
Del básico al intermedio: Colas, listas y árboles (III)

Introducción
En el artículo anterior Del básico al intermedio: Colas, listas y árboles (II), se explicó cuál era la base inicial para construir una lista enlazada. Sin embargo, la base presentada allí, en ese artículo, no está completa. Todavía falta implementar algo que convierte las listas enlazadas en algo realmente interesante, tanto desde el punto de vista práctico como desde el punto de vista teórico.
A diferencia de lo que se explicaría sobre listas enlazadas si estudiaras este tema en el ámbito académico, aquí nos centraremos en la parte práctica de su implementación y uso. Para entender correctamente lo que verás en este artículo, es necesario que hayas comprendido muy bien lo que se vio en el artículo anterior. Además, claro está, debes tener una buena comprensión de las bases y los conceptos que hay detrás de los arrays. Esto se debe a que no es raro que muchos principiantes confundan lo que se verá aquí con un tipo de implementación especial de arrays. Más aún cuando empezamos a usar otro tipo de recurso, posible y presente en MQL5, del cual todavía no he hablado, pero que explicaré en otro momento.
Precisamente para no volver aún más confuso un tema que necesita estar muy bien aclarado y comprendido, dada su importancia cuando se trata de listas y sus aplicaciones, vamos a iniciar el tema principal de este artículo.
Colas, listas y árboles (III)
Para empezar correctamente, vamos a repasar rápidamente lo que se vio en el artículo anterior. Es muy importante que tengas bien fresco en tu mente lo que se vio allí, para entender lo que haremos a continuación. Así pues, tomemos el código final de aquel artículo. Se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev; 10. //+----------------+ 11. public: 12. //+----------------+ 13. stList(void) 14. :prev(NULL) 15. {} 16. //+----------------+ 17. void Push(T arg) 18. { 19. stList <T> *loc; 20. 21. loc = new stList <T>; 22. (*loc).info = arg; 23. (*loc).prev = prev; 24. prev = loc; 25. } 26. //+----------------+ 27. bool Pop(T &arg) 28. { 29. stList <T> *loc; 30. 31. if (prev == NULL) 32. return false; 33. 34. loc = prev; 35. arg = (*loc).info; 36. prev = (*loc).prev; 37. 38. delete loc; 39. 40. return true; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. stList <char> list; 48. 49. list.Push(10); 50. list.Push(84); 51. list.Push(-6); 52. 53. for (char info; list.Pop(info);) 54. Print(info); 55. }; 56. //+------------------------------------------------------------------+
Código 01
Este código 01 tiene como objetivo crear el equivalente a una pila, que es un tipo de cola en la que los valores añadidos más recientemente son los primeros en leerse. Sin embargo, a diferencia de la implementación de una cola, este código 01 ya no usa ningún tipo de array interno. Y es justamente este pequeño detalle el que hace que esta implementación reciba una clasificación diferente. De esta forma, este código 01 se clasificaría como una LISTA ENLAZADA. No obstante, todavía no puede considerarse realmente una lista enlazada.
Esto se debe a que todavía falta algo que una lista enlazada es capaz de hacer y que este código 01 todavía no puede efectuar: la posibilidad de añadir o eliminar elementos en cualquier posición dentro de la lista de elementos. Es decir, un código que implementara una lista enlazada, en general, nos permitiría crear una simulación de lo que sería un array dinámico, pero sin necesidad de utilizar operaciones que normalmente son necesarias al trabajar con arrays dinámicos, ya que, en muchas situaciones, el procesamiento puede ser considerablemente más rápido que en implementaciones basadas en arrays.
Pero espera un momento. Déjame ver si entendí bien lo que acabo de leer. ¿Me estás diciendo que el objetivo de una lista enlazada es crear un sistema de arrays sin que tengamos que usar un array para ello? Pero ¿qué sentido tiene hacer esto? Para entenderlo, mi estimado lector, primero necesito que entiendas otra cosa. Estoy considerando que tienes un conocimiento mínimo sobre programación, es decir, que realmente no tienes idea de cómo ciertas cosas se hacen internamente en la CPU.
Cuando usas la función de biblioteca de MQL5 llamada ArrayInsert, su objetivo es insertar nuevos datos dentro de un array ya existente. Hasta ahí, todo correcto. Sin embargo, esta función tiene un pequeño detalle: cuando insertamos nuevos datos al final del array ya existente, los datos simplemente se copian dentro del array. Es básicamente equivalente a usar la función ArrayCopy.
Sin embargo, cuando queremos añadir elementos en medio de un array ya existente, o al inicio de ese mismo array, ocurre algo diferente. En este caso, la función ArrayInsert asignará un nuevo bloque de memoria; luego copiará parte de los elementos en este nuevo bloque. Añadirá los nuevos elementos que insertamos en el bloque recién asignado. Solo después copiará el resto del array original dentro del bloque asignado. Con esto, si usamos un array muy grande, podemos tener un tiempo de ejecución un tanto elevado. Aunque, con el bus de datos actual de las placas base modernas, estos bloques que necesitan moverse tienen que ser realmente muy grandes para que puedas notar la diferencia. O, como mínimo, necesitamos efectuar varias inserciones para que el tiempo de procesamiento pueda percibirse.
No obstante, al comienzo de la era de las computadoras, el procesamiento no era tan ágil. El bus de datos era lento, y estos movimientos, incluso con pocos elementos, requerían mucho tiempo. Así, ingenieros y académicos crearon una solución para el problema. Y esta solución son precisamente las listas. Ahora, volvamos a la cuestión del código 01. Cuando la lista está totalmente creada, lo que tendremos en la memoria es algo parecido a lo que se ve a continuación.
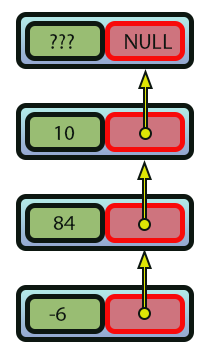
Imagen 01
La forma en que llegamos a este resultado, visto en la imagen 01, se explicó en el artículo anterior. Sin embargo, aquí daremos un paso extra: hacer que la lista enlazada sea realmente funcional. Pero, para que las operaciones que implementaremos tengan realmente sentido para ti, primero vamos a entender cómo se haría lo mismo si usáramos un array. Al hacer esto, esta misma imagen 01 se convertirá en algo parecido a la imagen 02, que se ve a continuación.
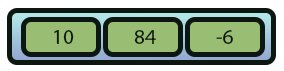
Imagen 02
Ahora, supongamos que quieres añadir un nuevo elemento al array de la imagen 0, como se muestra en la imagen 03 a continuación.
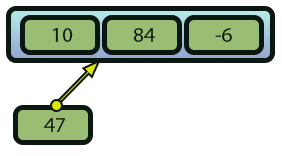
Imagen 03
¿Cómo harías esto sin usar la función ArrayInsert? Bien, si entendiste la explicación dada un poco más arriba, en este artículo, primero necesitarías asignar un nuevo bloque de memoria. Esto generaría lo que se ve en la siguiente imagen.

Imagen 04
Observa que todavía no hemos copiado nada en este nuevo bloque. Solo lo asignamos en la memoria. El siguiente paso sería copiar los elementos anteriores a la posición donde se insertará el nuevo elemento. Suponiendo que el nuevo elemento se insertará en el índice uno, la primera copia generará lo que puede verse a continuación.

Imagen 05
Bien, ahora podemos insertar el nuevo elemento en el array. Al hacerlo, tendremos lo que se ve en la siguiente imagen.

Imagen 06
Una vez que el nuevo elemento se haya insertado en el array final, podemos copiar el resto de los elementos que existían en el array original. Con esto, el resultado final es lo que puede verse en la imagen 07, a continuación.
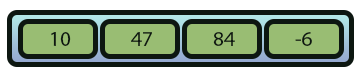
Imagen 07
Observa que el paso a paso es muy simple de implementar, incluso para un principiante en programación. Algo muy parecido ocurre cuando necesitamos eliminar algún elemento dentro del array. Solo que, en este caso, los pasos que deben realizarse serán los inversos de lo que se mostró aquí. Primero asignamos un bloque con menos elementos, copiamos los elementos que se mantendrán, saltamos los que se eliminarán y finalizamos la copia de los elementos restantes en el array.
Pero volvamos a la cuestión del tiempo de procesamiento. Piensa en hacer esto con un array que contenga miles de elementos y en que necesitas insertar o eliminar otros miles de elementos en posiciones no consecutivas, es decir, puede que insertes un elemento en la posición dos y el siguiente en la posición cuatro, y así sucesivamente. En este caso, lo que se hizo en las figuras anteriores tendrá que hacerse miles de veces, lo que dará como resultado una cantidad considerable de movimientos. Esto, al final, acaba consumiendo mucho tiempo de CPU, incluso en un bus de datos moderno. Sin embargo, aquí es donde la lista enlazada hace su magia. Para hacer lo mismo que se ve en las imágenes anteriores, podemos usar muchos menos pasos, como puedes observar a continuación.
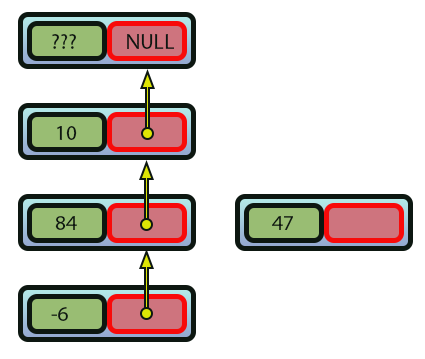
Imagen 08
Observa que esta imagen 08 es muy parecida a la imagen 01. Solo que aquí tenemos un nuevo elemento que debe añadirse. Y este todavía no forma parte de la lista enlazada. Entonces, todo lo que necesitamos hacer para añadir este nuevo elemento es decir dónde deberá añadirse. Y la propia implementación convertirá la imagen 08 en la imagen 09, que se ve a continuación.
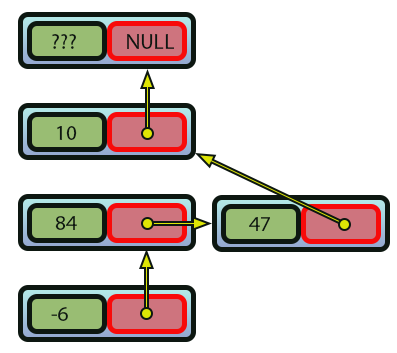
Imagen 09
Observa cómo fue mucho, pero mucho más simple añadir un nuevo elemento. También es mucho más simple eliminar un elemento. Basta con eliminar el enlace que lo une a la lista y reajustar los enlaces que mantienen la lista enlazada. Así, lo que sería un sistema lento pasa a ser ahora un sistema mucho más rápido, por el simple hecho de cambiar la forma en que la implementación hará las cosas internamente.
Muy bien, ahora que entendiste la idea que existe entre bastidores, podemos ver cómo se implementa esto en términos de código. Y esta es la parte realmente divertida del artículo.
Bien, entonces volvamos a lo que sería el código 01, visto al comienzo de este artículo. Solo que ahora modificaremos ese mismo código, como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. (*loc).info = arg; 25. (*loc).prev = prev; 26. prev = loc; 27. } 28. //+----------------+ 29. bool Restore(T &arg) 30. { 31. stList <T> *loc; 32. 33. if (prev == NULL) 34. return false; 35. 36. loc = prev; 37. arg = (*loc).info; 38. prev = (*loc).prev; 39. 40. delete loc; 41. 42. return true; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. stList <char> list; 50. 51. list.Store(10); 52. list.Store(84); 53. list.Store(-6); 54. 55. for (char info; list.Restore(info);) 56. Print(info); 57. }; 58. //+------------------------------------------------------------------+
Código 02
Ahora, presta atención, mi estimado lector. En este código 02 estamos empezando a implementar lo que sería realmente una lista enlazada simple. Aquí puedes usar cualquier nombre para las funciones y los procedimientos adoptados. Esto no importa. Sin embargo, y esta es la parte importante, necesitas tener cuidado con la forma en que se implementa el código para que la lista se cree y se mantenga de la forma correcta. Tal como se encuentra este código 02, seguimos teniendo lo que sería una pila, implementada en formato de lista. Entender esto es importante para entender lo que se verá después.
Ahora podemos empezar a implementar las funciones y los procedimientos poco a poco. Pero, antes de hacerlo, ¿qué tal ver el resultado de la ejecución de este código 02? Aunque ya lo conocen quienes vieron el artículo anterior. De cualquier modo, el resultado se ve a continuación.
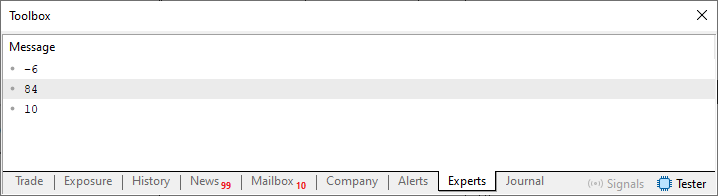
Imagen 10
Muy bien, ahora hagamos la primera modificación de este mismo código 02 con el fin de poder añadir un valor al inicio de lo que será nuestra lista. Esta primera modificación puede verse a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. switch(pos) 25. { 26. case SEEK_SET: 27. (*loc).info = arg; 28. (*loc).prev = NULL; 29. (*start).prev = loc; 30. start = loc; 31. break; 32. case SEEK_END: 33. (*loc).info = arg; 34. (*loc).prev = prev; 35. prev = loc; 36. start = (start == NULL ? loc : start); 37. break; 38. } 39. } 40. //+----------------+ 41. bool Restore(T &arg) 42. { 43. stList <T> *loc; 44. 45. if (prev == NULL) 46. return false; 47. 48. loc = prev; 49. arg = (*loc).info; 50. prev = (*loc).prev; 51. 52. delete loc; 53. 54. return true; 55. } 56. //+----------------+ 57. }; 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. stList <char> list; 62. 63. list.Store(10); 64. list.Store(84); 65. list.Store(-6); 66. list.Store(47, SEEK_SET); 67. 68. for (char info; list.Restore(info);) 69. Print(info); 70. }; 71. //+------------------------------------------------------------------+
Código 03
Ahora, presta muchísima atención a lo que voy a explicar, mi estimado lector. Pues, aunque para mí y para programadores con buena experiencia lo que se hace aquí en el código 03 sea muy simple de entender, para muchos de ustedes esto es algo extremadamente complicado. Y aquí solo estamos iniciando la implementación de la lista propiamente dicha. Para evitar crear demasiadas cosas, estoy utilizando la enumeración de posicionamiento de archivo aquí en el código. Esta puede verse en la línea 19.
Observa que existe una diferencia entre el código 02 y este código 03, justamente en este mismo procedimiento. Pues bien, este código 03 sigue funcionando como si fuera una pila. Pero una pila que puede construirse de manera un poco arbitraria. Ahora pasemos a la cuestión. SEEK_END siempre colocará las cosas a partir del final de lo que ya esté colocado en la lista. Y SEEK_SET siempre colocará las cosas a partir del inicio de lo que ya está colocado en la lista. Este sería el mismo principio adoptado durante la manipulación de archivos binarios.
Sin embargo, la parte confusa aparece justamente cuando necesitamos colocar algo al inicio de la lista. Esto ocurre cuando ya tenemos una lista previamente construida. Digo esto porque, si observas, notarás que la parte responsable de colocar datos al final de la cola es muy parecida a lo que ya se hacía. Sin embargo, fue necesario añadir la línea 36, justamente para que el puntero de inicio de la lista se asigne correctamente. Y es precisamente esto lo que después nos permitirá añadir nuevos elementos al inicio de la lista.
Pues bien, cuando una llamada al procedimiento de la línea 19 tiene SEEK_SET como segundo argumento, como ocurre en la línea 66, tendremos la ejecución del código entre las líneas 26 y 31. Bien, entonces entendamos, línea por línea, qué ocurre aquí. La línea 27 almacena el valor del elemento, tal como lo hace la línea 33. Por su parte, la línea 28 garantiza que el valor anterior sea NULL. Esto es importante para que la prueba de la línea 45 tenga éxito, en caso de que no exista ningún elemento en la lista. Bien, la línea 29 hace que el puntero actual al valor anterior apunte a lo que será el nuevo primer elemento al inicio de la lista. Y, para finalizar, la línea 30 asigna el primer elemento para que quede apuntado correctamente.
Sé que, visto así, este tipo de cosa, aparentemente simple, puede hacer que bajes la guardia, pensando que es demasiado fácil entender este código. Sin embargo, necesito advertirte, mi estimado lector, que, sin entender lo que se hace aquí en el código 03, difícilmente entenderás lo que se verá dentro de poco. De cualquier modo, al ejecutarse, este código 03 producirá el siguiente resultado, que se ve a continuación.
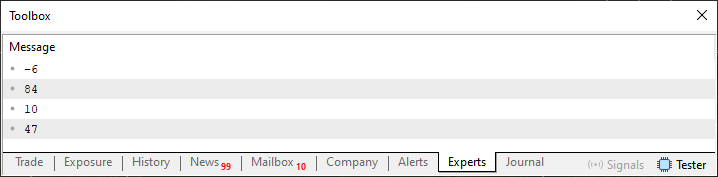
Imagen 11
Bien, pero puedes estar pensando: ¿no podríamos colocar el contenido de esta línea 66 antes de lo que sería la línea 63? Así evitaríamos crear esta posible confusión en el código. En realidad, este no es exactamente el problema aquí, mi estimado lector. El detalle es que necesitamos asegurarnos de que el código pueda añadir elementos en lo que sería el inicio de nuestra lista. Este es el motivo por el cual la línea 66 se presenta como se muestra en el código 03.
Esto fue un tanto divertido. Pero podemos, y lo haremos, dejar las cosas aún más divertidas. Entonces, modifiquemos el código 03, ahora para lo que sería el código 04, que se ve a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. 25. (*loc).info = arg; 26. (*loc).prev = NULL; 27. switch(pos) 28. { 29. case SEEK_SET: 30. (*loc).start = start; 31. (*start).prev = loc; 32. start = loc; 33. break; 34. case SEEK_END: 35. if (prev != NULL) (*prev).start = loc; 36. (*loc).prev = prev; 37. prev = loc; 38. start = (start == NULL ? loc : start); 39. break; 40. } 41. } 42. //+----------------+ 43. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 44. { 45. stList <T> *loc = NULL; 46. 47. if ((prev == NULL) || (start == NULL)) 48. return false; 49. 50. switch (pos) 51. { 52. case SEEK_SET: 53. loc = start; 54. start = (*loc).start; 55. break; 56. case SEEK_END: 57. loc = prev; 58. prev = (*loc).prev; 59. break; 60. } 61. arg = (*loc).info; 62. 63. delete loc; 64. 65. return true; 66. } 67. //+----------------+ 68. }; 69. //+------------------------------------------------------------------+ 70. void OnStart(void) 71. { 72. stList <char> list; 73. 74. list.Store(10); 75. list.Store(84); 76. list.Store(-6); 77. list.Store(47, SEEK_SET); 78. 79. for (char info; list.Restore(info, SEEK_SET);) 80. Print(info); 81. }; 82. //+------------------------------------------------------------------+
Código 04
En este código 04, ya empezamos a implementar algo que, a primera vista, no parece ser lo que realmente es. Entonces, relajémonos un poco y observemos este código 04 con calma. Observa que ahora tenemos la función Restore, presente en la línea 43, que también puede recibir una indicación de cómo deberá hacerse la lectura.
Así pues, en este momento exacto, nos encontramos con un tipo de cuestión ya vista en el artículo Del básico al intermedio: Colas, listas y árboles (I), donde hablamos sobre colas de tipo FIFO y también sobre colas circulares. Pero aquí, por motivos de simplicidad del propio código, no entraré en la cuestión referente a las colas circulares. Mantengámonos en la cuestión más simple y, al mismo tiempo, interesante para el artículo.
Antes de entrar en la cuestión de la función Restore, veamos qué cambió con respecto al procedimiento Store. Aunque parezca que no ha cambiado, las modificaciones hechas en este procedimiento crean algo diferente de lo que se ve en la imagen 01. Entonces, presta atención, mi estimado lector, porque, en la imagen 01, teníamos lo que sería una lista enlazada simple. Sin embargo, este código 04, más específicamente en el procedimiento Store, crea lo que se conoce como LISTA DOBLEMENTE ENLAZADA. Pero espera un momento. ¿En el código 03 no habíamos creado este tipo de lista doble? No, mi estimado lector. En el código 03, todavía estábamos en lo que sería una lista simple. Sin embargo, estos pocos cambios hechos en el código 04 convirtieron aquello que era una lista simple en una lista doble. Para entender esto, observa la siguiente imagen, que representa una lista doblemente enlazada.
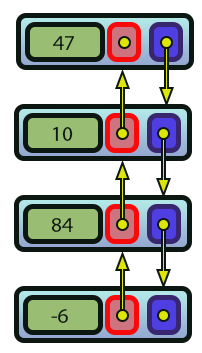
Imagen 12
Observa que, en este caso de la imagen 12, tenemos dos direcciones de flechas. Esto es diferente de lo que puede verse en la imagen 01, donde había una sola dirección de flecha. Esto es lo que nos permite distinguir entre lo que sería una lista doble y una lista simple.
Pero espera un momento. Todavía no he logrado entender por qué el código 03 es una lista simple y este código 04 es una lista doble. ¿Podrías explicarlo mejor? Bien, entonces vamos a entender esto de forma más clara. Observa que, en la línea 30 del código 04, creamos un enlace para marcar el inicio de una lista. También se hace en la línea 35. Pero la forma en que hacemos esto cambia el comportamiento de la lista. No durante la escritura, sino durante el proceso de lectura, que veremos dentro de poco. Observa que cada elemento, o nodo, como normalmente se llama a un elemento de una lista, tiene dos direcciones que pueden seguirse. La primera de estas direcciones nos hace avanzar hacia el origen, o primer elemento de la lista. La segunda dirección, en cambio, hace que avancemos hacia el final de la lista. Como no estamos cerrando la lista para hacerla circular, las cosas quedan limitadas a este intervalo de navegación.
Observa que las modificaciones hechas para crear la lista doble fueron solo estas que menciono. Y esto no cambia la forma de usar el procedimiento de almacenamiento de datos en la lista. Sin embargo, sí nos permite crear una forma muy diferente de leer la lista. Entonces, veamos la función Restore, presente en la línea 43. Claramente, notarás enseguida que podemos indicar si la lista se leerá desde el elemento más antiguo hacia el más reciente, o si será al contrario. Y es precisamente esto lo que diferencia lo que sería una cola de tipo FIFO de una de tipo pila, como se vio en los artículos anteriores. Sin embargo, aquí no estamos lidiando con colas, sino con listas. Aun así, el concepto sigue siendo válido.
Presta atención ahora a que, en la prueba de la línea 47, comprobamos dos condiciones que hacen que la lista esté vacía. Si no está vacía, pasamos a la parte de lectura. Como la implementación de SEEKEND, es decir, la lectura del elemento más reciente al más antiguo, ya se explicó bastante, pasemos a la novedad aquí. Es decir, pasemos a SEEK_SET. Cuando se usa este método, leeremos desde el elemento más antiguo, es decir, desde los primeros elementos de la lista, hasta los más recientes, que serían los últimos elementos presentes en la lista. Observa que, para hacer esto, leemos el elemento actual en la línea 53 y, justo después, ajustamos el puntero del elemento actual al siguiente elemento de la lista. Esto se hace en la línea 54. Y eso es todo lo que necesitamos hacer. Así pues, cuando se ejecuta el código, veremos lo que se muestra en la siguiente imagen.
Imagen 13
Vaya, qué extraño puede parecer esto a primera vista. En efecto, mi estimado lector, visto así, quizá no estés entendiendo bien qué ocurre. De cualquier modo, en el anexo tendrás los códigos principales vistos en este artículo para poder probarlos. Pero no dejes de probar los códigos intermedios que se muestran en este artículo, pues te ayudarán a entender mejor qué ocurre aquí.
De cualquier modo, antes de terminar este artículo, quiero mostrarte otra cosa, mi querido y estimado lector. Quizá esto te ayude a entender aún mejor cómo se crea esta lista doblemente enlazada en la memoria.
Es muy importante que consigas entender esto para comprender lo que explicaré en el próximo artículo, ya que no quiero bombardearte con demasiada información. Pues lo que ya tenemos en este artículo es suficiente para que muchos tengan bastante que estudiar y comprender. La parte que quiero mostrar puede verse en el código a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. 25. (*loc).info = arg; 26. (*loc).prev = NULL; 27. switch(pos) 28. { 29. case SEEK_SET: 30. (*loc).start = start; 31. (*start).prev = loc; 32. start = loc; 33. break; 34. case SEEK_END: 35. if (prev != NULL) (*prev).start = loc; 36. (*loc).prev = prev; 37. prev = loc; 38. start = (start == NULL ? loc : start); 39. break; 40. } 41. } 42. //+----------------+ 43. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 44. { 45. stList <T> *loc = NULL; 46. 47. if ((prev == NULL) || (start == NULL)) 48. return false; 49. 50. switch (pos) 51. { 52. case SEEK_SET: 53. loc = start; 54. start = (*loc).start; 55. break; 56. case SEEK_END: 57. loc = prev; 58. prev = (*loc).prev; 59. break; 60. } 61. arg = (*loc).info; 62. 63. delete loc; 64. 65. return true; 66. } 67. //+----------------+ 68. void Debug(void) 69. { 70. Print("===== DEBUG ====="); 71. for (stList <T> *loc = prev; loc != NULL; loc = (*loc).prev) 72. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]",(*loc).start, loc, (*loc).prev, loc.info); 73. Print("================="); 74. } 75. //+----------------+ 76. }; 77. //+------------------------------------------------------------------+ 78. void OnStart(void) 79. { 80. stList <char> list; 81. 82. list.Store(10); 83. list.Store(84); 84. list.Store(-6); 85. list.Store(47, SEEK_SET); 86. 87. list.Debug(); 88. 89. for (char info; list.Restore(info, SEEK_SET);) 90. Print(info); 91. }; 92. //+------------------------------------------------------------------+
Código 05
Si usas este código 05, que estará en el anexo, con bastante calma y atención, entenderás cómo se crea la lista en la práctica. Esto se debe a que, en la línea 68, añadí un procedimiento cuyo objetivo es mostrar la lista dentro de la memoria. Como aquí, en MetaTrader 5, no podemos hacer ciertas cosas sin entrar en otros detalles aún más avanzados, este procedimiento de la línea 68 imprimirá, en el terminal, la estructura de la lista de una forma relativamente simple de entender. Cuando se ejecuta la línea 87, llamaremos a este procedimiento de la línea 68. El resultado puede verse en la siguiente imagen.
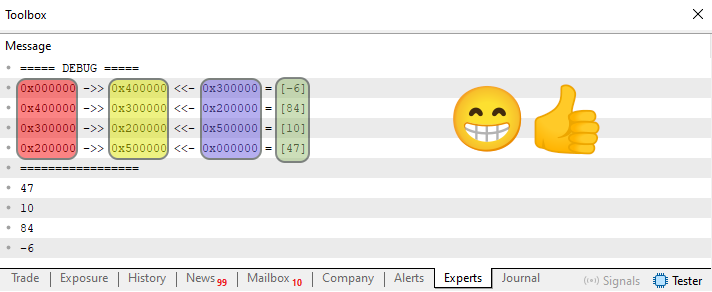
Imagen 14
Aquí tenemos cuatro regiones marcadas. Y estas regiones, en cierta medida, están relacionadas con lo que sería la imagen 12. Observa que, en verde, en esta imagen 14, tenemos los valores presentes en aquel nodo de la lista. En amarillo, tenemos la dirección del nodo. ¿Y las regiones en rojo y morado? Bien, estas regiones indican la dirección del siguiente bloque y la del bloque anterior. Observa que las flechas que se muestran en esta imagen 14 indican la dirección de lectura que seguiremos. Si la flecha apunta hacia la izquierda, leeremos del elemento más antiguo al más reciente. Esto sería equivalente a una lectura de tipo FIFO. En cambio, con las flechas orientadas hacia la derecha, leeremos los nodos en lo que sería equivalente a una pila. Es decir, del elemento más reciente al más antiguo en la lista.
Entonces, básicamente, eso es todo, mi estimado lector. Ahora toca estudiar y practicar para entender realmente qué ocurre aquí, en estos códigos.
Consideraciones finales
En este artículo, cuyo contenido es bastante denso y muy complicado para gran parte de los principiantes, vimos en la práctica cómo implementar un modelo simple y bastante práctico de una lista enlazada. Empezamos con lo que sería una implementación de lista simple y terminamos en aquello que se clasifica como una lista doblemente enlazada.
Aunque lo que se ve aquí pueda parecer mucho más complicado de lo que realmente es, me gustaría que tú, mi estimado lector, intentaras estudiar con calma lo que se vio aquí en este artículo. Esto se debe a que todavía falta mostrar cómo implementar una cosa en este sistema de lista. Esto sería justamente incluir o excluir elementos basándose en un valor de índice. Como este tipo de cosa implica usar algo que, para muchos, sería mucho más fácil y simple de entender usando arrays, no mostraré esta parte en este artículo. Incluso porque existe otro detalle que vuelve aún más confusa esta parte faltante. Sin embargo, este detalle se dejará para explicarlo en otro momento. A mi modo de ver, aunque este detalle vuelve la cosa mucho más confusa para los principiantes, hace que la implementación y el uso del código sean mucho más simples.
De cualquier modo, no comentaré esto en este primer momento. Pero me gustaría que hicieras un esfuerzo, aunque no llegues a lograrlo. Intenta crear un mecanismo que permita insertar y excluir elementos dentro de la lista, usando para ello un valor de índice, de la misma forma que lo harías si usaras arrays. Para ayudarte a entender cómo hacerlo, y para quienes quieran desafiarse a fin de ver cuánto han conseguido asimilar ya sobre programación en MQL5, dejo la siguiente pista:
Intenta modificar el procedimiento de la línea 68 del código 05 para poder conocer el punto de exclusión e inclusión de datos en la lista. Una vez que hayas conseguido hacerlo, intenta modificar adecuadamente el procedimiento de la línea 19 para que reciba un índice que indique en qué posición se modificará la lista. Esto permitirá que crees o elimines un determinado nodo de la lista, creando así algo muy parecido a lo que se ve en la imagen 09. Detalle: para una lista doblemente enlazada, será más simple implementar el código, ya que el código 05 crea una lista doblemente enlazada. Pero nada te impide crear una lista enlazada simple.
Intenta hacerlo antes de ver cuál será mi propuesta para solucionar este tipo de situación. Recuerda que el código no necesita ser igual al que presentaré. Pero debe ser capaz de conseguir el mismo tipo de efecto. Entonces, buen estudio, y que te diviertas pensando en cómo hacerlo. Nos vemos en el próximo artículo.
| Archivo MQ5 | Descripción |
|---|---|
| Code 01 | Lista simple |
| Code 02 | Lista simple |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/16628
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Utilizando redes neuronales en MetaTrader
Utilizando redes neuronales en MetaTrader
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso