
Desarrollo de asesores expertos autooptimizables en MQL5 (Parte 7): Trading con múltiples períodos simultáneamente

Los indicadores técnicos ofrecen al inversor moderno numerosas oportunidades y, a la vez, desafíos de magnitud similar. Los indicadores técnicos presentan numerosas limitaciones bien conocidas, como su retardo inherente, que han sido ampliamente debatidas.
En este análisis, queremos centrarnos en los retos más sutiles relacionados con la identificación del período adecuado para su indicador. El período de un indicador es un parámetro común a la mayoría de los indicadores técnicos que controla la cantidad de datos históricos en los que se basa el indicador para sus cálculos.
En términos generales, seleccionar valores de período demasiado pequeños hace que el indicador técnico capte una cantidad considerable de ruido del mercado, mientras que los valores de período demasiado grandes a menudo generarán señales mucho después de que el movimiento del mercado ya se haya producido. En ambos casos, se pierden oportunidades de trading y el rendimiento resulta deficiente.
La solución que proponemos en este artículo nos permite eliminar la complejidad de identificar el período óptimo y, en su lugar, utilizar todos los períodos disponibles a la vez. Para lograr este objetivo, presentaremos al lector una familia de algoritmos de aprendizaje automático conocidos como algoritmos de reducción de dimensionalidad, con especial atención a un algoritmo relativamente nuevo conocido como aproximación y proyección uniforme de variedades (UMAP). Posteriormente, demostraremos que esta familia de algoritmos nos permite emplear todos los datos disponibles que describen un problema en una representación significativa que proporciona una comprensión más profunda que la que nos ofrecía el conjunto de datos en su forma original.
Además, también consideraremos los principios relevantes de la Programación Orientada a Objetos (POO) en MQL5 que son necesarios para que podamos crear clases útiles que nos ayuden a gestionar de forma eficiente el espacio de nombres, el uso de la memoria y otras operaciones rutinarias necesarias para nuestras aplicaciones de trading. Entre las 4 clases que escribiremos juntos, crearemos una clase específica que nos permitirá desarrollar rápidamente aplicaciones basadas en modelos ONNX. Tenemos mucho que cubrir; comencemos.
Creación de las clases que necesitamos en MQL5
En nuestro análisis anterior sobre asesores expertos autooptimizables, creamos una clase RSI que nos proporcionó una forma significativa y organizada de obtener datos de indicadores en muchos períodos RSI diferentes. Los lectores que no estén familiarizados con ese debate pueden ponerse al día rápidamente siguiendo el enlace que se proporciona aquí. Para este análisis, sin embargo, dejaremos de lado el RSI y lo sustituiremos por el indicador Williams Percent Range (WPR).
El WPR se considera generalmente un oscilador de momento, y su rango total posible va de 0 a -100. Las lecturas entre 0 y -20 se consideran bajistas, mientras que las lecturas entre -80 y -100 se consideran alcistas. El indicador funciona básicamente comparando el precio actual de un símbolo determinado con el máximo alcanzado dentro del período seleccionado por el usuario. Nuestro primer objetivo será crear una nueva clase llamada "SingleBufferIndicator" que será compartida por nuestras clases RSI y WPR. Al hacer que nuestras clases RSI y WPR compartan una clase padre común, experimentaremos una funcionalidad coherente en ambas clases de indicadores. Comenzaremos definiendo la clase "SingleBufferIndicator" y enumerando sus miembros.
Este enfoque de diseño nos ofrece muchas ventajas; por ejemplo, si en el futuro queremos que todas las clases de indicadores tengan una nueva funcionalidad, solo necesitamos actualizar una clase, la clase padre "SingleBufferIndicator.mqh", y a partir de ahí solo necesitamos compilar las clases hijas para que las actualizaciones estén disponibles. La herencia es una característica indispensable de la programación orientada a objetos porque nos permite controlar eficazmente muchas clases modificando únicamente una de ellas.
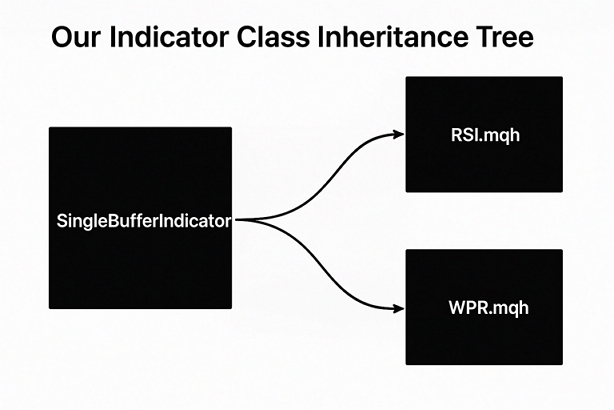
Figura 1: Visualización del árbol de herencia de nuestra familia de indicadores de búfer único.
Para empezar, generalizaremos la funcionalidad que utilizamos al diseñar la clase RSI para que sea adecuada para cualquier indicador que tenga solo un búfer. El lector debe tener en cuenta que MetaTrader 5 ofrece un conjunto completo de indicadores entre los que puede elegir. El hecho de que estemos creando una clase para indicadores con un solo búfer debería informar al lector de que existen indicadores que tienen más de un búfer. Al diseñar clases, generalmente queremos que la clase tenga un propósito claro y definido.
Intentar diseñar una única clase que gestione todos los indicadores, independientemente de la cantidad de búferes que tengan, puede resultar demasiado difícil de lograr de una sola vez. Además, si no se tiene cuidado en el diseño, el código puede contener errores lógicos y otros fallos involuntarios. Por lo tanto, al limitar el alcance de la clase, nos estamos preparando para el éxito.
//+------------------------------------------------------------------+ //| SingleBufferIndicator.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class SingleBufferIndicator { public: //--- Class methods bool SetIndicatorValues(int buffer_size,bool set_as_series); double GetReadingAt(int index); bool SetDifferencedIndicatorValues(int buffer_size,int differencing_period,bool set_as_series); double GetDifferencedReadingAt(int index); double GetCurrentReading(void); //--- Have the indicator values been copied to the buffer? bool indicator_values_initialized; bool indicator_differenced_values_initialized; //--- How far into the future we wish to forecast int forecast_horizon; //--- The buffer for our indicator double indicator_reading[]; vector indicator_differenced_values; //--- The current size of the buffer the user last requested int indicator_buffer_size; int indicator_differenced_buffer_size; //--- The handler for our indicator int indicator_handler; //--- The time frame our indicator should be applied on ENUM_TIMEFRAMES indicator_time_frame; //--- The price should the indicator be applied on ENUM_APPLIED_PRICE indicator_price; //--- Give the user feedback string user_feedback(int flag); //--- The Symbol our indicator should be applied on string indicator_symbol; //--- Our period int indicator_period; //--- Is our indicator valid? bool IsValid(void); //---- Testing the Single Buffer Indicator Class //--- This method should be deleted in production virtual void Test(void); }; //+------------------------------------------------------------------+
Ahora necesitamos un método que copie las lecturas del indicador desde nuestro manejador del indicador al búfer de indicadores. El método tiene dos parámetros: uno que especifica la cantidad de datos que se van a copiar y otro que especifica cómo queremos ordenar los datos. Cuando el segundo parámetro es verdadero, los datos se ordenan desde el pasado hasta el presente.
//+------------------------------------------------------------------+ //| Set our indicator values and our buffer size | //+------------------------------------------------------------------+ bool SingleBufferIndicator::SetIndicatorValues(int buffer_size,bool set_as_series) { //--- Buffer size indicator_buffer_size = buffer_size; CopyBuffer(this.indicator_handler,0,0,buffer_size,indicator_reading); //--- Should the array be set as series? if(set_as_series) ArraySetAsSeries(this.indicator_reading,true); indicator_values_initialized = true; //--- Did something go wrong? vector indicator_test; indicator_test.CopyIndicatorBuffer(indicator_handler,0,0,buffer_size); if(indicator_test.Sum() == 0) return(false); //--- Everything went fine. return(true); }
En el aprendizaje automático, registrar el cambio en una variable puede ser más informativo que la lectura sin procesar. Por lo tanto, vamos a crear también un método específico que calcule el cambio en la lectura del indicador y lo copie en un búfer de indicadores.
//+--------------------------------------------------------------+ //| Let's set the conditions for our differenced data | //+--------------------------------------------------------------+ bool SingleBufferIndicator::SetDifferencedIndicatorValues(int buffer_size,int differencing_period,bool set_as_series) { //--- Internal variables indicator_differenced_buffer_size = buffer_size; indicator_differenced_values = vector::Zeros(indicator_differenced_buffer_size); //--- Prepare to record the differences in our RSI readings double temp_buffer[]; int fetch = (indicator_differenced_buffer_size + (2 * differencing_period)); CopyBuffer(indicator_handler,0,0,fetch,temp_buffer); if(set_as_series) ArraySetAsSeries(temp_buffer,true); //--- Fill in our values iteratively for(int i = indicator_differenced_buffer_size;i > 1; i--) { indicator_differenced_values[i-1] = temp_buffer[i-1] - temp_buffer[i-1+differencing_period]; } //--- If the norm of a vector is 0, the vector is empty! if(indicator_differenced_values.Norm(VECTOR_NORM_P) != 0) { Print(user_feedback(2)); indicator_differenced_values_initialized = true; return(true); } indicator_differenced_values_initialized = false; Print(user_feedback(3)); return(false); }
Ahora que hemos definido métodos para copiar los valores de los indicadores en los búferes, necesitamos métodos para recuperar los datos que contienen. Tenga en cuenta que podríamos haber declarado fácilmente el búfer indicador como un miembro público de la clase, lo que nos permitiría recuperar rápidamente los valores que deseamos. El problema con ese enfoque es que contradice el propósito de crear una clase, que es tener una forma uniforme de leer y escribir en los objetos.
//--- Get a differenced value at a specific index double SingleBufferIndicator::GetDifferencedReadingAt(int index) { //--- Make sure we're not trying to call values beyond our index if(index > indicator_differenced_buffer_size) { Print(user_feedback(4)); return(-1e10); } //--- Make sure our values have been set if(!indicator_differenced_values_initialized) { //--- The user is trying to use values before they were set in memory Print(user_feedback(1)); return(-1e10); } //--- Return the differenced value of our indicator at a specific index if((indicator_differenced_values_initialized) && (index < indicator_differenced_buffer_size)) return(indicator_differenced_values[index]); //--- Something went wrong. return(-1e10); }
El método anterior devolvía la lectura del indicador diferenciada; se necesita un método equivalente que devuelva las lecturas reales del indicador tal como aparecen en él.
//+------------------------------------------------------------------+ //| Get a reading at a specific index from our RSI buffer | //+------------------------------------------------------------------+ double SingleBufferIndicator::GetReadingAt(int index) { //--- Is the user trying to call indexes beyond the buffer? if(index > indicator_buffer_size) { Print(user_feedback(4)); return(-1e10); } //--- Get the reading at the specified index if((indicator_values_initialized) && (index < indicator_buffer_size)) return(indicator_reading[index]); //--- User is trying to get values that were not set prior else { Print(user_feedback(1)); return(-1e10); } }
También pensé que sería útil tener una función dedicada a devolver el valor del indicador en el índice 0, es decir, la lectura actual del indicador.
//+------------------------------------------------------------------+ //| Get our current reading from the RSI indicator | //+------------------------------------------------------------------+ double SingleBufferIndicator::GetCurrentReading(void) { double temp[]; CopyBuffer(this.indicator_handler,0,0,1,temp); return(temp[0]); }
Esta función nos informará si nuestro manejador se ha cargado correctamente. Es una medida de seguridad muy útil para nosotros.
//+------------------------------------------------------------------+ //| Check if our indicator handler is valid | //+------------------------------------------------------------------+ bool SingleBufferIndicator::IsValid(void) { return((this.indicator_handler != INVALID_HANDLE)); }
A medida que nuestro usuario interactúa con la clase indicadora, queremos ofrecerle indicaciones sobre cualquier error que pueda haber cometido y la solución adecuada para corregirlo.
//+------------------------------------------------------------------+ //| Give the user feedback on the actions he is performing | //+------------------------------------------------------------------+ string SingleBufferIndicator::user_feedback(int flag) { string message; //--- Check if the indicator loaded correctly if(flag == 0) { //--- Check the indicator was loaded correctly if(IsValid()) message = "Indicator Class Loaded Correcrtly \nSymbol: " + (string) indicator_symbol + "\nPeriod: " + (string) indicator_period; return(message); //--- Something went wrong message = "Error loading Indicator: [ERROR] " + (string) GetLastError(); return(message); } //--- User tried getting indicator values before setting them if(flag == 1) { message = "Please set the indicator values before trying to fetch them from memory, call SetIndicatorValues()"; return(message); } //--- We sueccessfully set our differenced indicator values if(flag == 2) { message = "Succesfully set differenced indicator values."; return(message); } //--- Failed to set our differenced indicator values if(flag == 3) { message = "Failed to set our differenced indicator values: [ERROR] " + (string) GetLastError(); return(message); } //--- The user is trying to retrieve an index beyond the buffer size and must update the buffer size first if(flag == 4) { message = "The user is attempting to use call an index beyond the buffer size, update the buffer size first"; return(message); } //--- The class has been deactivated by the user if(flag == 5) { message = "Goodbye."; return(message); } //--- No feedback else return(""); }
Una vez hecho esto, ya podemos construir nuestra clase WPR, que heredará de su clase padre, la clase SingleBufferIndicator. En resumen, su árbol de dependencias debería parecerse a la Figura 1 si pretende seguir el artículo.
Figura 2: Nuestro árbol de dependencias para nuestras clases de indicadores.
Pasemos ahora al primer paso que daremos en nuestra clase WPR, que consistirá en incluir la clase SingleBufferIndicator en la clase WPR.
//+------------------------------------------------------------------+ //| WPR.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the parent class | //+------------------------------------------------------------------+ #include <VolatilityDoctor\Indicators\SingleBuffer\SingleBufferIndicator.mqh>
En esta ocasión, antes de definir los miembros de la clase WPR, especificaremos que la clase extiende la clase SingleBufferIndicator utilizando la sintaxis de dos puntos, ":". Así es como extendemos las clases en MQL5. Para los lectores que no estén familiarizados con los conceptos de la programación orientada a objetos (POO), extender una clase nos permite llamar a los métodos que escribimos en la clase SingleBufferIndicator desde dentro de la clase WPR. Al hacer que nuestras clases WPR y RSI extiendan la clase SingleBufferIndicator, experimentaremos una funcionalidad coherente en ambas clases. En otras palabras, todos los miembros de clase públicos que hemos incorporado a nuestra clase SingleBufferIndicator estarán disponibles en cualquier clase que la extienda.
//+------------------------------------------------------------------+ //| This class will provide us with usefull functionality for the WPR| //+------------------------------------------------------------------+ class WPR : public SingleBufferIndicator { public: WPR(); WPR(string user_symbol,ENUM_TIMEFRAMES user_time_frame,int user_period); ~WPR(); };
Los indicadores WPR y RSI tienen un solo búfer; sin embargo, requieren parámetros diferentes para su inicialización. Por lo tanto, tiene más sentido que el constructor sea específico para cada instancia de indicador, ya que las firmas de sus constructores pueden variar considerablemente de un indicador a otro.
//+------------------------------------------------------------------+ //| Our default constructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::WPR() { indicator_values_initialized = false; indicator_symbol = "EURUSD"; indicator_time_frame = PERIOD_D1; indicator_period = 5; indicator_handler = iWPR(indicator_symbol,indicator_time_frame,indicator_period); //--- Give the user feedback on initilization Print(user_feedback(0)); //--- Remind the user they called the default constructor Print("Default Constructor Called: ",__FUNCSIG__," ",&this); }
El constructor paramétrico permite al usuario especificar con qué símbolo, marco temporal y período debe inicializarse el indicador WPR.
//+------------------------------------------------------------------+ //| Our parametric constructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::WPR(string user_symbol,ENUM_TIMEFRAMES user_time_frame,int user_period) { indicator_values_initialized = false; indicator_symbol = user_symbol; indicator_time_frame = user_time_frame; indicator_period = user_period; indicator_handler = iWPR(indicator_symbol,indicator_time_frame,indicator_period); //--- Give the user feedback on initilization Print(user_feedback(0)); }
El destructor de la clase restablecerá nuestras banderas importantes y liberará el indicador por nosotros. En MQL5, es una buena práctica limpiar los recursos después de usarlos. Al crear una clase dedicada para este propósito, se reduce la carga cognitiva del desarrollador, ya que no es necesario estar pendiente de repetir el proceso de limpieza constantemente, puesto que la clase lo hace en su nombre.
//+------------------------------------------------------------------+ //| Our destructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::~WPR() { //--- Free up resources we don't need and reset our flags if(IndicatorRelease(indicator_handler)) { indicator_differenced_values_initialized = false; indicator_values_initialized = false; Print(user_feedback(5)); } } //+------------------------------------------------------------------+
Otra funcionalidad que necesitaremos es la capacidad de identificar cuándo se ha formado completamente una nueva vela. En estos casos, nos gustaría realizar ciertas tareas. Por lo tanto, dedicaremos una clase a este objetivo, ya que es esencial para nosotros, y en algunos casos puede que queramos realizar un seguimiento de la formación de velas en diferentes marcos temporales a la vez. Comenzaremos por declarar los miembros de la clase que necesita nuestra clase Time.
//+------------------------------------------------------------------+ //| Time.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class Time { private: datetime time_stamp; datetime current_time; string selected_symbol; ENUM_TIMEFRAMES selected_time_frame; public: Time(string user_symbol,ENUM_TIMEFRAMES user_time_frame); bool NewCandle(void); ~Time(); };
Observe que la clase no tiene un constructor predeterminado; esto se ha hecho deliberadamente. En este caso particular, los constructores predeterminados no tendrían mucho sentido.
//+------------------------------------------------------------------+ //| Create our time object | //+------------------------------------------------------------------+ Time::Time(string user_symbol,ENUM_TIMEFRAMES user_time_frame) { selected_time_frame = user_time_frame; selected_symbol = user_symbol; current_time = iTime(user_symbol,selected_time_frame,0); time_stamp = iTime(user_symbol,selected_time_frame,0); }
Actualmente, el destructor de la clase está vacío.
//+------------------------------------------------------------------+ //| Our destructor is currently empty | //+------------------------------------------------------------------+ Time::~Time() { } //+------------------------------------------------------------------+
Por último, necesitamos un método que nos informe si se ha formado una nueva vela. Este método devolverá verdadero si se ha formado una nueva vela, lo que nos permite ejecutar nuestras rutinas periódicamente.
//+------------------------------------------------------------------+ //| Check if a new candle has fully formed | //+------------------------------------------------------------------+ bool Time::NewCandle(void) { current_time = iTime(selected_symbol,selected_time_frame,0); //--- Check if a new candle has formed if(time_stamp != current_time) { time_stamp = current_time; return(true); } //--- No new candle has completely formed return(false); }
A continuación, también necesitaremos una clase específica para gestionar nuestros objetos ONNX. A medida que nuestros proyectos crecen y se vuelven más complejos, no queremos repetir ciertos pasos varias veces. En última instancia, tal vez nos convenga más tener una clase ONNXFloat para todos nuestros modelos ONNX que acepten tipos de datos float. En el momento de redactar este texto, el tipo de datos float es ampliamente aceptado como un tipo de datos estable para usar al ejecutar modelos ONNX. Comencemos con la clase ONNXFloat definiendo sus miembros.
//+------------------------------------------------------------------+ //| ONNXFloat.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| This class will help us work with ONNX Float models. | //+------------------------------------------------------------------+ class ONNXFloat { private: //--- Our ONNX model handler long onnx_model; int onnx_outputs; public: //--- Is our Model Valid? bool OnnxModelIsValid(void); //--- Define the input shape of our model bool DefineOnnxInputShape(int n_index,int n_stacks,int n_input_params); //--- Define the output shape of our model bool DefineOnnxOutputShape(int n_index,int n_stacks, int n_output_params); vectorf Predict(const vectorf &model_inputs); //--- ONNXFloat class constructor ONNXFloat(const uchar &user_proto[]); //---- ONNXFloat class destructor ~ONNXFloat(); };
El constructor de nuestra clase acepta un prototipo de modelo ONNX y crea el modelo ONNX a partir del búfer proporcionado por el usuario. Tenga en cuenta que los búferes del modelo ONNX solo se pueden pasar por referencia, no por valor. El signo de ampersand, "&", colocado delante del nombre del búfer del modelo ONNX "&user_proto" indica explícitamente que este parámetro es una referencia a un objeto en memoria. Siempre que una función tenga un parámetro que se pase por referencia, se espera que el usuario entienda que cualquier cambio que se realice en el parámetro dentro de la función, modificará el parámetro original fuera de la función.
En nuestro caso, no pretendemos editar el prototipo ONNX; por lo tanto, modificamos el parámetro a "const", indicando al programador y al compilador que no se deben realizar cambios. Por lo tanto, si el programador ignora nuestras directivas, el compilador no lo aceptará.
//+------------------------------------------------------------------+ //| Parametric Constructor For Our ONNXFloat class | //+------------------------------------------------------------------+ ONNXFloat::ONNXFloat(const uchar &user_proto[]) { onnx_model = OnnxCreateFromBuffer(user_proto,ONNX_DATA_TYPE_FLOAT); if(OnnxModelIsValid()) Print("Volatility Doctor ONNXFloat Class Loaded Correctly: ",__FUNCSIG__," ",&this); else Print("Failed To Create The specified ONNX model: ",GetLastError()); }
El destructor de la clase ONNXFloat liberará automáticamente la memoria que asignamos a nuestro modelo ONNX.
//+------------------------------------------------------------------+ //| Our ONNXFloat class destructor | //+------------------------------------------------------------------+ ONNXFloat::~ONNXFloat() { OnnxRelease(onnx_model); } //+------------------------------------------------------------------+
También necesitaremos una función específica que nos informe si nuestro modelo ONNX es válido, devolviendo un indicador booleano que solo será verdadero si el modelo es válido.
//+------------------------------------------------------------------+ //| A method that returns true if our ONNXFloat model is valid | //+------------------------------------------------------------------+ bool ONNXFloat::OnnxModelIsValid(void) { //--- Check if the model is valid if(onnx_model != INVALID_HANDLE) return(true); //--- Something went wrong return(false); }
Configurar la forma de entrada de cualquier modelo ONNX es un paso preparatorio necesario que probablemente necesitaremos con frecuencia.
//+------------------------------------------------------------------+ //| Set the input shape of our ONNXFloat model | //+------------------------------------------------------------------+ bool ONNXFloat::DefineOnnxInputShape(int n_index,int n_stacks,int n_input_params) { const ulong model_input_shape[] = {n_stacks,n_input_params}; if(OnnxSetInputShape(onnx_model,n_index,model_input_shape)) { Print("Succefully specified ONNX model output shape: ",__FUNCTION__," ",&this); return(true); } //--- Something went wrong Print("Failed to set the passed ONNX model output shape: ",GetLastError()); return(false); }
Lo mismo ocurre con la forma de salida del modelo ONNX.
//+------------------------------------------------------------------+ //| Set the output shape of our model | //+------------------------------------------------------------------+ bool ONNXFloat::DefineOnnxOutputShape(int n_index,int n_stacks,int n_output_params) { const ulong model_output_shape[] = {n_output_params,n_stacks}; onnx_outputs = n_output_params; if(OnnxSetOutputShape(onnx_model,n_index,model_output_shape)) { Print("Succefully specified ONNX model input shape: ",__FUNCSIG__," ",&this); return(true); } //--- Something went wrong Print("Failed to set the passed ONNX model input shape: ",GetLastError()); return(false); }
Por último, necesitamos una función de predicción. Esta función tomará los datos de entrada del modelo ONNX por referencia, y como no tenemos intención de cambiar los datos de entrada, modificamos este parámetro para que sea una constante. Esto evita que cualquier efecto secundario no deseado corrompa los datos de entrada y, lo que es más importante, le indica a nuestro compilador que evite que cometamos errores por descuido que pudieran alterar las entradas del modelo. Estas características de seguridad son invaluables, y el hecho de que estén integradas en el lenguaje de programación convierte a MQL5 en un lenguaje de programación de primera clase.
//+------------------------------------------------------------------+ //| Get a prediction from our model | //+------------------------------------------------------------------+ vectorf ONNXFloat::Predict(const vectorf &model_inputs) { vectorf model_output(onnx_outputs); if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_output)) { vectorf res = model_output; return(res); } Comment("Failed to get a prediction from our ONNX model"); Print("ONNX Run Failed: ",GetLastError()); vectorf res = {10e8}; return(res); }
La última clase que necesitaremos se encargará de obtener información útil sobre las operaciones, como el volumen mínimo de operación o el precio Ask actual.
//+------------------------------------------------------------------+ //| TradeInfo.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class TradeInfo { private: string user_symbol; ENUM_TIMEFRAMES user_time_frame; double min_volume,max_volume,volume_step; public: TradeInfo(string selected_symbol,ENUM_TIMEFRAMES selected_time_frame); double MinVolume(void); double MaxVolume(void); double VolumeStep(void); double GetAsk(void); double GetBid(void); double GetClose(void); string GetSymbol(void); ~TradeInfo(); };
El constructor de la clase paramétrica toma 2 parámetros que especifican el símbolo y el período de tiempo deseados.
//+------------------------------------------------------------------+ //| The constructor will load our symbol information | //+------------------------------------------------------------------+ TradeInfo::TradeInfo(string selected_symbol,ENUM_TIMEFRAMES selected_time_frame) { //--- Which symbol are you interested in? user_symbol = selected_symbol; user_time_frame = selected_time_frame; if(SymbolSelect(user_symbol,true)) { //--- Load symbol details min_volume = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_MIN); max_volume = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_MAX); volume_step = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_STEP); Print("Trade Info Loaded Successfully: ",__FUNCSIG__); } else { Print("Error Symbol Information Could Not Be Found For: ",selected_symbol," ",GetLastError()); } }
También definiremos métodos para obtener las lecturas actuales de cada una de las 4 fuentes de precios principales; es decir, cada uno de estos métodos devuelve los precios actuales de apertura, máximo, mínimo y cierre, respectivamente.
//+------------------------------------------------------------------+ //| Return the close of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetClose(void) { double res = iClose(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the open of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetOpen(void) { double res = iOpen(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the high of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetHigh(void) { double res = iHigh(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the low of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetLow(void) { double res = iLow(user_symbol,user_time_frame,0); return(res); }
Cuando se trabaja con varios símbolos, resulta útil tener un recordatorio de a qué símbolo se ha asignado la instancia actual de la clase.
//+------------------------------------------------------------------+ //| Return the selected symbol | //+------------------------------------------------------------------+ string TradeInfo::GetSymbol(void) { string res = user_symbol; return(res); }
Nuestra clase también proporciona funciones auxiliares para recuperar rápidamente información importante sobre los niveles de volumen permitidos en el símbolo actual.
//+------------------------------------------------------------------+ //| Return the volume step allowed | //+------------------------------------------------------------------+ double TradeInfo::VolumeStep(void) { double res = volume_step; return(res); } //+------------------------------------------------------------------+ //| Return the minimum volume allowed | //+------------------------------------------------------------------+ double TradeInfo::MinVolume(void) { double res = min_volume; return(res); } //+------------------------------------------------------------------+ //| Return the maximum volume allowed | //+------------------------------------------------------------------+ double TradeInfo::MaxVolume(void) { double res = max_volume; return(res); }
También necesitaremos que la clase nos facilite fácilmente los precios de compra y venta actuales.
//+------------------------------------------------------------------+ //| Return the current ask | //+------------------------------------------------------------------+ double TradeInfo::GetAsk(void) { return(SymbolInfoDouble(GetSymbol(),SYMBOL_ASK)); } //+------------------------------------------------------------------+ //| Return the current bid | //+------------------------------------------------------------------+ double TradeInfo::GetBid(void) { return(SymbolInfoDouble(GetSymbol(),SYMBOL_BID)); }
Actualmente, nuestro destructor de clase Time está vacío.
//+------------------------------------------------------------------+ //| Destructor is currently empty | //+------------------------------------------------------------------+ TradeInfo::~TradeInfo() { } //+------------------------------------------------------------------+
En resumen, si nos ha seguido hasta el final, su árbol de dependencias debería parecerse a la Figura 3 que aparece a continuación.
Figura 3: Estas clases deben mantenerse en un árbol de dependencias similar al nuestro, para los lectores que estén siguiendo el ejemplo.
Ahora vamos a definir el script que obtendrá los datos de mercado relevantes que necesitamos. Primero queremos obtener las cuatro fuentes de precios principales (OHLC), seguidas del crecimiento de estas 4 fuentes de precios y, finalmente, escribiremos los datos de los indicadores de nuestros 14 indicadores WPR.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 10 //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <VolatilityDoctor\Indicators\WPR.mqh> //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ WPR *my_wpr_array[14]; string file_name = Symbol() + " WPR Algorithmic Input Selection.csv"; //+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //--- How much data should we store in our indicator buffer? int fetch = size + (2 * HORIZON); //--- Store pointers to our WPR objects for(int i = 0; i <= 13; i++) { //--- Create an WPR object my_wpr_array[i] = new WPR(Symbol(),PERIOD_CURRENT,((i+1) * 5)); //--- Set the WPR buffers my_wpr_array[i].SetIndicatorValues(fetch,true); my_wpr_array[i].SetDifferencedIndicatorValues(fetch,HORIZON,true); } //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Open","True High","True Low","True Close","Open","High","Low","Close","WPR 5","WPR 10","WPR 15","WPR 20","WPR 25","WPR 30","WPR 35","WPR 40","WPR 45","WPR 50","WPR 55","WPR 60","WPR 65","WPR 70","Diff WPR 5","Diff WPR 10","Diff WPR 15","Diff WPR 20","Diff WPR 25","Diff WPR 30","Diff WPR 35","Diff WPR 40","Diff WPR 45","Diff WPR 50","Diff WPR 55","Diff WPR 60","Diff WPR 65","Diff WPR 70"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(Symbol(),PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(Symbol(),PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(Symbol(),PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(Symbol(),PERIOD_CURRENT,i + HORIZON), my_wpr_array[0].GetReadingAt(i), my_wpr_array[1].GetReadingAt(i), my_wpr_array[2].GetReadingAt(i), my_wpr_array[3].GetReadingAt(i), my_wpr_array[4].GetReadingAt(i), my_wpr_array[5].GetReadingAt(i), my_wpr_array[6].GetReadingAt(i), my_wpr_array[7].GetReadingAt(i), my_wpr_array[8].GetReadingAt(i), my_wpr_array[9].GetReadingAt(i), my_wpr_array[10].GetReadingAt(i), my_wpr_array[11].GetReadingAt(i), my_wpr_array[12].GetReadingAt(i), my_wpr_array[13].GetReadingAt(i), my_wpr_array[0].GetDifferencedReadingAt(i), my_wpr_array[1].GetDifferencedReadingAt(i), my_wpr_array[2].GetDifferencedReadingAt(i), my_wpr_array[3].GetDifferencedReadingAt(i), my_wpr_array[4].GetDifferencedReadingAt(i), my_wpr_array[5].GetDifferencedReadingAt(i), my_wpr_array[6].GetDifferencedReadingAt(i), my_wpr_array[7].GetDifferencedReadingAt(i), my_wpr_array[8].GetDifferencedReadingAt(i), my_wpr_array[9].GetDifferencedReadingAt(i), my_wpr_array[10].GetDifferencedReadingAt(i), my_wpr_array[11].GetDifferencedReadingAt(i), my_wpr_array[12].GetDifferencedReadingAt(i), my_wpr_array[13].GetDifferencedReadingAt(i) ); } } //--- Close the file FileClose(file_handle); //--- Delete our WPR object pointers for(int i = 0; i <= 13; i++) { delete my_wpr_array[i]; } } //+------------------------------------------------------------------+ #undef HORIZON
Analizando nuestros datos con Python
Una vez que hayas terminado, aplica el script al mercado que hayas elegido para que podamos analizar los datos del mercado. En este análisis, aplicaremos el script al par EURGBP y, ahora que nuestros datos están listos, cargaremos nuestras bibliotecas de Python para el análisis.
#Load the libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Leer los datos.
#Read in the data data = pd.read_csv("..\EURGBP WPR Algorithmic Input Selection.csv") #Label the data HORIZON = 10 data['Target'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last 10 rows data = data.iloc[:-HORIZON,:]
Crea copias de la entrada y del destino.
#Define inputs and target X = data.iloc[:,1:-1].copy() y = data.iloc[:,-1].copy()
Escala y centra cada columna numérica del conjunto de datos.
#Store Z-scores Z1 = X.mean() Z2 = X.std() #Scale the data X = ((X - Z1)/ Z2)
Cargamos las bibliotecas numéricas que necesitamos para comprobar nuestra precisión.
from sklearn.model_selection import cross_val_score,TimeSeriesSplit from sklearn.linear_model import Ridge
Cree un objeto de validación cruzada de series temporales.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)sdvdsvds Defina un método que siempre devuelva nuestros niveles de precisión validados de forma cruzada.
#Return our cross validated accuracy def score(f_model,f_X,f_y): return(np.mean(np.abs(cross_val_score(f_model,f_X,f_y,scoring='neg_mean_squared_error',cv=tscv,n_jobs=-1))))
También necesitaremos un método específico para devolver un nuevo modelo; esto garantiza que no se filtren datos a los modelos que utilizamos.
def get_model(): return(Ridge())
Mantener una columna completamente llena de ceros permite medir la precisión con la que se predice siempre la rentabilidad media del mercado.
X['Null'] = 0
Registre el error producido al predecir siempre el rendimiento promedio del mercado (suma total de cuadrados/TSS). Ahora que hemos registrado el umbral de error definido al predecir siempre el rendimiento promedio del mercado, podemos afirmar con seguridad que cualquier modelo que produzca niveles de error superiores a 0,000324 no tiene ninguna habilidad que nos impresione, en lo que respecta a esta discusión.
#This will be the last entry in our list of results #Record our error if we always predict the average market return (total sum of squares/TSS) tss = score(get_model(),X[['Null']],y) tss
0.00032439931180771236
Ahora crearemos una matriz que nos ayudará a realizar un seguimiento de nuestros resultados.
res = []
El primer resultado que queremos registrar son nuestros niveles de error utilizando los datos de mercado OHLC en su formato original.
#This will be our first entry in our list of results #Record our error using OHLC price data res.append(score(get_model(),X.iloc[:,:8],y))
A continuación, nos gustaría conocer nuestros niveles de error utilizando únicamente los 14 períodos del indicador WPR que hemos seleccionado.
#Second #Record our error using just indicators res.append(score(get_model(),X.iloc[:,8:-1],y))
Finalmente, registremos nuestros niveles de error utilizando todos los datos que tenemos disponibles.
#Third #Record our error using all the data we have res.append(score(get_model(),X.iloc[:,:-1],y))
Ahora carga la biblioteca UMAP. Nuestros datos originales tienen 36 columnas; la biblioteca UMAP nos ayudará a representar estos datos utilizando cualquier número de columnas mayor o igual a 1 y menor que el número original de columnas. Esta nueva representación de los datos puede resultar más informativa que los datos en su formato original. Por lo tanto, en este sentido, los algoritmos de reducción de dimensionalidad también pueden considerarse como una familia de métodos que nos permiten utilizar eficazmente todos los datos que tenemos para describir nuestro problema.
import umap
Queremos buscar una cantidad de embeddings que sea como máximo 2 menos que el número original de columnas.
EPOCHS = X.iloc[:,:-1].shape[1] - 2
Generamos embeddings de forma iterativa utilizando UMAP. El número de columnas generadas aumentará desde 1, en incrementos de 1, hasta el límite superior que establecimos en la línea de código anterior.
for i in range(EPOCHS): reducer = umap.UMAP(n_components=(i+1),metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(X.iloc[:,:-1])) res.append(score(get_model(),X_embedded,y))
Únete a nuestros resultados.
res.append(tss)
La línea roja continua representa nuestro punto de referencia de error crítico, el error que se produce al predecir siempre la rentabilidad media del mercado (TSS). La línea de puntos roja representa el nivel de error más bajo que logramos obtener. Esto corresponde al modelo que se construyó cuando nuestro algoritmo UMAP integró nuestros datos originales en 2 columnas. Observe que este nivel de error supera al TSS por un margen mayor que el que pudimos lograr al utilizar los datos de mercado en su formato original. Básicamente, estamos utilizando todos los períodos del WPR a la vez, de una manera más significativa de lo que podríamos haber logrado de otro modo.
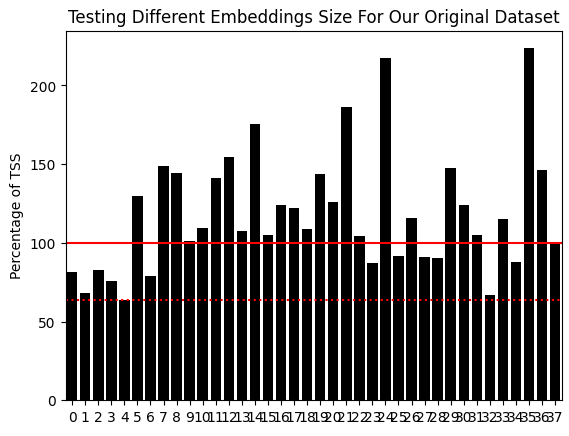
Figura 4: Utilizando 2 componentes UMAP integrados, superamos a un modelo equivalente que utilizaba todos los datos de mercado en su formato original.
Transforme los datos utilizando la configuración UMAP ideal que hemos identificado.
reducer = umap.UMAP(n_components=2,metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(X.iloc[:,:-1]))
Etiqueta nuestras 2 clases. Esto nos ayudará más adelante a visualizar qué está haciendo UMAP con nuestros datos.
data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1
Prepare a dataset to store the transformed data.
umap_data =pd.DataFrame(columns=['UMAP 1','UMAP 2'])
Almacenar los niveles de precios integrados.
umap_data['UMAP 1'] = X_embedded.iloc[:,0] umap_data['UMAP 2'] = X_embedded.iloc[:,1]
Sin UMAP, resulta difícil visualizar nuestros datos de forma significativa debido a la gran cantidad de dimensiones. De hecho, lo mejor que podemos hacer es crear pares de diagramas de dispersión; de lo contrario, no hay forma de visualizar eficazmente 36 dimensiones a la vez. En las figuras 5 y 6 que aparecen a continuación, los puntos rojos indican una tendencia alcista del precio y los puntos negros representan una tendencia bajista.
fig , axs = plt.subplots(2,2) fig.suptitle('Visualizing EURGBP 2002-2025 Daily Price Data') axs[0,0].scatter(data.loc[data['Target']>0 ,'Open'],data.loc[data['Target']>0 ,'Close'],color='red') axs[0,0].scatter(data.loc[data['Target']<0 ,'Open'],data.loc[data['Target']<0 ,'Close'],color='black') axs[0,1].scatter(data.loc[data['Target']>0 ,'True Open'],data.loc[data['Target']>0 ,'True Close'],color='red') axs[0,1].scatter(data.loc[data['Target']<0 ,'True Open'],data.loc[data['Target']<0 ,'True Close'],color='black') axs[1,1].scatter(data.loc[data['Target']>0 ,'WPR 5'],data.loc[data['Target']>0 ,'WPR 50'],color='red') axs[1,1].scatter(data.loc[data['Target']<0 ,'WPR 5'],data.loc[data['Target']<0 ,'WPR 50'],color='black') axs[1,0].scatter(data.loc[data['Target']>0 ,'WPR 15'],data.loc[data['Target']>0 ,'WPR 25'],color='red') axs[1,0].scatter(data.loc[data['Target']<0 ,'WPR 15'],data.loc[data['Target']<0 ,'WPR 25'],color='black')
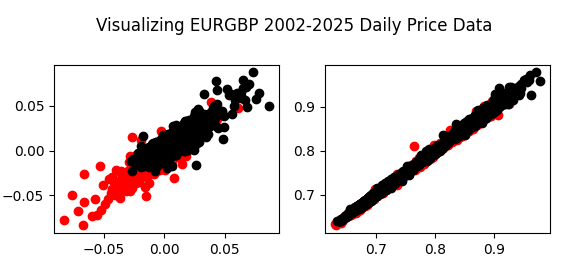
Figura 5: A la izquierda hemos representado gráficamente la variación del precio de apertura frente a la variación del precio de cierre. En el lado derecho, hemos representado gráficamente el precio real de apertura y cierre.
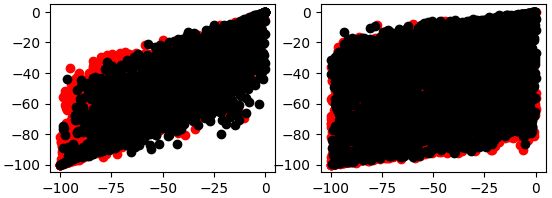
Figura 6: El diagrama de dispersión de la izquierda expresa la relación entre el WPR de 5 y 50 períodos, mientras que el de la derecha muestra el WPR de 15 y 25 períodos.
Como se observa, las figuras 5 y 6 son difíciles de interpretar de manera significativa, ya que no se aprecian patrones claros en los datos. Además, puede ser peligroso crear diagramas de dispersión bidimensionales de fenómenos que ocurren en más de dos dimensiones. Esto se debe a que lo que parece ser una relación entre las dos variables puede explicarse por otras dimensiones que no podemos incluir en un solo gráfico. Esto puede llevarnos a descubrimientos erróneos o a una confianza injustificada en relaciones que no son tan estables como parecen.
Sin embargo, tras aplicar UMAP, podemos representar fácilmente todos los datos disponibles en solo 2 dimensiones. En general, podemos observar que los valores bajos y altos del primer embedding parecen estar asociados con movimientos de precio bajistas y alcistas, respectivamente.
sns.scatterplot(x=X_embedded.iloc[:,0],y=X_embedded.iloc[:,1],hue=data['Class']) plt.grid() plt.ylabel('Second UMAP Embedding') plt.xlabel('First UMAP Embedding') plt.title('Visualizing The Most Effective Embedding We Found')
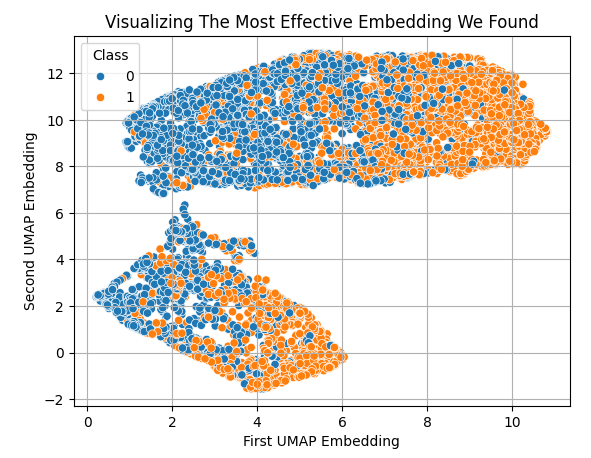
Figura 7: Visualización de los embeddings UMAP generados a partir de los datos de mercado originales.
Ahora, preparémonos para realizar pruebas retrospectivas con nuestros modelos. Importamos la biblioteca necesaria.
from sklearn.model_selection import train_test_split
Dividiremos los datos del mercado. Nuestras muestras de entrenamiento abarcan desde noviembre de 2002 hasta agosto de 2018, por lo que nuestro período de pruebas retrospectivas comenzará en septiembre de 2018.
train , test = train_test_split(data,test_size=0.3,shuffle=False) train
Figura 8: Visualización de nuestros datos de mercado en su formato original.
Ahora carguemos nuestro modelo estadístico.
from sklearn.neural_network import MLPRegressor
Escalar los datos de train.
#Sample mean Z1 = train.iloc[:,1:-2].mean() #Sample standard deviation Z2 = train.iloc[:,1:-2].std() train_scaled = train.copy() train_scaled.iloc[:,1:-2] = ((train.iloc[:,1:-2] - Z1) / Z2)
Generamos los embeddings a partir de los datos de entrenamiento.
reducer = umap.UMAP(n_components=2,metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(train_scaled.iloc[:,1:-2],columns=['UMAP 1','UMAP 2']))
Nuestro marco de trabajo sigue un proceso de dos pasos. Primero, ajusta un modelo que aprenda a aproximar el algoritmo UMAP. Esto elimina la necesidad de reescribir el algoritmo UMAP desde cero en MQL5. El algoritmo UMAP es bastante sofisticado y fue implementado por un equipo de investigadores postdoctorales. Para los investigadores, escribir una implementación numéricamente estable de un algoritmo requiere un esfuerzo considerable. Por lo tanto, no se considera una buena práctica intentar implementar dichos algoritmos por cuenta propia.
#Learn To Estimate UMAP Embeddings From The Data umap_model = MLPRegressor(shuffle=False,hidden_layer_sizes=(train.iloc[:,1:-2].shape[1],10,20,100,20,10,2),random_state=0,solver='lbfgs',activation='relu',learning_rate='constant',learning_rate_init=1e-4,power_t=1e-1) np.mean(np.abs(cross_val_score(umap_model,train.iloc[:,1:-2],X_embedded,scoring='neg_mean_squared_error',n_jobs=-1)))
11.2489992665160363
Aprenda la función UMAP.
umap_model.fit(train.iloc[:,1:-2],X_embedded) predictions = umap_model.predict(train.iloc[:,1:-2])
Ahora necesitamos un modelo que prediga la rentabilidad del mercado EURGBP teniendo en cuenta los embeddings UMAP del mercado. En scikit-learn, nuestros modelos de redes neuronales tienen un parámetro importante llamado "random_state". Este parámetro afecta a los pesos y sesgos iniciales con los que comienza la red neuronal. Dependiendo del problema en cuestión, entrenar el modelo varias veces con diferentes estados iniciales puede generar una variación considerable en los niveles de rendimiento, como podemos ver en la Figura 9 a continuación.
EPOCHS = 100 res = [] for i in range(EPOCHS): #Try different random states model = MLPRegressor(shuffle=False,early_stopping=False,hidden_layer_sizes=(2,1,10,20,1),activation='identity',solver='lbfgs',random_state=i,max_iter=int(2e5)) res.append(score(model,predictions,train['Target']))
Visualizando nuestros resultados.
plt.plot(res,color='black') plt.axhline(np.min(res),color='red',linestyle=':') plt.scatter(res.index(np.min(res)),np.min(res),color='red') plt.grid() plt.ylabel('Cross Validated RMSE') plt.xlabel('Neural Network Random State') plt.title('Our Neural Network Performance With Different Initial Conditions')
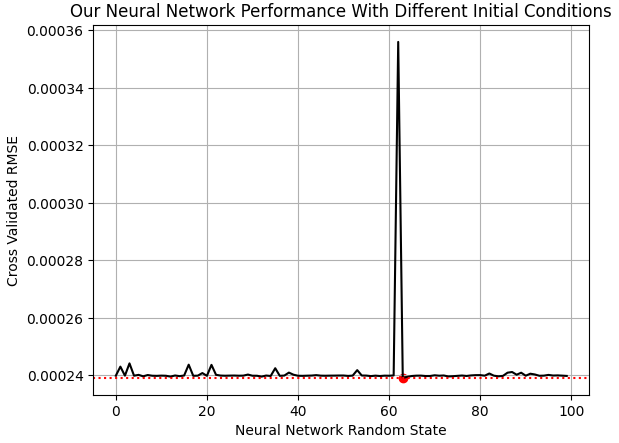
Figura 9: Visualización del estado inicial óptimo para nuestra red neuronal en este problema.
La red neuronal que hemos seleccionado predice la rentabilidad del mercado EURGBP a 10 días con un margen de error un 38 % menor que si prediciéramos siempre la rentabilidad media del mercado.
tss = score(Ridge(),train[['Close']]*0,train['Target']) 1-(np.min(res)/tss)
0.3822093585025088
Ajustamos el modelo utilizando el estado aleatorio óptimo que identificamos en la Figura 9.
embedded_model = MLPRegressor(shuffle=False,early_stopping=False,hidden_layer_sizes=(2,1,10,20,1),activation='identity',solver='lbfgs',random_state=res.index(np.min(res)),max_iter=int(2e5)) embedded_model.fit(predictions,train['Target'])
Cargamos las bibliotecas necesarias para convertir el modelo al formato ONNX.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Definimos las formas de los parámetros de nuestros modelos.
umap_model_input_shape = [("float_input",FloatTensorType([1,train.iloc[:,1:-2].shape[1]]))] umap_model_output_shape = [("float_output",FloatTensorType([X_embedded.iloc[:,:].shape[1],1]))] embedded_model_input_shape = [("float_input",FloatTensorType([1,X_embedded.iloc[:,:].shape[1]]))] embedded_model_output_shape = [("float_output",FloatTensorType([1,1]))]
Convertimos los modelos ONNX en sus prototipos.
umap_proto = convert_sklearn(umap_model,initial_types=umap_model_input_shape,final_types=umap_model_output_shape,target_opset=12) embeded_proto = convert_sklearn(embedded_model,initial_types=embedded_model_input_shape,final_types=embedded_model_output_shape,target_opset=12)
Guardamos los prototipos en el disco.
onnx.save(umap_proto,"EURGBP WPR Ridge UMAP.onnx") onnx.save(embeded_proto,"EURGBP WPR Ridge EMBEDDED.onnx")
Construyendo nuestra aplicación en MQL5
Ahora comencemos a construir nuestra aplicación. En primer lugar, necesitaremos especificar las constantes del sistema que no van a cambiar en nuestro programa.
//+------------------------------------------------------------------+ //| EURGBP Multiple Periods Analysis.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| REMINDER: | //| These ONNX models were trained with Daily EURGBP data ranging | //| from 24 November 2002 until 12 August 2018. Test the strategy | //| outside of these time periods, on the Daily Time-Frame for | //| reliable results. | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ //--- ONNX Model I/O Parameters #define UMAP_INPUTS 36 #define UMAP_OUTPUTS 2 #define EMBEDDED_INPUTS 2 #define EMBEDDED_OUTPUTS 1 //--- Our forecasting periods #define HORIZON 10 //--- Our desired time frame #define SYSTEM_TIMEFRAME_1 PERIOD_D1
Ahora, carguemos nuestros modelos ONNX.
//+------------------------------------------------------------------+ //| Load our ONNX models as resources | //+------------------------------------------------------------------+ //--- ONNX Model Prototypes #resource "\\Files\\EURGBP WPR UMAP.onnx" as const uchar umap_proto[]; #resource "\\Files\\EURGBP WPR EMBEDDED.onnx" as const uchar embedded_proto[];
A continuación, cargaremos las bibliotecas que necesitamos para nuestra aplicación.
//+------------------------------------------------------------------+ //| Libraries We Need | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Indicators\WPR.mqh> #include <VolatilityDoctor\ONNX\OnnxFloat.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
Defina las variables globales que utilizaremos a lo largo de nuestro programa. Observe que debemos definir solo un puñado de variables globales; a esto nos referíamos en la introducción de nuestra discusión cuando dijimos que la POO nos ayuda a controlar el espacio de nombres de nuestras aplicaciones. La mayoría de las variables y objetos que utilizamos están cuidadosamente organizados dentro de las clases que hemos escrito.
//+------------------------------------------------------------------+ //| Global varaibles | //+------------------------------------------------------------------+ CTrade Trade; TradeInfo *TradeInformation; //--- Our time object let's us know when a new candle has fully formed on the specified time-frame Time *eurgbp_daily; //--- All our different William's Percent Range Periods will be kept in a single array WPR *wpr_array[14]; //--- Our ONNX class objects have usefull functions designed for rapid ONNX development ONNXFloat *umap_onnx,*embedded_onnx; //--- Model forecast double expected_return; int position_timer;
También copiamos las puntuaciones Z1 y Z2 que utilizamos para escalar nuestros datos de entrenamiento en Python.
//--- The average column values from the training set double Z1[] = {7.84311120e-01, 7.87104135e-01, 7.81713516e-01, 7.84343731e-01, 5.23887980e-04, 5.26022077e-04, 5.25382257e-04, 5.25688880e-04, -5.08398234e+01, -5.07130228e+01, -5.05834313e+01, -5.04425081e+01, -5.02709031e+01, -5.01349627e+01, -5.00653250e+01, -5.01661938e+01, -5.03082375e+01, -5.04550339e+01, -5.05861939e+01, -5.06434696e+01, -5.07286211e+01, -5.07819768e+01, 1.96979782e-02, 5.29204133e-02, 4.12732506e-02, 3.20037455e-02, 2.61762719e-02, 2.34184127e-02, 2.62342592e-02, 3.32894491e-02, 3.81853070e-02, 3.85464026e-02, 3.85499926e-02, 3.94004124e-02, 4.02388908e-02, 4.02388908e-02 }; //--- The column standard deviation from the training set double Z2[] = {8.29473604e-02, 8.35406090e-02, 8.23981331e-02, 8.28950223e-02, 1.21995172e-02, 1.22880295e-02, 1.20471133e-02, 1.21798952e-02, 3.00742110e+01, 3.05948913e+01, 3.05244154e+01, 3.03776475e+01, 3.02862706e+01, 3.00844693e+01, 2.98788650e+01, 2.97182936e+01, 2.95133008e+01, 2.93983475e+01, 2.92679071e+01, 2.91072869e+01, 2.90154368e+01, 2.89821474e+01, 4.32293242e+01, 4.43537714e+01, 4.02730688e+01, 3.66106699e+01, 3.41930128e+01, 3.21743917e+01, 3.03647897e+01, 2.87462989e+01, 2.73771066e+01, 2.63857585e+01, 2.54625376e+01, 2.43656339e+01, 2.33983568e+01, 2.26334633e+01 };
Al inicializarse, configuraremos nuestros indicadores e inicializaremos nuestras clases personalizadas. Si nuestras clases no se cargan correctamente, interrumpiremos el procedimiento de inicialización y le informaremos al usuario sobre lo que salió mal.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Do no display the indicators, they will clutter our view TesterHideIndicators(true); //--- Setup our pointers to our WPR objects update_indicators(); //--- Get trade information on the symbol TradeInformation = new TradeInfo(Symbol(),SYSTEM_TIMEFRAME_1); //--- Create our ONNXFloat objects umap_onnx = new ONNXFloat(umap_proto); embedded_onnx = new ONNXFloat(embedded_proto); //--- Create our Time management object eurgbp_daily = new Time(Symbol(),SYSTEM_TIMEFRAME_1); //--- Check if the models are valid if(!umap_onnx.OnnxModelIsValid()) return(INIT_FAILED); if(!embedded_onnx.OnnxModelIsValid()) return(INIT_FAILED); //--- Reset our position timer position_timer = 0; //--- Specify the models I/O shapes if(!umap_onnx.DefineOnnxInputShape(0,1,UMAP_INPUTS)) return(INIT_FAILED); if(!embedded_onnx.DefineOnnxInputShape(0,1,EMBEDDED_INPUTS)) return(INIT_FAILED); if(!umap_onnx.DefineOnnxOutputShape(0,1,UMAP_OUTPUTS)) return(INIT_FAILED); if(!embedded_onnx.DefineOnnxOutputShape(0,1,EMBEDDED_OUTPUTS)) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Durante la desinicialización, limpiaremos los recursos y eliminaremos los punteros que creamos para nuestros objetos. Esta es una buena práctica de programación en MQL5 y previene problemas como fugas de memoria o desbordamientos de búfer si tenemos varias instancias de esta aplicación ejecutándose en una misma máquina, pero ninguna de ellas realiza la limpieza posterior. Además, cabe destacar que los desarrolladores con experiencia fuera de MQL5, especialmente en lenguajes como C, pueden estar familiarizados con los punteros como direcciones de memoria.
Es necesario hacer una distinción importante: las características de seguridad integradas en MQL5 no permiten el acceso directo a la memoria. En cambio, los ingeniosos desarrolladores del equipo de MetaQuotes encontraron una solución alternativa que crea un identificador único para cada objeto, y luego vincularon de forma inteligente cada identificador único con su objeto asociado. Por lo tanto, los lectores que ya estén familiarizados con los punteros gracias a sus estudios independientes deben tener en cuenta que la implementación de un puntero en MQL5 no proporciona literalmente al desarrollador ninguna dirección de memoria, ya que los desarrolladores de MQL5 consideraron que esto representaba una vulnerabilidad de seguridad.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Delete the pointers for our custom objects delete umap_onnx; delete embedded_onnx; delete eurgbp_daily; //--- Delete all pointers to our WPR objects for(int i = 0; i <= 13; i++) { delete wpr_array[i]; } }
Cada vez que recibamos precios actualizados, llamaremos a la clase Time para comprobar si se ha formado una nueva vela diaria; si es así, actualizaremos las lecturas de nuestros indicadores y, posteriormente, buscaremos una oportunidad de negociación si no tenemos operaciones abiertas, o gestionaremos las que ya tengamos abiertas.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Do we have a new daily candle? if(eurgbp_daily.NewCandle()) { static int i = 0; Print(i+=1); update_indicators(); if(PositionsTotal() == 0) { position_timer =0; find_setup(); } else if((PositionsTotal() > 0) && (position_timer < HORIZON)) position_timer += 1; else if((PositionsTotal() > 0) && (position_timer >= (HORIZON -1))) Trade.PositionClose(Symbol()); Comment("Position Timer: ",position_timer); } }
Para encontrar una configuración de trading, simplemente necesitamos obtener los datos de mercado relevantes y prepararlos como entradas para nuestro modelo ONNX. Tenga en cuenta que restamos la media de cada columna y dividimos por la desviación estándar de la columna antes de almacenar finalmente los datos de entrada en un vector constante de tipo f. Luego pasamos este vector constante a nuestro método ONNXFloat.Predict() y obtenemos una previsión de nuestro modelo. La creación de estas clases nos ha ayudado a reducir considerablemente el número total de líneas de código que necesitamos escribir.
//+------------------------------------------------------------------+ //| Find A Trading Setup For Us | //+------------------------------------------------------------------+ void find_setup(void) { //--- Update our indicators update_indicators(); //--- Prepare our input vector vectorf market_state(UMAP_INPUTS); //--- Fill in the Market Data that has to embedded into UMAP form market_state[0] = (float) iOpen(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[1] = (float) iHigh(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[2] = (float) iLow(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[3] = (float) iClose(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[4] = (float)(iOpen(_Symbol,SYSTEM_TIMEFRAME_1,0) - iOpen(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[5] = (float)(iHigh(_Symbol,SYSTEM_TIMEFRAME_1,0) - iHigh(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[6] = (float)(iLow(_Symbol,SYSTEM_TIMEFRAME_1,0) - iLow(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[7] = (float)(iClose(_Symbol,SYSTEM_TIMEFRAME_1,0) - iClose(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[8] = (float) wpr_array[0].GetReadingAt(0); market_state[9] = (float) wpr_array[1].GetReadingAt(0); market_state[10] = (float) wpr_array[2].GetReadingAt(0); market_state[11] = (float) wpr_array[3].GetReadingAt(0); market_state[12] = (float) wpr_array[4].GetReadingAt(0); market_state[13] = (float) wpr_array[5].GetReadingAt(0); market_state[14] = (float) wpr_array[6].GetReadingAt(0); market_state[15] = (float) wpr_array[7].GetReadingAt(0); market_state[16] = (float) wpr_array[8].GetReadingAt(0); market_state[17] = (float) wpr_array[9].GetReadingAt(0); market_state[18] = (float) wpr_array[10].GetReadingAt(0); market_state[19] = (float) wpr_array[11].GetReadingAt(0); market_state[20] = (float) wpr_array[12].GetReadingAt(0); market_state[21] = (float) wpr_array[13].GetReadingAt(0); market_state[22] = (float) wpr_array[0].GetDifferencedReadingAt(0); market_state[23] = (float) wpr_array[1].GetDifferencedReadingAt(0); market_state[24] = (float) wpr_array[2].GetDifferencedReadingAt(0); market_state[25] = (float) wpr_array[3].GetDifferencedReadingAt(0); market_state[26] = (float) wpr_array[4].GetDifferencedReadingAt(0); market_state[27] = (float) wpr_array[5].GetDifferencedReadingAt(0); market_state[27] = (float) wpr_array[6].GetDifferencedReadingAt(0); market_state[29] = (float) wpr_array[7].GetDifferencedReadingAt(0); market_state[30] = (float) wpr_array[8].GetDifferencedReadingAt(0); market_state[31] = (float) wpr_array[9].GetDifferencedReadingAt(0); market_state[32] = (float) wpr_array[10].GetDifferencedReadingAt(0); market_state[33] = (float) wpr_array[11].GetDifferencedReadingAt(0); market_state[34] = (float) wpr_array[12].GetDifferencedReadingAt(0); market_state[35] = (float) wpr_array[13].GetDifferencedReadingAt(0); //--- Standardize and scale each input for(int i =0; i < UMAP_INPUTS;i++) { market_state[i] = (float)((market_state[i] - Z1[i]) / Z2[i]); }; const vectorf onnx_inputs = market_state; const vectorf umap_predictions = umap_onnx.Predict(onnx_inputs); Print("UMAP Model Returned Embeddings: ",umap_predictions); const vectorf expected_eurgbp_return = embedded_onnx.Predict(umap_predictions); Print("Embeddings Model Expects EURGBP Returns: ",expected_eurgbp_return); expected_return = expected_eurgbp_return[0]; vector o,c; o.CopyRates(Symbol(),SYSTEM_TIMEFRAME_1,COPY_RATES_OPEN,0,HORIZON); c.CopyRates(Symbol(),SYSTEM_TIMEFRAME_1,COPY_RATES_CLOSE,0,HORIZON); bool bullish_reversal = o.Mean() < c.Mean(); bool bearish_reversal = o.Mean() > c.Mean(); if(bearish_reversal) { if(expected_return > 0) { Trade.Buy((TradeInformation.MinVolume()*2),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } else if(bullish_reversal) { if(expected_return < 0) { Trade.Sell((TradeInformation.MinVolume()*2),Symbol(),TradeInformation.GetBid(),0,0,""); } Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),0,0,""); return; } }
Esta es la implementación del método que utilizamos para actualizar nuestros indicadores técnicos.
//+------------------------------------------------------------------+ //| Update our indicator readings | //+------------------------------------------------------------------+ void update_indicators(void) { //--- Store pointers to our WPR objects for(int i = 0; i <= 13; i++) { //--- Create an WPR object wpr_array[i] = new WPR(Symbol(),SYSTEM_TIMEFRAME_1,((i+1) * 5)); //--- Set the WPR buffers wpr_array[i].SetIndicatorValues(60,true); wpr_array[i].SetDifferencedIndicatorValues(60,HORIZON,true); } }
Por último, recuerde siempre anular la definición de las constantes del sistema que haya creado, al final de su programa.
//+------------------------------------------------------------------+ //| Undefine system constants we no longer need | //+------------------------------------------------------------------+ #undef EMBEDDED_INPUTS #undef EMBEDDED_OUTPUTS #undef UMAP_INPUTS #undef UMAP_OUTPUTS #undef HORIZON #undef SYSTEM_TIMEFRAME_1 //+------------------------------------------------------------------+
Cuando inicie la aplicación, debería verse algo parecido a la Figura 10. Esto es lo esperado; solo debemos añadir una línea más al procedimiento de inicialización para indicar al terminal que no muestre indicadores durante las pruebas.
//--- Do no display the indicators, they will clutter our view TesterHideIndicators(true);
Figura 10: Nuestra vista estará inicialmente desordenada, debido a la gran cantidad de indicadores que estamos utilizando.
Una vez hecho esto, podemos comenzar nuestra prueba retrospectiva. Recordemos que nuestras muestras de entrenamiento abarcaron desde noviembre de 2002 hasta agosto de 2018; por lo tanto, nuestro período de pruebas retrospectivas debería haber comenzado en septiembre de 2018 y extenderse hasta la actualidad. Lamentablemente, mi conexión a internet no era fiable y no pude descargar de forma segura los datos históricos de mi bróker. Por lo tanto, tuve que realizar la prueba desde principios de 2023 hasta la actualidad.
Figura 11: Fechas de nuestro período de prueba retrospectiva.
Siempre preferimos utilizar datos basados en ticks reales para obtener una emulación realista del rendimiento pasado del mercado. Esto puede suponer una carga considerable para su conexión, ya que el volumen de datos solicitados será elevado.
Figura 12: Los ajustes que utilizamos para nuestra prueba retrospectiva también son importantes.
Las clases que hemos creado le proporcionarán información constante durante las pruebas retrospectivas. Podemos comprobar si hay errores leyendo los mensajes impresos. Como podemos ver en la Figura 13, nuestras clases se están ejecutando según lo previsto y no se registra ningún mensaje de error.
Figura 13: Las clases que hemos creado le proporcionarán información durante las pruebas retrospectivas. El feedback debe ser positivo y siempre debe finalizar con la predicción del modelo si no tiene posiciones abiertas.
También podemos visualizar la curva de capital generada por nuestra estrategia. La curva de capital presenta una tendencia alcista sostenida a largo plazo, lo que nos anima a seguir desarrollando la estrategia y a buscar más medidas de seguridad para limitar las pérdidas, si es posible.
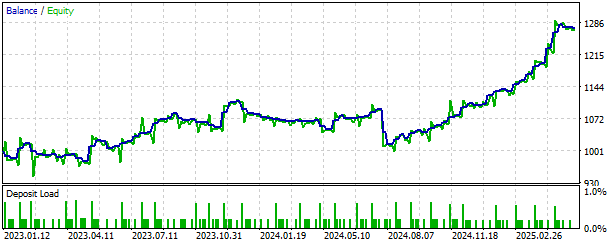
Figura 14: Visualización de la curva de capital generada por nuestra estrategia de trading.
Por último, también podemos visualizar un análisis detallado del rendimiento de nuestra estrategia de trading. Como se observa, nuestra estrategia tuvo un nivel de precisión del 58% en todas las operaciones realizadas, con un índice de Sharpe de 0,90.
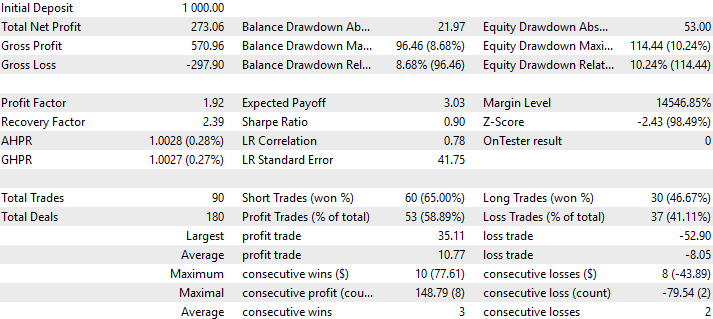
Figura 15: Un análisis detallado del rendimiento de nuestra estrategia de trading con datos no vistos anteriormente.
Conclusión
A través de este análisis, el lector obtiene información práctica sobre los beneficios de la modelización estadística, más allá de la tarea habitual de predicción de precios. Le mostramos al lector que:
- El aprendizaje automático se puede utilizar para la gestión del dinero: al aumentar el tamaño de nuestro lote cuando nuestro modelo se alinea con nuestra señal de trading, le estamos dando efectivamente al modelo estadístico el control sobre el volumen de trading, lo que permite que nuestro sistema realice operaciones de mayor volumen cuando el modelo tiene mayor confianza.
- El aprendizaje automático también puede utilizarse para descubrir formas más significativas de analizar los datos: podemos usar una familia de algoritmos de aprendizaje automático conocidos como métodos de reducción de dimensionalidad para compactar nuestros datos, lo que nos permite poner de relieve patrones importantes en grandes conjuntos de datos.
Esto significa que el lector puede sustituir el indicador WPR por una combinación de sus indicadores favoritos y, aplicando técnicas de reducción de dimensionalidad como se demuestra en este artículo, puede encontrar nuevas representaciones de sus estrategias propias que pueden mejorar su rendimiento de trading, como vimos anteriormente cuando superamos el rendimiento obtenido usando todos los datos de mercado disponibles, utilizando un embedding UMAP de solo 2 columnas a partir de las 36 columnas originales.
Además, el lector obtiene muchas ventajas al utilizar el algoritmo UMAP sugerido en este artículo, en comparación con opciones más populares como el PCA (Análisis de Componentes Principales). Destacaremos algunas ventajas concretas:
- UMAP es un método no lineal: las técnicas populares de reducción de dimensionalidad, como PCA, asumen inherentemente que existe una relación lineal en los datos. Los algoritmos fallan cuando esta suposición no es cierta. Por otro lado, UMAP está explícitamente diseñado para buscar relaciones no lineales. El lector no debería decir que UMAP es más "potente" que PCA, sino que sería más apropiado decir que UMAP es más "flexible" que PCA.
- UMAP es geométrico y no euclidiano: Es decir, UMAP ve formas, no solo distancias en línea recta. A diferencia de métodos como PCA, que dividen los datos en líneas rectas, UMAP se adapta a la forma de los datos. No parte de la premisa de que el mundo sea plano, sino que asume que sus datos residen en una superficie curva llamada variedad riemanniana, un concepto del estudio matemático de la topología que ayuda a describir espacios complejos y no lineales. Esto permite que UMAP preserve la geometría real de sus datos, no aplanándolos, sino adaptándose a ellos.
Por último, el lector se ha beneficiado al comprender el valor de la programación orientada a objetos en MQL5. Aunque la programación orientada a objetos (POO) pueda considerarse una tecnología antigua, sigue teniendo un valor inmenso, ya que nos permite centralizar el control y la gestión de fallos en un único archivo. Nos ahorra tiempo al evitar código repetitivo, lo que nos permite ejecutar rápidamente nuestras ideas con resultados predecibles.
| Nombre del archivo | Descripción del archivo |
|---|---|
| Use_All_Data.ipynb | El cuaderno Jupyter que utilizamos para analizar nuestros datos de mercado. |
| Fetch_Data_Algorithmic_Input_Selection.mq5 | El script MQL5 que utilizamos para obtener los datos de mercado que necesitábamos. |
| EURGBP_Multiple_Periods_Analysis.mq5 | El Asesor Experto que desarrollamos juntos utilizaba 14 períodos WPR diferentes a la vez. |
| EURGBP_WPR_Algorithmic_Input_Selection.csv | Los datos históricos del mercado que obtuvimos de nuestro bróker. |
| EURGBP_WPR_EMBEDDED.onnx | El modelo ONNX aproxima nuestras 36 columnas de datos a 2 embeddings UMAP. |
| EURGBP_WPR_UMAP.onnx | El modelo ONNX responsable de predecir la rentabilidad del mercado EURGBP usando 2 embeddings UMAP. |
| EURGBP_Multiple_Periods_Analysis.ex5 | Una versión compilada de nuestro Asesor Experto. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/18187
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso