
Del básico al intermedio: Colas, listas y árboles (I)

Introducción
En el artículo anterior "Del básico al intermedio: Como burbujas de jabón", se mostró cómo podríamos implementar un mecanismo de ordenación muy simple. Aunque no sea tan eficiente en términos de tiempo de ejecución, en muchos casos resulta adecuado para una amplia variedad de situaciones, cuando el objetivo es ordenar una serie de datos y, así, simplificar la tarea de interpretarlos y realizar búsquedas simples en ellos.
El tipo de mecanismo mostrado en el artículo anterior no siempre fno siempre actúa por sí solo. La mayoría de las veces, los sistemas de ordenación y búsqueda están vinculados a otros tipos de mecanismos. En este artículo, abordaremos uno de estos mecanismos.
Es cierto que, aunque todavía nos centramos en contenidos más básicos, para algunos lo que se verá aquí puede parecer más avanzado. Sin embargo, todo ello está ligado a las bases o fundamentos que todo programador profesional necesita conocer.
Bien, para comenzar correctamente, pasemos a un nuevo tema. Recuerda que, si tienes alguna dificultad para entender lo explicado aquí o se trata de elementos que no se explican en este artículo, debes consultar los artículos anteriores. En ellos encontrarás toda la información necesaria para comprender este artículo.
Colas, listas y árboles (I)
Existe un tipo de material que muchos principiantes acaban despreciando porque lo consideran innecesario, cuando en realidad conviene asimilarlo y comprenderlo muy bien. Este material, que muchos principiantes desprecian, tiene como objetivo precisamente permitirnos un análisis y una estructuración adecuados de los datos.
Ahora, presta atención, estimado lector. De nada sirve estudiar cómo crear un Asesor Experto o incluso un indicador simple si no sabes analizar correctamente todos los datos que genera la aplicación. Ahora, detente y piensa un poco. Si puedes entender cómo analizar y clasificar los datos que recibe tu aplicación para funcionar, podrás simplificar todo su funcionamiento y, en consecuencia, será más rápida.
Actualmente, hay un gran revuelo en torno al machine learning y temas similares. Sin embargo, incluso los sistemas de inteligencia artificial no son más que simples clasificadores y sistemas de análisis estadístico de datos. En ningún caso hay inteligencia real en esos sistemas capaz de superar la creatividad y la capacidad de comprensión humanas sobre un tema determinado.
Es decir, al final, aunque la inteligencia artificial o el aprendizaje automático, que muchos consideran lo máximo, puedan parecer sorprendentes, no son más que algoritmos capaces de usar una serie de fundamentos que todo buen programador debe dominar. Entender cómo y, sobre todo, por qué usar este modelo de implementación y no otro puede marcar la diferencia. Solo podrás dominarlo con el tiempo, una buena dosis de práctica y experiencia. El objetivo de estos artículos no es decirte cuándo usar este o aquel modelo de implementación, sino presentar los modelos y mostrar cómo pueden utilizarse mediante MQL5 para que MetaTrader 5 genere los resultados.
Bien, existe cierta secuencia lógica, si podemos llamarla así, para presentar el material que veremos aquí. Y, como quiero ser lo más didáctico posible, y algunos principiantes pueden no entender la importancia de lo que se verá, vamos a comenzar con la implementación más simple de todas, es decir, las colas.
En principio, una cola es equivalente a un array. A pesar de esta equivalencia, una cola puede adoptar diversas formas, algunas muy diferentes entre sí. Por consiguiente, estas formas pueden tener objetivos completamente diferentes, dependiendo de cada caso específico y de cómo se implemente. Precisamente por parecerse tanto a un array de datos, muchas veces gran parte de los principiantes las confunde, y no sin razón, con un array. Sin embargo, las colas no son necesariamente arrays, ya que el objetivo y la forma de trabajar con ellas son muy diferentes de la forma de trabajar con arrays propiamente dichos y su objetivo.
Como las colas pueden presentar características muy marcadas y, al mismo tiempo, bastante interesantes, e incluso pueden tener implementaciones muy exóticas según los recursos que ofrezca el lenguaje, vamos a comenzar con algo muy simple. Esto ocurre porque aún no se han explicado el concepto y el funcionamiento de una clase. Sin embargo, ya se han explicado elementos suficientes para que podamos implementar diversas estructuras sin mucha dificultad. Con esto, podemos escribir o, mejor dicho, implementar el código que se ve a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stFIFO 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. T Restore(void) 13. { 14. T local = NULL; 15. 16. if (value.Size() > 0) 17. { 18. local = value[0]; 19. ArrayRemove(value, 0, 1); 20. }; 21. return local; 22. }; 23. //+----------------+ 24. void Stock(T arg) 25. { 26. T local[1]; 27. local[0] = arg; 28. ArrayInsert(value, local, value.Size()); 29. } 30. //+----------------+ 31. }; 32. //+------------------------------------------------------------------+ 33. void OnStart(void) 34. { 35. stFIFO <char> fifo; 36. 37. fifo.Stock(10); 38. fifo.Stock(84); 39. fifo.Stock(-6); 40. 41. Print(fifo.Restore()); 42. Print(fifo.Restore()); 43. Print(fifo.Restore()); 44. Print(fifo.Restore()); 45. } 46. //+------------------------------------------------------------------+
Código 01
Bien, este es nuestro primer paso hacia una comprensión más amplia de estas estructuras, conocidas en programación como colas, listas y árboles. Ahora, quiero que prestes atención a algunos detalles de este código, estimado lector. Observa que estamos declarando un array dinámico en la línea ocho, y que ese array puede ser de cualquier tipo, como ya puedes deducir con solo observar la declaración de la línea ocho.
Este array no debe entenderse como los que hemos visto hasta ahora. La razón está en la función de la línea 12 y en el procedimiento de la línea 24. Estos procedimientos y funciones pueden tener cualquier nombre. Lo que realmente importa es cómo funcionan. Por tanto, presta mucha atención a lo que se explicará. Esto se debe a que, dependiendo de las funciones y los procedimientos involucrados, lo que se implementa puede cambiar rápidamente. Esto puede hacer que varíe el tipo de cola o provocar incluso un cambio drástico, hasta el punto de que, en lugar de implementar una cola, implementemos una lista o incluso un árbol.
Bien, esta es la parte fácil. Si observas el código de la función Restore, en la línea 12, verás que, cuando hay datos en el array declarado en la línea 8, siempre almacenamos el dato del índice 0 del array para después devolverlo al autor de la llamada. La parte realmente importante que hay que observar aquí es justamente lo que hará la línea 19. Su objetivo es eliminar precisamente el índice cero. Pero espera un poco. No lo entendí. Si siempre estamos devolviendo el contenido del índice cero, al eliminar ese mismo índice acabaremos generando cierta inconsistencia en el código. Ya que, en la siguiente llamada, el índice cero no contendrá ningún dato.
Bien, estimado lector, en realidad, eso no es exactamente lo que ocurrirá. Como dije, muchos principiantes acaban confundiendo los conceptos, precisamente porque solo revisan el código de forma superficial, sin entender realmente lo que ocurre internamente. Pero te garantizo que, pronto lo entenderás mejor. Solo presta atención a lo que explicaré.
Bien, ahora sabemos que la función de la línea doce siempre devolverá el contenido presente en el índice cero del array. ¿Y el procedimiento de la línea 24? ¿Qué hace? Bien, en este caso, este procedimiento almacena en el array los datos que se le envían. Sin embargo, esos mismos datos siempre se almacenarán al final del array. Hum, no entendí. ¿Podrías explicar esto un poco mejor?
Sí, estimado lector. Ya sabes que un array puede contener diversos índices, desde cero hasta cualquier valor. Cuando el primer dato se envía al procedimiento Stock de la línea 24, se almacenará en el índice cero. Hasta ahí todo normal, ya que cuando usemos la función Restore leeremos precisamente el contenido del índice cero. Aquí es donde muchos principiantes se confunden. El siguiente dato enviado a Stock se almacenará en el índice uno. Esto ocurre porque ya hay un dato en el índice cero. El siguiente se almacenará en el índice dos por la misma razón: ya hay un dato en el índice uno. Y así sucesivamente.
No obstante, en cualquiera de estas situaciones, la función Restore seguirá leyendo siempre el contenido del índice cero. Pero aquí es donde la explicación se vuelve interesante. Cuando usamos la función Restore, el índice decrementa en una unidad. Así creamos una cola de procesamiento. Para ver esto en la práctica, observa la lista de comandos del procedimiento OnStart, de la línea 33. Cuando se ejecutan las líneas 37 a 39, se creará una cola, exactamente en el orden en que declaramos los valores. En cambio, cuando se ejecuten las líneas 41 a 44, leeremos lo que se había insertado en la cola. Parece un tanto extraño, pero funciona. Observa el resultado de la ejecución en la siguiente imagen.
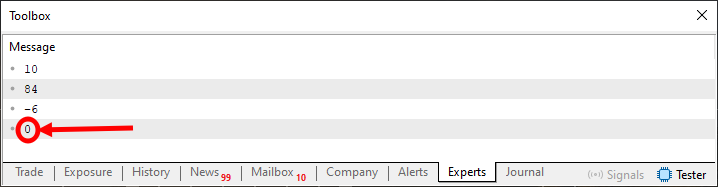
Imagen 01
Observa que en la imagen 01 tenemos un elemento diferente destacado. Este elemento lo devuelve la función Restore porque ya no hay ningún elemento en la cola. Esto ocurre porque en la línea 14 declaramos cuál será el valor de retorno cuando no haya ningún dato almacenado en el array declarado en la línea 8.
Es posible notar claramente que, aunque siempre consultemos el índice cero en la función Restore, aun así podemos ver los datos que se insertaron en la cola. Este tipo de cola tiene una denominación especial: FIFO, es decir, el primero en entrar es el primero en salir. Procura hacer algunas pruebas para entender esto mejor. Por ejemplo, añade algunos valores a la cola, lee parte de ellos y luego añade más valores. Intenta entender así cómo funciona este proceso de lectura y escritura.
Este tipo de cola es muy útil en diversas situaciones en las que necesitamos analizar los datos en un orden concreto y no podemos perderlos de vista. Por eso, conviene que practiques y entiendas cómo funciona este primer código antes de pasar al siguiente.
En el siguiente código, que podrás ver un poco más adelante, crearemos otro tipo de cola con un objetivo completamente diferente al que vimos hace poco. Pero, antes de intentar entender qué ocurrirá en el próximo código, te sugiero firmemente, estimado lector, que dediques un tiempo a entender realmente lo que se vio en el código 01 y cómo funciona. Así evitarás confundirlo con lo que veremos en el siguiente código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stQueue 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. uint c_Pos, 10. c_Max; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Init(uint arg) 15. { 16. ArrayResize(value, arg + 1); 17. c_Pos = c_Max = 0; 18. } 19. //+----------------+ 20. bool GetInfo(T &arg) 21. { 22. if (c_Pos == c_Max) 23. return false; 24. c_Pos = (c_Pos < value.Size() - 1 ? c_Pos + 1 : 0); 25. arg = value[c_Pos]; 26. 27. return true; 28. } 29. //+----------------+ 30. void Stock(const T arg) 31. { 32. c_Max = (c_Max < value.Size() - 1 ? c_Max + 1 : 0); 33. c_Pos = (c_Pos == c_Max ? (c_Pos < value.Size() - 1 ? c_Pos + 1 : 0) : c_Pos); 34. value[c_Max] = arg; 35. } 36. //+----------------+ 37. }; 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. stQueue <char> Queue; 42. 43. Queue.Init(5); 44. 45. Queue.Stock(10); 46. Queue.Stock(84); 47. Queue.Stock(-6); 48. Queue.Stock(15); 49. Queue.Stock(-35); 50. Queue.Stock(40); 51. Queue.Stock(-35); 52. 53. for (char info; Queue.GetInfo(info);) 54. Print(info); 55. } 56. //+------------------------------------------------------------------+
Código 02
En este código 02 estamos implementando otro tipo de cola, conocida entre los programadores como cola circular. Aunque este tipo de implementación es más sencillo cuando se utilizan clases, nada nos impide implementarlo con los recursos ya explicados en artículos anteriores. Cuando la implementación se haga mediante clases, verás que todo será mucho más sencillo, tanto al crearla como al usar la implementación presentada aquí. Pero ese es un tema para otro momento. Centrémonos en lo que tenemos ahora mismo.
Ahora, presta aún más atención, estimado lector. Si el código 01 te pareció un tanto confuso y complicado, el código 02 te dejará aún más desorientado, ya que aquí estamos haciendo algo que, para muchos, puede parecer pura locura. Aunque, en la práctica, puede ser muy útil en muchos casos. Observa que parte de la estructura declarada en la línea cuatro del código 02, se parece bastante a lo que se hizo en el código 01. Incluso contiene fragmentos muy parecidos. Sin embargo, la implementación que se hace aquí es muy diferente de lo que se hizo en el código 01. Y no solo eso. Aquí, en este código 02, algunos datos pueden perderse, a diferencia de lo que ocurría en el código 01.
Pero espera un poco. ¿cómo es posible que se puedan perder datos? ¿No es esto un problema para el código? En realidad, no, estimado lector. Existen situaciones en las que se espera que esto ocurra, o, dicho de otro modo, podemos perder datos sin que eso afecte al resultado final. Tal vez esto les parezca un tanto extraño a muchos de ustedes. Pero piensa en el caso de las medias móviles que usan en el gráfico. Las medias móviles funcionan, en cierto modo, como una cola de valores, donde los más antiguos se descartan. Por ejemplo, una media móvil de 20 períodos almacena 20 valores: el primero es el más reciente y el último se descartará en cuanto entre un valor más reciente en la cola.
Ahora, presta atención, porque esto es importante. Como tenemos un intervalo fijo de valores y estos se sustituyen por otros más nuevos, no debemos llamar lista a este tipo de estructura, sino cola. Las listas de valores cumplen otra función; las colas, en cambio, tienen un propósito muy sencillo y práctico. No es raro confundir estos dos términos. Pero, para que no tengamos problemas de interpretación, llamamos colas a la estructura que se muestra aquí. Aunque, en principio, esto te parezca una lista de valores.
Bien, ahora observa que, en este caso de la cola circular, necesitamos una forma de limitar el rango, o la cantidad de valores de la cola. Esto se hace mediante el procedimiento de la línea 14. Aquí indicamos la cantidad de valores que tendrá la cola; esa cantidad puede ser cualquier valor mayor que cero. Con esto, en la línea 16, asignamos memoria suficiente para que el array dinámico de la línea ocho se construya y se mantenga en memoria. Sin embargo, como inicializamos nuestra cola circular, también necesitamos inicializar dos valores adicionales. Esto se hace en la línea 17. Con esto, la cola queda construida y lista para recibir datos o leerlos.
Ahora viene la parte en la que muchos suelen confundirse bastante en el primer contacto con este tipo de implementación. Como necesitamos leer elementos de la cola, implementamos la función de la línea 20. Esta función devuelve un elemento cualquiera de la cola. ¿Qué elemento? Bien, eso depende, estimado lector. Para entender el motivo de mi respuesta, observa que, en la línea 22, se realiza una comprobación. Si el valor c_Pos, que indica la posición actual que se debe leer, es igual a c_Max, que indica la posición actual en la que se debe escribir, no hay elementos para devolver. Por esta razón, la comprobación de la línea 22 puede devolver false en algunos casos.
Si esto no ocurre, significa que significa que hay algún valor disponible para ser leído. En esta situación, usamos la línea 24 para calcular la nueva posición de lectura dentro de la cola. ¿Por qué necesitamos este cálculo? ¿No sería mucho más simple incrementar el valor del contador c_Pos? En realidad, no, estimado lector. Esto ocurre porque trabajamos con una cola circular y, a menos que esta cola contenga el número de elementos que pueden representarse con el tipo uint, realmente tendremos que ajustar, como el de la línea 24. Esto hace que, una vez que el contador c_Pos alcance el límite superior de la cola, vuelva a apuntar al primer índice del array. Así queda creada la cola circular. El resto del código es simple.
Entonces, pasemos al procedimiento de la línea 30, ya que este se encarga de una operación muy curiosa y, al mismo tiempo, muy intrigante. Observa lo siguiente: en la línea 32, encontramos una lógica muy parecida a la de la línea 24, con la única diferencia de que cambia la variable que se debe ajustar. Pero el objetivo es el mismo: volver al inicio del array en cuanto se alcance el número máximo de elementos alocados en la línea 16.
Un momento. Ahora sí que se complica todo. Lo digo porque noto que este mismo valor c_Max se usa en la línea 34 para indicar el índice en el que se almacenará el valor que indicamos. Sin embargo, tú me estás diciendo que la línea 32 volverá periódicamente al índice cero. Entonces, si tenemos capacidad para almacenar 20 elementos y almacenamos 21, es decir, uno más que el límite definido en la línea 16, ¿solo podremos leer un elemento? No, estimado lector. Seguiremos pudiendo leer 20 elementos ya registrados. Sin embargo, el primer elemento almacenado en la cola será sustituido por este nuevo elemento, el elemento 21. Vamos, qué explicación tan confusa. No entiendo cómo podremos hacer esto. Tranquilo, pronto lo entenderás. Pero, para garantizar que mantengamos esta capacidad de lectura en toda la cola circular, es necesario implementar la línea 33. Esta línea hace avanzar la cola sin que necesitemos desplazar ningún elemento del array.
Observa lo siguiente: cuando c_Max sea igual a c_Pos, significa que la cola está completamente llena. De lo contrario, estos valores jamás serán iguales. Como la cola ya está llena, forzamos c_Pos a avanzar a la siguiente posición. Pero, para garantizar que c_Pos apunte a la siguiente posición válida de la cola, usamos un segundo operador ternario, para garantizar que se respeten los límites de la cola circular. Por eso, este segundo operador ternario es exactamente igual al de la línea 24. Como sé que la mayoría sois principiantes y pueden tener cierta dificultad para entender este código 02, en el anexo encontrarás un código ligeramente diferente. El código se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stQueue 05. { 06. #define macro_AdjustLimit(A) (A < value.Size() - 1 ? A + 1 : 0) 07. //+----------------+ 08. private: 09. //+----------------+ 10. T value[]; 11. uint c_Pos, 12. c_Max; 13. //+----------------+ 14. public: 15. //+----------------+ 16. void Init(uint arg) 17. { 18. ArrayResize(value, arg + 1); 19. c_Pos = c_Max = 0; 20. } 21. //+----------------+ 22. bool GetInfo(T &arg) 23. { 24. if (c_Pos == c_Max) 25. return false; 26. c_Pos = macro_AdjustLimit(c_Pos); 27. arg = value[c_Pos]; 28. 29. return true; 30. } 31. //+----------------+ 32. void Stock(const T arg) 33. { 34. c_Max = macro_AdjustLimit(c_Max); 35. c_Pos = (c_Pos == c_Max ? macro_AdjustLimit(c_Pos) : c_Pos); 36. value[c_Max] = arg; 37. } 38. //+----------------+ 39. #undef macro_AdjustLimit 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. stQueue <char> Queue; 46. 47. Queue.Init(5); 48. 49. Queue.Stock(10); 50. Queue.Stock(84); 51. Queue.Stock(-6); 52. Queue.Stock(15); 53. Queue.Stock(-35); 54. Queue.Stock(40); 55. Queue.Stock(-35); 56. 57. for (char info; Queue.GetInfo(info);) 58. Print(info); 59. } 60. //+------------------------------------------------------------------+
Código 03
Este código 03 hace exactamente lo mismo que el código 02. La única diferencia es la definición de la macro en la línea seis, en este código 03. Sin embargo, esto hace que la misma línea 33 del código 02, sea algo más simple de entender. Esto ocurre porque la línea 35 del código 03 es mucho más fácil de leer. Aunque sea lo mismo que la línea 33 del código 02, resulta más fácil de leer.
Sin embargo, lo que nos interesa es ver cómo funciona esta estructura, para crear y mantener la llamada cola circular. Para poder probar esta estructura que crea la cola circular, usamos el contenido del procedimiento OnStart.
Ahora vamos a centrarnos en el código 03. Así podremos seguir las líneas indicadas. Lo primero que hacemos es definir la propia cola. La definición se realiza en la línea 45. Luego, definimos cuántos elementos tendrá la cola. En este caso, esto se define en la línea 47. Observa que, en este caso, definimos que habrá cinco elementos COMO MÁXIMO.
Ahora viene lo interesante, usar la cola circular. Para ello, usamos las líneas 49 a 55. Observa lo siguiente: tenemos una cola que puede contener, como máximo, cinco elementos. Sin embargo, pedimos que se inserten siete elementos en esta cola. Pregunta: ¿qué ocurrirá aquí? Respuesta: algunos elementos desaparecerán y serán sustituidos a medida que avanza la cola. ¿Cómo podemos estar seguros de ello? Bien, para ello, usamos la línea 57, donde aparece un bucle que puede resultar intrigante a primera vista. Sin embargo, en otro artículo expliqué exactamente cómo podemos trabajar con el comando for para crear bucles con objetivos muy interesantes. Este es uno de esos casos. Observa que el propio bucle crea las condiciones necesarias para ejecutarse y finalizar. Lo que nos interesa es la ejecución de la línea 58. Esa línea permite ver qué elementos se descartaron y qué elementos permanecían en la cola.
Bien, cuando ejecutamos este código 03 o el código 02, obtenemos el resultado que se muestra en la siguiente imagen.
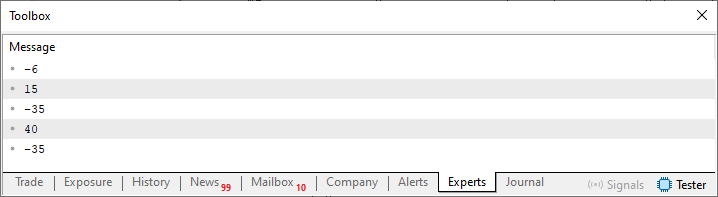
Imagen 02
Ahí lo tienes, estimado lector. Quiero que te detengas un momento y pienses en el resultado mostrado en esta imagen 02. Y compáralo con el contenido del código 03, entre las líneas 49 y 55. ¿Puedes entender qué ocurre aquí? ¿Puedes identificar alguna relación entre lo que se vio en el código 01, en el que implementamos una cola FIFO, de primero en entrar, primero en salir, y esta cola circular que se implementa en este código 03? ¿Sí? ¿No? O tal vez. Bien, tal vez no puedas ver esta relación. Pero sí existe una relación entre lo que se explicó al inicio de este artículo y lo que vemos aquí. La relación es esta: el primer elemento de la cola siempre es el primero que se muestra. Del mismo modo, el último elemento de la cola es el último que se muestra. A diferencia de lo que ocurría antes, aquí limitamos el número de elementos que puede haber en la cola. Ese límite se define en la línea 47 del código 03.
Esta es la parte confusa, que mucha gente no llega a comprender. Cuando empezamos a programar, perdemos mucho tiempo intentando crear o implementar algo. Sin embargo, es muy probable que ya exista en algún lugar una implementación de lo que intentamos hacer. Ahora, piensa en lo siguiente: suponiendo que estés creando un Asesor Experto para analizar una media móvil de X períodos. ¿Por qué necesitas almacenar más de X valores de precio? No tiene sentido. Del mismo modo, no tiene sentido desplazar datos de precios para mantener un array con X valores de precio siempre actualizado. Basta con crear o implementar una estructura de datos como una cola circular. La propia implementación se encargará de mantener los precios siempre actualizados, prácticamente sin operaciones de desplazamiento, ya que los contadores de índice que usamos se encargarán de ese desplazamiento por nosotros. Así, el código ejecutable resulta mucho más rápido y fácil de mantener.
Consideraciones finales
En este artículo, empezamos a explorar uno de los temas menos conocidos entre los programadores principiantes. Muchas veces, las personas se desesperan por aprender programación, pero no procuran comprender los conceptos básicos. Comprender adecuadamente estos conceptos es, a mi modo de ver, mucho más importante y necesario que escribir código una y otra vez. Porque conocer adecuadamente ciertos conceptos puede ayudarte a crear código mucho más seguro, rápido y fácil de mantener.
Entonces, estimado lector, estudia con calma y practica lo aprendido en este artículo. Tardé bastante tiempo en asimilar esta base que intento transmitirte. Cuando estudié este tema, nadie le daba mucha importancia. Todos nos exigían solo resultados, independientemente de cómo se obtuvieran. Pero aquí te muestro el camino. Depende de ti saber cómo recorrerlo. Así tu aprendizaje será lo más fluido y consistente posible. No tengas prisa. Estudia y practica bastante lo aprendido en este artículo. En el próximo artículo, seguiremos tratando colas, listas y árboles.
| Archivo | Descripción |
|---|---|
| Code 01 | Cola simple |
| Code 02 | Cola simple |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/16491
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso