 063. delete loc; 064. 065. return true; 066. } 067. //+----------------+ 068. bool Exclude(const T arg) 069. { 070. stList <T> *loc = start, 071. *ptr = NULL; 072. 073. for (; loc != NULL; ptr = loc, loc = (*loc).start) 074. if ((*loc).info == arg) break; 075. 076. if (loc == NULL) return false; 077. 078. (*ptr).start = (*loc).start; 079. (*loc).start.prev = ptr; 080. 081. delete loc; 082. 083. return true; 084. } 085. //+----------------+ 086. void Debug(void) 087. { 088. Print("===== DEBUG ====="); 089. for (stList <T> *loc = prev; loc != NULL; loc = (*loc).prev) 090. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]",(*loc).start, loc, (*loc).prev, (*loc).info); 091. Print("================="); 092. } 093. //+----------------+ 094. }; 095. //+------------------------------------------------------------------+ 096. void OnStart(void) 097. { 098. stList <char> list; 099. 100. list.Store(10); 101. list.Store(84); 102. list.Store(-6); 103. list.Store(47, SEEK_SET); 104. 105. list.Debug(); 106. list.Exclude(84); 107. list.Debug(); 108. 109. for (char info; list.Restore(info, SEEK_SET);) 110. Print(info); 111. }; 112. //+------------------------------------------------------------------+
Código 02
Ahora, presta atención, querido lector. Este código 02 implementa precisamente lo explicado hace un momento. Es decir, cuando se ejecuta la línea 106, se llama a una función que elimina el elemento cuyo valor es 84. Antes de entrar en los detalles de cómo funciona esta función de la línea 68, veamos el resultado de la ejecución del código 02. El resultado se muestra a continuación.
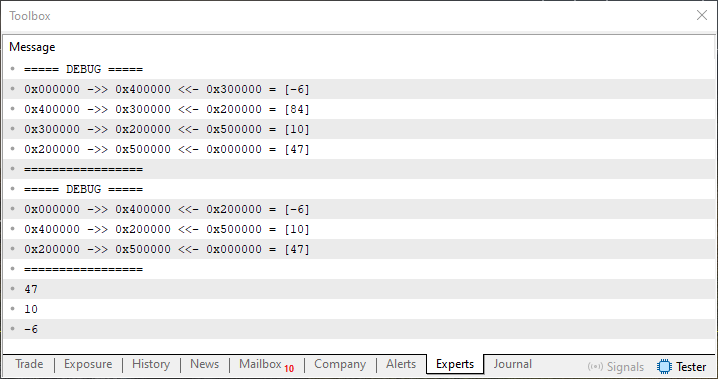
Imagen 02
Esta imagen 02 deja bastante claro lo que se está haciendo. Si observas los valores que se imprimieron debido a la línea 105, notarás que, cuando se ejecuta la línea 107, las direcciones de los elementos -6 y 10 se modifican. De este modo, el elemento con valor 84 deja de formar parte de la lista. Pero espera un momento, ¿adónde fue el elemento cuyo valor era 84? Bien, querido lector, este elemento fue destruido. Para entenderlo, ahora vamos a ver el código que realiza precisamente esta tarea.
Para simplificar al máximo la explicación y que no confundas una lista enlazada con otra cosa, al principio trabajaremos solo con los valores de los elementos. Así, la función de la línea 68 recibirá el valor del elemento que queremos eliminar de la lista enlazada. Como no sabemos dónde se encuentra este elemento en la lista, ya que puede estar en cualquier lugar, inicializaremos algunas variables auxiliares en las líneas 70 y 71. Ahora empezaremos a buscar el elemento en la lista. El bucle de la línea 73 se encarga de esta búsqueda. Cuando se encuentre el elemento, la línea 74 finalizará el bucle.
También puede ocurrir que el elemento no se encuentre. En este caso, el bucle terminará cuando no quede ningún otro elemento en la lista. Por esta razón, necesitamos la línea 76 para comprobar si se ha llegado al final de la lista o si se ha encontrado el elemento que debe eliminarse. Si encontramos el elemento que vamos a eliminar, ejecutaremos las siguientes líneas. De lo contrario, la función de eliminación terminará.
Bien, ahora viene la parte que confunde a mucha gente. Como el elemento tiene un nodo anterior y otro siguiente, debemos enlazar directamente el nodo anterior con el siguiente. Solo así podremos eliminar el elemento encontrado. Para crear este enlace, necesitamos las líneas 78 y 79. Una vez establecido este enlace, el elemento puede eliminarse. La eliminación se lleva a cabo en la línea 81. Al final, la lista enlazada continúa funcionando perfectamente, como si nada hubiera cambiado.
Esta fue la parte fácil. Procura entender muy bien lo explicado hasta ahora, porque viene la parte que hace que mucha gente desee enviar al infierno a las personas que crearon o implementaron el concepto de lista enlazada. Así de grande es la confusión que muchos generan con lo que veremos a partir de ahora.
Para empezar, indicar qué valor se debe eliminar de una lista enlazada no es muy práctico. Aunque en algunos casos podamos llegar a utilizar este enfoque, en la práctica no se usa demasiado. Lo que hacen muchos programadores es implementar el mecanismo de otra manera.
En el artículo anterior expliqué que una lista enlazada puede entenderse como un array. También expliqué por qué surgieron las listas enlazadas. Como una lista enlazada puede entenderse como un array, lo más práctico es indicar el índice del valor que queremos eliminar. Piensa en la siguiente situación: puedes estar trabajando con cualquier conjunto de valores y, aunque no sepas cuál es el valor que se debe eliminar, muy probablemente sí sabrás dónde está. Entonces, ¿no sería mucho más práctico indicar el índice del valor? De hecho, lo sería, querido lector. Sin embargo, existe un pequeño problema. Y ese problema puede verse en los propios códigos presentados hasta ahora.
Para explicarlo, vamos a usar el código 02 como referencia. Observa lo siguiente: en la línea 100, comenzamos nuestra lista con el valor 10; luego, insertamos el valor 84, seguido del valor -6. Sin embargo, el valor 47 se colocó antes del elemento con valor 10. Podríamos tener muchos otros valores insertados en cualquier punto de la lista, como veremos más adelante. Pero, por el momento, mantengámonos en estos valores y en este problema. La pregunta es: ¿en qué posición se encuentra el valor 84? Si prestas atención, verás que está en el índice dos. Recuerda que la numeración empieza en cero. Sin embargo, si miras el código sin entenderlo, pensarás que el valor 84 está en el índice uno. Esto se debe a que se añade después del elemento de valor 10, pero eso sería correcto si no fuera por la línea 103, donde añadimos el elemento de valor 47 ANTES del elemento de valor 10. Precisamente este tipo de cosas es lo que genera una gran confusión entre muchos principiantes.
Existe una segunda cuestión, menos compleja y confusa. Según cómo recorras la lista enlazada, es posible que acabes eliminando el elemento equivocado. Esto ocurre cuando se recorre la lista de atrás hacia adelante. Por esta razón, hay que tener mucho cuidado al definir cuál será el primer y el último elemento. Puede parecer una tontería, pero si llegas a crear una lista enlazada circular, este tipo de situación puede volver la implementación realmente muy confusa. Aunque las listas enlazadas circulares no son muy comunes, precisamente por la confusión que generan al determinar cuál es el primer elemento, es posible que necesites crear una. Y, si esto ocurre, ten cuidado al implementar el código.
Bien, entonces ya conocemos algunos de los peligros que debemos afrontar. Y también ya sabemos cómo visualizar la lista enlazada, para hacernos una idea de cuánto se parece a un array. Así que, podemos pasar a la parte divertida, que es precisamente implementar el código que usará índices en lugar de valores. El código correspondiente se muestra a continuación.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END, const uint index = 0) 030. { 031. stList <T> *loc; 032. 033. loc = new stList <T>; 034. 035. (*loc).info = arg; 036. (*loc).prev = NULL; 037. switch(pos) 038. { 039. case SEEK_SET: 040. (*loc).start = start; 041. (*start).prev = loc; 042. start = loc; 043. break; 044. case SEEK_CUR: 045. break; 046. case SEEK_END: 047. if (prev != NULL) (*prev).start = loc; 048. (*loc).prev = prev; 049. prev = loc; 050. start = (start == NULL ? loc : start); 051. break; 052. } 053. counter++; 054. } 055. //+----------------+ 056. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 057. { 058. stList <T> *loc = NULL; 059. 060. if ((prev == NULL) || (start == NULL)) 061. return false; 062. 063. switch (pos) 064. { 065. case SEEK_SET: 066. loc = start; 067. start = (*loc).start; 068. if (start != NULL) 069. (*start).prev = NULL; 070. break; 071. case SEEK_END: 072. loc = prev; 073. prev = (*loc).prev; 074. if (prev != NULL) 075. (*prev).start = NULL; 076. break; 077. } 078. arg = (*loc).info; 079. 080. return RemoveNode(loc); 081. } 082. //+----------------+ 083. bool Exclude(const uint index) 084. { 085. T arg; 086. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 087. 088. if (pos == SEEK_CUR) 089. { 090. stList <T> *loc = start, 091. *ptr = NULL; 092. 093. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (*loc).start, c++); 094. if (loc == NULL) return false; 095. 096. (*ptr).start = (*loc).start; 097. (*loc).start.prev = ptr; 098. 099. return RemoveNode(loc); 100. } 101. 102. return Restore(arg, pos); 103. } 104. //+----------------+ 105. void Debug(void) 106. { 107. Print("===== DEBUG ====="); 108. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 109. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 110. Print("================="); 111. } 112. //+----------------+ 113. }; 114. //+------------------------------------------------------------------+ 115. void OnStart(void) 116. { 117. stList <char> list; 118. 119. list.Store(10); 120. list.Store(84); 121. list.Store(-6); 122. list.Store(47, SEEK_SET); 123. 124. list.Debug(); 125. 126. list.Exclude(2); 127. 128. list.Debug(); 129. 130. for (char info; list.Restore(info, SEEK_SET);) 131. Print(info); 132. }; 133. //+------------------------------------------------------------------+
Código 03
Venga, tienes que estar bromeando, ¿qué clase de código tan loco es este? Bueno, quizá haya exagerado un poco al presentarlo de esta manera. (RISAS). Este código no es tan loco. Para ser sincero, es muy fácil de entender, aunque no sea el más bonito. Pero veamos qué hace este código. Primero, añadí una nueva variable en la línea once. Esta variable nos indica el número de elementos de la lista. Es algo parecido a usar la función ArraySizepara saber cuántos elementos hay actualmente en un array dinámico.
Como este número puede variar al añadir o eliminar elementos, las líneas 16 y 53 se encargan de ajustarlo. Observa que en la línea 44 de este código 03 ya estoy reservando una nueva opción que se implementará pronto. Pero centrémonos en la parte responsable de eliminar los elementos. Observa que ahora la función Exclude de la línea 83 recibe un valor que indica qué elemento debemos eliminar de la lista. Esto se determina según la posición que ocupa el elemento en la lista.
Ahora, presta atención, querido lector, porque esta parte es bastante interesante: leer los elementos de la lista es una actividad destructiva. Es decir, cuando leamos la lista, en cualquier orden, eliminaremos ese elemento. Podemos aprovechar esto. Cuando el índice recibido sea igual a cero, podemos usar la propia función Restore de la línea 56 para eliminar el primer elemento de la lista. Lo mismo ocurre si estamos eliminando el último elemento de la lista. Para ello, usamos la línea 86, que nos indica si el elemento que se va a eliminar es el primero, el último o algún elemento intermedio.
Si el elemento que se va a eliminar está en una posición intermedia de la lista, se cumplirá la comprobación de la línea 88 y podremos hacer algo parecido a lo que se hizo en el código 02. A diferencia de lo que se hizo en el código 02, en el código 03 la comprobación que usamos para encontrar el elemento que vamos a eliminar es distinta. En este caso, basta con observar el bucle de la línea 93 y compararlo con el del código 02. Verás que aquí estamos usando un contador para encontrar el elemento que se va a eliminar. No sabemos exactamente dónde está. Solo sabemos qué índice debemos usar. El resto del código es básicamente igual que en el código 02.
De este modo, cuando se ejecute la línea 126, el código 03 producirá el mismo resultado que vimos al ejecutar el código 02. Es decir, la imagen 02. Este código 03 es muy interesante, pero podemos hacer algo un poco diferente. Antes de mostrar cómo será el código de inserción de elementos en la lista, vamos a hacer un experimento con este código 03. El experimento se muestra a continuación.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END, const uint index = 0) 030. { 031. stList <T> *loc; 032. 033. loc = new stList <T>; 034. 035. (*loc).info = arg; 036. (*loc).prev = NULL; 037. switch(pos) 038. { 039. case SEEK_SET: 040. (*loc).start = start; 041. (*start).prev = loc; 042. start = loc; 043. break; 044. case SEEK_CUR: 045. break; 046. case SEEK_END: 047. if (prev != NULL) (*prev).start = loc; 048. (*loc).prev = prev; 049. prev = loc; 050. start = (start == NULL ? loc : start); 051. break; 052. } 053. counter++; 054. } 055. //+----------------+ 056. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 057. { 058. stList <T> *loc = NULL; 059. 060. if ((prev == NULL) || (start == NULL)) 061. return false; 062. 063. switch (pos) 064. { 065. case SEEK_SET: 066. loc = start; 067. start = (*loc).start; 068. if (start != NULL) 069. (*start).prev = NULL; 070. break; 071. case SEEK_END: 072. loc = prev; 073. prev = (*loc).prev; 074. if (prev != NULL) 075. (*prev).start = NULL; 076. break; 077. } 078. arg = (*loc).info; 079. 080. return RemoveNode(loc); 081. } 082. //+----------------+ 083. bool Exclude(const int arg) 084. { 085. T tmp; 086. uint index = MathAbs(arg); 087. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 088. 089. if (pos == SEEK_CUR) 090. { 091. stList <T> *loc = (arg < 0 ? prev : start), 092. *ptr = NULL; 093. 094. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (arg < 0 ? (*loc).prev : (*loc).start), c++); 095. if (loc == NULL) return false; 096. 097. if (arg < 0) 098. { 099. (*ptr).prev = (*loc).prev; 100. (*loc).prev.start = ptr; 101. }else{ 102. (*ptr).start = (*loc).start; 103. (*loc).start.prev = ptr; 104. } 105. 106. return RemoveNode(loc); 107. } 108. 109. return Restore(tmp, pos); 110. } 111. //+----------------+ 112. void Debug(void) 113. { 114. Print("===== DEBUG ====="); 115. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 116. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 117. Print("================="); 118. } 119. //+----------------+ 120. }; 121. //+------------------------------------------------------------------+ 122. void OnStart(void) 123. { 124. stList <char> list; 125. 126. list.Store(10); 127. list.Store(84); 128. list.Store(-6); 129. list.Store(47, SEEK_SET); 130. 131. list.Debug(); 132. 133. list.Exclude(-2); 134. 135. list.Debug(); 136. 137. for (char info; list.Restore(info, SEEK_SET);) 138. Print(info); 139. }; 140. //+------------------------------------------------------------------+
Código 04
El experimento consistió en cambiar el tipo de argumento que puede recibir la función Exclude. Observa que, a diferencia del código 03, en el código 04 podemos pasar valores positivos y negativos a la función Exclude. Pero, ¿qué significa esto en la práctica? Pues bien, mi querido lector, esto significa que podemos eliminar elementos tanto desde el inicio como desde el final de la lista. Vaya, no das tregua. Apenas consigo empezar a entender el código y ya vienes a complicarlo todavía más. ¿No te cansas nunca? Ni un poco, mi querido lector. Me parece muy divertido lo que podemos hacer. Y, cuanto más confuso parece volverse el mecanismo, más me divierto creando el código.
A pesar de esta aparente confusión, entenderás fácilmente lo que ocurrirá. Observa que lo único que hubo que cambiar en el código 04 fue la forma en que funcionará el bucle de búsqueda. También fue necesario hacer un pequeño ajuste porque podemos recorrer la lista tanto desde el principio como desde el final.
¿Cómo controlamos esto? Esta es la parte sencilla, querido lector. Si el valor del argumento de la función Exclude es positivo, trabajaremos de la misma forma que en el código 03. Si el valor es negativo, el recorrido se interpretará de otra manera. Para empezar, necesitamos convertir siempre el valor en positivo. Esto sirve para evitar problemas. Para ello, usamos la línea 86 para obtener el valor correcto, independientemente de si es positivo o negativo. Si se ejecuta el bucle de la línea 94, cambiaremos la dirección del recorrido. Es decir, si el valor es negativo, siempre apuntará al elemento anterior. Si es positivo, apuntaremos al siguiente. En cualquier caso, aquí se apuntará a algún elemento. Pero ahora viene la parte en la que necesitamos reajustar los punteros de manera adecuada.
Como podemos recorrer la lista de atrás hacia adelante, los punteros pueden quedar invertidos. Por esta razón, en la línea 97 comprobamos en qué sentido se está recorriendo la lista. Si la estamos recorriendo en sentido inverso, es decir, del final al inicio, necesitamos usar las líneas 99 y 100 para corregir adecuadamente los punteros. Al final, el resultado siempre será correcto, siempre que se tenga el cuidado necesario.
Para demostrarlo, observa que en la línea 133 estamos pasando un valor negativo como argumento a la función Exclude. Por lo tanto, se eliminará el elemento de índice dos, contando desde el final de la lista. Si has entendido todo lo que hemos hecho desde el principio, sabrás que este elemento tiene el valor 10, por lo que, al ejecutar este código 04, el resultado será el que se muestra en la siguiente imagen.
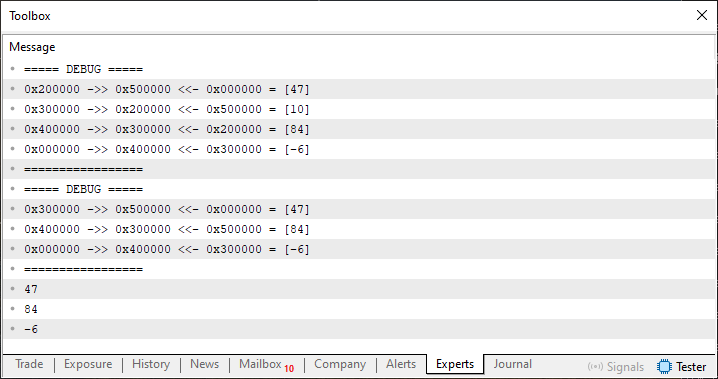
Imagen 03
Muy bien, basta de bromas. Ha llegado el momento de implementar la parte responsable de insertar valores en posiciones arbitrarias de la lista. Algo parecido a lo que acabamos de hacer con el método de eliminación. Como ya puedes imaginar, no lo implementaremos de cualquier manera; iremos experimentando con el código a medida que lo construyamos. Así entenderás mejor cómo funciona el mecanismo y por qué se implementa de esa manera.
Bien, entonces centrémonos en el código 04, que es el responsable de almacenar los valores en la lista. Si observas la instrucción switch de la línea 37, verás que, para insertar un nuevo elemento al final o al inicio de la lista, se ejecutan una serie de pasos. Estos pasos sirven precisamente para configurar la dirección de memoria del elemento anterior y del siguiente al nuevo elemento que estamos añadiendo. Es muy importante que notes cómo se hace esto. De hecho, la diferencia entre colocar el nuevo elemento al inicio o al final de la cola está en qué puntero recibirá la referencia al nuevo elemento. Pero ¿cómo es eso? Pues bien, mi estimado lector, si observas el case de la línea 39, verás que estamos añadiendo un nuevo elemento al inicio de la cola. La razón está en la línea 42.
Si miras el caso de la línea 46, verás que estamos añadiendo el elemento al final de la cola. La línea 49 se encarga de eso. Ahora surge una cuestión. Cuando indiquemos un índice, la lógica cambiará, ya que en este caso pasaremos a informar de dónde se insertará el elemento. Pero en este punto hay que pensar el mecanismo con calma. Y el motivo, en cierta forma, está relacionado precisamente con lo que vimos al eliminar elementos de la lista.
Para no complicar el mecanismo de entrada, hagamos lo siguiente: insertemos un nuevo elemento tomando como referencia el inicio de la lista. El siguiente código muestra lo que necesitamos hacer.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END, const uint index = 0) 030. { 031. stList <T> *loc; 032. 033. loc = new stList <T>; 034. 035. (*loc).info = arg; 036. (*loc).prev = NULL; 037. switch(pos) 038. { 039. case SEEK_SET: 040. (*loc).start = start; 041. (*start).prev = loc; 042. start = loc; 043. break; 044. case SEEK_CUR: 045. { 046. stList <T> *ptr1 = start, 047. *ptr2 = NULL; 048. 049. for (uint c = 0; (ptr1 != NULL) && (c < index); ptr2 = ptr1, ptr1 = (*ptr1).start, c++); 050. 051. (*loc).start = (ptr2 != NULL ? (*ptr2).start : ptr1); 052. (*loc).prev = (ptr1 != NULL ? (*ptr1).prev : ptr2); 053. if (ptr2 != NULL) (*ptr2).start = loc; else start = loc; 054. if (ptr1 != NULL) (*ptr1).prev = loc; else prev = loc; 055. } 056. break; 057. case SEEK_END: 058. if (prev != NULL) (*prev).start = loc; 059. (*loc).prev = prev; 060. prev = loc; 061. start = (start == NULL ? loc : start); 062. break; 063. } 064. counter++; 065. } 066. //+----------------+ 067. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 068. { 069. stList <T> *loc = NULL; 070. 071. if ((prev == NULL) || (start == NULL)) 072. return false; 073. 074. switch (pos) 075. { 076. case SEEK_SET: 077. loc = start; 078. start = (*loc).start; 079. if (start != NULL) 080. (*start).prev = NULL; 081. break; 082. case SEEK_END: 083. loc = prev; 084. prev = (*loc).prev; 085. if (prev != NULL) 086. (*prev).start = NULL; 087. break; 088. } 089. arg = (*loc).info; 090. 091. return RemoveNode(loc); 092. } 093. //+----------------+ 094. bool Exclude(const uint index) 095. { 096. T tmp; 097. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 098. 099. if (pos == SEEK_CUR) 100. { 101. stList <T> *loc = start, 102. *ptr = NULL; 103. 104. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (*loc).start, c++); 105. if (loc == NULL) return false; 106. 107. (*ptr).start = (*loc).start; 108. (*loc).start.prev = ptr; 109. 110. return RemoveNode(loc); 111. } 112. 113. return Restore(tmp, pos); 114. } 115. //+----------------+ 116. void Debug(void) 117. { 118. Print("===== DEBUG ====="); 119. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 120. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 121. Print("================="); 122. } 123. //+----------------+ 124. }; 125. //+------------------------------------------------------------------+ 126. void OnStart(void) 127. { 128. stList <char> list; 129. 130. list.Store(10); 131. list.Store(84); 132. list.Store(-6); 133. list.Store(47, SEEK_SET); 134. 135. list.Debug(); 136. 137. list.Store(35, SEEK_CUR, 2); 138. 139. list.Debug(); 140. 141. for (char info; list.Restore(info, SEEK_SET);) 142. Print(info); 143. }; 144. //+------------------------------------------------------------------+
Código 05
Antes de explicar cómo funciona este código 05, ¿qué tal ver el resultado de su ejecución? Esto se muestra en la siguiente imagen.
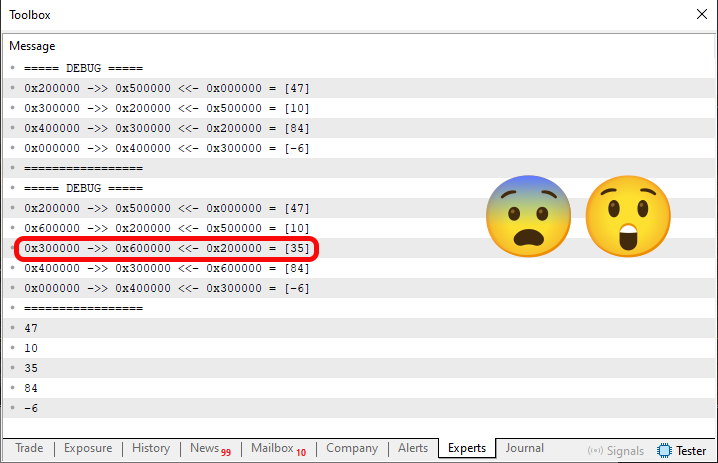
Imagen 04
Bien, en esta imagen 04, muestro el resultado de insertar un valor en una posición determinada de la lista. Al observar el código 05, es posible que te preguntes: «¿Cómo hiciste esto?». Como el objetivo es ser didáctico, he simplificado el código 04. Esto se puede ver en el código 05, en la parte relativa a la eliminación de valores. Sin embargo, en este código lo que realmente nos interesa es la inserción de valores. Por esta razón, quiero que intentes establecer un paralelismo entre el código de eliminación, que se encuentra en la línea 94, y el código de inclusión, que se encuentra entre las líneas 44 y 56.
Una vez más, el objetivo es ser lo más didáctico posible. Si comparas el código de exclusión con el de inclusión, verás que gran parte es similar. Muchos se pierden en este punto: el código de inserción necesita tres punteros, mientras que el código de exclusión solo necesita dos. ¿Y a qué se debe esta diferencia? El motivo es sencillo.
Cuando insertamos un valor en la lista, no movemos ningún valor, como se haría si estuviéramos trabajando con arrays. En el caso de una lista enlazada, solo es necesario ajustar los punteros para que indiquen el elemento anterior o siguiente de un elemento de la lista. Por eso, el código que inserta realmente un nuevo elemento en la lista corresponde a las líneas 53 y 54. Es decir, usamos dos instrucciones if para ajustar adecuadamente la lista. Para que la estructura de la lista se mantenga intacta, usamos las líneas 51 y 52 para que el elemento que vamos a insertar apunte a los elementos ya existentes.
Ahora, presta atención. Estas líneas que acabo de mencionar permiten crear la lista doblemente enlazada sin necesidad de utilizar el código de los casos SEEK_SET y SEEK_END. Es decir, este código dentro del caso SEEK_CUR puede insertar elementos al principio, al final o en una posición arbitraria de la lista. Basta con indicar el índice que se va a utilizar.
Mmm... Déjame ver si he entendido bien. Me estás diciendo que este código 05 se puede modificar para reducir la cantidad de código. Aun así, funcionará y dará el mismo resultado que el de la imagen 04, ¿no? Sí, mi estimado lector. Este código 05 se creó de esta manera para que pudieras entender cómo se puede implementar el mecanismo. Este mismo código 05 puede modificarse para obtener el resultado que se muestra a continuación.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const uint index = 0xFFFFFFFF) 030. { 031. stList <T> *loc, 032. *ptr1 = start, 033. *ptr2 = NULL; 034. 035. for (uint c = 0; (ptr1 != NULL) && (c < index); ptr2 = ptr1, ptr1 = (*ptr1).start, c++); 036. 037. loc = new stList <T>; 038. (*loc).info = arg; 039. (*loc).start = (ptr2 != NULL ? (*ptr2).start : ptr1); 040. (*loc).prev = (ptr1 != NULL ? (*ptr1).prev : ptr2); 041. if (ptr2 != NULL) (*ptr2).start = loc; else start = loc; 042. if (ptr1 != NULL) (*ptr1).prev = loc; else prev = loc; 043. 044. counter++; 045. } 046. //+----------------+ 047. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 048. { 049. stList <T> *loc = NULL; 050. 051. if ((prev == NULL) || (start == NULL)) 052. return false; 053. 054. switch (pos) 055. { 056. case SEEK_SET: 057. loc = start; 058. start = (*loc).start; 059. if (start != NULL) 060. (*start).prev = NULL; 061. break; 062. case SEEK_END: 063. loc = prev; 064. prev = (*loc).prev; 065. if (prev != NULL) 066. (*prev).start = NULL; 067. break; 068. } 069. arg = (*loc).info; 070. 071. return RemoveNode(loc); 072. } 073. //+----------------+ 074. bool Exclude(const uint index) 075. { 076. T tmp; 077. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 078. 079. if (pos == SEEK_CUR) 080. { 081. stList <T> *loc = start, 082. *ptr = NULL; 083. 084. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (*loc).start, c++); 085. if (loc == NULL) return false; 086. 087. (*ptr).start = (*loc).start; 088. (*loc).start.prev = ptr; 089. 090. return RemoveNode(loc); 091. } 092. 093. return Restore(tmp, pos); 094. } 095. //+----------------+ 096. void Debug(void) 097. { 098. Print("===== DEBUG ====="); 099. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 100. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 101. Print("================="); 102. } 103. //+----------------+ 104. }; 105. //+------------------------------------------------------------------+ 106. void OnStart(void) 107. { 108. stList <char> list; 109. 110. list.Store(10); 111. list.Store(84); 112. list.Store(-6); 113. list.Store(47, 0); 114. 115. list.Debug(); 116. 117. list.Store(35, 2); 118. 119. list.Debug(); 120. 121. for (char info; list.Restore(info, SEEK_SET);) 122. Print(info); 123. }; 124. //+------------------------------------------------------------------+
Código 06
Ahora presta mucha, muchísima atención a lo que voy a explicar. De lo contrario, perderás el hilo. y no entenderás lo que haremos después. Si observas el procedimiento de la línea 29 de este código 06, verás que ha cambiado, pero muy ligeramente. Ahora, este procedimiento solo recibirá el elemento que se va a almacenar junto con un índice. Para que el código 06 siga funcionando igual que el código 05 en lo que respecta al contenido del procedimiento OnStart, el índice predeterminado del procedimiento Store es el límite superior de la lista. Es decir, si no se indica ningún valor como índice de posición del elemento, SIEMPRE colocaremos el nuevo elemento en el tope o al final de la lista, como prefieras.
Es muy importante que entiendas esto, querido lector. De lo contrario, podrías intentar implementar el mecanismo de una forma mientras el código lo ejecuta de otra. Para que esto quede más claro, compara el procedimiento OnStart de este código 06 con el mismo procedimiento del código 05. Verás que son muy parecidos.
Ahora, para terminar, vamos a realizar un pequeño ajuste en este mismo código 06. Esto nos permitirá leer el elemento de cualquier posición de la lista. Recuerda que, al realizar esta lectura, eliminaremos de la lista el valor leído. Pero, como el objetivo aquí es didáctico, no veo problema en hacerlo. Así que, una vez aplicado el cambio, obtendremos el código que se muestra a continuación.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. public: 014. //+----------------+ 015. stList(void) 016. :prev(NULL), 017. start(NULL), 018. counter(0) 019. {} 020. //+----------------+ 021. void Store(T arg, const uint index = 0xFFFFFFFF) 022. { 023. stList <T> *loc, 024. *ptr1 = start, 025. *ptr2 = NULL; 026. 027. for (uint c = 0; (ptr1 != NULL) && (c < index); ptr2 = ptr1, ptr1 = (*ptr1).start, c++); 028. 029. loc = new stList <T>; 030. (*loc).info = arg; 031. (*loc).start = (ptr2 != NULL ? (*ptr2).start : ptr1); 032. (*loc).prev = (ptr1 != NULL ? (*ptr1).prev : ptr2); 033. if (ptr2 != NULL) (*ptr2).start = loc; else start = loc; 034. if (ptr1 != NULL) (*ptr1).prev = loc; else prev = loc; 035. 036. counter++; 037. } 038. //+----------------+ 039. bool Restore(T &arg, const uint index = 0xFFFFFFFF) 040. { 041. if ((prev == NULL) || (start == NULL)) 042. return false; 043. 044. stList <T> *loc = (index < counter ? start : prev), 045. *ptr = NULL; 046. 047. for (uint c = 0; (loc != NULL) && (c < index) && (index < counter); ptr = loc, loc = (*loc).start, c++); 048. if (loc == NULL) return false; 049. 050. if (index == 0) 051. { 052. start = (*loc).start; 053. if (start != NULL) (*start).prev = NULL; 054. } else if (index >= (counter - 1)) 055. { 056. prev = (*loc).prev; 057. if (prev != NULL) (*prev).start = NULL; 058. } 059. else 060. { 061. (*ptr).start = (*loc).start; 062. (*loc).start.prev = ptr; 063. } 064. arg = (*loc).info; 065. delete loc; 066. counter--; 067. 068. return true; 069. } 070. //+----------------+ 071. bool Exclude(const uint index) 072. { 073. T tmp; 074. 075. return Restore(tmp, index); 076. } 077. //+----------------+ 078. void Debug(void) 079. { 080. Print("===== DEBUG ====="); 081. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 082. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 083. Print("================="); 084. } 085. //+----------------+ 086. }; 087. //+------------------------------------------------------------------+ 088. void OnStart(void) 089. { 090. stList <char> list; 091. 092. list.Store(10); 093. list.Store(84); 094. list.Store(-6); 095. list.Store(47, 0); 096. 097. list.Debug(); 098. 099. list.Exclude(3); 100. list.Store(35, 2); 101. 102. list.Debug(); 103. 104. for (char info; list.Restore(info, 0);) 105. Print(info); 106. }; 107. //+------------------------------------------------------------------+
Código 07
Este código 07 es casi una versión final de la implementación de una lista doblemente enlazada. Pero lo que realmente nos interesa es el resultado que puede generar. Cuando se ejecute, nos proporcionará el resultado que se muestra a continuación.
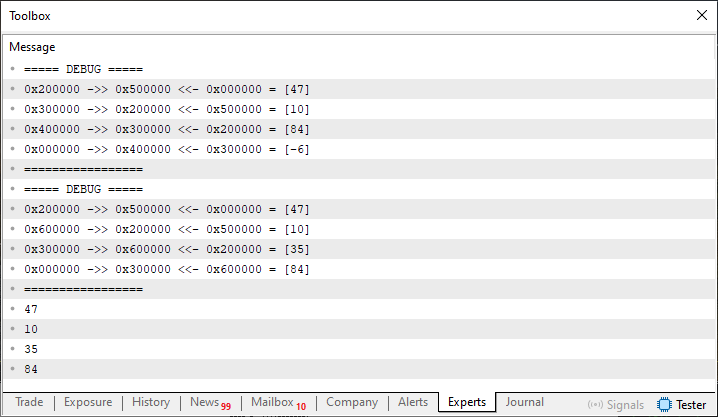
Imagen 05
Observa que este código 07 es mucho más sencillo que los demás que hemos visto hasta ahora. Sin embargo, te resultará más fácil si has entendido los pasos necesarios para llegar a este punto. Si se hubiera presentado de entrada como el primer y único código, sin duda te costaría mucho entender cómo funciona. Pero creo que no hace falta que dé más explicaciones al respecto, teniendo en cuenta que los cambios se hicieron poco a poco.
Consideraciones finales
En este artículo, vimos cómo implementar una lista enlazada perfectamente funcional. Quedó un punto por explicar: el hecho de que toda lectura que hagamos elimina el elemento leído de la lista. Hay formas de evitarlo. Como todavía no se ha explicado cómo trabajar con clases de forma adecuada, no profundizaré en este tema por ahora. Así que lo dejaremos para otra ocasión. En el próximo artículo veremos qué resulta de la evolución de una lista enlazada. El resultado de esta evolución dará lugar a un nuevo tipo de estructura de datos.
| MQ5 | Descripción |
|---|---|
| Código 01 | Lista simple |
| Código 02 | Lista simple |
| Código 03 | Lista simple |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/16669
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Utilizando redes neuronales en MetaTrader
Utilizando redes neuronales en MetaTrader
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso