
Del básico al intermedio: Plantilla y Typename (III)

Introducción
El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación final, cuyo objetivo no sea el estudio de los conceptos mostrados aquí.
En el artículo anterior, "Del básico al intermedio: Plantilla y typename (II)", se explicó cómo lidiar con algunas situaciones muy específicas del día a día de los programadores. Ya sea como una actividad esporádica, ya sea como programador profesional, el uso de plantillas de funciones y procedimientos puede ayudar bastante en determinados momentos. Aunque no sea algo muy común ni aplicable en todo momento aquí en MQL5, es bueno saber que tal concepto puede aplicarse y que tiene sus momentos, necesitando, por esta razón, que sea adecuadamente comprendido, a fin de que tú no te confundas al intentar modificar un código que, eventualmente, utilice tal modelado.
Los templates no se aplican solo a funciones y procedimientos. En realidad, tienen un amplio rango de aplicaciones prácticas, siendo más o menos utilizados dependiendo del tipo de aplicación que tú, mi estimado lector, desees desarrollar. Vale recordar —y resaltar una vez más— que podemos implementar el mismo tipo de aplicación sin utilizar plantillas. Aunque, hacer uso de tal herramienta y recurso presente en MQL5 vuelve la fase de implementación más simple y placentera, y evita algunos tipos de fallas difíciles y molestas de ser detectadas.
Plantillas en variables locales
En los dos artículos anteriores, en los que hablamos solo sobre plantillas en funciones o procedimientos, todo era bastante simple e incluso curioso. Pero, debido a las explicaciones dadas, creo que quedó claro que las plantillas de funciones o procedimientos son una forma agradable de delegar el trabajo al compilador, hasta el punto de crear la sobrecarga de una función o procedimiento. Sin embargo, los ejemplos presentados eran muy simples, pues el tipo de dato a ser utilizado se informaba solo en relación con los parámetros de entrada, ya sea de la función o del procedimiento. Aunque, la cosa puede llevarse a un nivel un poco mayor.
Para entender esto, comencemos con un ejemplo simple e interesante: el cálculo de medias. Sí, aunque sea algo sencillo, podemos ver cómo aplicar plantillas a este tipo de situación. Sin embargo, quiero recordarte, estimado lector, que los códigos aquí presentados tienen únicamente fines didácticos. No representan necesariamente un código que sería utilizado en una aplicación real.
Como creo que tú ya comprendiste cómo funciona una función o procedimiento sobrecargado, podremos enfocarnos solo en las partes que realmente merecen destaque, eliminando lo que es innecesario colocar en el código. Así, tenemos de primera mano el código presentado justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. double Averange(const double &arg[]) 16. { 17. double local = 0; 18. 19. for (uint c = 0; c < arg.Size(); c++) 20. local += arg[c]; 21. 22. return local / arg.Size(); 23. } 24. //+------------------------------------------------------------------+ 25. long Averange(const long &arg[]) 26. { 27. long local = 0; 28. 29. for (uint c = 0; c < arg.Size(); c++) 30. local += arg[c]; 31. 32. return local / arg.Size(); 33. } 34. //+------------------------------------------------------------------+
Código 01
Aquí tenemos un código común, cuyo objetivo es calcular la media de un conjunto de datos. Para quien no entiende, el cálculo de la media consiste en sumar todos los valores y luego dividir el resultado de esa suma por el número de elementos presentes en el cálculo. Aunque este tipo de cálculo sea simple, presenta un pequeño problema: los valores pueden ser positivos o negativos. Podemos obtener un valor medio distorsionado, que no represente realmente lo que estamos verdaderamente interesados en saber. Pero esto es un detalle menor, que no viene al caso aquí. Solo lo menciono para que tú sepas que no siempre un código nos proporciona la información deseada, aunque haya sido creado por otra persona. Además, el hecho de que otro programador haya creado un código específico hace que este responda a lo que ese programador estaba buscando, y no a lo que tú puedas estar buscando.
No obstante, creo que no será necesario explicar cómo funciona ese código 01, ya que hace uso de la sobrecarga para que la factorización se realice de la manera más adecuada. Así, el resultado del mismo, cuando se ejecuta, puede observarse en la imagen siguiente.
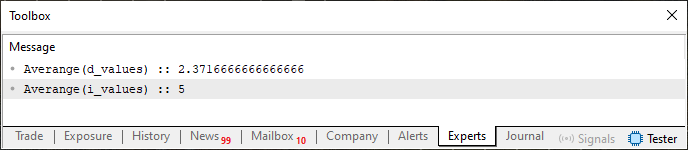
Imagen 01
O sea, algo trivial y simple. Sin embargo, quiero que observes con atención la función implementada en las líneas 15 y 25. ¿Qué tienen en común? Bien, tú podrías decir que son prácticamente idénticas, salvo por una parte muy específica. Esa parte es precisamente el tipo de dato utilizado. Fuera de eso, son lo mismo, sin ninguna diferencia aparente. Y, de hecho, si tú lograste notar eso, debes estar pensando en algo: podemos transformar esas dos funciones, vistas en el código 01, en una plantilla. Esto simplificaría las cosas. No obstante, tengo una duda. En ambas funciones, hay una variable local, que puede verse en las líneas 17 y 27. Sé cómo declarar e implementar la llamada de la función como plantilla, pues ya vi cómo hacerlo en los artículos anteriores. Sin embargo, esta variable local me está incomodando, porque no sé cómo lidiar con ella. Tal vez pueda hacer algo parecido al código presentado justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. double local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return (T)(local / arg.Size()); 24. } 25. //+------------------------------------------------------------------+
Código 02
De hecho, tú podrías hacer lo que se muestra en el código 02, mi estimado lector. Sin embargo, al intentar compilar ese código, recibirías una advertencia del compilador, como se muestra justo abajo.
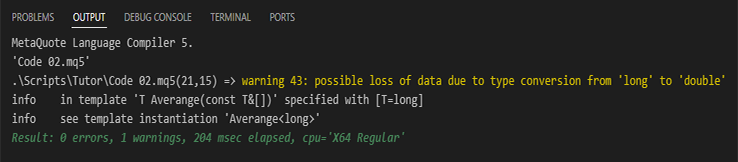
Imagen 02
Observa que NO SE TRATA DE UN MENSAJE DE ERROR, sino de una advertencia. Esto ocurre porque, en la línea 21, donde estamos sumando los valores del array, habrá un momento en que estaremos sumando un valor de punto flotante con un valor entero. Esto puede causar distorsiones en el resultado final. No obstante, el resultado final, cuando tú ejecutes este código (02), será el mismo que podemos ver en la imagen 01. Aun así, esta advertencia del compilador puede resultar un tanto molesta para algunos programadores. Siendo así, ¿cómo corregir este detalle? Bien, para resolver esto, necesitaremos hacer una conversión de tipo, de la misma forma que estamos haciendo en la línea 23, solo que aplicando la conversión aquí en la línea 21. Pero atención: no debes usar lo que se muestra justo abajo.
local += (T)arg[c];
Esto NO RESOLVERÁ LA ADVERTENCIA, ya que necesitamos hacer la conversión para que el valor presente en el array sea compatible con el valor de la variable de la línea 18. Aunque esto pueda parecer complicado, es bastante simple y directo. Todo lo que necesitamos hacer es modificar la línea 21 del código 02 por la línea que podemos ver justo abajo, a continuación.
local += (double)arg[c]; Ahora sí, resolvimos nuestro problema. Tenemos la función Average implementada en forma de plantilla, y es perfectamente funcional. No obstante, existe otra manera de lidiar con estas mismas cuestiones, de modo que no sea necesario modificar tanto el código. Entonces, volvamos al código 01. Observa que el código 02 representa lo que está implementado en el código 01. Si la variable local es la que nos está generando inconvenientes, como se mostró arriba, ¿por qué no hacer algo un poco más elaborado? Así, el propio compilador se encarga de este tipo de inconvenientes. Parece algo atrevido, ¿verdad?
Sin embargo, si tú entendiste realmente cómo el código 01 fue traducido al código 02 y cómo lidiamos con la advertencia disparada por el compilador, debes haber pensado en otra solución. Una que haga posible cambiar el tipo de la variable declarada en la línea 18 del código 02. Eso sí sería una solución realmente interesante. Y es precisamente eso lo que podemos ver siendo implementado justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. T local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return local / arg.Size(); 24. } 25. //+------------------------------------------------------------------+
Código 03
Este código 03 nos da el mismo resultado visto en la imagen 01 y no genera ninguna advertencia por parte del compilador. ¿Por qué? Porque, cuando el compilador nota que necesitamos un tipo entero, adecuará el tipo de la variable al tipo entero. Si el compilador nota que necesitamos un tipo de dato de punto flotante, hará que la variable declarada en la línea 18 sea del tipo adecuado para el uso de punto flotante.
Así, tenemos un código mucho más simple que el código 01, aunque muy parecido con el código 02, sin la necesidad de realizar todos aquellos ajustes. Esto garantiza que la conversión de tipo ocurra y no se disparen advertencias del compilador. Genial, ¿verdad? Creo que, si tú ya habías visto un código parecido con este, debiste haber imaginado cómo debía funcionar aquello. Pero, entendiendo los conceptos básicos y viendo cómo cada cosa encaja, códigos que antes parecían complicados pasan a ser cada vez más simples e interesantes.
Muy bien, esta fue la parte más agradable. Ahora veremos la parte realmente divertida. Considerando las posibilidades de uso presentadas en el código 03, surge el deseo de experimentar eso con otros tipos de datos.
Como hasta el momento solo se mostró el tipo de dato que utiliza la unión, podemos intentar hacer uso de esta misma técnica vista en el código 03, a fin de crear una plantilla aún más amplia. No obstante, para separar adecuadamente las cosas, veremos eso en otro tema.
Usar las cosas en uniones
Primero, veremos lo que se muestra en el código 03 de manera un poco más simple, al menos en este inicio. De hecho, no vamos a modificar nuevamente el código 03, pero vamos a utilizar aquel concepto para crear una región de memoria dinámica dentro de una unión. O sea, vamos a crear una plantilla para generar una unión entre un array y un tipo de dato cualquiera.
Cuando estudiamos cómo una unión sería definida, vimos que está constituida por un bloque con tamaño fijo. Ese bloque, definido en términos de bytes, tiene como valor la cantidad de bytes pertenecientes al tipo de mayor tamaño presente dentro de la unión. Pues bien, podemos hacer que eso no sea una verdad absoluta. Es decir, podemos hacer que una determinada unión sea configurada dinámicamente por el compilador, permitiéndonos crear una unión que, en principio, tendrá un bloque de tamaño dinámico, ya que la anchura, en términos de bytes, será definida en el momento de la compilación de nuestro código, pasando, a partir de entonces, a tener un tamaño fijo.
En este momento, tú puedes estar pensando: "Amigo, pero esto parece algo muy complicado de hacer". Al fin y al cabo, a primera vista, no sé cómo le diremos al compilador cómo trabajar con este tipo de enfoque o implementación. ¿Necesitamos ver esto ahora? Bien, mi estimado lector, de cierta manera, algunos pueden pensar que este concepto es avanzado. Pero, en mi opinión, este aún es un concepto básico que todo principiante debería conocer, ya que facilita mucho la creación de diversos tipos de códigos con un objetivo más amplio.
Sé que muchos pueden estar pensando que estamos yendo demasiado rápido. Sin embargo, estoy yendo lo más despacio posible, sin saltarme ningún concepto ni explicación. Si esta base de conocimiento está bien construida y asimilada, todo lo que se verá después se volverá mucho más natural y fácil de comprender. Aunque, como sé que lo que se verá puede ser algo confuso al principio, comenzaremos con un código mucho más simple. Así, será más agradable y fácil estudiar este nuevo concepto. Pensando de esta forma, empecemos con el código presentado abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ulong info = 0xA1B2C3D4E5F6789A; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. ulong Swap(ulong arg) 13. { 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }info; 19. 20. info.value = arg; 21. 22. PrintFormat("The region is composed of %d bytes", sizeof(info)); 23. 24. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 25. { 26. tmp = info.u8_bits[i]; 27. info.u8_bits[i] = info.u8_bits[j]; 28. info.u8_bits[j] = tmp; 29. } 30. 31. return info.value; 32. } 33. //+------------------------------------------------------------------+
Código 04
Este código aún no utiliza el recurso plantilla. Como ya fue explicado en otro artículo, cuando introdujimos el tema de la unión, no veo necesidad de explicar cómo funciona, ya que eso fue hecho anteriormente. Sin embargo, cuando el código 04 fue presentado, no estábamos interesados en expandirlo. Por lo tanto, esta función que se ve en la línea 12 no existía en realidad. Todo se hacía dentro de OnStart. Pero ahora, debido al hecho de que vamos a explicar plantillas en uniones, es adecuado separar las cosas en un bloque distinto. Esto facilita el primer contacto con plantillas de unión. Luego, veremos que podemos colocar todo en un único bloque de código, tal como se hacía originalmente.
Bien, cuando tú compiles y ejecutes este código 04, verás la respuesta en el terminal de MetaTrader 5.
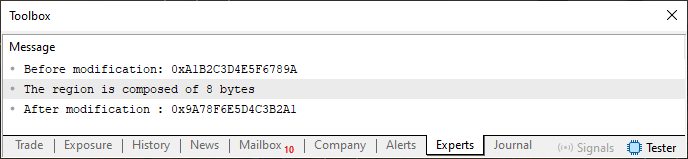
Imagen 03
Es decir, cambiamos los bits de lugar. Así de simple. Ahora, ¿cómo haríamos para cambiar bits de otros tipos de datos? Porque, si tenemos un tipo como ushort, que tiene 2 bytes, y enviamos ese tipo a la función de la línea 12, obtendremos un resultado incorrecto, o al menos algo bastante extraño. Para verificar eso, basta con cambiar la línea seis del código 04 por la línea que se muestra justo abajo.
const ushort info = 0xCADA;
Ahora, cuando ejecutemos este código 04 con esta línea mostrada arriba, el resultado es lo que podemos ver siendo impreso justo abajo, esto en el terminal de MetaTrader 5.
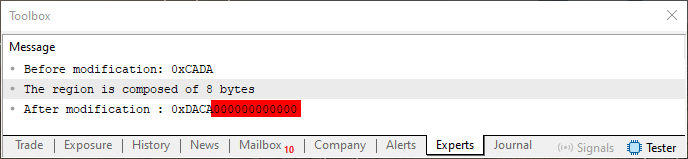
Imagen 04
Ahora, presta atención a una cosa en esta imagen 04: la región que estoy marcando en rojo son datos no deseados añadidos al valor del tipo ushort. Aunque notes que la rotación de hecho ocurrió, esos bytes son un problema. Aún más si necesitas mantener el tipo como ushort. Es precisamente aquí donde entra la plantilla.
Como se vio en el tema anterior, es posible trabajar con valores de diferentes tipos de manera muy simple, práctica y segura. Esto nos permite efectuar un cálculo de media de valores. De hecho, nuestra aplicación podía trabajar con valores de tipo entero y de tipo punto flotante sin ningún problema. Pero, ¿cómo podríamos hacer lo mismo aquí, donde estamos haciendo uso y necesitamos de una unión para tornar el código más simple? Bien, esta es la parte interesante y divertida.
Primero, necesitamos transformar el código 04 en un código con capacidad de plantilla. Con base en lo que ya fue mostrado hasta aquí, hacer eso es muy simple y directo, principalmente si tú estás de hecho comprendiendo los conceptos explicados. Entonces, sin mucho problema, tú creas el código mostrado a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. ulong value; 18. uchar u8_bits[sizeof(ulong)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
Código 05
Sin embargo, al intentar compilar este código 05, tú recibes una advertencia del compilador. Esta advertencia puede observarse justo en la imagen de abajo.

Imagen 05
Ahora, piensa conmigo. Estás viendo esta advertencia, que informa que el valor en la línea 32 no es compatible con el valor de retorno, pues son de tipos diferentes. ¿Dónde viste esto antes? Bien, si tú retrocedes un poco en este mismo artículo, verás algo semejante en la imagen 02. Con base en eso, ya tienes medios para solucionar este mismo problema. Puedes seguir por un camino o por otro. No obstante, como debiste haber notado en el tema anterior, el mejor camino, que nos obliga a hacer menos modificaciones en el código, es aquel que transforma la variable de tipo incorrecto en un tipo esperado como retorno. Es decir, NO necesitamos modificar la línea 32, sino la línea 15, donde la unión de valores está siendo declarada.
Observa lo siguiente: ¿por qué no estoy diciendo que modifiquemos la línea 17? Pues es allí donde está la variable usada en la línea 32 para retornar el valor. El motivo para esto es que no vamos a alterar solo la línea 17. Necesitamos también modificar el array ubicado en la línea 18. Si modificamos solamente la línea 17, corregiremos parte del problema. Sin embargo, el problema se moverá de un punto a otro, ya que no estaremos modificando el ancho de la unión. Por eso, es importante prestar atención a lo que se está programando. Si tú tomas los debidos cuidados, no habrá problemas, ya que tu código pasará a tener una utilidad mayor, cubriendo más casos con mucho menos riesgo y esfuerzo.
Así, con esta pequeña introducción de lo que necesita hacerse, podemos modificar el código 05, como se muestra justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. T value; 18. uchar u8_bits[sizeof(T)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
Código 06
Al ejecutar este código 06, que no es más que una modificación del código 05, obtenemos el resultado presentado en la imagen de abajo.
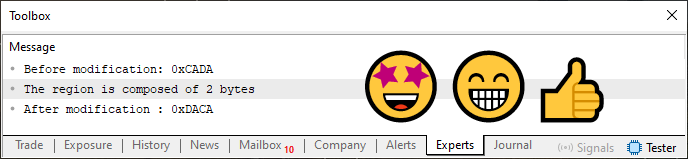
Imagen 06
Simplemente perfecto y maravilloso. Ahora tenemos la respuesta correcta. Además, transformamos el código 04 en un código mucho mejor. Ahora que podemos hacer que el compilador cree y genere funciones o procedimientos sobrecargados para nosotros, podemos utilizar cualquier tipo de dato sin ninguna preocupación. Con base en la plantilla de este código 06, el compilador creará los procedimientos adecuados para que la rutina funcione correctamente, dándonos siempre resultados coherentes con lo esperado.
Muy bien, debido al hecho de que ya hemos creado un modelo mucho más interesante, tú puedes estar pensando: Bien, entonces eso es todo. Ahora ya sé cómo crear plantillas de uniones. Cierto, mi estimado lector, tú ya sabes cómo hacerlo en un caso muy simple. Sin embargo, lo que mostré aquí NO ES UNA PLANTILLA DE UNIÓN. Se trata solamente de la adecuación de una unión para utilizar una plantilla en una función o procedimiento. Para alcanzar lo que sería una plantilla de unión, el asunto se vuelve un poco más profundo, como algunos dicen. Pero, para separar los temas de manera adecuada, veremos cómo hacerlo en un nuevo tema. Así, no correrás el riesgo de confundir una cosa con la otra.
Definir una plantilla de unión
Bien, ahora vamos a profundizar un poco más en la cuestión sobre cómo trabajar con plantillas. A diferencia de lo que se ha visto hasta este momento, cuando definimos una plantilla para una unión, al igual que para otros tipos que veremos más adelante, necesitamos tomar algunas decisiones que dejan a muchos programadores principiantes inquietos al ver cómo debe implementarse el código. Esto se debe a que parte del código que construiremos puede terminar teniendo un aspecto algo exótico, por así decirlo.
Si por ventura tú sientes que el código se está volviendo muy complicado y confuso, detente, relájate y da un paso atrás, mi estimado lector. Lo ideal es que procures estudiar y practicar lo que ya fue mostrado hasta aquí, hasta comprender adecuadamente los principios y conceptos adoptados. Solo después, vuelve y comienza desde donde habías parado antes de la pausa.
No intentes atropellar las cosas ni pienses que ya entendiste algo solo porque viste un código que utiliza cierto recurso, ya que las cosas no funcionan bien así. Comprende el concepto de manera adecuada y correcta, y todo se volverá mucho más simple y fácil de entender.
Pues bien, lo que haremos ahora, de hecho, es bastante confuso en este primer momento. La confusión quedará para el próximo artículo. De cualquier forma, lo que se verá aquí necesita hacerse, y tú necesitas entender lo que ocurre cuando encuentres algo parecido o cuando necesites implementar algo que deba hacerse de la manera en que será mostrado.
Como de costumbre, comenzaremos con algo muy simple y didáctico. Algo semejante al código 06, presentado en el tema anterior, será nuestro objetivo. Sin embargo, NO USAREMOS UNA FUNCIÓN O PROCEDIMIENTO. Eso se verá después, pues es algo más complicado de entender. Entonces, en este primer momento, haremos todo dentro de la función OnStart. Siendo así, comencemos. Primero, el código presentado a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. //+----------------+ 07. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 08. { \ 09. tmp = X.u8_bits[i]; \ 10. X.u8_bits[i] = X.u8_bits[j]; \ 11. X.u8_bits[j] = tmp; \ 12. } 13. //+----------------+ 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }; 19. 20. { 21. un_01 info; 22. 23. info.value = 0xA1B2C3D4E5F6789A; 24. PrintFormat("The region is composed of %d bytes", sizeof(info)); 25. PrintFormat("Before modification: 0x%I64X", info.value); 26. macro_Swap(info); 27. PrintFormat("After modification : 0x%I64X", info.value); 28. } 29. 30. { 31. un_01 info; 32. 33. info.value = 0xCADA; 34. PrintFormat("The region is composed of %d bytes", sizeof(info)); 35. PrintFormat("Before modification: 0x%I64X", info.value); 36. macro_Swap(info); 37. PrintFormat("After modification : 0x%I64X", info.value); 38. } 39. } 40. //+------------------------------------------------------------------+
Código 07
Cuando se ejecute, este código 07 producirá un resultado muy parecido con el código 04. Sin embargo, aquí estamos ingresando dos valores al mismo tiempo, con el objetivo de mostrar las cosas de una sola vez. De esta forma, el resultado real de la ejecución de este código 07 es lo que podemos ver justo abajo.
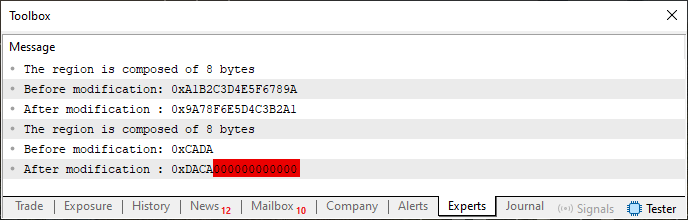
Imagen 07
De la misma manera que marcamos en la imagen 04, donde había valores inapropiados siendo colocados en el resultado final, aquí en la imagen 07 vemos esos mismos valores apareciendo nuevamente. Simplificando: tenemos un valor que sería de una variable ushort, pero que sufre interferencia de otros valores indebidos. Sé que, al principio, este código puede parecer correcto, pudiendo incluso estar correcto, dependiendo de lo que se esté implementando. No obstante, el objetivo de este estudio es precisamente promover la creación de una plantilla para que podamos utilizar las cosas de forma que generen un resultado parecido con el que fue visto y obtenido en el tema anterior.
Sin embargo, sin hacer uso de funciones o procedimientos. Nota otra cosa: precisamente para evitar utilizar una función o procedimiento en este momento, estamos trasladando la parte común del código dentro de una macro. Ella puede verse a partir de la línea siete. Como el funcionamiento de las macros ya fue explicado, no entraré en detalles, ya que no veo necesidad en este caso específico.
Bien, entonces vamos a la cuestión principal. A diferencia de lo que fue hecho en el tema anterior, ahora lidiamos con un tipo de situación diferente, pero con un objetivo parecido. Observa que, ahora, aquel concepto que antes podía aplicarse ya no podrá ser aplicado. Esto porque no tenemos una función o procedimiento aquí en el código 07 para poder aplicar una plantilla sobre él. No obstante, el concepto base que se aplicará aquí es muy similar al que se ha venido aplicando, solo que un tanto confuso al principio.
Presta atención, estimado lector. Nuestro objetivo es crear un código que sea capaz de manejar cualquier tipo de dato, tal como hicimos al construir lo que sería el código 06. Sin embargo, para alcanzar este objetivo, necesitamos recurrir a un tipo de sobrecarga un poco diferente. Hasta el momento, la sobrecarga se aplicaba sobre funciones o procedimientos. No obstante, ahora necesitamos una sobrecarga de tipo. Esto puede parecer confuso, pero el concepto básico es el mismo que cuando usamos sobrecarga para funciones o procedimientos.
Entonces, observa el siguiente detalle: necesitamos que la unión declarada en la línea 14 del código 07 funcione de la misma manera que la unión presente en el código 06. ¿Pero cómo hacer eso? Es simple. Basta con decir que esta unión de la línea 14 es una plantilla. ¿Eh? No lo entiendo. ¿Cómo haremos eso? Bien, como dije, esto puede ser un poco confuso en este primer contacto con este tipo de modelado. Para comenzar, esta unión que vemos en la línea 14 es de ámbito local. Y toda plantilla DEBE SER GLOBAL. Así que lo primero que debe hacerse es remover esta declaración del procedimiento OnStart. Al hacer esto, la declaración se convertirá en un modelo global. Después, simplemente necesitamos añadir lo que ya estamos acostumbrados a ver o sea, la transformación de la unión en una plantilla, así como haríamos para una función o procedimiento. De esta manera, surge lo que se muestra en el código 08, justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. //+----------------+ 14. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 15. { \ 16. tmp = X.u8_bits[i]; \ 17. X.u8_bits[i] = X.u8_bits[j]; \ 18. X.u8_bits[j] = tmp; \ 19. } 20. //+----------------+ 21. 22. { 23. un_01 info; 24. 25. info.value = 0xA1B2C3D4E5F6789A; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. macro_Swap(info); 29. PrintFormat("After modification : 0x%I64X", info.value); 30. } 31. 32. { 33. un_01 info; 34. 35. info.value = 0xCADA; 36. PrintFormat("The region is composed of %d bytes", sizeof(info)); 37. PrintFormat("Before modification: 0x%I64X", info.value); 38. macro_Swap(info); 39. PrintFormat("After modification : 0x%I64X", info.value); 40. } 41. } 42. //+------------------------------------------------------------------+
Código 08
Hasta este punto, todo ha sido muy fácil y simple, ya que estamos lidiando exactamente con algo que ya sabemos cómo manejar. Sin embargo, y aquí es donde las cosas comienzan a complicarse: si tú intentas compilar este código 08, no lo lograrás. Esto se debe a que, desde el punto de vista del compilador, este código contiene un tipo de error difícil de comprender para principiantes. El tipo de información que el compilador reportará cuando intentemos compilar este código se muestra justo abajo.
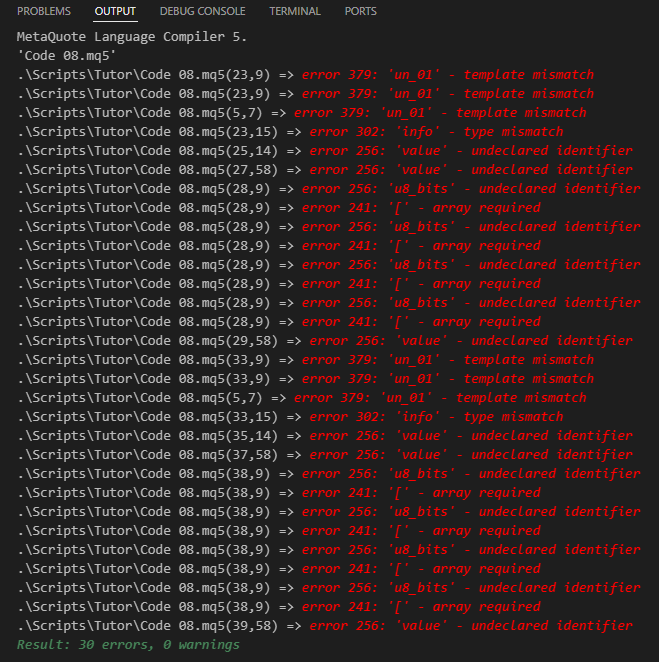
Imagen 08
Definitivamente, parece que no estamos en el camino correcto, ya que esta cantidad de errores es algo desalentadora. Pero es aquí donde se encuentra la cuestión realmente confusa para muchos principiantes. Porque lo que está generando todos estos errores, que tú puedes observar en la imagen 08, es el hecho de que el compilador NO SABE qué tipo de dato debe ser utilizado. Como ya he dado muchas explicaciones sobre diversos temas en este artículo y NO QUIERO confundirte, estimado lector, mostrando cómo resolver esta cuestión, haré una pausa en este momento, dejando esta cuestión para ser explicada en el próximo artículo.
Consideraciones finales
En este artículo, comenzamos a explorar un tema muy complicado, al principio, si tú no estás, de hecho, practicando lo que se viene mostrando. Sin embargo, como quiero que tú, mi querido y estimado lector, aprendas de la manera correcta, decidí interrumpir el último tema de este artículo. Como explicar adecuadamente cómo decirle al compilador cómo actuar demanda tiempo, no quiero volver aún más confuso un tema que ya es bastante complicado de entender.
Así que procura practicar lo que se está mostrando en este artículo. Pero, principalmente, trata de imaginar cómo decirle al compilador qué tipo de dato deberá utilizarse para que el código 08, presentado al final de este artículo, pueda realmente funcionar. Piensa en ello con calma, pues en el próximo artículo veremos cómo hacerlo de hecho, así como también cómo utilizar esto a nuestro favor.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15669
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Cuerpo en Connexus (Parte 4): Añadiendo compatibilidad con cuerpos HTTP
Cuerpo en Connexus (Parte 4): Añadiendo compatibilidad con cuerpos HTTP
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
un_01 <ulong> info;