
От начального до среднего уровня: Произвольный доступ (II)

Введение
В предыдущей статье, От начального до среднего уровня: Произвольный доступ (I), мы дали краткое введение в то, что представляет собой модель произвольного доступа как для записи, так и для чтения данных в файле. Однако в той статье, чтобы не давать слишком много информации за раз, мы не объяснили один из вопросов, сильнее всего влияющих на тех, кто реализует что-либо, где вообще требуется работа с файлами.
Однако обратите особое внимание на то, о чем пойдет речь дальше, поскольку правильное понимание этого момента гораздо важнее, чем понимание всего остального материала, который будет изложен в данной статье. Не всегда требуется реализовывать или знать, какой тип данных будет храниться в файле. Большую часть времени файлы структурированы определенным образом, каким бы он ни был. Такая структура каждого файла обязывает нас, или, другими словами, позволяет нам использовать определенные типы данных, избавляя от необходимости беспокоиться о том, как эти данные считываются или записываются.
Возможно, это прозвучит несколько странно, но на практике обычно всё происходит именно так. Редко, за исключением очень специфических моментов, нам действительно нужно знать, какой тип данных хранится в определенной позиции файла. Но когда возникает подобная ситуация, знание и понимание того, что необходимо сделать, оказывается гораздо важнее, чем может показаться. Это связано с тем, что в зависимости от вашего представления о принципах работы механизмов, вы, как программист, можете столкнуться с серьезными трудностями при решении определенных задач, связанных с файлами. По этой причине я прошу вас, мой уважаемый читатель, обратить пристальное внимание на каждый момент, который объясним в этой статье, поскольку понимание изложенного здесь материала может стать решающим фактором между корректным чтением файла и полной неспособностью понять хоть что-либо из его содержимого.
Произвольный доступ к файлам (Часть 2)
Когда мы говорим об объединениях, в предыдущих статьях этой же серии я показывал, что необходимо обращать пристальное внимание на тип данных и количество байтов, которое содержит каждый тип. Без знания этого становится очень сложно по-настоящему понять, что именно представляется в любом типе данных.
Объединения сами по себе — это тема, которую многие люди иногда игнорируют или даже не используют в своем коде. Однако в отношении структур и массивов ситуация совершенно иная. В этом случае это зачастую бывает очень сложно, если не сказать почти невозможно, создавать определенные модели данных без истинного понимания таких концепций программирования, поскольку структуры и массивы являются гораздо более распространенными элементами в коде, чем сами объединения.
Хорошо, но есть проблема, с которой в итоге сталкиваются многие. В этом случае всё может сильно усложниться, так как существует такой способ моделирования, при котором структуры, массивы и объединения присутствуют одновременно. Когда это происходит, вы либо действительно понимаете, как работать с такими концепциями, либо остаетесь в полной растерянности. Такое моделирование подразумевает, в частности, работу с файлами произвольного доступа.
"Может, вы хотите меня напугать? Я не думаю, что файлы могут быть настолько сложными, как вы говорите". Это не совсем так, мой уважаемый читатель. Возможно, вы до сих пор не понимаете уровня сложности того, с чем мы имеем дело. Файлы — это, безусловно, самый сложный способ организации данных, который программист может создать и спроектировать. Это утверждение настолько верно, что при появлении нового формата файла вместе с ним возникает серия документов, предназначенных исключительно для объяснения того, как работать с этим новым стандартом.
Без доступа к таким документам, объясняющим внутренний стандарт файла, при открытии вы абсолютно ничего не поймете в его содержимом, если только этот файл чисто текстовый. Это, пожалуй, единственное исключение, когда не требуется никакой документ, объясняющий, как использовать внутренний стандарт файла. Чтобы проиллюстрировать сказанное, давайте возьмем самый простой пример — формат bitmap. Этот формат описан в различных документах, распространенных по всей сети, и является очень простым и довольно практичным форматом, предназначенным как раз для хранения изображений без какого-либо сложного сжатия.
Хотя в некоторых случаях присутствует незначительное сжатие, это всего лишь деталь, которую мы можем проигнорировать в данный момент. Проблема здесь как раз в другом. В данном случае вопрос здесь заключается в том, понимаем мы или нет, что именно хранится в любом файле. Например, если вы откроете изображение в шестнадцатеричном редакторе, вы увидите нечто похожее на то, что показано на следующем рисунке:
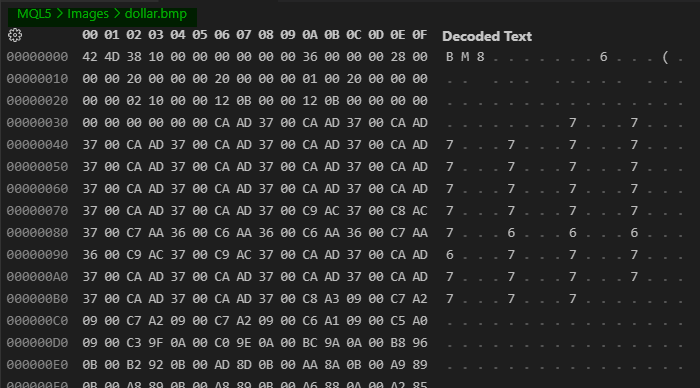
Изображение 01
Обратите внимание на этот рисунок 01, здесь есть кое-что весьма любопытное, уважаемый читатель. Прошу заметить, что показанный здесь файл выделен зелёным цветом. Однако, взглянув на эти данные, вы точно не сможете определить, что именно содержится в этом файле. За исключением того факта, что существуют некоторые маркеры, которые помогают нам его идентифицировать. Как, например, первые три значения, присутствующие в этом файле. Очевидно, другой программист или даже другая программа могли бы использовать эти же три значения для обозначения совершенно другого типа файла. Хотя это и нечастое явление, ничто не мешает кому-либо это сделать.
Однако, если предположить, что этого не происходит, можно сразу догадаться, что речь идет о файле bitmap. И, как таковой, он должен считываться как bitmap. Теперь я спрашиваю вас: Знаете ли вы, как извлечь данные из этого файла, не имея документации, объясняющей его структуру? Скорее всего, нет. Это связано с тем, что, за исключением того факта, что первые три значения отсылают нас к формату bitmap, не существует никакой другой информации, которая подсказала бы нам, как файл структурирован изнутри. Поэтому, если вы не знаете, какая программа должна использоваться для визуализации реального содержимого файла, вы не сможете узнать, какая информация содержится в этом файле.
Вот, в общем-то, так и работают эти программы. Это кажется магией, но операционная система проверяет заголовок файла. В зависимости от заголовка, он может быть связан или нет с каким-либо конкретным приложением. Если он связан, то при запросе на просмотр содержимого файла ОС будет использовать наиболее подходящую программу для данного типа заголовка. Хотя многие считают, что это связано с другими вопросами. Иногда так и бывает. Но это сейчас не имеет значения.
Хорошо, но к чему я клоню? Что ж, в предыдущей статье мы рассмотрели, как можно читать и записывать данные в файл совершенно произвольным образом, используя такие вызовы, как FileSeek и другие вспомогательные функции. Но там мы проделали работу с целью чтения одного байта, а на каждый прочитанный или записанный байт индекс позиции файла автоматически продвигался на одну позицию вперед. Но всегда ли так? Чтобы ответить на этот вопрос, нам необходимо затронуть ещё один момент, который рассматривался в других статьях, например, когда мы говорили об объединениях, структурах и массивах. Хотя мы рассматривали эти темы по отдельности и постепенно, здесь мы будем использовать все эти темы одновременно. Это делается для того, чтобы понять, как продвигается индекс позиции файла при каждом выполняемом нами чтении или записи.
Хорошо, теперь давайте забудем то, что показали на рисунке 01, потому что в данный момент это нам не поможет. Нам нужно начать с чего-то более простого, но адекватного тому, что будет объяснено. Для этого мы воспользуемся следующим кодом:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. const datetime dt = D'31.10.2024 15:30:10'; 08. const int i32 = 356248; 09. 10. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 11. { 12. Print("Error..."); 13. return; 14. }; 15. 16. FileWrite(handle, i32, "Info", dt); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileTell(handle), " >> ", FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Код 01
Хорошо, при выполнении кода 01 будет создан файл, содержимое которого показано ниже:

Изображение 02
Но тот же самый код 01 также приведет к появлению следующего в терминале:
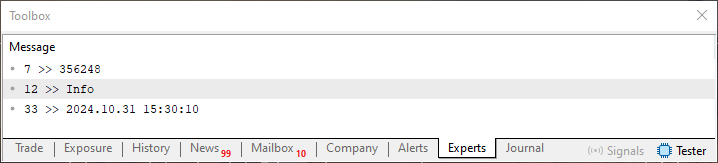
Изображение 03
Теперь мы подходим к интересующей нас части. Обратите внимание, что на изображении 03 перед фрагментом данных, которые будут считаны из файла, указано числовое значение. Что ж, это числовое значение, которое мы видим перед информацией, является позицией, где заканчивается текущая информация и начинается новая. Таким образом, если мы знаем предыдущее значение позиции чтения или записи файла, мы можем определить, сколько единиц информации было записано или прочитано. "Но подождите, разве не правильнее было бы сказать "прочитано" байтов или "записано" байтов?" Нет, уважаемый читатель, и вы скоро поймете почему.
Хорошо, давайте изменим код, чтобы понять, сколько единиц информации считывается за один шаг (а по аналогии — и записывается). В данном случае мы просто читаем. Но вам необходимо учитывать то, что объясняется для обоих случаев. Итак, у нас есть следующий код:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. 18. FileWrite(handle, i32, "Info", dt); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. old = FileTell(handle); 26. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+
Код 02
При выполнении код 02 даст следующий результат:
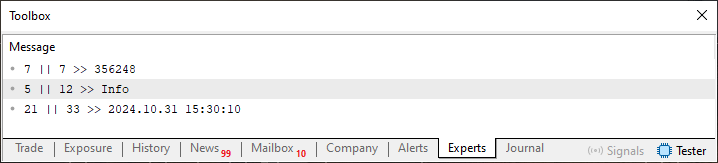
Изображение 04
Поскольку этот код 02, а также результат его выполнения, очень просты для понимания, мы можем перейти на следующий уровень. Но я хочу, чтобы вы поняли следующее, уважаемый читатель. В данный момент чтение, которое мы выполняем, заставляет систему считывать по одному значению за раз, основываясь на том, что является разделителем, присутствующим в файле. В качестве разделителя здесь используется символ табуляции, как можно видеть на следующем рисунке:

Изображение 05
Обратите внимание, что на этом рисунке я выделяю именно этот символ табуляции. Но что произойдет, если мы немного изменим код? Хорошо, чтобы это увидеть, мы воспользуемся следующим кодом:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI | FILE_TXT)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. 18. FileWrite(handle, i32, "Info", dt); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. old = FileTell(handle); 26. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+
Код 03
При выполнении кода 03 вы увидите то, что показано на следующем изображении:
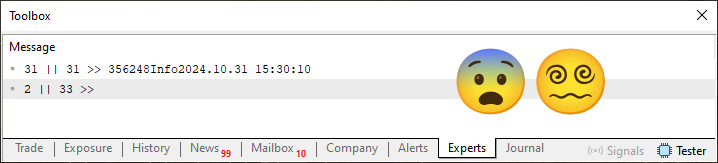
Изображение 06
"Что это за безумие? Я не понял, что изменилось в коде, из-за чего результат получился таким". Что ж, я не скажу этого, вам придется самим изучить код, чтобы найти то, что было изменено. Однако, если вы посмотрите на бинарное содержимое файла, вы увидите показанное ниже:

Изображение 07
"Что вы натворили? Скажите, куда вы внесли изменения". И снова, уважаемый читатель, вам придётся взглянуть на код, чтобы понять, что я изменил. В любом случае, можно увидеть, что результат уже не тот, что был раньше. Это связано с тем, что мы изменили формат самого файла. Поскольку приложение больше не знает, как прочитать файл для восстановления данных, результатом стала эта полная неразбериха.
Теперь обратите внимание: чтобы разобраться в этом беспорядке, нам нужно каким-то образом указать в коде, где заканчивается одно значение и начинается другое. Это можно сделать различными способами. Здесь мы рассмотрим лишь один из множества способов сделать это. Поскольку каждый случай уникален, не существует единого способа решения этого вопроса. Но давайте не будем спешить, потому что я хочу, чтобы вы поняли, как сделать это надлежащим образом.
Сначала мы изменим код на нечто похожее на то, что показано ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. FileWriteString(handle, (string)i32); 18. FileWriteString(handle, "info"); 19. FileWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 20. 21. FileFlush(handle); 22. 23. FileSeek(handle, 0, SEEK_SET); 24. while (!FileIsEnding(handle)) 25. { 26. old = FileTell(handle); 27. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 28. } 29. 30. FileClose(handle); 31. } 32. //+------------------------------------------------------------------+
Код 04
Отлично, хотя результат, который будет виден в терминале, совпадает с результатом выполнения кода 03, код 04 генерирует немного другой файл. Этот код можно увидеть ниже:

Изображение 08
Итак, обратите внимание, уважаемый читатель. Как уже упоминалось, существуют разные способы сделать одно и то же. Но здесь мы применим метод, очень похожий на тот, что существовал в языке программирования BASIC и который ушел в прошлое. Таким образом, следующий шаг показан ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. FileWriteInteger(handle, 0, CHAR_VALUE); 18. FileWriteString(handle, (string)i32); 19. FileWriteInteger(handle, 0, CHAR_VALUE); 20. FileWriteString(handle, "info"); 21. FileWriteInteger(handle, 0, CHAR_VALUE); 22. FileWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 23. 24. FileFlush(handle); 25. 26. FileSeek(handle, 0, SEEK_SET); 27. while (!FileIsEnding(handle)) 28. { 29. old = FileTell(handle); 30. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 31. } 32. 33. FileClose(handle); 34. } 35. //+------------------------------------------------------------------+
Код 05
А теперь — максимум внимания. Код 05 создаст файл, подобный тому, что показан на следующем изображении:

Изображение 09
При анализе изображения 09 можно заметить, что я отмечаю некоторые точки, где шестнадцатеричное значение равно нулю. Почему? Причина заключается в том, что мы используем именно ту позицию, где находятся эти значения, чтобы указать приложению, как правильно считывать строку. Это делается для того, чтобы иметь возможность выводить корректный текст напрямую в терминал. Если вы посмотрите на терминал при выполнении кода 05, то заметите кое-что странное, хотя и вполне понятное для тех, кто следил за тем, что объясняется и показывается в этих статьях. Это происходит так потому, что когда мы пытаемся вывести что-то в терминал, первым символом файла оказывается значение, равное нулю. Поэтому мы получим результат, который в принципе может показаться довольно необычным.
Однако даже в коде 05, если изменить значение, используемое в функции FileSeek в строке 26, чтобы пропустить это первое нулевое значение, появляющееся в самом начале файла, вы заметите, что в терминале отобразятся определенные данные. Протестируйте это позже, чтобы увидеть и понять, как будет вести себя программа. Так что это остается в качестве предложения для эксперимента, который вы сможете провести позже. Однако здесь, в статье, мы не будем этого делать, так как я хочу, чтобы вы сами увидели, как можно контролировать результаты по мере изменения кода. Но давайте вернемся к нашему главному вопросу.
Поскольку файл, который мы сейчас генерируем, должен восприниматься как бинарный, функция FileReadString должна знать, сколько символов (в данном представлении — байтов) нужно прочитать. Это необходимо для того, чтобы получить корректный и полный текст, который будет выведен в терминал. Чтобы сделать это, мы снова изменим код, как показано ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. const datetime dt = D'31.10.2024 15:30:10'; 09. const int i32 = 356248; 10. 11. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 12. { 13. Print("Error..."); 14. return; 15. }; 16. FWriteString(handle, (string)i32); 17. FWriteString(handle, "info"); 18. FWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. uchar old = (uchar) FileReadInteger(handle, CHAR_VALUE); 26. Print(old, " || ", FileTell(handle), " >> ", FileReadString(handle, old)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+ 32. void FWriteString(int &handle, const string szArg) 33. { 34. long offs = (long) FileWriteInteger(handle, 0, CHAR_VALUE); 35. long size = (long) FileWriteString(handle, szArg); 36. ulong ftell = FileTell(handle); 37. FileSeek(handle, (size + offs) * -1, SEEK_CUR); 38. FileWriteInteger(handle, (uchar)size, CHAR_VALUE); 39. FileSeek(handle, ftell, SEEK_SET); 40. } 41. //+------------------------------------------------------------------+
Код 06
Отлично, вот теперь у нас действительно есть код, который выдаст интересный результат в терминале. При выполнении этого кода вы увидите результат, показанный на следующем изображении:
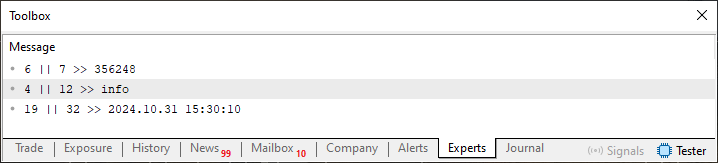
Изображение 10
Теперь перейдём к файлу. Если вы откроете его в шестнадцатеричном редакторе, то увидите нечто похожее на то, что показано ниже.

Изображение 11
Обратите внимание, что в данном случае, как видно на изображении 11, некоторые значения выделяются. Эти значения являются важной частью для нас. Так происходит, потому что они указывают количество символов, которые должна прочитать функция FileReadString. Иначе говоря: эти же значения, выделенные на рисунке 11, указывают на то, сколько символов должно быть прочитано далее. В сущности вы совершенно отчетливо можете видеть, что эти же самые значения также отображаются на рисунке 10. Но почему тогда этот код 06 сработал, в то время как остальные лишь сгенерировали файл, который не выдавал никакого правдоподобного результата в терминале?
Чтобы понять это, нам необходимо спокойно изучить именно ту процедуру, которая была создана в строке 32 этого кода 06. Данная процедура, в некотором смысле, является сердцем нашего приложения, поскольку она будет осуществлять произвольный доступ к файлу для формирования той части содержимого, которое будет в него записано. Однако эта же процедура сосредотачивает операцию на одном типе или, лучше сказать, на определенной ширине байтов, поэтому всё во многом зависит от типа данных, которые мы будем хранить в файле.
Теперь обратите внимание на некоторые моменты, потому что они важны. В строке 34 мы записываем один байт. Этот же байт послужит для последующей корректировки смещения. Это смещение является ключевым моментом. Но мы доберемся до этого без спешки. Прежде всего, давайте поймем, как работает эта подпрограмма из строки 32. Итак, теперь, когда у нас есть смещение, мы записываем содержимое строки в файл. Это происходит в строке 35. Примечание: строка НЕ ДОЛЖНА СОДЕРЖАТЬ БОЛЕЕ 255 символов, поскольку это ограничение, заданное ранее записанным байтом. Теперь, в строке 36, мы временно сохраняем текущее положение файла. Так происходит, потому что мы возвращаемся к положению байта, содержащего длину сообщения, и изменяем содержимое этого байта. Это происходит в строке 37. Сама запись осуществляется на строке 38. Обратите внимание, что все эти обращения можно было бы заменить одним единственным обращением, если бы мы использовали массив. Но пока мы оставим всё как есть, просто для того, чтобы было легко понять, что именно делаем.
Хорошо, как только данные будут записаны, строка 20 принудительно выполняет немедленную запись файла на случай, если в буфере ещё остались какие-то данные. Затем строка 22 указывает на начало файла, и в этот момент мы входим в цикл строки 23, который инициирует чтение: сначала мы считываем символ, указывающий нам количество знаков, которые необходимо прочитать. Далее, используя строку 26, мы считываем и показываем те же самые символы.
Обратите внимание, что нам нужно, чтобы строки 25 и 34 были согласованы. Это служит для того, чтобы приложение знало, сколько байт действительно представляют количество символов, которые необходимо прочитать. Вот тут-то и возникает вопрос смещения. Отлично, но этот же тип конструкции можно смоделировать и другим способом, который, на мой взгляд, значительно упрощает разработку кода, а также его поддержку и улучшение.
А теперь остановись и подумай на мгновение, уважаемый читатель. То, что мы делаем здесь, в создаваемом файле, — это именно то, что уже рассмотрели в другой статье этой же серии. Однако в то время у нас ещё не было достаточно информации, чтобы объяснить некоторые моменты, которые мы могли бы применить на практике здесь. Я имею в виду, что, наблюдая за тем, как всё это реализовано, мы на самом деле работаем со структурой данных. Поэтому важно не цепляться за код, а попытаться понять принятые концепции и подумать о возможностях получения аналогичного результата. Одни из них проще, другие — эффективнее. В любом случае, понимание концепции важнее, чем попытки заучивать и писать код наугад.
Хорошо, чтобы показать, что мы можем работать разными способами и при этом всегда получать один и тот же результат, давайте немного поэкспериментируем с тем, что мы рассмотрели к этому моменту. Для этого мы будем работать с кодом, который в некоторых аспектах несколько отличается. Этот код можно увидеть ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle, 07. start = 1; 08. uchar arr[]; 09. 10. const datetime dt = D'31.10.2024 15:30:10'; 11. const int i32 = 356248; 12. 13. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_BIN)) == INVALID_HANDLE) 14. { 15. Print("Error..."); 16. return; 17. }; 18. 19. start += arr[start - 1] = (uchar) StringToCharArray((string)i32, arr, start); 20. start += arr[start - 1] = (uchar) StringToCharArray("info", arr, start); 21. start += arr[start - 1] = (uchar) StringToCharArray(StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS)), arr, start); 22. 23. FileWriteArray(handle, arr, 0, start - 1); 24. FileFlush(handle); 25. 26. ArrayFree(arr); 27. 28. FileSeek(handle, 0, SEEK_SET); 29. FileReadArray(handle, arr); 30. 31. FileClose(handle); 32. 33. for (uint i = 0; i < arr.Size(); i+= arr[i]) 34. Print(i, " >> ", CharArrayToString(arr, i + 1, arr[i])); 35. } 36. //+------------------------------------------------------------------+
Код 07
При выполнении кода 07 результат в терминале будет таким:
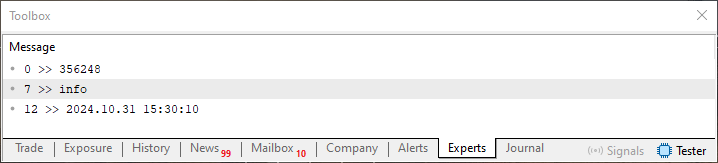
Изображение 12
Сейчас необходимо кое-что понять, уважаемый читатель. В отличие от остальных кодов, рассмотренных до этого момента, здесь мы выполняем некоторые операции несколько иным способом. Это связано с тем, что мы заменяем то огромное количество обращений к дисковому накопителю на операцию непосредственно в оперативной памяти. Это хорошо видно здесь, в коде 07. Но какое влияние это оказывает на код и на использование приложения? В конечном итоге и цель, и результат, по-видимому, остались неизменными.
Итак, исключение всех этих обращений к диску и перенос большей их части на манипуляции, выполняемые в памяти, делает приложение более быстрым, а также предотвращает задержки или падение производительности MetaTrader 5 из-за непрекращающихся запросов записи на диск. Фактически запись на диск выполняется только в этой части кода. Однако в коде 07 есть некоторые вещи, которые могут быть не совсем понятны начинающему программисту. Хотя предыдущие статьи помогают понять значительную часть кода, я думаю, мне необходимо кратко объяснить, почему код 07 работает и генерирует тот же результат, что и в предыдущих кодах.
Для начала отметим, что в строке 07 инициализируется переменная, которая будет нам очень полезна. Кроме того, в строке 08 мы объявляем динамический массив. Этот массив будет представлять собой наш файл в памяти. Теперь обратите внимание на то, что происходит в строках 19, 20 и 21. В этих строках кода 07 мы делаем то же самое, что сделали в строках 16, 17 и 18 кода 06. Однако в коде 07 те же три упомянутые строки также выполняют операцию, эквивалентную процедуре FWriteString, которая также встречается в коде 06.
"Но подождите секунду. Теперь меня немного смущает код 07. Вы хотите сказать, что строки 19, 20 и 21 заменяют всё, что сделали в коде 06 для записи данных в файл?" Да, такое возможно, уважаемый читатель. "Но эти строки в коде 07, на мой взгляд, этого не делают. По крайней мере, сейчас я этого не вижу. Могли бы вы объяснить это подробнее?" Конечно, я могу это объяснить. Итак, давайте разберемся, что делает одна из строк кода, поскольку остальные работают аналогично.
Возможно, путаницу вызывает то, что эти строки сжаты. Итак, давайте посмотрим, как работает строка 19. Во-первых, следует помнить, что переменная start уже будет иметь значение на момент выполнения функции StringToCharArray. Таким образом, значение, содержащееся в start, укажет нам, с какой позиции в массиве начинается вставка символов, присутствующих в строке. Для получения более подробной информации о функции StringToCharArray обратитесь к документации. После того, как все символы будут добавлены в массив, функция вернет количество добавленных символов. Таким образом, мы используем значение start, чтобы поместить в начало массива количество символов. Таким образом, это дает нам точно такой же тип моделирования, какой был реализован в коде 06.
Однако здесь есть разница. Функция StringToCharArray подсчитает все символы, включая символ NULL. Иными словами, значение счетчика будет отличаться от значения, полученного в коде 06. Обратите особое внимание на этот момент. Однако последним шагом этой строки, в данном случае строка 19, будет обновление позиции, на которую указывает переменная start.
Теперь перейдём к интересной части кода, а именно к строке 23. Если вы поняли, что произошло в строках 19, 20 и 21, то наверняка заметили, что переменная start всегда указывает на символ NULL внутри массива. Этот символ является последним в массиве. Однако поскольку этот символ нас не интересует, мы используем функцию FileWriteArray для сохранения всех символов на диске, кроме одного, который является последним символом в массиве. В результате мы получим бинарный файл, очень похожий на тот, который создаст код 06. Тем не менее, он будет несовместим с файлом, сгенерированным кодом 06, именно из-за символа подсчета в начале строки. По этой причине мы также изменили алгоритм чтения на тот, который показан в строке 29. Там мы прочли весь файл за один раз. Но чтобы иметь возможность отобразить его должным образом и получить таким образом ожидаемый результат, мы используем цикл в строке 33.
Заключительные идеи
В этой статье мы рассмотрели, как можно реализовать систему произвольного доступа для записи данных в файл. Это делается для того, чтобы задать некоторый протокольный формат хранения данных. Однако делать это напрямую в файле — не всегда хорошая идея.
Зачастую наилучшим подходом будет создание файла в памяти в виде массива. Только после того, как в массив будут должным образом загружены все значения, мы переходим к фазе записи данных в файл на диске. Это делает процесс более эффективным, так как оперативная память работает гораздо быстрее, чем физические диски. Даже твердотельные накопители (SSD) работают медленнее, чем оперативная память (RAM). Кроме того, читать файл побайтно не имеет особого смысла. Самое лучшее — это считывать большой блок данных напрямую в память и работать с ним уже там, где мы можем побайтово искать конкретные данные.
Хотя здесь мы работали только с однобайтными типами, вы можете расширить все увиденное для работы с более длинными или сложными типами. Это можно сделать без какого-либо труда, поскольку для этого вы можете свести всё к таким элементам, как структуры или объединения. Они уже рассматривались здесь, в этой серии статей.
| Файл MQ5 | Описание |
|---|---|
| Code 01 | Демонстрация доступа к файлам |
| Code 02 | Демонстрация доступа к файлам |
| Code 03 | Демонстрация доступа к файлам |
| Code 04 | Демонстрация доступа к файлам |
| Code 05 | Демонстрация доступа к файлам |
| Code 06 | Демонстрация доступа к файлам |
| Code 07 | Демонстрация доступа к файлам |
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/16271
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования