
Del básico al intermedio: Colas, listas y árboles (II)

Introducción
En el artículo anterior Del básico al intermedio: Colas, listas y árboles (I), empezamos a explicar uno de los temas que muchos principiantes ignoran o suelen menospreciar, ya que, en su gran mayoría, no reciben la orientación adecuada sobre ciertas implementaciones o modelos de implementación. Gran parte de los principiantes simplemente imaginan que basta con arremangarse y meterse hasta el cuello entre libros y artículos para aprender programación. Pero la verdad es que la programación, en sí, no es algo muy complejo, ya que todo lo que necesitas saber se resume en conocer algunos comandos y su sintaxis.
Aunque esto sea cierto, el principal problema que enfrenta todo principiante es entender que la programación es, básicamente, matemática. Y, muchas veces, esta matemática se ha estudiado y aplicado en diversos mecanismos ampliamente discutidos en numerosos libros y artículos disponibles públicamente. No obstante, incluso cuando esto ocurre, muchas veces un principiante tiene dificultades para entender por qué usar y cuándo usar dichos mecanismos, y acaba perdiendo mucho tiempo intentando idear soluciones que ya existen. Para ello, bastaría con adaptar conceptos ya existentes al problema que se analiza.
Precisamente uno de estos conceptos es el que empezamos a ver en el artículo anterior. No obstante, aquello fue solo una primera aproximación, básicamente orientada a demostrar cómo podríamos implementar mecanismos de colas, listas y árboles usando un mínimo de conocimiento general sobre MQL5.
Pero, aunque se haya presentado la demostración de colas de tipo FIFO y de tipo circular, todavía falta hablar de otro tipo de cola, completando así los tipos básicos que podemos implementar. Es muy importante que tú, mi estimado lector, intentes entender los conceptos adoptados aquí. No intentes memorizar cómo se construye el código, ya que esto puede variar de un caso a otro. Depende, claro está, del tipo de problema que se esté solucionando.
Así pues, vamos a continuar con ese mismo tema iniciado en el artículo anterior. Para ello, pasemos a un nuevo tema. Conviene recordar que el material visto aquí estará íntimamente ligado a lo que se mostró en el artículo anterior.
Colas, listas y árboles (II)
Bien, muy probablemente, si te estás iniciando en la programación, puede que te hayas quedado un tanto confundido sobre dónde y cómo utilizar lo que se vio en el artículo anterior. No obstante, hay muchos momentos en las que saber cómo implementar lo que se vio y explicó allí podrá marcar la diferencia en tu vida como programador. Pero debes haber notado que tanto la cola de tipo FIFO como la de tipo circular tienen en común el hecho de que los elementos siempre se procesarán en el orden en que fueron colocados en la cola. Es decir, el elemento más antiguo siempre es el primero en leerse y, en consecuencia, el elemento más reciente en la cola siempre es el último en leerse. No obstante, muchas veces necesitamos que este orden se invierta. Es decir, queremos que el elemento más reciente sea el primero en leerse y que el elemento más antiguo en la cola sea el último en leerse.
Puedes incluso pensar que, para hacer esto, bastaría con invertir el orden de lectura de los elementos colocados en una cola de tipo FIFO o de tipo circular. De hecho, y en algunos casos prácticos, es exactamente lo que ocurre. Sin embargo, existe un tipo de cola creado especialmente para que esto pueda implementarse sin que tengamos que modificar el código ya implementado. Este tipo de cola, creado especialmente para invertir el orden, se conoce como pila.
Una pila no es más que lo que su propio nombre indica. Es decir, cuando añadimos nuevos elementos, no podemos eliminar elementos más antiguos sin antes eliminar los elementos más recientes. Incluso existe un juguete que ejemplifica perfectamente qué es una pila y dónde podría utilizarse. Ese juguete se muestra en la imagen siguiente.

Imagen 01
Para quienes no conocen este juguete, se conoce como Torre de Hanói. Créanme, este juguete ya se usó como forma de análisis y comparación entre CPUs en el pasado. Esto se debe a que existen formas de implementarlo para obtener una buena medida de la velocidad de procesamiento. Sin embargo, debido a que muchas CPU comenzaron a optimizarse para hacer que el algoritmo fuera más rápido que la velocidad real de ejecución de la CPU, dicho modelo de comparación fue abandonado. Si deseas experimentar la forma de resolver esta torre, puedes echar un vistazo al sitio Somatemática.
Bien, pero ¿dónde entramos nosotros en toda esta historia? Bien, mi estimado lector, entender cómo funciona esta Torre de Hanói te ayudará a entender la lógica que hay detrás de la implementación de una pila. Pues la pila en sí es muy fácil de implementar. Pero entender dónde y cuándo usarla es algo que solo con la práctica lograrás ver con mayor rapidez y sin tropiezos. Para que esto sea más fácil de entender, tomemos como base el código de la cola de tipo FIFO que se mostró y explicó en el artículo anterior. Ese mismo código se reproduce a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stFIFO 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. T Restore(void) 13. { 14. T local = NULL; 15. 16. if (value.Size() > 0) 17. { 18. local = value[0]; 19. ArrayRemove(value, 0, 1); 20. }; 21. return local; 22. }; 23. //+----------------+ 24. void Stock(T arg) 25. { 26. T local[1]; 27. local[0] = arg; 28. ArrayInsert(value, local, value.Size()); 29. } 30. //+----------------+ 31. }; 32. //+------------------------------------------------------------------+ 33. void OnStart(void) 34. { 35. stFIFO <char> fifo; 36. 37. fifo.Stock(10); 38. fifo.Stock(84); 39. fifo.Stock(-6); 40. 41. Print(fifo.Restore()); 42. Print(fifo.Restore()); 43. Print(fifo.Restore()); 44. Print(fifo.Restore()); 45. } 46. //+------------------------------------------------------------------+
Código 01
Este código 01, cuando se ejecuta, produce el resultado que ya conocemos y que puede verse en la siguiente imagen.
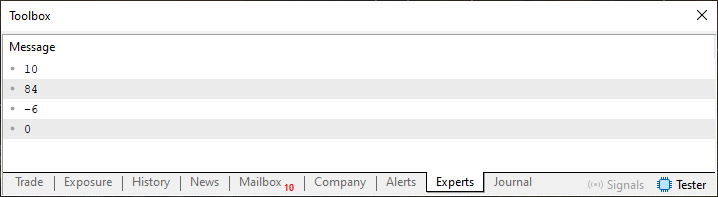
Imagen 02
Ahora, presta atención. Los nombres de las funciones y procedimientos pueden ser cualesquiera. Sin embargo, normalmente, cuando usamos una estructura de tipo pila, como programadores, nos gusta usar ciertos nombres para estas funciones y procedimientos que implementan una pila. Así pues, lo primero que hay que hacer es cambiar el código 01 por lo que se ve a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stStack 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. bool Pop(T &arg) 13. { 14. arg = NULL; 15. 16. if (value.Size() == 0) 17. return false; 18. arg = value[0]; 19. ArrayRemove(value, 0, 1); 20. return true; 21. }; 22. //+----------------+ 23. void Push(T arg) 24. { 25. T local[1]; 26. local[0] = arg; 27. ArrayInsert(value, local, value.Size()); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. stStack <char> my; 35. 36. my.Push(10); 37. my.Push(84); 38. my.Push(-6); 39. 40. for (char info; my.Pop(info);) 41. Print(info); 42. } 43. //+------------------------------------------------------------------+
Código 02
Muy bien, ahora observa que cambiamos algunas cosas del código 01 a este código 02. No obstante, aun así, seguimos implementando una cola de tipo FIFO, incluso en este código 02. Sin embargo, al ejecutarlo, el resultado será ligeramente diferente, como puedes notar en la imagen 03, que se ve a continuación.
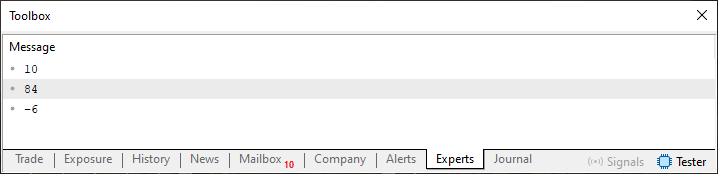
Imagen 03
Ahora viene la parte interesante. Observa que el orden en que añadimos los elementos a la cola no se modifica. No obstante, queremos que los elementos colocados en la parte superior de la cola, es decir, los últimos elementos, sean los primeros en leerse y eliminarse de la cola, haciendo que la cola se lea desde el elemento más reciente hasta el elemento más antiguo. Y, para que esto ocurra, todo lo que necesitamos hacer es cambiar el código en las líneas 18 y 19 del código 02. Al hacerlo, cambiamos una cola de tipo FIFO por una cola de tipo pila. Observa que es muy simple realizar el cambio. Y, como el cambio que hay que realizar se encuentra en un punto muy concreto, podemos dejar de lado el resto del código y centrarnos solo en este punto específico. Entonces, el cambio que debe hacerse puede observarse en el siguiente fragmento de código.
. . . 11. //+----------------+ 12. bool Pop(T &arg) 13. { 14. arg = NULL; 15. 16. if (value.Size() == 0) 17. return false; 18. arg = value[value.Size() - 1]; 19. ArrayRemove(value, value.Size() - 1, 1); 20. return true; 21. }; 22. //+----------------+ . . .
Fragmento 01
¿Pero es solo esto? No lo creo. Necesito ver el resultado de la ejecución de este código. Bien, mi estimado lector, puedes verlo mirando la siguiente imagen, que presenta el resultado que se muestra en el terminal de MetaTrader 5.
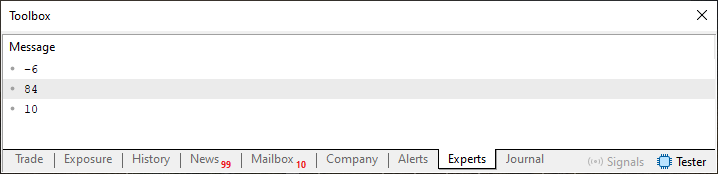
Imagen 04
Observa que, en esta imagen 04, tenemos los elementos leyéndose en el orden inverso al que se muestra en la imagen 03. Y, como no cambiamos ninguna otra parte del código, solo las líneas 18 y 19, significa que leemos los elementos desde el más recientemente colocado en la cola hasta el más antiguo. Es decir, funciona; tenemos, entonces, una cola de tipo pila, o más comúnmente llamada pila.
Este procedimiento que ves aquí no se restringe solo a situaciones especiales. La propia CPU usa algo muy parecido en el momento en que efectuamos llamadas a procedimientos o funciones. En este caso, la CPU usa una región reservada de la memoria como una pila. Si buscas cómo se ejecutan las aplicaciones a nivel de CPU, encontrarás referencias a esto que acabamos de ver. Puede ser algo que llegue a interesarte, en caso de que pretendas entender mejor cómo funciona una computadora.
Pero ahora me queda una duda. ¿Existe alguna implementación y, si existe, dónde se usaría? ¿Una que use el concepto de pila en una cola circular? Bien, mi estimado lector, existir puede existir; nada impide que esto pueda llegar a ocurrir. El detalle es cuál sería el objetivo de tal implementación. Puesto que una cola circular, en algún momento, acabará destruyendo los elementos más antiguos dentro de ella. Pero, dependiendo del tipo de caso que implementes, puede llegar a ser interesante usar el concepto de pila en una cola circular. Pero esto depende de cada caso. Y, como es algo muy específico, no veo motivo para mostrar cómo implementarlo aquí. Pero creo que no tendrás dificultades para hacer tal cosa, debido justamente a la similitud entre una cola de tipo FIFO y la de tipo circular. Como se demostró en el artículo anterior.
Ahora que ya hemos hablado de los tipos básicos de colas, llegó la hora de convertir estas mismas colas en algo un poco más elaborado. Y, con esto, surge un nuevo concepto, que son las listas. Para entender qué es una lista y por qué es una evolución de las colas, primero necesitas entender una cosa, que obviamente ya debes haber notado. Cuando lidiamos con colas, NO PODEMOS cambiar, o mejor dicho, no podemos informar en qué posición un determinado elemento deberá quedar en la cola. Este tipo de cosa NO ES POSIBLE. Todo lo que podemos hacer es enviar el elemento, o dato, para que se coloque dentro de la cola, sin poder decir dónde se colocaría.
Ahora, presta atención, porque esto es muy importante. Una cola sería una abstracción de un array. En cambio, una lista sería la evolución de una cola, lo que, en teoría, nos haría volver al concepto de array. Sin embargo, esta es la parte importante: cuando lidiamos con listas, no indicamos necesariamente un índice para colocar el elemento en la cola, como se haría si usáramos un array. En vez de hacer esto, que sería indicar el índice que el elemento debería ocupar en la cola, hacemos algo un poco diferente. Y es en este punto donde el asunto se complica, ya que muchos principiantes tienen dificultades para entender por qué hacemos esto o aquello. El concepto no cambia, pero la implementación en sí cambia bastante, dependiendo de cada caso específico, lo que acaba confundiendo a mucha gente. Más aún cuando entramos en el concepto de árbol. Pero vayamos con calma. Un paso a la vez.
Empecemos entendiendo cómo podemos modificar los códigos de cola vistos hasta aquí para crear una lista. Con un detalle: existen dos tipos de lista. La lista simplemente enlazada y la doblemente enlazada. La diferencia entre una y otra está en cómo podemos navegar dentro de ella. Además, claro está, de algunas diferencias en la forma de implementar el código. Pero esto se verá con calma.
Antes de empezar a hablar sobre listas propiamente dichas, necesito explicar rápidamente otra cosa. La explicación será muy breve, solo para que entiendas lo que se hará. Después profundizaremos en este tema. El detalle aquí es que MQL5 NO NOS PERMITE USAR PUNTEROS A ESTRUCTURAS. No entiendo. ¿Por qué esto es un problema para nosotros? Bien, mi estimado lector, el problema es que, para crear listas de la forma correcta, necesitamos utilizar punteros. Y, sea cual sea el motivo, aquí en MQL5 no podemos hacer esto usando estructuras.
Sin embargo, podemos hacerlo usando clases. A grandes rasgos, y dicho de una manera bastante aproximada, una clase no es más que una estructura. Nuevamente, esta no es la mejor forma de definir ni crear un concepto sobre clases. Las clases son elementos mucho más elaborados que las estructuras. Sin embargo, como todavía no quiero profundizar en la explicación sobre clases, tú, en este momento, y solo para los fines que implementaremos aquí, sí puedes considerar las clases como estructuras. Pero ten presente que pronto profundizaremos en qué es una clase.
Partiendo de esto, que espero que haya quedado claro, podemos empezar a trabajar en una lista. Para mantener las cosas lo más simples posible y, al mismo tiempo, hacer la explicación mucho más didáctica, vamos a empezar con una implementación muy simplificada. Esta puede verse a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. class stList 05. { 06. private: 07. //+----------------+ 08. int info; 09. //+----------------+ 10. public: 11. //+----------------+ 12. void Set(int arg) 13. { 14. info = arg; 15. } 16. //+----------------+ 17. int Get(void) 18. { 19. return info; 20. } 21. //+----------------+ 22. }; 23. //+------------------------------------------------------------------+ 24. void OnStart(void) 25. { 26. stList list; 27. 28. list.Set(512); 29. Print(list.Get()); 30. }; 31. //+------------------------------------------------------------------+
Código 03
Esto, que puede verse en el código 03, NO representa una lista, no todavía. Pero quiero que observes lo que se declara en la línea cuatro. Aquí, la palabra reservada class está sustituyendo a la palabra reservada struct. Por lo tanto, hasta que se explique el concepto de clase, debes intentar pensar en este código como si creara una estructura y no una clase. Dado que el resultado de este código, cuando se ejecuta, es muy simple y directo, no voy a entrar en detalles sobre él. Pero, si lo modificamos de una determinada manera, podemos crear la cola de tipo pila. Me gusta empezar de esta forma; así podrás entender adónde quiero llegar. Bien, para convertir este código 03 en una pila, necesitamos modificarlo como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. void Push(T arg) 13. { 14. T loc[1]; 15. loc[0] = arg; 16. ArrayInsert(info, loc, info.Size()); 17. } 18. //+----------------+ 19. bool Pop(T &arg) 20. { 21. arg = NULL; 22. if (info.Size() == 0) 23. return false; 24. arg = value[value.Size() - 1]; 25. ArrayRemove(value, value.Size() - 1, 1); 26. 27. return true; 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. stList <char> list; 35. 36. list.Push(10); 37. list.Push(84); 38. list.Push(-6); 39. 40. for (char info; list.Pop(info);) 41. Print(info); 42. 43. }; 44. //+------------------------------------------------------------------+
Código 04
Este código 04, cuando se ejecute, producirá el mismo resultado visto en la imagen 04, ya que aquí creamos algo muy parecido al código 02, utilizando el fragmento 01, visto en este mismo artículo. Presta atención: aún no hemos creado la lista, ya que, en la línea ocho, todavía usamos un array. Ahora, quiero que prestes mucha atención a una cosa en este código 04. Observa lo que hacemos en las líneas 16 y 25. Justamente en estas líneas añadimos algún elemento al array y también eliminamos algo del array.
Pero, y ahora es cuando las cosas se ponen interesantes: ¿qué ocurrirá si eliminamos el array del sistema? Bien, en este caso, estas líneas 16 y 25 dejarán de ser válidas, ya que ya no trabajaremos con un array. No obstante, si convertimos la línea ocho de este código 04 en un valor de tipo escalar, volveremos a la situación vista en el código 03, donde no podríamos añadir una secuencia de valores en la memoria y luego recuperarlos. Muy probablemente no hayas entendido lo que acabo de decir. Entonces, vamos a llevar estas palabras al código. Esto se ve a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. //+----------------+ 10. public: 11. //+----------------+ 12. void Push(T arg) 13. { 14. info = arg; 15. } 16. //+----------------+ 17. bool Pop(T &arg) 18. { 19. arg = info; 20. 21. return true; 22. } 23. //+----------------+ 24. }; 25. //+------------------------------------------------------------------+ 26. void OnStart(void) 27. { 28. stList <char> list; 29. 30. list.Push(10); 31. list.Push(84); 32. list.Push(-6); 33. 34. for (char info, c = 0; list.Pop(info) && c < 4; c++) 35. Print(info); 36. 37. }; 38. //+------------------------------------------------------------------+
Código 05
Ahora, cuando se ejecute este código 05, tendremos como resultado lo que se ve en la siguiente imagen.
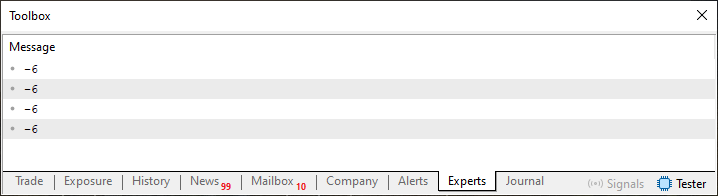
Imagen 05
Aquí, en este caso, fue necesario cambiar la línea 34, vista en el código 05, para evitar un bucle infinito. Pero observa lo que ocurrió con el código 05. En este caso, trabajamos con un código que ya no puede memorizar los valores que proporcionamos en las líneas 30 a 32, y solo se devolverá el último valor. Obviamente puedes pensar que esto se debe a que, en la línea ocho del código 05, tenemos un escalar en uso y ya no un array. Y es en este punto donde está el truco, y donde la lista empieza a tener sentido.
Lo que necesitamos hacer aquí, mi estimado lector, es crear un mecanismo que fuerce, de alguna forma, que el valor de la variable de la línea ocho quede memorizado. Esto debe ocurrir cuando se utilicen los procedimientos y funciones de acceso. Sin embargo, dicho mecanismo NO DEBE USAR UN ARRAY. Entonces, ¿cómo podemos hacer esto? Bien, la respuesta se ve en el código a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev; 10. //+----------------+ 11. public: 12. //+----------------+ 13. stList(void) 14. :prev(NULL) 15. {} 16. //+----------------+ 17. void Push(T arg) 18. { 19. stList <T> *loc; 20. 21. loc = new stList <T>; 22. (*loc).info = arg; 23. (*loc).prev = prev; 24. prev = loc; 25. } 26. //+----------------+ 27. bool Pop(T &arg) 28. { 29. stList <T> *loc; 30. 31. if (prev == NULL) 32. return false; 33. 34. loc = prev; 35. arg = (*loc).info; 36. prev = (*loc).prev; 37. 38. delete loc; 39. 40. return true; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. stList <char> list; 48. 49. list.Push(10); 50. list.Push(84); 51. list.Push(-6); 52. 53. for (char info; list.Pop(info);) 54. Print(info); 55. }; 56. //+------------------------------------------------------------------+
Código 06
Esto que ves en el código 06 es algo muy, pero muy divertido. Y, al mismo tiempo, muy interesante, ya que, cuando este código 06 se ejecute, tendrás el mismo resultado visto en la imagen 04. Y observa que aquí no usamos un array. Pero entonces, ¿cómo es posible? La respuesta es que este código 06 crea lo que se conoce como lista simplemente enlazada. Pero esta lista no se implementa con toda su capacidad. Solo se modela de forma que tú, mi estimado lector, puedas entender lo que hacemos aquí. En este artículo, básicamente tratamos de una pila. Y, como la pila es un tipo de cola simple, acabamos, por así decirlo, creando una lista simple, pero con la misma capacidad operativa que se obtendría si programáramos una cola de tipo pila.
Ahora, quiero que prestes atención al siguiente hecho. Este código 06 crea el mismo resultado que se vería si se utilizara el código 04. O incluso el código 02, pero con el fragmento 01 incluido en él. En este caso, el código completo estará disponible en el anexo, al igual que este código 06.
Pero lo que quiero que entiendas, y esto puede llegar a marcar toda la diferencia en el futuro en tu vida como programador, es que no importa cómo se implementó internamente el código en sí. Lo que importa es cómo será la interfaz de acceso a lo que programaste. Esto influye enormemente en la forma de usar el código que ofreces, así como en el tipo de resultado que se espera obtener. Observa que, incluso usando una metodología diferente para generar una pila, el resultado final obtenido es exactamente idéntico al que se había logrado anteriormente.
Es decir, puedes llegar a implementar algo que funciona internamente de una manera, y el usuario de tu código jamás se dará cuenta del tipo de mecanismo que usas. Esta es la gracia de programar. Puedes crear las cosas de una forma que, para muchos, sonará absurda. Ya sea por ser muy complicada o por ser extremadamente simple. No importa; lo que importa es el resultado final que se obtendrá.
Bien, creo que he logrado captar la idea. Pero ¿podrías explicar cómo funciona este código 06? No consigo entender cómo puede almacenar los valores y luego restaurarlos como se mostró. Sin problema, mi estimado lector. Creo que no tienes ninguna duda sobre la forma en que funciona el procedimiento OnStart, ubicado en la línea 45. Tu principal duda debe estar en cómo, sin usar un array, conseguimos apilar valores, lo que nos permite recuperarlos en un momento futuro. Pues bien, para entender esto, es necesario que entiendas, o ya conozcas, otro tema que ya abordé aquí.
El tema en cuestión es la recursividad. Este tema fue abordado en el artículo Del básico al intermedio: Recursividad. ¿Y por qué entender este tema es importante aquí? La razón es que, cuando creamos una lista, o la base inicial de una lista, como se hace en el código 06, creamos un mecanismo de recursividad. Sin embargo, este mecanismo es un poco diferente del que se abordó en el artículo mencionado. Entonces, presta atención para entender lo que ocurre aquí. Puedes notar que, en la línea cuatro del código 06, declaramos una plantilla para una clase. Ahora, olvida el hecho de que usamos una clase; piensa en esto como una estructura. Bien, dentro de una estructura de datos podemos tener diversos datos agrupados de manera lógica. Normalmente, estos datos se refieren solo a valores que tú, como programador, puedes manipular y declarar. Este es el principio básico.
Por esta razón, en la línea ocho tenemos ese valor que, como programadores, podemos manipular de la forma que resulte más conveniente. Pero, y es aquí donde la magia empieza a ocurrir, dentro de una estructura de datos también podemos añadir un elemento extra. O elementos, dependiendo del caso. En nuestro caso, este elemento extra es justamente la línea nueve. Esta línea es como una línea mágica que, si la observas, verás que declaramos un puntero. Pero ¿un puntero que apunta a qué? Bien, este puntero apuntará a una copia de la estructura declarada en la línea cuatro. Vaya, ahora sí se complicó del todo. ¿Cómo es eso? ¿Estamos dentro de una estructura que apuntará hacia dentro de ella misma? Esto no tiene mucho sentido. Al menos a mi entender. En cierto modo, debo estar de acuerdo contigo, mi estimado lector. Cuando empecé a aprender programación, tuve cierta dificultad para entender esto que intento explicarte.
El hecho es que, cuando usamos este puntero declarado en la línea nueve dentro de la estructura, podemos crear una recursividad dentro de la propia estructura sin que dicha recursividad afecte a la propia estructura. Como muy probablemente sea la primera vez que ves esto, puede que no tenga mucho sentido. Pero lo tendrá cuando ampliemos la funcionalidad de este código 06 para crear una lista enlazada. Pero, antes de hacer esto, es necesario que entiendas muy bien estos conceptos que explico. De lo contrario, no podrás asimilar el conocimiento necesario para crear tus propios códigos.
Bien, volvamos a la explicación. Cuando usamos el procedimiento de la línea 17 para apilar cualquier elemento, observa que lo primero que haremos es declarar, en la línea 19, algo muy parecido a lo que se ve en la línea nueve. Es decir, un puntero. Solo que aquí, en la línea 19, este puntero es local y temporal. Presta mucha, pero mucha atención a este detalle, porque es importante. En la línea 21, asignamos memoria para el tipo de estructura que se declara en el puntero de las líneas nueve y 19.
Ahora viene la parte en la que mucha gente se pierde al intentar entender las listas. NO DEBES ALMACENAR EL NUEVO ELEMENTO EN LA VARIABLE DECLARADA EN LA LÍNEA OCHO. Debes almacenar el nuevo elemento en la región de memoria que acabamos de asignar. Recuerda que esta región obedece exactamente a lo declarado en la estructura para la que asignamos memoria. Así, ahora aquella variable de la línea ocho puede usarse para almacenar el nuevo elemento. Sin embargo, la parte importante es lo que ocurre en la línea 23. Es en este preciso momento cuando creamos un enlace entre la posición actual y la nueva posición, creando así una estructura encadenada que, en cierto sentido, recuerda a un array, como se verá más adelante.
Como ahora apuntamos a un nuevo elemento, usamos la línea 24 para actualizar el sistema y mantener así el enlace entre los elementos. Un detalle importante. La línea 14 evita que tengamos que añadir una variable extra en la propia estructura. Como aquí usamos una clase, podemos utilizar esta metodología para simplificar la propia estructura de datos. Muy bien, entonces, cuando se inicializa la estructura, tenemos inicialmente lo que puede verse en la siguiente imagen.

Imagen 06
Aquí, la región en verde indica el contenido presente en la variable de la línea ocho. En cambio, la región en rojo indica el valor del puntero declarado en la línea nueve. Bien, esto ocurre cuando se ejecuta la línea 47. Ahora, cuando se ejecute la línea 49, tendremos una llamada al procedimiento Push, que puede verse en la línea 17, y del que acabo de dar una breve descripción de cómo funciona. Pero, para que sea mucho más simple entender el funcionamiento de este procedimiento Push, recurriremos a una nueva imagen. Esta se ve a continuación.
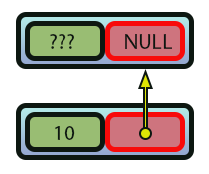
Imagen 07
Hum, no entendí. ¿Qué representa esta imagen 07? Esta imagen 07 representa la creación de la recursividad de datos. Observa que ahora el valor 10 fue apilado en la memoria. Pero el valor de la variable presente en la línea nueve ahora apunta a la región anterior de la memoria. Y esto se indica mediante la flecha en amarillo. Después de que se haya ejecutado la línea 51, lo que habremos creado se ve en la siguiente imagen.
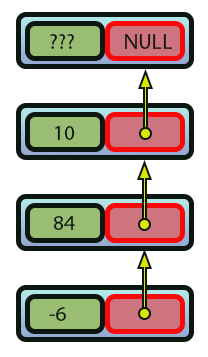
Imagen 08
Observa que, en todos los casos, el valor que se colocará en la variable de la línea nueve siempre apuntará a la región asignada anteriormente. Así se crea un encadenamiento de valores. Entonces, cuando el bucle de la línea 53 llegue a ejecutarse, tendremos un recorrido de este sistema visto en la imagen 08, solo que en orden inverso. Ahora, observa que la condición que hace que el bucle de la línea 53 termine se ejecuta exactamente en la línea 31. Cuando esta prueba tenga éxito, esto indicará que alcanzamos la base inicial de la lista que se crea. Con esto, podemos extraer los datos de la pila de manera muy simple y fácil, bastando para ello con usar un mecanismo inverso al mecanismo adoptado en el apilamiento.
En este caso específico, usamos la línea 34 para acceder a la región de memoria que fue asignada allá en la línea 21. Esto simplifica el código, ya que podríamos usar otra forma de decirle al compilador qué hacer. Pero, como aquí el objetivo es ser didáctico, decidí dejarlo de esta manera. Entonces, como ahora apuntamos a la región asignada, podremos acceder al valor presente en aquella región usando, para ello, la línea 35. Y, usando la línea 36, actualizamos el puntero actual, para, finalmente, en la línea 38, poder devolver la memoria asignada al sistema operativo, completando así, el ciclo.
Consideraciones finales
Este artículo merece estudiarse muy bien, ya que aquí solo introduje el concepto básico necesario para que podamos crear una lista. Sin embargo, como el proceso de creación de una lista puede ser un tanto complicado de entender para cualquier principiante, procuré elaborar este artículo de forma que tengas una base inicial para estudiar. Para ello, utilicé inicialmente una cola con el objetivo de crear una pila y, luego, creé la base de una lista usando también una pila. De esta forma, resulta mucho más fácil entender los conceptos básicos involucrados en la creación e implementación de listas enlazadas, ya que, en la práctica, son bastante simples de implementar. Pero entender la teoría y la forma correcta de crearlas implica entender lo que se explica en este artículo.
Intenté mantener las cosas lo más simples y didácticas posible. Creo haber alcanzado ese objetivo. De cualquier manera, procura estudiar muy bien estos códigos, mi estimado lector, ya que en el próximo artículo profundizaremos un poco más en este tema de las listas. Pero, sin entender lo que se mostró y explicó aquí, será muy difícil entender lo que se verá en el próximo artículo. Entonces, que estudies bien y nos vemos en el próximo artículo.
| Archivo | Descripción |
|---|---|
| Code 01 | Cola simple |
| Code 02 | Cola simple |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/16558
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso